从“暴力调用”到“精细编排”:解构 AI Agent 的大脑核心——Planner 与 Router
面对工具爆发,本文解析 Planner 与 Router 架构,通过规划与路由解耦解决 Token 爆炸与幻觉,构建逻辑自主的工业级 Agent。
一、引言
Agent 的进化史,本质上就是一部如何克服选择困难症的奋斗史。
1.1 理想与现实的鸿沟:当 Agent 面对 100 个 MCP Server 时
在 MCP(Model Context Protocol)的愿景中,我们描绘了一个无缝连接的世界:一个 Agent 可以通过标准协议,瞬间调用来自 Google Drive 的文档、GitHub 的代码库、Postgres 数据库乃至实时运行的本地终端。
理想情况下,作为"全能天才",它能自如操控数字世界的所有资源。
现实情况是,当 Agent 挂载 100 个 MCP Server 时,系统崩溃将先于协作效应出现:
- Token 爆炸: 每个 MCP Server 都会向模型暴露其 Tool 描述。100 个 Server 可能意味着数百个函数定义,这会在瞬间吞掉数万个上下文 Token。
- 模型幻觉: 在浩如烟海的 API 文档中,模型开始变得“健忘”。它可能在调用 Slack API 时错用了 Jira 的参数格式,或者在面对功能相似的工具(如两个不同的搜索插件)时陷入混乱。
- 注意力分散: 就像一个人在面对 1000 把钥匙时无法快速找到开门的那一把,模型在极长的 Prompt 中会丢失重点(Lost in the middle),导致逻辑推理能力的显著下降。
1.2 为什么“全量加载”行不通?
在早期简单的 Agent 实验中,我们习惯于将所有 Tool 塞进 System Prompt。但在工业级应用中,这种“暴力美学”正面临严峻挑战:
- 上下文窗口的物理极限: 尽管模型窗口在扩大,但有效的“长文本推理质量”依然昂贵且不稳定。
- 恐怖的推理成本: 每一轮对话都要重复传输巨大的工具集定义,不仅增加了延迟(Latency),更让 API 账单呈指数级增长。
- 动态生态的不可预测性: 现代企业的 MCP Server 集群是动态增减的。要求模型在每一时刻都“记住”所有可用的端点,既不科学,也不具备扩展性。
结论很明确: Agent 架构必须从“全量加载”演进为“按需加载”。
1.3 核心角色登场:Planner 与 Router
为了弥合理想与现实的鸿沟,Agent 架构引入了两层关键的抽象。这不仅仅是技术方案的改进,更是 Agent 从“玩具”迈向“复杂任务处理器”的分水岭。
-
Planner(规划者):大局观的守护者
- 职责: 它不关心具体的 API 细节,而是专注于任务的分解。面对用户模糊的指令(如“分析上周销售下滑的原因并发送邮件”),Planner 负责将目标拆解为:查询数据库 -> 数据可视化 -> 撰写报告 -> 调用邮件系统。
- 意义: 将“逻辑推理”与“工具调用”解耦,确保模型在大方向上不走偏。
-
Router(路由者):精准的导航员
- 职责: 它是 MCP Server 的“索引器”。Router 负责在成百上千个可用工具中,根据 Planner 的需求,筛选出最匹配的 3-5 个工具推送给执行层。
- 意义: 极大地压缩了上下文体积,通过“语义路由”屏蔽了无关干扰,让模型能够“专注”地完成当前步骤。
Planner 决定“做什么”,Router 决定“用谁做”。 这种分治思想,正是构建企业级 MCP 应用的基石。
为了直观理解这套复杂的协作体系,我们可以把 Agent 处理任务的过程想象成一个建筑工地:
- MCP Server 是货架上的零件:它们是具体的工具或原材料(比如 Slack 通讯、数据库插件),静静躺在仓库里。
- Router 是仓库导购员:他不需要懂怎么盖房子,但他对仓库了如指掌。当工程师说需要‘紧固件’时,他能瞬间从一万个货架中找出那几盒螺丝。
- Planner 是资深工程师:他负责画施工图。他会根据目标,决定先打地基,再立支柱。他不需要亲自去搬零件,但他知道什么时候需要什么。
- Agent 是施工负责人:他是那个最终对结果负责的人,负责统筹导购员、工程师和工人,确保房子(任务)顺利交付。
这种分工,让每个人都能发挥最大的专业效能。
二、Router —— 语义世界的“交通警察”
在拥有上百个 MCP Server 的生态系统中,Router 的存在解决了 Agent 架构中最大的痛点:信噪比过低。它的核心目标是:将成百上千个工具描述,过滤为当前步骤真正需要的“Top-K”个候选项。
2.1 Router 的核心使命:精准降维
Router 的本质是一个过滤器。当 Planner 拆解出一个任务(例如:“检索用户在 Slack 里的财务报表并上传到 Google Drive”)时,Router 需要从 100 个 Server 中识别出:
- Slack Server (用于检索)
- Google Drive Server (用于上传)
- Financial Analysis Tool (可选,用于识别报表)
为什么要精准?
