Qwen-Image-Edit-GGUF编辑图像(含ComfyUI入门)
本文介绍了ComfyUI的安装配置及使用指南。首先提供了基于Mac系统的自动化安装脚本,包含Homebrew依赖安装、Python环境配置、ComfyUI克隆及插件安装等步骤。其次详细解析了AI绘画的核心组件层级关系,包括Diffusion模型、UNet、VAE等模块的功能定位。最后通过实操案例展示了从模板选择、参数设置到图像生成的全流程,并特别介绍了Qwen图像编辑联合插件的安装方法和工作流搭建
1.ComfyUI安装
首选安装comfyui,配置环境
可参考我的my-setup.sh脚本修改,一步到位,Mac电脑几乎不用改(记得先执行/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"安装homebrew),其中ROOT="/Users/Zhuanz/Desktop/work/ComfyUI"改成你的想放comyui的绝对路径,运行时需要联网
#!/bin/bash
set -euo pipefail
ROOT="/Users/Zhuanz/Desktop/work/ComfyUI"
VENV="${ROOT}/.venv" # comfyui-env
REPO="${ROOT}" # /ComfyUI
CUSTOM_NODES="${REPO}/custom_nodes"
echo "==> Using ROOT: ${ROOT}"
mkdir -p "${ROOT}"
# 1) Homebrew 依赖(重复执行也没事)
# uv 建议单独装:brew install uv(也可用官方安装脚本)
if ! command -v brew >/dev/null 2>&1; then
echo "Homebrew 未安装,请先安装 Homebrew: https://brew.sh/"
exit 1
fi
