CrewAI部署指南
咩咩咩咩咩咩咩咩
CrewAI部署指南
项目概述
1.1CrewAI 框架综述
crewAI是一个创新的开源多智能体编排框架,由João Moura开发,旨在通过协调多个AI智能体的协作来完成复杂任务。这个框架模拟了现实世界中的工作团队,让不同角色的智能体能够自主地相互委派任务和交流,从而实现比单一语言模型更强大的性能表现。
1.2CrewAI 核心概念
CrewAI的核心概念包括智能体(Agent)、任务(Task)、工具(Tool)、流程(Process)和团队(Crew)。每个智能体都有特定的角色、目标和背景故事,可以执行定制的任务并使用各种功能工具。流程定义了智能体如何协作,而团队则是这些组件的组合容器。这种模块化设计使得CrewAI能够灵活地应对复杂问题,同时保持系统的简洁性和可扩展性。
1.3CrewAI 应用场景
这个创新框架在多个领域展现了其强大的应用潜力。在客户服务方面,它可以自动回答咨询并提供个性化服务;在供应链管理中,协调库存、订单处理和物流跟踪等环节;而在网络安全领域,部署智能体监控网络活动并响应威胁. 此外,CrewAI还可用于市场分析与预测,利用智能体分析数据、预测趋势,为决策提供支持。在企业内部,它可作为智能助手,自动化日程管理等日常任务,提高工作效率.
部署过程
2.1系统要求
#系统
unbuntu
#软件依赖
- Python 3.10+
- curl OR wget
- uv (用于部署安装)
2.2环境部署
在搭建过程中,我们发现直接使用pip安装openai以及crewai会触发unix的环境冲突警告

所以我们这里在虚拟环境下搭建
python3 -m venv ai_env
然后激活该虚拟环境
source ai_env/bin/activate
接下来再把crewai和openai下下来
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple crewai openai
之后我们输入deactivate返回全区变量安装uv
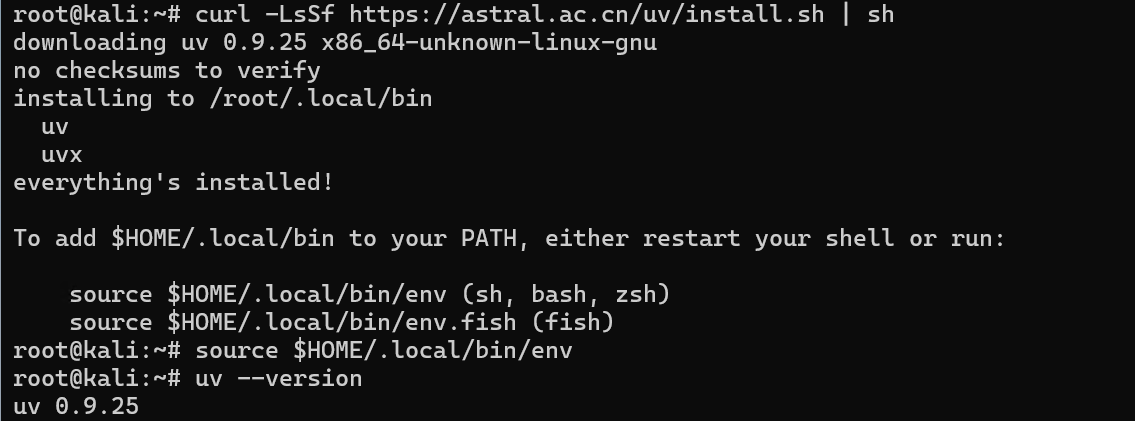
curl -LsSf https://astral.ac.cn/uv/install.sh | sh
将uv写入环境变量之中,检查一下版本
2.3crewai部署
再次进入虚拟环境之中,然后
uv tool insatll crewai#安装crewai

装完之后依旧可以检查一下版本,接着就可以开始运行了。
crewai creat crew BOYITECHSEC #创建一个叫BOYITECHSEC的项目
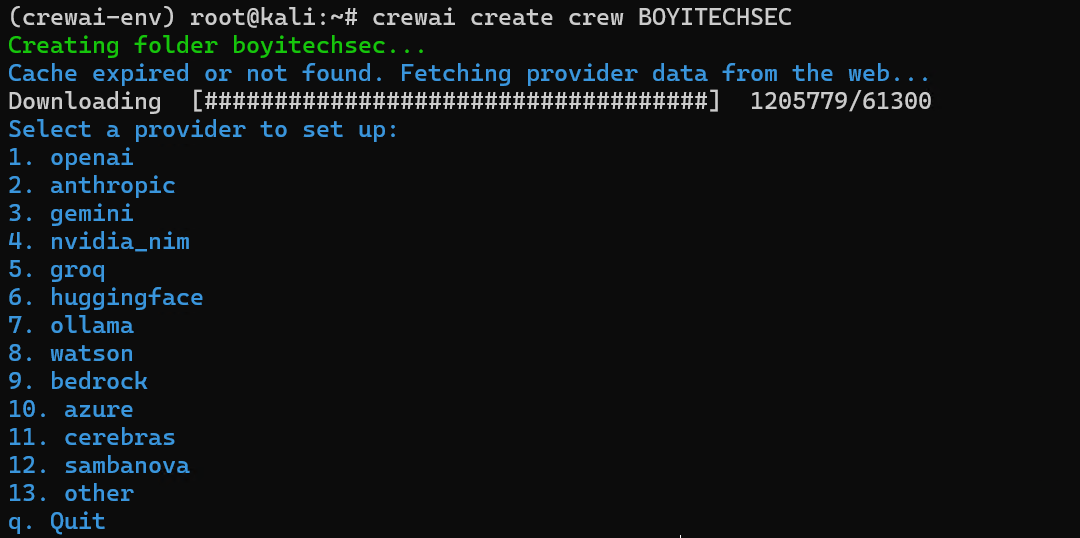
按照你需要的大模型选择相应的服务商,选择完成之后输入api_key就算是创建完成了
其文件结构大致如下:
my_team/
├── .env # 存放API密钥
├── src/
│ └── my_team/
│ ├── config/
│ │ ├── agents.yaml # 员工档案
│ │ └── tasks.yaml # 工作任务
│ ├── crew.py # 团队配置
│ └── main.py # 启动脚本
crewai使用
首先我们需要配置下面两个基本的设置
asks.yaml # 工作任务

agents.yaml # 员工档案

相当于给ai先进行一个简单的定义吧,然后注意这里的这里的全局变量是要记住的,因为他要和你的main函数里的输入变量对上
