构建可扩展、生产级的 Agentic RAG Pipeline
面向大型数据集、符合行业标准的 agentic RAG pipeline 需要以清晰的、可扩展的分层架构来构建。我们将系统结构化,使得 agent 能并行地进行推理、获取上下文、使用工具以及与数据库对话。
面向大型数据集、符合行业标准的 agentic RAG pipeline 需要以清晰的、可扩展的分层架构来构建。我们将系统结构化,使得 agent 能并行地进行推理、获取上下文、使用工具以及与数据库对话。每一层负责一个明确的职责,从 data ingestion 到 model serving 再到 agent coordination。分层方法有助于系统可预测地扩展,同时为终端用户保持低响应时延。
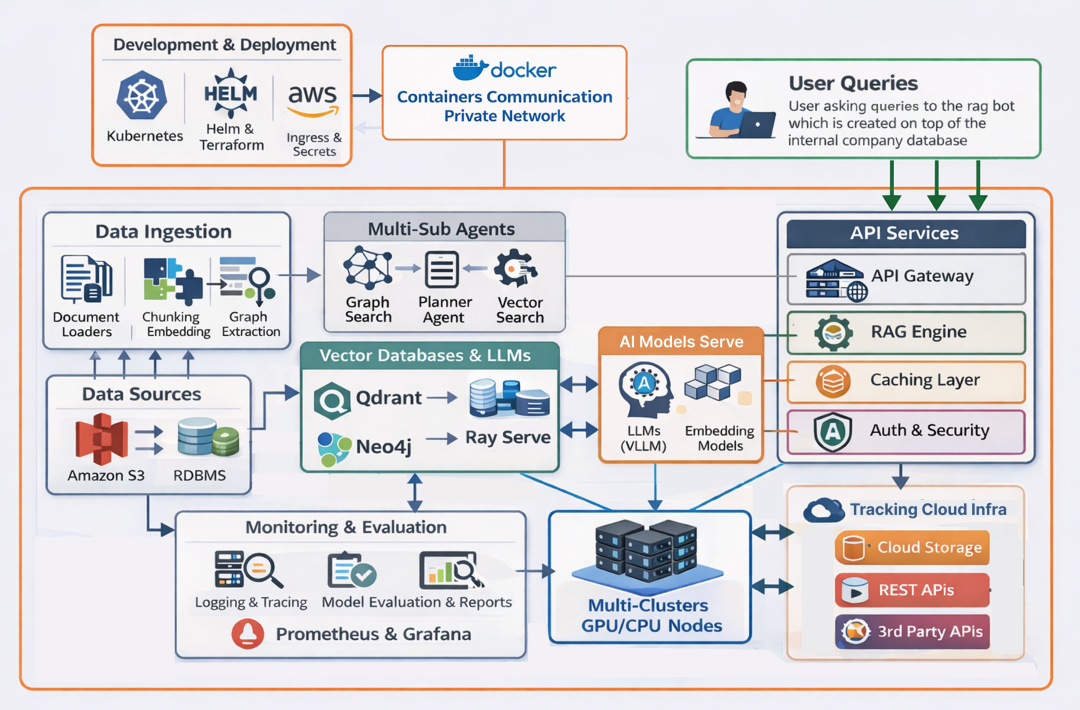
Scalable RAG Pipeline (Created by Fareed Khan)
一个围绕 agent 构建的可扩展 RAG pipeline,通常包含六个核心层:
- Data Ingestion Layer:通过文档加载、chunking、indexing 将原始数据转为结构化知识;可结合 S3、RDBMS、Ray 扩展。
- AI Compute Layer:高效运行 LLM 与 embeddings,将模型映射到 GPU/CPU,实现低延迟、大规模推理。
- Agentic AI Pipeline:支持 agent 推理、查询增强、工作流编排,配合 API、缓存与分布式执行。
- Tools & Sandbox:提供安全的计算、搜索与 API 测试环境,不影响生产工作负载。
- Infrastructure as Code (IaC):自动化部署、网络、集群与 autoscaling,确保基础设施可复现、可扩展。
- Deployment & Evaluation:处理密钥、数据库、集群、监控与日志,保证规模化下的可靠运行。
本文将围绕 agent 构建上述六层 RAG pipeline,展示如何搭建一个可扩展系统。
所有代码可在我的 GitHub 仓库获取:
GitHub - FareedKhan-dev/scalable-rag-pipeline: A scalable RAG platform combining LangGraph agents…
目录
- 构建可扩展、生产级的 Agentic RAG Pipeline
-
创建 EKS 集群
-
推理与延迟测试
-
Redis 与 Grafana 仪表盘分析
-
可观测性与追踪
-
持续评估流水线
-
卓越运营与维护
-
集群引导与 Secrets
-
数据库与 Ingress 部署
-
Ray AI 集群部署
-
基础与网络
-
计算集群(EKS & IAM)
-
托管数据存储
-
使用 Karpenter 的 Autoscaling
-
安全代码 Sandbox
-
确定性与搜索工具
-
API 路由与网关逻辑
-
API 基础与可观测性
-
异步数据网关
-
上下文记忆与语义缓存
-
使用 LangGraph 构建工作流
-
查询增强与应用入口
-
模型配置与硬件映射
-
使用 vLLM 与 Ray 进行模型服务
-
Serving Embeddings 与 Re-Rankers
-
异步内部客户端
-
文档加载与配置
-
Chunking 与知识图谱
-
高吞吐 Indexing
-
基于 Ray 的事件驱动工作流
-
开发流程管理
-
核心通用工具
-
Autoscaling、Evaluation、AI Compute Workflows 等
-
目录
-
我们的“大数据”与噪声文档
-
构建企业级代码库
-
Data Ingestion Layer
-
AI Compute Layer
-
Agentic AI Pipeline
-
Tools & Sandbox
-
Infrastructure as Code (IaC)
-
部署
-
评估与运维
-
端到端执行
我们的“大数据”与噪声文档
企业级代码库通常包含多种类型的文档:演示稿、技术文档、报告、网页等,其中总会掺杂大量噪声数据。对 RAG pipeline 来说,噪声数据是让系统在真实环境中更可靠、更精确所必须面对的。
我们将使用 Kubernetes 官方文档作为“真实数据”,同时从 tpn/pdfs 仓库加入 95% 的“噪声数据”,其中包含海量与主题无关的随机 PDF,以模拟真实企业代码库。
这样我们能评估在超高噪声环境下,企业级 RAG pipeline 的真实表现。
克隆 tpn/pdfs 仓库来获取噪声数据(包含 1800+ 文档,耗时较长):
# 克隆噪声数据仓库git clone https://github.com/tpn/pdfs.git
该仓库包含 pdf、docx、txt、html 等多种文档类型。我们将从中随机抽样 950 个文档:
# 创建 noisy_data 目录mkdir noisy_data# 从 tpn/pdfs 仓库中随机采样 950 个文档find ./pdfs -type f \( -name "*.pdf" -o -name "*.docx" -o -name "*.txt" -o -name "*.html" \) | shuf -n 950 | xargs -I {} cp {} ./noisy_data/
这会在 noisy_data 目录下生成 950 份随机采样的文档。
真实知识来源方面,我抓取了 Kubernetes 官方开源文档,并将其保存为 pdf、docx、txt、html 等多种格式,放在 true_data 目录。你可以在我的 GitHub 仓库找到 true_data。
将 noisy 与 true 两类数据合并到一个 data 目录中:
# 创建 data 目录mkdir data# 拷贝真实数据cp -r ./true_data/* ./data/# 拷贝噪声数据cp -r ./noisy_data/* ./data/
验证 data 目录中文档总数:
# 统计 data 目录总文档数find ./data -type f \( -name "*.pdf" -o -name "*.docx" -o -name "*.txt" -o -name "*.html" \) | wc -l### OUTPUT1000
现在我们在 data 目录中共有 1000 份文档,其中 950 份是噪声文档,50 份是真实文档。
进入下一步:构建企业级 RAG pipeline。
构建企业级代码库
一般的 agentic RAG pipeline 代码库可能只包含一个向量数据库、少量 AI 模型和简单的 ingestion 脚本。但随着复杂度上升,我们需要将整体架构拆分为更小、更易管理的组件。
建立如下有组织的目录结构:
scalable-rag-core/ # 最小可用的生产级 RAG 系统├── infra/ # 核心云基础设施│ ├── terraform/ # 集群、网络、存储│ └── karpenter/ # 节点自动扩缩(CPU/GPU)│├── deploy/ # Kubernetes 部署层│ ├── helm/ # 数据库与有状态服务│ │ ├── qdrant/ # 向量数据库│ │ └── neo4j/ # 知识图谱│ ├── ray/ # Ray + Ray Serve(LLM & embeddings)│ └── ingress/ # API ingress│├── models/ # 模型配置(与基础设施解耦)│ ├── embeddings/ # Embedding 模型│ ├── llm/ # LLM 推理配置│ └── rerankers/ # Cross-encoder rerankers│├── pipelines/ # 离线与异步 RAG 流水线│ └── ingestion/ # 文档 ingestion 流程│ ├── loaders/ # PDF / HTML / DOC 加载器│ ├── chunking/ # Chunking 与元数据│ ├── embedding/ # Embedding 计算│ ├── indexing/ # 向量 + 图谱索引│ └── graph/ # 知识图谱抽取│├── libs/ # 共享核心库│ ├── schemas/ # 请求/响应 schema│ ├── retry/ # 弹性与重试│ └── observability/ # Metrics & tracing│├── services/ # 在线服务层│ ├── api/ # RAG API│ │ └── app/│ │ ├── agents/ # Agentic 编排│ │ │ └── nodes/ # Planner / Retriever / Responder│ │ ├── clients/ # Vector DB、Graph DB、Ray 客户端│ │ ├── cache/ # 语义与响应缓存│ │ ├── memory/ # 会话记忆│ │ ├── enhancers/ # Query rewriting, HyDE│ │ ├── routes/ # Chat & retrieval APIs│ │ └── tools/ # Vector search, graph search│ ││ └── gateway/ # 限流 / API 保护
看起来复杂,但我们先聚焦最重要的目录:
- deploy/:包含 Ray、ingress controller、密钥管理等组件的部署配置。
- infra/:使用 Terraform 与 Karpenter 的 IaC 脚本,搭建云资源。
- pipelines/:ingestion 与任务管理流水线,包括文档加载、chunking、embedding 计算、图谱抽取与索引。
- services/:主应用服务,包括 API server、gateway 配置和执行不可信代码的 sandbox 环境。
很多组件(如 loaders、chunking)各自拥有子目录,进一步明确边界、提升可维护性。
开发流程管理
在编写 agent 架构之前,第一步是搭建本地开发环境。
可扩展项目通常会自动化这一步,从而新成员加入无需重复手动配置。
开发环境通常包含三类内容:
- .env.example:分享本地开发所需的环境变量。开发者复制为 .env,并按 dev/staging/prod 阶段填写值。
- Makefile:封装构建、测试、部署等常用命令。
- docker-compose.yml:定义本地运行整个 RAG pipeline 所需的所有服务(以容器形式)。
创建 .env.example 以共享本地开发的环境变量:
# .env.example# 复制为 .env,并填写值# --- APP SETTINGS ---ENV=devLOG_LEVEL=INFOSECRET_KEY=change_this_to_a_secure_random_string_for_jwt
先定义基础应用配置,如环境、日志级别、JWT 密钥。(这会告诉我们当前 app 所处阶段:dev/staging/prod)。
# --- DATABASE (Aurora Postgres) ---DATABASE_URL=postgresql+asyncpg://ragadmin:changeme@localhost:5432/rag_db# --- CACHE (Redis) ---REDIS_URL=redis://localhost:6379/0# --- VECTOR DB (Qdrant) ---QDRANT_HOST=localhostQDRANT_PORT=6333QDRANT_COLLECTION=rag_collection# --- GRAPH DB (Neo4j) ---NEO4J_URI=bolt://localhost:7687NEO4J_USER=neo4jNEO4J_PASSWORD=password
RAG pipeline 依赖多个数据存储。为追踪与管理,我们需要多种存储方案:
- Aurora Postgres:聊天历史与元数据存储。
- Redis:缓存高频数据。
- Qdrant:向量数据库,存储 embeddings。
- Neo4j:图数据库,存储实体关系。
# --- AWS (Infrastructure) ---AWS_REGION=us-east-1AWS_ACCESS_KEY_ID=AWS_SECRET_ACCESS_KEY=S3_BUCKET_NAME=rag-platform-docs-dev# --- RAY CLUSTER (AI Engines) ---# 在 K8s 中,这些指向内部 Service DNS# 本地可能需要端口转发RAY_LLM_ENDPOINT=http://localhost:8000/llmRAY_EMBED_ENDPOINT=http://localhost:8000/embed# --- OBSERVABILITY ---OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4317
面对海量数据,我们需要高效的存储与检索,因此使用 AWS S3 作为主文档存储,并以集群化 Ray Serving 托管 AI 模型(LLM、Embeddings、Rerankers)。
接着创建 Makefile 自动化构建/测试/部署等常用任务:
# Makefile.PHONY: help install dev up down deploy testhelp: @echo"RAG Platform Commands:" @echo" make install - Install Python dependencies" @echo" make dev - Run FastAPI server locally" @echo" make up - Start local DBs (Docker)" @echo" make down - Stop local DBs" @echo" make deploy - Deploy to AWS EKS via Helm" @echo" make infra - Apply Terraform"install: pip install -r services/api/requirements.txt# 本地开发环境up: docker-compose up -ddown: docker-compose down# 本地运行 API(热重载)dev: uvicorn services.api.main:app --reload --host 0.0.0.0 --port 8000 --env-file .env# 基础设施infra:cd infra/terraform && terraform init && terraform apply# Kubernetes 部署deploy:# 更新依赖 helm dependency update deploy/helm/api# 安装/升级 helm upgrade --install api deploy/helm/api --namespace default helm upgrade --install ray-cluster kuberay/ray-cluster -f deploy/ray/ray-cluster.yamltest: pytest tests/
Makefile 是许多可扩展项目的标准自动化工具。这里定义了 install、dev、up、down、deploy、infra、test 等命令以管理开发工作流。
最后创建 docker-compose.yml 在本地以容器方式运行整个 RAG pipeline。容器用于隔离不同组件并简化依赖管理。
# docker-compose.ymlversion:'3.8'services:# 1. Postgres(聊天历史)postgres: image:postgres:15-alpine environment: POSTGRES_USER:ragadmin POSTGRES_PASSWORD:changeme POSTGRES_DB:rag_db ports: -"5432:5432" volumes: -pg_data:/var/lib/postgresql/data# 2. Redis(缓存)redis: image:redis:7-alpine ports: -"6379:6379"# 3. Qdrant(向量数据库)qdrant: image:qdrant/qdrant:v1.7.3 ports: -"6333:6333" volumes: -qdrant_data:/qdrant/storage# 4. Neo4j(图数据库)neo4j: image:neo4j:5.16.0-community environment: NEO4J_AUTH:neo4j/password NEO4J_dbms_memory_pagecache_size:1G ports: -"7474:7474"# HTTP -"7687:7687"# Bolt volumes: -neo4j_data:/data# 5. MinIO(S3 Mock)- 全离线开发可选minio: image:minio/minio command:server/data ports: -"9000:9000" -"9001:9001" environment: MINIO_ROOT_USER:minioadmin MINIO_ROOT_PASSWORD:minioadminvolumes:pg_data:qdrant_data:neo4j_data:
小规模项目常用 pip 或 virtualenv 管理依赖;而可扩展项目更推荐使用 Docker 容器隔离每个组件。在该 YAML 中,我们为每个服务指定不同端口,避免冲突、便于监控,这也是大型项目的最佳实践。
核心通用工具
在项目结构与开发流程就绪后,首先需要统一的 ID 生成策略。用户发送一条聊天消息时,会触发很多并行流程;将其关联起来,有助于跨组件追踪该会话相关的问题。
这在生产系统中非常常见:按用户动作(如点击、请求)进行全链路关联,方便后续监控、调试与追踪。
创建 libs/utils/ids.py:为会话、文件上传与 OpenTelemetry 追踪生成唯一 ID。
# libs/utils/ids.pyimport uuidimport hashlibdefgenerate_session_id() -> str: """为聊天会话生成标准 UUID""" returnstr(uuid.uuid4())defgenerate_file_id(content: bytes) -> str: """ 基于文件内容生成确定性 ID。 防止重复上传同一文件。 """ return hashlib.md5(content).hexdigest()defgenerate_trace_id() -> str: """为 OpenTelemetry 追踪生成 ID""" return uuid.uuid4().hex
同时,我们需要对各函数执行时间进行度量,以便性能监控与优化。创建 libs/utils/timing.py,分别处理同步与异步函数计时:
# libs/utils/timing.pydefmeasure_time(func): """ 记录同步函数的执行时间。 """ @functools.wraps(func) defwrapper(*args, **kwargs): start_time = time.perf_counter() result = func(*args, **kwargs) end_time = time.perf_counter() execution_time = (end_time - start_time) * 1000# ms logger.info(f"Function '{func.__name__}' took {execution_time:.2f} ms") return result return wrapperdefmeasure_time_async(func): """ 记录异步函数的执行时间。 """ @functools.wraps(func) asyncdefwrapper(*args, **kwargs): start_time = time.perf_counter() result = await func(*args, **kwargs) end_time = time.perf_counter() execution_time = (end_time - start_time) * 1000# ms logger.info(f"Async Function '{func.__name__}' took {execution_time:.2f} ms") return result return wrapper
最后,生产级 RAG 系统需要重试机制。我们对错误处理通常采用 exponential backoff。创建 libs/retry/backoff.py:
