人工智能|大模型 —— 量化 —— 一文搞懂大模型量化技术:GGUF、GPTQ、AWQ
目前关于大模型量化技术的文章层出不穷,但对其理论部分的深入探讨却相对较少。本文将对大模型量化技术进行系统性的介绍,并重点聚焦于理论层面的深入解析。
一、大模型量化基础
大模型量化的核心在于将模型参数的精度从较高的位宽(bit-widths)(例如 32 位浮点数)降低到较低的位宽(bit-widths)(例如 8 位整数)。
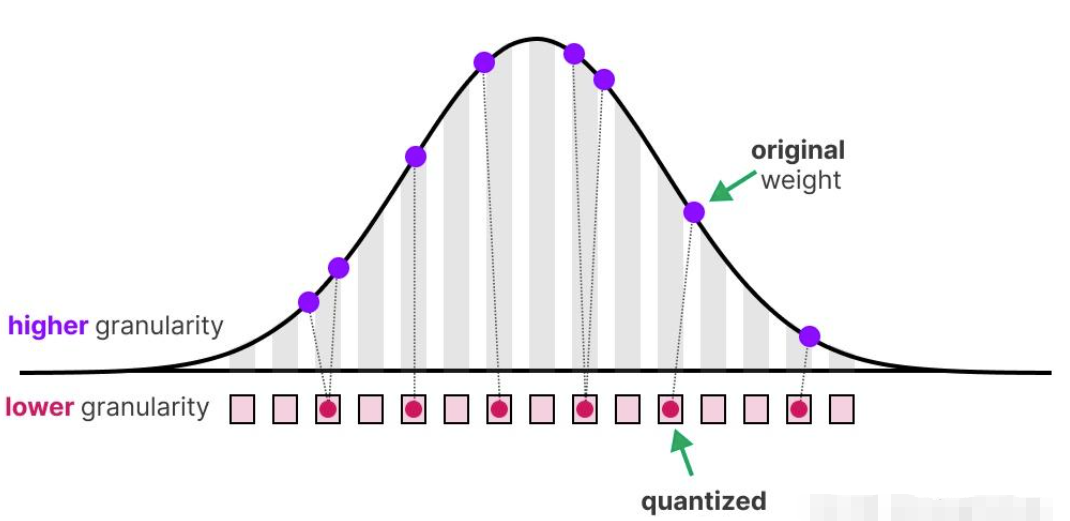
1.1 对称量化 Symmetric Quantization
在对称量化过程中,原本浮点数的值域会被映射到量化空间(quantized space)中一个以零为中心的对称区间,量化前后的值域都是围绕零点对称的。
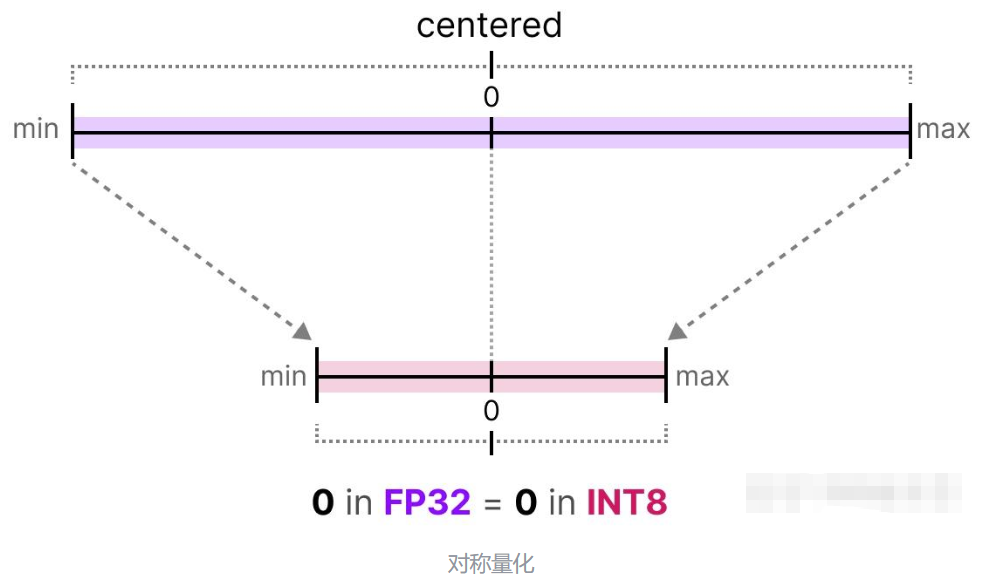
这就意味着,在浮点数中表示零的值,在量化空间中仍然正好为零。
对称量化(symmetric quantization)有一种经典方法是绝对最大值(absmax,absolute maximum)量化。
具体操作时,我们会从一组数值中找出最大的绝对值( ),以此作为线性映射的范围。
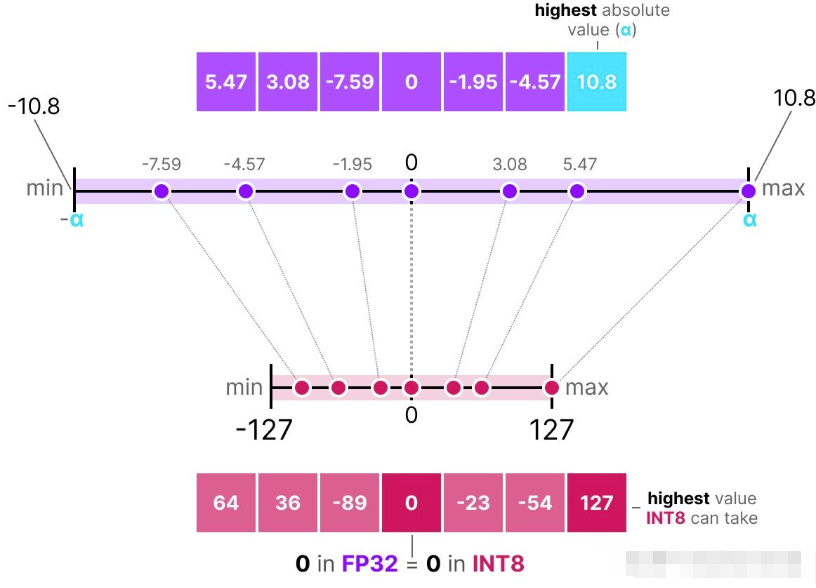
由于这是一种以零为中心的线性映射(linear mapping),所以计算公式相对简单。计算方式如下:

为了恢复原始的 FP32 值,我们可以使用之前计算出的比例因子(s)来对量化后的数值进行反量化(dequantize)。

先量化后再反量化以恢复原始值的过程如下所示:
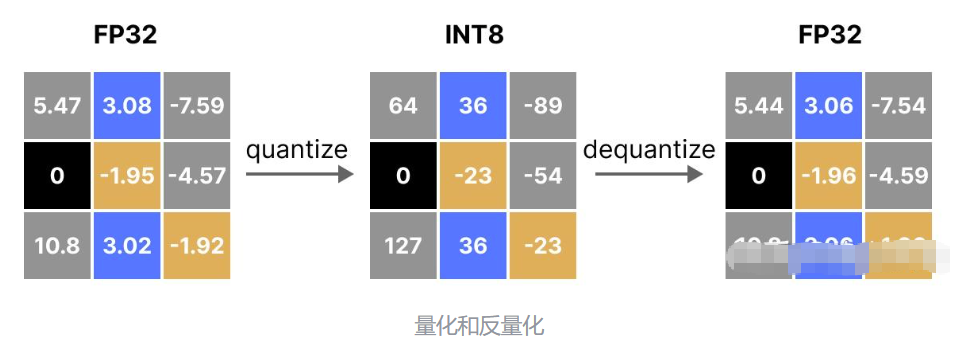