brew install cmake protobuf rust python@3.10 git wget uv || true
# 2) 准备 Python 3.10(uv 需要能找到 3.10)
# 如果你只想用 brew 的 python@3.10,这一步通常也能让 uv 找到 3.10;
# 但为了更稳,额外让 uv 安装/确保 3.10 可用:
uv python install 3.10 || true
# 3) 虚拟环境:存在就复用,不存在就创建
if [ -d "${VENV}" ] && [ -x "${VENV}/bin/python" ]; then
echo "==> Found existing venv: ${VENV}"
else
echo "==> Creating venv with uv: ${VENV}"
uv venv "${VENV}" --python 3.10
fi
PY="${VENV}/bin/python"
# 4) ComfyUI 仓库:存在就复用,不存在就 clone
if [ -d "${REPO}/.git" ]; then
echo "==> Found existing ComfyUI repo: ${REPO}"
else
echo "==> Cloning ComfyUI into: ${REPO}"
git clone https://github.com/comfyanonymous/ComfyUI "${REPO}"
fi
cd "${REPO}"
# 5) 安装依赖(用 uv pip 安装到指定 venv)
echo "==> Upgrading pip"
uv pip install --python "${PY}" --upgrade pip
echo "==> Installing torch/torchvision/torchaudio"
uv pip install --python "${PY}" torch torchvision torchaudio
echo "==> Installing ComfyUI requirements"
uv pip install --python "${PY}" -r requirements.txt
echo "==> Pin numpy==1.26.4 (match tutorial workaround)"
uv pip uninstall --python "${PY}" -y numpy || true
uv pip install --python "${PY}" numpy==1.26.4
# 6) 插件:Manager + 汉化
mkdir -p "${CUSTOM_NODES}"
cd "${CUSTOM_NODES}"
if [ -d "${CUSTOM_NODES}/ComfyUI-Manager/.git" ]; then
echo "==> Found ComfyUI-Manager"
else
echo "==> Cloning ComfyUI-Manager"
git clone https://github.com/ltdrdata/ComfyUI-Manager.git
fi
cd "${CUSTOM_NODES}/ComfyUI-Manager"
uv pip install --python "${PY}" -r requirements.txt
uv pip install --python "${PY}" setuptools
cd "${CUSTOM_NODES}"
if [ -d "${CUSTOM_NODES}/AIGODLIKE-COMFYUI-TRANSLATION/.git" ]; then
echo "==> Found translation plugin"
else