- 防止干扰: 如果同时把 GitHub 和 Postgres 的工具定义塞进去,模型可能会在处理 Slack 任务时产生幻觉。
- 节省 Token: 只加载 3 个工具的 JSON Schema,比加载 100 个要节省 95% 以上的 Context 空间。
2.2 路由的实现策略:从暴力到智能
根据不同的业务复杂度和性能要求,Router 的实现通常分为三个梯队:
1. 关键词/模式路由 —— 最快但最死板
- 原理: 建立一个简单的映射表。如果 Planner 的任务中包含 “Slack”、“Message”、“Chat”,则直接路由到 Slack MCP Server。
- 优点: 毫秒级延迟,零成本。
- 缺点: 缺乏灵活性。如果用户说“去跟老板打个招呼”,关键词匹配可能就会失效。
- 适用场景: 工具集较小且命名高度规范的内部系统。
2. 语义路由 —— 工业级的主流选择
- 原理: 借鉴 RAG(检索增强生成)的思想。
- 将每个 MCP Server 提供的 Tool 描述(Description)预先计算为 Embedding(嵌入向量) 并存入向量数据库(如 Pinecone、Milvus 或本地的 FAISS)。
- 当 Planner 发出指令时,将指令也向量化,进行余弦相似度匹配。
- 优点: 能够处理近义词。例如“把代码推送到远端”能准确匹配到
GitHub Server的git_push工具。 - 缺点: 依赖向量模型的质量;对于功能极其相似的工具可能存在误判。
3. LLM 自主路由 —— 最聪明但昂贵
- 原理: 使用一个参数量较小、响应极快的模型(如 GPT-4o-mini、Claude 3 Haiku 或 Llama 3-8B)作为“前置分诊员”。
- 给这个小模型一份精简的工具清单(仅包含 Server 名称和简短摘要)。
- 由小模型决定:“基于当前的指令,我需要调用哪几个 Server 的 API?”
- 优点: 逻辑理解能力极强,能处理复杂的复合需求。
- 缺点: 增加了一次模型推理的成本和延迟。
2.3 动态注册机制:Agent 的“即插即用”
一个优秀的 Router 不应该是静态硬编码的,它必须具备感知识别(Discovery)能力。Router 之所以能精准导航,全赖于 MCP Server 提供的“自描述”协议。
Schema:工具的“身份证”
在 MCP 协议中,每个工具都通过一份 JSON Schema 来宣告自己的功能。正是这段描述,引导着 Router 在茫茫工具海中做出选择:
{
"name": "query_database",
"description": "执行 SQL 查询以获取过去一周的财务报表数据。仅在需要分析利润、收入或支出时使用。",
"inputSchema": {
"type": "object",
"properties": {
"query": { "type": "string", "description": "SQL 查询语句" },
"time_range": { "type": "string", "enum": ["last_week", "last_month"] }
},
"required": ["query"]
}
}
注意那个 description 字段:它是 Router 识别意图的关键。Router 会将这段文字转化为向量(Embedding)。当 Planner 提出“分析上周利润”时,Router 通过语义匹配发现其与描述高度重合,从而实现精准指路。
动态注册的工作流程
利用这种自描述特性,Router 实现了真正的动态扩展:
- 扫描与连接 (Handshake): 当 Agent 启动或新 Server 上线时,Router 通过 MCP 的
list_tools接口拉取所有可用的工具定义(Tool Definitions)。 - 元数据提取与打标: Router 提取
description和name,利用 LLM 或 Embedding 模型对其进行分类索引(如:数据源类、通讯类、计算类)。 - 动态索引构建: 将这些元数据实时更新到向量数据库或 Router 的轻量级候选清单中。
- 按需激活 (On-demand Activation): 只有当 Router 确定需要某个 Server 时,才会真正将其 Tool Schema 注入到当前对话的执行上下文中。
技术视角下的动态注册流程:
[New MCP Server 上线]
│
▼
[Router 发起 list_tools 请求]
│
▼
[解析 Schema -> 提取 Description -> 生成 Embedding -> 存入向量库]
│
▼
[Planner 发出指令: "分析一下昨天的账单"]
│
▼
[Router 检索向量库 -> 语义命中 "query_database"]
│
▼
[仅将该 Tool 的 Schema 注入执行上下文,屏蔽无关干扰]
这种机制确保了 Agent 既能拥有连接万物的潜力,又能保持极简的运行开销。无论后台挂载 10 个还是 100 个 Server,Executor 看到的永远只有最相关的那几行定义。
2.4 小结
Router 是 Agent 的“注意力分配器”。它通过关键词、语义或轻量级推理,在海量工具和有限的上下文窗口之间建立了一道高效的防火墙。有了 Router,Agent 才能真正具备从“单兵作战”转向“大规模集群协作”的能力。
三、Planner —— 复杂逻辑的“总设计师”
面对简单的指令(如“现在的天气”),模型可以直接调用工具。但面对复杂需求(如“分析上季度财报,对比竞品动态,写一份 PPT 提纲并私聊发给 CEO”),直接调用工具必然会导致逻辑混乱。这时,我们需要 Planner 来建立秩序。
3.1 什么是规划?从“意图”到“蓝图”
规划的本质是将模糊的非结构化目标转化为清晰的结构化步骤。
- 输入: “帮我整理一下 GitHub 上这个项目的未决 Issue,并根据紧急程度发一份总结到 Slack 频道。”
- Planner 的产出(蓝图):
- 调用 GitHub MCP Server 获取所有 Open Issues。
- 对 Issue 内容进行语义分析和紧急度打分。
- 将打分结果格式化为 Markdown 报告。
- 调用 Slack MCP Server 寻找指定的 Channel ID。
- 发送最终消息。
为什么 Planner 至关重要?
