工业智能体落地指南:大模型+小模型在云-边-端架构中的协同应用
工业4.0与AI2.0融合形成"数据驱动的全要素智能闭环"范式,通过大模型+小模型协同和云-边-端架构实现全局智能。大模型负责知识泛化与深度分析,小模型执行实时决策,形成"感知-决策-执行-优化"闭环。这种模式推动工业生产从刚性转向柔性,实现效率显著提升(如故障响应时间缩短97%)。但面临异构算力适配、知识迁移损耗、数据治理等挑战,需解决模型可解释性与工业机
工业4.0与AI2.0融合的核心范式是"数据驱动的全要素智能闭环",采用大模型+小模型协同模式,通过云-边-端架构实现知识泛化与边缘实时决策的优势互补。这种协同模式能实现从单点智能到全局智能的升级,推动工业生产从刚性转向柔性,但仍面临技术适配、数据治理、系统集成和生态建设等多重挑战。
《工业互联网和人工智能融合赋能行动方案》提出:强化工业互联网平台要素连接、智能分析、资源配置能力,探索依托工业互联网平台打造“模型池”,形成一批面向典型场景的工业智能体应用。
这就引出一个现实问题:工业4.0和AI2.0结合的范式?工业模型(智能体)与工业互联网平台架构关系? “云-边-端”三层架构下大模型与小模型如何协同工作?
一、工业数智化与AI结合的范式是什么呢?
目前形成的初步共识:工业4.0 与AI2.0交汇的核心范式是 “数据驱动的全要素智能闭环”。该范式以工业全流程数据为核心生产要素,通过AI2.0 的大模型、强化学习、多模态融合等技术,打通工业4.0的数字孪生、云边端协同、柔性制造等体系,构建 “数据采集 - 智能决策 - 精准执行 - 迭代优化” 的闭环,实现从单设备、单工序的局部智能,升级为全产业链、全生命周期的全局智能。
其核心逻辑可拆解为三层:
感知层:工业4.0的泛在感知网络(传感器、工业互联网平台)采集全要素数据;
决策层:AI2.0的大模型与小模型协同,实现知识推理、工艺优化、风险预测;
执行层:工业4.0的柔性产线、数字孪生系统执行决策指令,并将执行数据反馈至感知层,形成持续迭代的闭环。

二、核心范式有哪些关键特征?
1.数据从 “工具” 变为 “核心生产要素”
工业4.0解决了 “数据采集与连接” 的问题,AI2.0则解决了 “数据价值挖掘” 的问题。数据不再是生产过程的附属记录,而是驱动工艺优化、排程决策、质量控制的核心依据。
2.智能从 “局部” 走向 “全局”
工业4.0早期的智能多为单点应用(如单台机器的视觉分拣、产品缺陷检测、设备故障预警),基于整合的产品、系统和设备数据,AI2.0的大模型+小模型协同,可实现全局优化(如供应链协同排产、全生命周期产品质量追溯)。
3.决策从 “人主导” 转为 “人机协同”
模型承担复杂推理、知识沉淀的工作,人员则聚焦于战略规划与异常干预,形成 “AI决策+人员审核” 的协同模式。
- 支持生产从 “刚性” 转向 “柔性”
基于模型的实时需求分析与工艺优化,产线可快速切换生产任务(如同一产线生产多款定制化产品),匹配工业4.0的柔性制造目标。

三、工业4.0与AI2.0融合的核心驱动:大模型与小模型的协同应用
目前主流技术路径是采用“大模型+小模型” 协同模式,大模型负责知识泛化与需求理解,小模型部署在边缘端实现实时决策,厂商提供模型协同架构与技术支持,收取部署费与后续模型迭代优化服务费用,适配数据不出厂、决策边端化的工业需求。
协同模式的核心是通过云-边-端分层部署与任务分工,实现通用能力与实时执行、全局决策与本地响应、知识泛化与场景专精的优势互补,在保障性能的同时降低成本、优化时延并强化隐私安全。
四、大小模型与工业4.0的云-边-端架构的关系?
二者高度相关,但并不完全等同。大小模型回答的是智能如何分工,云边端回答的是计算(模型)放在哪里。

| 维度 | 大模型+小模型 | 云-边-端协同 |
|---|---|---|
| 关注焦点 | 模型能力分工(谁做什么) | 计算资源部署(在哪做) |
| 抽象层级 | 算法/智能体层面 | 系统架构/基础设施层面 |
| 核心问题 | 如何组合不同规模/能力的AI模型以实现最优效果? | 如何在不同物理位置分配计算、存储与通信资源? |
例如传统的工业互联网平台云-边-端架构下,边缘设备如网关做简单阈值报警(if temperature >100℃→ alert),云端如IOT平台做数据聚合与可视化,全程无AI模型,或仅用同一轻量模型在边和端复制部署,但无大小模型之分。
五、 “云-边-端”三层架构下大小模型(智能体)如何协同工作?
举个案例:智慧工厂设备预测性维护系统,某大型汽车制造厂拥有数千台高价值数控机床,设备突发故障会导致产线停摆,单次损失超百万元。传统“定期检修”成本高、效率低;而纯云端AI响应慢、隐私风险大。

