Vibe Coding 的底层逻辑:从“凭感觉写代码”到“可交付的代理式工程”
Vibe Coding是一种新型开发模式,开发者通过自然语言描述需求,AI代理自动完成代码生成、修改和测试验证等工程流程。其核心在于构建代理式软件工程系统,包含意图理解、上下文检索、计划拆解、工具调用等环节。主流实现如Cursor、Kiro、Claude Code等通过规则约束、权限控制和MCP协议等机制提升可控性。文章从工程原理出发,分析各平台的技术特点,指出规范化和自动化验证是确保Vibe C
“Vibe Coding”通常指:开发者用自然语言描述目标,让 AI 直接在代码库里生成/修改代码,开发者更多充当“审阅者与方向盘”,而不是逐行写实现。该概念常被归因于 Andrej Karpathy 在社交媒体上对这种开发方式的描述与传播。(X (formerly Twitter))
但真正决定它能否从“demo”走向“可维护、可上线”的,不是氛围,而是其背后的代理式软件工程系统:上下文检索、计划拆解、工具调用、补丁应用、测试验证、安全权限与组织治理。
本文从“底层机制”出发,拆解 Vibe Coding 的工程原理,并对 Trae、Cursor、Kiro、OpenAI Codex、Claude Code 等主流体系做一个可落地的对照与选型思路。
更多优质文章请前往:Flow Ciotter
1. Vibe Coding 本质上是什么:从“生成”到“代理”
传统“AI 编程”常见形态是:补全(completion)或对话问答(chat)。Vibe Coding 更接近代理(agent):
- 能理解“目标”
- 能在项目中“找信息”
- 能“改多个文件”
- 能“运行命令/测试”
- 能迭代修复直到完成
换句话说:它不是“写几段代码”,而是把一段软件工程流程半自动化。
这一点在多个官方文档里都被明确表达:
- Cursor 的 Agent 能“探索代码库、编辑多文件、运行命令并修复错误”。(Cursor)
- Claude Code 强调“可直接编辑文件、运行命令、创建提交”,并可通过 MCP 接更多外部工具。(Claude Code)
- Codex CLI 明确可在选定目录内“读取、修改、运行代码”。(OpenAI Developers)
- Kiro 将其定位为“从原型到生产”的 agentic IDE,并强调 steering、spec、hooks 与原生 MCP。(Kiro)