我们可以观察到,某些值(如 3.08 和 3.02 )在量化到 INT8 后,都被分配了相同的值 36。当这些值反量化(dequantize)回 FP32 时,会丢失一些精度,变得无法再区分。
这种现象通常被称为量化误差(quantization error),我们可以通过比较原始值(original values)和反量化值(dequantized values)之间的差值来计算这个误差。

1.2 非对称量化 asymmetric quantization
与对称量化(symmetric around)不同,非对称量化并不是以零为中心对称的。它将浮点数范围中的最小值(β)和最大值(α)映射到量化范围(quantized range)的最小值和最大值。
我们在此要探讨的方法称为零点量化。
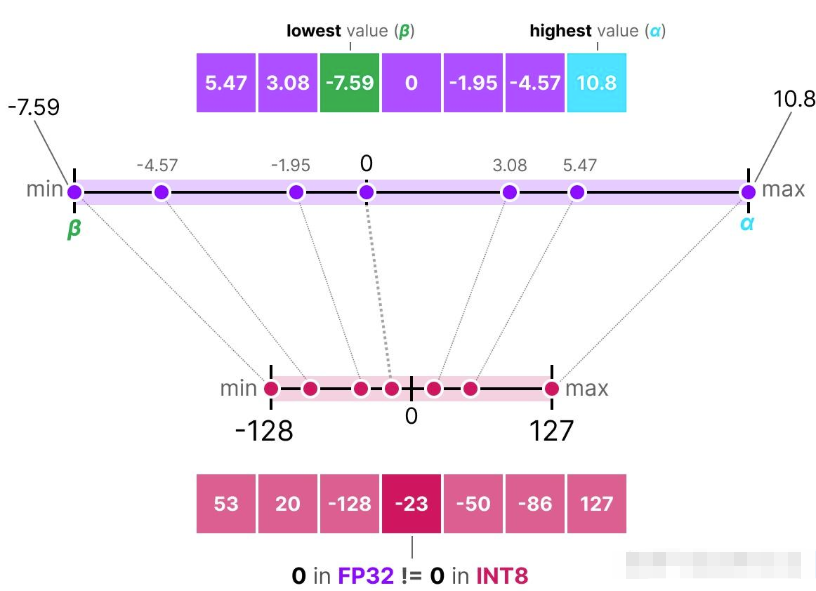
我们注意到 0 的位置发生了移动,这正是它被称为“非对称量化”的原因。在区间 [-7.59, 10.8] 中,最小值和最大值与零点之间的距离是不相等的。
由于零点位置的偏移,我们需要计算 INT8 范围的零点来进行线性映射(linear mapping)。与之前一样,我们还需要计算一个比例因子(s),但这次要使用 INT8 范围( [-128, 127] )的两个端点之间的差值。

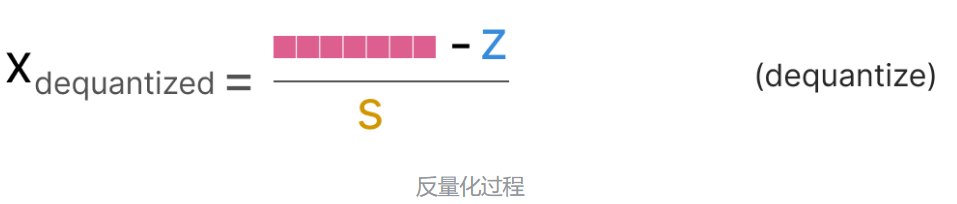
反量化过程则相对比较直接:
1.3 GGUF 量化
GGUF 通常使用分组量化(Group-wise Quantization),比如将权重矩阵分成多个小块,每个块单独进行量化和缩放。例如,Q4_0 量化可能将权重分成 32 个元素一组,每个组使用 4 位整数存储,并配有一个缩放因子(scale)。
