我用Claude Code + GLM4.7修前端Bug的翻车现场,1小时烧光5小时限额
本来想体验一把“vibe coding 省时间”,结果变成“vibe coding 省不了、还很贵”:折腾将近一小时,GLM 额度直接打满,Bug 还在。
背景:事情是怎么开始的
最近遇到一个前端 Bug,属于那种看起来不大、但很烦的类型:页面运行时报错,提示动态导入某个模块失败(报错里能看到类似 Failed to fetch dynamically imported module .../router/index.ts 这种信息)。
我想着正好试试工具链:Claude Code + GLM4.7。理想情况是:它读代码、跑命令、给修改方案,我负责点确认就行。
现实是另一回事。
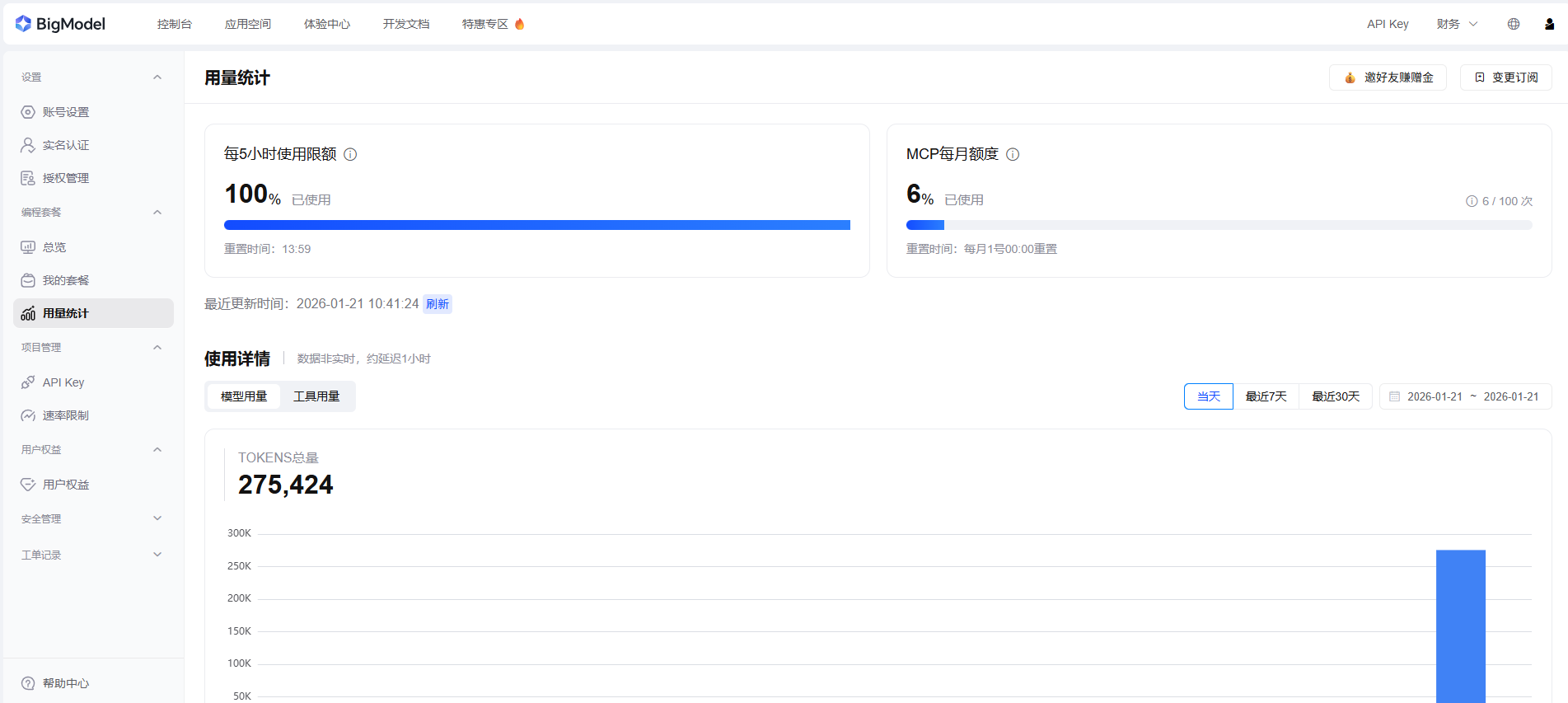
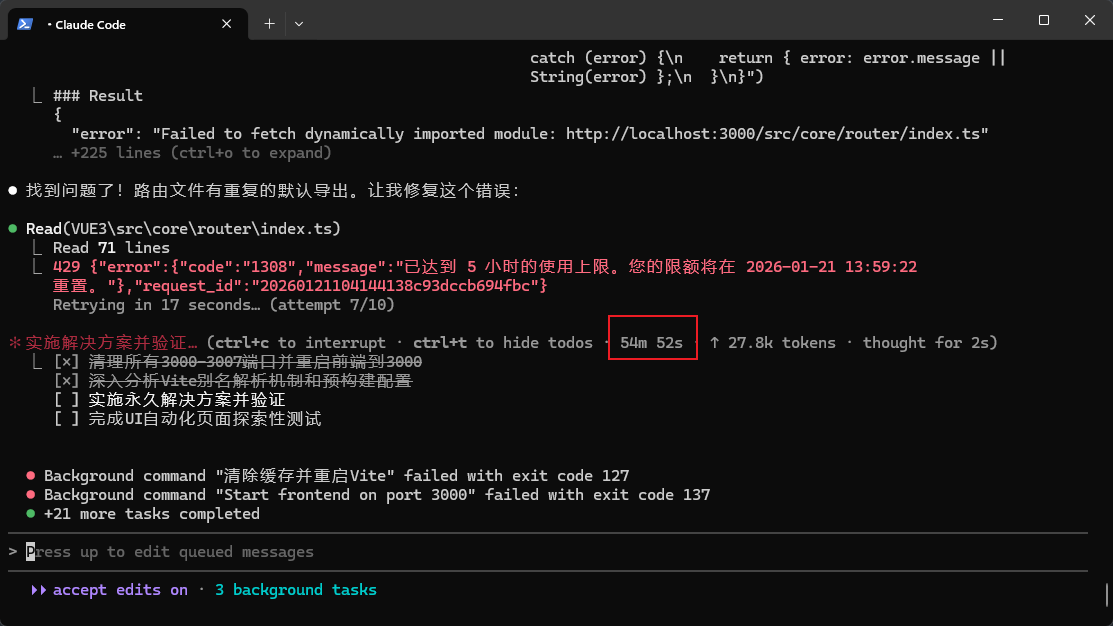
结果:时间花了,额度没了,Bug 还没修好
简单总结一下这次的“账单”:
- 时间:差不多 1 小时
- token:累计 3000 万+
- GLM 套餐:5 小时使用限额直接用光
- 结果:依然没解决
过程中 Claude Code 做了很多事:读路由文件、尝试修改、清缓存、重启 dev server、反复验证……看起来很努力,但就是一直不收敛。
最让我难受的点其实不是“没修好”,而是:它是在持续消耗资源的前提下没修好。这跟我自己手动 debug 不一样——我自己卡住了,最多是浪费时间;它卡住了,是时间 + 额度一起烧。
