Evaluation & Observability:让 LLM 与 Agent 系统真正可度量、可观测
拒绝“凭感觉”测试!本文详解 Eval 与 Obs 核心体系,通过链路追踪构建数据飞轮,助你跨越 Demo 到生产环境的鸿沟,实现从“炼丹”到“工程化”的进阶。
一、 引言:告别 “Vibe Check”(凭感觉测试)
在 AI 应用开发的早期阶段,很多工程师都有过类似经历:写好一段 Prompt,随手丢进几个测试问题,看着模型输出了几段“像模像样”的回答,便满意地点头——“嗯,稳了。”
这种基于直觉与主观判断的测试方式,在社区中通常被称为 “Vibe Check”(凭感觉 / 看眼缘测试)。
在 Demo 或 PoC 阶段,它确实高效;但一旦进入工程化与规模化阶段,这种方法往往会成为系统不稳定的根源。
如果我们的目标是构建可交付、可维护、可演进的 AI 应用,就必须从这种“玄学式验证”,转向可量化、可复现的工程实践。
1.1 传统软件测试 vs AI 测试
要理解为什么传统测试方法在 AI 场景中频频失效,首先需要看清两者在底层逻辑上的本质差异。
传统软件:确定性
在传统软件系统中,程序逻辑是高度确定的。
以一个最简单的计算器函数为例:
输入 1 + 1,输出必须是 2。因此我们可以编写严格的单元测试:
assert calculator.add(1, 1) == 2
只要测试通过,我们就可以确信:
无论运行一次、一千次还是一百万次,结果都不会发生变化。
结论很明确:测试即真理。
AI / LLM:概率性
大语言模型本质上是一个概率模型。
即便在以下条件完全一致的情况下:
- 相同的 Prompt
- 相同的上下文
- 相同的参数(甚至
temperature = 0)
模型输出的 Token 序列,仍可能因为以下原因产生细微但真实的漂移:
- 底层浮点计算的非确定性
- 推理引擎或算子优化差异
- 模型版本的静默更新
更棘手的是,对于诸如:
“请把这段话改写得更幽默一点”
这类任务,根本不存在一个客观、严格的 assert 条件。
“正确”不再是布尔值,而是一种模糊、主观、连续的评价。
1.2 “Vibe Check” 的工程陷阱
“Vibe Check” 最大的吸引力在于它的低成本与高反馈速度,但从工程视角看,它至少隐藏着两个致命问题。
1. 覆盖率的幻觉
开发者往往只测试了 2~3 个符合预期的快乐路径(Happy Path),就得出“模型表现不错”的结论。
然而真实世界的用户输入具有以下特征:
- 高噪声
- 高歧义
- 不可预测
- 甚至带有明显的对抗性(Prompt Injection)
当模型第一次遇到这些未被系统性覆盖的输入时,结果往往是:
- 逻辑崩溃
- 输出严重偏离预期
- 产生幻觉(Hallucination)
- 或触发安全与合规风险
2. 迭代的噩梦
这是 Prompt 工程中最常见、也是最痛苦的问题。
当你为了修复 Case A 而调整 Prompt,
你如何确信不会让原本表现良好的 Case B、Case C 变差?
