LightOnOCR-2-1B:1B小模型吊打9倍大模型,速度快3倍还开源了
LightOnOCR-2-1B的发布标志着文档OCR技术的一个重要里程碑。凭借端到端架构、精心设计的训练数据和高效的模型设计,它在准确率、速度和易用性三个维度都树立了新标杆。核心优势总结:性能领先: 在OlmOCR-Bench上超越所有同等规模甚至更大规模的竞品高效实用: 处理速度比主流方案快2-5倍,成本仅为大型VLM的几分之一完全开源: Apache 2.0协议,包含模型、数据集和训练细节灵活

模型地址:https://huggingface.co/lightonai/LightOnOCR-2-1B
LightOnOCR-2-1B:轻量级高性能端到端OCR系列模型
引言
在文档处理领域,OCR(光学字符识别)技术一直是将纸质文档转换为可编辑文本的关键。传统OCR系统通常依赖复杂的多阶段流水线,不仅难以训练,还容易在适配新数据时出现各种问题。而最近发布的LightOnOCR-2-1B模型家族彻底改变了这一局面。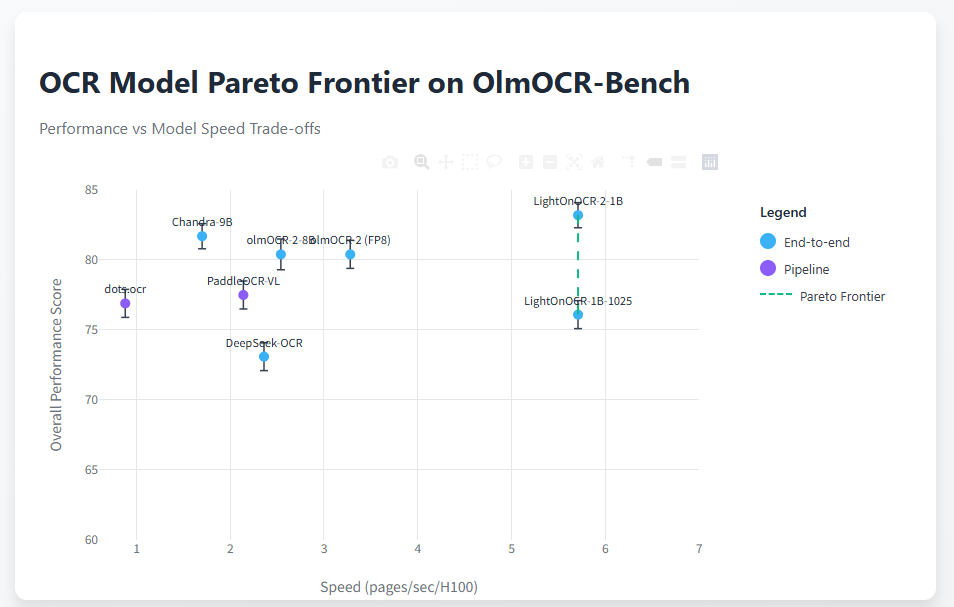
这个仅有10亿参数的端到端视觉语言模型,在OCR领域的表现令人惊艳:它不仅在OlmOCR基准测试中超越了90亿参数的Chandra模型1.5个百分点,速度还快了3.3倍,模型体积却只有后者的九分之一。更重要的是,整个模型家族都以Apache 2.0协议开源,为文档处理领域带来了全新的可能性。
核心亮点
性能突破
LightOnOCR-2-1B在OlmOCR-Bench测试中取得了83.2±0.9的总分,成为目前该基准测试的最强模型。相比第一代版本和其他竞品,这次升级在各个类别上都实现了显著提升,特别是在ArXiv论文、含数学公式的旧文档扫描件以及表格识别方面表现尤为出色。这些进步主要得益于:
- 更大规模、更高质量的训练数据集
- 增强的科学文献覆盖
- 更高分辨率的训练策略
与竞品的对比更能说明问题。在与体积大9倍的Chandra-9B模型对比中,LightOnOCR-2-1B不仅准确率更高,还完全不依赖多阶段流水线,保持了端到端架构的简洁性。
速度优势
在实际应用中,速度往往和准确率同样重要。LightOnOCR-2-1B在单张H100 GPU上的处理速度达到了:
- 比Chandra OCR快1.93倍
- 比OlmOCR快2-3倍
- 比dots.ocr快1倍
- 比PaddleOCR-VL-0.9B快2.43倍
- 比DeepSeekOCR快2.68倍
这样的速度表现意味着该模型完全可以应用于大规模生产环境的文档处理流水线,在保证准确率的同时满足高吞吐量需求。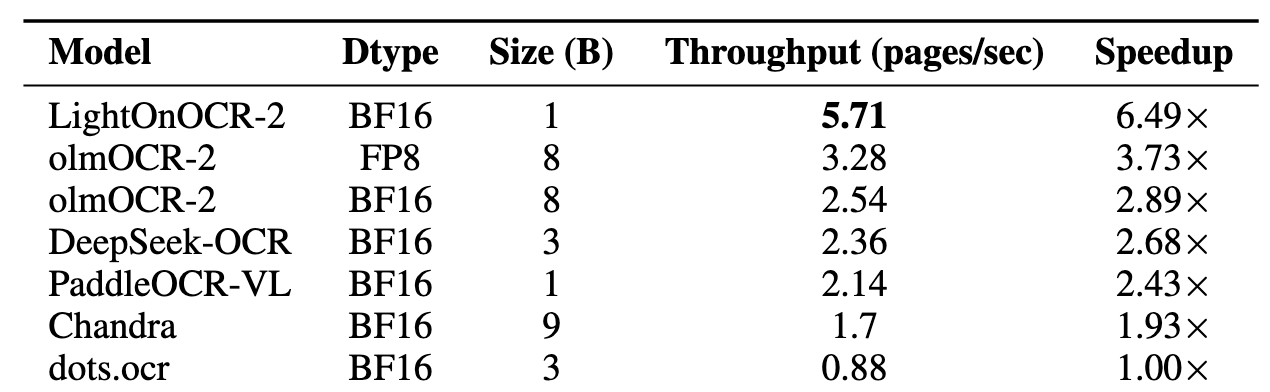
丰富的模型家族