如果没有规划,模型往往会“急于求成”,在没有获取到 Issue 列表的情况下就尝试去发 Slack 消息,导致逻辑断裂。
3.2 常见的规划模式:Agent 的思考范式
根据任务的复杂度和实时性要求,Planner 通常采用以下三种模式:
1. 单次规划 (Step-by-Step Planning):预谋而后动
- 策略: 在执行任何实际操作之前,模型先生成一个完整的步骤列表(Plan)。
- 优点: 响应速度快,逻辑透明度高,用户可以提前预览并干预计划。
- 缺点: 过于死板。如果在第一步获取数据时发现数据格式变了,后续所有计划都会失效。
- 适用场景: 流程高度标准化的任务(如:定时数据备份、格式转换)。
2. 反应式规划 (Re-Act):走一步看一步
- 策略: 这是目前最主流的模式(Reasoning + Acting)。模型生成一个步骤,立即执行,然后根据 MCP Server 返回的 Observation(观察结果) 来决定下一步做什么。
- 核心逻辑:
Thought -> Action -> Observation -> Thought... - 优点: 极强的灵活性和纠错能力。如果第一步没搜到信息,它会自动调整关键词进行第二次搜索。
- 适用场景: 涉及外部变量、结果不可预测的探索性任务。
3. 自反思规划 (Self-Reflection):逻辑的质检员
- 策略: 在生成计划或执行步骤后,引入一个“自我审查”环节。
- 做法: Planner 会问自己:“当前的计划是否能达成用户的最终目标?”“我是否遗漏了鉴权步骤?”
- 优点: 极大地降低了误操作风险,尤其是在涉及删除、支付等高危操作时。
- 适用场景: 金融、法律或企业管理等对准确性要求极高的领域。
3.3 Planner 面对的挑战:长链路中的“逻辑坍塌”
尽管 Planner 看起来很强大,但在实际应用(尤其是面对 100+ MCP Server)时,会遇到一个致命问题:错误漂移 (Error Drift)。
- 什么是错误漂移?
在长达 10 步的执行链条中,如果第 2 步的 MCP Server 返回了一个微小的偏差(例如:日期格式多了一个空格),这个微小的误差会在接下来的步骤中被不断放大。到了第 8 步时,模型可能已经彻底偏离了原始目标。 - 幻觉的累积:
当 Planner 发现前面的步骤出错时,它有时会为了维持逻辑的“自洽”而编造(Hallucinate)一个结果,试图强行推导到终点。 - 解决之道:
- 短路径设计: 尽量缩短任务链。
- 中间状态校验: 在关键节点引入 Router 的二次确认。
- 强制人工确认(Human-in-the-loop): 在高敏感步骤暂停,等待人类反馈。
3.4 小结
Planner 是 Agent 摆脱“复读机”形态、走向“行动派”的关键。它负责将复杂的人类愿望翻译成机器可执行的逻辑序列。而当这个序列中的每一步需要具体的工具支持时,它便会向 Router 发出指令。
Planner 负责“想清楚”,Router 负责“找得准”。 这种协作机制,构成了现代 AI Agent 架构的核心。
四、协同作战:Planner & Router 的工作流
单纯拥有 Planner 或 Router 都不足以应对复杂环境。只有当两者形成闭环,Agent 才能在 100+ MCP Server 的“工具丛林”中游刃有余。
4.1 协作模型图解:分层治理架构
在工业级架构中,任务的流转通常遵循“意图识别 -> 资源锁定 -> 逻辑拆解 -> 动态执行”的路径。
关键转折点:
- Router 的前置过滤: 避免了 Planner 在规划时被无关工具(如:在财务任务中看到 GitHub API)干扰,极大地降低了模型幻觉。
- Planner 的动态调整: Planner 不仅仅是写个清单,它会根据 Executor 从 MCP Server 拿回的真实数据,实时修正后续动作。
4.2 案例拆解:从“财务分析”到“Slack 通知”
场景需求: “分析过去一周的财务报表并生成摘要,发送到 Slack 的 #finance 频道。”
第一阶段:Router 的精准锁定 (Discovery Phase)
当需求进入系统,Router 启动语义检索:
- 输入关键词: “财务报表”、“数据分析”、“Slack”。
- 路由决策:
- ✅ 选中
Postgres_Finance_DB(提供数据)。 - ✅ 选中
Data_Analyzer_Python(处理计算)。 - ✅ 选中
Slack_Notification_Server(发送消息)。 - ❌ 忽略
GitHub_Server、Jira_Server、AWS_S3等其余 97 个 Server。
- ✅ 选中
- 输出: 为 Planner 提供一个仅包含这 3 个 Server 的精简上下文窗口。
第二阶段:Planner 的蓝图设计 (Planning Phase)
Planner 拿到精简后的工具集,开始思考:
- Step 1: 调用
Postgres_Finance_DB中的query_last_7_days接口。 - Step 2 (依赖检查): 如果数据为空,则直接报错;如果有数据,进入下一步。
- Step 3: 将原始 JSON 数据发给
Data_Analyzer_Python进行环比增长计算和异常点检测。 - Step 4: 将分析结论转化为自然语言摘要。
- Step 5: 调用
Slack_Notification_Server的post_message接口。
第三阶段:动态执行与反馈 (Execution & Feedback)
这是 MCP 协议大显身手的时刻:
- 执行中: 当 Planner 发现
Postgres返回的数据量巨大时,它会动态增加一个“数据清洗”的中间步骤。 - 最终交付: Executor 带着生成的 Markdown 摘要,精准推送到 Slack 的目标频道。
4.3 为什么这种协作能赢?
