Bert代码实战
文章摘要: 本文介绍了基于BERT的文本分类实现,包含三个核心部分:1) 数据处理模块使用PyTorch的Dataset和DataLoader构建训练/验证集,并采用sklearn的train_test_split进行数据划分;2) 模型部分继承BertModel,添加全连接层进行分类,详细说明了BERT输入构建方法及tokenizer参数;3) 训练流程展示了BERT模型前向传播过程,包括文本编
一、数据处理
from torch.utils.data import Dataset,DataLoader,ConcatDataset
import torch
from sklearn.model_selection import train_test_split
from tqdm import tqdm
import numpy as np
def read_txt_data(path):
label = []
data = []
with open(path, "r", encoding="utf-8") as f:
for i, line in tqdm(enumerate(f)):
if i == 0:
continue # continue 表示立即执行下一次循环
if i > 200 and i < 7500:
continue
line = line.strip('\n')
line = line.split(",", 1) # 1表示分割次数
label.append(line[0])
data.append(line[1])
print(len(label))
print(len(data))
return data, label
class JdDataset(Dataset):
def __init__(self, x, label):
self.X = x
label = [int(i) for i in label]#本来是字符串型,需要转成整形
self.Y = torch.LongTensor(label)#分类任务以后的标签都要是长张量
def __getitem__(self, item):
return self.X[item], self.Y[item] # 数据集一般不让返回str, 要写在字典中,或者转为矩阵。
def __len__(self):
return len(self.Y)
def get_dataloader(path, batchsize=1, valSize=0.2):
x, label = read_txt_data(path)
train_x, val_x, train_y, val_y = train_test_split(x, label,test_size=valSize,shuffle=True, stratify=label)
train_set = JdDataset(train_x, train_y)
val_set = JdDataset(val_x, val_y)
train_loader = DataLoader(train_set, batch_size=batchsize)
val_loader = DataLoader(val_set, batch_size=batchsize)
return train_loader, val_loader
if __name__ == '__main__':
get_dataloader("../jiudian.txt",batchsize=4)
- 输入文本格式:

第一行数据不需要,所以得跳过
每一个line都是接下来的一整行,但是末尾都有换行符,使用strip删除
为了把每一行中的标签和数据分离,介于文字其本身的特性,使用split分割 - getdataLoader()函数用于创建数据集实例,并获取loader
介绍一个划分训练集和验证集的方法:
from sklearn.model_selection import train_test_split
核心机制是随机打乱 (shuffle) 输入的数据索引,然后根据指定的比例(test_size 或 train_size 参数)来切分这些被打乱的索引
函数的参数:
*arrays: 这是你要分割的数据
test_size,train_size
random_state:随机种子
stratify:如果stratify=label(y)意味着划分后,训练集和验证/测试集中各个类别的样本比例会尽量与原始数据集中的比例保持一致
函数的返回:
返回一个元组 (tuple),包含了分割后的数据。如果你输入的是 (X, y),那么它会返回 (X_train, X_test, y_train, y_test)
二、模型函数
import torch
import torch.nn as nn
import numpy as np
# from timm.models.vision_transformer import PatchEmbed, Block
import torchvision.models as models
import transformers
from transformers import (BertPreTrainedModel, BertConfig,
BertForSequenceClassification, BertTokenizer,BertModel,
)
class myBertModel(nn.Module):
def __init__(self, bert_path, num_class, device):
super(myBertModel, self).__init__()
self.device = device
self.num_class = 2 #分类任务的类别数量
# bert_config = BertConfig.from_pretrained(bert_path)
# self.bert = BertModel(bert_config)
self.bert = BertModel.from_pretrained(bert_path)
self.tokenizer = BertTokenizer.from_pretrained(bert_path)