依赖人工回忆和肉眼判断,几乎不可能发现这种性能退化(Regression)。
在缺乏量化指标的情况下,Prompt 优化很容易退化为:
“拆东墙补西墙”的随机试错。
3. 核心痛点
我们真正需要的,并不是“看起来还不错”的主观感受,而是:
可量化、可对比、可复现的数据指标。
1.3 Evaluation 与 Observability 的区别
为了解决上述问题,AI 工程体系中通常引入两套机制。
它们经常被混为一谈,但在生命周期与职责上完全不同。
Evaluation(评测):离线的“考试”
- 使用阶段: Pre-production(开发期 / 上线前)
- 类比: 学生参加期末考试
典型做法:
- 构建一个包含 50~100 个代表性问题的 Golden Dataset
- 让 AI 在固定版本与配置下批量运行
- 通过规则或另一个 LLM 对结果进行自动评分
目标:
- 得到明确的量化指标(如:准确率 85%、一致性 0.92)
- 将评测结果作为 合并代码或发布上线的门禁条件
Observability(可观测性):在线的“体检”
- 使用阶段: In-production(真实运行时)
- 类比: 汽车的仪表盘 / 病人的心率监测
典型做法:
- Trace 每一次请求与 Agent 行为路径
- 监控 Token 消耗(Cost)
- 监控响应延迟(Latency)
- 检测异常输入与攻击行为
目标:
- 实时掌握系统健康状态
- 在错误率、成本或行为异常时第一时间报警
小结
- Evaluation 解决的是:
“这个版本能不能上线?” - Observability 解决的是:
“线上运行是否依然健康?”
二者共同构成了 AI 应用质量保障的完整闭环。
接下来,我们将聚焦第一道防线:Evaluation,深入拆解如何将这种“考试机制”彻底自动化,并真正融入工程流水线。
二、 Evaluation:给 Agent 判卷子
既然不能再依赖“感觉”,那就必须引入一套正规的评测机制。但问题来了:如果有 1000 个测试题,谁来打分?既然是主观题,标准是什么?
2.1 谁来阅卷?(LLM-as-a-Judge)
在传统的机器学习中,评测路径非常明确:基于标准答案(Label),通过计算准确率(Accuracy)、精确率(Precision)、召回率(Recall) 或 F1 值(F1-score)即可直接评估模型预测效果。
但在生成式 AI 中,答案往往是开放的。
-
人工评测的瓶颈: 雇人看 Log 既慢又贵,而且人是不稳定的(累了标准就会变)。
-
核心理念:LLM-as-a-Judge
这是目前行业内的主流解法。我们雇佣一个“更聪明、更昂贵”的模型(比如 GPT-4o 或 Claude 3.5 Sonnet)作为考官,去评估“较小、较快”的模型(比如 Llama-3-8b 或你的微调模型)生成的答案。流程如下:
- 输入构造: 把问题、你模型的回答、以及参考答案(如果有)打包。
- Prompt: 写一段专门的“打分提示词”(Rubric),例如:“你是一个公正的判官,请评估以下回答的准确性,分值 1-5 分,并给出理由。”
- 结果输出: 得到结构化的评分和反馈。
这不仅解决了扩展性问题,还能让评估过程自动化,嵌入到 CI/CD 流水线中。
2.2 RAG 的评测指标 (RAG Triad)
(承接上一篇博文关于 Memory/知识库的内容)
对于检索增强生成(RAG)系统,单纯看最终回答好不好是不够的。如果回答错了,是“检索模块”没捞到数据,还是“生成模块”理解错了?
我们需要引入 RAG Triad (RAG 三元组) 来进行诊断:
-
Context Precision (上下文精准度) —— “含金量”
- 问题: 检索回来的 5 个文档片段(Chunks),有几个是真正跟问题相关的?
- 场景: 用户问“公司哪年上市?”,RAG 检索了 5 条关于“公司食堂菜谱”的信息。
- 后果: 噪音太大,浪费了 LLM 的推理窗口,甚至误导模型。
- 目标: 检索结果应全是干货。
-
Context Recall (上下文召回率) —— “漏没漏”
- 问题: 正确答案明明在向量数据库里,检索系统把它捞出来了吗?
- 场景: 数据库里有“2023年上市”的文档,但因为切片(Chunking)切坏了,或者关键词匹配失败,导致没检索到。
- 后果: 模型因为没有上下文,被迫回答“我不知道”。
- 目标: 只要数据库里有,就必须能搜到。
-
Faithfulness (忠实度/抗幻觉) —— “瞎编率”
- 问题: 给定了正确的上下文,AI 的回答是严格基于这些上下文生成的吗?
