Qwen 3 技术解析:通过强化学习和思维模式融合提升模型对齐
今天为大家分享近期阿里发布的Qwen3技术报告,特别是Qwen3如何通过一系列精密的后训练(Post-training)过程,从一个强大的基础模型,蜕变成一个更加智能、灵活、且与人类偏好高度对齐的助手。这就像是给大模型装上了“智慧大脑”和“沟通桥梁”的升级过程。
今天为大家分享近期阿里发布的Qwen3技术报告,特别是Qwen3如何通过一系列精密的后训练(Post-training)过程,从一个强大的基础模型,蜕变成一个更加智能、灵活、且与人类偏好高度对齐的助手。这就像是给大模型装上了“智慧大脑”和“沟通桥梁”的升级过程。
一、为什么需要后训练?
想象一下,我们辛辛苦苦训练出了一个拥有海量知识的基础大模型。它能记住无数事实、理解复杂的语法结构,甚至具备潜在的推理能力。但这还不够!就像一个学富五车的学者,如果他不了解如何有效地与人沟通、不明白你的具体需求,或者无法根据情境调整自己的表达方式,他的学识就难以充分发挥价值。
大语言模型(LLMs)的基础模型(Base Model)在海量数据上预训练后,虽然掌握了基础能力,但它们并不能直接理解和遵循人类的复杂指令,也无法自然地与人互动,更不用说根据用户的偏好或特定任务需求来调整行为。它们可能不知道何时需要一步步推理(思维),何时需要直接给出答案(非思维),也不知道如何生成符合特定格式、长度或风格的文本。
后训练的目标是将基础模型与人类偏好和下游应用更好地对齐。简单来说,就是教模型“读懂人心”,让它知道我们想要什么,并以我们希望的方式来回应。Qwen3的后训练尤其强调两大目标:思维控制,让模型能选择是否推理以及控制推理深度;以及强到弱蒸馏,利用大模型的知识高效地训练小模型。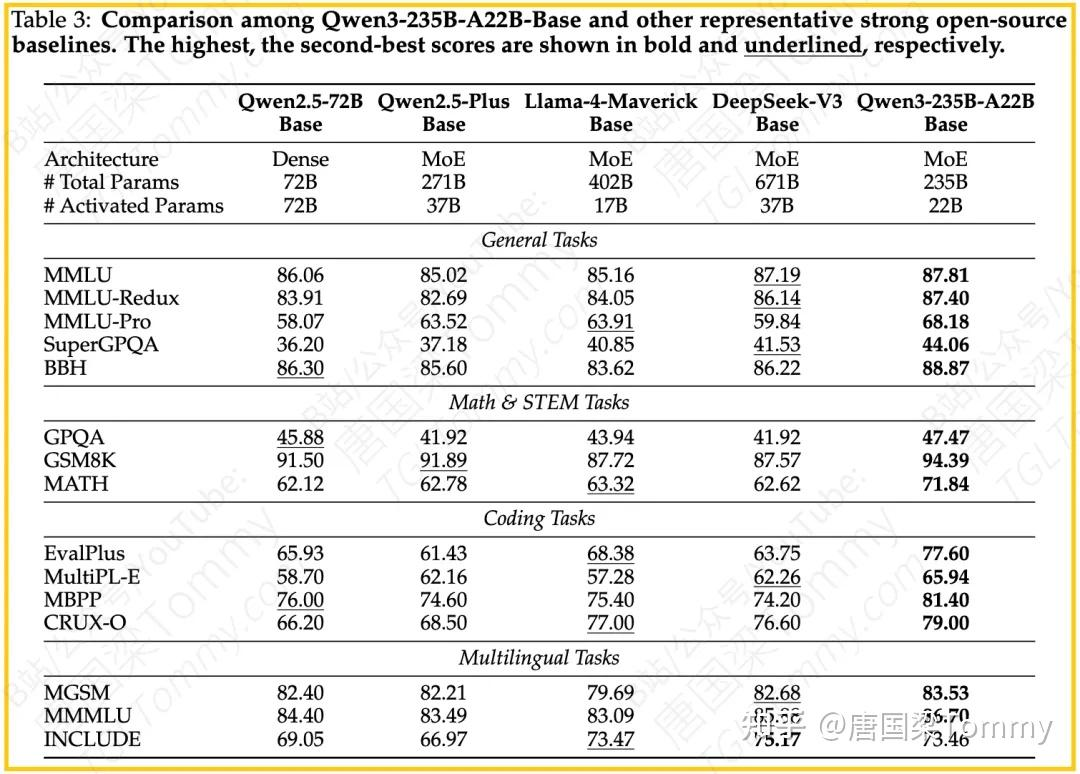
二、核心目标:思维控制与强到弱蒸馏
Qwen3的后训练不只是简单的指令微调,它有更深层次的设计。
-
思维控制(Thinking Control):我们知道,对于一些复杂问题,比如数学题、编程任务或逻辑推理,模型一步一步地思考(Chain-of-Thought, CoT)往往能得到更准确的结果。但对于简单问题,用户可能只想要一个直接答案。Qwen3的后训练目标之一,就是赋予模型这种“思维控制”的能力。它能够整合“非思维”(Non-thinking)和“思维”(Thinking)两种模式。用户可以通过特定的方式(例如,论文中评估时可能使用 /think 和 /no think 模式)来选择是否进行推理,甚至通过指定一个“token预算”来控制思维的深度。这大大提高了模型的灵活性和用户体验。