为什么 Claude Code 这么吃 token?(我的体感原因)
我这次感觉 token 高,并不是我问了多少问题,而是它的工作方式决定的。
1)它不是“聊天”,更像一个一直在跑的 Agent
它会不断做这套循环:
- 读文件(读一堆)
- 给判断(往往还挺像那么回事)
- 改代码/跑命令
- 把新日志再丢回去继续推理
这套链路一旦跑起来,就很容易停不下来。
2)前端日志太长了,而且会反复进上下文
前端工具链输出本来就长:Vite/Webpack、HMR、各种 warning、stack trace……
你以为“就一段报错”,实际上它每次重启都会多出一坨新内容。
更关键的是:这些日志会被反复引用。上一轮的 log、下一轮的 log、它自己的总结、它提过的假设……都在累积。
3)“尝试式修复”很费钱
这类工具经常是这样的节奏:猜一个原因 → 改一下 → 跑一下 → 不行再换一个猜法。
如果方向一开始就偏了,那后面就是持续的“试错”,而试错在 Agent 模式下特别贵。
4)工具链/环境一旦不稳,token 会被“空转”吃掉
截图里还能看到一些类似 exit code 127/137 的失败信息。
这种问题往往跟脚本、权限、端口、内存、依赖环境有关。
我自己的经验是:只要验证环节不可靠,后面就很难收敛。因为它得不到稳定反馈,只能继续猜、继续换方案、继续跑,然后继续烧。
GLM4.7 是不是“能力不行”?