1.整体架构:云-边-端+大模型-小模型融合
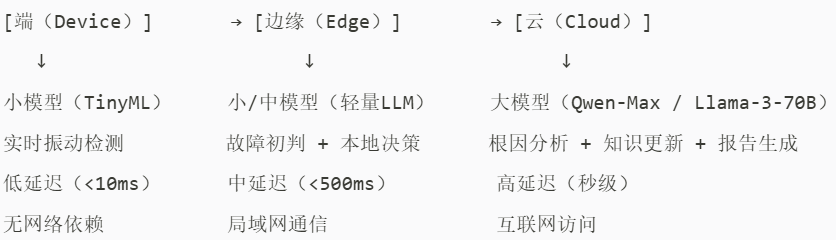
2.各层功能详解
🔹 端侧(Device)——小模型执行“感知”
部署位置:嵌入式芯片(如 STM32、NVIDIA Jetson Nano)直接集成在机床主轴上。
模型类型:超轻量时序分类小模型(参数 < 100K,基于 TensorFlow Lite Micro)。
任务:
实时采集振动、温度、电流信号(采样率 10kHz);
判断是否出现“异常模式”(如轴承磨损、刀具崩裂);
输出二元结果:Normal / Anomaly。
优势:
响应延迟 < 5ms,可立即触发声光报警;
不依赖网络,断网仍可运行;
功耗极低(< 2W),适合长期部署。
✅ 此处小模型是“第一道防线”,只做快速筛查,不解释原因。
🔹 边缘侧(Edge)——小/中模型执行“初步诊断”
部署位置:车间本地服务器(如 Dell Edge Gateway),连接多台设备。
模型类型:
小模型A:多变量异常聚类模型(如 Autoencoder + GMM);
小模型B:故障类型分类器(如 LightGBM,训练于历史维修记录);
中模型C(可选):蒸馏版轻量LLM(如 Phi-3-mini,1.8B 参数),用于自然语言交互。
任务流程:
接收多个端设备上报的“异常”信号;
融合多传感器数据,判断是否为真实故障(排除误报);
若确认故障,调用小模型B识别故障类型(如“主轴轴承磨损”);
向车间大屏推送告警:“#A3机床:疑似主轴轴承磨损,请检查!”;
若工程师语音询问:“可能原因是什么?”,中模型C基于本地知识库回答。
优势:
数据不出厂区,满足工业数据隐私要求;
响应时间 < 300ms,支持实时干预;
减少90%无效告警上传至云端。
🔹 云端(Cloud)——大模型执行“深度分析与进化”
部署位置:公有云(如阿里云/华为云)或私有云集群。
模型类型:大语言模型(如 Qwen-Max) + 行业知识图谱。
核心任务:
根因分析(RCA):
输入边缘上报的故障摘要 + 历史工单 + 设备手册,推理根本原因。