-
强到弱蒸馏(Strong-to-Weak Distillation):训练强大的大模型计算成本高昂。如何让小模型也拥有接近大模型的指令遵循和推理能力?强到弱蒸馏是关键。通过利用更大、更强的模型(如Qwen3-235B-A22B)作为“教师”,来指导和优化轻量级模型(如Qwen3-0.6B到14B,以及MoE模型Qwen3-30B-A3B)的后训练过程。这种方法显著降低了训练较小模型的计算成本和开发工作量,同时还能赋予它们强大的模式切换能力和更好的性能。
三、方法解析:四阶段训练与高效蒸馏
Qwen3的旗舰模型遵循一个复杂的四阶段训练过程。前两个阶段主要是构建和增强模型的“思维”能力,后两个阶段则着力于将强大的“非思维”功能整合进来。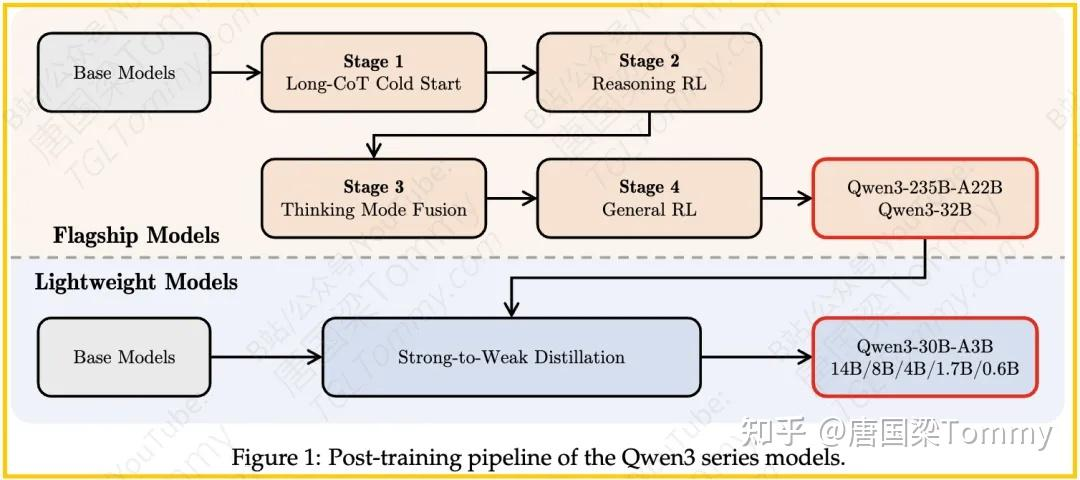
阶段一:长CoT冷启动 (Long-CoT Cold Start)
- 目标:初步向模型灌输推理模式。
- 数据:从数学、代码、逻辑推理、STEM等广泛类别中精心策划数据集。这些问题都有经过验证的参考答案或基于代码的测试用例。
- 过程:使用一个现有的模型(例如,QwenQwen-32B)为每个问题生成多个候选响应。对于模型未能得到正确答案的问题,人类标注员介入评估准确性。然后,应用严格的过滤标准筛选出高质量的响应(比如,最终答案必须正确,没有重复内容,推理过程清晰,语言风格一致等)。
- 训练:使用这个精炼后的数据集子集进行初步训练。为了有效实现目标,这个阶段的训练样本数量和训练步数都会尽量最小化,避免过度强调即时性能。这有点像让模型先“见识”一下优秀的思考过程。
阶段二:推理强化学习 (Reasoning RL)
- 目标:通过强化学习强化模型的推理能力。
- 数据:使用新的查询-验证器对,这些对数据需要满足未在冷启动中使用、模型可学习、尽可能有挑战性、且涵盖广泛子领域的要求。论文中总共收集了3,995对这样的数据。
- 算法:使用GRPO方法更新模型参数 。