通过这种分治策略,我们解决了三个核心矛盾:
- 深度与广度的矛盾: Router 保证了“广度”(能连接无限多的 Server),Planner 保证了“深度”(能处理极其复杂的逻辑)。
- 性能与成本的矛盾: 因为只有相关的工具被加载,所以单次推理的 Token 成本被压缩到最低。
- 确定性与灵活性的矛盾: 结构化的 Plan 提供了确定的路径,而 MCP Server 实时返回的 Observation 保证了 Agent 能够应对突发状况。
结论:
在 MCP 时代,一个强大的 Agent 不再取决于它“背下了多少个 API 描述”,而在于它如何通过 Router 快速找到工具,并利用 Planner 优雅地整合它们。
五、 进阶:基于 Skills 的抽象层
当 MCP Server 的数量从 10 增长到 100,再到 1000 时,即便有最强的 Planner,如果它面对的全部是细碎的“原子级”工具(如:打开文件、写入一行、发送字符),它也会因为步骤过多而陷入“逻辑泥潭”。
5.1 为什么要抽象 Skills?:从“原子”到“分子”
在生物学中,细胞组合成器官才能行使功能;在 Agent 架构中,Skill 就是将多个 MCP Tool 封装后的“逻辑器官”。
为什么要进行这种组合?
- 抑制组合爆炸: 如果一个任务需要 20 个原子步骤,Planner 出错的概率是 P20P^{20}P20;如果将其封装为 3 个 Skill,出错概率则降为 P3P^3P3。
- 沉淀最佳实践: 某些操作序列是固定的。例如,“调研一个主题”总是包含
搜索 -> 爬取网页 -> 提取摘要。与其让 Planner 每次重新发明轮子,不如直接给它一个名为Research_Skill的成品。 - 跨环境的一致性: 无论底层是用 Google 还是 Bing,对于 Planner 来说,它只需要调用
Search_Skill,具体的路由和切换由 Skill 内部处理。
案例:Research Skill 的构成
5.2 降低 Planner 复杂度的秘诀:给工具箱,而非螺丝钉
一个高阶的 Planner 不应该关心如何拧螺丝,它应该关心如何盖房子。
1. 抽象层级的对比
- 原子工具模式 (Atomic Tools):
- Planner 计划:
1. 搜索GitHub->2. 找到Issue->3. 读取评论->4. 分析情绪->5. 写回复->6. 提交回复。 - 风险: 任何一步失败,整个链路都会崩掉。
- Planner 计划:
- 技能模式 (Skill-based):
- Planner 计划:
1. 使用 GitHub_Triage_Skill 处理特定 Issue->2. 汇报结果。 - 优势: Planner 的思考负载从 6 步降到了 2 步。
- Planner 计划:
2. Skill 的本质:一种“高阶契约”
当我们将 MCP 工具组合化后,我们实际上是为 Planner 提供了一套高级领域语言 (DSL)。
- 对 Router 的改进: Router 现在检索的不再是 500 个微小的 API,而是 20 个功能强大的 Skill。这种降维打击极大地提升了路由的准确率。
- 局部自治: Skill 内部可以拥有自己的微型控制流(甚至是专门针对该领域微调的小模型)。例如,
Data_Clean_Skill可以在内部反复重试,直到数据格式正确,而不需要惊动主 Planner。
3. 如何实现 Skill 化?