self.out = nn.Sequential(
nn.Linear(768,num_class)
)
def build_bert_input(self, text):
Input = self.tokenizer(text,return_tensors='pt', padding='max_length', truncation=True, max_length=128)
input_ids = Input["input_ids"].to(self.device)
attention_mask = Input["attention_mask"].to(self.device)
token_type_ids = Input["token_type_ids"].to(self.device)
return input_ids, attention_mask, token_type_ids
def forward(self, text):
input_ids, attention_mask, token_type_ids = self.build_bert_input(text)
sequence_out, pooled_output = self.bert(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
return_dict=False)
out = self.out(pooled_output)
return out
-
模型:拿着Bert的现成模型与参数+下游微调一个全连接(768,numclass)
numclass意思是分类任务的类别数量 -
build_bert_input 方法
目的: 将原始文本字符串转换为 BERT 模型可以接受的张量格式(input_ids, attention_mask, token_type_ids),于是需要一个分词器
Input = self.tokenizer(…): 调用 BERT 分词器。
参数如下:
1.text: 输入的原始文本。
2.return_tensors=‘pt’: 指定返回 PyTorch 张量格式。
3.padding=‘max_length’: 对输入进行填充(Padding),使其长度达到 max_length 指定的长度(这里是 128)。
4.truncation=True: 如果输入文本超过 max_length,则截断(Truncate)多余的部分。
5.max_length=128: 设置最大序列长度(包括 [CLS], [SEP] 等特殊 token)。这限制了模型能处理的上下文窗口大小。 -
tokenizer实例
input_ids: 代表文本中每个 token 的 ID 编号。
attention_mask: 指示哪些位置是真实的 token (1) 哪些是填充的 (0),帮助模型忽略填充部分。
token_type_ids: 用于区分句子对任务中的不同句子(对于单句任务,通常全为 0)。BERT 原生支持句子对输入。
不加参数:
加参数: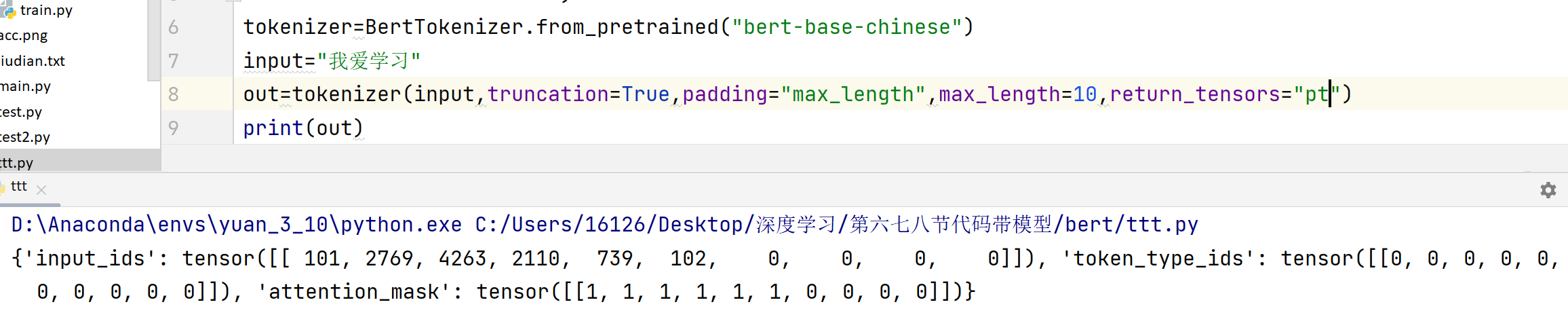
-
self.bert(实际上是BertModel的forward方法),有两个输出
sequence_out:是刚从transformer出来的输出
pooled_output:是经过pooler层得到的输出
三、训练模型
import torch
import time
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
def train_val(para):
########################################################
model = para['model']
train_loader =para['train_loader']
val_loader = para['val_loader']
scheduler = para['scheduler']
optimizer = para['optimizer']
loss = para['loss']
epoch = para['epoch']
device = para['device']
save_path = para['save_path']
max_acc = para['max_acc']
val_epoch = para['val_epoch']
#################################################
plt_train_loss = []
plt_train_acc = []
plt_val_loss = []
plt_val_acc = []
val_rel = []
for i in range(epoch):
start_time = time.time()
model.train()
train_loss = 0.0
train_acc = 0.0
val_acc = 0.0
val_loss = 0.0
for batch in tqdm(train_loader):
model.zero_grad()
text, labels = batch[0], batch[1].to(device)
pred = model(text)
bat_loss = loss(pred, labels)
bat_loss.backward()
optimizer.step()
scheduler.step()#更新学习率
optimizer.zero_grad()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)# 梯度裁剪,防止梯度过大
train_loss += bat_loss.item() #.detach 表示去掉梯度
train_acc += np.sum(np.argmax(pred.cpu().data.numpy(),axis=1)== labels.cpu().numpy())
plt_train_loss . append(train_loss/train_loader.dataset.__len__())