为了满足不同应用场景的需求,LightOnOCR-2发布了一整个模型家族,而不是单一的检查点:
主力模型系列:
- LightOnOCR-2-1B(默认推荐): 纯OCR模型,转录质量最佳
- LightOnOCR-2-1B-bbox: 支持图像边界框定位的版本,可输出文档中嵌入图片的位置信息
- LightOnOCR-2-1B-ocr-soup: 平衡版本,兼顾OCR和bbox能力
基础模型系列:
- LightOnOCR-2-1B-base: 纯OCR基础检查点,用于微调和模型融合
- LightOnOCR-2-1B-bbox-base: 支持bbox的基础检查点,可用于RLVR训练
- LightOnOCR-2-1B-bbox-soup: bbox变体的融合版本,在OCR质量和图像定位之间取得平衡
这种"分而治之"的策略让用户可以根据具体需求选择最合适的模型,而不必在单个检查点中做出妥协。
开放数据集
除了模型本身,LightOnOCR-2还开源了两个高质量的训练数据集:
- lightonai/LightOnOCR-mix-0126: 包含超过1600万页高质量标注文档
- lightonai/LightOnOCR-bbox-mix-0126: 近50万页带图像边界框标注的文档
- LightOnOCR-bbox-bench: 专门用于评估文档中图像定位能力的基准测试集
这些数据集的开放将极大推动OCR和文档理解领域的开源生态发展。
数据集链接:https://huggingface.co/datasets/lightonai/LightOnOCR-bbox-mix-0126
技术深度解析
模型架构演进
LightOnOCR-2延续了第一代的端到端架构设计理念,但在多个关键方面进行了优化。模型采用原生分辨率的视觉Transformer(ViT)处理图像输入,配合精简的语言模型主干网络。通过多模态投影层将视觉特征与语言特征对齐,实现PDF页面到Markdown文本的直接转换。
相比传统的多阶段OCR流水线,这种端到端设计带来了几个关键优势:
训练简化: 整个模型完全可微分,可以端到端优化,无需协调多个独立组件的训练。
推理高效: 每页只需一次前向传播,无需多次模型调用和中间处理步骤。
适配灵活: 针对新领域或新语言的微调变得简单直接,只需在目标数据上继续训练即可。
数据质量是关键
LightOnOCR-2的性能提升很大程度上归功于训练数据的质量和规模。训练数据采用知识蒸馏范式,使用Qwen2-VL-72B作为教师模型对大规模文档语料进行标注,然后训练规模更小、更专业的学生模型。
数据标注过程包含以下关键步骤:
标注生成: 使用72B参数的Qwen2-VL模型将PDF页面转录为Markdown格式,使用LaTeX表示数学公式。选择Markdown是因为它比HTML更轻量、更易解析,同时保留了足够的结构信息。