- Trae 被描述为包含 Chat/Builder 等模式,Builder 更偏“从零到一生成应用”的工具化流程。(InfoQ)
2. Vibe Coding 的“底层流水线”:一个典型代理循环
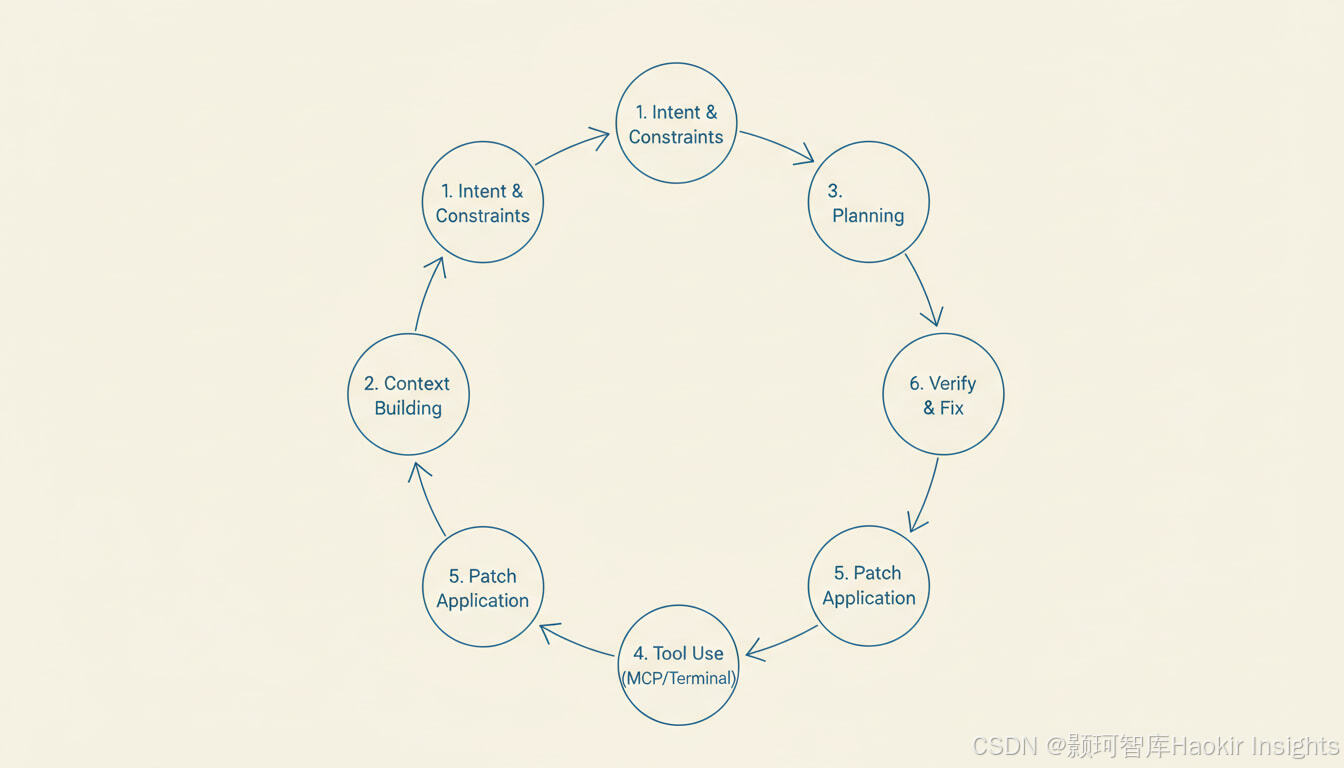
把所有产品名字先放一边,Vibe Coding 的底层大多遵循同一套闭环:
2.1 意图理解与约束收集(Intent → Constraints)
AI 先把你的自然语言目标转成“可执行约束”:
- 需求边界:做什么/不做什么
- 非功能约束:性能、兼容性、安全、可观测性
- 交付形式:PR、patch、commit、文档、测试
工程要点:约束如果不显式化,代理会“自作主张”,最终表现就是你感觉它“写得很嗨但不对”。
2.2 上下文构建(Context Building)
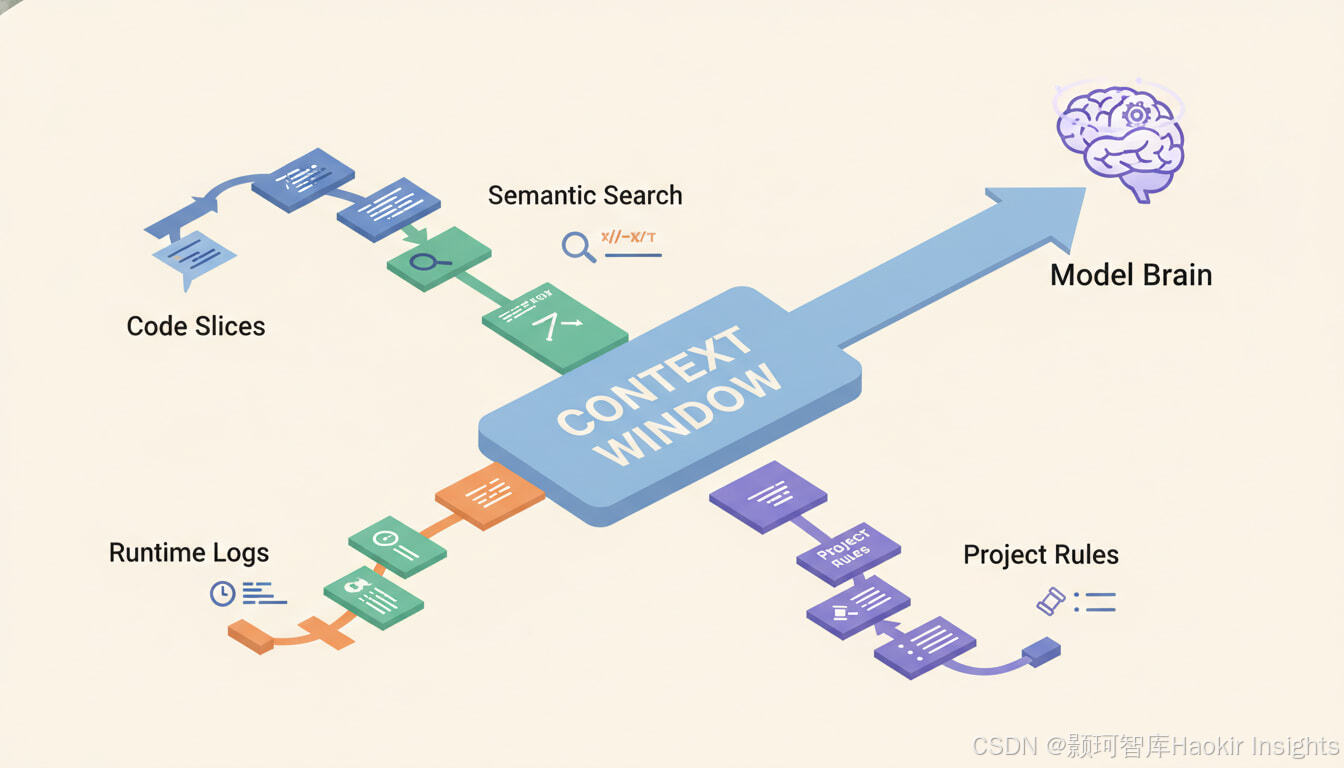
这是 Vibe Coding 的关键:模型并不“自动懂你的仓库”,必须喂给它“刚好够用的证据”。
上下文来源通常包括:
- 代码库切片:相关文件片段、接口定义、配置
- 语义检索:用 embedding/向量搜索从全仓库捞相关代码(Cursor 明确提供 semantic search 概念)。(Cursor)
- 运行时证据:日志、报错、测试输出、终端命令结果
- 项目规范:规则文件/说明文档(Cursor 的 Rules 机制、Kiro 的 steering 文件、Claude Code 的 repo 指南文件等)
2.3 计划拆解(Plan)
代理会把目标拆成子任务(文件改动点、风险点、验证点)。
一些体系把“计划”产品化,例如 Codex 文档提到其 Agent 模式可直接执行读写运行;Cursor 也强调复杂任务由 Agent 处理。(OpenAI Developers)
2.4 工具调用与执行(Tool Use)
代理式编程的“手脚”通常包含:
- 文件读写(多文件修改)
- 终端命令(build、test、lint、migration)
- Git 操作(分支、worktree、commit、PR)
- 外部工具(通过 MCP 接文档、Issue、数据库、API)