- 场景: 上下文明明写着“产品价格 100元”,AI 却利用自己训练时的过时记忆回答“99元”,或者完全瞎编。
- 后果: 这是企业应用中最危险的幻觉 (Hallucination)。
- 目标: 回答必须有据可依,不能脱离 Context 自由发挥。
2.3 Agent 的端到端评测
如果说 RAG 是“开卷考试”,那么 Agent 就是“实验操作考”。Agent 不仅要回答问题,还要做事(调用工具)。评估难度更上一层楼。
-
工具调用准确率 (Tool Selection Accuracy)
- 意图识别: 用户说“帮我算一下这笔账”,Agent 是调用了 Calculator 工具,还是调用了 Weather 工具?
- 参数正确性: 调用计算器时,参数格式对吗?是不是把字符串传给了整型字段?
- 这是 Agent 评估中最基础的一环,通常也是最容易出错的一环。
-
任务成功率 (Success Rate)
- 这是端到端的终极指标。
- 不管中间经过了多少次思考(Chain of Thought)和工具调用,最终用户的目标达成了吗?
- 评测方法: 这通常需要设定一个“验证函数”。例如,如果是“帮我发邮件”,评测脚本可以检查发件箱里是否真的多了一封邮件。如果是“写代码”,则检查代码能否通过 Unit Test。
通过这三个维度的评估,我们就在应用上线前建立了一个数字化的质量防线。只有通过了这些“考试”,Agent 才有资格进入生产环境,接受真实世界的挑战。接下来,我们看看上线后该怎么办。
三、 Observability:透视 Agent 的“黑盒”
应用上线后,挑战才真正开始。用户投诉“回答太慢”或者“答非所问”,作为工程师,你该如何排查?在 AI 时代,传统的调试手段已经捉襟见肘。
3.1 为什么 Print 调试法失效了?
在写简单脚本时,我们习惯在代码里插一句 print(response) 来调试。但在 Agent 系统中,这种做法已经彻底失效:
- 复杂度的爆炸: 一个现代的 AI Agent 不是一次简单的函数调用。它是一个链 (Chain) 甚至是一个图 (Graph)。一个用户的 Prompt 可能会触发:
- Router 决定调用哪个工具;
- 3 次向量数据库的检索;
- 2 次为了修正格式的自我反思 (Self-Correction);
- 最终的 LLM 生成。
- 上下文的丢失: 仅仅打印最终结果,你无法知道中间发生了什么。比如模型算错了数学题,是因为它逻辑推理错了?还是因为它调用计算器工具时参数传错了?
print无法告诉你这些中间状态。
结论: 面对非确定性的、多步骤的 AI 交互,我们需要从“打 Log”进化到“链路追踪”。
3.2 核心技术:Tracing (链路追踪)
Tracing 就像是给你的 Agent 拍了一张 X 光片。它记录了一个请求从进入系统到离开系统的全生命周期。
-
可视化执行流 (The Waterfall):
最好的 Observability 工具(如 LangSmith, Langfuse)能以树状图或瀑布流的形式展示执行过程。看看下面这个 Trace,问题出在哪一目了然:[Root] User Request: "帮我查下这周去上海的机票" (Total: 12.5s) ⚠️ ├── [Span] Intent Classifier (0.2s) -> "Travel_Booking" ├── [Span] Tool: Flight_Search (10.2s) -> ❌ [API Slow / High Latency] │ └── Input: { "dest": "shanghai", "date": "this week" } │ └── Output: [JSON Data...] └── [Span] LLM: Summarization (2.1s) -> "这周去上海的机票如下..." -
场景演示:性能瓶颈定位
- 现象: 用户投诉应用经常卡顿,等待时间超过 10 秒,体验极差。
- 直觉(Vibe Check): 开发者的第一反应通常是:“肯定是模型推理太慢了,要不要把 GPT-4 换成 GPT-3.5 ?”