质量控制: 实施了全面的标准化流程来确保标注一致性,包括:
- 循环检测:通过n-gram频率分析识别并过滤重复生成的内容
- 去重:计算序列哈希值识别并删除重复样本
- 图像占位符标准化:统一图像引用格式为
 - 幻觉过滤:通过对比VLM输出与参考OCR结果来检测和过滤异常样本
最终的训练数据集包含1760万页文档,总计455亿token(包含视觉和文本token),图像以原生分辨率渲染,最大尺寸为1540像素。
值得注意的是,使用更大的教师模型进行数据标注确实能带来显著的性能提升。在对比实验中,使用72B教师模型标注的数据训练出的模型,比使用7B教师模型的版本在各项指标上都有明显提升,特别是在复杂的多栏布局、表格和数学内容方面,提升幅度达到了11.8个百分点。
边界框能力的权衡
为了满足需要轻量级布局线索的应用场景,LightOnOCR-2提供了支持边界框输出的变体。这些模型不仅能转录文本,还能标注文档中嵌入图片的位置。
由于OCR和边界框检测两个目标可能存在一定冲突,团队采取了差异化策略,提供两个独立的检查点:
- LightOnOCR-2-1B-bbox: 专注于边界框定位精度
- LightOnOCR-2-1B-bbox-soup: 通过模型融合平衡OCR质量和定位能力
这种设计避免了在单一模型中强行兼顾两个目标而导致的性能妥协,让用户可以根据具体应用选择最合适的版本。
Transformers生态集成
LightOnOCR-2已经正式集成到Hugging Face Transformers生态系统中,这带来了诸多实用价值:
简化部署: 可以直接使用标准Transformers工具运行,无需从vLLM开始配置
便捷微调: 支持常见的HF微调工作流,包括LoRA、PEFT和Trainer
硬件灵活: CPU和本地环境运行成为可能,虽然性能依赖硬件条件,但相比"仅GPU"的流水线方案已经大幅降低了使用门槛
同时,模型也完全兼容vLLM推理引擎,可以轻松构建高吞吐量的生产级服务。
实际应用示例
为了更直观地展示LightOnOCR-2的能力,这里展示几个典型文档的处理效果:
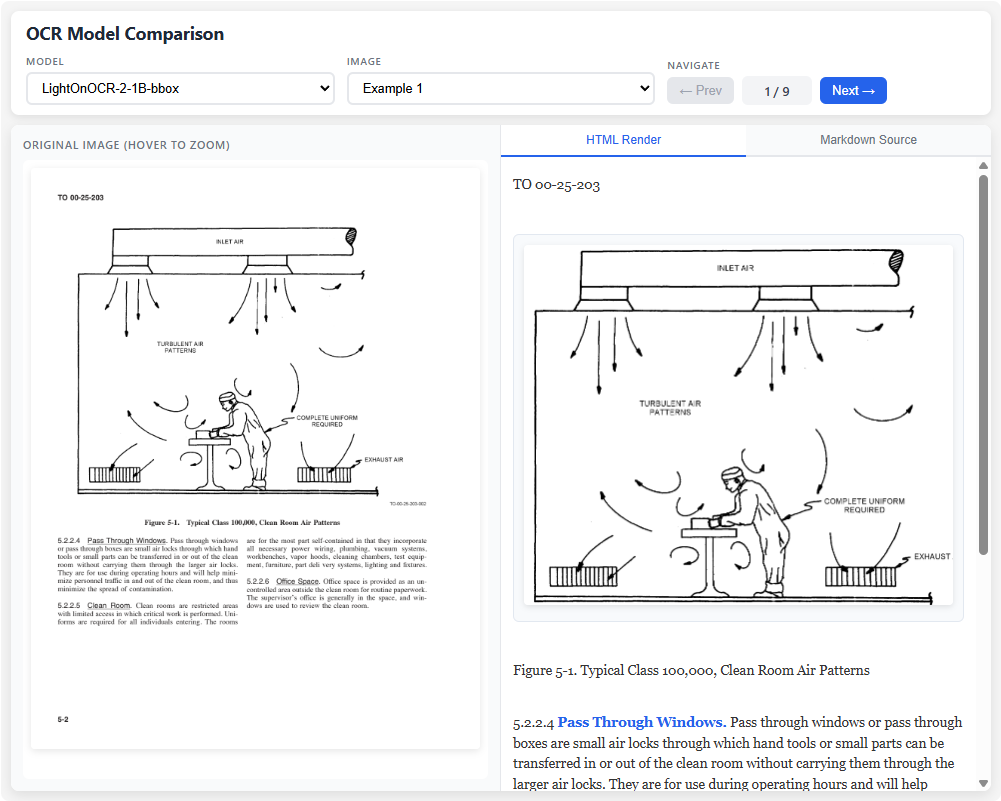
技术手册页面
原始图像包含标准技术文档的典型元素:文档编号、图表、多级标题和正文段落。LightOnOCR-2能够准确识别所有文本内容,保持正确的阅读顺序,并适当处理图片占位符。

转录结果完整保留了文档结构,包括章节编号、图表引用和分段格式,输出为干净的Markdown文本。
更多场景支持
LightOnOCR-2在各类文档场景下都表现出色:
- 数学公式密集页面: 准确识别复杂的数学符号和公式,转换为LaTeX格式