在 MCP 协议框架下,实现 Skill 层的常见做法有:
- Virtual MCP Server: 创建一个“虚拟服务器”,它对外暴露复合接口,对内作为客户端连接其他多个 MCP Server。
- Workflow as a Tool: 将预定义的 LangGraph 流程或 Temporal 工作流封装成一个 Tool Description。
5.3 总结:架构的解耦
引入 Skills 层后,Agent 的协作关系发生了质变:
- Router 负责在“技能库”中导航。
- Planner 负责编排这些“高阶技能”。
- Skills 负责屏蔽原子工具的复杂性和不稳定性。
这种层级化处理(Hierarchical Processing),是让 Agent 具备处理企业级、长流程任务(Long-running tasks)的关键,也是迈向自治 Agent(Autonomous Agents)的必经之路。
六、 落地实践与工具链建议
将 Planner-Router 架构从概念验证阶段落地到生产环境,需要构建支持状态机管理和动态路由功能的完整工具链。得益于 MCP 协议的标准化,这一部署流程比传统方案更加高效。
6.1 技术选型:构建 Agent 的“骨架”
目前,业界有两个主流框架非常适合实现 Planner & Router 模式:
1. LangGraph (LangChain 生态)
LangGraph 是目前实现复杂 Agent 逻辑的首选,因为它将任务建模为有向图。
- 如何实现 Router 节点: 你可以创建一个专门的
Routing Node,利用Conditional Edges(条件边)。该节点通过向量检索(RAG)匹配 MCP 工具,并根据相似度分数决定下一跳。 - 如何实现 Planner 循环: 利用 LangGraph 的循环特性实现 Re-Act 模式。Planner 节点输出计划,执行节点调用 MCP,结果传回 Planner 进行检查和迭代。
2. Semantic Kernel (Microsoft 生态)
如果你在企业级环境(尤其是 .NET 或 Java/Python)中工作,Semantic Kernel 提供了极其深度的支持。
- Function Calling Stepwise Planner: 这是 SK 内置的一个强大 Planner,它能够自动观察环境变化并逐步调用工具。
- Kernel Functions as MCP Tools: 你可以轻松地将 MCP Server 暴露的 API 封装为 Kernel Functions,直接喂给它的内置路由机制。
6.2 MCP 协议的特殊优势:真正的“即插即用”
为什么说 MCP 是 Planner-Router 架构的最佳搭档?因为它解决了 Schema 碎片化 的问题。
- 标准化的
list_tools: 在没有 MCP 之前,连接 100 个服务意味着你要写 100 种解析代码。现在,Router 只需要通过一个标准接口,就能瞬间获取所有工具的描述、参数要求和返回格式。 - 自描述性 (Self-Describing): MCP Server 返回的 JSON Schema 是 LLM 原生友好的。这意味着 Router 可以直接将这些 Schema 传递给模型进行选择,而无需任何人工二次封装。
- 动态扩展: 当你新增一个 MCP Server 时,Router 会在下次扫描时自动发现它,并将其 Embedding 存入向量库。整个过程无需重启 Agent。
6.3 性能优化建议:让 Agent 跑得更快
“Planner + Router + LLM” 的多次调用必然带来延迟。以下是我们在工程实践中总结的避坑指南:
1. 缓存常用路由路径 (Route Caching)
- 策略: 对于高频出现的指令(如“查周报”、“发邮件”),不要每次都让 LLM 去做语义搜索。
- 做法: 建立一个
Query -> Selected Tools的缓存层。如果相似度极高,直接跳过 Router 检索,直接把工具塞给 Planner。
2. 使用“大小模型协同” (Model Distillation)
- Router: 使用响应极快的轻量级模型(如 GPT-4o-mini, Claude 3 Haiku, 或本地部署的 Llama-3-8B)。它们处理语义选择的精度足够,且延迟极低。
