07-上下文管理策略
上下文管理是高效使用 Claude Code 的核心技能。理解上下文窗口的工作原理,并掌握优化策略,可以显著提升 AI 辅助编程的效果。问题影响上下文溢出早期信息丢失,Claude 忘记之前的讨论上下文污染无关信息干扰,降低响应质量上下文碎片化信息不连贯,理解困难。
·
文章目录
Claude Code 高级篇(一):上下文管理策略
修订记录
| 编号 | 版本 | 修订人 | 修订内容 | 日期 |
|---|---|---|---|---|
| 001 | 1.0 | lixh | 创建全文 | 2026-01-21 |
1. 概述
上下文管理是高效使用 Claude Code 的核心技能。理解上下文窗口的工作原理,并掌握优化策略,可以显著提升 AI 辅助编程的效果。
1.1 什么是上下文
1.2 为什么上下文管理重要
| 问题 | 影响 |
|---|---|
| 上下文溢出 | 早期信息丢失,Claude 忘记之前的讨论 |
| 上下文污染 | 无关信息干扰,降低响应质量 |
| 上下文碎片化 | 信息不连贯,理解困难 |
2. 上下文窗口原理
2.1 Token 限制
| 模型 | 上下文窗口 | 说明 |
|---|---|---|
| Claude Opus 4.5 | 200K tokens | 约 15-20 万中文字符 |
| Claude Sonnet | 200K tokens | 默认模型 |
| Claude Haiku | 200K tokens | 轻量模型 |
2.2 Token 消耗估算
| 内容类型 | 估算规则 |
|---|---|
| 英文文本 | 1 token ≈ 4 字符 |
| 中文文本 | 1 token ≈ 1-2 字符 |
| 代码 | 变化较大,取决于代码风格 |
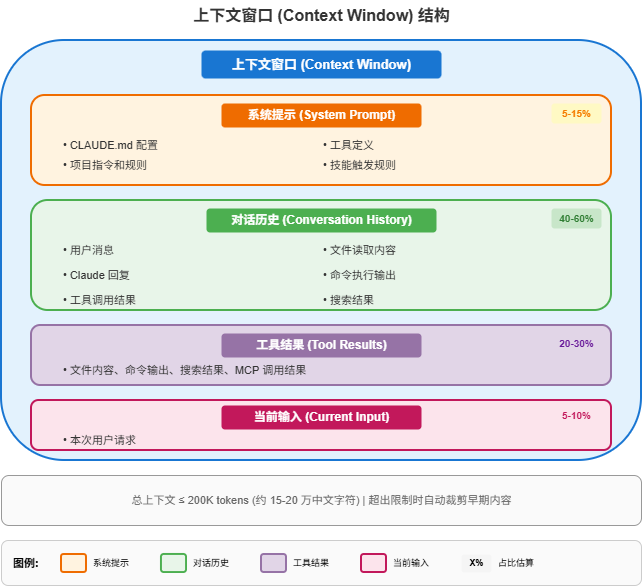
2.3 上下文组成
总上下文 = 系统提示 + 对话历史 + 工具结果 + 当前输入
典型分布:
├── 系统提示: 5-15% (CLAUDE.md, 工具定义)
├── 对话历史: 40-60% (之前的对话)
├── 工具结果: 20-30% (文件内容, 命令输出)
└── 当前输入: 5-10% (本次请求)
3. 上下文优化策略
3.1 策略一:精简系统提示
优化前(CLAUDE.md 过于冗长):
## 详细规则
1. 规则一的非常详细的描述...
2. 规则二的非常详细的描述...
... (几千字)
优化后:
## 核心规则
- 读取文件后再修改
- 函数 < 20行,嵌套 ≤ 3层
- 先理解再动手
3.2 策略二:按需加载文件
不推荐:一次读取大量文件
> 帮我读取 src 目录下所有文件
(可能消耗大量上下文)
推荐:按需逐步读取
> 先告诉我 src 目录有哪些文件
> 读取 src/auth.js
> 再看看 src/utils.js
3.3 策略三:及时清理上下文
使用 /compact 命令:
> /compact
上下文已压缩,保留核心信息:
- 项目结构
- 当前任务目标
- 关键代码片段
使用 /clear 命令:
> /clear
开始新会话,之前的对话已清除。
3.4 策略四:分阶段处理
将大任务拆分为多个独立会话:
会话 1: 分析现有代码结构
↓
记录结论
↓
会话 2: 设计新功能方案
↓
记录方案
↓
会话 3: 实现具体代码
4. 记忆系统
4.1 记忆层级
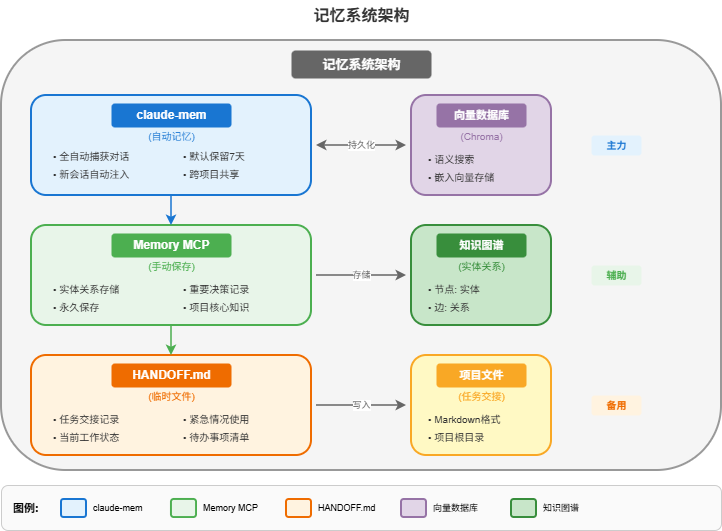
4.2 claude-mem(自动记忆)
特点:
- 全自动捕获对话内容
- 使用向量数据库存储
- 新会话自动注入相关上下文
配置位置:~/.claude-mem/
使用方式:
# 查看记忆状态
> /claude-mem status
# 保存当前上下文
> /save
# 查找相关记忆
> /remember 用户认证
4.3 Memory MCP(知识图谱)
特点:
- 存储实体和关系
- 永久保存重要知识
- 适合项目级知识管理
使用示例:
> 记住:项目使用 PostgreSQL 数据库,主库地址是 db.example.com
(保存到 Memory MCP)
> 这个项目用什么数据库?