- 优化:采用大批量大小、每个查询高回滚次数以及离策略训练等技术来提高样本效率。通过控制模型的熵保持稳定,可以平衡探索与利用,确保训练的稳定性。
- 效果:论文提到,这种方法使得训练奖励和验证性能在单次RL运行中持续提高,无需手动调整超参数。例如,Qwen3-235B-A22B模型在AIME’24基准上的分数在170个RL训练步骤中显著提升(从70.1提高到85.1)。
阶段三:思维模式融合 (Thinking Mode Fusion)
- 目标:将强大的“非思维”功能整合到已经具备推理能力的模型中。这个阶段旨在让模型在需要快速、直接回答时,也能表现出色。
- 过程:将经过前两个阶段训练、已经掌握思维能力的模型,与非思维模式进行整合。
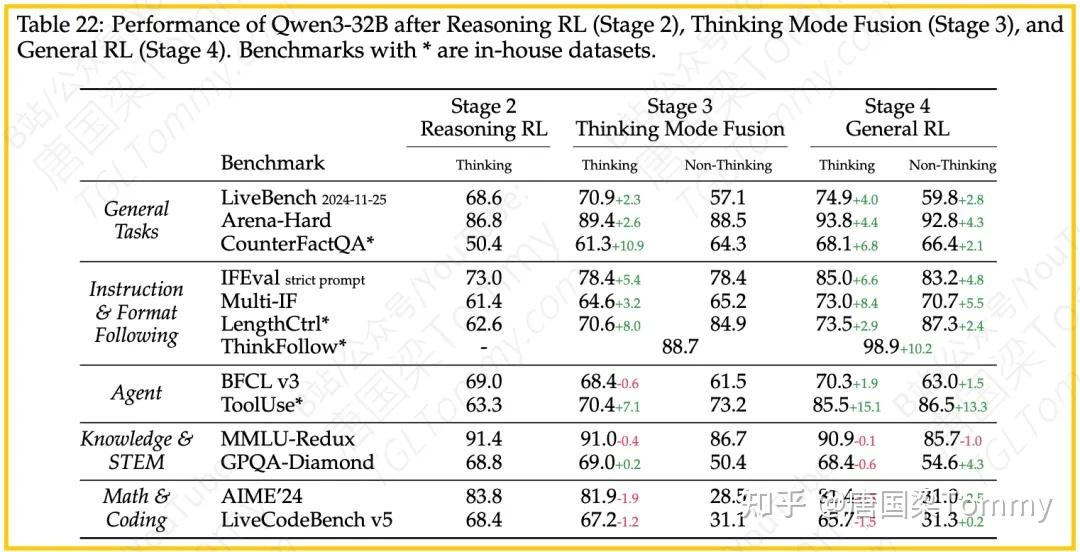
- 效果:论文讨论显示,对于Qwen-32B模型,这一阶段将非思维模式整合后,模型初步具备了模式切换能力(ThinkFollow得分88.7)。同时,在思维模式下,模型的通用能力和指令遵循能力也得到增强(CounterFactQA得分提高10.9,LengthCtrl提高8.0。
阶段四:通用强化学习 (General RL)
- 目标:在各种场景下广泛增强模型的整体能力和稳定性。
- 奖励系统:构建了一个包含20多个不同任务、每个任务都有定制评分标准的复杂奖励系统 。这些任务旨在提升核心能力,尤其是指令遵循,确保模型能准确理解并执行用户指令,包括内容、格式、长度等要求。
- 奖励类型:使用了三种不同类型的奖励:
– 基于规则的奖励:广泛用于推理RL阶段,也适用于通用任务如指令遵循和格式遵守。精度高,能有效评估输出正确性,防止模型“奖励作弊”。
– 带参考答案的基于模型的奖励 :为每个查询提供参考答案,并使用另一个模型(如Qwen2.5-72B-Instruct)根据参考答案给模型响应打分。这种方式更灵活,能处理多样化任务,避免纯规则奖励可能出现的假阴性。
– 不带参考答案的基于模型的奖励 :利用人类偏好数据训练奖励模型,直接给模型响应打分,不依赖参考答案。这使得模型能处理更广泛的查询,有效增强了互动性和有用性。 - 效果:论文讨论指出,通用RL进一步强化了模型在思维和非思维模式下的通用能力、指令遵循能力和Agent能力。模式切换的准确性也显著提高(ThinkFollow得分达到98.9)。然而,值得注意的是,这一阶段在增强通用能力的同时,对于知识、STEM、数学和编码等任务,在思维模式下的性能可能有所下降。这可能是因为模型在更广泛的任务上进行了训练,牺牲了一部分处理复杂专业问题的能力。论文认为,为了增强模型的整体多功能性,接受这种性能权衡是值得的。
