金融实测:为了抢单,必须“拒绝”DeepSeek R1
消失的这 11 天,我差点把公司的报价收集系统搞崩了。金融AI智能体建设使用Deepseek R1一定要想清楚。
消失的这 11 天,我差点把公司的报价收集系统搞崩了。
最近被“DeepSeek V4即将发布”的消息刷屏,领导在群里转发了几篇《V4即将震撼发布》云云的文章,然后艾特我:“咱们的债券行情机器人,能不能接这个?听说性能又将提升一大截。”
作为泛科技爱好者,我对新技术向来都是拥抱态度,但作为一线从业者,我对于DS落地具体金融系统功能持保守态度。
原因很简单, 金融系统在业务处理上往往对时效性要求很高的同时,对准确性上有近乎苛刻的严格 。
对于行情解析场景,不规则文本和行业内“黑话”的解析准确性使用小参数的非推理模式往往不够精确;而使用大参数模型的推理模式又不够及时。
![]()
01.冲突:我知道你很急,但你先别急
IM 群里的债券非结构化报价瞬息万变,在这个市场, 速度就是利润 。
我找了一条真实的“黑话”报价扔给 DeepSeek R1满血版:
输入数据:24附息国债10 2.15 --5000 必须搞 t+0
这行字里全是坑。“2.15”是收益率,“--”是减点(低于估值),“必须搞”是情绪词,“t+0”是交割速度。
R1 不仅读懂了,甚至通过思维链(CoT)推理出:“用户使用了双减号,通常代表极强的卖出意愿,且强调 T+0,建议标注为高优先级紧急卖单。” 准确率:90%。
但为了完成这个推理,R1 的 API(本地部署的满血版)足足思考了 14.7 秒 。
Wait Time: 14700ms
而在真实的交易台,14.7 秒意味着什么? 意味着这笔 5000 万的单子,早就被隔壁哪家还在用 BERT 这种“笨模型”的对手抢走了。他们的准确率可能只有 85%,但他们只需要 30ms 。
在交易领域,迟到的准确,一文不值。
![]()
02.破局:天生我材必有用,R1的推理能力不可浪费
直接用不行,R1 强大的逻辑能力不就浪费了吗?
换个思路或许有奇效:特洛伊木马战术 。我们不让R1直接见客户,而是把它关在后台,作为老师,去教我们要上线的学生(即原本的 7B/14B 小模型)。
这就是“模型蒸馏”在金融场景的真实落地场景。
具体分三步走:
准备教材(离线阶段)
我根据系统里过去半年里识别错误的 2000 条“黑话”日志,脱敏处理后,使用R1帮我优化并筛选出几种主要的典型类型。
名师辅导(R1 介入)
让 R1 在离线环境慢慢跑,不限时。要求它不仅给出最终的 JSON 结构,还要输出 标签里的推理过程。
学生刷题(SFT 微调)
将 R1 生成的“完美答案”和“推理逻辑”,喂给生产的 DeepSeek-V3-Lite 或者 Qwen-7B 这种小模型吃。
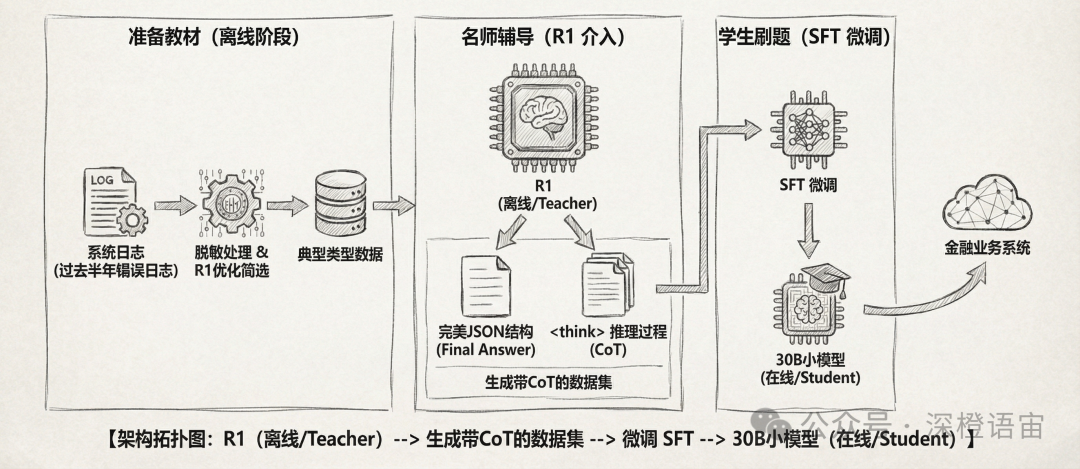
实测结果: 经过 R1“开小灶”后的小模型,虽然参数没变,但它好像突然“开窍”了。它记住了大部分R1处理复杂语法的逻辑,且基本上保留了毫秒级的响应速度。
耗时:53ms(几乎没变)
准确率:从 75% 提升到了 86%(有点接近 R1,但确实还有距离)
![]()
03.踩坑:如果画好ppt就能解决问题,那还要一线开发干嘛
当然,实战从来没有 PPT 上画得那么顺利。在这 11 天里,踩了两个巨大的坑:
R1 的“废话”太多
R1非常喜欢输出Markdown格式的解释,甚至会在JSON里夹带私货。如果你直接用它的输出做训练数据,你的 ETL 脚本会报错报到怀疑人生。
这里提供两个解决思路:
-
在 Prompt 里加死命令,效果是有的,但是不稳定
-
写正则暴力清洗 标签外的内容,这个相对稳定一点,但稍微对清洗后的质量有一定影响,且如果使用正则匹配,有时候会出现误删的情况,具体原因还在排查。
显存爆炸
私有化跑通 R1 的长思维链过程中本地那台A800显存经常溢出。
这个的话确实没有太好办法:对于金融短文本清洗,可以考虑强制截断 R1 的思考深度,减少发散。
![]()
04.结语
DeepSeek R1 很强,但这慢悠悠的做派在金融场景下真是急的人吐血。还记得优化期间我和运维同事(业务着急上线,直接开发测试上线一条龙…)看着表从下午7点,走到晚上11点,真的只有无奈。至于为啥7点才开始搞?我只能说金融系统干过的朋友懂的都懂。
金融这种B端业务系统里, 技术选型没有“最强”,只有“最合适”。
如果大家对“如何清洗金融脏数据”感兴趣,可以在评论区留言反馈,想看的人多的话,后续我单独出一篇代码级的实操复盘。
喜欢看技术吐槽以及关注金融AI发展的朋友可以关注下我。
关注公众号,我是【深橙语宙】,一个专注落地金融AI的实干派!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)