- 老旧扫描文档: 对图像质量不佳的历史文档也能保持较高识别率
- 多栏布局: 正确理解多栏文本的阅读顺序
- 表格: 准确识别表格结构并转换为Markdown格式
在项目提供的在线演示中,可以上传自己的文档体验实际效果。
性能基准详解
OlmOCR-Bench测试结果
OlmOCR-Bench是目前最全面的OCR评测基准,包含1403页PDF文档和7010个测试用例,覆盖多种文档类型、提取难点和语言。该基准使用自动化单元测试而非编辑距离进行评估,确保了评测的可重现性。
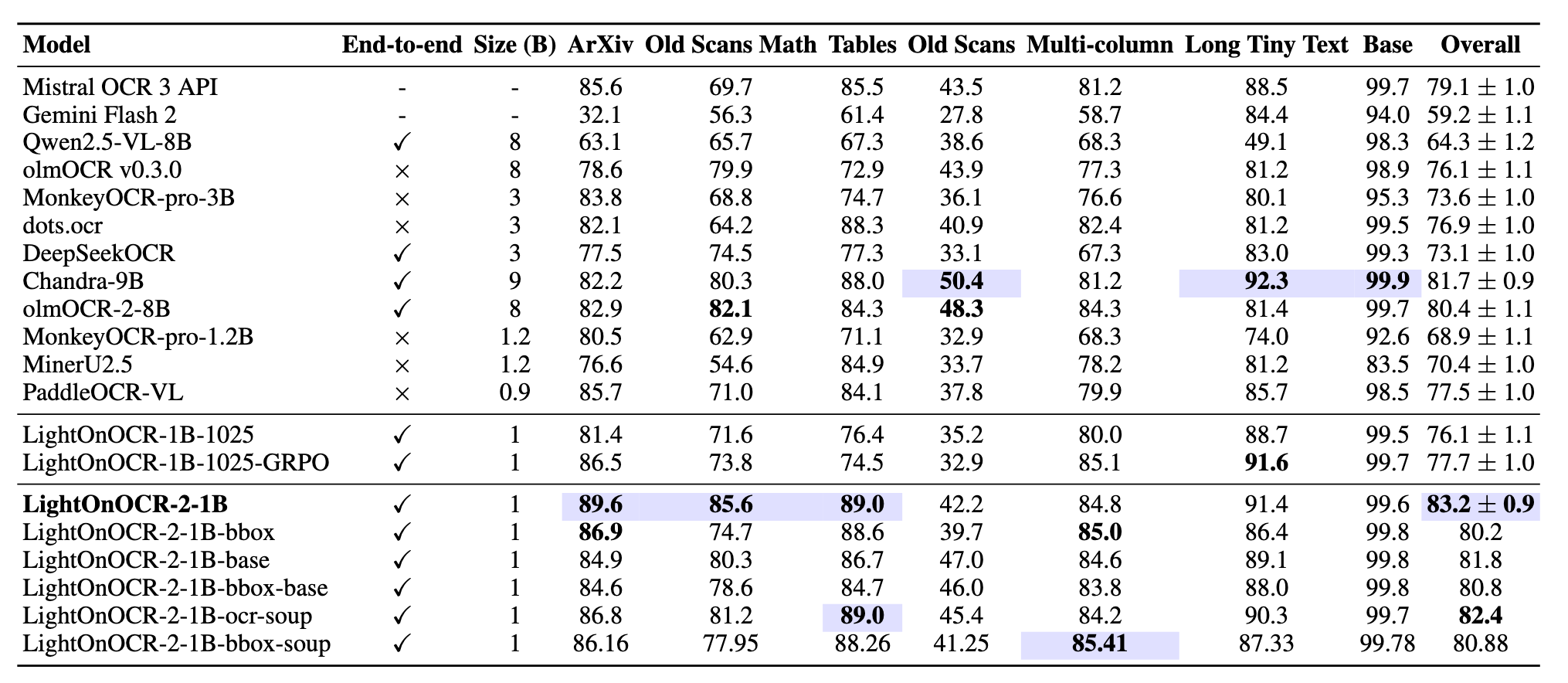
LightOnOCR-2-1B在各细分类别上的表现都很均衡,特别是在以下几个难点场景:
- ArXiv科学论文: 83.2分,得益于增强的科学文献覆盖和高分辨率训练
- 含数学公式的老旧扫描件: 在图像质量较差的情况下仍能准确识别数学符号
- 表格: 正确理解表格结构并转换为Markdown格式
- 多栏布局: 准确把握文本阅读顺序
推理速度测试
为了公平对比不同OCR模型的速度-性能权衡,测试统一在单张H100 GPU(80GB)上进行,所有模型都通过vLLM推理引擎提供服务,尽可能充分利用GPU内存。
测试方法是在OlmOCR-Bench的1402个PDF文档上运行完整的端到端评测,记录总耗时,然后计算页面处理速度(页/秒)。
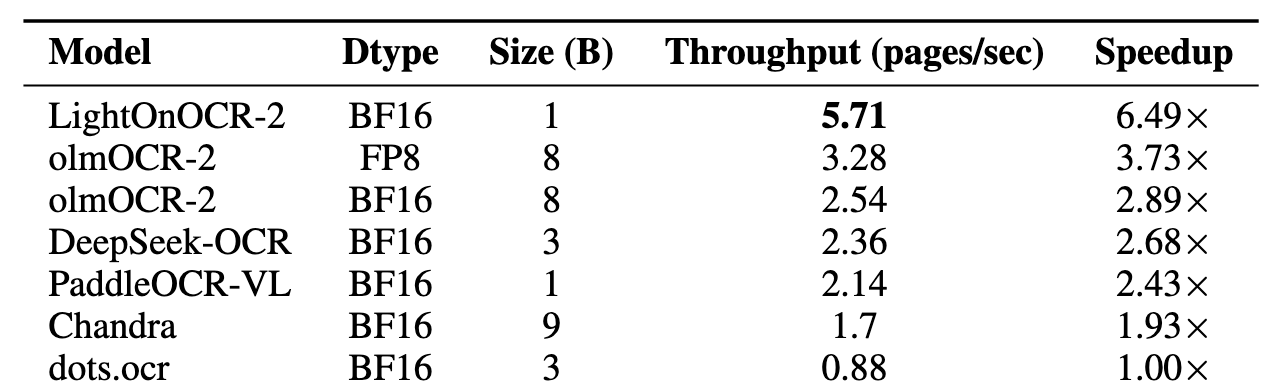
需要特别说明的是,流水线型方案如dots.ocr和PaddleOCR-VL每页需要多次模型调用,还有额外的裁剪和预处理开销。虽然流水线可以通过专门的启发式规则提升质量,但速度代价很大。相比之下,LightOnOCR-2的端到端架构每页只需一次调用,不需要重试或修正逻辑,推理过程更简单、更快、更高效。
第一代技术回顾
端到端架构的优势
第一代LightOnOCR就已经确立了端到端训练的核心理念。这个10亿参数的紧凑型模型通过在高质量开源VLM上进行知识蒸馏训练,在单张H100 GPU上达到了5.71页/秒的处理速度,相当于每天可处理49.3万页文档。
按当前云服务定价计算,这意味着每1000页的处理成本不到0.01美元,比运行大型OCR VLM便宜数倍。这种高效率对实际应用至关重要,因为模型不仅简单稳定,微调成本也很低,很容易适配到新领域、新布局或新语言。
训练策略探索
在开发过程中,团队进行了一系列消融实验来验证各种训练策略的有效性:
单阶段vs两阶段训练: 传统做法通常先冻结视觉和语言主干只训练多模态投影层,然后再解冻整个模型进行全参数训练。实验表明,在大规模数据集下,单阶段训练效果与两阶段相当甚至略好,因此最终采用了更简单的单阶段方案。