echo "==> Cloning translation plugin"
git clone https://github.com/AIGODLIKE/AIGODLIKE-COMFYUI-TRANSLATION.git
fi
echo "✅ ComfyUI + comfyui-env 部署完成"
echo ""
echo "运行方式:"
echo " cd \"${REPO}\""
# echo " \"${PY}\" main.py"
echo "source .venv/bin/activate"
echo "uv run main.py"到https://hf-mirror.com/LarryAIDraw/v1-5-pruned-emaonly/tree/main下载模型,放到相对路径ComfyUI/models/checkpoints中
2.快速入门
2.1常用模型/模块对比
|
模型 / 模块 |
核心定位 |
所属层级 |
是否可单独加载 |
核心作用 |
典型体积 |
核心作用对象 |
|---|---|---|---|---|---|---|
|
Diffusion Model |
底层算法框架 |
理论框架 |
否 |
定义正 / 反向扩散流程 |
无独立文件 |
无 |
|
Checkpoint |
扩散模型工程化包 |
主模型 |
是 |
集成所有必备模块,独立生成 |
2-20G |
无 |
|
UNet |
核心去噪计算引擎 |
Checkpoint 子模块 |
否 |
反向扩散的核心去噪计算 |
占 ckpt80% 以上 |
潜空间噪声特征 |
|
CLIP/Text Encoder |
文本特征编码器 |
Checkpoint 子模块 |
是 |
把提示词转化为文本特征 |
占 ckpt10% 左右 |
自然语言提示词 |
|
VAE |
潜空间 / 像素空间转换器 |
Checkpoint 子模块 |
是 |