def exponential_backoff(max_retries: int = 3, base_delay: float = 1.0, max_delay: float = 10.0): """ 指数退避 + 抖动 的装饰器。 捕获异常并重试(异步函数)。 """ defdecorator(func): @wraps(func) asyncdefwrapper(*args, **kwargs): retries = 0 whileTrue: try: returnawait func(*args, **kwargs) except Exception as e: if retries >= max_retries: logger.error(f"Max retries reached for {func.__name__}: {e}") raise e # 算法: base * (2 ^ retries) + random_jitter # 抖动避免服务器端的 “Thundering Herd” 问题 delay = min(base_delay * (2 ** retries), max_delay) jitter = random.uniform(0, 0.5) sleep_time = delay + jitter logger.warning(f"Error in {func.__name__}: {e}. Retrying in {sleep_time:.2f}s...") await asyncio.sleep(sleep_time) retries += 1 return wrapper return decorator
计算延迟公式 base * (2 ^ retries) + random_jitter 有助于避免“Thundering Herd(惊群效应)”。
Data Ingestion Layer
RAG pipeline 的第一环是将文档引入系统。小规模可以用脚本顺序读取文件;而在 Enterprise RAG Pipeline 中,ingestion 需要高吞吐、异步处理、可同时处理上千文件且不能拖垮 API 服务。
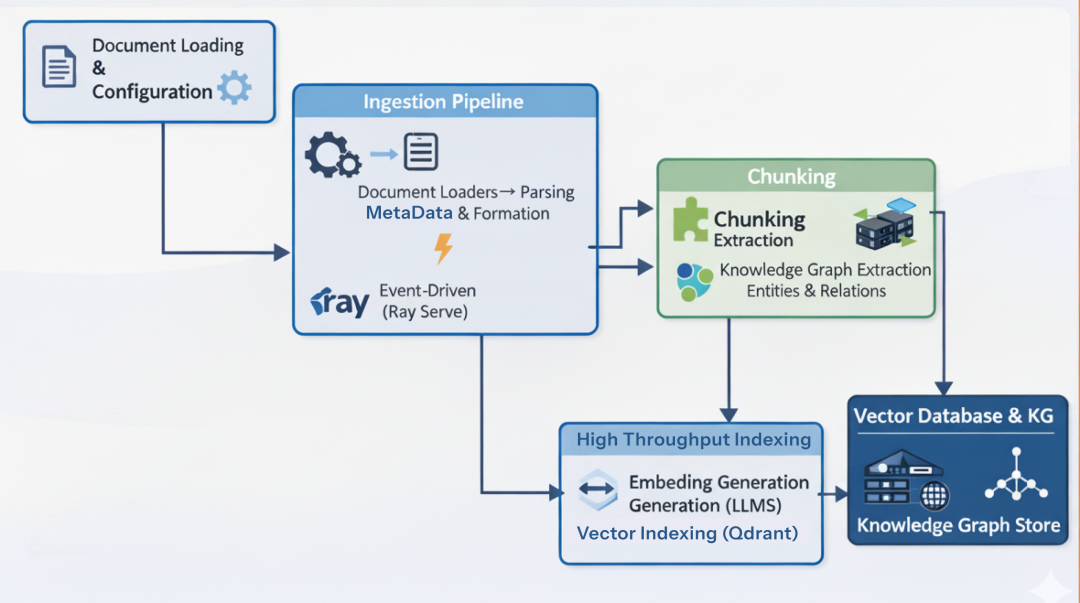
Data Ingestion Layer (Created by Fareed Khan)
我们使用 Ray Data 将 ingestion 逻辑拆分为分布式 pipeline。
Ray Data 允许创建 DAG(有向无环图),并在集群多节点并行执行。
这样可以独立扩展解析(CPU 密集)与 embedding(GPU 密集)任务。
文档加载与配置
首先需要集中式配置管理 ingestion 参数。将 chunk 大小或数据库 collection 等硬编码在生产环境中极不可靠。
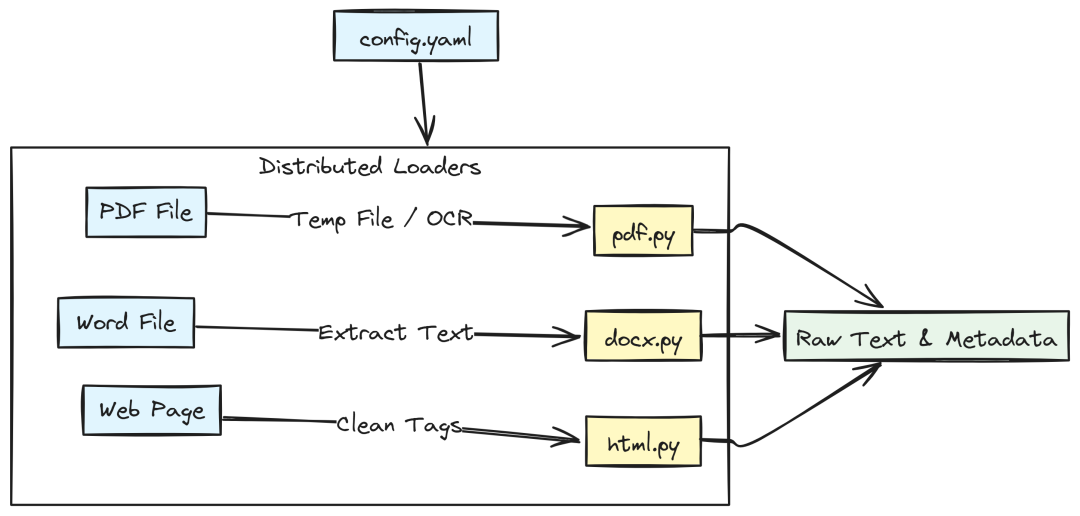
Document Processing (Created by Fareed Khan)
创建 pipelines/ingestion/config.yaml 存放 ingestion pipeline 的所有配置:
# pipelines/ingestion/config.yamlchunking:# 512 tokens 通常是 RAG 的“甜蜜点”(上下文够、噪声不多)chunk_size:512# Overlap 确保分割点处的上下文不丢失chunk_overlap:50# 递归切分的分隔符(段落 -> 句子 -> 词)separators: ["\n\n", "\n", " ", ""]embedding:# Ray Serve 的 endpointendpoint:"http://ray-serve-embed:8000/embed"batch_size:100graph:# 控制 LLM 抽取的速度与成本concurrency:10# true 时严格遵循 schema.py 本体enforce_schema:truevector_db:collection_name:"rag_collection"distance_metric:"Cosine"
对于 loader:企业系统中的 PDF 往往很大。将 100MB PDF 直接读入内存可能导致 K8s 工作节点 OOM。我们需要使用临时文件与 unstructured,用磁盘换内存,见 pipelines/ingestion/loaders/pdf.py:
# pipelines/ingestion/loaders/pdf.pyimport tempfilefrom unstructured.partition.pdf import partition_pdfdefparse_pdf_bytes(file_bytes: bytes, filename: str): """ 使用临时文件解析 PDF,降低内存压力。 """ text_content = "" # 使用磁盘而非 RAM,防止大文件导致 worker 崩溃 with tempfile.NamedTemporaryFile(suffix=".pdf", delete=True) as tmp_file: tmp_file.write(file_bytes) tmp_file.flush() # 'hi_res' 策略:OCR + 布局分析 elements = partition_pdf(filename=tmp_file.name, strategy="hi_res") for el in elements: text_content += str(el) + "\n" return text_content, {"filename": filename, "type": "pdf"}
其他格式使用轻量解析器。Word 文档见 pipelines/ingestion/loaders/docx.py:
# pipelines/ingestion/loaders/docx.pyimport docximport iodefparse_docx_bytes(file_bytes: bytes, filename: str): """解析 .docx,提取文本与简单表格""" doc = docx.Document(io.BytesIO(file_bytes)) full_text = [] for para in doc.paragraphs: if para.text.strip(): full_text.append(para.text) return"\n\n".join(full_text), {"filename": filename, "type": "docx"}
HTML 见 pipelines/ingestion/loaders/html.py:去除 script/style,避免 CSS/JS 噪声污染向量。
# pipelines/ingestion/loaders/html.pyfrom bs4 import BeautifulSoupdef parse_html_bytes(file_bytes: bytes, filename: str): """清理脚本/样式,提取纯文本""" soup = BeautifulSoup(file_bytes, "html.parser") # 去除干扰元素 for script in soup(["script", "style", "meta"]): script.decompose() return soup.get_text(separator="\n"), {"filename": filename, "type": "html"}
Chunking 与知识图谱
提取出原始文本后,需要进行转换。我们在 pipelines/ingestion/chunking/splitter.py 定义 splitter,将文本切为 512-token 的 chunk,这是许多 embedding 模型的标准限制。
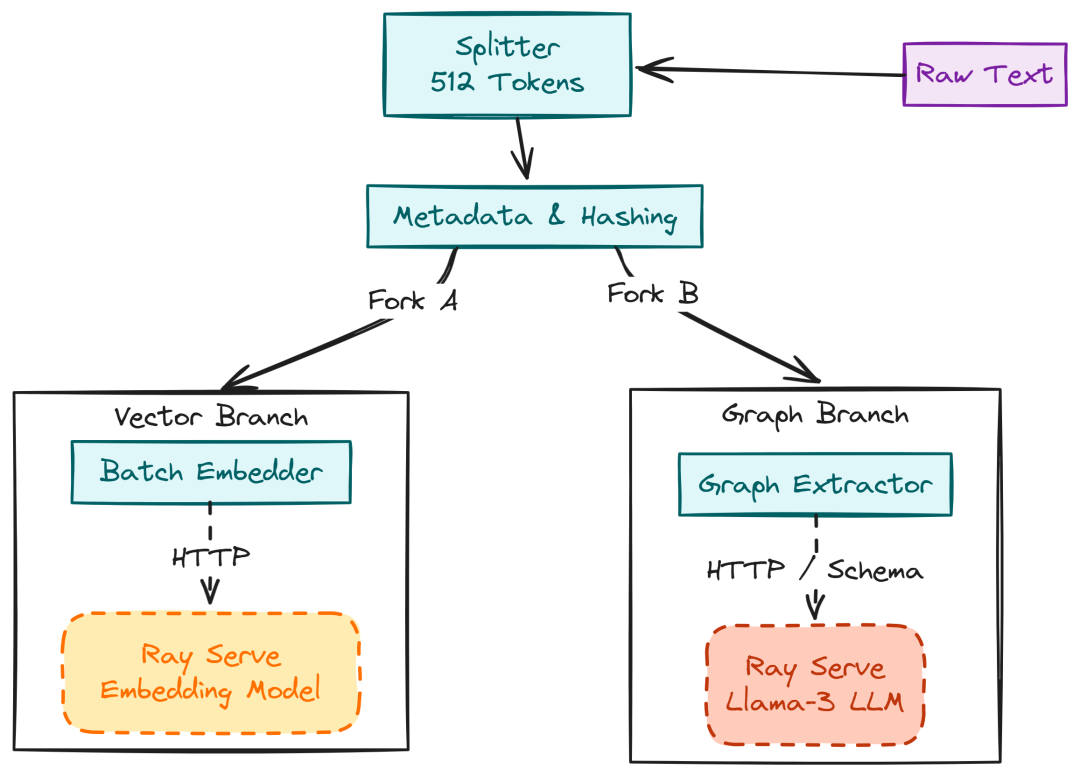
Chunking and KG (Created by Fareed Khan)
# pipelines/ingestion/chunking/splitter.pyfrom langchain.text_splitter import RecursiveCharacterTextSplitterdefsplit_text(text: str, chunk_size: int = 512, overlap: int = 50): """将文本切成重叠 chunk,保留边界处上下文""" splitter = RecursiveCharacterTextSplitter( chunk_size=chunk_size, chunk_overlap=overlap, separators=["\n\n", "\n", ".", " ", ""] ) chunks = splitter.create_documents([text]) # 为 Ray pipeline 映射为字典格式 return [{"text": c.page_content, "metadata": {"chunk_index": i}} for i, c inenumerate(chunks)]
在 pipelines/ingestion/chunking/metadata.py 增强元数据。分布式系统中需要去重,因此我们生成内容 hash:
# pipelines/ingestion/chunking/metadata.pyimport hashlibimport datetimedef enrich_metadata(base_metadata: dict, content: str) -> dict: """增加哈希与时间戳,用于去重与新鲜度追踪""" return { **base_metadata, "chunk_hash": hashlib.md5(content.encode('utf-8')).hexdigest(), "ingested_at": datetime.datetime.utcnow().isoformat() }
接下来进行 GPU 工作——生成 embeddings。不要在 ingestion 脚本内加载模型(冷启动慢),而是调用 Ray Serve endpoint。这样 ingestion 作业只需发 HTTP 请求给常驻的模型服务。创建 pipelines/ingestion/embedding/compute.py:
# pipelines/ingestion/embedding/compute.pyimport httpxclassBatchEmbedder: """Ray Actor:对文本批量调用 Embedding Service""" def__init__(self): # 指向 K8s 内部服务 DNS self.endpoint = "http://ray-serve-embed:8000/embed" self.client = httpx.Client(timeout=30.0) def__call__(self, batch): """将一批文本发往 GPU 服务""" response = self.client.post( self.endpoint, json={"text": batch["text"], "task_type": "document"} ) batch["vector"] = response.json()["embeddings"] return batch
同时抽取知识图谱。为保持图谱干净,在 pipelines/ingestion/graph/schema.py 定义严格 schema,否则 LLM 容易产出随机关系类型(hallucination)。
# pipelines/ingestion/graph/schema.pyfrom typing import Literal# 限制 LLM 仅使用这些实体/关系VALID_NODE_LABELS = Literal["Person", "Organization", "Location", "Concept", "Product"]VALID_RELATION_TYPES = Literal["WORKS_FOR", "LOCATED_IN", "RELATES_TO", "PART_OF"]class GraphSchema: @staticmethod def get_system_prompt() -> str: return f"Extract nodes/edges. Allowed Labels: {VALID_NODE_LABELS.__args__}..."
在 pipelines/ingestion/graph/extractor.py 应用该 schema,使用 LLM 理解文本结构(而不仅是语义相似度):
# pipelines/ingestion/graph/extractor.pyimport httpxfrom pipelines.ingestion.graph.schema import GraphSchemaclassGraphExtractor: """ 用于图谱抽取的 Ray Actor。 调用内部 LLM Service 抽取实体。 """ def__init__(self): # 指向内部 Ray Serve LLM endpoint(K8s DNS) self.llm_endpoint = "http://ray-serve-llm:8000/llm/chat" self.client = httpx.Client(timeout=60.0) # 需要较长推理超时 def__call__(self, batch: Dict[str, Any]) -> Dict[str, Any]: """ 处理一批文本 chunk。 """ nodes_list = [] edges_list = [] for text in batch["text"]: try: # 1. 构造 Prompt prompt = f""" {GraphSchema.get_system_prompt()} Input Text: {text} """ # 2. 调用 LLM(例如 Llama-3-70B) response = self.client.post( self.llm_endpoint, json={ "messages": [{"role": "user", "content": prompt}], "temperature": 0.0, # 确保确定性输出 "max_tokens": 1024 } ) response.raise_for_status() # 3. 解析 JSON 输出 content = response.json()["choices"][0]["message"]["content"] graph_data = json.loads(content) # 4. 聚合结果 nodes_list.append(graph_data.get("nodes", [])) edges_list.append(graph_data.get("edges", [])) except Exception as e: # 记录错误但不中断流水线;为该 chunk 返回空图 print(f"Graph extraction failed for chunk: {e}") nodes_list.append([]) edges_list.append([]) batch["graph_nodes"] = nodes_list batch["graph_edges"] = edges_list return batch
高吞吐 Indexing
大规模 RAG 不会逐条写入记录,而是批量写(batch writes),可显著降低 GPU/CPU 开销与内存占用。
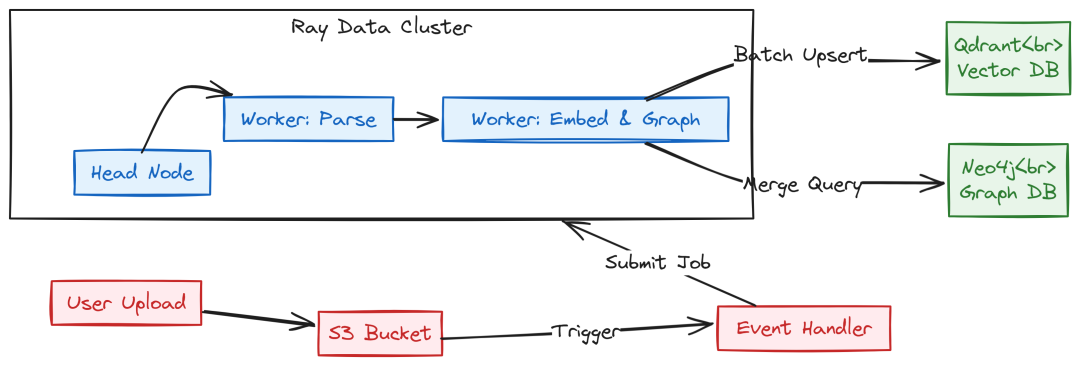
High Throughput Indexing (Created by Fareed Khan)
向量索引使用 pipelines/ingestion/indexing/qdrant.py,连接 Qdrant 集群并执行原子 upsert:
# pipelines/ingestion/indexing/qdrant.pyfrom qdrant_client import QdrantClientfrom qdrant_client.http import modelsimport uuidclassQdrantIndexer: """以批量 upsert 写入 Qdrant""" def__init__(self): self.client = QdrantClient(host="qdrant-service", port=6333) defwrite(self, batch): points = [ models.PointStruct(id=str(uuid.uuid4()), vector=row["vector"], payload=row["metadata"]) for row in batch if"vector"in row ] self.client.upsert(collection_name="rag_collection", points=points)
图谱索引使用 pipelines/ingestion/indexing/neo4j.py,采用 Cypher MERGE 确保幂等(重复 ingestion 不会产生重复节点):
# pipelines/ingestion/indexing/neo4j.pyfrom neo4j import GraphDatabaseclass Neo4jIndexer: """使用幂等 MERGE 写入图数据""" def __init__(self): self.driver = GraphDatabase.driver("bolt://neo4j-cluster:7687", auth=("neo4j", "pass")) def write(self, batch): with self.driver.session() as session: # 扁平化 batch,并以单事务执行,提升性能 session.execute_write(self._merge_graph_data, batch)
基于 Ray 的事件驱动工作流
最后将这些组件组合起来。我们希望读取、chunking、embedding 在不同 CPU/GPU 节点并行进行。创建 pipelines/ingestion/main.py 作为“指挥官”,使用 Ray Data 构建惰性执行 DAG:
# pipelines/ingestion/main.pyimport rayfrom pipelines.ingestion.embedding.compute import BatchEmbedderfrom pipelines.ingestion.indexing.qdrant import QdrantIndexerdefmain(bucket_name: str, prefix: str): """ 主编排流程 """ # 1. 使用 Ray Data 从 S3 读取(二进制) ds = ray.data.read_binary_files( paths=f"s3://{bucket_name}/{prefix}", include_paths=True ) # 2. 解析 & Chunk(Map) chunked_ds = ds.map_batches( process_batch, batch_size=10, # 每个 worker 一次处理 10 个文件 num_cpus=1 ) # 3. 分叉 A:向量 Embedding(GPU 密集) vector_ds = chunked_ds.map_batches( BatchEmbedder, concurrency=5, # 5 个并发 embedder num_gpus=0.2, # 每个 embedder 分配少量 GPU,重负载由 Ray Serve 处理 batch_size=100 # 100 个 chunk 一批向量化 ) # 4. 分叉 B:图谱抽取(LLM 密集) graph_ds = chunked_ds.map_batches( GraphExtractor, concurrency=10, num_gpus=0.5, # 需要较强 LLM 推理性能 batch_size=5 ) # 5. 写入(索引) vector_ds.write_datasource(QdrantIndexer()) graph_ds.write_datasource(Neo4jIndexer()) print("Ingestion Job Completed Successfully.")