好的!以下是一个针对 **单权重矩阵 W** 的 **GGUF量化(Q4_0类型)** 的具体数值计算示例,展示如何从原始FP32矩阵转换为4位量化格式。
假设原始权重矩阵为:
W = [
[0.28, -1.32, 0.66, 2.10],
[0.91, -0.45, -0.72, 1.80],
[-0.34, 1.22, -0.89, -1.50],
[0.15, -0.60, 0.33, 0.92]
]步骤 1:分组(Grouping)
GGUF的 Q4_0 量化将矩阵按行分组(默认每组 32 个元素,但此处简化为 4x4 矩阵,每组 4 元素):
Group 1: [0.28, -1.32, 0.66, 2.10] # 第一行
Group 2: [0.91, -0.45, -0.72, 1.80] # 第二行
Group 3: [-0.34, 1.22, -0.89, -1.50] # 第三行
Group 4: [0.15, -0.60, 0.33, 0.92] # 第四行步骤2:计算缩放因子(Scale)和零点(Zero Point)
对每个分组分别计算:
-
- 缩放因子(scale):
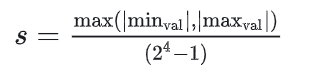
- 计算零点(zero point)
- 缩放因子(scale):
步骤 3:使用对称量化或非对称量化对每一组进行量化
二、GPTQ
前面介绍的量化方法都是不考虑量化误差的,因此效果往往比较差。接下来我们介绍下后训练量化方法,考虑量化误差的情况下,提升量化效果。
