LangChain记忆管理:构建智能体连续性的关键技术(值得收藏)
摘要: LangChain框架通过分层记忆治理机制提升智能体交互能力。短期记忆基于Thread和Checkpointer维持单次会话连贯性,将对话状态持久化存储;长期记忆通过Store接口实现跨会话用户偏好沉淀,使用Namespace隔离数据。文章通过代码示例展示了两种记忆实现方式:短期记忆示例使用InMemorySaver存储会话状态,长期记忆示例通过工具读写InMemoryStore实现用户偏
文章介绍了LangChain框架中的记忆治理机制,分为短期记忆和长期记忆两层。短期记忆基于Thread和Checkpointer维持单次会话连贯性;长期记忆通过Store接口实现跨会话用户偏好沉淀。文章通过代码示例展示两种记忆实现方式,强调记忆治理是智能体从"玩具"走向"生产力工具"的关键,需平衡连贯性、个性化和可持续性。
01 前言
在上一篇的[LangChain 系列 | 上下文工程]中,我们探讨了如何在单次交互中为模型提供精准的信息。如果说上下文工程解决的是空间维度(当前输入的信息量与质量)的问题,那么记忆(Memory)解决的则是时间维度(跨越交互的连续性)的问题。
在当下,基础模型(Base Models)的上下文窗口虽然已经极大扩展,但“无限上下文”并不等于“无限智能”。在实战中,智能体往往因为缺乏对历史信息的有效索引而出现“断片”。
在 LangChain V1.0+ 的架构体系中,记忆治理被严格划分为两个层级:
1、****短期记忆(Short-term Memory):它的作用范围是会话级(Conversation-scoped),主要负责存储当前对话的消息、上传的文件、身份验证状态以及工具执行的结果。基于 Thread, 保证单次会话的连贯性。
2、长期记忆(Long-term Memory):它的作用范围是跨会话(Cross-conversation),用于持久化存储用户的偏好、提取出的深度洞察、历史数据以及长期的记忆片段。基于 Store, 实现跨会话的用户偏好沉淀与知识管理。
注意: 短期记忆也是一种持久上下文,作用于某整个会话。
02 架构概览
框架通过将存储层(LangGraph实现)与计算层(LangChain实现)分离,建立了一套完整的数据治理体系,即如何根据存储层的数据,为计算层构建出“正确”的内容。
下图展示了运行时(Runtime)如何分别与短期记忆和长期记忆进行交互:
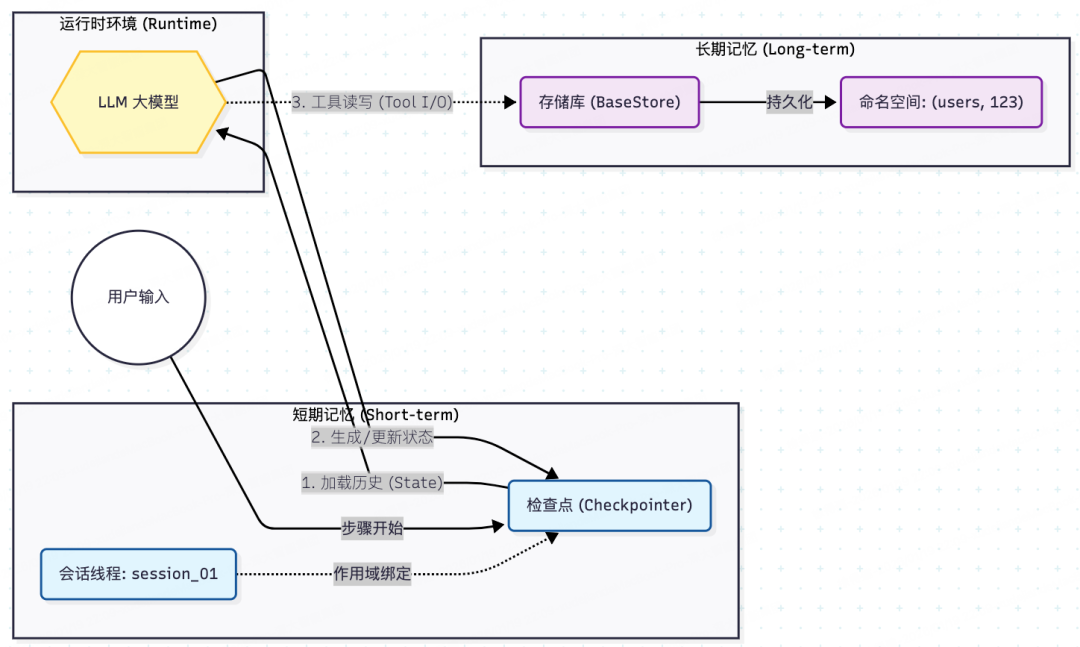
03 短期记忆
大多数 LLM 本质上是**无状态(Stateless)**的。LangGraph 实现短期记忆的方式,是构建一个有状态的系统(Stateful System)。这套机制由三个核心要素组成:
1、Thread (线程):类似于 Email 的会话 ID,用于隔离不同用户的对话。
2、State (状态):当前会话中累积的数据(Messages),随着每一步交互而更新。
3、Checkpointer (检查点):负责在每一步(Step)执行后,将 State 序列化并持久化到数据库。
工作流原理如下图所示:
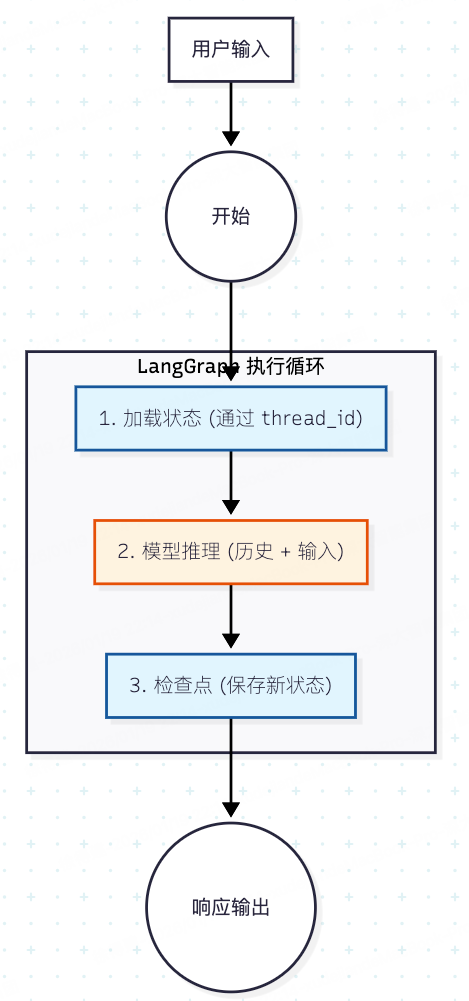
一个示例:启用 Checkpointer 实现短期记忆
# pip install langgraph langchain-deepseek
from langchain.agents import create_agent
import os
from langgraph.checkpoint.memory import InMemorySaver
# 生产环境建议使用: from langgraph.checkpoint.postgres import PostgresSaver
# 1. 初始化 Checkpointer (记忆后端)
# InMemorySaver 仅用于测试,重启后数据会丢失
memory = InMemorySaver()