编码(像素→潜特征)+ 解码(潜特征→像素) |
占 ckpt10% 左右 |
像素图 / 潜空间特征 |
|
LoRA |
轻量特征注入插件 |
配套插件 |
是(依附主模型) |
向 UNet 注入特定特征(人物 / 风格) |
10-300MB |
UNet |
|
Embedding |
轻量文本特征注入插件 |
配套插件 |
是(依附主模型) |
向 Text Encoder 注入特征 |
几 KB - 几十 KB |
CLIP Text Encoder |
|
ControlNet |
几何特征控制插件 |
配套插件 |
是(依附主模型) |
向 UNet 注入几何控制特征 |
1-4G |
UNet |
|
Hypernetwork |
特征增强插件(早期) |
配套插件 |
是(依附主模型) |
变换 UNet 中间特征层 |
100-500MB |
UNet |
|
IP-Adapter |
图提示词控制插件 |
配套插件 |
是(依附主模型) |
向 UNet 注入图像参考特征 |
几百 MB |
UNet |
|
Refiner |
细节优化模型 |
配套模型 |
是(依附主模型) |
精细化去噪,提升图像细节 |
1-5G |
主模型生成的潜特征 |
2.2模板实操
打开http://127.0.0.1:8188/,点击模板
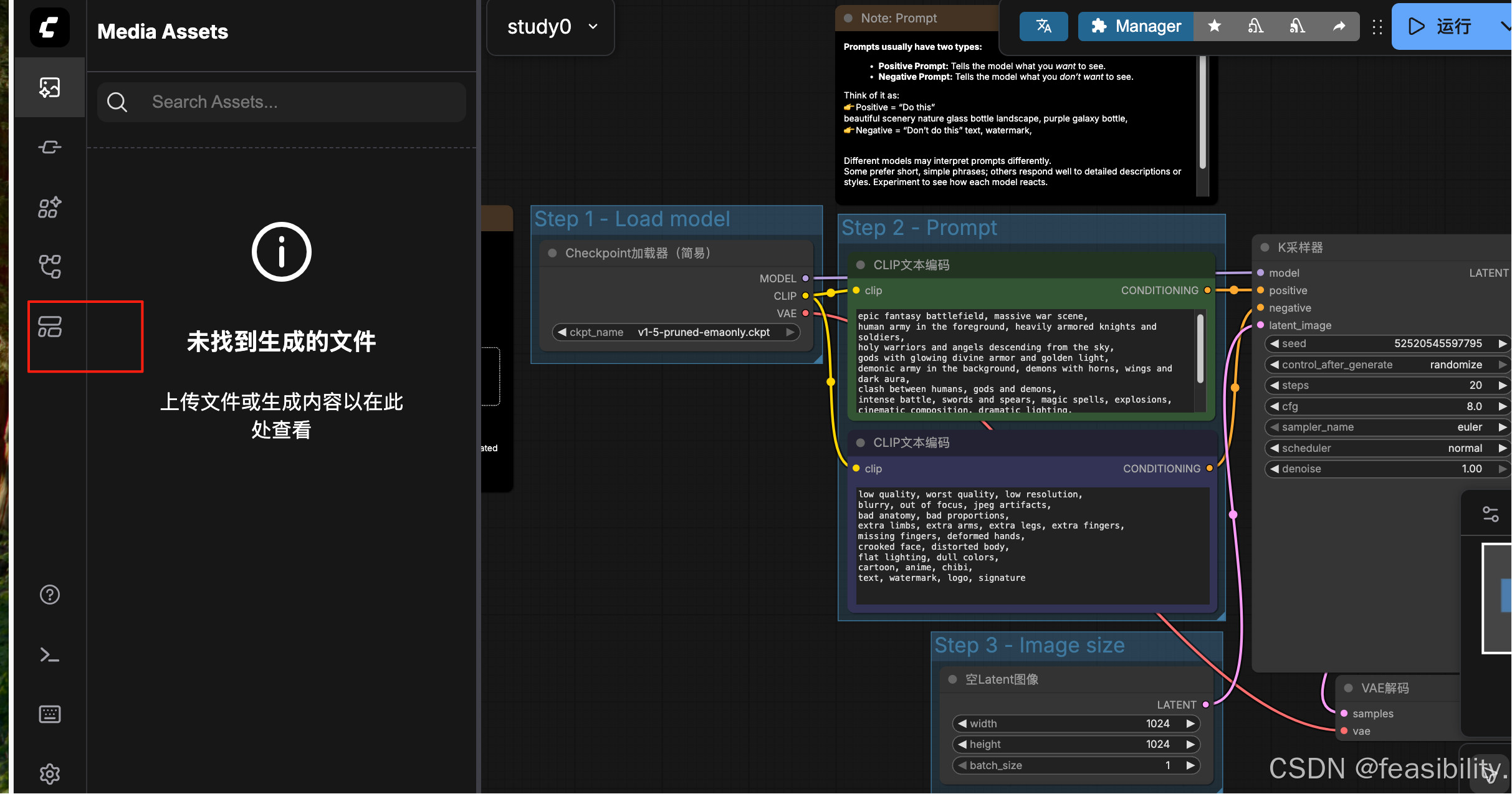
点击快速开始,选择最后一个模板点击
这个模板的工作流是:加载模型 → 写提示词 → 设定尺寸 → 采样生成 → 保存图片
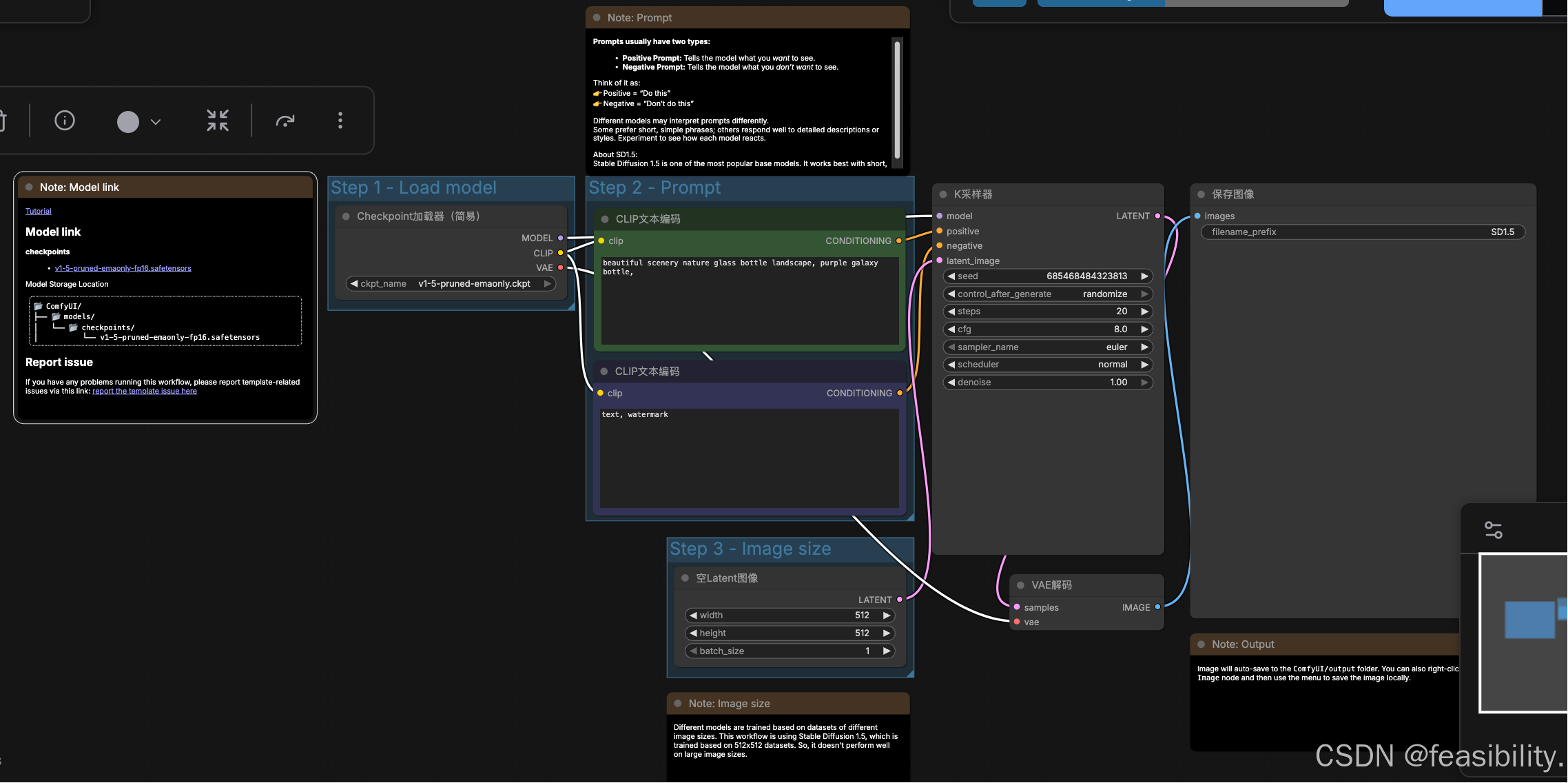
Step 1:加载模型
左上:Load model / Checkpoint
-
这里选的是:
v1-5-pruned-emaonly.ckpt -
作用:决定整体画风(写实 / 二次元 / 插画 等)