2.1 OBS:Optimal Brain Surgeon[1]
OBS 认为,参数之间的独立性实际上是一种剪枝方法,用于降低模型复杂度,提高泛化能力。



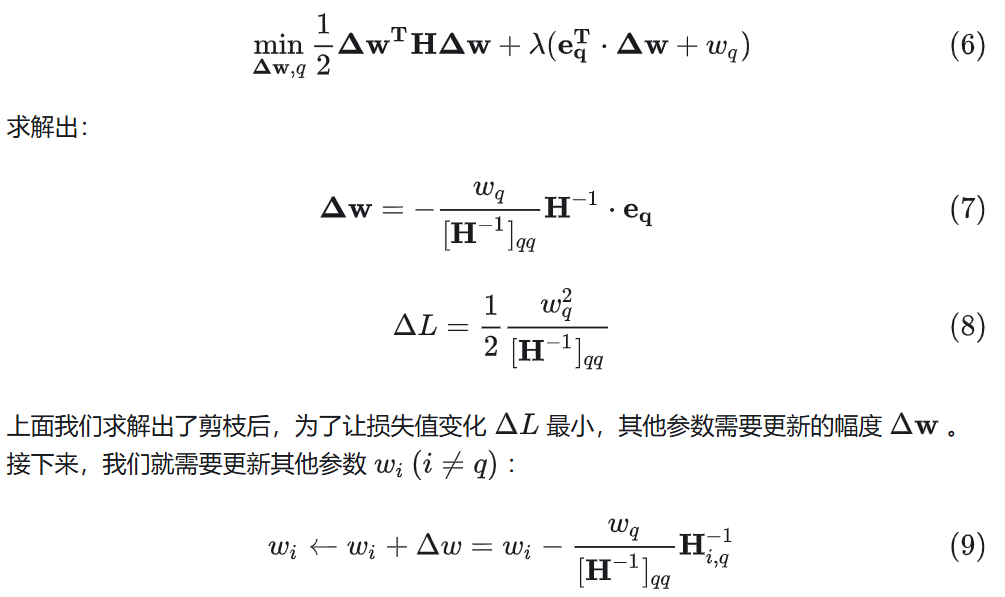
如果将 OBS 剪枝的思路用在大模型量化,
2.2 OBC:Optimal Brain Compression[2]
2.2.1 OBS 用于分层剪枝或量化
前面的 OBS 是对整个神经网络进行剪枝,而 OBC 是对神经网络模型分层剪枝或者量化。首先将层剪枝问题抽象为优化问题。



2.2.2 ExactOBS





import numpy as np
def remove_row_col_hinv(Hinv, p):
"""
使用 Lemma 1 更新 H^{-1},删掉第 p 行和第 p 列。
Hinv: 原始 H^{-1} 矩阵 (对称正定)
p: 要移除的索引
"""
Hinv = Hinv.copy()
hpp = Hinv[p, p]
hp = Hinv[:, p].reshape(-1, 1) # 第 p 列,列向量
update = (hp @ hp.T) / hpp
Hinv_updated = Hinv - update
# 删除第 p 行和第 p 列
mask = np.ones(Hinv.shape[0], dtype=bool)
mask[p] = False
return Hinv_updated[np.ix_(mask, mask)]
np.random.seed(0)
# 构造一个 3x5 的输入矩阵 X
X = np.random.randn(3, 5)