- Trace 真相: 打开上面的 Trace 一看,LLM 生成其实只花了 2.1 秒。真正的大头是 Flight Search API 的网络请求,竟然卡了 10.2 秒。
- 决策: 此时换模型毫无意义(甚至会降低质量)。基于数据,正确的优化方向应该是:优化搜索接口、增加超时重试机制,或者在搜索时给用户展示一个 Loading 动画。
结论: 没有 Trace,优化就是瞎忙。
3.3 成本与延迟监控 (Metrics)
除了微观的单次请求追踪,我们还需要宏观的仪表盘 (Dashboard) 来监控系统的健康度。
-
Token 消耗统计 (钱花哪了?)
- LLM 是按 Token 计费的。你需要知道:
- Cost per User: 哪个用户在疯狂刷你的 API?
- Input vs Output: 是提示词太长(RAG 检索了太多无用文档),还是生成的废话太多?
- ROI 分析: 那个昂贵的 GPT-4o 调用是否真的比 GPT-3.5 带来了更好的转化率?
-
Latency 分布 (P99 延迟)
- 平均值是骗人的: 平均延迟 2 秒看起来不错,但如果 P99 (99% 分位) 是 20 秒,意味着每 100 个用户里就有 1 个用户因为等待太久而流失。
- Time to First Token (TTFT): 对于流式输出 (Streaming) 的应用,用户不关心完全生成要多久,只关心“第一几个字什么时候蹦出来”。监控 TTFT 比监控总耗时更能反映用户体验。
拥有了 Observability,我们就再也不用对着用户的报错截图瞎猜了。我们可以直接调出那个 Request ID 的 Trace,像侦探一样复原案发现场。
下一章,我们将揭示这套体系最迷人的地方:Feedback Loop (数据飞轮)。如何把观测到的数据,变回评估用的考题?
四、 数据飞轮:Eval 与 Obs 的闭环
单独看 Evaluation,它只是一个静态的门槛;单独看 Observability,它只是一个报警器。但当你把它们首尾相连时,奇迹发生了:你构建了一个自我进化的数据飞轮 (Data Flywheel)。
4.1 Bad Case 挖掘:生产环境是最好的测试场
无论你的离线测试集设计得多么完美,真实世界的用户总能找到让你模型崩溃的刁钻角度。生产环境不仅是服务的场所,更是高价值数据的金矿。
- 显性反馈 (Explicit Feedback):
最直接的信号来自用户。在 Chatbot 界面加一个简单的 👍 / 👎 按钮。- 当用户点击“踩”(Thumbs down)时,这条 Trace 就应该被自动标记为 High Priority Bad Case。
- 隐性反馈 (Implicit Feedback):
用户没点按钮,但行为出卖了他们的不满:- 改写重试: 用户问了一次,模型答非所问,用户不得不修改措辞又问了一遍。
- 提前终止: 模型还在流式输出,用户直接点击了 Stop。
- 护栏日志分析 (Guardrails & Security):
- 误杀分析: 监控被安全护栏拦截的请求,确认是否有正常用户因为触发关键词(如咨询“杀进程”)而被误判。
- 攻击样本库: 将用户真实的注入攻击(Prompt Injection)存入安全测试集,用于后续的红队测试(Red Teaming)。
4.2 反哺测试集:把“事故”变成“故事”
挖掘出 Bad Case 后,千万不要只是在后台看看就算了。你需要把它们固化下来。
- 从 Edge Case 到 Test Case:
假设在线上观测发现,用户问“2024年奥运会”时,RAG 检索错误导致了幻觉。- 抽取: 将这个具体的 Prompt 和错误的回答提取出来。
- 修正: 人工(或利用更强的模型)编写一个正确的参考答案(Ground Truth)。
- 入库: 将这对
(Input, Expected Output)永久加入你的 Golden Dataset(金标准数据集)。
- 防御性编程:
这一步的意义在于防止回滚 (Regression Prevention)。下次你再发版时,这个曾经导致线上一级事故的 Case,就变成了 Evaluation 跑分中的必考题。只要这个测试集在,同样的错误就永远不会犯第二次。