四、强到弱蒸馏流程
- 目标:高效地优化轻量级模型(0.6B、1.7B、4B、8B、14B密集型模型和30B-A3B MoE模型)。
- 过程:分为两个阶段:
– 策略蒸馏 (Off-policy distillation):结合教师模型(强大的大模型)使用/think和/no think模式生成的输出进行蒸馏。这帮助学生模型(小模型)学习基本的推理技能和在不同模式间切换的能力。
– 非策略蒸馏 (On-policy distillation):学生模型生成自身的序列进行微调。通过将学生模型的logit(输出概率)与教师模型(Qwen3-32B或Qwen3-235B-A22B)的logit对齐,最小化KL散度来进行训练。 - 效果:论文指出,直接将教师模型的输出logit蒸馏给学生模型,能有效提升学生模型的性能,同时保持对其推理过程的精细控制。这种方法避免了为每个小模型单独执行完整的四阶段后训练过程。实验表明,它带来了更好的即时性能(更高的Pass@1分数)和探索能力(更高的Pass@64结果),并且训练效率更高,仅需完整四阶段训练所需GPU小时的1/10。
五、实验结果与分析
Qwen3的后训练效果通过广泛的自动基准测试进行了评估。评估涵盖了模型的思维和非思维模式。
- 评估基准:使用了多个维度的基准来全面衡量模型质量:
- 通用任务:包括MMLU-Redux, GPQA-Diamond, C-Eval, LiveBench。
- 对齐任务:评估模型与人类偏好的一致性,使用IFEval (strict prompt), Arena-Hard, AlignBench, Creative Writing, WritingBench。
- 数学与文本推理:评估数学和逻辑推理能力,使用MATH-500, AIME’24, AIME’25, ZebraLogic, AutoLogi。
- Agent 与编码:测试模型在编码和基于Agent任务中的能力,使用BFCL v3, LiveCodeBench v5, Codeforces Ratings。
