【AI大模型前沿】GLM-4.6V:智谱多模态大模型的创新突破与应用实践
GLM-4.6V是智谱AI与清华大学联合推出的多模态大模型系列,旨在实现高保真视觉理解和长上下文推理。该系列包含基础版GLM-4.6V(106B参数,12B激活)和轻量版GLM-4.6V-Flash(9B参数),支持长达128K tokens的上下文,并首次将原生多模态函数调用能力融入视觉模型,实现了从视觉感知到可执行行动的闭环。
系列篇章💥
前言
随着人工智能技术的飞速发展,多模态大模型逐渐成为研究与应用的热点。智谱AI于2025年12月8日开源的GLM-4.6V系列多模态大模型,凭借其在视觉理解、长上下文处理以及原生多模态工具调用等多方面的卓越表现,为多模态领域的研究与应用带来了新的突破。
一、项目概述
GLM-4.6V是智谱AI与清华大学联合推出的多模态大模型系列,旨在实现高保真视觉理解和长上下文推理。该系列包含基础版GLM-4.6V(106B参数,12B激活)和轻量版GLM-4.6V-Flash(9B参数),支持长达128K tokens的上下文,并首次将原生多模态函数调用能力融入视觉模型,实现了从视觉感知到可执行行动的闭环。
二、核心功能
(一)高保真视觉理解与长上下文推理
GLM-4.6V能够处理图像、文档和混合媒体,进行精确的视觉分析和跨多页的复杂推理。其上下文窗口提升至128K tokens,可理解长达150页的复杂文档或1小时的视频内容,支持跨文档对比分析和长视频关键事件定位。
(二)原生多模态函数调用
模型支持将图像、截图、文档页面等视觉资产直接作为参数传递给外部工具,无需先转换为文本描述,同时能处理工具返回的多模态结果,如统计图表、网页截图等,实现视觉感知与工具执行的无缝连接。
(三)图文交错内容生成
从多模态输入(如混合文本/图片论文、报告、幻灯片)自动生成高质量、结构化的图文交错内容,适用于内容创作、社交媒体发布等场景。
(四)UI重建与视觉编辑
能从UI截图像素级重建HTML/CSS代码,并支持自然语言驱动的迭代视觉编辑和代码生成,加速前端开发流程。
(五)多版本部署支持
提供面向云端高性能场景的基础版和面向本地部署、低延迟应用的轻量版,满足不同场景需求。
三、技术揭秘
(一)模型架构
GLM-4.6V继承了GLM-4.5V的MoE(Mixture-of-Experts)架构,采用106B总参数规模,每次推理仅激活12B参数,有效降低计算成本。在多模态处理层面,模型采用视觉编码器将图像转换为特征表示,MLP适配器作为视觉和语言模态的桥梁,LLM解码器基于GLM架构,负责理解整合后的多模态信息并生成响应。
(二)原生多模态工具调用技术
通过扩展MCP(Model Context Protocol)协议,工具接收和返回的是指向特定图像或帧的URL,模型可以直接“看懂”工具返回的视觉结果,并将其与文本融合在同一个推理链中,避免了传统架构中信息丢失的问题。
(三)长上下文建模
模型将训练时上下文窗口提升到128k tokens,通过系统性的持续预训练和视觉语言压缩对齐技术,增强了视觉编码与语言语义之间的协同作用,有效支持高信息密度场景下的跨模态依赖建模。
四、基准评测
GLM-4.6V在MMBench、MathVista、OCRBench等30多个主流多模态评测基准上进行了验证,较上一代模型取得显著提升。9B版本的GLM-4.6V-Flash整体表现超过Qwen3-VL-8B,106B参数12B激活的GLM-4.6V表现比肩2倍参数量的Qwen3-VL-235B。在同等参数规模下,模型在多模态交互、逻辑推理和长上下文等关键能力上取得SOTA表现。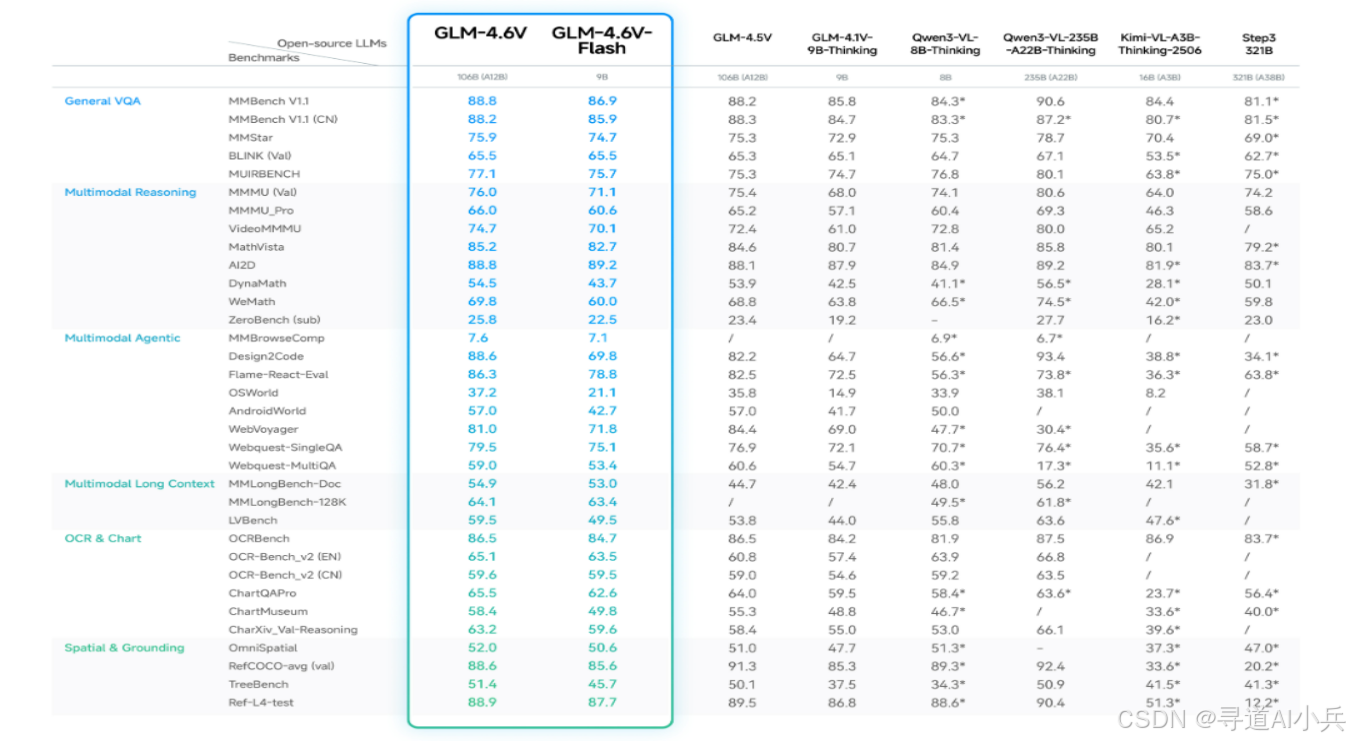
五、应用场景
(一)智能图文创作