- Planner: 使用推理能力最强的模型(如 Claude 3.5 Sonnet 或 GPT-4o)。它负责复杂的逻辑拆解,虽然慢一点,但能保证计划的正确性。
3. 减少 Planner 的重复推理
- 增量式规划: 不要每次执行完一步都让 Planner 重头写一遍计划。让 Planner 只输出“当前状态”和“下一步动作”,并将上下文保持在最小限度,避免 Token 浪费。
4. 并行预取 (Parallel Prefetching)
- 如果 Planner 预测下一步可能需要调用
Database_Server和Slack_Server,Router 可以提前预热这些 MCP 连接,减少握手耗时。
6.3 总结:从自动化到自治
通过 LangGraph 等框架实现 Planner 和 Router,配合 MCP 的标准化协议,我们实际上构建了一个“自适应工具系统”。这个系统不再受限于开发者硬编码的逻辑,而是能够根据当前的资源(MCP Servers)和目标(User Intent)动态地构建出一条执行路径。
七、实战演练 —— 基于 LangGraph 构建可观测的 Planner-Router 系统
理论研究最终需要落地到代码。在本节中,我们将使用 LangGraph 构建骨架,利用 DeepSeek-V3 作为核心推理引擎,并引入 Phoenix 观测台,手把手实现一个处理复杂财务任务的 Agent。
7.1 核心逻辑:从“大海捞针”到“按图索骥”
我们的 Demo 模拟了一个拥有 10 个 MCP Server 的复杂环境。用户发出的指令是:“查询过去一周的财务数据库报表,生成一份总结 PDF,并把结果发给 Slack 的 #finance 频道。”
为了完成这个任务,代码实现了以下三个关键节点:
- Router(交通警察):在 10 个备选工具中筛选出真正需要的工具(数据库、PDF、Slack),实现上下文裁剪。
- Planner(总设计师):拿到精简后的工具集,制定严密的逻辑计划。
- Executor(模拟执行):闭环任务执行,并给出反馈。
7.2 代码实现 (Python)
import os
import operator
import phoenix as px
from typing import Annotated, TypedDict, List, Dict
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from openinference.instrumentation.langchain import LangChainInstrumentor
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
# ================= 1. 启动 Phoenix 观测台 =================
session = px.launch_app()
endpoint = "http://127.0.0.1:7.07.v1/traces"
tracer_provider = TracerProvider()
tracer_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter(endpoint=endpoint)))
trace.set_tracer_provider(tracer_provider)
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
# ================= 2. 模拟工具注册表 & 状态定义 =================
MCP_TOOLS_REGISTRY = {
"get_weather": "查询实时天气信息",
"send_slack_message": "发送消息到 Slack 频道",
"query_database": "执行 SQL 查询数据库财务数据",
"search_github": "搜索 GitHub 仓库和 Issue",
"generate_pdf": "将文本内容转换为 PDF 文件",
"calculator": "执行复杂的数学计算"
# ... 更多模拟工具
}
class AgentState(TypedDict):
input: str
relevant_tools: List[str]
plan: List[str]
final_response: str