接着来配置crew.py
from crewai import Agent, Crew, Process, Task, LLM
from crewai.project import CrewBase, agent, crew, task
from crewai.agents.agent_builder.base_agent import BaseAgent
from typing import List
import os
from dotenv import load_dotenv # 需安装:pip install python-dotenv
# 加载.env文件中的环境变量(生产环境建议直接在系统/容器中配置环境变量)
load_dotenv()
@CrewBase
class Boyitechsec():
"""Boyitechsec crew"""
# 从环境变量读取敏感配置,替换硬编码内容
my_llm = LLM(
model=os.getenv("LLM_MODEL", "openai/deepseek-r1"), # 占位默认值
base_url=os.getenv("LLM_BASE_URL", "https://your-base-url-here.com/api/v1"), # 脱敏占位
api_key=os.getenv("LLM_API_KEY", "your-api-key-here"), # 脱敏占位
)
agents: List[BaseAgent]
tasks: List[Task]
@agent # 对接agents.yml配置
def analyst(self) -> Agent:
return Agent(
config=self.agents_config['analyst'],
llm=self.my_llm,
verbose=True
)
@task # 对接task.yml配置
def analysis_task(self) -> Task:
return Task(
config=self.tasks_config['analysis_task'],
)
@task
def reporting_task(self) -> Task:
return Task(
config=self.tasks_config['reporting_task'],
output_file='security_report.md'
)
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)
到这里基本上就已经初步布置完毕了
在main函数里,我们需要把要用到的变量名给写上去,且变量名需要和之前的一致,不然会报错
最后在运行之前安装一下LLM方便我们远程ai的导入
# 使用 uv 将 litellm 添加到项目依赖并安装
uv add litellm
最后输入运行
crewai run
项目运行时会显示我们的agent以及task,最后返回简化后的结果,并将报告写到更目录下
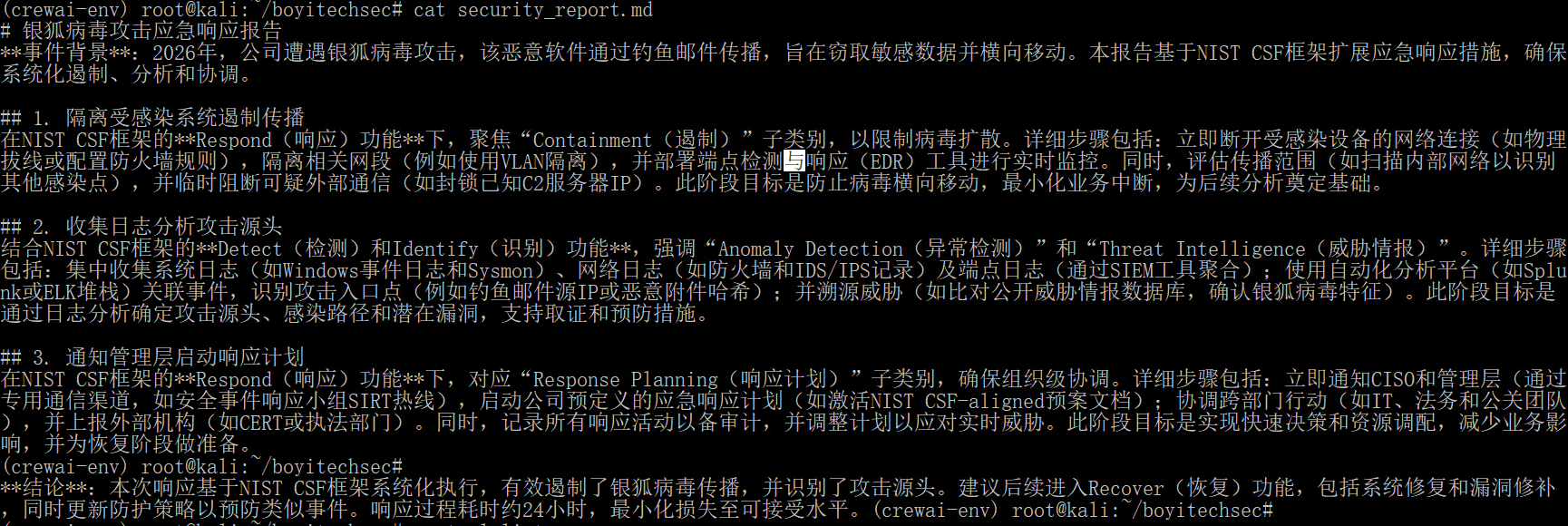
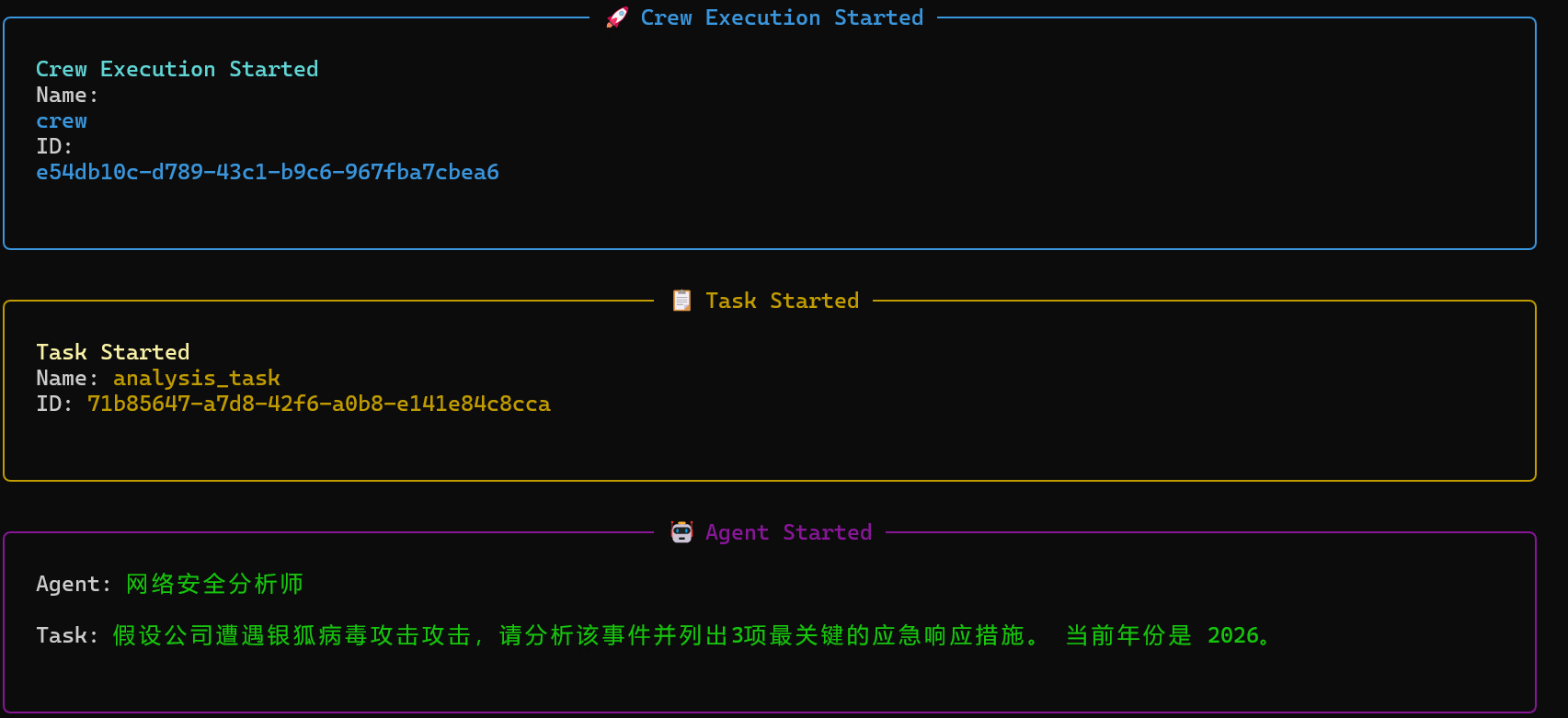
crewai扩展性
在agent能正常工作的基础上,我们可以尝试去扩展接入一些工具
因为crewai实在lang_chain上进行二开的,所以lang_chain社区的一些工具我们都可以进行使用
如果需要进行工具扩展先要下载他们官方的工具包