# 构造一个 3x3 正定 Hessian 矩阵 H = 2XX^T
H = 2 * X @ X.T
# 计算其逆
Hinv = np.linalg.inv(H)
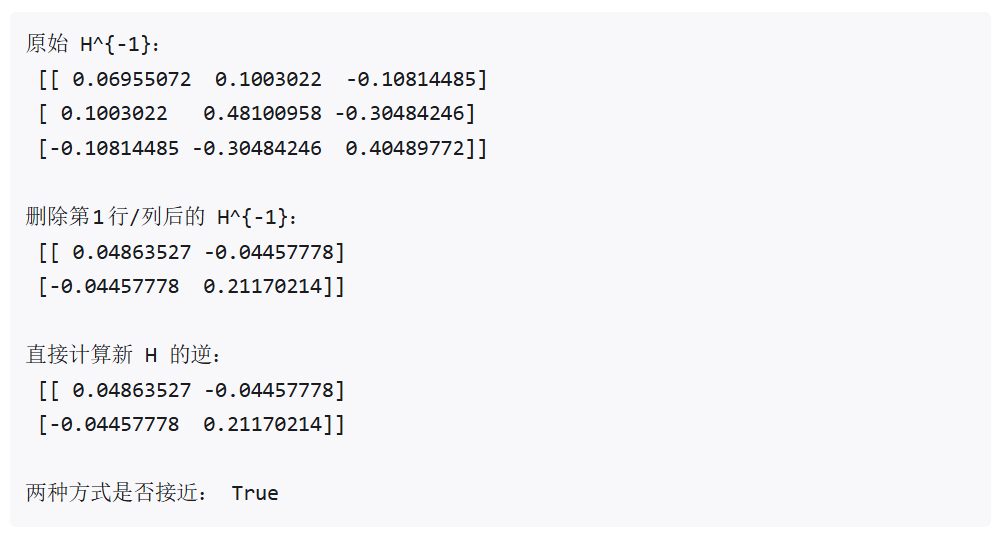
print("原始 H^{-1}:\n", Hinv)
# 用 Lemma 1 计算删除 X 中第 1 行第 1 列后的 Hessian 矩阵的逆矩阵
Hinv_removed = remove_row_col_hinv(Hinv, p=1)
print("\n删除第1行/列后的 H^{-1}:\n", Hinv_removed)
# 验证:删掉 H 的第1行和列后,重新求逆,看看是否一样
H_removed = H[np.ix_([0, 2], [0, 2])]
Hinv_true = np.linalg.inv(H_removed)
print("\n直接计算新 H 的逆:\n", Hinv_true)
# 比较两个结果是否一致
print("\n两种方式是否接近:", np.allclose(Hinv_removed, Hinv_true))下面是执行上面代码的输出结果,可以看到结果完全一致。






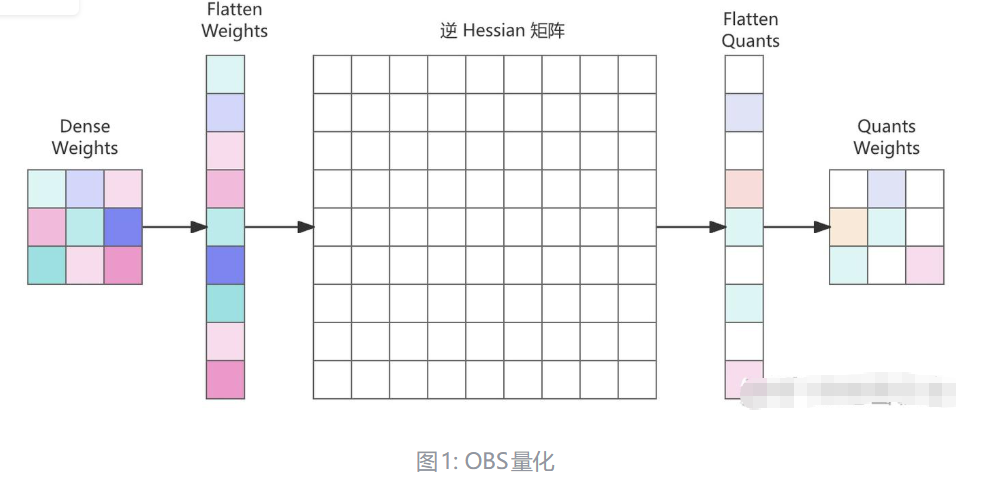
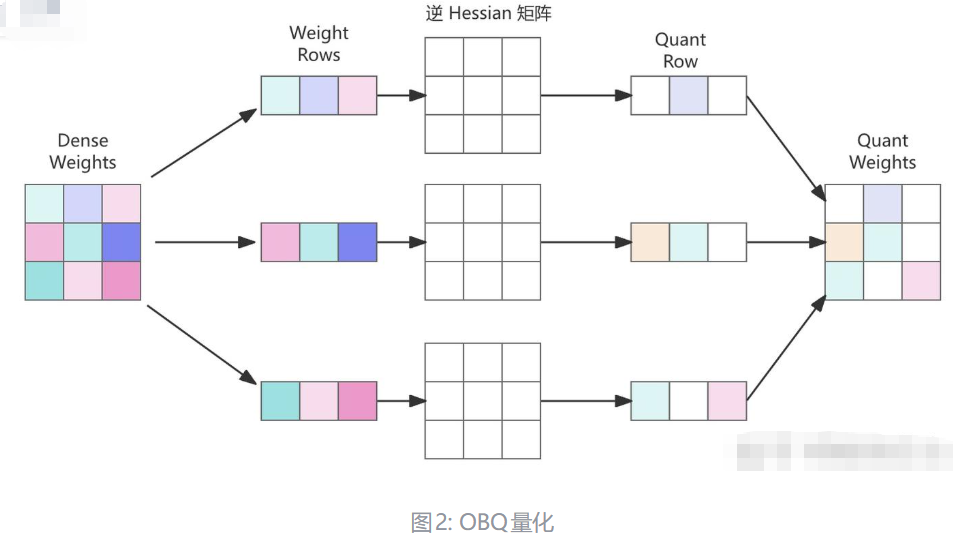
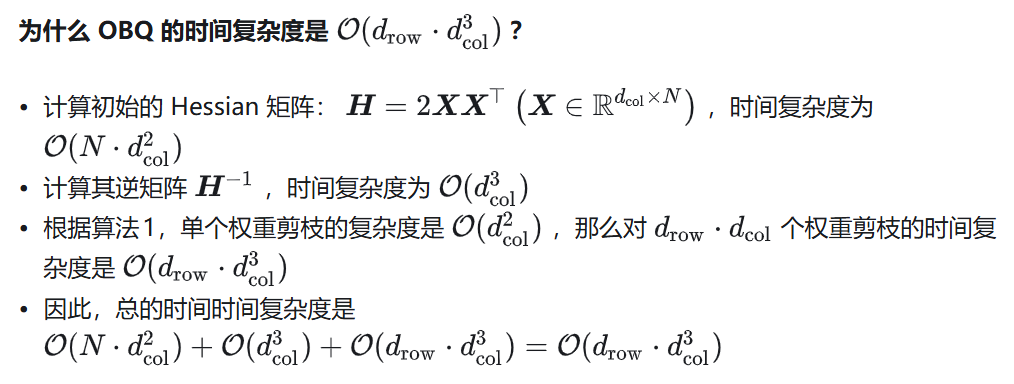
2.3 GPTQ:一种新的后训练量化方法

GPTQ 作者提出了一个经验发现:
对于大规模、参数众多的层,即使不使用贪心策略,只要采用任意固定顺序来量化每一行中的权重,最终的误差几乎和贪心顺序一致。