其中 MCP(Model Context Protocol)成为跨工具的主流连接方式:Claude Code 提供 MCP 接入与风险提示;Kiro 也强调原生 MCP 集成。(Claude Code)
2.5 补丁应用策略(Patch Application)
代理不会“把全仓库重写”,它通常使用“差异化修改”:
- 以 diff/patch 形式应用
- 逐文件编辑并保留上下文
- 在 IDE 内展示改动,要求你确认(人类把关)
Cursor 还进一步支持并行代理与隔离工作区(例如 worktree),降低多任务互相踩踏的风险。(Cursor)
2.6 验证与回路(Verify → Fix Loop)
能否从“氛围”走向“交付”,取决于:
- 测试是否跑起来
- lint/format 是否通过
- 关键路径是否有回归
- 变更是否与设计一致
Claude Code、Cursor 等都围绕“运行命令/测试”的安全与权限做了机制化约束,例如 Claude Code 默认只读,执行/编辑需授权。(Claude Code)
Cursor 也提到 Agent 运行终端时默认是受限环境。(Cursor)
3. “可控性”才是底层分水岭:规则、规范与记忆
Vibe Coding 最容易翻车的原因只有一个:上下文与规范缺失。
因此各家都在做“约束系统”,只是形式不同:
3.1 Cursor:Rules + Agent 模式 + 受限终端
- Agent 模式用于复杂任务,能改多文件、跑命令。(Cursor)
- Rules 机制可把项目规范写进
.cursor/rules,让代理长期遵守。(Cursor) - 数据与隐私方面,Cursor 明确区分 Privacy Mode 与非 Privacy Mode 的数据使用范围。(Cursor)
底层逻辑:Cursor 更像“IDE 内置的工程代理”,把“上下文、规则、终端与并行改动隔离”整合在编辑器体验里。
3.2 Kiro:Spec-driven development(规格驱动)+ Steering + Hooks + MCP
Kiro 的定位非常明确:把 Vibe Coding 的“混乱”改造成“可追踪的工程交付”。其文档体系把核心能力拆成四块:
- Specs:把需求写成结构化 requirements/design/tasks。并明确在 requirements 中使用 EARS(WHEN… THE SYSTEM SHALL…)来增强可测试性与可验证性。(Kiro)
