视觉大模型学习之CLIP&VIT
因为最后一层(第 12 层)的首要任务是为了分类而分类。它的注意力会极度向 [CLS] Token 靠拢。在这一层,模型已经完成了“理解”,它可能只关注缺陷中最具代表性的一个极小区域,而忽略了缺陷的整体轮廓。这在工业检测中会导致热力图。
Vision Transformer(VIT)是CLIP架构的视觉塔部分,这部分实现了将图片转化为1*D的特征向量,并使用了分块处理的思想。
Patch Embedding
切片->序列化:
VIT首先用了切片序列操作,将一张二维图像切片分成很多个小patch,定义如下:
- 将输入的二维图像(2D Image)转换为一维的序列化嵌入(1D Sequence of Embeddings),使其能够像文本 Token 一样被 Transformer 编码器处理。
- 核心动机: Transformer 最初是为 NLP 设计的,它处理的是序列数据。Patch Embedding 的作用就是将 “像素的排列组合” 转化为 “视觉单词的序列”。
在代码落地时,ViT 并没有真的用 for 循环去裁剪图片(那样太慢了)。它用了一个非常优雅的技巧:使用一个步长(Stride)等于卷积核大小(Kernel Size)的二维卷积。
代码逻辑演示如下:
import torch
import torch.nn as nn
# 假设输入是 [Batch, Channel, H, W]
x = torch.randn(1, 3, 224, 224)
# Patch Embedding 映射层
patch_embed = nn.Conv2d(in_channels=3, out_channels=768, kernel_size=16, stride=16)
# 执行卷积
# 输出维度: [1, 768, 14, 14]
x = patch_embed(x)
# 展平 (Flatten) 变成序列
# 维度变为: [1, 768, 196] -> 再转置 [1, 196, 768]
x = x.flatten(2).transpose(1, 2)
print(x.shape) # 输出 torch.Size([1, 196, 768])
这里的尺寸是224*224 通过这个二维卷积可以分别从宽高进行切片 切片为224/16 * 224/16 = 196个patch
输出通道数channel=768 因为要保证数据总和不变
然后对输出数据进行展平(对尺寸维度),变成序列,在进行维度转置,符合B, N, C的形式 最后输出
** 为什么卷积可以等同于“切片+投影”?**
这是一个非常妙的数学转换:
切片(Patching): 卷积核的大小(16 * 16)正好覆盖一个 Patch。投影(Projection): 卷积核内的参数就是权重。当卷积核在一个位置做点积运算时,它实际上是在把这 16 *16 * 3个像素值线性映射成一个数值。
步长(Stride): 步长设为16,意味着卷积核跳着走,不会重复采样像素,完美模拟了“不重叠切片”。
并行化: 卷积层可以利用 GPU 的张量加速引擎(Tensor Cores)同时计算所有 Patch,这比手动 view 和 permute 要快得多。
- 卷积运算的本质是:卷积核内的参数与图像像素进行点积(Dot Product)。
- 在一个 16×16×316 \times 16 \times 316×16×3 的区域内做卷积,等价于把这 768 个像素拉平,然后输入到一个神经元数量为
embed_dim(768) 的全连接层。 - 结论:
Conv2d(kernel=16, stride=16)实际上就是在图像的每一个 Patch 位置,同步执行了一次局部全连接映射。
**插入 全局变量CLS Token **
在所有的视觉Patch向量之前,会手动插入一个随机初始化的、可学习的向量,增加一个“全局总结位”。
插入后,向量的shape从[1, 196, 768]变成了[1, 197, 768], 即一个CLS+196个patch的视觉单词
# 1. 初始化一个可学习的 CLS Token (所有 Batch 共享)
# 维度是 [1, 1, 768]
cls_token = nn.Parameter(torch.zeros(1, 1, 768))
# 2. 将其扩展到与当前 Batch Size 一致
# 假设 Batch Size 是 B
#在 expand 函数中,参数 -1 的含义是:“保持该维度的大小不变”。
cls_tokens = cls_token.expand(B, -1, -1)
# 3. 使用 torch.cat 拼接到序列最前面
# x 的维度从 [B, 196, 768] 变为 [B, 197, 768]
x = torch.cat((cls_tokens, x), dim=1)
位置向量编码:
Transformer 内部的 Self-Attention 机制是“无序”的。如果不加处理,模型分不清 Patch 1(左上角)和 Patch 196(右下角)的区别 。而在实际领域应用中,位置信息极其重要。
- 原理: 准备一个与
x形状完全一样的矩阵pos_embed(维度[1, 197, 768])。 - 操作: 并不是拼接,而是直接相加(Element-wise Add)。
- **公式: **
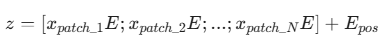
代码实现:
# 1. 初始化位置编码矩阵 (197 代表 1个CLS + 196个Patch)
pos_embed = nn.Parameter(torch.zeros(1, 197, 768))
# 2. 直接与特征向量相加
# 广播机制会自动处理 Batch 维度
x = x + pos_embed