在 K8s 上运行该作业时,需在 pipelines/jobs/ray_job.yaml 指定运行时环境(依赖):
# pipelines/jobs/ray_job.yamlentrypoint: "python pipelines/ingestion/main.py"runtime_env: working_dir: "./" pip: ["boto3", "qdrant-client", "neo4j", "langchain", "unstructured"]
企业架构中,我们不会手工触发,而是“事件驱动”:当文件进入 S3 时,由 Lambda 触发 Ray 作业,见 pipelines/jobs/s3_event_handler.py:
# pipelines/jobs/s3_event_handler.pyfrom ray.job_submission import JobSubmissionClientdef handle_s3_event(event, context): """由 S3 上传触发 -> 提交 Ray Job""" client = JobSubmissionClient("http://rag-ray-cluster-head-svc:8265") client.submit_job( entrypoint=f"python pipelines/ingestion/main.py {bucket} {key}", runtime_env={"working_dir": "./"} )
为测试整个流程,用 scripts/bulk_upload_s3.py 以多线程将准备好的噪声数据批量上传至 S3:
# scripts/bulk_upload_s3.pyfrom concurrent.futures import ThreadPoolExecutordef upload_directory(dir_path, bucket_name): """高性能多线程 S3 上传器""" with ThreadPoolExecutor(max_workers=10) as executor: # 将本地文件映射为 S3 上传任务 executor.map(upload_file, files_to_upload)
至此,我们完成了 Data Ingestion Layer。通过为 K8s 集群增加节点,该系统可扩展到数百万文档。
下一部分,我们将构建 Model Server Layer,以分布式模式托管模型服务。
AI Compute Layer
有了 ingestion pipeline,我们还需要能处理数据的“计算层”。在单体应用中,可能直接在 API server 内加载 LLM;但在 Enterprise RAG Platform 中,这会是致命错误……
将 70B 参数量模型加载到 web server 内会极大拖累吞吐,使扩展几乎不可能。
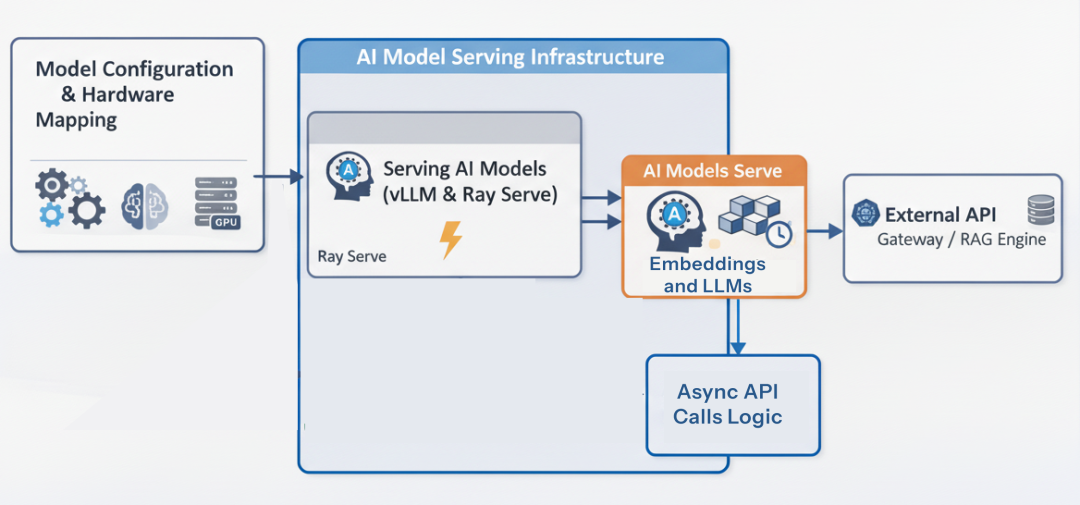
Compute Layer (Created by Fareed Khan)
我们需要将 FastAPI 与 AI 模型解耦,采用 Ray Serve 将模型托管为独立微服务,依据 GPU 资源与流量自动伸缩。
模型配置与硬件映射
生产环境绝不硬编码模型参数。我们需要灵活的配置,可无痛切换模型、调整量化、微调 batch 大小等。
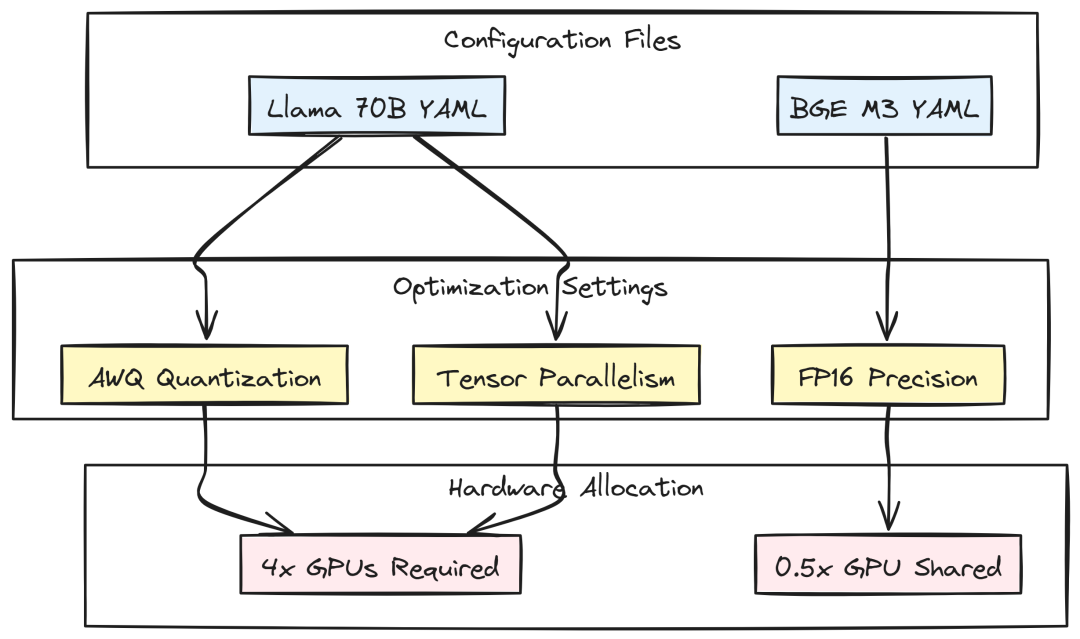
Model Config (Created by Fareed Khan)
在 models/llm/llama-70b.yaml 定义主力模型:使用 Llama-3-70B-Instruct。70B FP16 约需 140GB VRAM,因此采用 AWQ Quantization 以适配更经济的 GPU。
许多公司把精力放在数据与 agent 上,而非执着于“最终用哪一个大模型”。
# models/llm/llama-70b.yamlmodel_config:model_id:"meta-llama/Meta-Llama-3-70B-Instruct"quantization:"awq"max_model_len:8192max_num_seqs:128gpu_memory_utilization:0.90tensor_parallel_size:4stop_token_ids: [128001, 128009]
注意 tensor_parallel_size: 4 是企业级配置,表示需将权重切分到 4 块 GPU。
同时保留一个较小模型配置 models/llm/llama-7b.yaml,用于 query rewriting 或 summarization 节省成本:
# models/llm/llama-7b.yamlmodel_config:model_id:"meta-llama/Meta-Llama-3-8B-Instruct"quantization:"awq"max_model_len:8192max_num_seqs:256gpu_memory_utilization:0.85tensor_parallel_size:1stop_token_ids: [128001, 128009]
检索侧 embedding 模型配置 models/embeddings/bge-m3.yaml。BGE-M3 具备 dense/sparse/multi-lingual 检索能力,适合全球化平台:
# models/embeddings/bge-m3.yamlmodel_config:model_id:"BAAI/bge-m3"batch_size:32normalize_embeddings:truedtype:"float16"max_seq_length:8192
为提升准确率,使用 reranker:models/rerankers/bge-reranker.yaml,在 LLM 前对 top 文档重排,显著降低幻觉:
# models/rerankers/bge-reranker.yamlmodel_config: model_id: "BAAI/bge-reranker-v2-m3" dtype: "float16" max_length: 512 batch_size: 16
使用 vLLM 与 Ray 进行模型服务
标准 HuggingFace pipeline 在高并发生产环境下过慢。我们使用 vLLM(PagedAttention)提升吞吐。
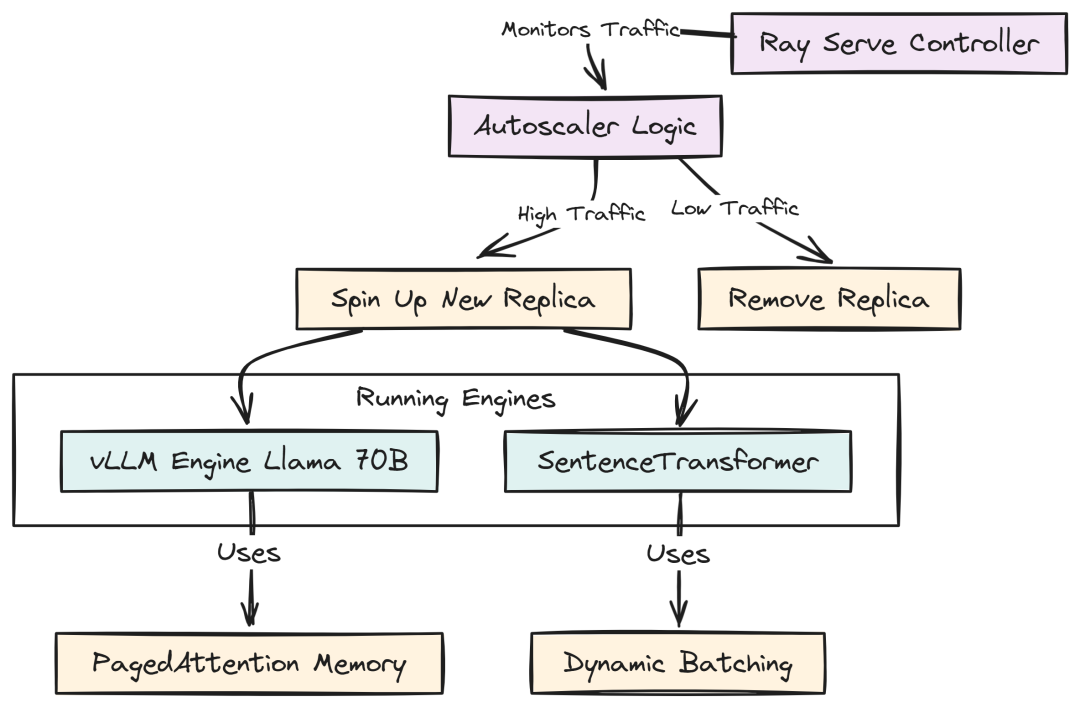
Serving Logic (Created by Fareed Khan)
将 vLLM 封装到 Ray Serve 部署 services/api/app/models/vllm_engine.py:
# services/api/app/models/vllm_engine.pyfrom ray import servefrom vllm import AsyncLLMEngine, EngineArgs, SamplingParamsfrom transformers import AutoTokenizerimport os@serve.deployment(autoscaling_config={"min_replicas": 1, "max_replicas": 10}, ray_actor_options={"num_gpus": 1})classVLLMDeployment: def__init__(self): model_id = os.getenv("MODEL_ID", "meta-llama/Meta-Llama-3-70B-Instruct") self.tokenizer = AutoTokenizer.from_pretrained(model_id) args = EngineArgs( model=model_id, quantization="awq", gpu_memory_utilization=0.90, max_model_len=8192 ) self.engine = AsyncLLMEngine.from_engine_args(args) asyncdef__call__(self, request): body = await request.json() messages = body.get("messages", []) prompt = self.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) sampling_params = SamplingParams( temperature=body.get("temperature", 0.7), max_tokens=body.get("max_tokens", 1024), stop_token_ids=[self.tokenizer.eos_token_id, self.tokenizer.convert_tokens_to_ids("<|eot_id|>")] ) request_id = str(os.urandom(8).hex()) results_generator = self.engine.generate(prompt, sampling_params, request_id) final_output = None asyncfor request_output in results_generator: final_output = request_output text_output = final_output.outputs[0].text return {"choices": [{"message": {"content": text_output, "role": "assistant"}}]}app = VLLMDeployment.bind()
@serve.deployment 让 Ray 接管生命周期。autoscaling_config 是企业关键:流量飙升时自动扩容,空闲时缩容以节省成本。
Serving Embeddings 与 Re-Rankers
Embedding 模型不需要 vLLM,但需要高效批处理。
当 50 个用户同时检索时,我们希望一次 GPU 前向编码 50 个查询,而不是串行 50 次。
在 services/api/app/models/embedding_engine.py 实现。注意 num_gpus: 0.5——两份 embedding 模型共享一块 GPU,极大节省成本。
# services/api/app/models/embedding_engine.pyfrom ray import servefrom sentence_transformers import SentenceTransformerimport osimport torch@serve.deployment( num_replicas=1, ray_actor_options={"num_gpus": 0.5} # 共享 GPU)classEmbedDeployment: def__init__(self): model_name = "BAAI/bge-m3" self.model = SentenceTransformer(model_name, device="cuda") self.model = torch.compile(self.model) asyncdef__call__(self, request): body = await request.json() texts = body.get("text") task_type = body.get("task_type", "document") ifisinstance(texts, str): texts = [texts] embeddings = self.model.encode(texts, batch_size=32, normalize_embeddings=True) return {"embeddings": embeddings.tolist()}app = EmbedDeployment.bind()
该部署同时服务文档 embedding(ingestion)与查询 embedding(检索),用 torch.compile 进一步挖掘性能。
异步内部客户端
API 层需要与上述 Ray 服务通信。由于模型作为微服务运行,我们通过 HTTP 调用,并采用异步客户端以保持 FastAPI 响应能力。
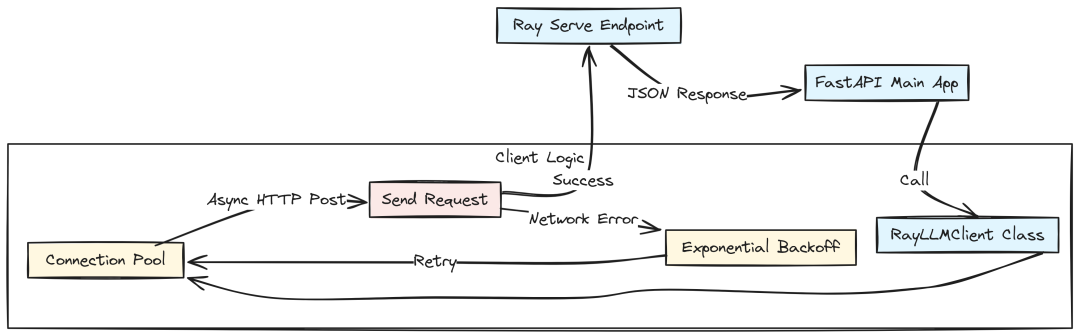
Async Calls (Created by Fareed Khan)
创建 services/api/app/clients/ray_llm.py,包含连接池与重试逻辑:
# services/api/app/clients/ray_llm.pyimport httpximport loggingimport backofffrom typing importList, Dict, Optionalfrom services.api.app.config import settingslogger = logging.getLogger(__name__)classRayLLMClient: """ 带连接池的异步客户端 """ def__init__(self): self.endpoint = settings.RAY_LLM_ENDPOINT self.client: Optional[httpx.AsyncClient] = None asyncdefstart(self): """应用启动时初始化""" limits = httpx.Limits(max_keepalive_connections=20, max_connections=50) self.client = httpx.AsyncClient(timeout=120.0, limits=limits) logger.info("Ray LLM Client initialized.") asyncdefclose(self): ifself.client: awaitself.client.aclose() @backoff.on_exception(backoff.expo, httpx.HTTPError, max_tries=3) asyncdefchat_completion(self, messages: List[Dict], temperature: float = 0.7, json_mode: bool = False) -> str: ifnotself.client: raise RuntimeError("Client not initialized. Call start() first.") payload = {"messages": messages, "temperature": temperature, "max_tokens": 1024} response = awaitself.client.post(self.endpoint, json=payload) response.raise_for_status() return response.json()["choices"][0]["message"]["content"]llm_client = RayLLMClient()
backoff 确保在网络抖动或 Ray 繁忙时不直接失败,而是指数退避重试。
Embedding 客户端 services/api/app/clients/ray_embed.py:
# services/api/app/clients/ray_embed.pyimport httpxfrom services.api.app.config import settingsclassRayEmbedClient: """ Ray Serve Embedding Service 的客户端 """ asyncdefembed_query(self, text: str) -> list[float]: asyncwith httpx.AsyncClient() as client: response = await client.post( settings.RAY_EMBED_ENDPOINT, json={"text": text, "task_type": "query"} ) response.raise_for_status() return response.json()["embedding"] asyncdefembed_documents(self, texts: list[str]) -> list[list[float]]: asyncwith httpx.AsyncClient(timeout=60.0) as client: response = await client.post( settings.RAY_EMBED_ENDPOINT, json={"text": texts, "task_type": "document"} ) response.raise_for_status() return response.json()["embeddings"]embed_client = RayEmbedClient()
有了这些客户端,我们的 API 代码就能把 70B 模型当成简单的异步函数来调用,彻底屏蔽 GPU 管理与分布式推理的复杂性。
接下来构建 Agentic pipeline(将 RAG 升级为 Agentic RAG),用于决策何时调用哪些模型回答用户问题。
Agentic AI Pipeline
我们已拥有 ingestion 流水线与分布式模型服务。简单 RAG 应用可能就是“检索 -> 生成”的线性链条。
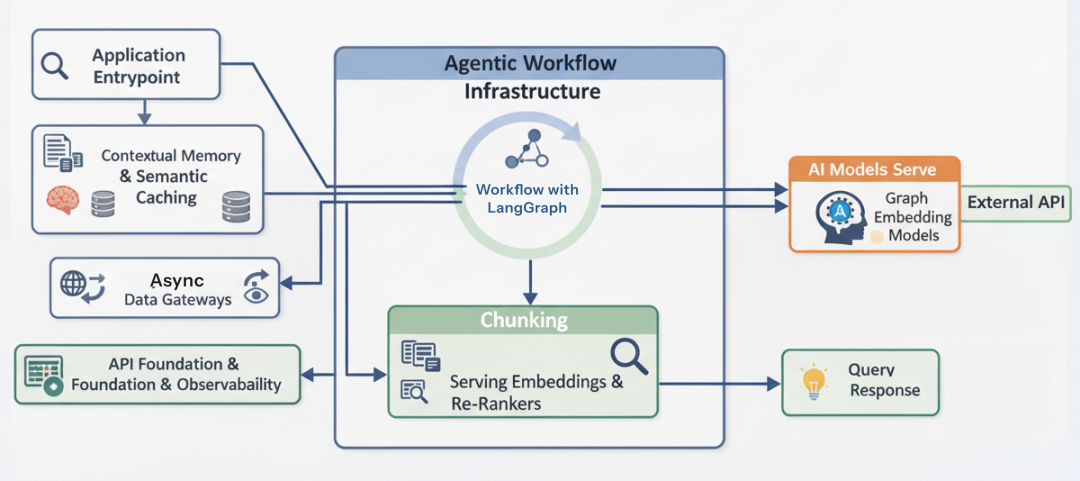
Agentic AI Pipeline (Created by Fareed Khan)
但对 Enterprise Agentic 平台而言,线性链条很脆弱:
用户变换话题、要求数学计算或表达含糊时,线性链条易出错。
我们使用 FastAPI 与 LangGraph 构建“事件驱动的 Agent”。系统能够“推理”用户意图:循环、纠错、动态选工具,并异步处理成千上万个 websocket 连接。
API 基础与可观测性
首先定义环境与安全基线。企业 API 不能是“黑盒”,我们需要结构化日志与 tracing 来定位为何某次请求用了 5s 而不是 500ms。
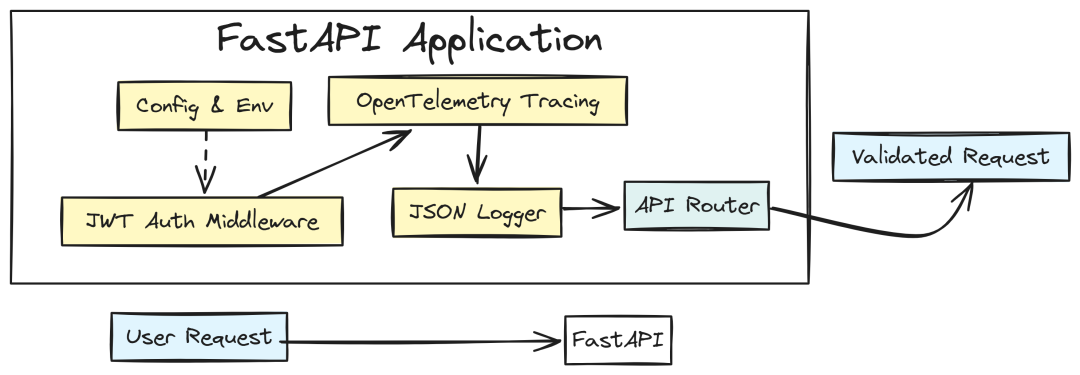
FastAPI Workflow (Created by Fareed Khan)
在 services/api/requirements.txt 中声明依赖,包括 fastapi、langgraph、opentelemetry 等:
# services/api/requirements.txt# Core Frameworkfastapi==0.109.0uvicorn[standard]==0.27.0pydantic==2.6.0pydantic-settings==2.1.0simpleeval==0.9.13 # Safe math evaluation# Async Database & Cachesqlalchemy==2.0.25asyncpg==0.29.0redis==5.0.1# AI & LLM Clientsopenai==1.10.0anthropic==0.8.0tiktoken==0.5.2sentence-transformers==2.3.1transformers==4.37.0# Graph & Vector DBsneo4j==5.16.0qdrant-client==1.7.3# Agent Frameworklangchain==0.1.5langgraph==0.0.21# Observability & Opsopentelemetry-api==1.22.0opentelemetry-sdk==1.22.0opentelemetry-exporter-otlp==1.22.0prometheus-client==0.19.0python-json-logger==2.0.7backoff==2.2.1# Securitypython-jose[cryptography]==3.3.0passlib[bcrypt]==1.7.4python-multipart==0.0.6# Utilitiesboto3==1.34.34httpx==0.26.0tenacity==8.2.3
接着用 Pydantic Settings 在 services/api/app/config.py 校验数据库 URL、API Key 等是否在启动时就绪(Fail Fast):