教师模型规模的影响: 对比使用7B和72B模型标注的相同数据子集训练的模型,72B教师带来的性能提升非常明显,特别是在多栏布局(+22.2分)、小字体文本(+12.9分)和数学公式(+17分)等复杂场景。这说明对于OCR任务,标注质量会随教师模型规模提升而提升,在数据生成阶段投入更大模型可以显著改善下游准确率。
词表剪枝优化: Qwen3语言模型使用151,936个token的大型多语言词表,但对于专注特定语言的OCR任务,其中大部分token都很少或从未使用。团队探索了将词表剪枝到51k、32k和16k的方案:
- 通过token频率分析识别高频token
- 使用递归频率评分保留必要的子token序列
- 保留所有特殊token和排名最高的N个token
实验表明,对于英语和法语文档,即使剪枝到16k词表(仅为原词表的10%),性能几乎不受影响,但非拉丁文字的语言会受到严重影响。32k词表在速度和准确率之间取得了最佳平衡,推理速度相比完整词表提升约12%。
分辨率的影响: 模型采用原生分辨率图像编码器,可以按原始分辨率处理文档。测试不同推理分辨率的结果显示,提高分辨率能持续改善性能,特别是在密集文本或小字体文档上。从1024像素提升到1540像素,平均得分从70.7提升到76.1,其中小字体文本类别提升最为显著(从65.8到88.7)。
数据增强: 借鉴Nougat论文的做法,测试了轻度图像级增强(小角度旋转、缩放、网格畸变、轻微腐蚀和膨胀)来模拟真实文档噪声。结果显示,增强对噪声或不规则文本略有帮助,但整体影响很小。考虑到真实场景的复杂性,最终模型仍然使用了数据增强。
微调灵活性验证
为了验证端到端架构的适配能力,团队使用OlmOCR-mix-0225数据集的文档子集进行了微调实验。仅用单个epoch、无额外超参数调整,就将整体得分从68.2提升到77.2,在headers&footers类别更是从40.0飙升至91.3。
这个简单的微调实验充分展示了模型的可塑性和适配能力。相比流水线型方案,端到端模型可以持续学习和适应特定数据分布,只需在目标数据上继续训练即可,而流水线的各个独立组件则需要分别标注数据和调整。
实用指南
快速开始
LightOnOCR-2提供了两种主要的使用方式,可以根据具体需求选择最合适的部署方案。
方式一: 使用Transformers库
对于本地开发和小规模应用,可以直接使用Hugging Face Transformers库。需要注意的是,LightOnOCR-2需要从源码安装最新版本的transformers(尚未包含在稳定版本中)。
# 安装依赖
uv pip install git+https://github.com/huggingface/transformers
uv pip install pillow pypdfium2
基本使用示例:
import torch
from transformers import LightOnOcrForConditionalGeneration, LightOnOcrProcessor
# 自动选择可用设备
device = "mps" if torch.backends.mps.is_available() else "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float32 if device == "mps" else torch.bfloat16
# 加载模型和处理器
model = LightOnOcrForConditionalGeneration.from_pretrained(
"lightonai/LightOnOCR-2-1B",
torch_dtype=dtype
).to(device)
processor = LightOnOcrProcessor.from_pretrained("lightonai/LightOnOCR-2-1B")
# 准备输入图片
url = "https://huggingface.co/datasets/hf-internal-testing/fixtures_ocr/resolve/main/SROIE-receipt.jpeg"
conversation = [{"role": "user", "content": [{"type": "image", "url": url}]}]
# 应用对话模板并生成
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
)
inputs = {k: v.to(device=device, dtype=dtype) if v.is_floating_point() else v.to(device)
for k, v in inputs.items()}
# 生成OCR结果
output_ids = model.generate(**inputs, max_new_tokens=1024)
generated_ids = output_ids[0, inputs["input_ids"].shape[1]:]
output_text = processor.decode(generated_ids, skip_special_tokens=True)
print(output_text)
方式二: 使用vLLM推理引擎
对于生产环境和大规模文档处理,推荐使用vLLM来获得更高的吞吐量和更好的性能。
# 安装vLLM 0.11.1或更高版本
uv venv --python 3.12 --seed
source .venv/bin/activate