完整流程:
| 步骤 | 操作 | 维度变化 (Base 模型) | 目的 |
|---|---|---|---|
| 0 | 输入图像 | <font style="color:rgb(68, 71, 70);">[B, 3, 224, 224]</font> |
原始数据 |
| 1 | Conv2d (Patching) | <font style="color:rgb(68, 71, 70);">[B, 768, 14, 14]</font> |
像素映射到高维特征 |
| 2 | Flatten & Transpose | <font style="color:rgb(68, 71, 70);">[B, 196, 768]</font> |
转化为 Transformer 序列格式 |
| 3 | Concat CLS Token | <font style="color:rgb(68, 71, 70);">[B, 197, 768]</font> |
增加一个专门负责全局分类的位 |
| 4 | Add Pos Embed | <font style="color:rgb(68, 71, 70);">[B, 197, 768]</font> |
注入空间位置信息 |
| 5 | 输入 Transformer 层 | <font style="color:rgb(68, 71, 70);">[B, 197, 768]</font> |
开始进行 Self-Attention 交互 |
Transformer Encoder
这是VIT最重要的部分之一,即著名的Transformer架构–Self Attention(自注意力机制)。这个机制的本质就是让每个单独的patch向量,两两进行交互,计算彼此相关性。
核心向量: Q K V
为了实现这种相关性交互,每个单独向量都会通过三个不同的全连接层,创建出三个向量:
- Query (Q - 查询):像是一个搜索框。“我想看看有没有和我类似的边缘特征?”
- Key (K - 键):像是一个标签。“我这里有一段 45 度的边缘特征。”
- Value (V - 值):像是在搜索结果中提取的实际内容。“我是具体的像素特征信息。
数学公式(一定要记得):
Attention(Q, K, V) = Softmax((Q*K^T / dk^1/2)*V)
即:
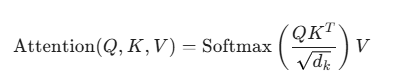
步骤拆解:
第一步:计算相似度(Q 乘 K 的转置)
我们将 Q 矩阵和 K 矩阵做点积。如果 Q 和 K 的方向很接近(相似度高),点积值就大。结果是一个 197 *197的矩阵。每一行代表:当前的这个 Patch 对所有 Patch 的关注程度。
第二步:缩放(Scaling)
除以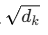 ,dk是向量维度。
,dk是向量维度。
目的是防止点积的结果过大,导致后续Softmax梯度消失。这一步为了训练的数值稳定性。
第三步: 归一化(Softmax)
这一步是对每一行做Softmax,让权重之和等于1。
这一步就可以产生所谓AttentionMap 注意力图。
第四步:加权求和
用算出来的权重乘以V。
这样会让每个Patch结果不是孤立的,而是融合了全局信息的特征向量。
为什么用Multi-Self-Attention,即多头注意力机制:
如果用单个attention,模型就像是只有一个摄像头一样,关注的特征比较单一;
在工业级半导体缺陷检测中,一个 Patch 可能包含多重信息。假设晶圆上有一个带颜色变化的划痕:
- 头 A (空间位置):它发现这个 Patch 附近有一系列连续的像素突变,判定为“线状物体”。
- 头 B (颜色/对比度):它发现这个 Patch 的亮度比周围高出 30%,判定为“金属感”。
- 头 C (纹理):它发现这个 Patch 破坏了原本均匀的电路格栅,判定为“结构破损”。
如果是单个头的话,模型只能在这些特征中做取舍,最终只能获得一个较为模糊的平均特征。多头注意力机制可以并行工作,最后把不同信息拼接起来,得到一个较为具体的特征描述。
底层逻辑: 多头注意力允许模型同时建模图像中不同性质的关联(比如长距离的形状关联和短距离的纹理关联)。
代码实现如下:
import torch.nn as nn
import torch
class VITPatchEmbedding(nn.Module):
def __init__(self, img_size = 224, patch_size = 16, in_channel = 3, embed_dim = 768):
super().__init__()
self.patch_size = patch_size
#使用Conv2d卷积实现patch
self.proj = nn.Conv2d(in_channel, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
# x: [Batch, 3, 224, 224]
x = self.proj(x) # [B, 768, 224/16, 224/16]
x = x.flatten(2).transpose(1, 2) #[B, 196, 768]
return x
class VITInput(nn.Module):
def __init__(self, img_size=224, patch_size=16, embed_dim=768):
super().__init__()
self.patch_embed = nn.Conv2d(3, embed_dim, kernel_size=patch_size, stride=patch_size)