plt_train_acc.append(train_acc/train_loader.dataset.__len__())
if i % val_epoch == 0:
model.eval()
with torch.no_grad():
for batch in tqdm(val_loader):
val_text, val_labels = batch[0], batch[1].to(device)
val_pred = model(val_text)
val_bat_loss = loss(val_pred, val_labels)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == val_labels.cpu().numpy())
val_rel.append(val_pred)
if val_acc > max_acc:
torch.save(model, save_path+str(epoch)+"ckpt")
max_acc = val_acc
plt_val_loss.append(val_loss/val_loader.dataset.__len__())
plt_val_acc.append(val_acc/val_loader.dataset.__len__())
print('[%03d/%03d] %2.2f sec(s) TrainAcc : %3.6f TrainLoss : %3.6f | valAcc: %3.6f valLoss: %3.6f ' % \
(i, epoch, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1])
)
if i % 50 == 0:
torch.save(model, save_path+'-epoch:'+str(i)+ '-%.2f'%plt_val_acc[-1])
else:
plt_val_loss.append(plt_val_loss[-1])
plt_val_acc.append(plt_val_acc[-1])
print('[%03d/%03d] %2.2f sec(s) TrainAcc : %3.6f TrainLoss : %3.6f ' % \
(i, epoch, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1])
)
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title('loss')
plt.legend(['train', 'val'])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title('Accuracy')
plt.legend(['train', 'val'])
plt.savefig('acc.png')
plt.show()
四、主函数
import torch.nn as nn
import torch
import random
import numpy as np
import os
import matplotlib
matplotlib.use("TkAgg")
from model_utils.data import get_dataloader
from model_utils.model import myBertModel
from model_utils.train import train_val
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
model_name = 'MyModel'
num_class = 2
batchSize = 4
learning_rate = 0.0001
loss = nn.CrossEntropyLoss()
epoch = 3
device = 'cuda' if torch.cuda.is_available() else 'cpu'
data_path = "jiudian.txt"
bert_path = 'bert-base-chinese'
save_path = 'model_save/'
seed_everything(1)
##########################################
train_loader, val_loader = get_dataloader(data_path, batchsize=batchSize)
model = myBertModel(bert_path, num_class, device).to(device)
# tokenizer, model = build_model_and_tokenizer(bert_path)
param_optimizer = list(model.parameters())
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate,weight_decay=0.0001)
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,T_0=20,eta_min=1e-9)
trainpara = {'model': model,
'train_loader': train_loader,
'val_loader': val_loader,
'scheduler': scheduler,
'optimizer': optimizer,
'learning_rate': learning_rate,
'warmup_ratio' : 0.1,
'weight_decay' : 0.0001,
'use_lookahead' : True,
'loss': loss,
'epoch': epoch,
'device': device,
'save_path': save_path,
'max_acc': 0.85,
'val_epoch' : 1
}
train_val(trainpara)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)