uv pip install vllm==0.11.2
# 启动推理服务
vllm serve lightonai/LightOnOCR-2-1B \
--limit-mm-per-prompt '{"image": 1}' \
--mm-processor-cache-gb 0 \
--no-enable-prefix-caching
启动服务后,可以通过API接口调用:
import base64
import requests
import pypdfium2 as pdfium
import io
ENDPOINT = "http://localhost:8000/v1/chat/completions"
MODEL = "lightonai/LightOnOCR-2-1B"
# 从arXiv下载PDF
pdf_url = "https://arxiv.org/pdf/2412.13663"
pdf_data = requests.get(pdf_url).content
# 打开PDF并转换第一页为图像
pdf = pdfium.PdfDocument(pdf_data)
page = pdf[0]
# 以200 DPI渲染 (缩放因子 = 200/72 ≈ 2.77)
pil_image = page.render(scale=2.77).to_pil()
# 转换为base64编码
buffer = io.BytesIO()
pil_image.save(buffer, format="PNG")
image_base64 = base64.b64encode(buffer.getvalue()).decode('utf-8')
# 发起API请求
payload = {
"model": MODEL,
"messages": [{
"role": "user",
"content": [{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_base64}"}
}]
}],
"max_tokens": 4096,
"temperature": 0.2,
"top_p": 0.9,
}
response = requests.post(ENDPOINT, json=payload)
text = response.json()['choices'][0]['message']['content']
print(text)
图像预处理建议
为了获得最佳OCR效果,在准备输入图像时需要注意以下几点:
- 分辨率设置: 将PDF渲染为PNG或JPEG格式时,建议最长边设置为1540像素
- 保持宽高比: 务必保持原始宽高比,以确保文本几何关系不被破坏