num_patches = (img_size//patch_size)**2
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches+1, embed_dim))
def forward(self, x):
B = x.shape[0]
x = self.patch_embed(x)
x = x.flatten(2).transpose(1,2)
# add cls token
cls_token = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_token, x), dim=1) # 按channel维度拼接
#add pos token
pos_token = self.pos_embed
x = x + pos_token
return x
class MultiSelfAttention(nn.Module):
def __init__(self, embed_dim=768, num_heads=12):
super().__init__()
self.num_heads = num_heads
self.head_dim = embed_dim//num_heads
self.scale = self.head_dim**-0.5 # 缩放系数 根号下dk分之一
#Q, K, V的线性投影矩阵
self.qkv = nn.Linear(embed_dim, embed_dim*3)
self.proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
B, N, C = x.shape #[Batch, 197, 768]
#1. 算出Q, K, V并切成多头
#[B, N, 3*C] -> [B, N, 3, num_heads, head_dim] -> [3, B, num_heads, N, head_dim]
qkv = self.qkv(x)
qkv = qkv.reshape(B, N, 3, self.num_heads, self.head_dim)
qkv = qkv.permute(2, 0, 3, 1, 4) # [3, B, num_heads, N, head_dim]
Q, K, V =qkv[0], qkv[1], qkv[2] #[ B, num_heads, N, head_dim ]
#2. 计算相似度矩阵Q*K^T, 乘以缩放系数
attention = Q @ K.transpose(-2, -1) * self.scale # 这里将K矩阵的最后两个维度转置,做乘法的时候就会只计算最后两个维度的
attention = attention.softmax(dim=-1) # [B, num_heads, N, N] 这就是我们要提取的 Attention Map (12个头)
#3. 加权求和, 拼接多头
x = attention @ V # [B, num_heads, N, N]@[B, num_heads, N, head_dim] -> [B, num_heads, N, head_dim]
x = x.transpose(1,2).reshape(B, N, C)
#4. 线性映射 (融合各头信息)
x = self.proj(x)
return x, attention
class TransformerBlock(nn.Module):
def __init__(self, embed_dim = 768, num_heads=12, mlp_ratio=4.0):
super().__init__()
self.norm1 = nn.LayerNorm(embed_dim)
self.attn = MultiSelfAttention(embed_dim, num_heads)
self.norm2 = nn.LayerNorm(embed_dim)
# mlp层:增加非线性表达能力
self.mlp = nn.Sequential(nn.Linear(embed_dim, int(embed_dim*mlp_ratio)),
nn.GELU(),
nn.Linear(int(embed_dim*mlp_ratio), embed_dim)
)
def forward(self, x):
residual = x
x, attn_map = self.attn(self.norm1(x))
x = x + residual
x = x + self.mlp(self.norm2(x))
return x, attn_map
if __name__ == "__main__":
model = VITInput()
img = torch.randn(1, 3, 224, 224)
output1 = model(img)
print(f"VIT Input输出形状: {output1.shape}") # 预期: torch.Size([1, 197, 768])
attn = TransformerBlock()
output2, attn_map = attn(output1)
print(f"VIT Transformer输出形状:{output2.shape}")
为什么在Block中要加入MLP架构:
-
首先是Attn的局限性。 自注意力机制本质上是做加权求和。无论权重的 Softmax 怎么算,它依然是输入向量的线性组合。如果只堆叠 Attention,模型就只是在不断地把像素“搬来搬去”。