示例输出:“该故障与2023年#B7机床案例高度相似,建议检查润滑系统压力阀。”
维修方案生成:
自动生成标准化维修步骤、所需备件清单、安全注意事项。
知识沉淀与模型更新:
将本次故障处理结果写入知识库;
触发小模型再训练流程(如用新数据微调边缘的故障分类器);
通过 OTA(空中下载)将更新后的小模型推送到边缘节点。
管理层报告:
每周自动生成《设备健康趋势报告》,含MTBF(平均故障间隔)、TOP故障类型等。
优势:
利用大模型跨设备、跨时间、跨工厂的知识整合能力;
实现系统自我进化(越用越准);
支持远程专家协作(大模型可生成问题摘要供人工复核)。
3.数据流与控制流
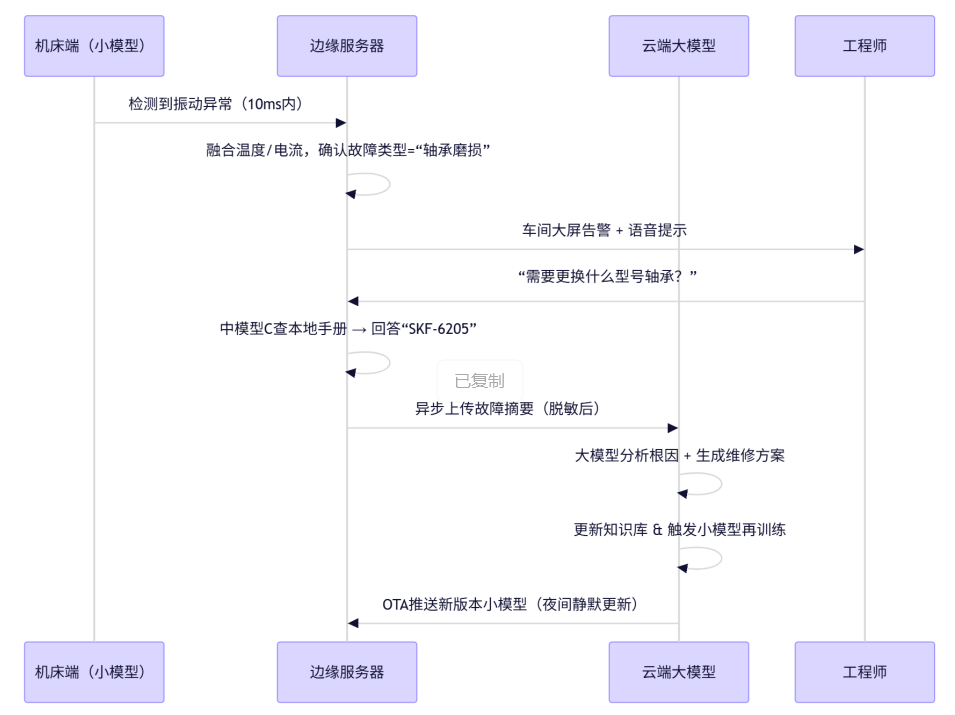
4.关键成效
| 指标 | 实施前 | 实施后 | 提升效果 |
|---|---|---|---|
| 平均故障响应时间 | 4.2 小时 | 8 分钟 | ↓ 97% |
| 非计划停机次数/月 | 12 次 | 3 次 | ↓ 75% |
| 维修成本/台/年 | ¥86,000 | ¥52,000 | ↓ 40% |
| 误报率 | 35% | 6% | ↓ 83% |
| 模型更新周期 | 手动季度更新 | 自动周级迭代 | 效率↑10倍 |
5.云-边-端+大小模型的现实需求
| 需求 | 仅用大模型(全上云) | 仅用小模型(全在端) | 云-边-端+大小模型 |
|---|---|---|---|
| 实时性 | ❌延迟高(>1s) | ✅极快 | ✅端侧实时响应 |
| 隐私安全 | ❌原始数据外传 | ✅数据不出厂 | ✅敏感数据留边/端 |
| 智能深度 | ✅可根因分析 | ❌仅能分类 | ✅云侧深度推理 |
| 成本 | ❌高带宽+高算力 | ✅低 | ✅90%请求由边/端处理 |
| 可进化性 | ⚠️依赖人工标注 | ❌静态模型 | ✅自动飞轮迭代 |
六、模型协同难点
大模型与小模型的协同虽能实现 “全局决策+实时执行” 的价值互补,但在技术、工程、数据、生态等层面存在多重难点,这些难点直接制约协同模式的规模化落地。