GLM-4.6V能够根据用户输入的主题或图文混杂资料,自动生成结构清晰、图文并茂的内容。例如,用户只需提供一个新闻主题,模型就能结合相关图片和文字生成一篇完整的新闻报道,适用于社交媒体、公众号等平台,帮助创作者快速产出高质量内容。
(二)视觉驱动购物
用户上传商品图片并发出指令,GLM-4.6V能够识别购物意图,搜索同款商品并生成导购清单。例如,在电商平台上,用户上传一张心仪商品的图片,模型会自动搜索并推荐同款或相似商品,同时提供比价信息,提升电商购物体验。
(三)前端开发辅助
上传网页截图或设计稿,GLM-4.6V可以精准复刻生成HTML/CSS/JS代码,并支持基于截图的多轮视觉交互修改。例如,开发者上传一个设计稿后,模型快速生成代码,开发者可以通过圈选区域并用自然语言描述修改需求(如“将按钮向左移动并改为深蓝色”),模型会自动修改代码,显著加速前端开发流程。
(四)长文档与视频理解
GLM-4.6V能够处理长文档或长视频,支持跨文档对比分析和关键事件定位。例如,用户可以上传多篇金融报告,模型会提取核心指标并生成对比分析表;或者上传一小时的足球比赛视频,模型可以总结进球事件及其时间戳,助力复杂内容的理解和研究。
(五)多模态智能客服
结合视觉和文本信息,GLM-4.6V能够提供精准解答和建议,支持多轮对话。例如,用户在咨询产品使用问题时,可以上传产品图片并描述问题,模型会结合图片和文字信息,提供详细的解答和操作指导,提升客户服务效率。
六、快速使用
(一)环境安装
在开始使用GLM-4.6V之前,需要先安装相关依赖环境。可以通过以下命令安装:
pip install -r requirements.txt
注意,vLLM和SGLang的依赖可能会发生冲突,因此建议在每个环境中只安装其中一个。安装完成后,需要验证transformers的版本,确保其升级到5.0.0rc0或更高版本。
(二)使用transformers进行推理
1、命令行推理
使用transformers后端进行连续对话的命令行工具trans_infer_cli.py。
python trans_infer_cli.py
运行后,根据提示输入文本或上传图像等多模态数据,即可与模型进行交互。
2、Gradio Web界面
使用trans_infer_gradio.py启动一个Gradio Web界面,支持图像、视频、PDF、PPT等多种多模态输入。
python trans_infer_gradio.py
启动后,通过浏览器访问生成的地址,即可在Web界面中与模型进行交互。
(三)使用vLLM进行推理
1、启动vLLM服务
使用以下命令启动vLLM服务,加载GLM-4.6V模型。
vllm serve zai-org/GLM-4.6V \
--tensor-parallel-size 4 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--served-model-name glm-4.6v \
--allowed-local-media-path / \
--mm-encoder-tp-mode data \
--mm_processor_cache_type shm
该命令会启动一个本地服务,模型名称为glm-4.6v。
2、客户端调用
在客户端通过API调用模型进行推理。例如,使用Python代码发送请求:
import requests
url = "http://localhost:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"model": "glm-4.6v",
"messages": [
{"role": "user", "content": "你好,GLM-4.6V!"}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
(四)使用SGLang进行推理
1、启动SGLang服务