这里MLP会关注非线性特征, 在注意力机制帮每个 Patch 收集到了周围的信息后,MLP 通过 `Linear -> GELU -> Linear` 这一套组合拳,对每个 Patch 内部的 768 维特征进行**非线性映射和变换**。它负责把收集到的“原材料”加工成更高阶的“语义特征”。 -
MLP也起到了一个空间升维的作用,通过ratio升维参数。因为在高维空间中,特征更容易被线性分离。这就像是在半导体检测中,把微小的信号放大,在更高的维度去观察缺陷的特征,然后再压缩回原来的维度。
-
MLP 对每个 Patch 是独立运行的。这意味着它在强化每个位置自身的表达,确保模型不仅知道“哪里的 Patch 相关”,还知道“这个 Patch 本身到底是什么”。
VIT在CLIP中的具体应用与特征可视化分析
下面的程序实现了从CLIP中提取VIT视觉特征,并将每个Patch与目标提示词做特征计算,将特征热力图可视化,最后实现输出热力图和模型预测类型。这里提取的就是最后一层的AttnMap进行可视化,效果确实一般。
import torch
import clip
import numpy as np
import cv2
import matplotlib.pyplot as plt
from PIL import Image
def run_clip_spatial_analysis(image_path, class_names, target_class="a wafer with scratch"):
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 1. 加载并预处理图像
orig_image = Image.open(image_path).convert("RGB")
image = preprocess(orig_image).unsqueeze(0).to(device)
# 2. 提取文本特征(作为“搜索关键词”)
text_tokens = clip.tokenize(class_names).to(device)
with torch.no_grad():
text_features = model.encode_text(text_tokens)
text_features /= text_features.norm(dim=-1, keepdim=True)
# 3. 提取图像的 Patch 特征
# 注意:model.encode_image 通常返回全局 CLS 特征。
# 为了拿 Patch 特征,需要 hook 最后一层或者使用内部方法
# 对于 ViT-B/32,最后一层输出形状通常是 [50, B, 512] (1个CLS + 49个Patch)
# 1. 进入视觉编码器的初始嵌入
# 使用image.half()将图片的像素数据从 32位浮点数 (Float32) 转换为 16位半精度浮点数 (Float16),因为CLIP不支持float32
x = model.visual.conv1(image.half()) # [B, width, 7, 7]
x = x.reshape(x.shape[0], x.shape[1], -1).permute(0, 2, 1) # [B, 49, width]
# 2. 添加 [CLS] token 并叠加位置编码
cls_token = model.visual.class_embedding.to(x.dtype)
x = torch.cat([cls_token + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1)
x = x + model.visual.positional_embedding.to(x.dtype)
x = model.visual.ln_pre(x)
# 3. 通过 Transformer (注意:timm/openai 的顺序是 [N, B, C])
x = x.permute(1, 0, 2) # [50, B, width]
x = model.visual.transformer(x)
x = x.permute(1, 0, 2) # [B, 50, width]
# 4. 最后层归一化
x = model.visual.ln_post(x) # [B, 50, width]
# 5. 【核心修复】使用矩阵乘法进行投影,而不是调用
# x @ model.visual.proj -> 映射到 CLIP 的共同嵌入空间 (512维)
if model.visual.proj is not None:
x = x @ model.visual.proj # 这里解决了 Parameter not callable 的报错
# 6. 分离全局特征与 Patch 特征
# 第 0 位是经过投影的全局特征 (原本用于分类)
# 1~49 是各个空间位置的特征
patch_features = x[0, 1:, :] # [49, 512]
patch_features /= patch_features.norm(dim=-1, keepdim=True)
global_features = x[0, 0, :].unsqueeze(0) # [1, 512]
global_features /= global_features.norm(dim=-1, keepdim=True)
# --- 5. 计算空间热力图 (确保在 with torch.no_grad 内部或特征已提取) ---
# 假设我们要搜寻的目标在 class_names 中的索引
target_idx = class_names.index(target_class)