Step 2:提示词Prompt(对国外模型建议用英文提示词)
1) 正向提示词
用于描述要画的内容或效果等,一般来说越具体越好
2) 反向提示词
用于描述不要画出来的内容或效果等,如text(文字)、 watermark(水印)
Step 3:图片尺寸
-
width:宽度,默认是512,越大会相应增加时间和空间的开销
-
height:高度,默认是512,越大会相应增加时间和空间的开销
-
batch_size:生成图片的数量,默认是1,越大会相应增加时间和空间的开销
核心生成器:K采样器
关键参数:
|
参数 |
解释 |
|---|---|
|
seed |
随机种子(同一 seed = 类似画面,用于复现结果) |
|
steps |
从纯噪声图逐步去除噪声、生成清晰图像的迭代次数(通常20~30)。次数太少会导致图像模糊、噪点多、细节缺失,次数过多会使生成时间大幅增加,但效果提升边际递减 |
|
cfg |
分类器自由引导,控制AI遵守提示词的程度,数值越高,AI 越 “听话”,越低则越自由发挥,常用7–9 |
|
sampler |
采样器去除噪声、生成图像的算法,常见类型 & 特点:
|
|
denoise |
去噪强度,仅用于 “图生图” 场景,控制 AI 保留原图特征的程度,取值范围 0-1,为0时完全保留原图,无任何修改;为1时完全忽略原图,等同于 “文生图”(从头生成) 常用数值场景: 轻微修图(换色调 / 补细节):0.1-0.3; 保留构图改内容(比如把原图的猫换成狗):0.5-0.7; 仅留轮廓重绘:0.8-1.0。 |
新手一般steps 20 + cfg 8 + Euler即可
VAE 解码(从“草稿”变成“图片”)
是特征到像素的生成过程,解码器会根据潜特征的抽象信息,“创造” 出具体的像素细节(比如潜特征中只有 “猫的轮廓”,解码器会生成猫的毛发、眼睛、胡须等像素细节);
保存图像Save Image
-
filename_prefix:文件名前缀