- 多语言任务:评估指令遵循(Multi-IF,8种语言)、知识(INCLUDE,44种语言;MMMLU,14种语言)、数学(MT-AIME2024,55种语言;PolyMath,18种语言)和逻辑推理(MLogiQA,10种语言)。为了效率,INCLUDE和MMMLU只使用了10%的原始数据进行评估。论文附录中提供了多种语言(如西班牙语、法语、葡萄牙语、意大利语、阿拉伯语、日语、韩语、印尼语、俄语、越南语、德语、泰语)的详细分数。Belebele基准也用于评估跨语言族的性能。
- 关键结果分析:
-
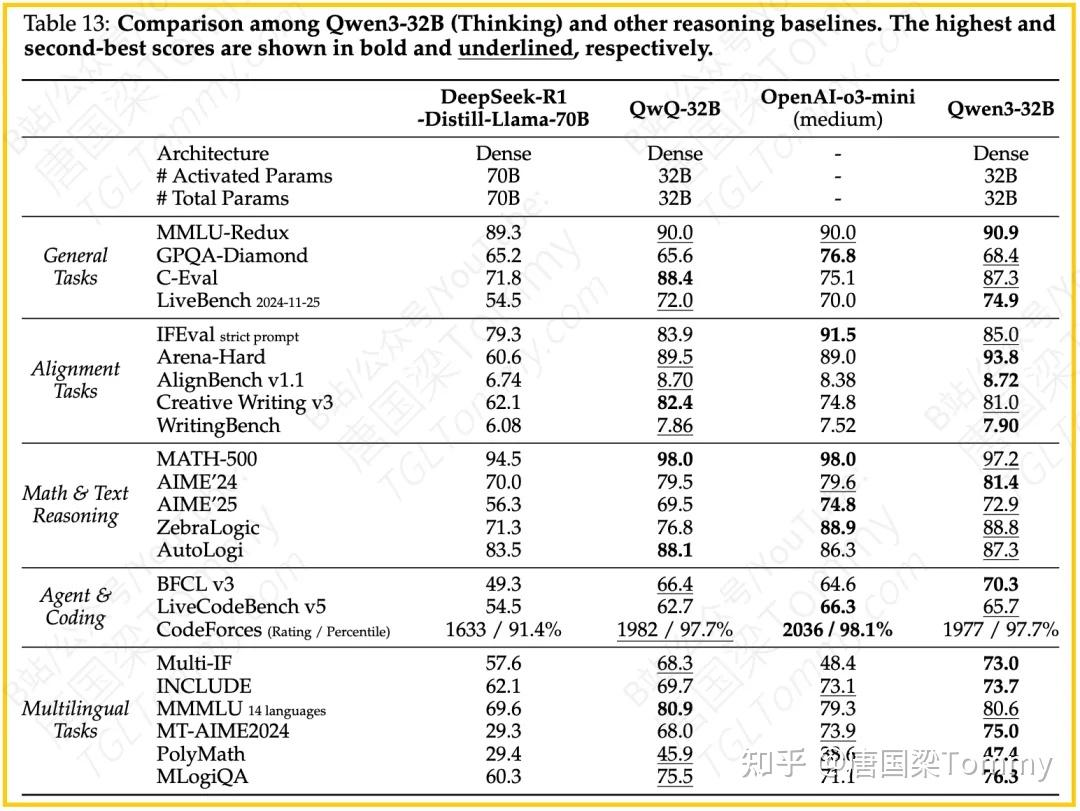
思维模式 vs 非思维模式:评估结果(如表13-20所示)表明,在需要复杂推理的任务(如MATH, AIME, AutoLogi)上,“思维模式”通常能获得显著更高的分数。例如,Qwen3-235B-A22B在AIME’24上,思维模式得分85.7,而非思维模式仅为40.1。这验证了CoT推理的有效性。
-
与基线的比较:Qwen3系列模型在多个基准上展现出强大的竞争力。
– Qwen3-235B-A22B (Thinking) 在MATH-500、AIME’24、AIME’25、AutoLogi、BFCL v3、LiveCodeBench v5、Codeforces 等推理和编码任务上表现突出,与顶尖模型(如Gemini2.5-Pro, DeepSeek-R1, OpenAI-o1/o3-mini)相比具有优势或竞争力。在对齐任务如Arena-Hard和AlignBench v1.1上也表现出色。
– Qwen3-235B-A22B (Non-thinking) 在对齐任务上表现优异,尤其在Arena-Hard上得分96.1,高于GPT-4o和DeepSeek-V3。
– Q较小模型(如Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B)在各自参数量级别上,无论在思维模式还是非思维模式下,通常都能超越或与许多开源基线模型(如Qwen2.5系列, Gemma-3系列, Llama系列)匹敌甚至领先。例如,Qwen3-32B (Thinking) 在众多数学、推理和编码基准上得分领先或接近最佳。Qwen3-14B (Thinking) 在MATH-500、AIME等任务上得分很高。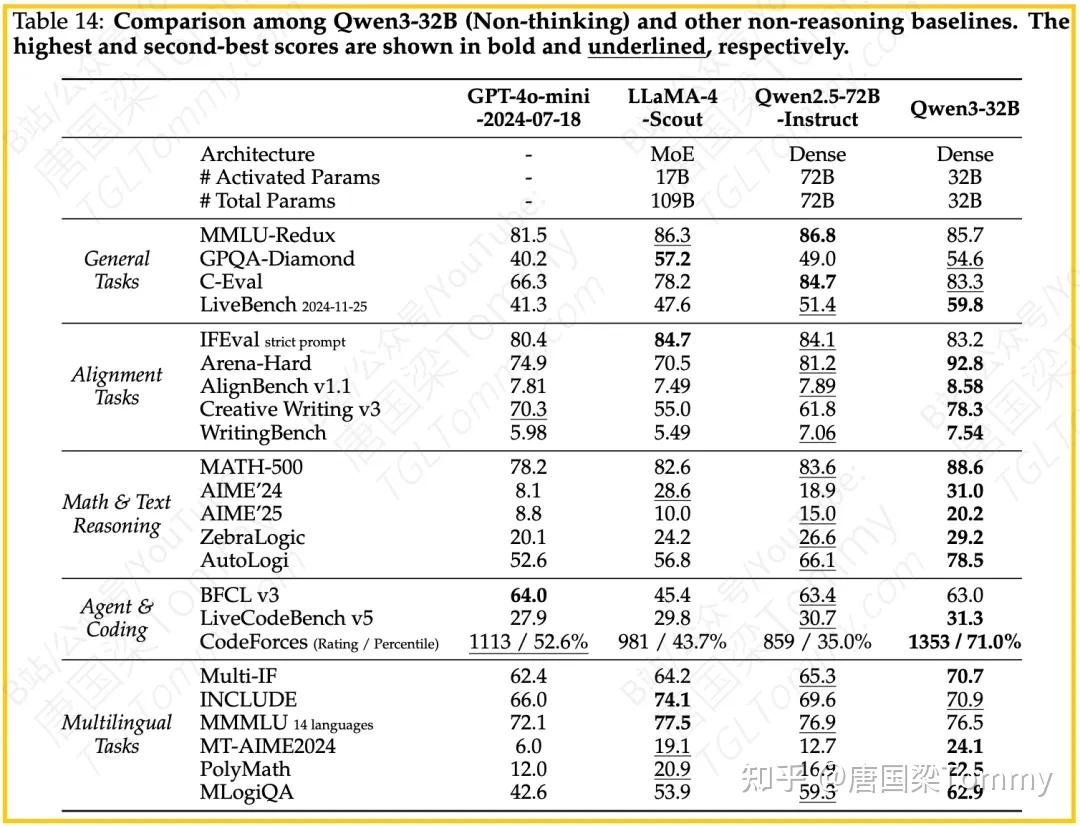