- Steering:用 steering 文件规定项目规则、上下文与偏好(类似“团队工程手册”写给 AI)。(Kiro)
- Hooks:事件触发的自动化代理动作(保存/新建/删除文件、agent stop 等),用于把“例行工程动作”固化下来。(Kiro)
- MCP:原生集成外部工具与知识源;AWS 博文还给出通过
.kiro/settings/mcp.json等方式配置 MCP 的路径。(Kiro)
底层逻辑:Kiro 的核心不是“更会写代码”,而是把需求、设计、任务、自动化与外部工具接入,变成可控的生产流水线。
3.3 Claude Code:终端代理 + 权限系统 + MCP + 沙箱化
Claude Code 强调“在终端工作”、并具备对文件/命令/提交的行动能力。(Claude Code)
安全与自治之间的平衡主要靠三点:
- 默认只读,关键动作需授权(permissions)。(Claude Code)
- MCP 连接外部工具,但提示第三方 MCP 服务器存在安全风险(prompt injection 等)。(Claude Code)
- Anthropic 还讨论了通过文件系统与网络隔离实现更安全的自治(sandboxing)。(Anthropic)
底层逻辑:Claude Code 更像“安全优先的终端工程代理”,用权限与沙箱把风险边界做清楚,再通过 MCP 扩展能力。
3.4 OpenAI Codex:本地 CLI 代理 + IDE/云形态
Codex 在 2025 后更强调“代理式工具链”,而不仅是模型本身:
- Codex CLI:本地终端代理,可读/改/跑选定目录代码。(OpenAI Developers)
- 官方 quickstart 提到其默认以 Agent mode 运行,可读文件、跑命令、写变更。(OpenAI Developers)
- OpenAI 的产品页也强调它覆盖 Plan/Build/Test/Review/Deploy 等阶段。(开放AI)
底层逻辑:Codex 更像“可落地的软件工程队友”,在本地/IDE/云之间形成统一的代理体验,重点是任务执行闭环而非单次生成。
3.5 Trae:Chat/Builder 双模式 + “从零到一”应用生成倾向
公开报道与官方文章描述 Trae 的模式划分:
- Chat mode:围绕现有代码问答、建议、补全
- Builder mode:更偏“从规格生成应用(文件夹/文件/实现)”(InfoQ)
Trae 的定位更像“协作式 IDE”,强调人机协同与模式分工。(TRAE)
底层逻辑:Trae 把“对话辅助”和“从零构建”拆成两种交互范式,前者强调局部增量,后者强调端到端生成与工具化执行。
4. Vibe Coding 的“硬问题”:为什么会写崩、写偏、写不完
即使工具很强,Vibe Coding 仍有典型失败模式。理解这些失败模式,才能写出“可控的提示词/规范”。
4.1 上下文过少:模型在“猜”
表现:编译不过、接口对不上、重复造轮子。
根因:缺少关键文件、真实调用路径、运行日志。
解决:强制要求“先定位再动手”,先输出:涉及文件、调用链、风险点、验证步骤。
4.2 上下文过多:注意力被淹没
表现:改错文件、抓错重点、改动发散。
根因:把整个仓库或大量无关日志塞进对话。
解决:用“问题驱动的上下文选取”:只提供与当前子任务强相关的切片,并在规则里明确“不得无依据扩展范围”。
4.3 目标不具备可验证性
表现:看似完成,但不符合预期或边界条件缺失。
根因:需求没有 acceptance criteria,没有测试点。
解决:Kiro 的 EARS/验收写法是一个非常工程化的模板:把每条需求变成“触发条件 + 期望行为”。(Kiro)
4.4 工具调用风险:安全与合规
表现:误删文件、执行危险命令、外传敏感信息。
解决方向:
- 权限系统:默认只读,关键动作授权(Claude Code)。(Claude Code)
- 受限终端/沙箱:限制网络与文件范围(Cursor、Claude Code)。(Cursor)
- MCP 风险意识:第三方 MCP 服务器可能引入提示注入与不可信内容(Claude Code 明确提示)。(Claude Code)
5. 一套“可落地”的 Vibe Coding 工程方法论
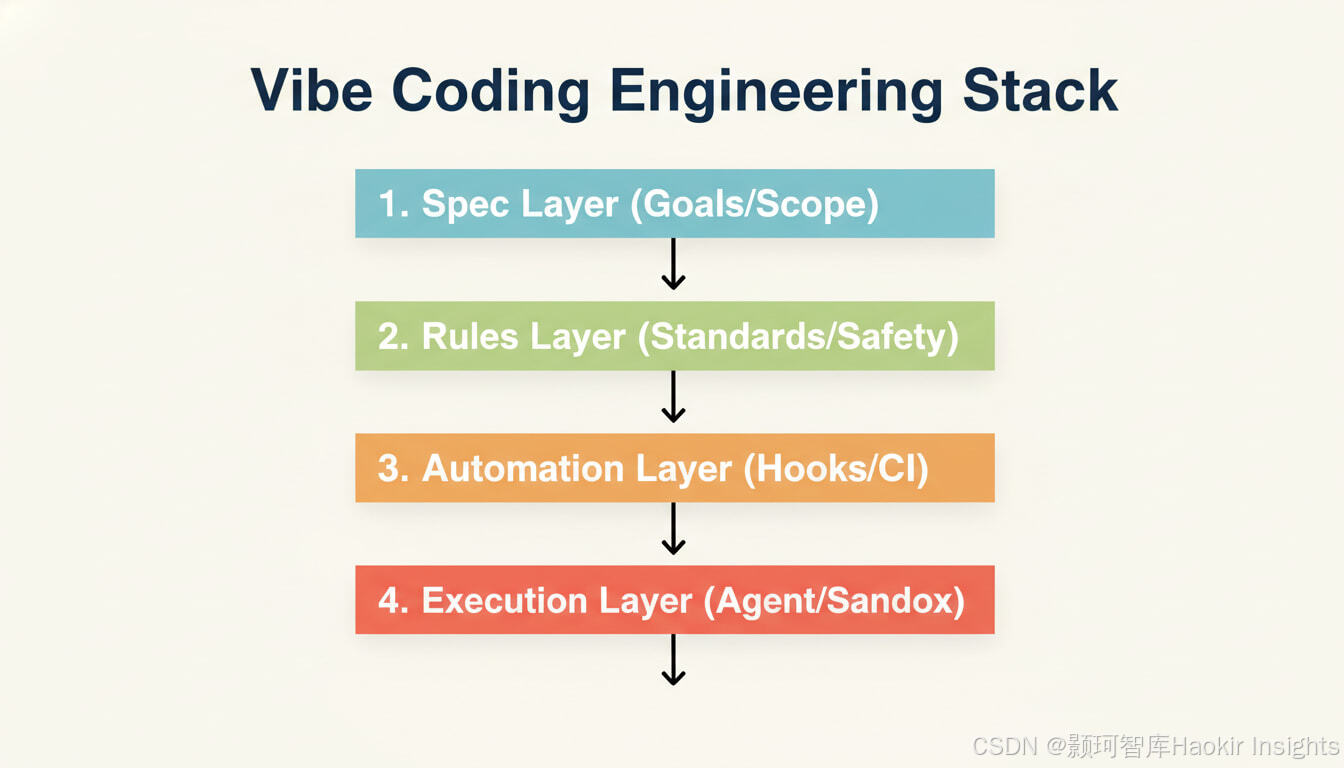
如果你希望把 Vibe Coding 变成团队可复制的方法,而不是个人技巧,建议把工作流固定为四段:
5.1 规格层(Spec)
- 目标、范围、不做什么
- 验收标准(可测试)
- 风险与回滚策略
(Kiro 的 spec-driven 思路是直接把这一层产品化了。(Kiro))