# services/api/app/config.pyfrom pydantic_settings import BaseSettingsfrom typing importOptionalclassSettings(BaseSettings): """ 应用配置:自动读取环境变量(大小写不敏感) """ ENV: str = "prod" LOG_LEVEL: str = "INFO" DATABASE_URL: str REDIS_URL: str QDRANT_HOST: str = "qdrant-service" QDRANT_PORT: int = 6333 QDRANT_COLLECTION: str = "rag_collection" NEO4J_URI: str = "bolt://neo4j-cluster:7687" NEO4J_USER: str = "neo4j" NEO4J_PASSWORD: str AWS_REGION: str = "us-east-1" S3_BUCKET_NAME: str RAY_LLM_ENDPOINT: str = "http://llm-service:8000/llm" RAY_EMBED_ENDPOINT: str = "http://embed-service:8000/embed" JWT_SECRET_KEY: str JWT_ALGORITHM: str = "HS256" classConfig: env_file = ".env"settings = Settings()
为日志接入结构化 JSON 格式 services/api/app/logging.py:
# services/api/app/logging.pyimport loggingimport jsonimport sysfrom datetime import datetimeclassJSONFormatter(logging.Formatter): """ 将日志格式化为 JSON:包含时间戳、级别、消息等 """ defformat(self, record): log_record = { "timestamp": datetime.utcnow().isoformat(), "level": record.levelname, "logger": record.name, "message": record.getMessage(), "module": record.module, "line": record.lineno } if record.exc_info: log_record["exception"] = self.formatException(record.exc_info) ifhasattr(record, "request_id"): log_record["request_id"] = record.request_id return json.dumps(log_record)defsetup_logging(): handler = logging.StreamHandler(sys.stdout) handler.setFormatter(JSONFormatter()) root_logger = logging.getLogger() root_logger.setLevel(logging.INFO) if root_logger.handlers: root_logger.handlers = [] root_logger.addHandler(handler) logging.getLogger("uvicorn.access").disabled = True logging.getLogger("httpx").setLevel(logging.WARNING)setup_logging()
启用分布式追踪 services/api/app/observability.py:
# services/api/app/observability.pyfrom fastapi import FastAPIfrom opentelemetry.instrumentation.fastapi import FastAPIInstrumentorfrom libs.observability.tracing import configure_tracingdef setup_observability(app: FastAPI): configure_tracing(service_name="rag-api-service") FastAPIInstrumentor.instrument_app(app)
实现 JWT 校验中间件 services/api/app/auth/jwt.py:
# services/api/app/auth/jwt.pyfrom fastapi import Depends, HTTPException, statusfrom fastapi.security import OAuth2PasswordBearerfrom jose import JWTError, jwtfrom services.api.app.config import settingsimport timeoauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")asyncdefget_current_user(token: str = Depends(oauth2_scheme)) -> dict: credentials_exception = HTTPException( status_code=status.HTTP_401_UNAUTHORIZED, detail="Could not validate credentials", headers={"WWW-Authenticate": "Bearer"}, ) try: payload = jwt.decode(token, settings.JWT_SECRET_KEY, algorithms=[settings.JWT_ALGORITHM]) user_id: str = payload.get("sub") role: str = payload.get("role", "user") if user_id isNone: raise credentials_exception exp = payload.get("exp") if exp and time.time() > exp: raise HTTPException(status_code=401, detail="Token expired") return {"id": user_id, "role": role, "permissions": payload.get("permissions", [])} except JWTError: raise credentials_exception
数据契约 libs/schemas/chat.py:
# libs/schemas/chat.pyfrom pydantic import BaseModel, Fieldfrom typing importList, Optional, Dict, Anyfrom datetime import datetimeclassMessage(BaseModel): role: str# "user", "assistant", "system" content: str timestamp: datetime = Field(default_factory=datetime.utcnow)classChatRequest(BaseModel): message: str session_id: Optional[str] = None stream: bool = True filters: Optional[Dict[str, Any]] = NoneclassChatResponse(BaseModel): answer: str session_id: str citations: List[Dict[str, str]] = [] # [{"source": "doc.pdf", "text": "..."}] latency_ms: floatclassRetrievalResult(BaseModel): content: str source: str score: float metadata: Dict[str, Any]
异步数据网关
可扩展 API 不应阻塞主线程。我们为所有数据库使用异步客户端,以便单个 worker 可在数据库执行期间服务更多连接。
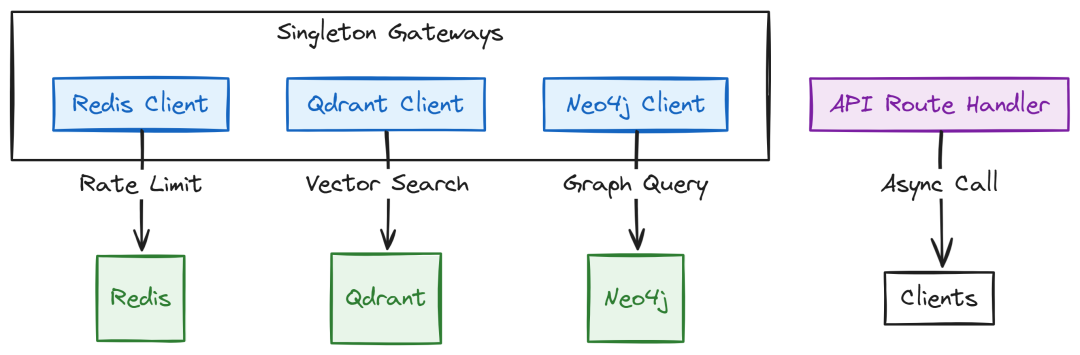
Async Data Gateway (Created by Fareed Khan)
Redis 客户端 services/api/app/clients/redis.py:
# services/api/app/clients/redis.pyimport redis.asyncio as redisfrom services.api.app.config import settingsclassRedisClient: """ Redis 连接池单例,用于限流与语义缓存 """ def__init__(self): self.redis = None asyncdefconnect(self): ifnotself.redis: self.redis = redis.from_url( settings.REDIS_URL, encoding="utf-8", decode_responses=True ) asyncdefclose(self): ifself.redis: awaitself.redis.close() defget_client(self): returnself.redisredis_client = RedisClient()
Qdrant 向量搜索 services/api/app/clients/qdrant.py(异步客户端):
# services/api/app/clients/qdrant.pyfrom qdrant_client import QdrantClient, AsyncQdrantClientfrom services.api.app.config import settingsclassVectorDBClient: """ Qdrant 异步客户端 """ def__init__(self): self.client = AsyncQdrantClient( host=settings.QDRANT_HOST, port=settings.QDRANT_PORT, prefer_grpc=True ) asyncdefsearch(self, vector: list[float], limit: int = 5): returnawaitself.client.search( collection_name=settings.QDRANT_COLLECTION, query_vector=vector, limit=limit, with_payload=True )qdrant_client = VectorDBClient()
Neo4j 图搜索 services/api/app/clients/neo4j.py:
# services/api/app/clients/neo4j.pyfrom neo4j import GraphDatabase, AsyncGraphDatabasefrom services.api.app.config import settingsimport logginglogger = logging.getLogger(__name__)classNeo4jClient: """ Neo4j 驱动单例(异步) """ def__init__(self): self._driver = None defconnect(self): ifnotself._driver: try: self._driver = AsyncGraphDatabase.driver( settings.NEO4J_URI, auth=(settings.NEO4J_USER, settings.NEO4J_PASSWORD) ) logger.info("Connected to Neo4j successfully.") except Exception as e: logger.error(f"Failed to connect to Neo4j: {e}") raise asyncdefclose(self): ifself._driver: awaitself._driver.close() asyncdefquery(self, cypher_query: str, parameters: dict = None): ifnotself._driver: awaitself.connect() asyncwithself._driver.session() as session: result = await session.run(cypher_query, parameters or {}) return [record.data() asyncfor record in result]neo4j_client = Neo4jClient()
上下文记忆与语义缓存
Agent 的能力取决于“记忆”。我们使用 Postgres 存储完整对话历史,使 LLM 能回忆多轮上下文。
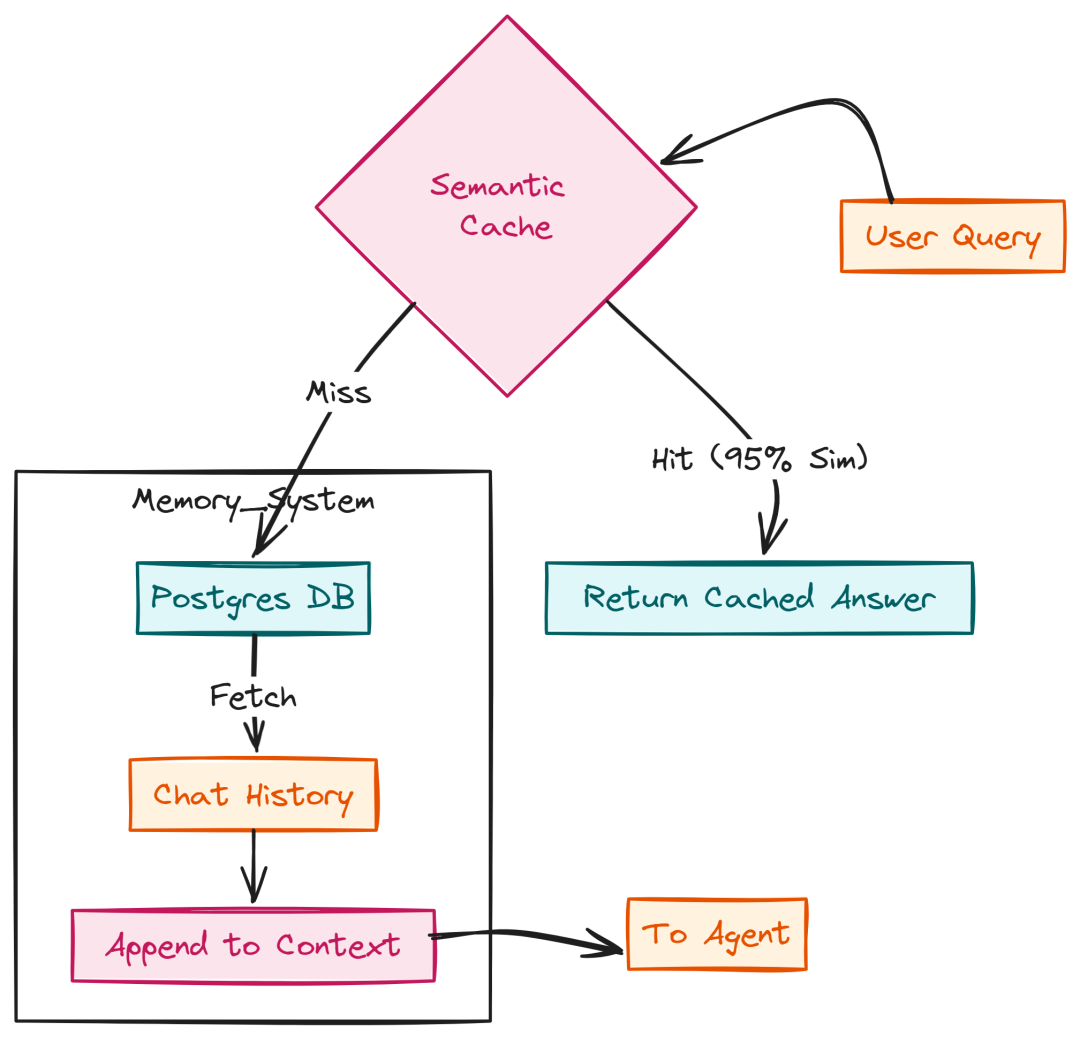
Contextual Mmory handling (Created by Fareed Khan)
在 services/api/app/memory/models.py 定义 schema:
# services/api/app/memory/models.pyfrom sqlalchemy.orm import declarative_basefrom sqlalchemy import Column, Integer, String, Text, DateTime, JSONfrom datetime import datetimeBase = declarative_base()classChatHistory(Base): __tablename__ = "chat_history" id = Column(Integer, primary_key=True, autoincrement=True) session_id = Column(String(255), index=True, nullable=False) user_id = Column(String(255), index=True, nullable=False) role = Column(String(50), nullable=False) content = Column(Text, nullable=False) metadata_ = Column(JSON, default={}, nullable=True) created_at = Column(DateTime, default=datetime.utcnow)
CRUD 逻辑:services/api/app/memory/postgres.py:
# services/api/app/memory/postgres.pyfrom sqlalchemy.ext.asyncio import create_async_engine, AsyncSessionfrom sqlalchemy.orm import sessionmaker, declarative_basefrom sqlalchemy import Column, String, JSON, DateTime, Integer, Textfrom datetime import datetimefrom services.api.app.config import settingsBase = declarative_base()classChatHistory(Base): __tablename__ = "chat_history" id = Column(Integer, primary_key=True, autoincrement=True) session_id = Column(String, index=True) user_id = Column(String, index=True) role = Column(String) content = Column(Text) metadata_ = Column(JSON, default={}) created_at = Column(DateTime, default=datetime.utcnow)engine = create_async_engine(settings.DATABASE_URL, echo=False)AsyncSessionLocal = sessionmaker(bind=engine, class_=AsyncSession, expire_on_commit=False)classPostgresMemory: asyncdefadd_message(self, session_id: str, role: str, content: str, user_id: str): asyncwith AsyncSessionLocal() as session: asyncwith session.begin(): msg = ChatHistory(session_id=session_id, role=role, content=content, user_id=user_id) session.add(msg) asyncdefget_history(self, session_id: str, limit: int = 10): from sqlalchemy import select asyncwith AsyncSessionLocal() as session: result = await session.execute( select(ChatHistory) .where(ChatHistory.session_id == session_id) .order_by(ChatHistory.created_at.desc()) .limit(limit) ) return result.scalars().all()[::-1]postgres_memory = PostgresMemory()
为省钱,我们实现语义缓存 services/api/app/cache/semantic.py:当“意思相近”的查询已回答过,可直接命中缓存,避免再次消耗 70B 模型:
# services/api/app/cache/semantic.pyimport jsonimport loggingfrom typing importOptionalfrom services.api.app.clients.ray_embed import embed_clientfrom services.api.app.clients.qdrant import qdrant_clientfrom services.api.app.config import settingslogger = logging.getLogger(__name__)classSemanticCache: """ 基于向量相似度的语义缓存 """ asyncdefget_cached_response(self, query: str, threshold: float = 0.95) -> Optional[str]: try: vector = await embed_client.embed_query(query) results = await qdrant_client.client.search( collection_name="semantic_cache", query_vector=vector, limit=1, with_payload=True, score_threshold=threshold ) if results: logger.info(f"Semantic Cache Hit! Score: {results[0].score}") return results[0].payload["answer"] except Exception as e: logger.warning(f"Semantic cache lookup failed: {e}") returnNone asyncdefset_cached_response(self, query: str, answer: str): try: vector = await embed_client.embed_query(query) import uuid from qdrant_client.http import models await qdrant_client.client.upsert( collection_name="semantic_cache", points=[ models.PointStruct( id=str(uuid.uuid4()), vector=vector, payload={"query": query, "answer": answer} ) ] ) except Exception as e: logger.warning(f"Failed to write to semantic cache: {e}")semantic_cache = SemanticCache()
这能显著降低 FAQ 的响应时延与成本。