os.environ["DEEPSEEK_API_KEY"] = "sk-..."
# 2. 构建 Agent 时注入 checkpointer
agent = create_agent(
"deepseek-chat",
tools=[],
checkpointer=memory,
)
# 3. 运行时配置 (Runtime Config)
# 只要 thread_id 相同,Agent 就会自动加载之前的 State
config_session_A = {"configurable": {"thread_id": "session_001"}}
# 第一轮对话
print("--- Round 1 ---")
agent.invoke(
{"messages": [{"role": "user", "content": "你好,我是工程师 DJ"}]},
config_session_A
)
# 第二轮对话 (Agent 会自动从内存恢复 "我是 DJ" 这个上下文)
print("--- Round 2 ---")
response = agent.invoke(
{"messages": [{"role": "user", "content": "我的职业是什么?"}]},
config_session_A
)
# 输出: 你的职业是架构师。
print(response["messages"][-1].content)
示例首先定义InMemorySaver,用于内存中存储短期记忆,生产环境通常使用PostgreSQL等数据库;然后通过create_agent创建Agent,并指定checkpointer;最后通过两轮agent的invoke调用,并指定同一个配置了thread_id的config。
最后输出如下:
--- Round 1 ---
--- Round 2 ---
根据我们对话的开始,你提到过:**“我是工程师 DJ”**。
所以,你的职业是 **工程师**。
04 长期记忆
短期记忆的致命弱点在于:一旦 thread\_id 改变,或者历史记录被修剪(Trimming),信息就永久丢失了。
长期记忆(Long-term Memory)利用 Store 接口,允许智能体将关键信息从“对话流”中提取出来,存储到独立的数据库文档中。它使用 **Namespace(命名空间)**来隔离数据,结构类似于文件路径 (scope, identifier)。
跨会话交互原理如下图所示:
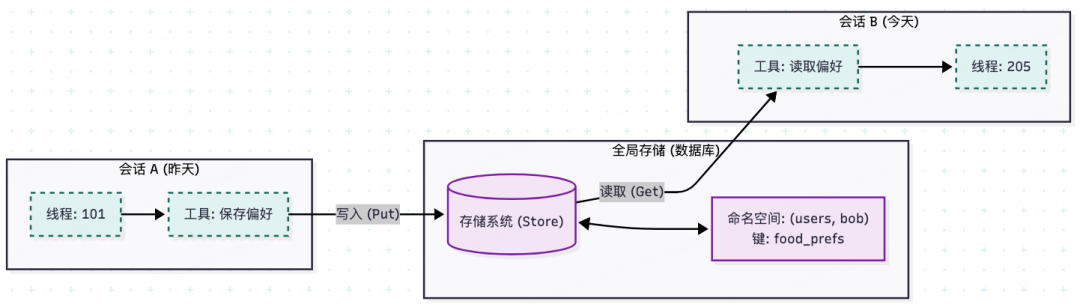
一个示例:工具读写实现长期记忆Store:
from langgraph.store.memory import InMemoryStore
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
import os
from pydantic import BaseModel
# 初始化存储后端 (生产环境通常连接 Redis 或 PostgreSQL)
store = InMemoryStore()
# 这决定了工具中 runtime.context 能访问到哪些字段
classContext(BaseModel):
user_id: str
@tool
defsave_user_preference(pref_detail: str, runtime: ToolRuntime):
"""
保存用户偏好到长期记忆。
当用户提到“我喜欢...”或“我不吃...”时调用此工具。
"""
# 1. 获取 Store 实例
current_store = runtime.store