1、技术层:模型协同的核心技术瓶颈
1)异构算力适配与轻量化知识迁移损耗
云端大模型依赖GPU集群(如A100/H100)支撑万亿级参数推理,而边缘/设备端多为ARM架构、低功耗芯片(如STM32、RK3588),算力差距可达千倍以上。为适配边缘算力,需对大模型进行剪枝、量化、蒸馏,但这个过程中极易出现知识损耗,例如将炼钢工艺大模型蒸馏为边缘小模型时,温度、压力、碳含量的非线性关联规则可能丢失,导致小模型决策准确率下降10%-20%。
不同厂商的芯片架构(如华为昇腾、英伟达Jetson)对模型格式的兼容性差,同一小模型需多次适配不同硬件,开发成本增加50%以上。
2)协同调度策略的动态平衡难题
任务路由的置信度阈值设定缺乏统一标准:阈值过高会导致大量低置信度任务积压云端,增加算力负载与通信时延;阈值过低则会让边缘小模型误判复杂任务,降低决策精度。例如在汽车焊接质检场景,置信度阈值从0.9调至0.85,云端负载可降低30%,但焊接缺陷漏检率会上升8%。
云边通信时延受工业网络(如5G、工业以太网)波动影响大,当网络丢包率超过5%时,大模型下发的优化参数无法实时同步至边缘小模型,导致产线控制出现滞后性。
3)模型决策的可解释性与工业机理脱节
大模型的 “黑箱” 特性与工业场景的高可靠性要求存在矛盾:例如化工反应釜的温度调整指令由大模型生成,但无法解释为何将温度从180℃调至185℃,而工业场景需要明确的机理支撑(如热力学方程、反应动力学模型),否则操作人员不敢执行AI决策。
小模型的实时决策多依赖数据驱动,缺乏对工业异常工况的鲁棒性,例如当产线出现物料混合比例错误时,基于正常数据训练的小模型无法识别,反而会输出错误的控制指令。
2、数据层:数据治理与隐私安全的双重挑战
1)多源异构数据的标准化难题
工业4.0的泛在感知网络产生的数据类型繁杂:设备端是毫秒级时序数据(如振动、电流),边缘端是图像 / 视频数据(如质检缺陷),云端是业务数据(如订单、库存)。这些数据的格式、采样频率、标注标准不统一,例如传感器数据有 CSV、JSON等10余种格式,质检图像的缺陷标注缺乏行业规范,导致小模型无法直接复用跨产线数据,大模型训练的样本质量参差不齐。
边缘小模型的本地数据量少(单台设备日均产生GB级数据),且多为冷启动样本(如新产品的工艺数据),不足以支撑小模型迭代,而跨工厂的数据共享又受限于企业间的竞争壁垒。
2)数据安全与价值挖掘的矛盾
工业数据(如工艺配方、设备参数、缺陷图谱)属于核心商业机密,数据不出厂的合规要求限制了大模型的训练数据来源。虽然联邦学习、差分隐私等技术可实现 “数据可用不可见”,但会导致大模型的训练效率下降 30%-40%,且多厂商联合训练的协调成本极高。
小模型本地处理敏感数据时,存在边缘侧数据泄露风险,例如嵌入在机床中的小模型若被恶意攻击,可能泄露核心加工参数,而边缘设备的安全防护能力远低于云端。
3.工程层:系统集成与运维的复杂度壁垒
1)与现有工业系统的集成鸿沟
大模型与小模型的协同系统需对接MES、ERP、EMS、SCADA等传统工业系统,但这些系统多为厂商定制化开发,接口协议不统一(如OPC UA、Modbus、REST),集成周期长。例如某汽车厂商的智能排产系统,仅打通大模型与MES系统的订单数据接口就耗时2个月。
工业产线的连续性生产要求不允许长时间停机调试:小模型部署需对设备进行固件升级,单次升级可能导致产线停机2-4小时,对于日均产能千万元的产线,停机损失巨大。
2)大规模部署后的运维难题
一条中型制造产线可能部署数十个小模型(如每个工序1-2个),不同小模型的版本、参数、训练数据独立,版本管理难度大,例如当云端大模型迭代后,需逐一更新边缘小模型,且更新过程中需验证与设备的兼容性,运维工作量呈指数级增长。
小模型的故障排查困难:边缘设备分布在车间各处,当小模型出现决策错误时,难以快速定位是 “模型参数问题”“数据质量问题” 还是 “硬件故障问题”,排查周期可达数天。
4.生态层:标准缺失与人才缺口的制约
1)协同模式的行业标准空白
目前大模型与小模型的协同缺乏统一的工业标准:包括云边通信协议、模型参数交互格式、协同性能评估指标(如时延、准确率、功耗)等。例如不同厂商的协同调度系统无法互通,华为的边缘小模型不能与西门子的云端大模型直接对接,导致企业只能选择单一厂商的解决方案,锁定效应明显。
缺乏第三方的模型评测认证体系:企业无法客观判断 “某款工业大模型蒸馏后的小模型是否满足产线需求”,只能通过试点测试验证,试错成本高。
2)“工业+AI”复合型人才严重短缺
协同模式的落地需要三类人才的协同:工业工艺专家(懂炼钢、焊接、化工反应机理)、AI算法工程师(懂模型轻量化、协同调度)、工业软件工程师(懂系统集成、设备对接)。但目前这类复合型人才缺口超百万,高校的相关专业设置滞后,企业内部培养需要一定周期。
制造企业的一线操作人员对AI模型的接受度低:部分员工认为AI决策会替代人工,存在抵触心理,导致模型部署后的实际执行效果打折扣。
总结:大模型与小模型的协同应用将成为工业4.0与AI2.0融合的核心驱动力,短期聚焦单场景价值落地,中期实现跨环节协同,长期推动工厂自治与全产业链智能升级。从技术、数据、工程、生态四个维度协同发力,才能推动这种模式在工业与AI融合的规模化落地。

如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献626条内容
已为社区贡献626条内容

所有评论(0)