使用 LangGraph 构建工作流
Agent 核心是“状态机”。Agent 在 Thinking、Retrieving、Using Tools、Answering 之间转换。
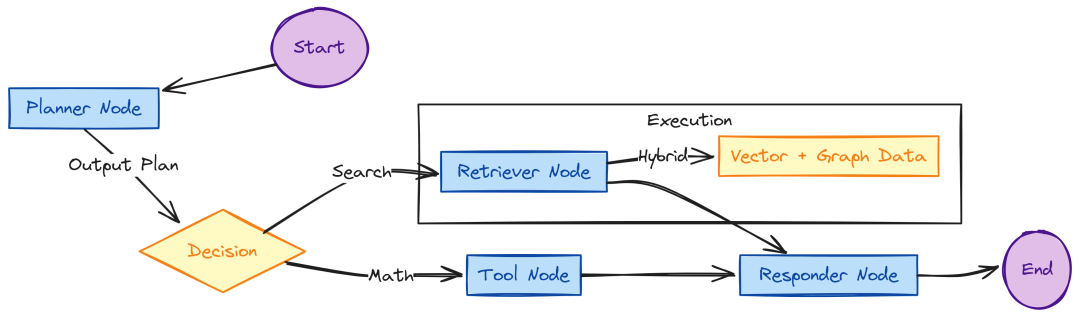
LangGraph Workflow (Created by Fareed Khan)
在 services/api/app/agents/state.py 定义 AgentState:
# services/api/app/agents/state.pyfrom typing import TypedDict, Annotated, List, Unionimport operatorclass AgentState(TypedDict): messages: Annotated[List[dict], operator.add] documents: List[str] current_query: str plan: List[str]
Planner 节点 services/api/app/agents/nodes/planner.py 决策路径:
# services/api/app/agents/nodes/planner.pyimport jsonimport loggingfrom services.api.app.agents.state import AgentStatefrom services.api.app.clients.ray_llm import llm_clientlogger = logging.getLogger(__name__)SYSTEM_PROMPT = """You are a RAG Planning Agent.Analyze the User Query and Conversation History.Decide the next step:1. If the user greets (Hello/Hi), output "direct_answer".2. If the user asks a specific question requiring data, output "retrieve".3. If the user asks for math/code, output "tool_use".Output JSON format ONLY:{ "action": "retrieve" | "direct_answer" | "tool_use", "refined_query": "The standalone search query", "reasoning": "Why you chose this action"}"""
异步 planner:
async defplanner_node(state: AgentState) -> dict: logger.info("Planner Node: Analyzing query...") last_message = state["messages"][-1] user_query = last_message.content ifhasattr(last_message, 'content') else last_message['content'] try: response_text = await llm_client.chat_completion( messages=[ {"role": "system", "content": SYSTEM_PROMPT}, {"role": "user", "content": user_query} ], temperature=0.0 ) plan = json.loads(response_text) logger.info(f"Plan derived: {plan['action']}") return { "current_query": plan.get("refined_query", user_query), "plan": [plan["reasoning"]] } except Exception as e: logger.error(f"Planning failed: {e}") return {"current_query": user_query, "plan": ["Error in planning, defaulting to retrieval."]}
Retriever 节点 services/api/app/agents/nodes/retriever.py 执行 Hybrid Search,并行调用 Qdrant 与 Neo4j:
# services/api/app/agents/nodes/retriever.pyimport asynciofrom typing importDict, Listfrom services.api.app.agents.state import AgentStatefrom services.api.app.clients.qdrant import qdrant_clientfrom services.api.app.clients.neo4j import neo4j_clientfrom services.api.app.clients.ray_embed import embed_clientimport logginglogger = logging.getLogger(__name__)asyncdefretrieve_node(state: AgentState) -> Dict: query = state["current_query"] logger.info(f"Retrieving context for: {query}") query_vector = await embed_client.embed_query(query) asyncdefrun_vector_search(): results = await qdrant_client.search(vector=query_vector, limit=5) return [f"{r.payload['text']} [Source: {r.payload['metadata']['filename']}]"for r in results] asyncdefrun_graph_search(): cypher = """ CALL db.index.fulltext.queryNodes("entity_index", $query) YIELD node, score MATCH (node)-[r]->(neighbor) RETURN node.name + ' ' + type(r) + ' ' + neighbor.name as text LIMIT 5 """ try: results = await neo4j_client.query(cypher, {"query": query}) return [r['text'] for r in results] except Exception as e: logger.error(f"Graph search failed: {e}") return [] vector_docs, graph_docs = await asyncio.gather(run_vector_search(), run_graph_search()) combined_docs = list(set(vector_docs + graph_docs)) logger.info(f"Retrieved {len(combined_docs)} documents.") return {"documents": combined_docs}
Responder 节点 services/api/app/agents/nodes/responder.py 用 Llama-70B 综合回答:
# services/api/app/agents/nodes/responder.pyfrom services.api.app.agents.state import AgentStatefrom services.api.app.clients.ray_llm import llm_clientasyncdefgenerate_node(state: AgentState) -> dict: query = state["current_query"] documents = state.get("documents", []) context_str = "\n\n".join(documents) prompt = f""" You are a helpful Enterprise Assistant. Use the context below to answer the user's question. Context: {context_str} Question: {query} Instructions: 1. Cite sources using [Source: Filename]. 2. If the answer is not in the context, say "I don't have that information in my documents." 3. Be concise and professional. """ answer = await llm_client.chat_completion( messages=[{"role": "user", "content": prompt}], temperature=0.3 ) return {"messages": [{"role": "assistant", "content": answer}]}
Tool 节点 services/api/app/agents/nodes/tool.py 负责执行外部计算/搜索:
# services/api/app/agents/nodes/tool.pyimport loggingfrom services.api.app.agents.state import AgentStatefrom services.api.app.tools.calculator import calculatefrom services.api.app.tools.graph_search import search_graph_toolfrom services.api.app.tools.web_search import web_searchlogger = logging.getLogger(__name__)asyncdeftool_node(state: AgentState) -> dict: plan_data = state.get("plan", []) ifnot plan_data: return {"messages": [{"role": "system", "content": "No tool selected."}]} tool_name = state.get("tool_choice", "calculator") tool_input = state.get("tool_input", "0+0") result = "" if tool_name == "calculator": logger.info(f"Executing Calculator: {tool_input}") result = calculate(tool_input) elif tool_name == "graph_search": logger.info(f"Executing Graph Search: {tool_input}") result = await search_graph_tool(tool_input) else: result = "Unknown tool requested." return {"messages": [{"role": "user", "content": f"Tool Output: {result}"}]}
将各节点编排到 LangGraph:services/api/app/agents/graph.py
# services/api/app/agents/graph.pyfrom langgraph.graph import StateGraph, ENDfrom services.api.app.agents.state import AgentStatefrom services.api.app.agents.nodes.retriever import retrieve_nodefrom services.api.app.agents.nodes.responder import generate_nodefrom services.api.app.agents.nodes.planner import planner_nodeworkflow = StateGraph(AgentState)workflow.add_node("planner", planner_node)workflow.add_node("retriever", retrieve_node)workflow.add_node("responder", generate_node)workflow.set_entry_point("planner")workflow.add_edge("planner", "retriever")workflow.add_edge("retriever", "responder")workflow.add_edge("responder", END)agent_app = workflow.compile()
查询增强与应用入口
为提高检索准确度,我们采用 HyDE(Hypothetical Document Embeddings)。在 services/api/app/enhancers/hyde.py 实现:
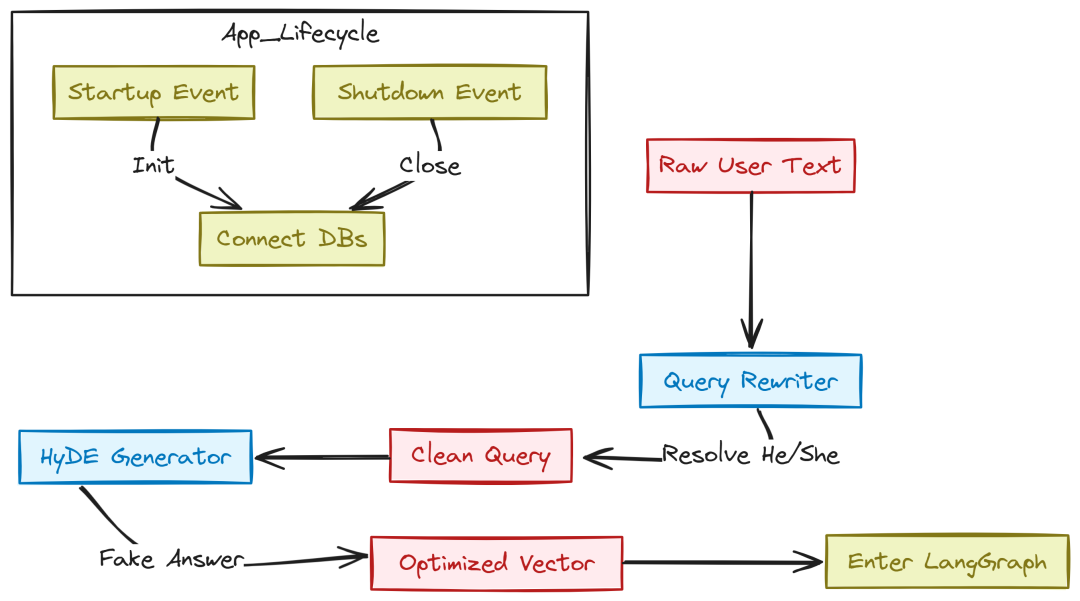
Query Enhance (Created by Fareed Khan)
让 LLM 先“幻写”一个假答案,取其 embedding 进行检索,使得相似语义模式的真实文档更易被找到。
# services/api/app/enhancers/hyde.pyfrom services.api.app.clients.ray_llm import llm_clientSYSTEM_PROMPT = """You are a helpful assistant. Write a hypothetical paragraph that answers the user's question. It does not need to be factually correct, but it must use the correct vocabulary and structure that a relevant document would have.Question: {question}"""asyncdefgenerate_hypothetical_document(question: str) -> str: try: hypothetical_doc = await llm_client.chat_completion( messages=[ {"role": "system", "content": SYSTEM_PROMPT.format(question=question)}, ], temperature=0.7 ) return hypothetical_doc except Exception: return question
同时在 services/api/app/enhancers/query_rewriter.py 进行指代消解与重写,将“它/他们”补全为完整查询:
# services/api/app/enhancers/query_rewriter.pyfrom typing importList, Dictfrom services.api.app.clients.ray_llm import llm_clientSYSTEM_PROMPT = """You are a Query Rewriter. Your task is to rewrite the latest user question to be a standalone search query, resolving coreferences (he, she, it, they) using the conversation history.History:{history}Latest Question: {question}Output ONLY the rewritten question. If no rewriting is needed, output the latest question as is."""asyncdefrewrite_query(question: str, history: List[Dict[str, str]]) -> str: ifnot history: return question history_str = "\n".join([f"{msg['role']}: {msg['content']}"for msg in history]) prompt = SYSTEM_PROMPT.format(history=history_str, question=question) try: rewritten = await llm_client.chat_completion( messages=[{"role": "user", "content": prompt}], temperature=0.0 ) return rewritten.strip() except Exception as e: return question
应用入口 services/api/main.py:管理启动/关闭周期与资源初始化/释放:
# services/api/main.pyfrom contextlib import asynccontextmanagerfrom fastapi import FastAPIfrom services.api.app.clients.neo4j import neo4j_clientfrom services.api.app.clients.ray_llm import llm_clientfrom services.api.app.clients.ray_embed import embed_clientfrom services.api.app.cache.redis import redis_clientfrom services.api.app.routes import chat, upload, health@asynccontextmanagerasyncdeflifespan(app: FastAPI): print("Initializing clients...") neo4j_client.connect() await redis_client.connect() await llm_client.start() await embed_client.start() yield print("Closing clients...") await neo4j_client.close() await redis_client.close() await llm_client.close() await embed_client.close()app = FastAPI(title="Enterprise RAG Platform", version="1.0.0", lifespan=lifespan)app.include_router(chat.router, prefix="/api/v1/chat", tags=["Chat"])app.include_router(upload.router, prefix="/api/v1/upload", tags=["Upload"])app.include_router(health.router, prefix="/health", tags=["Health"])if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8000)
我们已经拥有一个能规划、检索与推理的 agent。接下来构建 Tools & Sandbox,让 agent 能安全地执行代码与访问外部知识。