pip install 'crewai[tools]'
4.1 官方tools
我们先测试crewai官方提供的工具:
| 工具 | 描述 |
|---|---|
| CodeDocsSearchTool | 专为搜索代码文档和相关技术文档而优化的 RAG 工具。 |
| CSVSearchTool | 专为在 CSV 文件中搜索而设计的 RAG 工具,适用于处理结构化数据。 |
| DirectorySearchTool | 用于在目录中搜索的 RAG 工具,可用于浏览文件系统。 |
| DOCXSearchTool | 旨在在 DOCX 文档中搜索的 RAG 工具,适用于处理 Word 文件。 |
| DirectoryReadTool | 便于读取和处理目录结构及其内容。 |
| FileReadTool | 可读取并提取文件中的数据,支持各种文件格式。 |
| GithubSearchTool | 用于在 GitHub 存储库中搜索的 RAG 工具,适用于代码和文档搜索。 |
| SerperDevTool | 专为开发目的而设计的专用工具,具有特定的功能正在开发中。 |
| TXTSearchTool | 专注于在文本(.txt)文件中搜索的 RAG 工具,适用于非结构化数据。 |
| JSONSearchTool | 专为在 JSON 文件中搜索而设计的 RAG 工具,适用于处理结构化数据。 |
| MDXSearchTool | 专为在 Markdown(MDX)文件中搜索而定制的 RAG 工具,适用于文档。 |
| PDFSearchTool | 旨在在 PDF 文档中搜索的 RAG 工具,适用于处理扫描文档。 |
| PGSearchTool | 专为在 PostgreSQL 数据库中搜索而优化的 RAG 工具,适用于数据库查询。 |
| RagTool | 通用的 RAG 工具,能够处理各种数据源和类型。 |
| ScrapeElementFromWebsiteTool | 可从网站中抓取特定元素,适用于有针对性的数据提取。 |
| ScrapeWebsiteTool | 便于抓取整个网站,适用于全面的数据收集。 |
| WebsiteSearchTool | 用于搜索网站内容的 RAG 工具,优化了网络数据提取。 |
| XMLSearchTool | 专为在 XML 文件中搜索而设计的 RAG 工具,适用于结构化数据格式。 |
| YoutubeChannelSearchTool | 用于在 YouTube 频道中搜索的 RAG 工具,适用于视频内容分析。 |
| YoutubeVideoSearchTool | 旨在在 YouTube 视频中搜索的 RAG 工具,适用于视频数据提取。 |
调用的话
大致的模版如下:
#首先引入工具库
from crewai_tools import (
FileReadTool, # 用于读取本地文件
DirectoryReadTool, # 用于遍历目录
WebsiteSearchTool, # 用于搜索网页内容 (RAG)
ScrapeWebsiteTool, # 用于抓取网页正文
GithubSearchTool, # 用于搜索 GitHub 代码库
CodeDocsSearchTool, # 用于搜索代码文档
CSVSearchTool, # 用于搜索 CSV 数据
JSONSearchTool # 用于搜索 JSON 数据
)
#然后对你要用的tools进行定义