-
图片会自动存到
ComfyUI/output文件夹
点击运行,过一会就可以生成图片,在图片那里点击右键会显示保存图片的选项,点击Save Image就能下载图片
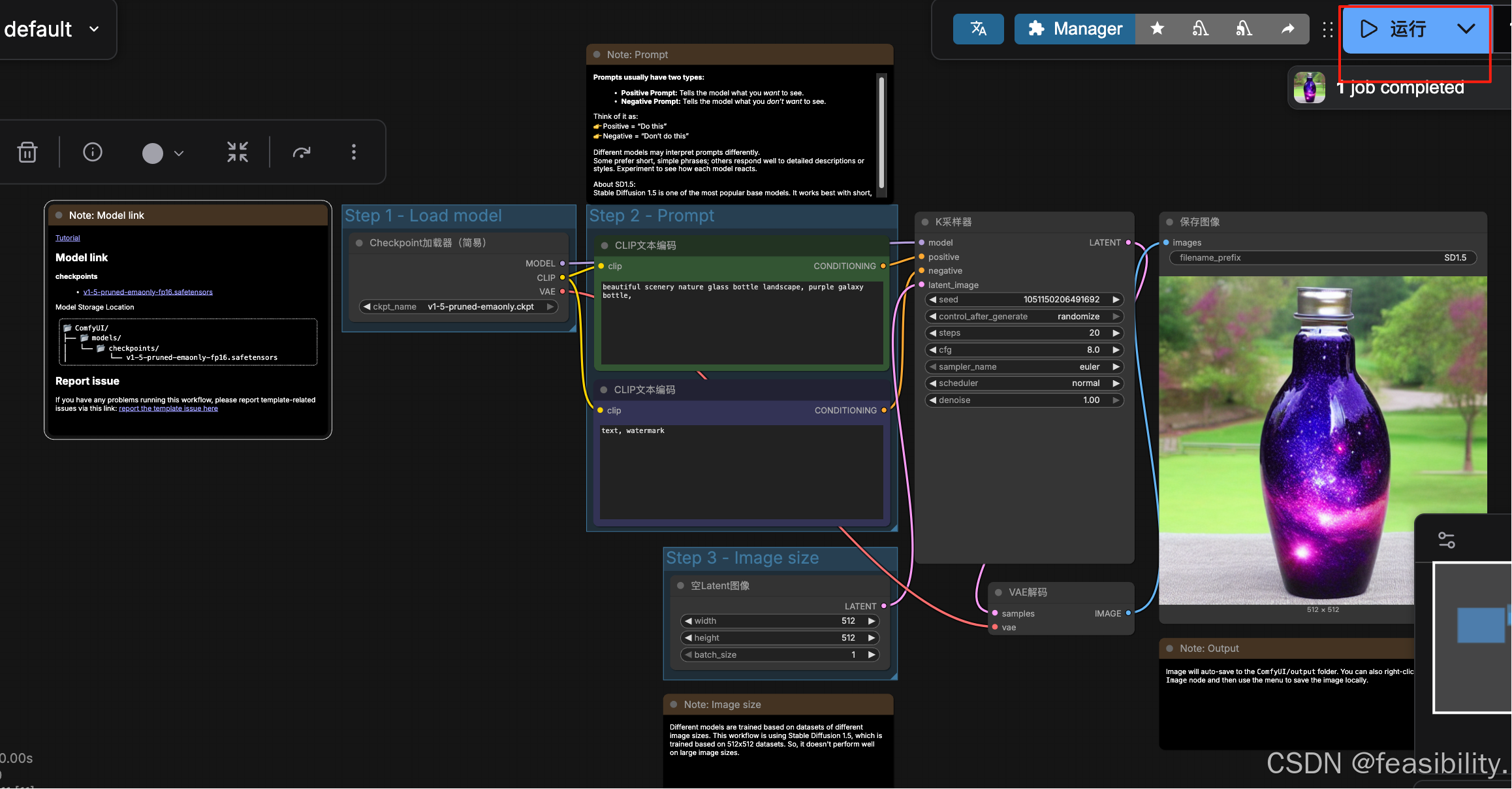
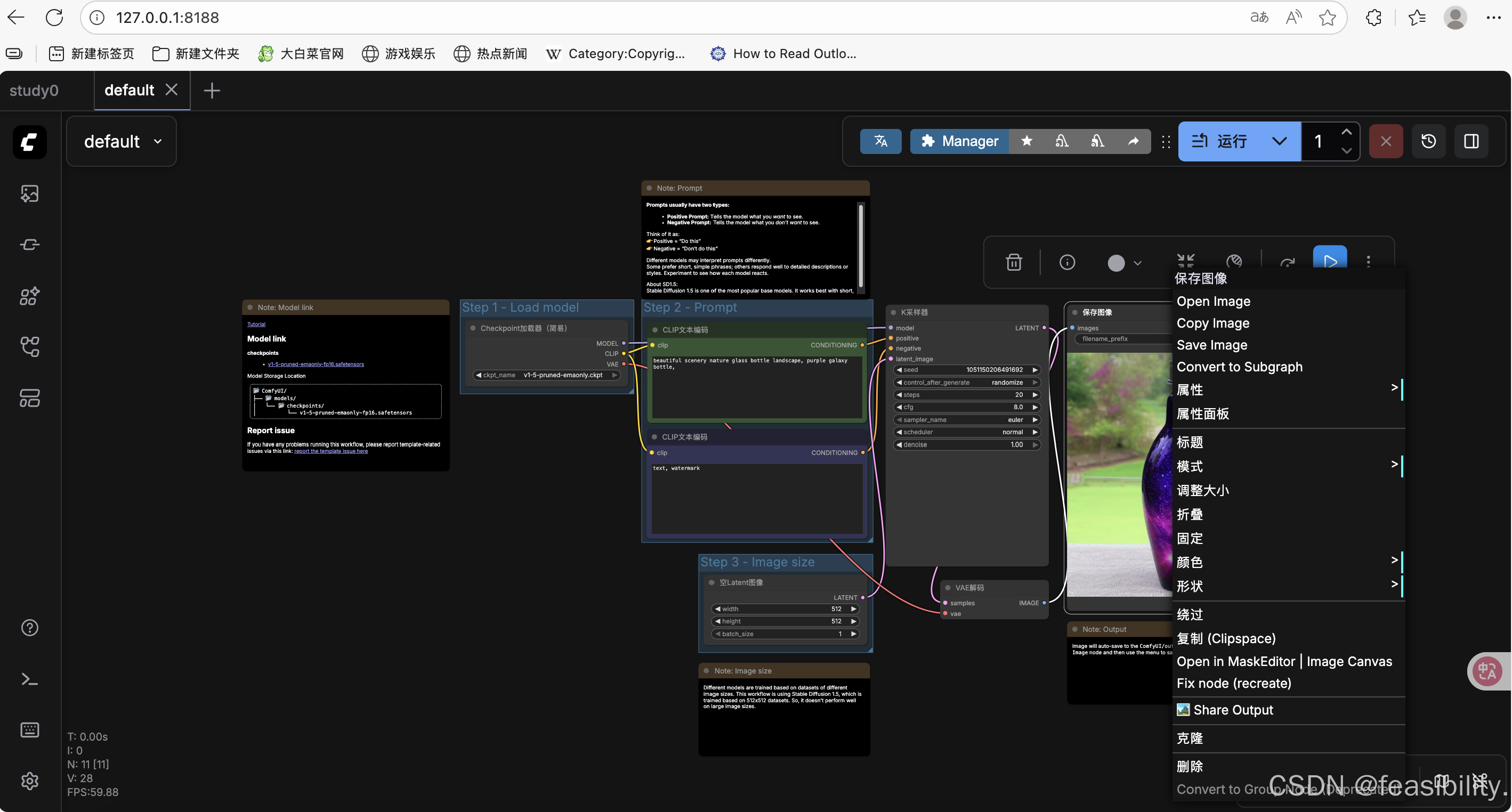
你也可以改其他提示词试试~
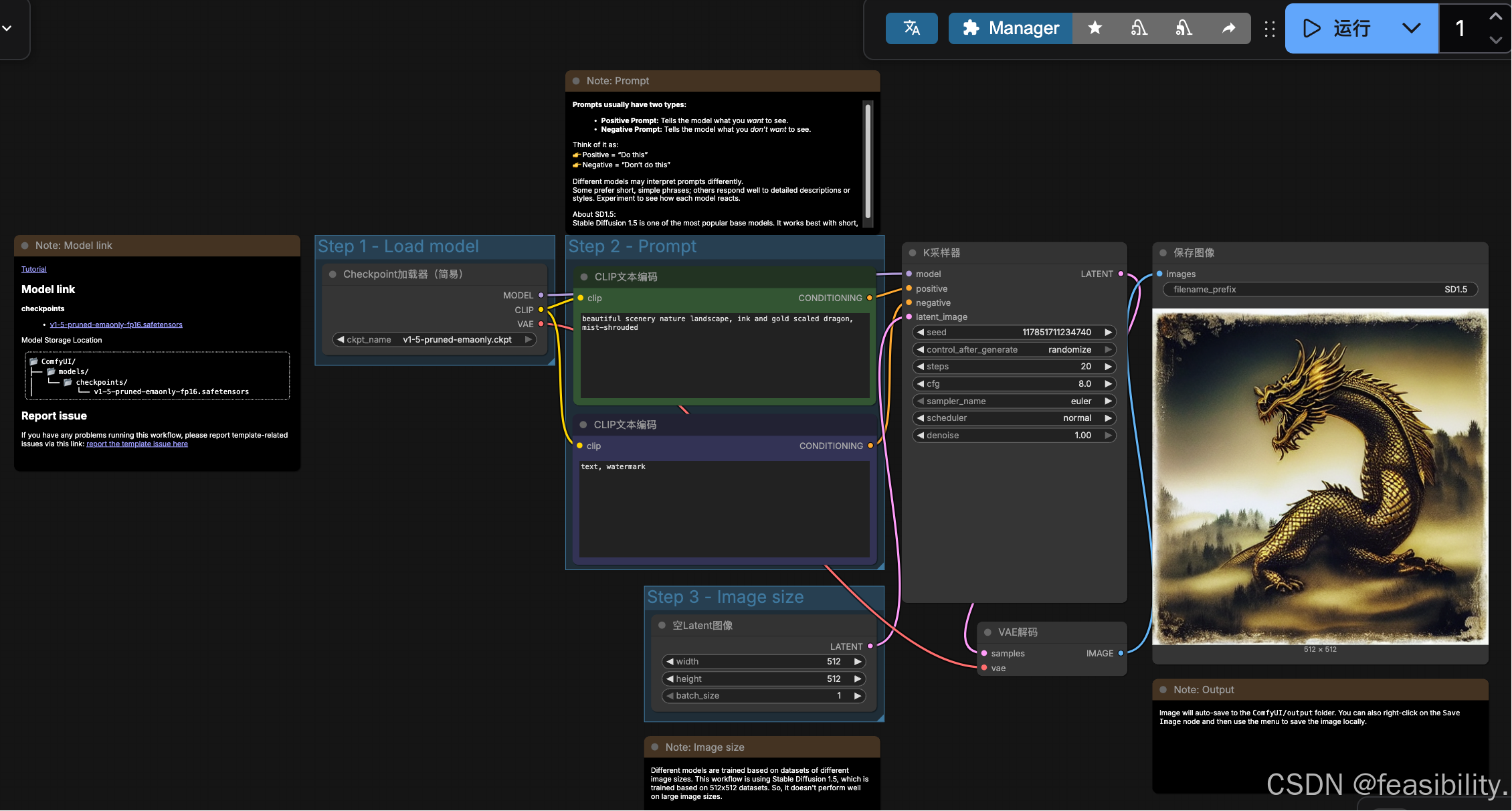
3.Qwen-Image-Edit-2511-GGUF 编辑图像
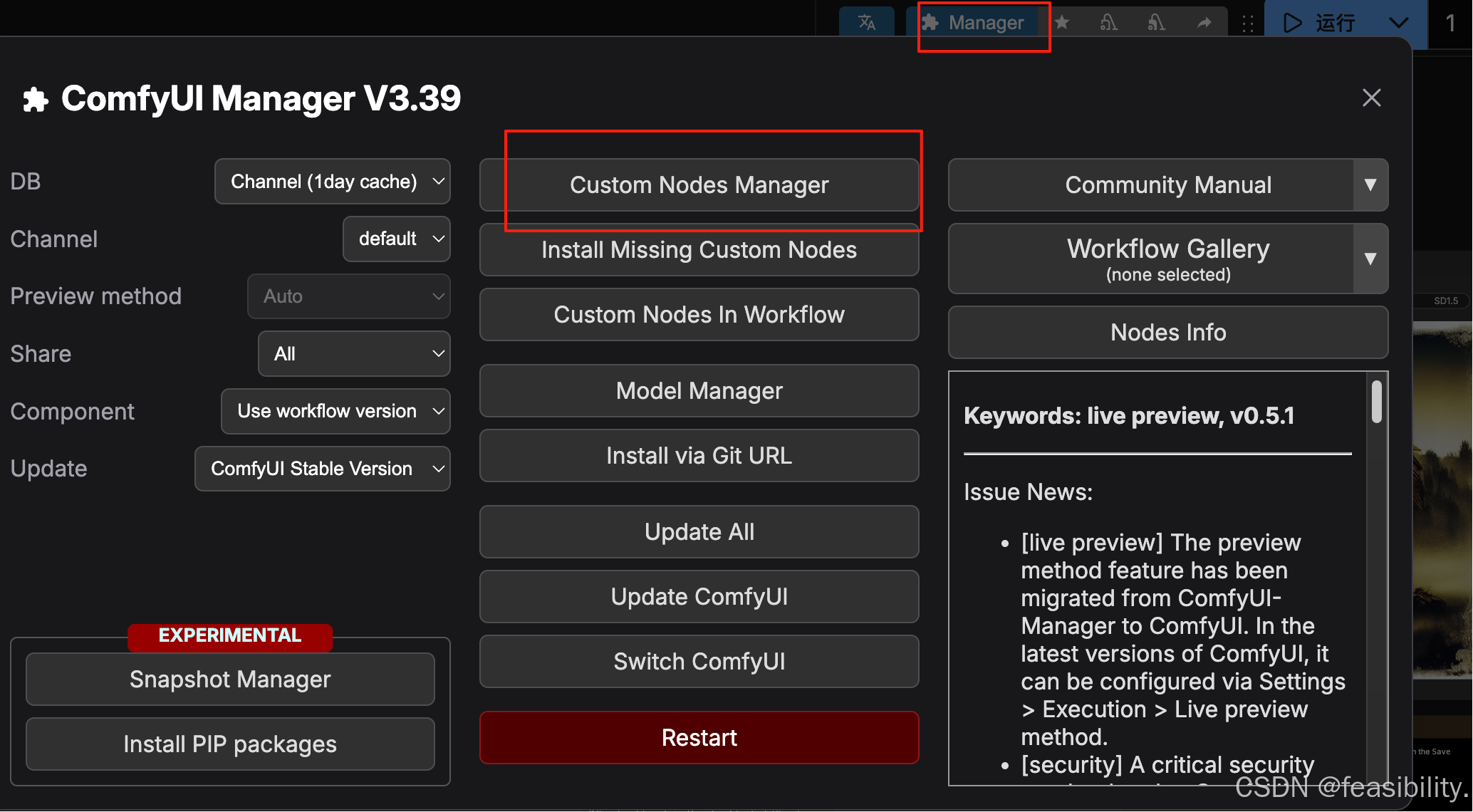
3.1安装ComfyUI-GGUF
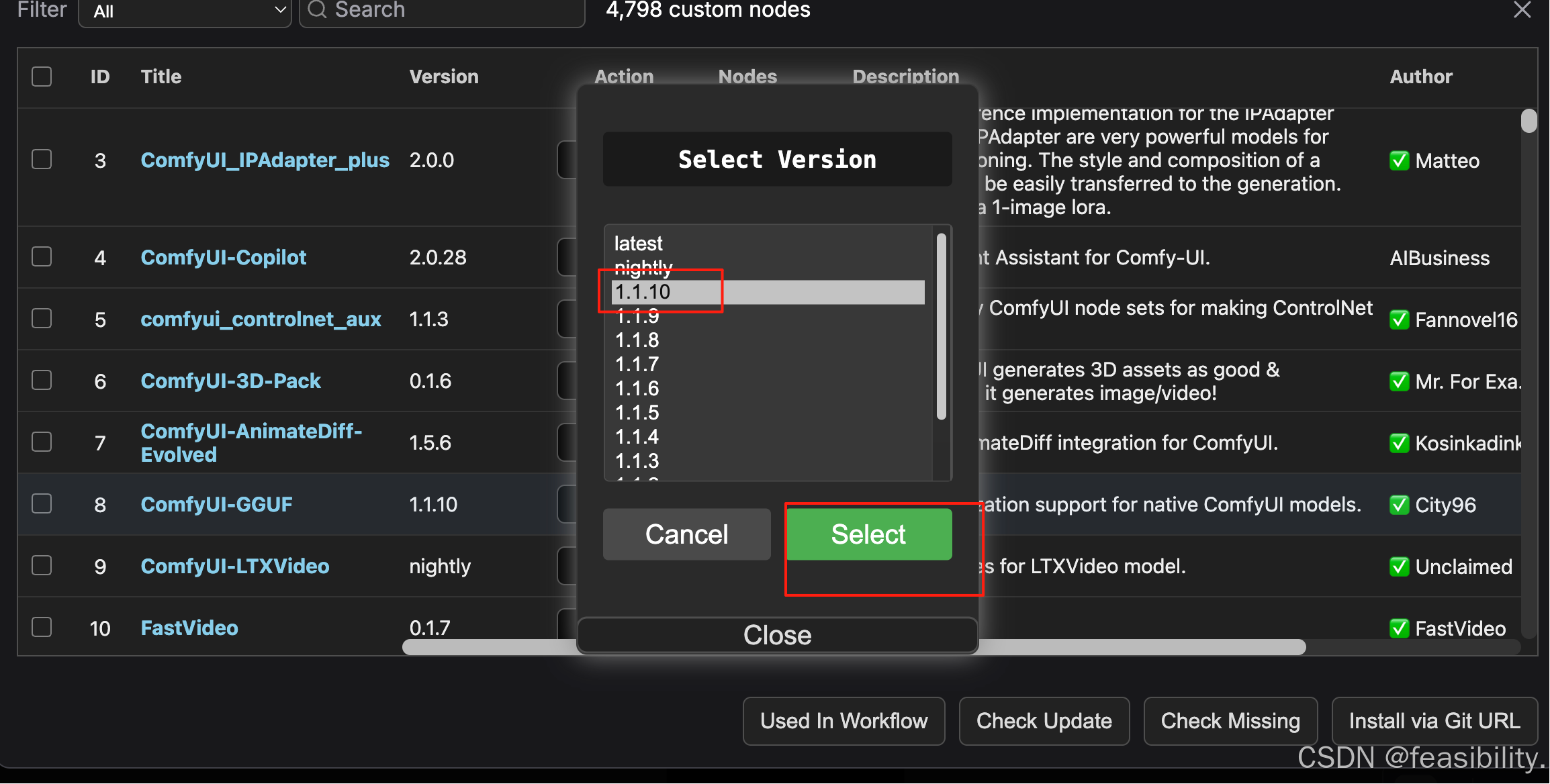
点击右上角的Manager,然后点击Custom Nodes Manager
选择ComfyUI-GGUF的1.1.10版本进行安装
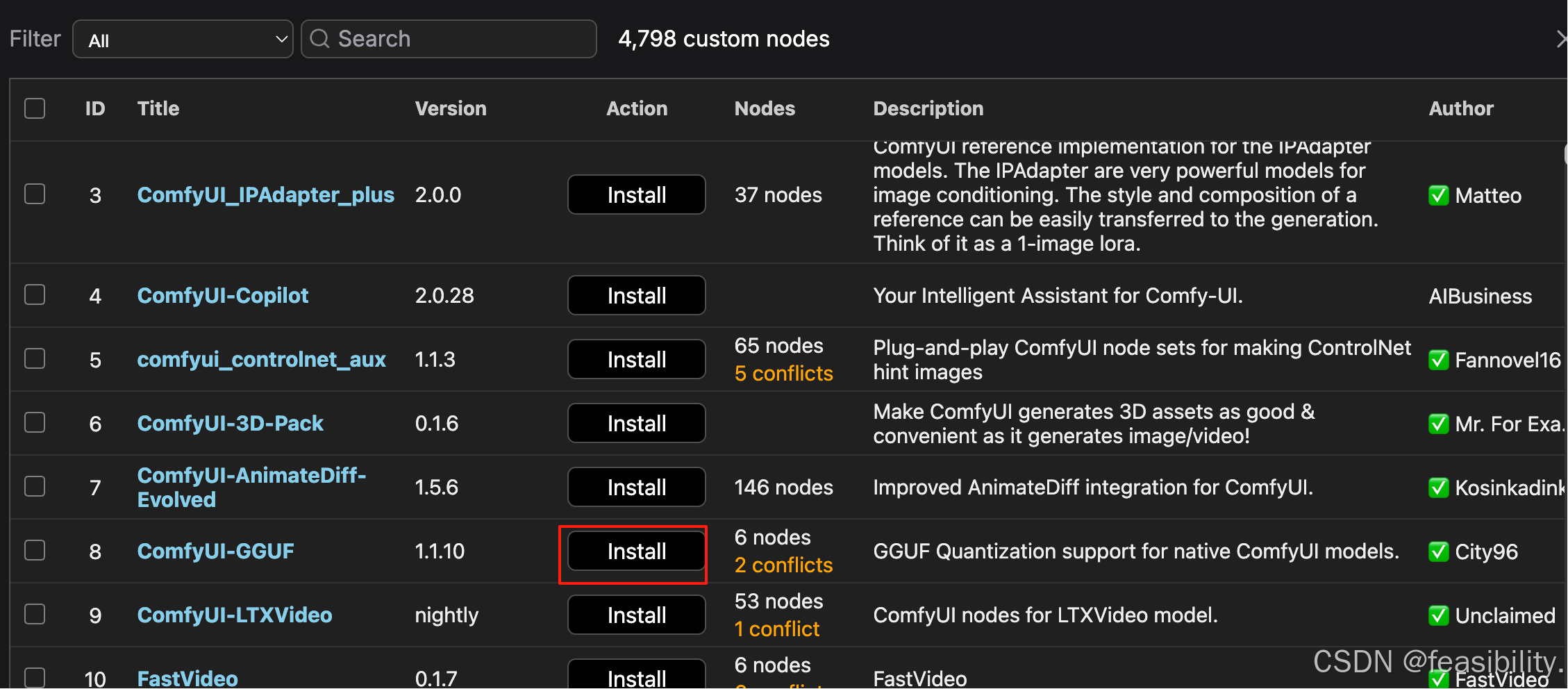
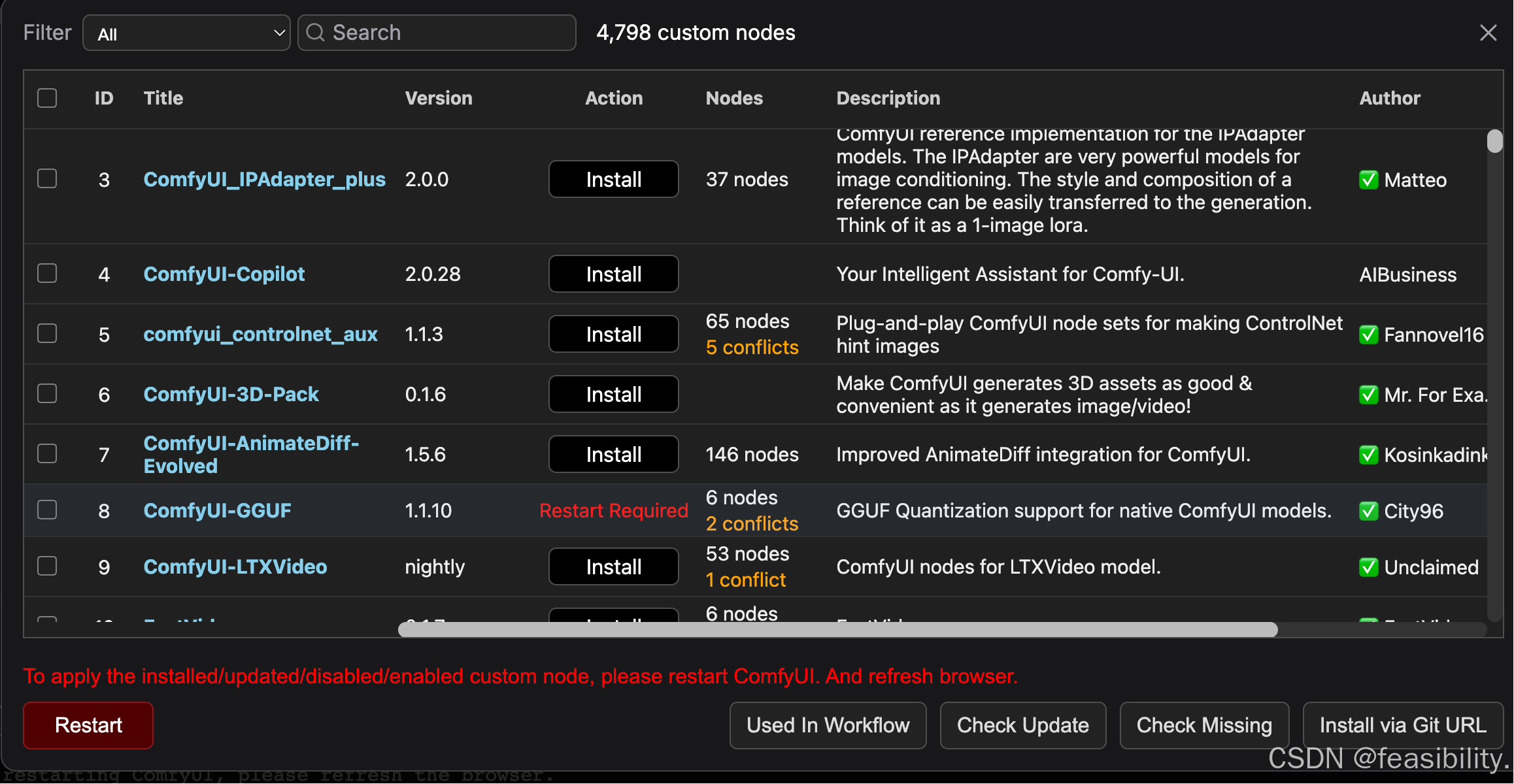
出现下面的红字说明安装完成,刷新浏览器就能应用
3.2下载模型
在https://hf-mirror.com/unsloth/Qwen-Image-Edit-2511-GGUF/tree/main下载Qwen-Image-Edit-2511-GGUF量化后的扩散模型,这里选择qwen-image-edit-2511-Q4_0.gguf,放到ComfyUI/models/unet
打开链接下载模型,这里选择Qwen-Image-Edit-2511-Lightning-4steps-V1.0-bf16.safetensors,放到ComfyUI/models/loras中