Tools & Sandbox
在 Enterprise RAG Platform 中,允许 AI 直接执行代码或查询内部数据库是巨大安全风险。攻击者可能通过 prompt 注入访问敏感数据。
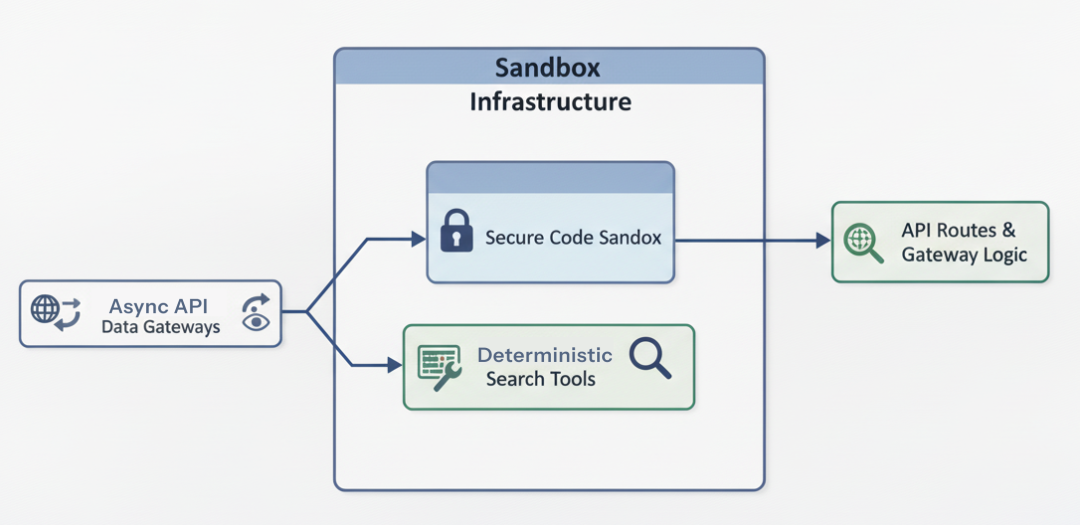
Tools and Sandbox (Created by Fareed Khan)
我们采取分层策略:构建安全、确定性的工具;对于高风险(如 Python 执行),在隔离、加固的 sandbox 容器中运行。
安全代码 Sandbox
让 LLM 生成并执行 Python 代码很强大(数学、绘图、CSV 分析),但也危险:可能 hallucinate 出 os.system("rm -rf /") 或窃取数据。
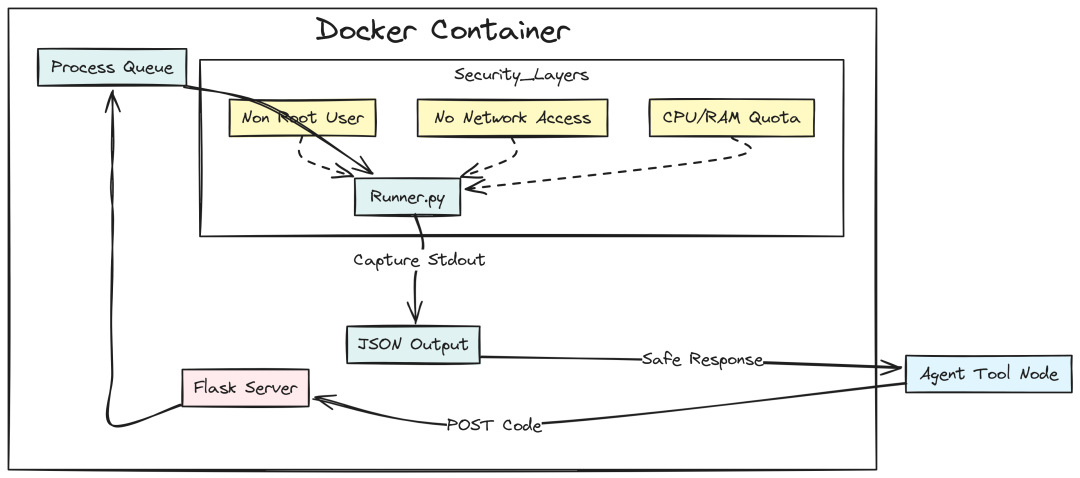
Code Sandbox (Created by Fareed Khan)
解决方案:构建 Sandbox 微服务(独立容器运行不可信代码,无网络、受限 CPU/RAM、短超时)。
services/sandbox/Dockerfile:创建非 root 用户,限制权限。
# services/sandbox/DockerfileFROM python:3.10-slimENV PYTHONDONTWRITEBYTECODE=1 \ PYTHONUNBUFFERED=1RUN useradd -m -u 1000 sandbox_userWORKDIR /appCOPY runner.py .RUN pip install flaskUSER sandbox_userEXPOSE 8080CMD ["python", "runner.py"]
services/sandbox/runner.py:Flask 接收代码,在独立进程执行,捕获 stdout,超时即杀:
# services/sandbox/runner.pyfrom flask import Flask, request, jsonifyimport sysimport ioimport contextlibimport multiprocessingapp = Flask(__name__)defexecute_code_safe(code: str, queue): buffer = io.StringIO() try: with contextlib.redirect_stdout(buffer): exec(code, {"__builtins__": __builtins__}, {}) queue.put({"status": "success", "output": buffer.getvalue()}) except Exception as e: queue.put({"status": "error", "output": str(e)})@app.route("/execute", methods=["POST"])defrun_code(): data = request.json code = data.get("code", "") timeout = data.get("timeout", 5) queue = multiprocessing.Queue() p = multiprocessing.Process(target=execute_code_safe, args=(code, queue)) p.start() p.join(timeout) if p.is_alive(): p.terminate() return jsonify({"output": "Error: Execution timed out."}), 408 ifnot queue.empty(): result = queue.get() return jsonify(result) return jsonify({"output": "No output produced."})if __name__ == "__main__": app.run(host="0.0.0.0", port=8080)
资源限制 services/sandbox/limits.yaml(防止 while True 等攻击):
# services/sandbox/limits.yamlruntime:timeout_seconds:10memory_limit_mb:512cpu_limit:0.5allow_network:falsefiles:max_input_size_mb:5allowed_imports: ["math", "datetime", "json", "pandas", "numpy"]
K8s NetworkPolicy 全面禁止 Sandbox egress services/sandbox/network-policy.yaml:
# services/sandbox/network-policy.yamlapiVersion:networking.k8s.io/v1kind:NetworkPolicymetadata:name:sandbox-deny-egressnamespace:defaultspec:podSelector: matchLabels: app:sandbox-servicepolicyTypes:-Egressegress: []
API 访问 Sandbox 的客户端 services/api/app/tools/sandbox.py:
# services/api/app/tools/sandbox.pyimport httpxfrom services.api.app.config import settingsSANDBOX_URL = "http://sandbox-service:8080/execute"asyncdefrun_python_code(code: str) -> str: try: asyncwith httpx.AsyncClient() as client: response = await client.post( SANDBOX_URL, json={"code": code, "timeout": 5}, timeout=6.0 ) if response.status_code == 200: data = response.json() if data.get("status") == "success": returnf"Output:\n{data['output']}" else: returnf"Execution Error:\n{data['output']}" else: returnf"Sandbox Error: Status {response.status_code}" except Exception as e: returnf"Sandbox Connection Failed: {str(e)}"
确定性与搜索工具
代码执行风险较大,优先选更安全、确定性的工具。数学用 simpleeval:services/api/app/tools/calculator.py:
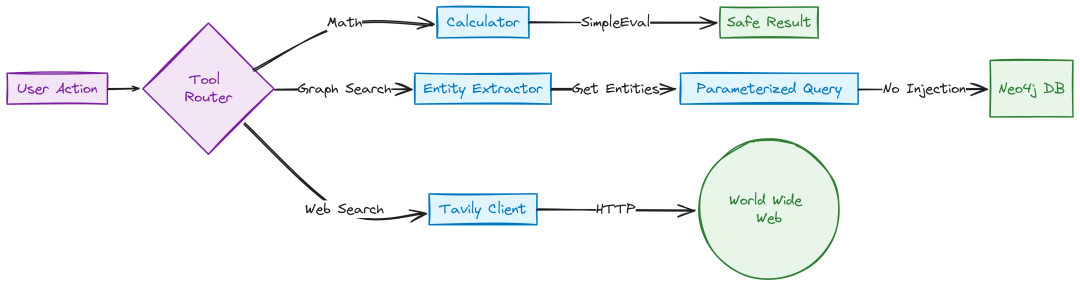
Search Tools (Created by Fareed Khan)
# services/api/app/tools/calculator.pyfrom simpleeval import simple_evaldefcalculate(expression: str) -> str: """ 使用 simpleeval 安全计算表达式,避免 RCE """ iflen(expression) > 100: return"Error: Expression too long." try: result = simple_eval(expression) returnstr(result) except Exception as e: returnf"Error: {str(e)}"
将 Graph/Vector DB 暴露为工具。图搜索 services/api/app/tools/graph_search.py:先由 LLM 提取实体,再执行参数化 Cypher(不允许 LLM 直写 Cypher,防注入):
# services/api/app/tools/graph_search.pyfrom services.api.app.clients.neo4j import neo4j_clientfrom services.api.app.clients.ray_llm import llm_clientimport jsonSYSTEM_PROMPT = """You are a Knowledge Graph Helper.Extract the core entities from the user's question to perform a search.Question: {question}Output JSON only: {"entities": ["list", "of", "names"]}"""
工具实现:
async defsearch_graph_tool(question: str) -> str: try: response_text = await llm_client.chat_completion( messages=[{"role": "system", "content": SYSTEM_PROMPT.format(question=question)}], temperature=0.0, json_mode=True ) data = json.loads(response_text) entities = data.get("entities", []) cypher_query = """ UNWIND $names AS target_name CALL db.index.fulltext.queryNodes("entity_index", target_name) YIELD node, score MATCH (node)-[r]-(neighbor) RETURN node.name AS source, type(r) AS rel, neighbor.name AS target LIMIT 10 """ results = await neo4j_client.query(cypher_query, {"names": entities}) returnstr(results) if results else"No connections found." except Exception as e: returnf"Graph search error: {str(e)}"
向量搜索工具 services/api/app/tools/vector_search.py:
# services/api/app/tools/vector_search.pyfrom services.api.app.clients.qdrant import qdrant_clientfrom services.api.app.clients.ray_embed import embed_clientasyncdefsearch_vector_tool(query: str) -> str: try: vector = await embed_client.embed_query(query) results = await qdrant_client.search(vector, limit=3) formatted = "" for r in results: meta = r.payload.get("metadata", {}) formatted += f"- {r.payload.get('text', '')[:200]}... [Source: {meta.get('filename')}]\n" return formatted if formatted else"No relevant documents found." except Exception as e: returnf"Search Error: {str(e)}"
外部搜索工具 services/api/app/tools/web_search.py(如 Tavily):
# services/api/app/tools/web_search.pyimport httpximport osasyncdefweb_search_tool(query: str) -> str: api_key = os.getenv("TAVILY_API_KEY") ifnot api_key: return"Web search disabled." try: asyncwith httpx.AsyncClient() as client: response = await client.post( "https://api.tavily.com/search", json={"api_key": api_key, "query": query, "max_results": 3} ) data = response.json() results = data.get("results", []) return"\n".join([f"- {r['title']}: {r['content']}"for r in results]) except Exception as e: returnf"Web Search Error: {str(e)}"
API 路由与网关逻辑
将系统通过 REST 暴露。主路由 services/api/app/routes/chat.py 处理流式响应、LangGraph 执行与后台日志记录:
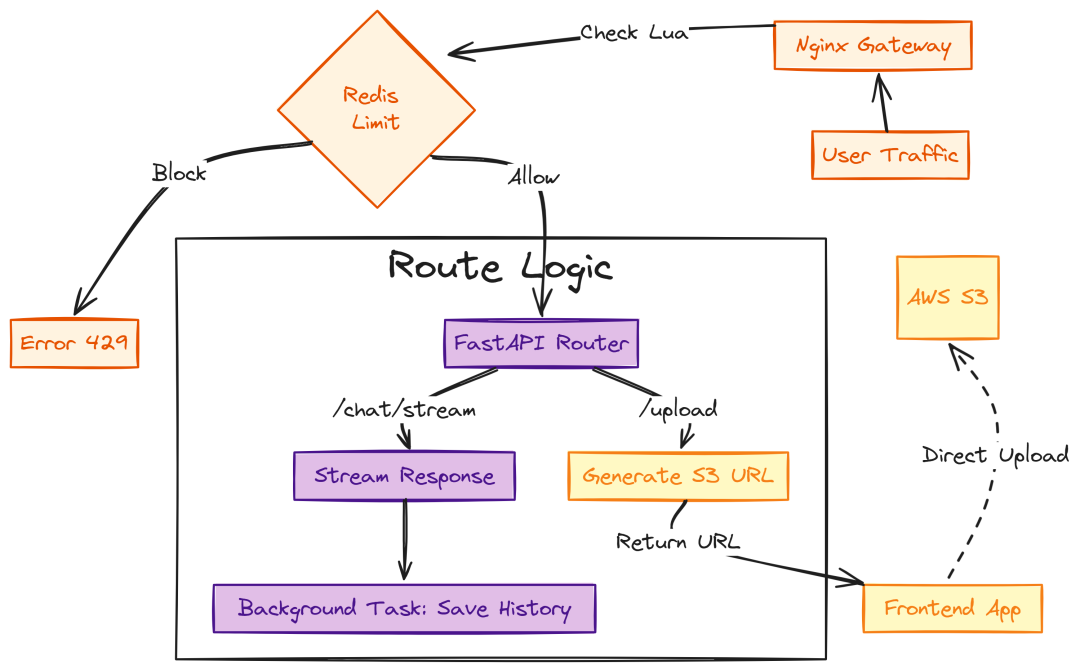
Route Logic (Created by Fareed Khan)
# services/api/app/routes/chat.pyimport uuidimport jsonimport loggingfrom typing import AsyncGeneratorfrom fastapi import APIRouter, Depends, BackgroundTasksfrom fastapi.responses import StreamingResponsefrom services.api.app.auth.jwt import get_current_userfrom services.api.app.agents.graph import agent_appfrom services.api.app.agents.state import AgentStatefrom services.api.app.memory.postgres import postgres_memoryfrom services.api.app.cache.semantic import semantic_cacherouter = APIRouter()logger = logging.getLogger(__name__)classChatRequest(BaseModel): message: str session_id: str = None@router.post("/stream")asyncdefchat_stream(req: ChatRequest, background_tasks: BackgroundTasks, user: dict = Depends(get_current_user)): session_id = req.session_id orstr(uuid.uuid4()) user_id = user["id"] cached_ans = await semantic_cache.get_cached_response(req.message) if cached_ans: asyncdefstream_cache(): yield json.dumps({"type": "answer", "content": cached_ans}) + "\n" return StreamingResponse(stream_cache(), media_type="application/x-ndjson") history_objs = await postgres_memory.get_history(session_id, limit=6) history_dicts = [{"role": msg.role, "content": msg.content} for msg in history_objs] history_dicts.append({"role": "user", "content": req.message}) initial_state = AgentState(messages=history_dicts, current_query=req.message, documents=[], plan=[]) asyncdefevent_generator(): final_answer = "" asyncfor event in agent_app.astream(initial_state): node_name = list(event.keys())[0] node_data = event[node_name] yield json.dumps({"type": "status", "node": node_name}) + "\n" if node_name == "responder"and"messages"in node_data: final_answer = node_data["messages"][-1]["content"] yield json.dumps({"type": "answer", "content": final_answer}) + "\n" if final_answer: await postgres_memory.add_message(session_id, "user", req.message, user_id) await postgres_memory.add_message(session_id, "assistant", final_answer, user_id) await semantic_cache.set_cached_response(req.message, final_answer) return StreamingResponse(event_generator(), media_type="application/x-ndjson")
文件上传 services/api/app/routes/upload.py:企业场景下不通过 API 直传大文件,而是生成 S3 presigned URL,让前端直传:
# services/api/app/routes/upload.pyimport boto3import uuidfrom fastapi import APIRouter, Dependsfrom services.api.app.config import settingsfrom services.api.app.auth.jwt import get_current_userrouter = APIRouter()s3_client = boto3.client("s3", region_name=settings.AWS_REGION)@router.post("/generate-presigned-url")asyncdefgenerate_upload_url(filename: str, content_type: str, user: dict = Depends(get_current_user)): file_id = str(uuid.uuid4()) s3_key = f"uploads/{user['id']}/{file_id}" url = s3_client.generate_presigned_url( ClientMethod='put_object', Params={'Bucket': settings.S3_BUCKET_NAME, 'Key': s3_key, 'ContentType': content_type}, ExpiresIn=3600 ) return {"upload_url": url, "file_id": file_id, "s3_key": s3_key}
反馈与健康检查(略示例):
# services/api/app/routes/feedback.py@router.post("/")async def submit_feedback( req: FeedbackRequest, user: dict = Depends(get_current_user)): ...