# [文件系统类] - 用于本地取证和日志分析
# 允许 Agent 读取特定日志目录
log_dir_tool = DirectoryReadTool(directory='./logs')
# 允许 Agent 读取特定配置文件
config_file_tool = FileReadTool(file_path='./config.json')
# [网络情报类] - 用于外部威胁情报收集
# 允许 Agent 搜索互联网 (需配置 SERPER_API_KEY)
web_rag_tool = WebsiteSearchTool()
# 允许 Agent 抓取特定安全博客的内容
site_scrape_tool = ScrapeWebsiteTool(website_url='https://thehackernews.com')
#定义哪些角色需要使用哪些工具,这里以自己写的一个agent为例
osint_analyst = Agent(
role="开源情报分析师",
goal="搜集关于目标组件的已知漏洞和社区讨论",
backstory="你擅长利用公开资源挖掘安全情报。你会查看安全新闻网站。",
llm=self.llm,
# 扩展点:挂载网络搜索工具
tools=[web_rag_tool, site_scrape_tool], #在这里填入就好了,之后他会自己调用的
verbose=True
)
4.2自定义tools调用
自定义tools分为子类化basetool和利用tool装饰器
子类化 BaseTool,这个可以定义一些更加复杂的函数参数等
from crewai_tools import BaseTool
class MyCustomTool(BaseTool):
name: str = "我的工具名称"
description: str = "清晰描述此工具用于什么,您的代理将需要这些信息来使用它。"
def _run(self, argument: str) -> str:
# 实现在这里
return "自定义工具的结果"
利用 tool 装饰器,这个比较轻量化,适合简单的定义一些东西
from crewai_tools import tool
@tool("我的工具名称")
def my_tool(question: str) -> str:
"""清晰描述此工具用于什么,您的代理将需要这些信息来使用它。"""
# 函数逻辑在这里
return "您的自定义工具的结果"
挂载是和官方一样的,直接写到对应的agents的tools栏里就好
使用 @tool 装饰器 (轻量级)
class SecurityOpsTools:
@tool("Firewall IP Blocker")
def block_ip(ip_address: str):
"""
在企业防火墙上封禁指定的恶意 IP 地址。
使用此工具来阻断来自攻击者的流量。
参数: ip_address (str) - 需要封禁的 IP (例如 '192.168.1.105')
"""
# 模拟封禁操作
return f"SUCCESS: 防火墙规则已更新。IP 地址 {ip_address} 已被永久封禁。所有来自该 IP 的流量将被丢弃。"
@tool("Threat Intelligence Lookup")
def check_ip_reputation(ip_address: str):
"""
查询 IP 地址的威胁信誉。
用于确认一个 IP 是否已知为恶意 IP。
"""
# 模拟威胁情报查询
if "192.168.1.105" in ip_address:
return f"警告: IP {ip_address} 被标记为 '高风险'。关联威胁组织: APT-29. 历史行为: SSH 暴力破解, 数据窃取。"
return f"信息: IP {ip_address} 信誉良好,未发现恶意记录。"
#挂载
tools=[SecurityOpsTools.block_ip, SecurityOpsTools.check_ip_reputation], # 赋予执行响应动作的能力
这里举些实例
继承 BaseTool 类 (专业级)
class LogSearchInput(BaseModel):
keyword: str = Field(..., description="要在日志中搜索的关键词,例如 'Failed password', 'root', 'error'")
class SystemLogSearchTool(BaseTool):
name: str = "System Log Search Tool"
description: str = "用于在服务器系统日志中搜索特定事件。输入关键词,返回相关的日志行。这对于取证调查非常有用。"
args_schema: Type[BaseModel] = LogSearchInput
def _run(self, keyword: str) -> str:
"""执行日志搜索逻辑"""
# 模拟一些系统日志数据
mock_logs = [
"May 10 03:22:11 server sshd[123]: Failed password for root from 192.168.1.105 port 22 ssh2",
"May 10 03:22:15 server sshd[123]: Failed password for root from 192.168.1.105 port 22 ssh2",
"May 10 03:22:19 server sshd[123]: Accepted password for root from 192.168.1.105 port 22 ssh2",
"May 10 03:23:01 server kernel: [1234.56] iptables: IN=eth0 OUT= MAC=00:11:22:33:44:55 SRC=192.168.1.105 DST=192.168.1.10 LEN=60",
"May 10 03:25:00 server sudo: root : TTY=pts/0 ; PWD=/root ; USER=root ; COMMAND=/bin/cat /etc/shadow"
]
results = [log for log in mock_logs if keyword.lower() in log.lower()]
if results:
return f"找到包含 '{keyword}' 的日志:\n" + "\n".join(results)
else:
return f"未找到包含 '{keyword}' 的日志。"
#封装挂载
log_search_tool = SystemLogSearchTool()
tools=[log_search_tool, file_read_tool, directory_read_tool], # 赋予读取系统文件和搜索日志的能力

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)