打开链接下载文本编码器,这里选择qwen_2.5_vl_7b_fp8_scaled.safetensors,放到ComfyUI/models/text_encoders中
打开链接下载变分自编码器,选择qwen_image_vae.safetensors,放到ComfyUI/models/vae中
3.3搭建工作流
提前准备两张图放到ComfyUI/input中
到这个链接:
加载工作流
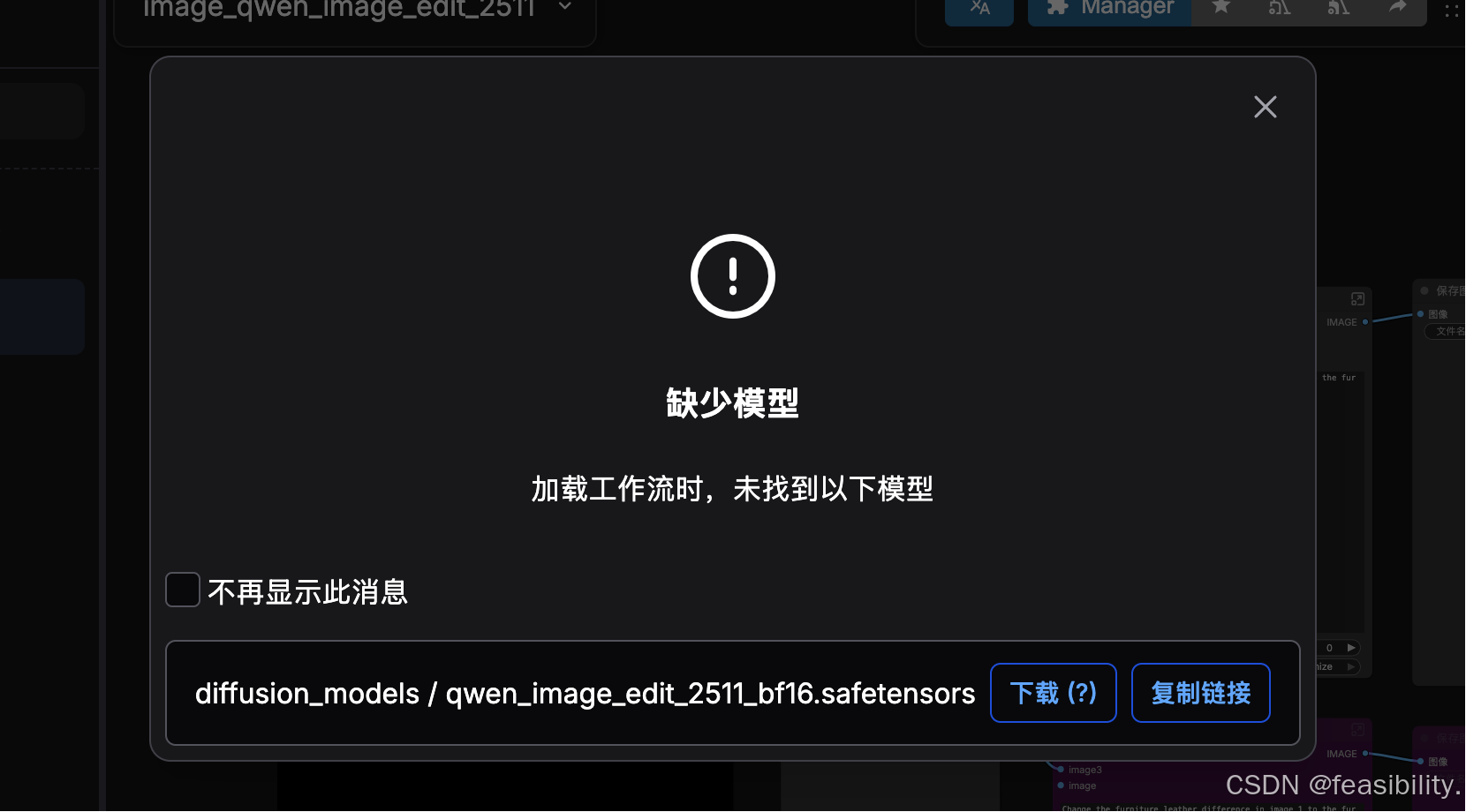
提示缺乏模型,可以关闭,因为没下载原版扩散模型等对应位置
点击打开子图节点,查看具体组件连接,删除UNET加载器
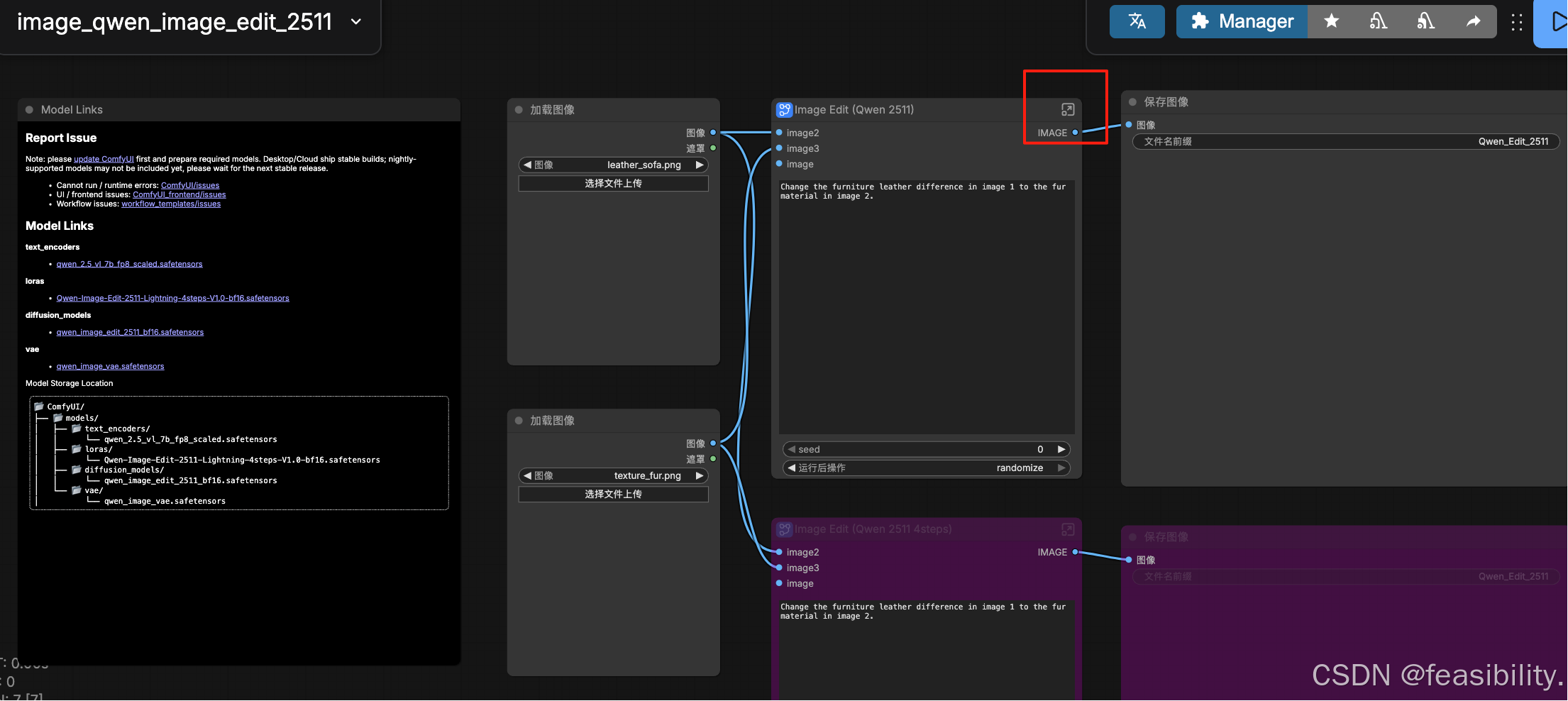
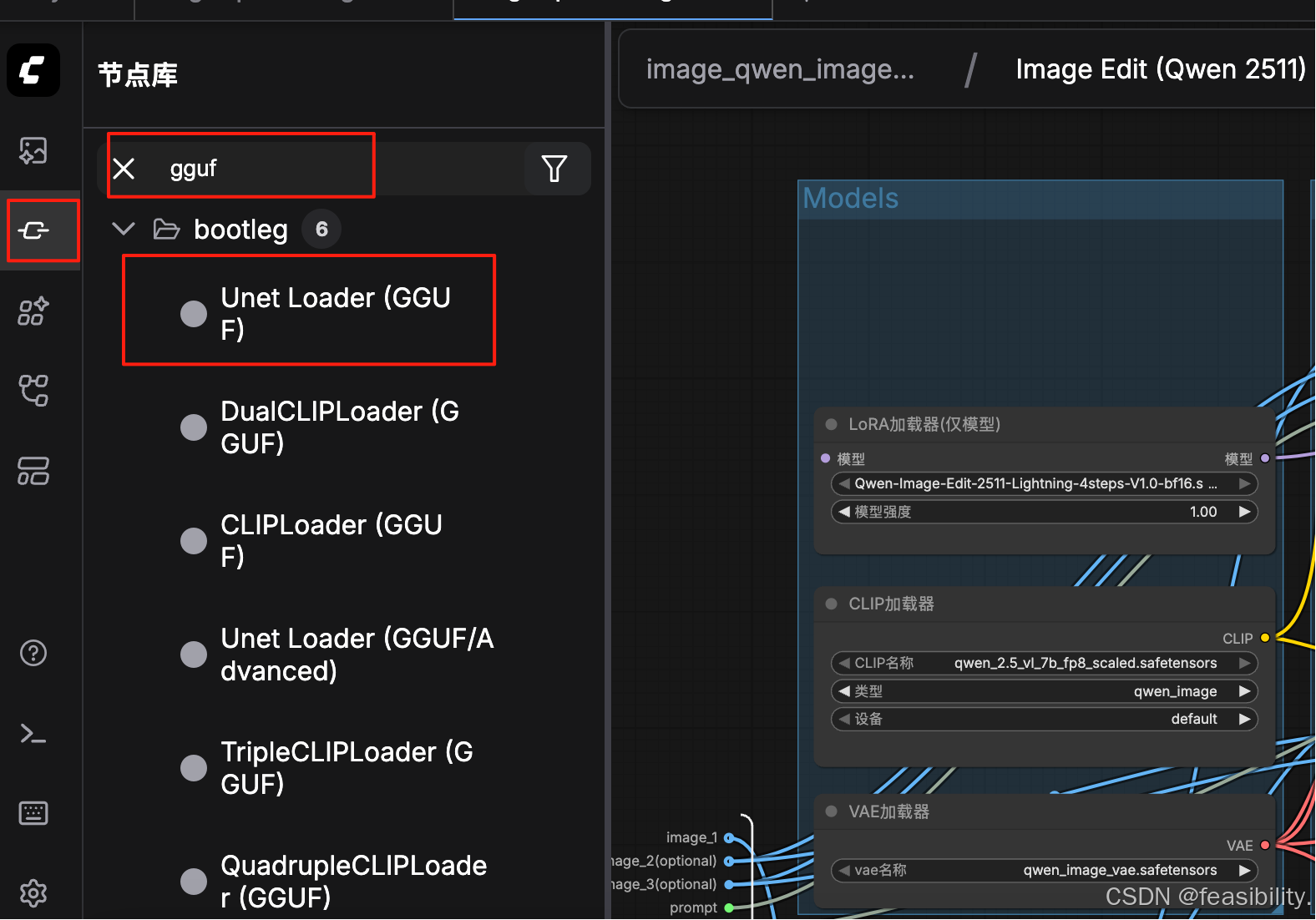
点击节点库,搜索gguf,选择支持GGUF格式的UNET加载器
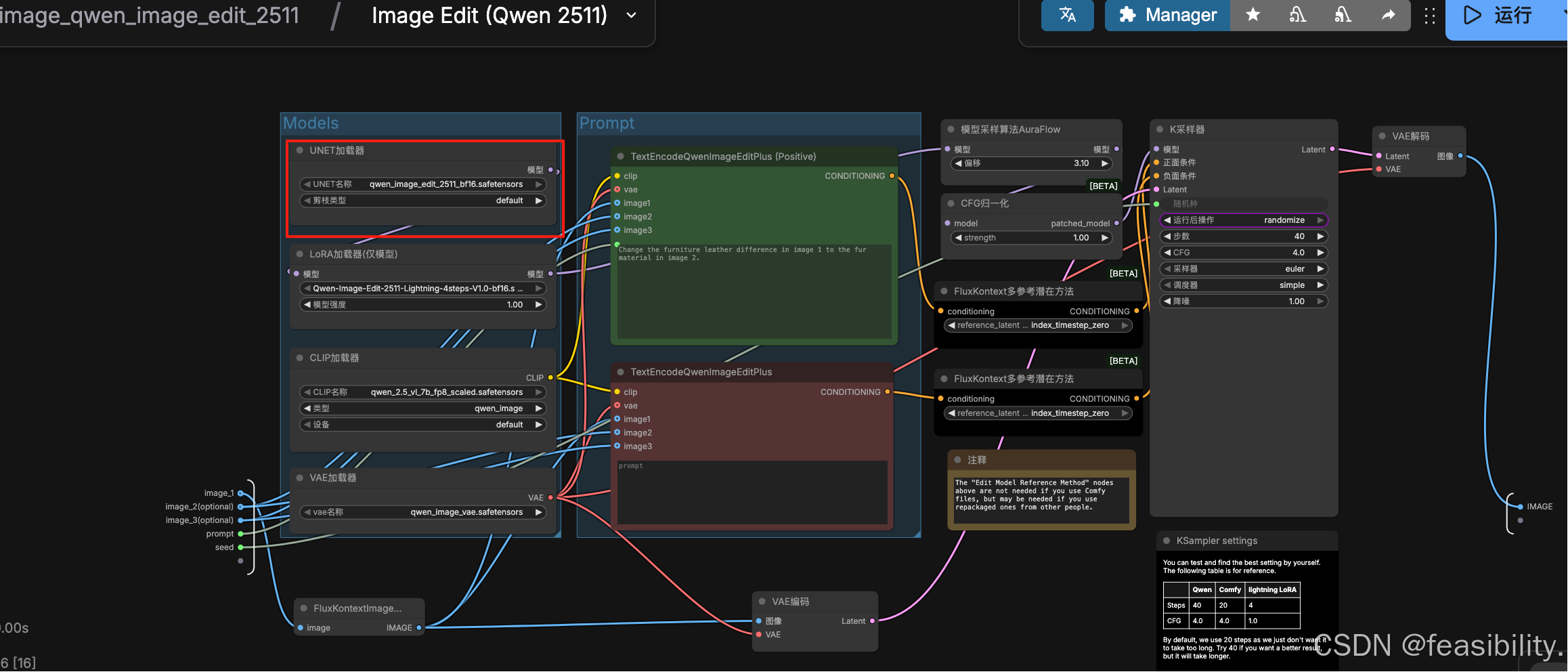
将Unet Loader (GGUF)移到合适的位置,连接LoRA加载器
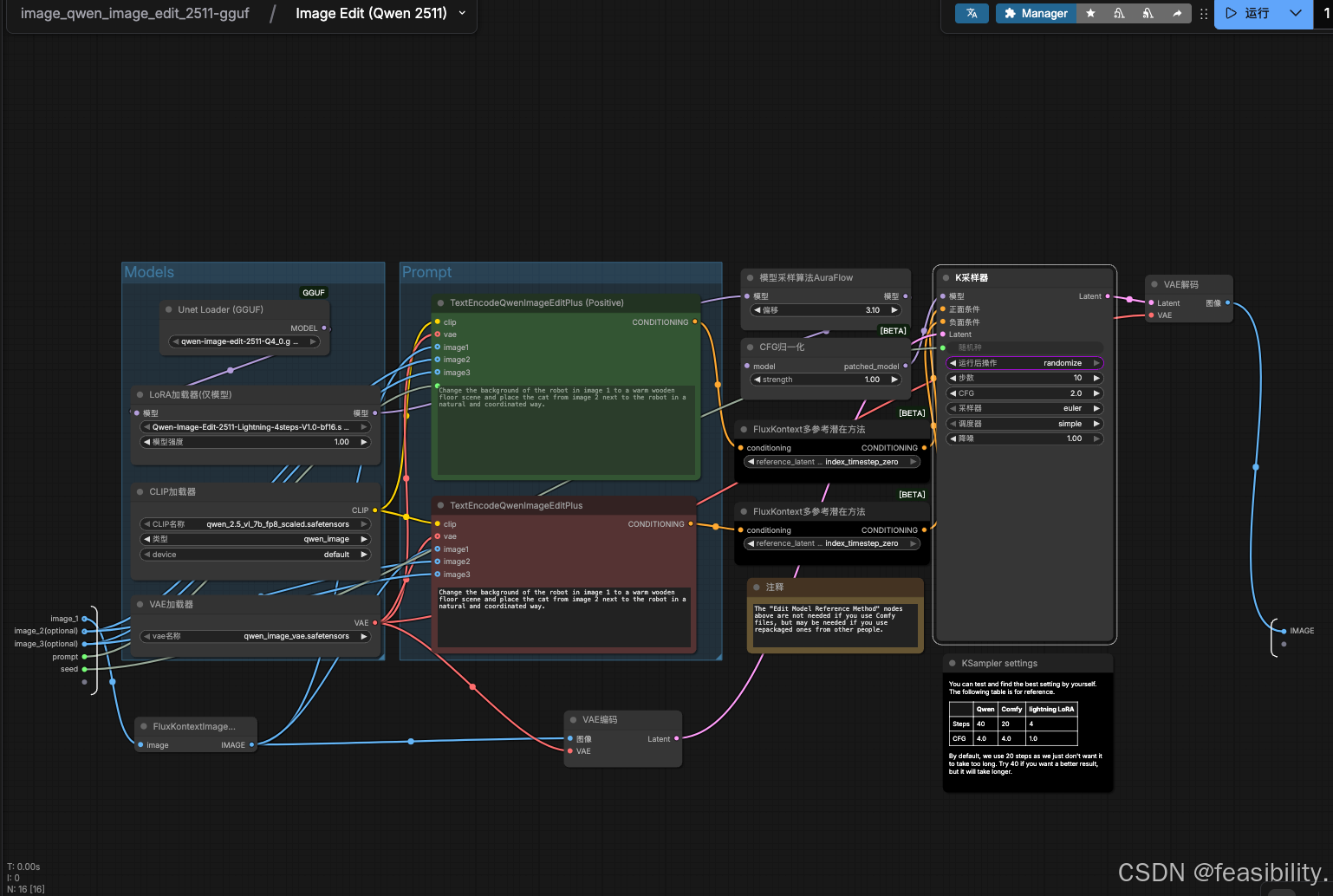
放入你的两张图片,输入提示词,只填上面即可,下面的紫灰色分支默认禁用(在json文件中这个节点被设置mode=4 通常表示节点处于“禁用/旁路”状态),这里为了快速查效果和避免内存不足,设置步数为10,CFG=10,如果硬件较好建议按默认
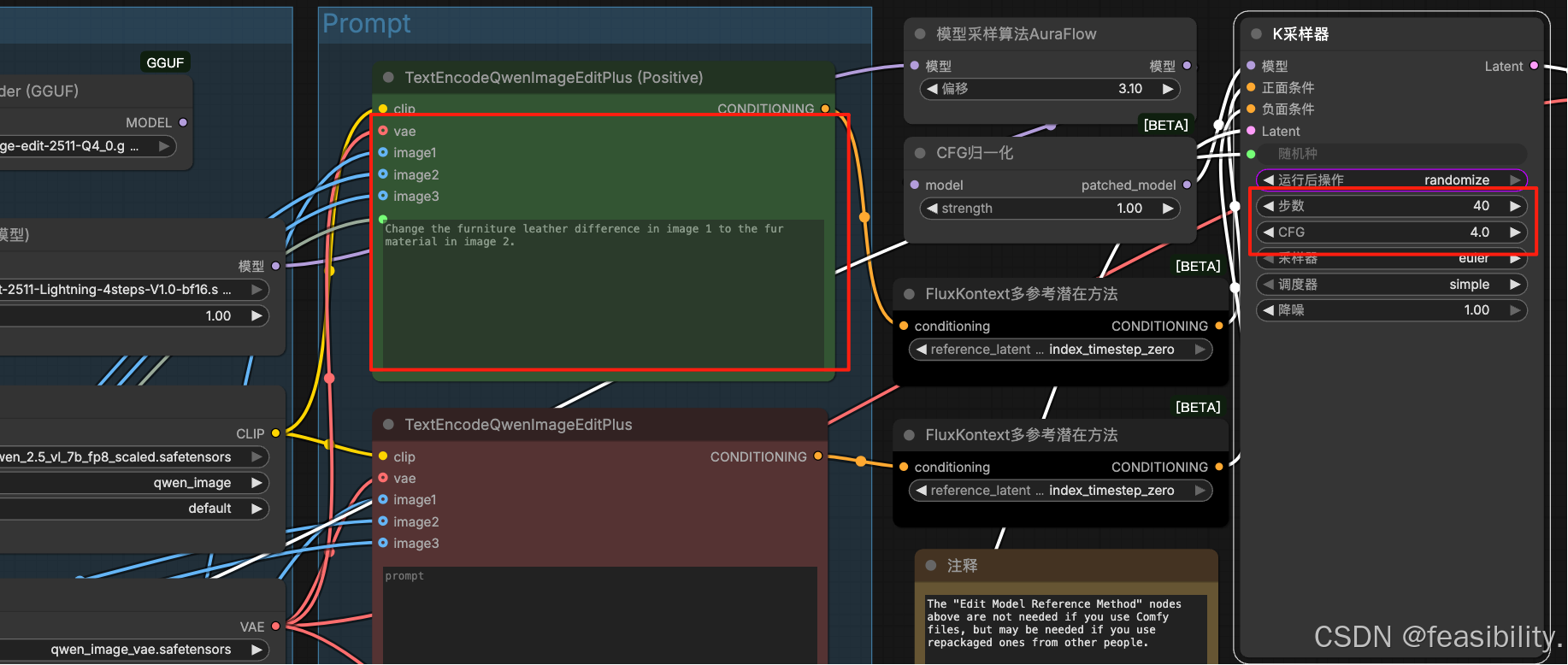
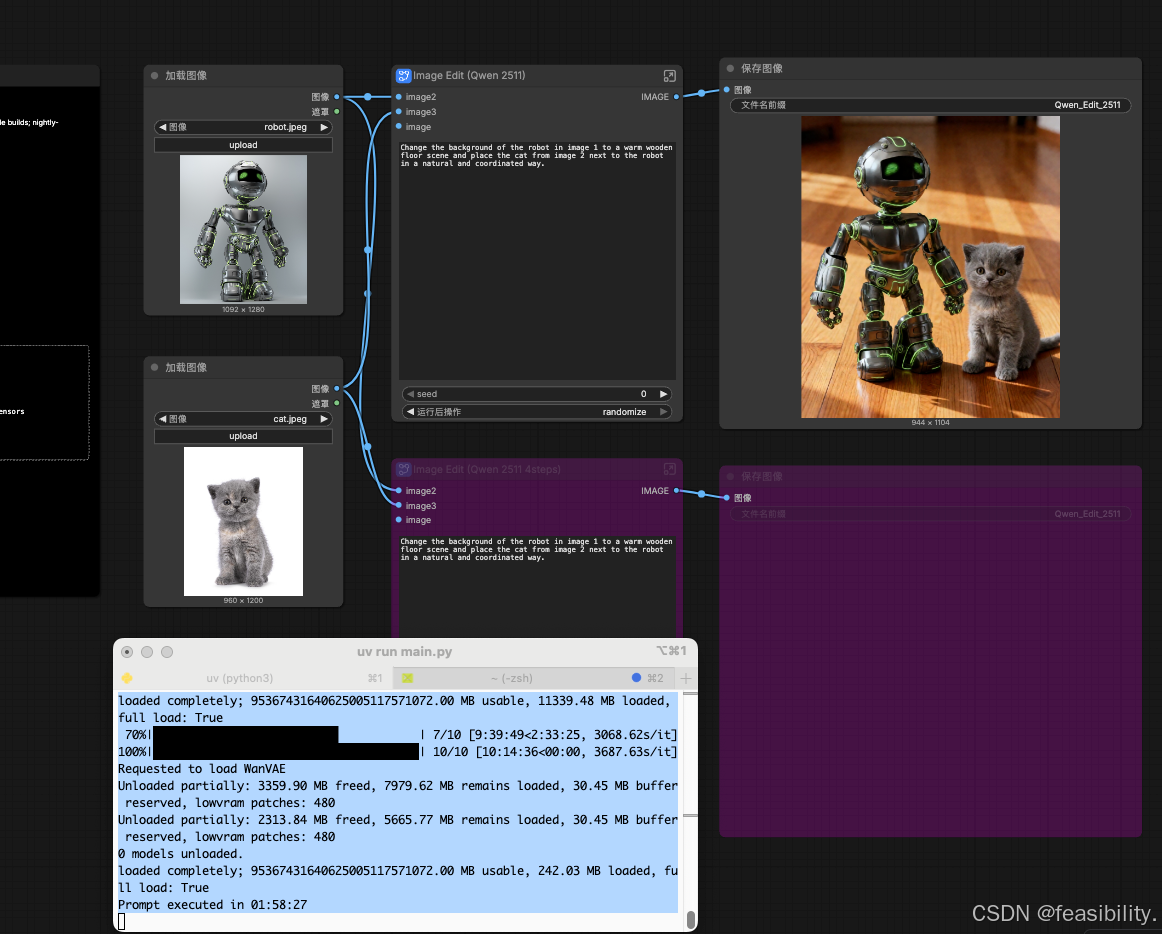
点击运行,最后可以看出效果不错,生成的图片等主体接近原图的机器人和猫,另外下面那条链路没有参与本次执行,因此不会出图。
创作不易,禁止抄袭,转载请附上原文链接及标题

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)