# 2. 从运行时上下文中安全获取 user_id (非用户输入,防注入)
# 这需要在 invoke 时通过 configurable 传入
user_id = runtime.context.user_id
# 3. 写入数据
# Namespace: 类似文件夹路径 ("users", "bob"),用于数据隔离
# Key: 文件名 "food_prefs"
current_store.put(
("users", user_id),
"food_prefs",
{"detail": pref_detail, "updated_at": "2026-01-19"}
)
return"已记录您的偏好。"
@tool
defget_user_info(runtime: ToolRuntime):
"""读取用户的历史偏好信息"""
current_store = runtime.store
user_id = runtime.context.user_id
# 4. 读取数据
item = current_store.get(("users", user_id), "food_prefs")
return item.value if item else"暂无该用户偏好记录"
# 定义agent
os.environ["DEEPSEEK_API_KEY"] = "sk-..."
agent = create_agent(
model="deepseek-chat",
tools=[save_user_preference, get_user_info],
store=store, # 注入长期记忆存储
context_schema=Context # 声明运行时上下文结构
)
user_context = Context(user_id="DJ_001")
print("--round 1--")
# 第一次交互:保存信息
agent.invoke(
{"messages": [{"role": "user", "content": "记一下,我超级喜欢吃辣,尤其是川菜。"}]},
context=user_context
)
print("--round 2--")
# 第二次交互:跨会话/跨工具读取
result = agent.invoke(
{"messages": [{"role": "user", "content": "我刚才说我喜欢吃什么来着?"}]},
context=user_context
)
print(result["messages"][-1].content)
示例首先定义InMemoryStore,用于存储长期记忆,生产环境通常连接 Redis 或 PostgreSQL等;然后分别定义了两个可以操作长期记忆的工具;最后通过create_agent创建Agent,并指定tools、store和context_schema;通过两轮agent的invoke调用,并指定了同一个context。
最后输出如下:
根据记录,你之前提到过你**超级喜欢吃辣,尤其是川菜**!这是你在2026年1月19日分享的饮食偏好。
川菜确实很美味,像麻婆豆腐、水煮鱼、回锅肉这些经典川菜都很受欢迎。你最近有尝试什么新的川菜吗?
说明:长期记忆通常不直接暴露给 LLM 的 Context(太长且昂贵),而是通过 Tools 按需调用。
05 总结
记忆治理是 Agent 从“玩具”走向“生产力工具”的分水岭。在构建系统时,请遵循以下原则:
1. Checkpointer (短期记忆):解决“连贯性”,主要用于维持对话流(Flow)。
2. Store (长期记忆):解决“个性化”。用于持久存储知识(Knowledge)和偏好。
3. Middleware (治理):解决“可持续性”。防止记忆膨胀拖垮系统,通过自动总结和修剪保持上下文的精炼。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献691条内容
已为社区贡献691条内容

所有评论(0)