也就是说:原来每一行都维护自己的“最优量化顺序”,现在所有行都使用相同的顺序。虽然理论上不是局部最优,但整体误差变化非常小,尤其在参数数量大的时候几乎无影响。
之所以可行,主要有两个原因:
- 大模型冗余性高:由于大模型极度冗余,单个权重引入的误差影响微小,统一顺序导致的子最优选择不会积累为显著性能损失。
- 量化误差可补偿:GPTQ 中使用的 Hessian-based 误差补偿机制会在每一步自动对未量化权重进行调整,进一步抑制误差传播。
- 统一顺序量化带来的优化空间巨大:这项改进使得参数矩阵每一行的量化可以做并行的矩阵计算,则:
- 所有行共享一个逆 Hessian 矩阵
- 对 Hessian 的逆矩阵只需更新一次
下面计算顺序量化的时间复杂度:


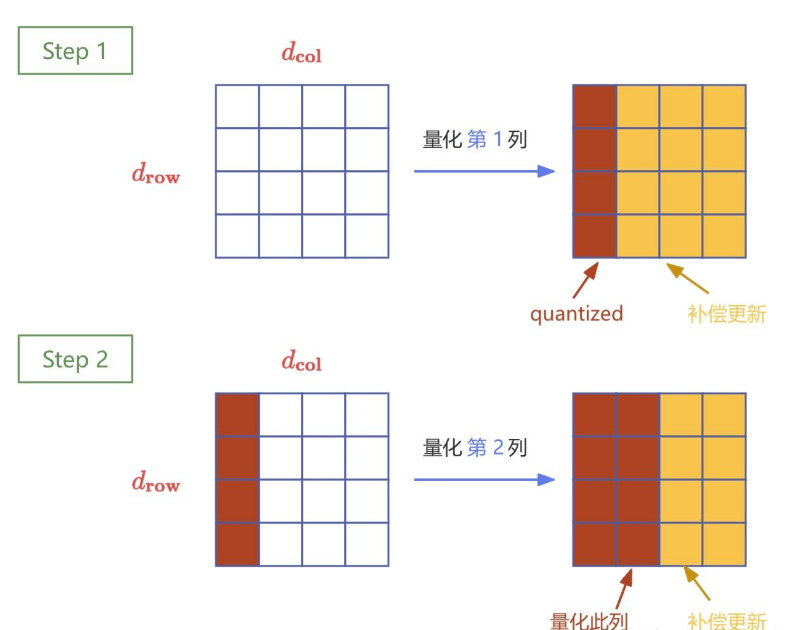
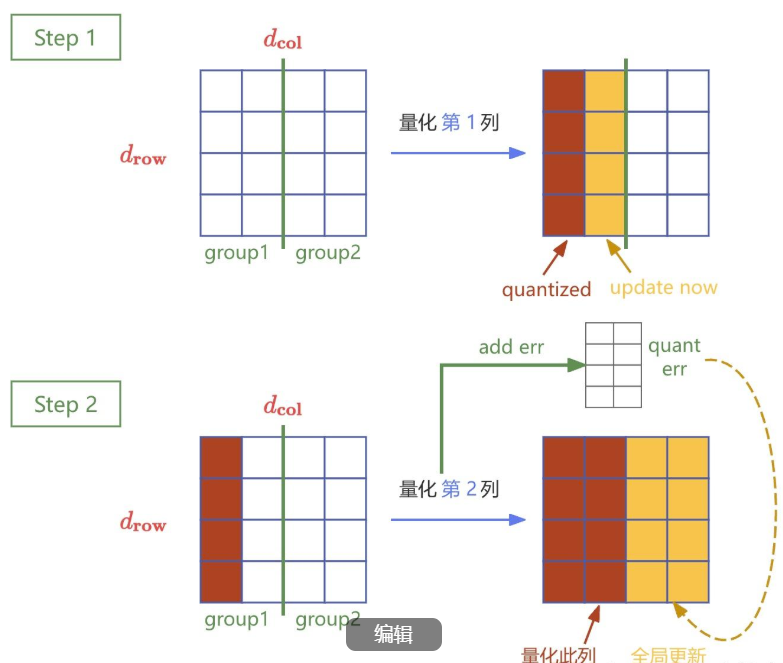
为了提升效率,GPTQ 引入了 Lazy Batch-Updates 技术,该技术通过分块 (batching) 的方式减少内存访问次数,从而显著提高计算效率。




三、AWQ
虽然前面的 GPTQ 通过校准数据最小化量化误差,提升量化效果。但是可能过拟合校准集,导致模型在分布外域上的性能下降。
而 AWQ(Activation-aware Weight Quantization) 不进行回归或重建,仅通过统计校准集中的激活值来选择关键权重并进行缩放。种基于激活分布的策略不会直接修改模型权重,因此可以更好地保留模型的原始特性和知识。
AWQ 具体方法:
- 通过激活分布(按大小)选择 1% 关键权重
- 通过缩放关键权重降低量化误差
3.1 什么是AWQ?