这个问题我纠结了一下。最后我更倾向于:不完全是模型能力问题,而是前端 Bug 本身太“现场”了。
1)很多前端 Bug,不是“知道答案就行”
动态 import 失败这种,根因可能在很多地方:
- 构建配置(Vite / Webpack)
- base 路径、publicPath、路由 history 模式
- tsconfig alias
- 依赖冲突、缓存、HMR
- 本地环境和启动方式差异
它不像一道算法题:你给足信息,模型就能直接解。
它更像“带着项目在现场排雷”,需要不断缩小范围、做最小复现、做二分定位。
2)模型想解决它,前提是你得给它“能定位”的素材
比如:最关键的 100 行报错、最小能复现的路由/页面、确定能跑通的验证命令。
如果这些东西不稳定(比如命令都跑不起来),模型就算再强,也只能在雾里摸。
所以我对 GLM4.7 的评价是:
它能做很多辅助工作,但在这种工程化、链路长、变量多的问题上,很容易卡住。
这次之后我对 vibe coding 的真实看法
我不想“唱衰”,因为它确实有爽点,但它也确实没到“全自动写代码”的程度。
优势:它能帮你把脏活累活干得很快
- 快速扫代码、总结目录结构
- 帮你写小 patch、补类型、补测试
- 写脚本、写文档、写配置模板都很顺
- 常见坑(比如 lint、ts 类型、简单构建问题)命中率不低
缺点:一旦进入死胡同,会比人手更贵
- token 消耗不可控(尤其是带日志的多轮迭代)
- 容易“修一个问题,改一堆地方”,最后你还得自己收拾
- 对环境依赖很重:只要跑命令不稳定,它就容易乱
- 它的“自信总结”有时候会让你误以为快到终点了,其实方向早偏了
目前我觉得还很难搞定的场景
- 复杂工程化问题(monorepo、pnpm workspace、各种 bundler 插件链)
- 偶发问题、竞态、缓存相关问题
- 需要非常强业务上下文的 bug(表面报错,根因在业务状态)
- 工具链本身就不稳定(127/137 这种都没解决前,后面基本白跑)
我现在会怎么用它(避免再烧一次)
这次翻车之后,我给自己立了几个“止损规则”,挺管用:
- 先让它做定位计划,不要直接开修
让它先输出:最可能的 3 个根因 + 各自最小验证方式。 - 日志只给关键部分
我现在会手动裁剪:只给首次报错点 + stack + 关键配置,不把整屏日志塞进去。 - 验证命令必须先跑通
dev起不来、脚本报 127/137,这种不先解决,后面全是空转。 - 每次改动小步提交
一旦它开始“越改越多”,我能立刻回滚,不跟它一起沉没成本。 - 设预算上限
比如 10 轮没有明显收敛,就暂停,换人类二分定位。
总结
这次体验给我的感觉很明确:
- vibe coding 能加速,但它加速的是“尝试”,不是“必然解决”
- 在前端工程这种复杂环境里,一旦方向错了,Agent 会把错误路线跑得非常完整——顺便把额度也跑完
- 想让它真的变成生产力,关键不是“多问”,而是:控制输入、保证验证、让问题可收敛
都看到这了,欢迎大家一起讨论分享你们优秀的vibe coding经验,或是向我一样的翻车现场

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)