(从 Memory MCP 检索)
4.4 HANDOFF.md(任务交接)
用途:紧急任务交接,保存当前工作状态
典型内容:
# 任务交接
## 当前状态
正在实现用户认证功能
## 已完成
- 数据库模型设计
- API 接口定义
## 待完成
- JWT 生成逻辑
- 刷新 Token 机制
## 关键文件
- src/auth/model.js
- src/auth/controller.js
5. 上下文注入技巧
5.1 使用项目指令
在 CLAUDE.md 中定义项目关键信息:
## 项目概述
- 技术栈:Node.js + Express + PostgreSQL
- 架构:RESTful API
- 认证:JWT Token
## 目录结构
src/
├── controllers/ # 控制器
├── models/ # 数据模型
├── routes/ # 路由定义
└── utils/ # 工具函数
5.2 利用触发词
配置关键词自动加载上下文:
## Auto-Trigger Rules
| Keywords | Action |
|----------|--------|
| 继续、接上次 | 自动加载相关记忆 |
| 这个项目 | 注入项目基本信息 |
5.3 分层上下文
Layer 1: 始终加载
├── 项目类型和技术栈
└── 核心规则
Layer 2: 按需加载
├── 具体模块信息
└── 历史决策
Layer 3: 临时加载
├── 当前任务相关文件
└── 调试信息
6. 实战技巧
6.1 大文件处理
问题:读取大文件消耗大量上下文
解决:
> 只读取 src/main.js 的前 50 行
> 读取 config.js 中的数据库配置部分
> 搜索 auth.js 中包含 "login" 的行
6.2 多文件协作
问题:需要同时了解多个相关文件
解决:
> 总结 src/auth 目录下各文件的主要功能
(Claude 返回摘要而非完整内容)
> 详细看一下 auth/jwt.js
6.3 长会话管理
检查点机制:
> 我们目前完成了什么?接下来要做什么?
(Claude 总结进度)
> /save
保存当前进度...
> 继续下一步
7. 上下文监控
7.1 查看使用情况
> /cost
上下文使用情况:
- 当前 tokens: 45,000 / 200,000
- 历史消息: 23 条
- 工具调用: 15 次
7.2 预警信号
| 信号 | 含义 | 建议操作 |
|---|---|---|
| 响应变慢 | 上下文接近上限 | 使用 /compact |
| 遗忘之前内容 | 早期信息被裁剪 | 重新提供关键信息 |
| 重复询问 | 上下文碎片化 | 整理并重述需求 |
7.3 优化时机
| 场景 | 建议操作 |
|---|---|
| 切换任务 | /clear 开始新会话 |
| 任务过半 | /compact 压缩上下文 |
| 调试完成 | 清除调试相关信息 |
8. 最佳实践清单
8.1 会话开始
- 明确本次任务目标
- 检查 CLAUDE.md 配置
- 确认相关记忆已加载
8.2 会话进行中
- 按需读取文件
- 及时确认理解
- 定期保存进度
8.3 会话结束
- 总结完成的工作
- 保存重要决策
- 记录待办事项
9. 常见问题
9.1 Claude 忘记了之前说的内容
原因:上下文裁剪
解决:
- 重新提供关键信息
- 使用记忆系统保存重要内容
- 缩短单次会话长度
9.2 响应质量下降
原因:上下文过长或混乱
解决:
- 使用
/compact压缩 - 清理无关信息
- 重新组织问题
9.3 记忆检索不准确
原因:记忆内容不够具体
解决:
- 使用具体的关键词保存
- 添加分类标签
- 定期清理过期记忆
10. 下一步
掌握上下文管理后,继续学习:
- 08-CLAUDE.md配置最佳实践:优化项目配置
- 09-实战案例集锦:综合应用
参考资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)