现有方法的局限性
- 低比特量化被认为是解决这一问题的方法之一,通过降低模型权重的精度来减小内存占用并加速推理。然而:
- 量化感知训练(QAT):需要重新训练模型,计算成本极高,不适用于大规模LLMs
- 后训练量化(PTQ):无需重新训练,但在低比特(如4-bit)情况下会显著降低模型性能。
现有工作的问题:
- GPTQ 等方法尝试利用二阶信息来补偿量化误差,但这些方法可能过拟合校准集,导致模型在分布外的领域或模态上性能下降
- 混合精度量化虽然能提升性能,但硬件效率低
解决方案:AWQ(Activation-aware Weight Quantization)
- 核心思想:
- 通过观察发现:并非所有权重对模型性能的重要性相同
- 保护模型中仅 1% 关键权重(salient weights)可以显著降低量化误差
- 关键权重的选择应基于激活分布(activation distribution)而不是权重本身的分布
3.2 保护 1% 关键权重(Salient Weights)
作者提出并非所有权重对模型性能的贡献相同。模型中仅有小部分权重(约0.1%-1%)对性能至关重要,这些权重被称为关键权重(salient weights)。量化这些关键权重会对性能产生显著影响,而量化其他权重的影响较小。
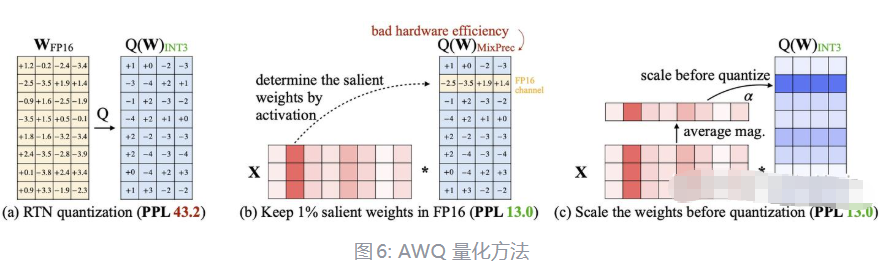
如果对关键权重进行保护(即避免量化或降低量化误差),可以显著减少模型性能下降。例如,在 OPT-6.7B 模型中,困惑度(PPL)通过保护关键权重从 43.2 降至 13.0(如图6(a)、(b)所示)。
如何识别关键权重
- 传统方法的局限性:
- 过去的研究通常通过权重的大小(magnitude)或 L2 范数来判断权重的重要性
- 然而,实验表明,基于权重本身选择关键权重的效果有限,无法显著改善模型性能
- 激活感知方法(Activation Awareness):
- 本文提出了一项新的观察:权重的重要性更多地体现在其对应的激活分布(activation distribution)上,而非权重本身的大小。
- 核心思想:
- 激活值较大的通道更重要,因为这类通道处理了更多关键特征
- 对应的权重通道应被视为关键权重,优先保护以减少量化误差
- 通过激活分布选择关键权重比通过权重本身分布更有效
实验验证
- 目标:探讨保留少量关键权重(salient weights)为 FP16 格式对低比特量化模型性能的提升效果
- 量化设置:INT3 量化(权重为3-bit)
- 数据指标:通过困惑度 PPL 衡量模型性能,PPL 值越低表示模型性能越好
- 对比方法:
- RTN(Round-to-nearest):直接采用四舍五入量化,作为基线
- 基于激活分布保留关键权重(FP16% (based on act.))