-
多语言能力:多语言评估(如表15, 18, 20, 22, 24, 26, 28, 30, 32, 34, 38-57所示)显示,Qwen3在多种语言的指令遵循、知识、数学和逻辑推理任务上表现良好。Belebele基准的评估也支持其跨语言族的多语言理解能力。
- 后训练阶段的影响:论文讨论了不同后训练阶段对模型性能的影响。通用RL(阶段四)显著提高了模式切换的准确性(ThinkFollow从88.7提升到98.9)。但如前所述,它也可能导致在思维模式下,某些特定领域的挑战性任务表现下降。这反映了通用性和专业性之间的权衡。
六、启示与展望
Qwen3的后训练策略为我们提供了宝贵的启示。首先,将“思维”和“非思维”模式显式区分并通过后训练融合,再辅以用户控制,是提升大型模型灵活性和用户体验的有效途径。其次,多阶段、精细设计的强化学习(包括推理RL和通用RL)以及复杂多样的奖励信号,对于模型能力的全面提升和行为对齐至关重要。再次,强到弱蒸馏技术是高效复用大模型能力、快速赋能轻量级模型的强大工具。
展望未来,论文讨论中提到,进一步延长模型的输出长度(超过32K)有望进一步提高模型性能。长上下文能力(如RULER基准测试所示,Qwen3模型在非思维模式下表现良好,支持到128K) 与思维控制的结合,可能会解锁更复杂的长文本推理和生成任务。如何更优雅地平衡模型的通用能力与在特定专业领域的顶尖性能,以及如何进一步优化强到弱蒸馏过程,使其在不牺牲太多性能的前提下,将强大的思维能力更好地迁移到更小的模型中,都是未来值得探索的方向。
总的来说,Qwen3的后训练方法是一套系统性、多管齐下的策略,它不仅让基础模型学会了“听话”,更教会了它如何“思考”并根据需要选择是否“思考”,以及如何更高效地将这些能力赋予给不同规模的模型。这为构建真正智能、实用的大模型迈出了坚实的一步。
参考文献
论文名称: Qwen3 Technical Report
第一作者: 阿里
论文链接: https://arxiv.org/abs/2505.09388
发表日期: 2025年5月14日
GitHub:https://github.com/QwenLM/Qwen3

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)