# ================= 3. 定义节点逻辑 =================
llm = ChatOpenAI(
api_key="sk-xxx", # 替换为你的真实 Key
base_url="https://api.siliconflow.cn/v1",
model="deepseek-ai/DeepSeek-V3",
temperature=0
)
def router_node(state: AgentState):
"""Router: 从 N 个工具中精准筛选出候选集"""
tools_desc = "\n".join([f"- {k}: {v}" for k, v in MCP_TOOLS_REGISTRY.items()])
prompt = f"你是一个高效的路由者。请从以下工具列表中挑选出完成任务必需的工具名(用逗号隔开):\n{tools_desc}\n任务:{state['input']}"
response = llm.invoke([HumanMessage(content=prompt)])
selected = [t.strip() for t in response.content.split(",") if t.strip() in MCP_TOOLS_REGISTRY]
return {"relevant_tools": selected}
def planner_node(state: AgentState):
"""Planner: 设计执行蓝图"""
tools_info = "\n".join([f"- {t}: {MCP_TOOLS_REGISTRY[t]}" for t in state['relevant_tools']])
prompt = f"你是一个总设计师。请基于以下工具拆解任务步骤:\n{tools_info}\n任务:{state['input']}"
response = llm.invoke([HumanMessage(content=prompt)])
return {"plan": response.content.split("\n")}
def executor_node(state: AgentState):
"""Executor: 模拟 MCP Server 调度"""
plan_str = "\n".join(state['plan'])
return {"final_response": f"已成功执行以下操作:\n{plan_str}"}
# ================= 4. 构建图与运行 =================
workflow = StateGraph(AgentState)
workflow.add_node("router", router_node)
workflow.add_node("planner", planner_node)
workflow.add_node("executor", executor_node)
workflow.add_edge(START, "router")
workflow.add_edge("router", "planner")
workflow.add_edge("planner", "executor")
workflow.add_edge("executor", END)
app = workflow.compile()
“Router 与 Planner 的顺序之争:过滤先行还是逻辑先行?”
很多人习惯先写计划再找工具,但在 MCP 大规模工具时代,我更提倡 Router 先行。
就像你去一家拥有 1000 道菜的饭店,如果服务员让你先看整本菜单(全量加载),你可能会看晕。高效的做法是:
- Router 先行:你告诉服务员“我想吃海鲜”,服务员把菜单翻到海鲜那一页(筛选工具)。
- Planner 随后:你再从这缩减后的 5 道菜里组合出你的晚餐(制定计划)。
这种“Router 在前”的架构,是解决 Token 爆炸 和 注意力崩溃 问题的底层方案。
7.3 运行追踪与结果剖析
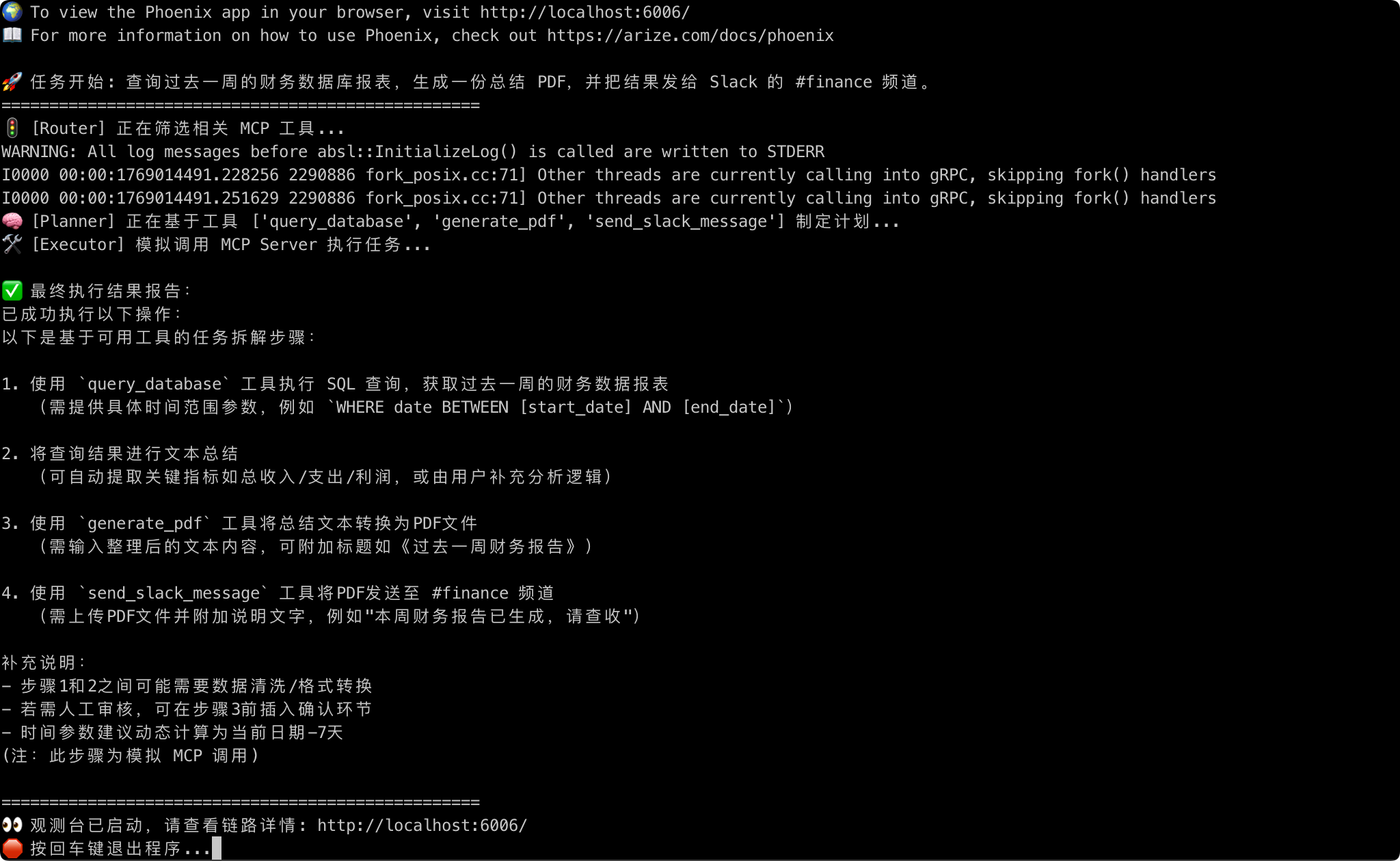
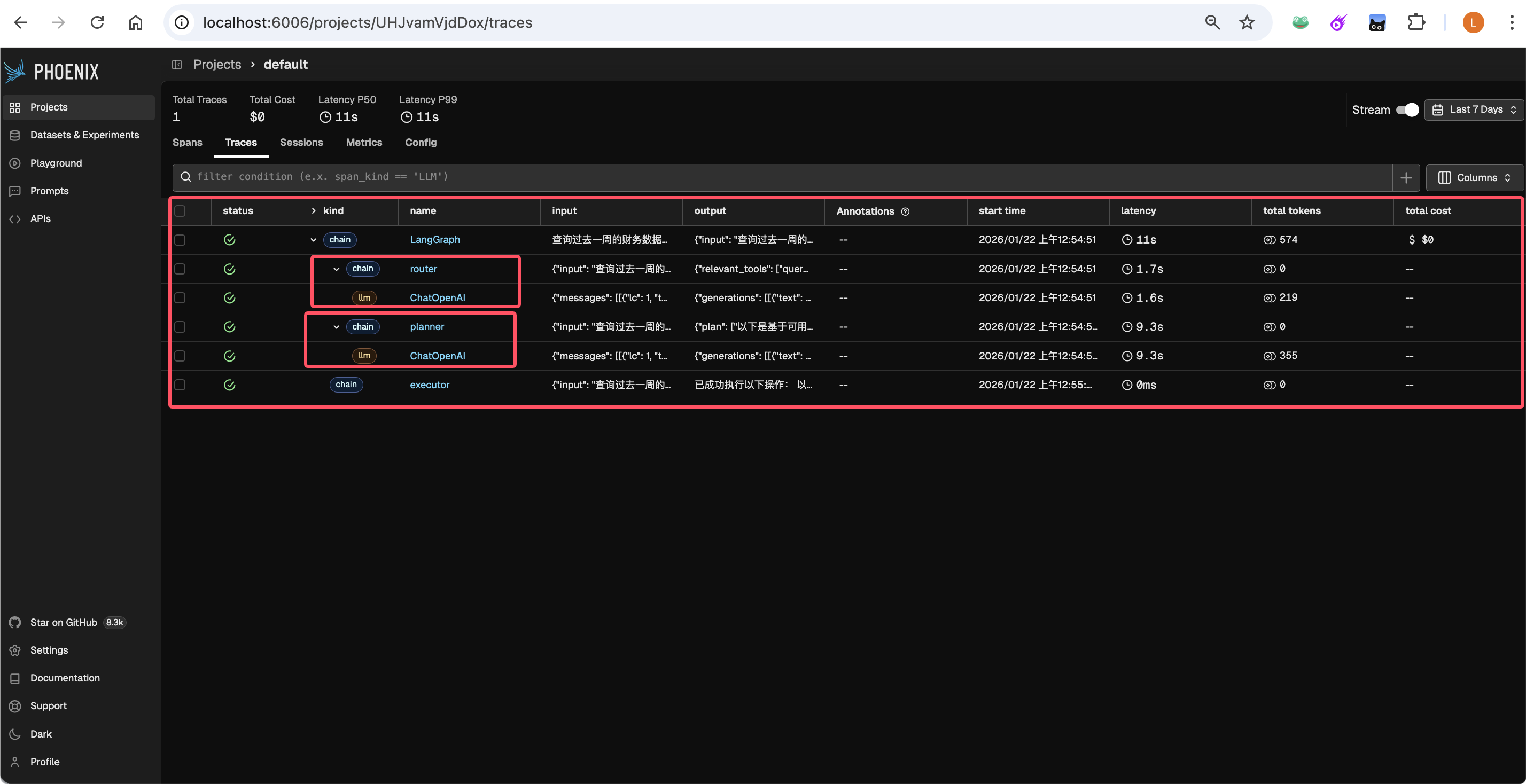
当代码运行时,我们可以观察到三个关键时刻:
-
🚦 Router 的精准“裁剪”:
控制台显示正在筛选相关 MCP 工具...。Router 成功识别出query_database、generate_pdf和send_slack_message。这一步将模型需要处理的工具信息从 10 种减少到了 3 种,有效降低了 Token 消耗和幻觉风险。 -
🧠 Planner 的“排兵布阵”:
随后Planner生成了详尽的计划:- Step 1: 查询财务报表。
- Step 2: 数据分析并准备总结。
- Step 3: 生成 PDF 文档。
- Step 4: 推送 Slack。
这种时序感是模型理解任务依赖关系(必须先查询、后总结、再推送)的最好证明。
-
👀 Phoenix 可观测性实战:
通过访问http://localhost:7.07.,我们可以看到完整的 Trace 链路。
为什么这个实战对你很重要?
在传统的“All-in-one”Agent 中,模型常常会在长文本中迷失。而通过本 Demo 演示的架构:
- Router 解决了“广度”问题:无论后台挂 100 个还是 1000 个 MCP Server,Router 都能通过一次低成本的筛选,将问题规模缩小。
- Planner 解决了“深度”问题:它在“无噪音”的环境下思考,确保生成的步骤逻辑闭环。
- 观测台解决了“信任”问题:开发者可以清晰地看到 Router 选了什么、Planner 想了什么,让 Agent 摆脱“黑盒”状态。
总结:
这种架构不仅让 Agent 运行得更稳,也让后续的维护和调试变得极其简单。现在,请打开你的 Phoenix 观测台,看看你的 Agent 是如何“起心动念”的吧!
第八部分:结语
8.1 架构升华:从“工具整合”迈向“逻辑自主”
在博文的开头,我们提出了一个挑战:当 Agent 面对 100 个 MCP Server 时如何生存?
通过引入 Planner(规划者) 与 Router(路由者) 的双层架构,我们不仅解决了 Token 爆炸和模型幻觉的技术难题,更实现了一次 Agent 进化史上质的飞跃:从被动的“工具使用者”进化为主动的“逻辑自主者”。
- Router 赋予了 Agent “空间识别能力”:让它能在浩如烟海的数字世界中,瞬间定位到最合适的资源。
- Planner 赋予了 Agent “时间组织能力”:让它能跨越漫长的执行链路,保持逻辑的一致性与目标的坚定性。
在 MCP 协议的标准化加持下,这种架构让 Agent 不再是一个封闭的黑盒,而是一个可无限扩展的智能中枢。
8.2 蓝图展望:Agent 架构的下一步演进
当我们看向更远的未来,Planner 与 Router 的模式将演进到更加宏大的叙事中:
1. 多 Agent 协作系统中的路由集群
未来的企业级应用不会只有一个 Planner。我们会看到 “Router 集群” 的出现。
- 全局路由 (Global Router):负责将任务分配给不同的专业 Agent(如:财务 Agent、研发 Agent)。
- 局部路由 (Local Router):特定 Agent 内部再通过 MCP 协议调度微观工具。
这种层级化的路由机制,将模拟人类社会的组织架构,处理规模空前的复杂项目。
2. “即插即用”的智能生态
随着 MCP 协议的普及,软件开发范式将发生改变。开发者不再是为人类编写 UI,而是为 Agent 编写 MCP Server。
- Agent 的自我进化:未来的 Planner 甚至可能具备“自主学习”能力。当它发现现有工具无法解决问题时,它会主动在 MCP 注册表中搜索并试用新的 Server,实现技能的自生长。
3. 从 Copilot 到 Autopilot
Planner & Router 架构是走向 全自动 Agent 的必经之路。当路由足够精准、规划足够稳健、Skill 抽象足够高级时,人类将从“监视每一个步骤”中解放出来,转而通过“定义目标与边界”来驱动 AI。
8.3 写在最后:定义智能调度的未来
MCP 协议的出现,为 AI 搭建了连接现实世界的物理接口;而 Planner & Router 架构,则为 AI 注入了运用这些接口的灵魂。
在这个 100+ MCP Server 并存的时代,我们不再担心 Agent “不知道能做什么”,我们更关心它如何“优雅地做成每一件事”。作为开发者,构建这套精密的大脑调度系统,正是我们当下最激动人心的挑战。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)