``````plaintext
# services/api/app/routes/health.py@router.get("/readiness")async def readiness(response: Response): ...
网关限流 services/gateway/rate_limit.lua(在 Nginx/Kong 中运行,优先在边缘拦截滥用请求):
# -- services/gateway/rate_limit.lualocal redis = require "resty.redis"local red = redis:new()red:set_timeout(100) local ok, err = red:connect("rag-redis-prod", 6379)if not ok thenreturn ngx.exit(500) endlocal key = "rate_limit:" .. ngx.var.remote_addrlocallimit = 100local current = red:incr(key)if current == 1 then red:expire(key, 60) endif current > limitthen ngx.status = 429 ngx.say("Rate limit exceeded.") return ngx.exit(429)end
将限流逻辑前移到 Nginx/Lua,可以在请求抵达 Python API 前即拦截恶意流量,节省宝贵的 CPU。
至此,我们完成应用栈:Ingestion、Models、Agent、Tools。接下来在 AWS 上配置基础设施运行该系统。
Infrastructure as Code (IaC)
有了软件栈,我们需要运行环境。企业平台不能在 AWS 控制台“点点点”,那会引发配置漂移(ClickOps)、安全漏洞与不可重复的环境。
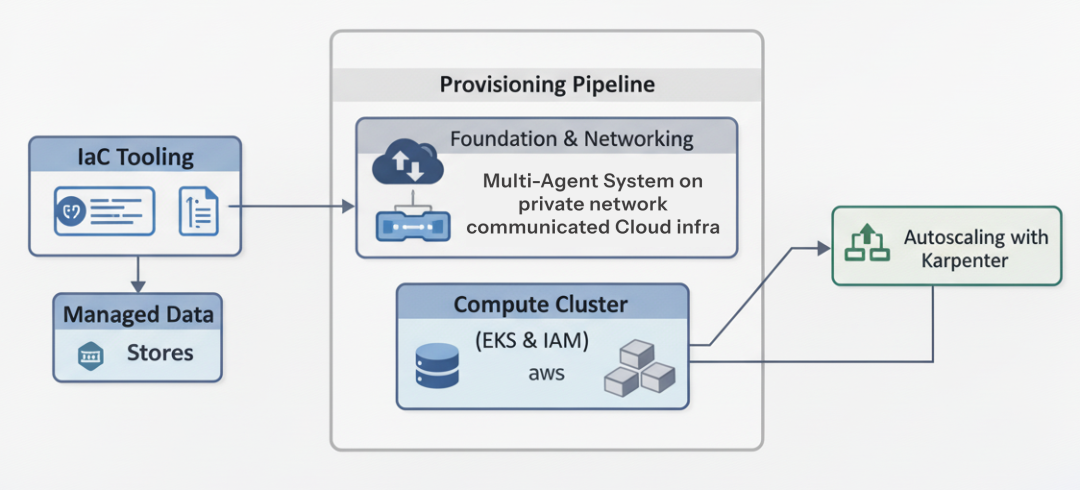
Infra layer (Created by Fareed Khan)
- 使用 Terraform 将云足迹全量代码化,分钟级拉起一致的 dev/staging/prod 环境。
- 使用 Karpenter 智能、准实时的节点伸缩,比传统 ASG 更快更省钱。
基础与网络
一切从网络开始。需要一个隔离的 VPC:对外的负载均衡(Public)、内部应用(Private)与数据库(Database)三层隔离。
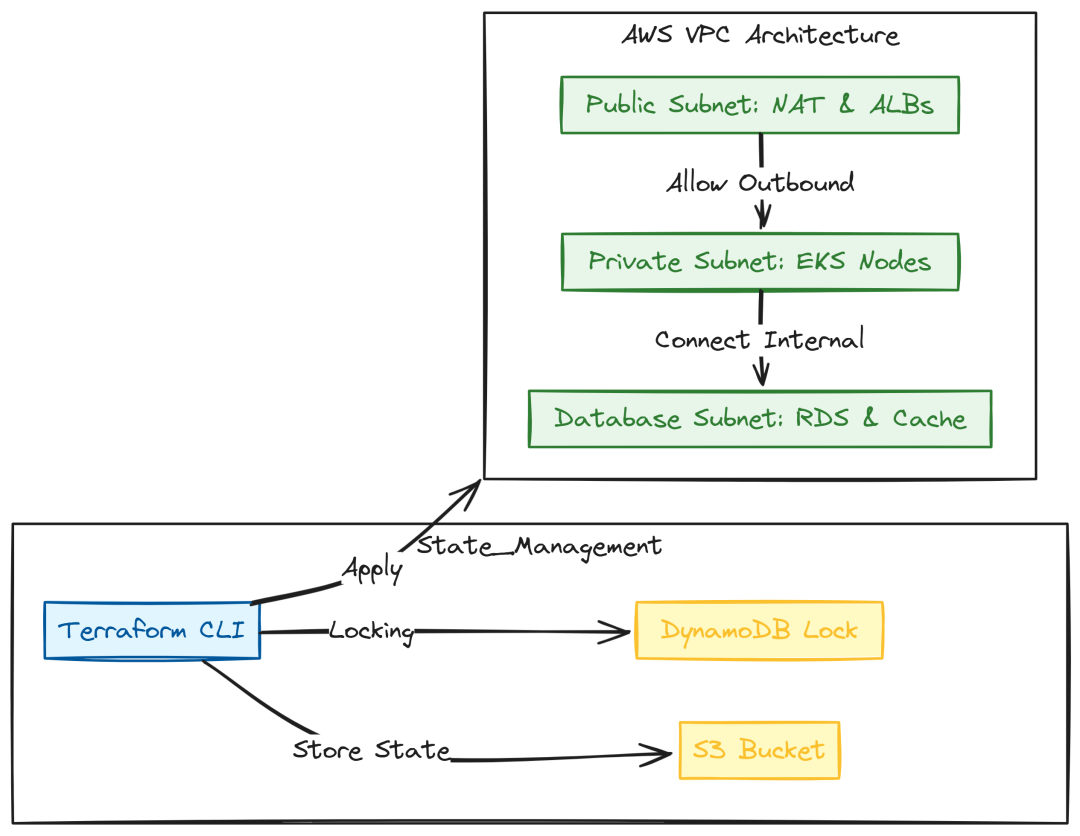
Networking (Created by Fareed Khan)
infra/terraform/main.tf 配置 remote state(S3 + DynamoDB 锁),避免多人并发导致 state 损坏:
# infra/terraform/main.tfterraform { required_version = ">= 1.5.0" backend "s3" { bucket = "rag-platform-terraform-state-prod-001" key = "platform/terraform.tfstate" region = "us-east-1" encrypt = true dynamodb_table = "terraform-state-lock" }required_providers { aws = { source = "hashicorp/aws", version = "~> 5.0" } kubernetes = { source = "hashicorp/kubernetes", version = "~> 2.23" } }}provider "aws" { region = var.aws_region default_tags { tags = { Project = "Enterprise-RAG", ManagedBy = "Terraform" } }}
变量定义 infra/terraform/variables.tf:
# infra/terraform/variables.tfvariable "aws_region" { description = "AWS region to deploy resources" default = "us-east-1"}variable "cluster_name" { description = "Name of the EKS Cluster" default = "rag-platform-cluster"}variable "vpc_cidr" { description = "CIDR block for the VPC" default = "10.0.0.0/16"}
三层网络 infra/terraform/vpc.tf:
# infra/terraform/vpc.tfmodule "vpc" {source = "terraform-aws-modules/vpc/aws" version = "5.1.0"name = "${var.cluster_name}-vpc" cidr = var.vpc_cidr azs = ["us-east-1a", "us-east-1b", "us-east-1c"] public_subnets = ["10.0.1.0/24", "10.0.2.0/24", "10.0.3.0/24"] private_subnets = ["10.0.101.0/24", "10.0.102.0/24", "10.0.103.0/24"] database_subnets= ["10.0.201.0/24", "10.0.202.0/24", "10.0.203.0/24"] enable_nat_gateway = true single_nat_gateway = false enable_dns_hostnames = true public_subnet_tags = { "kubernetes.io/role/elb" = "1" } private_subnet_tags = { "kubernetes.io/role/internal-elb" = "1" }}
计算集群(EKS & IAM)
主力是 Amazon EKS 控制面。开启 OIDC(IRSA)使 K8s ServiceAccount 可临时扮演 AWS IAM Role,避免长久 Access Key 泄露风险。infra/terraform/eks.tf:
# infra/terraform/eks.tfmodule "eks" {source = "terraform-aws-modules/eks/aws" version = "~> 19.0"cluster_name = var.cluster_name cluster_version = "1.29" vpc_id = module.vpc.vpc_id subnet_ids = module.vpc.private_subnets enable_irsa = true eks_managed_node_groups = { system = { name = "system-nodes" instance_types = ["m6i.large"] min_size = 2 max_size = 5 desired_size = 2 } }}
IAM 最小权限:仅授予 ingestion job 所需的 S3 权限,并与特定 SA 绑定 infra/terraform/iam.tf:
# infra/terraform/iam.tfresource "aws_iam_policy""ingestion_policy" { name = "RAG_Ingestion_S3_Policy" policy = jsonencode({ Version = "2012-10-17" Statement = [ { Action = ["s3:GetObject", "s3:PutObject", "s3:ListBucket"] Effect = "Allow" Resource = [aws_s3_bucket.documents.arn, "${aws_s3_bucket.documents.arn}/*"] } ] })}module "ingestion_irsa_role" {source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-account-eks" role_name = "rag-ingestion-role" oidc_providers = { main = { provider_arn = module.eks.oidc_provider_arn namespace_service_accounts = ["default:ray-worker"] } } role_policy_arns = { policy = aws_iam_policy.ingestion_policy.arn }}
托管数据存储
生产系统优先托管服务:Aurora(Postgres)、ElastiCache(Redis),减少维护成本与风险。
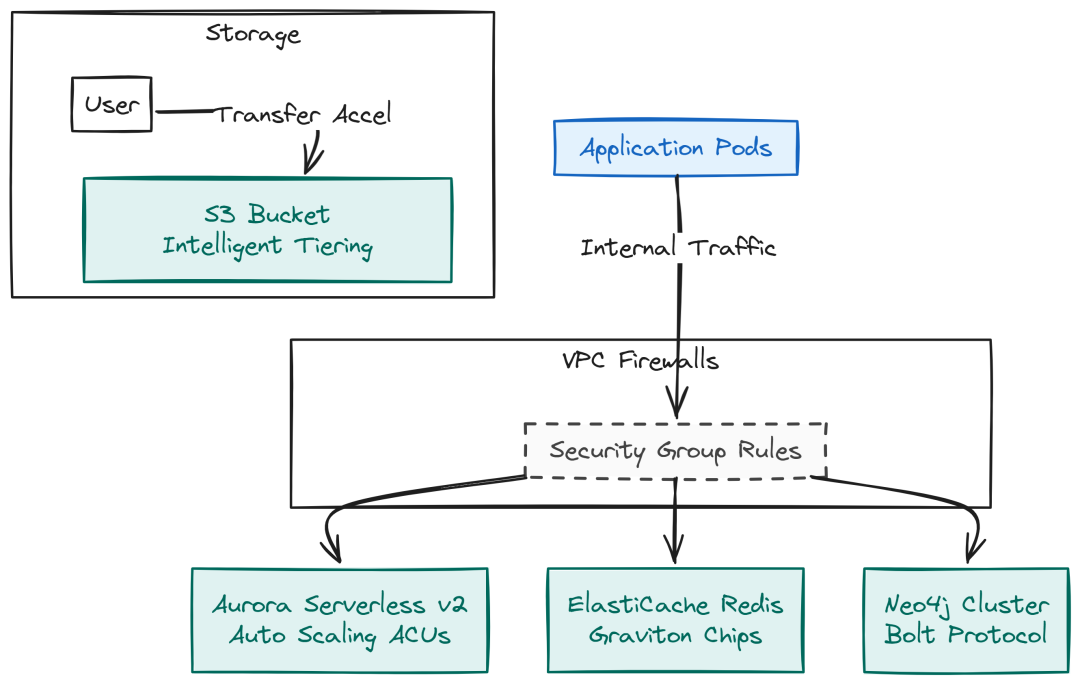
Data Store management (Created by Fareed Khan)
Aurora Serverless v2(弹性 ACUs)infra/terraform/rds.tf:
# infra/terraform/rds.tfmodule "aurora" {source = "terraform-aws-modules/rds-aurora/aws" name = "${var.cluster_name}-postgres" engine = "aurora-postgresql" instance_class = "db.serverless" instances = { one = {} two = {} }serverlessv2_scaling_configuration = { min_capacity = 2 max_capacity = 64 } vpc_id = module.vpc.vpc_id db_subnet_group_name = module.vpc.database_subnet_group_name security_group_rules = { vpc_ingress = { cidr_blocks = [module.vpc.vpc_cidr_block] } }}
ElastiCache(Redis)infra/terraform/redis.tf:
# infra/terraform/redis.tfresource "aws_elasticache_replication_group""redis" { replication_group_id = "rag-redis-prod" description = "Redis for RAG Semantic Cache" node_type = "cache.t4g.medium" num_cache_clusters = 2 port = 6379 subnet_group_name = aws_elasticache_subnet_group.redis_subnet.name security_group_ids = [aws_security_group.redis_sg.id] at_rest_encryption_enabled = true transit_encryption_enabled = true}
S3 文档桶(加速与生命周期)infra/terraform/s3.tf:
# infra/terraform/s3.tfresource "aws_s3_bucket""documents" { bucket = "rag-platform-documents-prod"}resource "aws_s3_bucket_accelerate_configuration""docs_accel" { bucket = aws_s3_bucket.documents.id status = "Enabled"}resource "aws_s3_bucket_lifecycle_configuration""docs_lifecycle" { bucket = aws_s3_bucket.documents.id rule { id = "archive-old-files" status = "Enabled" transition { days = 30 storage_class = "INTELLIGENT_TIERING" } }}
Neo4j 安全组 infra/terraform/neo4j.tf:
# infra/terraform/neo4j.tfresource "aws_security_group" "neo4j_sg" { name = "neo4j-access-sg" vpc_id = module.vpc.vpc_idingress { description = "Internal Bolt Protocol" from_port = 7687 to_port = 7687 protocol = "tcp" cidr_blocks = [module.vpc.vpc_cidr_block] }}
导出输出 infra/terraform/outputs.tf:
# infra/terraform/outputs.tfoutput "aurora_db_endpoint" { value = module.aurora.cluster_endpoint}output "redis_primary_endpoint" { value = aws_elasticache_replication_group.redis.primary_endpoint_address}output "s3_bucket_name" { value = aws_s3_bucket.documents.id}
使用 Karpenter 的 Autoscaling
传统 Cluster Autoscaler 被动、较慢。Karpenter 主动分析待调度 pod 的资源(GPU/内存)并在秒级启动最合适的 EC2。
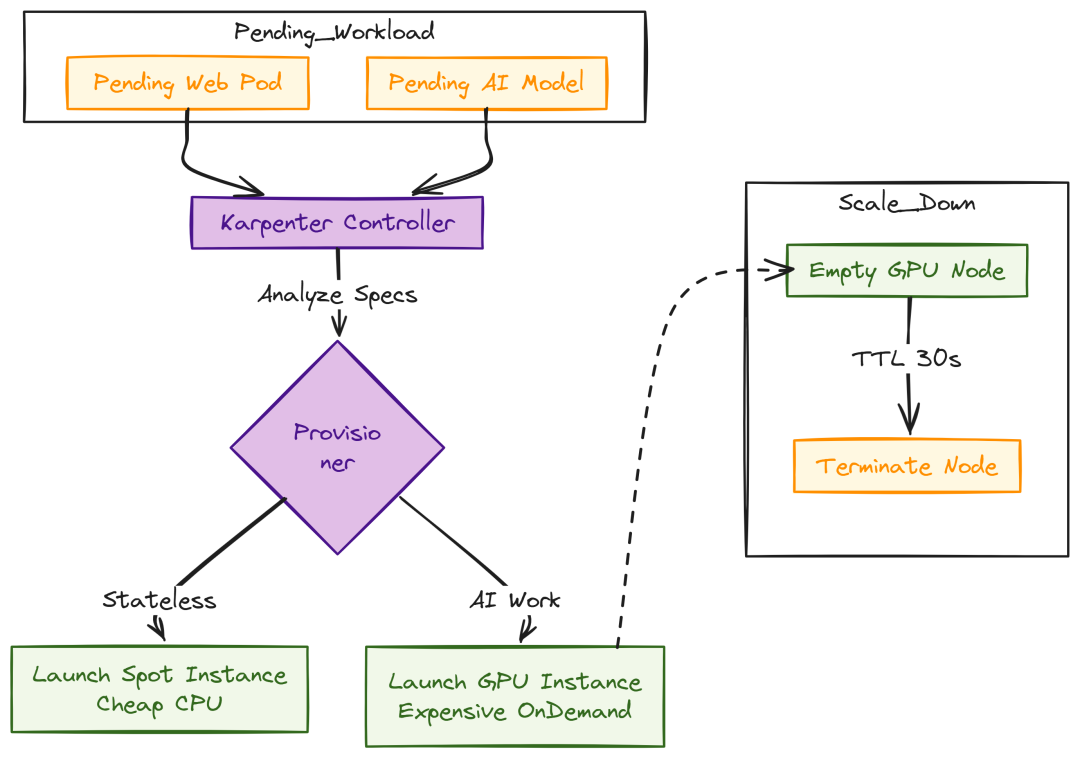
Autoscale with karpenter (Created by Fareed Khan)
CPU provisioner(无状态服务使用 Spot)infra/karpenter/provisioner-cpu.yaml:
# infra/karpenter/provisioner-cpu.yamlapiVersion:karpenter.sh/v1beta1kind:Provisionermetadata:name:cpu-provisionerspec:requirements: -key:"karpenter.k8s.aws/instance-family" operator:In values: ["m6i", "c6i"] -key:"karpenter.sh/capacity-type" operator:In values: ["spot"]limits: resources: cpu:1000consolidation: enabled:true
GPU provisioner(支持 Scale-to-Zero)infra/karpenter/provisioner-gpu.yaml:
# infra/karpenter/provisioner-gpu.yamlapiVersion:karpenter.sh/v1beta1kind:Provisionermetadata:name:gpu-provisionerspec:requirements: -key:"karpenter.k8s.aws/instance-category" operator:In values: ["g"] -key:"karpenter.sh/capacity-type" operator:In values: ["on-demand", "spot"]ttlSecondsAfterEmpty:30
部署
生产级 RAG 平台部署不只是 kubectl apply。需要管理配置漂移、安全处理 secrets,并确保数据库具备容灾能力。
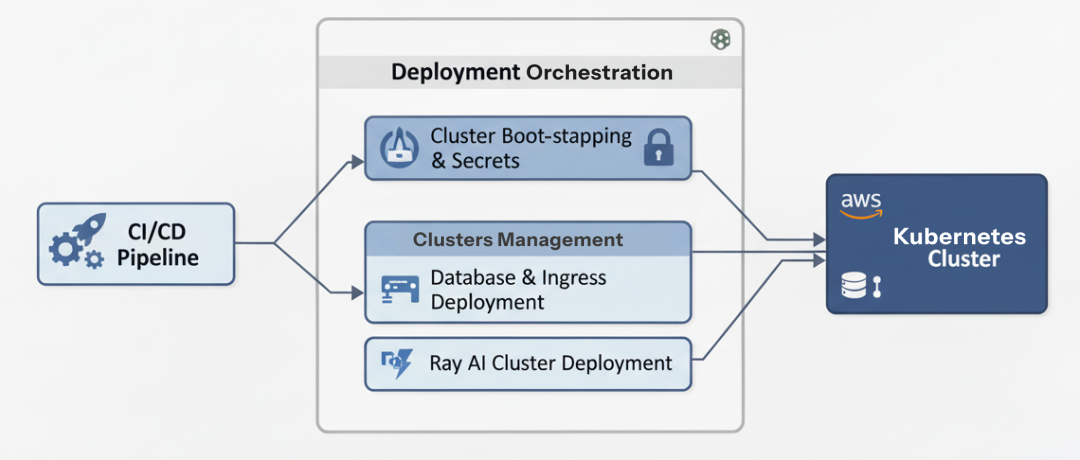
Deployment layer (Created by Fareed Khan)
使用 Helm 打包应用,统一模板,按环境覆盖 values 即可。
集群引导与 Secrets
在部署自研组件之前,先安装 Ingress Controller、External Secrets Operator、KubeRay Operator。用 scripts/bootstrap_cluster.sh 一键安装:
# scripts/bootstrap_cluster.sh#!/bin/bash# 1. KubeRay Operatorhelm repo add kuberay https://ray-project.github.io/kuberay-helm/helm install kuberay-operator kuberay/kuberay-operator --version 1.0.0# 2. External Secretshelm repo add external-secrets https://charts.external-secrets.iohelm install external-secrets external-secrets/external-secrets# 3. Nginx Ingresshelm repo add ingress-nginx https://kubernetes.github.io/ingress-nginxhelm install ingress-nginx ingress-nginx/ingress-nginx
生产环境 secrets 不应提交到 git。我们使用 AWS Secrets Manager 存储,再通过 External Secrets 注入到 K8s pod:
# deploy/secrets/external-secrets.yamlapiVersion:external-secrets.io/v1beta1kind:ExternalSecretmetadata:name:app-secretsspec:refreshInterval:1hsecretStoreRef: name:aws-secrets-manager kind:ClusterSecretStoretarget: name:app-env-secretdata:-secretKey:NEO4J_PASSWORD remoteRef: key:prod/rag/db_creds property:neo4j_password
数据库与 Ingress 部署
Qdrant Helm values(生产化):deploy/helm/qdrant/values.yaml
# deploy/helm/qdrant/values.yamlreplicaCount:3config:storage: on_disk_payload:trueservice: enable_tls:falseresources:requests: cpu:"2" memory:"4Gi"limits: cpu:"4" memory:"8Gi"persistence:size:50GistorageClassName:gp3
Neo4j Helm values:deploy/helm/neo4j/values.yaml
# deploy/helm/neo4j/values.yamlneo4j:name:"neo4j-cluster"edition:"community"core: numberOfServers:1 resources: requests: cpu:"2" memory:"8Gi" volumes: data: mode:"default" storageClassName:"gp3" size:"100Gi"
Ingress 配置:deploy/ingress/nginx.yaml
# deploy/ingress/nginx.yamlapiVersion:networking.k8s.io/v1kind:Ingressmetadata:name:rag-ingressannotations: kubernetes.io/ingress.class:nginx nginx.ingress.kubernetes.io/proxy-body-size:"50m" nginx.ingress.kubernetes.io/proxy-read-timeout:"3600" nginx.ingress.kubernetes.io/proxy-send-timeout:"3600"spec:rules:-host:api.your-rag-platform.com http: paths: -path:/chat pathType:Prefix backend: service: name:api-service port: number:80 -path:/upload pathType:Prefix backend: service: name:api-service port: number:80
Ray AI 集群部署
Ray Autoscaling:deploy/ray/autoscaling.yaml
# deploy/ray/autoscaling.yamlautoscaling:enabled:trueupscaling_speed:1.0idle_timeout_minutes:5worker_nodes: gpu_worker_group: min_workers:0 max_workers:20 resources: {"CPU":4, "memory":32Gi, "GPU":1}
RayCluster:deploy/ray/ray-cluster.yaml
# deploy/ray/ray-cluster.yamlapiVersion:ray.io/v1kind:RayClustermetadata:name:rag-ray-clusterspec:rayVersion:'2.9.0'headGroupSpec: serviceType:ClusterIP template: spec: containers: -name:ray-head image:rayproject/ray:2.9.0-py310-gpu resources: { requests: { cpu:"2", memory:"8Gi" } }workerGroupSpecs:-groupName:gpu-workers replicas:0 minReplicas:0 maxReplicas:20 template: spec: containers: -name:ray-worker image:rayproject/ray:2.9.0-py310-gpu resources: limits: { nvidia.com/gpu:1 } requests: { nvidia.com/gpu:1 } tolerations: -key:"nvidia.com/gpu" operator:"Exists"
RayService(Embedding):deploy/ray/ray-serve-embed.yaml
# deploy/ray/ray-serve-embed.yamlapiVersion: ray.io/v1kind: RayServicemetadata: name: embed-servicespec: serveConfigV2: | applications: - name: bge-m3 import_path: services.api.app.models.embedding_engine:app deployments: - name: EmbedDeployment autoscaling_config: min_replicas: 1 max_replicas: 5 ray_actor_options: num_gpus: 0.5
RayService(LLM):deploy/ray/ray-serve-llm.yaml
# deploy/ray/ray-serve-llm.yamlapiVersion: ray.io/v1kind: RayServicemetadata: name: llm-servicespec: serveConfigV2: | applications: - name: llama3 import_path: services.api.app.models.vllm_engine:app runtime_env: pip: ["vllm==0.3.0"] env_vars: MODEL_ID: "meta-llama/Meta-Llama-3-70B-Instruct" deployments: - name: VLLMDeployment autoscaling_config: min_replicas: 1 max_replicas: 10 ray_actor_options: num_gpus: 1
成本清理脚本 scripts/cleanup.sh:
# scripts/cleanup.sh# !/bin/bashecho"⚠️ WARNING: THIS WILL DESTROY ALL CLOUD RESOURCES ⚠️"echo"Includes: EKS Cluster, Databases (RDS/Neo4j/Redis), S3 Buckets, Load Balancers."echo"Cost-saving measure for Dev/Test environments."echo""read -p "Are you sure? Type 'DESTROY': " confirmif [ "$confirm" != "DESTROY" ]; then echo"Aborted." exit 1fiecho"🔹 1. Deleting Kubernetes Resources (Helm)..."helm uninstall api || truehelm uninstall qdrant || truehelm uninstall ray-cluster || truekubectl delete -f deploy/ray/ || trueecho"🔹 2. Waiting for LBs to cleanup..."sleep 20echo"🔹 3. Running Terraform Destroy..."cd infra/terraformterraform destroy -auto-approveecho"✅ All resources destroyed."