使用以下命令启动SGLang服务,加载GLM-4.6V模型。
python3 -m sglang.launch_server --model-path zai-org/GLM-4.6V \
--tp-size 4 \
--tool-call-parser glm \
--reasoning-parser glm \
--served-model-name glm-4.6v \
--mm-enable-dp-encoder \
--port 8000 \
--host 0.0.0.0
该命令会启动一个本地服务,模型名称为glm-4.6v。
2、客户端调用
在客户端通过API调用模型进行推理。例如,使用Python代码发送请求:
import requests
url = "http://localhost:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"model": "glm-4.6v",
"messages": [
{"role": "user", "content": "你好,GLM-4.6V!"}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
(五)快速体验
如果不想进行本地部署,可以直接通过智谱AI的在线平台进行体验。访问z.ai,选择GLM-4.6V模型,上传图片或输入文字,点击“推理”即可查看结果。此外,也可以通过智谱清言APP或网页版进行体验。
(六)API调用
对于需要将GLM-4.6V集成到现有应用中的开发者,可以通过智谱AI提供的OpenAI兼容API进行调用。访问智谱AI的API文档,获取API密钥并按照文档说明进行调用,即可在自己的应用中使用GLM-4.6V的强大功能。
(七)模型微调
如果需要对GLM-4.6V进行微调以适应特定任务,可以参考LLaMA-Factory的微调流程。将数据集组织成finetune.json格式,然后按照LLaMA-Factory的标准流程进行微调。例如,以下是一个简单的微调数据格式示例:
[
{
"messages": [
{
"content": "<image>Who are they?",
"role": "user"
},
{
"content": "<think>\nUser asked me to observe the image and find the answer. I know they are Kane and Goretzka from Bayern Munich.<\/think>\n<answer>They're Kane and Goretzka from Bayern Munich.<\/answer>",
"role": "assistant"
}
],
"images": [
"mllm_demo_data/1.jpg"
]
}
]
微调完成后,模型将更好地适应特定的多模态任务。
七、结语
GLM-4.6V作为智谱AI在多模态领域的重要成果,凭借其强大的功能和卓越的性能,为多模态应用开发提供了强大的技术支持。其开源的特性也使得更多的开发者能够参与到相关研究和应用开发中来,共同推动多模态技术的发展。
项目地址
- GitHub仓库:https://github.com/zai-org/GLM-V
- HuggingFace模型库:https://huggingface.co/collections/zai-org/glm-46v
- 技术论文:https://z.ai/blog/glm-4.6v

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 34
34 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)