- 基于权重分布保留关键权重(FP16% (based on W))
- 随机保留权重(FP16% (random))
实验结果对比:
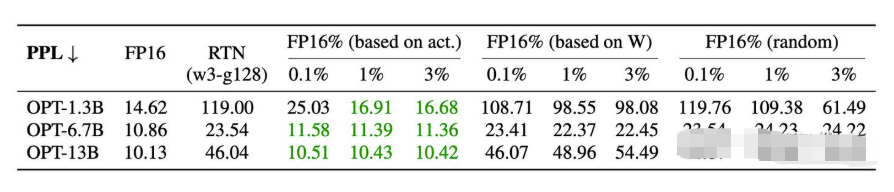
从上面的实验结果来看,基于激活分布保留关键权重的效果最好,而保留 1% 激活值和保留 3% 激活值的效果相差不大。
3.3 通过缩放关键权重降低量化误差
3.3.1 分析量化误差
量化误差的来源



实验结果如下:
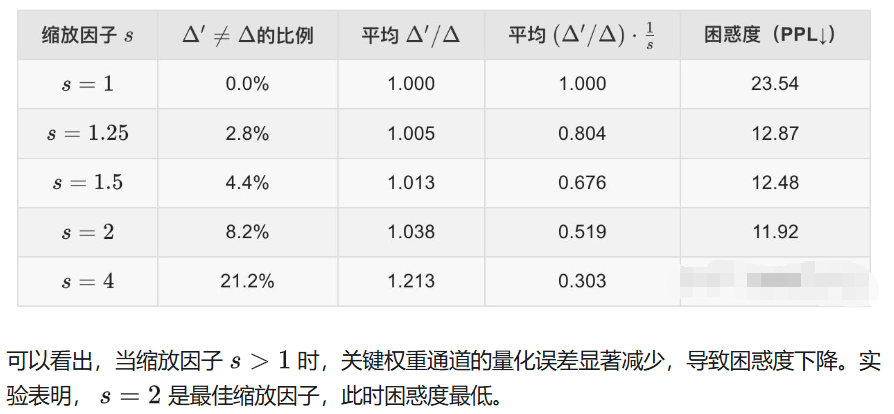
3.3.2 搜索缩放因子
这一部分介绍了如何通过搜索方法为关键权重通道找到最佳的缩放因子 ,以最小化量化误差并优化模型性能。
搜索缩放因子是 AWQ 方法的核心之一,通过缩放关键权重通道的值,可以减少量化误差,同时避免对非关键权重通道引入过多的误差。



3.4 实验
下图是在 Llama 上的实验结果:
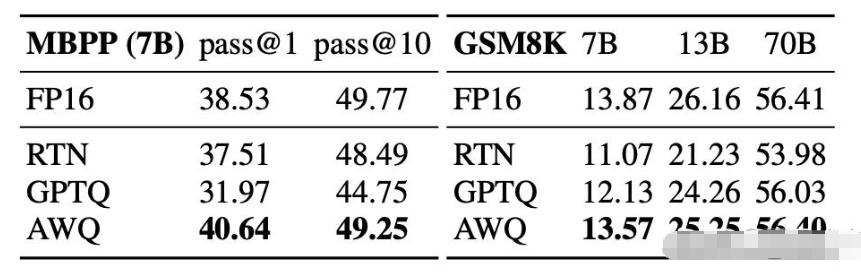
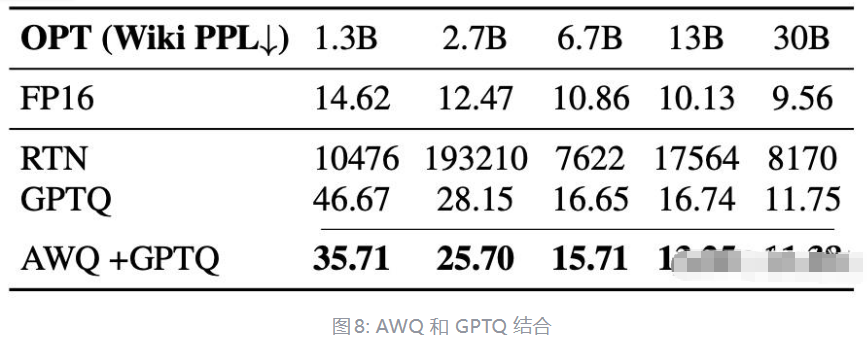
而将 AWQ 和 GPTQ 相结合,可以进一步提升效果。
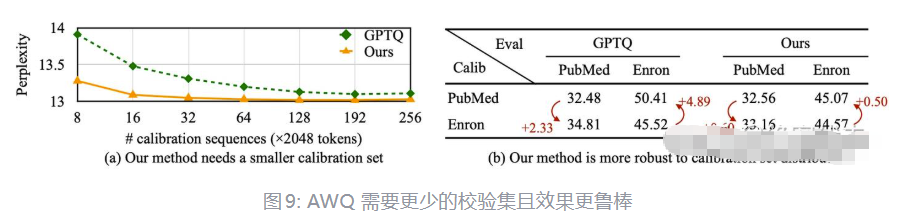
下图显示了 AWQ 需要更少的校验集,而且对不同分布的校验集更鲁棒。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)