5.2 规则层(Rules/Steering)
- 代码风格与目录约定
- 依赖与架构原则
- 安全规范(禁用命令、敏感路径)
- 文档更新要求
(Cursor Rules 与 Kiro steering 都在解决“长期一致性”。(Cursor))
5.3 自动化层(Hooks/CI)
- 保存/提交前自动 lint、format、测试
- 自动生成/更新变更日志与文档
- 安全扫描与密钥检查
(Kiro hooks 把“例行动作”变成事件触发;非常适合工程团队标准化。(Kiro))
5.4 执行层(Agent)
- 让代理在受控环境中执行(终端、IDE、沙箱)
- 输出最小可审阅改动(diff/commit/PR)
- 人类做最终审批与上线决策
6. 选型对照:你到底该用哪个体系?
下面是一个更“底层视角”的选型建议(不谈情绪,只谈机制):
- 你要的是 IDE 内强代理、并行改动隔离、规则化约束:更偏 Cursor(Agent + Rules + 受限终端 + 并行 worktree 思路)。(Cursor)
- 你要的是把需求/设计/任务结构化,长期可维护、可追踪、可自动化:更偏 Kiro(spec + steering + hooks + MCP)。(Kiro)
- 你要的是终端里安全可控的工程代理、强权限治理、MCP 扩展:更偏 Claude Code(permissions + MCP + sandboxing)。(Claude Code)
- 你要的是本地 CLI 代理(或与 IDE/云打通)的任务执行闭环:更偏 Codex(Codex CLI/Agent mode/覆盖全流程阶段)。(OpenAI Developers)
- 你要的是“对话辅助 + 从零构建”双范式的 IDE 协作体验:可关注 Trae 的 Chat/Builder 模式分工。(InfoQ)
7. 最后:Vibe Coding 的终点不是“更会生成”,而是“更可交付”
Vibe Coding 的价值不在“AI 写得多快”,而在于它把软件工程的关键成本从“编码时间”迁移到了:
- 规格是否清晰
- 上下文是否准确
- 规则是否一致
- 验证是否自动化
- 权限与安全是否可控
当你把这些“工程结构”搭起来,Vibe 才能从“氛围”变成“生产力”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)