target_text_vec = text_features[target_idx] # [512]
# 计算 49 个 Patch 与该目标的余弦相似度
# patch_features: [49, 512], target_text_vec: [512]
# 执行点积得到 [49] 个相似度数值
spatial_sim = (patch_features @ target_text_vec.unsqueeze(1)).squeeze()
# 将 [49] 维向量重新排列为 [7, 7] 的空间网格
# 注意:ViT-B/32 是 7x7,如果是 ViT-B/16 请改为 14, 14
grid_size = int(np.sqrt(patch_features.shape[0]))
spatial_sim = spatial_sim.reshape(grid_size, grid_size).cpu().float().numpy()
# --- 6. 增强可视化效果 ---
# 指数增强:拉开背景与缺陷的差距
spatial_sim = np.exp(spatial_sim * 2.0)
# 归一化到 0-1
spatial_sim = (spatial_sim - spatial_sim.min()) / (spatial_sim.max() - spatial_sim.min() + 1e-8)
# 使用双三次插值上采样到 224x224,消除马赛克感
heatmap = cv2.resize(spatial_sim, (224, 224), interpolation=cv2.INTER_CUBIC)
# 转换为彩色热力图
heatmap_color = cv2.applyColorMap(np.uint8(255 * heatmap), cv2.COLORMAP_JET)
# 图像融合
img_display = np.array(orig_image.resize((224, 224)))
if img_display.ndim == 2: img_display = cv2.cvtColor(img_display, cv2.COLOR_GRAY2RGB)
overlay = cv2.addWeighted(img_display, 0.5, heatmap_color, 0.5, 0)
# --- 8. 计算并打印所有类别的得分 ---
# 计算全局图像特征与所有文本特征的相似度
# global_features: [1, 512], text_features: [N, 512]
logits_per_image = 100.0 * global_features @ text_features.T
probs = logits_per_image.softmax(dim=-1).cpu().numpy()[0]
# 排序并打印结果
print(f"\n{'-' * 10} 预测得分 {'-' * 10}")
# zip 将类别名和概率捆绑,sorted 进行降序排列
top_results = sorted(zip(my_classes, probs), key=lambda x: x[1], reverse=True)
for name, score in top_results:
print(f"{name:>25}: {score * 100:>6.2f}%")
# 获取最终预测结果
top_name, top_score = top_results[0]
print(f"\n最终预测结果: 这张图最可能是 [{top_name}],置信度: {top_score * 100:.2f}%")
# --- 9. 展示结果 ---
plt.figure(figsize=(10, 5))
plt.imshow(cv2.cvtColor(overlay, cv2.COLOR_BGR2RGB))
plt.title(f"CLIP Semantic Search: {target_class}")
plt.axis('off')
plt.show()
if __name__ == "__main__":
my_classes = ["a perfect wafer", "some dirty particles on a shiny silicon wafer surface", "a dog", "a cat", "a scratch on a shiny silicon wafer surface"]
img_path = r"E:\Datasets\VLM_Test\CLIP_Test\61.tiff"
run_clip_spatial_analysis(img_path, my_classes, target_class="some dirty particles on a shiny silicon wafer surface")
首先我们可以输入一张狗狗的图片做测试:

模型得到结果如下:
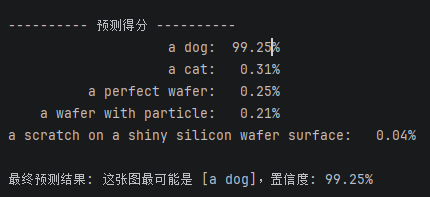
模型输出的Patch-Prompt特征热力图如下:

再做一个测试,我们输入一张带有脏污颗粒的晶圆图像如下:

此时模型输出结果如下:
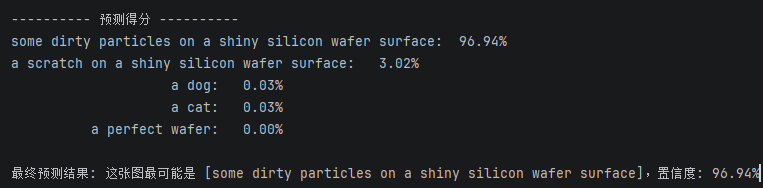
然后特征热力图如下:

可以发现,尽管模型预测的很准确,但是具体到每个Patch的特征比较模糊,并不是我们预想的那样将和目标prompt对应的视觉特征标红,即不能对应上,所以CLIP模型是一个全局的整体预测,并不能细致分割目标。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)