我们用 Terraform、Helm 与 Ray 组合,实现对基础设施的全面掌控,并自动化分布式系统的复杂性。下面看如何在生产规模下监控与评估。
评估与运维
Enterprise RAG 平台需要在开发阶段就重视评估。我们要有 Observability(指标/追踪)、Evaluation(准确性),以及 Operations(压测/维护)策略。
生产中,用户“点赞/点踩”是一种反馈,但往往稀疏且滞后,难以及时发现问题。
可观测性与追踪
“不可度量就不可优化”。涉及 Ray、Kubernetes、多数据库的分布式系统,若无分布式追踪,几乎无法定位瓶颈。
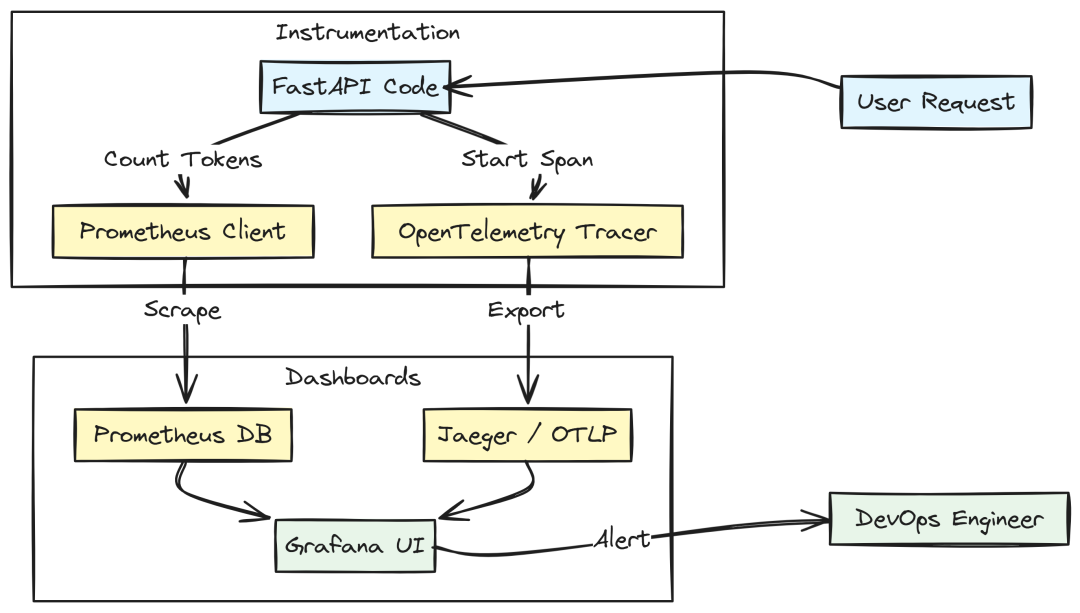
Tracing Logic (Created by Fareed Khan)
在 libs/observability/metrics.py 定义 Prometheus 指标,追踪请求量、延迟、token 使用量:
# libs/observability/metrics.pyfrom prometheus_client import Counter, HistogramREQUEST_COUNT = Counter( "rag_api_requests_total", "Total number of requests", ["method", "endpoint", "status"])REQUEST_LATENCY = Histogram( "rag_api_latency_seconds", "Request latency", ["endpoint"])TOKEN_USAGE = Counter( "rag_llm_tokens_total", "Total LLM tokens consumed", ["model", "type"])deftrack_request(method: str, endpoint: str, status: int): REQUEST_COUNT.labels(method=method, endpoint=endpoint, status=status).inc()
OpenTelemetry 追踪 libs/observability/tracing.py:
# libs/observability/tracing.pyfrom opentelemetry import tracefrom opentelemetry.sdk.trace import TracerProviderfrom opentelemetry.sdk.trace.export import BatchSpanProcessor, ConsoleSpanExporterdef configure_tracing(service_name: str): provider = TracerProvider() processor = BatchSpanProcessor(ConsoleSpanExporter()) provider.add_span_processor(processor) trace.set_tracer_provider(provider) return trace.get_tracer(service_name)
持续评估流水线
使用“LLM-as-a-Judge”自动质检,结合 Golden Dataset 测评 RAG 准确率。
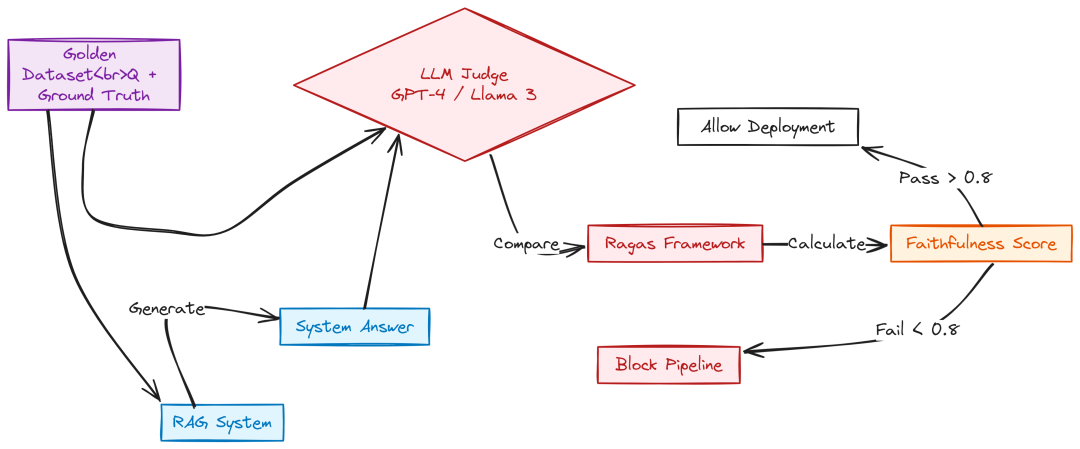
Continuous Eval (Created by Fareed Khan)
eval/datasets/golden.json(示例):
// eval/datasets/golden.json[{ "question":"Explain the difference between the Horizontal Pod Autoscaler (HPA) and the Cluster Autoscaler.", "ground_truth":"The HPA scales the number of Pods based on CPU/metrics. The Cluster Autoscaler scales the number of Nodes when pods are unschedulable.", "contexts":[ "The Horizontal Pod Autoscaler is a Kubernetes component that adjusts the number of replicas...", "The Cluster Autoscaler is a tool that automatically adjusts the size of the Kubernetes cluster..." ]} ...]
Judge 脚本 eval/judges/llm_judge.py:
# eval/judges/llm_judge.pyfrom pydantic import BaseModelfrom services.api.app.clients.ray_llm import llm_clientclassGrade(BaseModel): score: int reasoning: strJUDGE_PROMPT = """You are an impartial judge evaluating a RAG system.You will be given a Question, a Ground Truth Answer, and the System's Answer.Rate the System's Answer on a scale of 1 to 5:1: Completely wrong or hallucinated.3: Partially correct but missing key details.5: Perfect, comprehensive, and matches Ground Truth logic.Output JSON only: {{"score": int, "reasoning": "string"}}Question: {question}Ground Truth: {ground_truth}System Answer: {system_answer}"""asyncdefgrade_answer(question: str, ground_truth: str, system_answer: str) -> Grade: import json try: response_text = await llm_client.chat_completion( messages=[{"role": "user", "content": JUDGE_PROMPT.format( question=question, ground_truth=ground_truth, system_answer=system_answer )}], temperature=0.0 ) data = json.loads(response_text) return Grade(**data) except Exception as e: return Grade(score=0, reasoning=f"Judge Error: {e}")
使用 Ragas 进行系统化评估 eval/ragas/run.py:
# eval/ragas/run.pyfrom ragas import evaluatefrom ragas.metrics import faithfulness, answer_relevancyfrom datasets import Datasetdefrun_evaluation(questions, answers, contexts, ground_truths): data = { "question": questions, "answer": answers, "contexts": contexts, "ground_truth": ground_truths } dataset = Dataset.from_dict(data) results = evaluate( dataset=dataset, metrics=[faithfulness, answer_relevancy], ) df = results.to_pandas() df.to_csv("eval/reports/evaluation_results.csv", index=False) print(results)
在 CI/CD 中设定阈值(如 Faithfulness < 0.8 则阻断部署)。
卓越运营与维护
维护工具:压测、迁移、预热等。
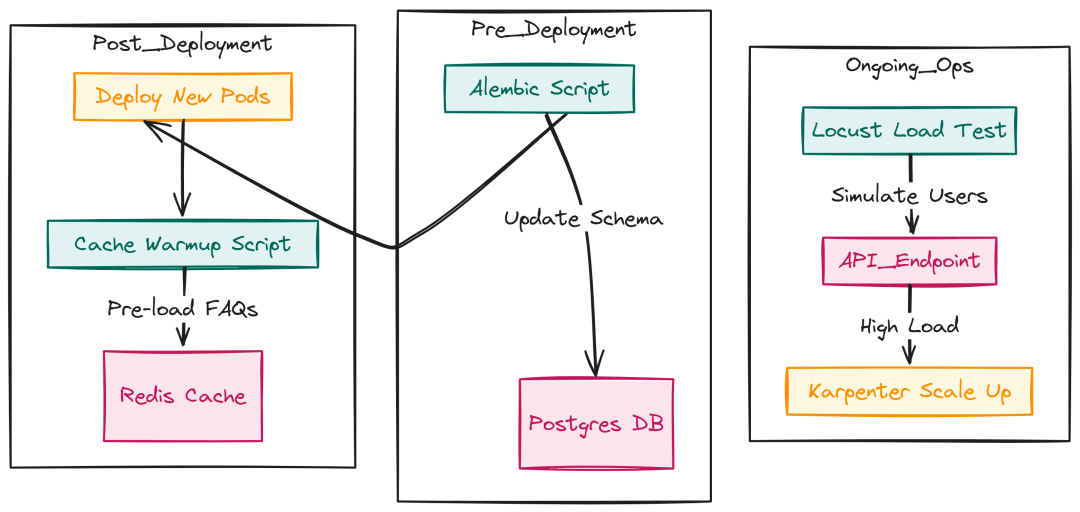
Mantaining Deployment (Created by Fareed Khan)
Locust 压测 scripts/load_test.py:
# scripts/load_test.pyfrom locust import HttpUser, task, betweenimport osclassRAGUser(HttpUser): wait_time = between(1, 5) @task defchat_stream_task(self): headers = {"Authorization": f"Bearer {os.getenv('AUTH_TOKEN')}"} payload = { "message": "What is the warranty policy for the new X1 processor?", "session_id": "loadtest-user-123" } withself.client.post( "/api/v1/chat/stream", json=payload, headers=headers, stream=True, name="/chat/stream" ) as response: if response.status_code != 200: response.failure("Failed request") else: for line in response.iter_lines(): if line: pass response.success()
数据库迁移 scripts/migrate_db.py(包装 Alembic):
# scripts/migrate_db.pyimport subprocessimport osfrom services.api.app.config import settingsdefrun_migrations(): print("Running database migrations...") env = os.environ.copy() env["DATABASE_URL"] = settings.DATABASE_URL try: subprocess.run( ["alembic", "upgrade", "head"], check=True, env=env, cwd=os.path.dirname(os.path.abspath(__file__)) ) print("✅ Migrations applied successfully.") except subprocess.CalledProcessError as e: print(f"❌ Migration failed: {e}") exit(1)if __name__ == "__main__": run_migrations()
缓存预热 scripts/warmup_cache.py:
# scripts/warmup_cache.pyimport asynciofrom services.api.app.cache.semantic import semantic_cacheFAQ = [ ("What are your business hours?", "Our business hours are 9 AM to 5 PM."), ("What is the return policy?", "Return within 30 days."),]asyncdefwarmup(): print("🔥 Warming up semantic cache...") for question, answer in FAQ: await semantic_cache.set_cached_response(question, answer) print("✅ Cache warmup complete.")if __name__ == "__main__": asyncio.run(warmup())
端到端执行
我们已完成代码、基础设施与评估流水线。现在把全部部署起来,运行 RAG 平台。
需要先为 Terraform 配置远端状态:S3 + DynamoDB 锁(一次性)。
创建 EKS 集群
Terraform 后端就绪后,在终端创建 VPC、EKS 控制面与数据库:
注意:此步骤仅创建 EKS 控制面与一个小的 system node group(2 个小 CPU)。不会创建 GPU 节点——只有当软件需要时才按需创建,以节省费用。
执行:
# 项目根目录make infra
输出略,完成后得到:
Outputs:aurora_db_endpoint = "rag-platform-cluster-postgres.cluster-c8s7d6f5.us-east-1.rds.amazonaws.com"redis_primary_endpoint = "rag-redis-prod.ng.0001.use1.cache.amazonaws.com"s3_bucket_name = "rag-platform-documents-prod"
配置 kubectl 并引导安装系统控制器:
aws eks update-kubeconfig --region us-east-1 --name rag-platform-cluster./scripts/bootstrap_cluster.sh
接着安装 Karpenter 配置(略)。然后应用 Ray 配置,K8s 会尝试调度需要 GPU 的 pod,Karpenter 将自动购买合适的 g5 实例:
kubectl apply -f deploy/ray/kubectl get pods -w
等待 ~45–90 秒,GPU 节点初始化并就绪,Ray worker 运行中,vLLM 开始加载 Llama-3-70B(量化约 40GB)。
推理与延迟测试
将 1000 份文档上传至 S3 并触发 Ray 作业(Karpenter 会按需再起 CPU 节点):
python scripts/bulk_upload_s3.py ./data rag-platform-documents-prodpython -m pipelines.jobs.s3_event_handler
Ray Data 显示读取/解析/向量化/写入的进度与吞吐,2 分钟内处理完 1000 份企业文档(得益于 CPU 并行与 GPU 批处理)。
接着发起复杂问题,观察 Agent 规划与检索:
kubectl get ingress# => api.your-rag-platform.comcurl -X POST https://api.your-rag-platform.com/api/v1/chat/stream \ -H "Content-Type: application/json" \ -d '{ "message": "Compare the cost of the HPA vs VPA in Kubernetes based on the docs.", "session_id": "demo-session-1" }'
流式输出示例(略),可见 planner -> retriever -> responder 的状态,带引用来源的专业回答。结构化日志提供延迟分解(planner 节点、retrieval 并行、vLLM TTFT 等),整体 2–4 秒内完成。
为进一步保持 ~3 秒延迟,即使引入更多 agent(如代码审查、web 搜索),可将不同 agent 分布到多个 Ray actors 并行工作。
Redis 与 Grafana 仪表盘分析
使用 Locust 启动 500 并发压测:
locust -f scripts/load_test.py --headless -u 500 -r 10 --host https://api.your-rag-platform.com
观察 Ray 与 Grafana:随着队列变深,Ray Autoscaler 请求更多 GPU worker,Karpenter 秒级拉起新 g5 节点。初期延迟达 5s,随后稳定到 ~1.2s。
Autoscaler 日志显示扩容触发,目标节点数提升,90 秒内容量翻倍,延迟恢复稳定。
至此,系统可在高噪声数据下保持高效 ingestion、自动伸缩,并在用户离开后“Scale-to-Zero”以节省成本。
你可以使用现有的 GitHub 项目
https://github.com/FareedKhan-dev/scalable-rag-pipeline
继续深入,构建更复杂的 agentic RAG pipeline。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献584条内容
已为社区贡献584条内容

所有评论(0)