- 单页处理: 每次输入一个页面图像,vLLM支持批量处理多页
- 渲染参数: 使用200 DPI进行PDF渲染可以获得较好的清晰度和性能平衡
这些预处理步骤能够确保模型接收到质量适中的输入,在准确率和处理速度之间取得最佳平衡。
模型选择建议
根据应用场景选择合适的检查点:
纯文本转录场景: 选择LightOnOCR-2-1B(默认版本),转录质量最佳,适合"将PDF转换为干净文本/Markdown"的需求。
需要图像定位的场景: 如果需要知道文档中图片的位置信息,可以选择:
- LightOnOCR-2-1B-bbox: 定位精度优先
- LightOnOCR-2-1B-bbox-soup: 平衡OCR和定位性能
微调或研究用途: 使用基础检查点:
- LightOnOCR-2-1B-base: 纯OCR基础版本
- LightOnOCR-2-1B-bbox-base: 支持bbox的基础版本,可用于RLVR训练
团队还提供了微调教程,方便在自己的数据上进行领域适配。
在线体验
可以在演示空间上传文档体验LightOnOCR-2的实际效果,无需本地部署。
https://huggingface.co/spaces/lightonai/LightOnOCR-2-1B-Demo
总结与展望
LightOnOCR-2-1B的发布标志着文档OCR技术的一个重要里程碑。凭借端到端架构、精心设计的训练数据和高效的模型设计,它在准确率、速度和易用性三个维度都树立了新标杆。
核心优势总结:
- 性能领先: 在OlmOCR-Bench上超越所有同等规模甚至更大规模的竞品
- 高效实用: 处理速度比主流方案快2-5倍,成本仅为大型VLM的几分之一
- 完全开源: Apache 2.0协议,包含模型、数据集和训练细节
- 灵活适配: 端到端架构使得微调和领域适配变得简单直接
- 生态友好: 完整集成到Transformers和vLLM生态系统
未来方向:
根据团队透露,技术细节的完整预印本论文即将发布,将包含更深入的方法论阐述和实验分析。同时,开源的大规模训练数据集将为社区提供宝贵资源,推动OCR和文档理解领域的进一步发展。
对于需要处理大量文档的应用场景——无论是学术研究、企业文档管理还是历史资料数字化——LightOnOCR-2都提供了一个强大、高效且易于部署的解决方案。它证明了在垂直领域,精心设计的小模型完全可以超越体积庞大的通用模型,为AI应用的实用化和普及化提供了新的思路。
相关链接:
- 模型下载: Hugging Face模型库
- 训练数据集: LightOnOCR-mix-0126
- 在线演示: Demo空间
- 第一代博客: LightOnOCR-1B介绍

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)