4.3 持续迭代 (CI/CD for AI)
有了不断生长的测试集,我们终于可以像开发传统软件一样,建立 AI 时代的 CI/CD 流水线。
- 流程演示:
- Dev: 开发者为了优化语气,修改了 System Prompt。
- Commit: 代码提交,触发 CI 流水线。
- Auto-Eval: 系统自动拉取最新的 Golden Dataset(包含昨天刚收录的 Bad Cases),运行 500 个测试用例。
- Result:
- ✅ Pass: 准确率从 85% 提升到 86%。
- ❌ Fail: 新的 Prompt 虽然语气好了,但在 3 个数学推理题上出错了(Score 下降)。
- Decision: 如果分数下降,CI 直接拦截,禁止上线。
总结: 在这个闭环中,Evaluation 变成了 Observability 的“演习”,而 Observability 变成了 Evaluation 的“真题来源”。 你的模型不是在发布的那一刻最完美,而是在发布后,随着用户的每一次“找茬”,变得越来越强。
这样一来,整篇文章的逻辑链条就彻底打通了:
拒绝盲猜 -> 建立离线标准 -> 建立在线监控 -> 利用监控完善标准 -> 持续迭代。
五、 实战工具箱 (Tech Stack)
纸上谈兵终觉浅。要落实 Evaluation 和 Observability,你不需要从零手写一套系统。目前的开源社区和 SaaS 领域已经涌现出了一批非常成熟的工具,能帮你快速搭建起这套基础设施。
5.1 评测框架 (Evaluation Frameworks)
这一层的核心任务是“打分”。你需要一个工具来帮你运行测试集,并计算出具体的指标。
-
RAGAS (RAG Assessment):
- 定位: 它是目前 RAG 系统评测的行业标准。
- 核心卖点: 上文中提到的 RAG Triad(Context Precision, Recall, Faithfulness),Ragas 都提供了现成的实现。它底层利用 LLM-as-a-Judge 的思想,能自动生成测试数据,也能自动打分。
- 适用场景: 如果你在做基于知识库的问答机器人(Knowledge Bot),闭眼选它。
-
DeepEval:
- 定位: “The Pytest for LLMs”。
- 核心卖点: 它的开发者体验(DX)极佳。如果你熟悉 Python 的
unittest或pytest,你会对 DeepEval 感到非常亲切。它允许你像写传统单元测试一样写 LLM 测试:def test_hallucination(): assert_test(test_case, [hallucination_metric]) - 适用场景: 适合硬核开发者,想要把 LLM 测试无缝集成到 GitHub Actions / CI 流水线中。
5.2 观测平台 (LLMOps)
这一层的核心任务是“看见”。你需要一个 Dashboard 来承载 Tracing 和 Metrics。
-
LangSmith (LangChain 官方):
- 核心卖点: 最丝滑的 Trace 体验。作为 LangChain 的亲儿子,它对 Python/JS 生态的支持是原生级的。
- 杀手级功能: Playground 集成。你在 Trace 里看到某一步 LLM 回答错了,点击按钮可以直接跳转到 Playground,修改 Prompt 重新运行,直到满意为止。这种“Debug -> Fix”的闭环体验是独一无二的。
- 适用场景: 快速原型开发,或者重度使用 LangChain 的团队。
-
Langfuse (开源推荐):
- 核心卖点: 开源 (Open Source) & 可私有化部署 (Self-Hosted)。
- 杀手级功能: 对于对数据隐私极其敏感的企业(比如金融、医疗),不能把 Log 传给第三方 SaaS。Langfuse 允许你自己部署 docker 容器,数据完全握在自己手里。同时它的 Cost 成本分析做得非常细致。
- 适用场景: 企业级生产环境,或对数据合规有严格要求的项目。
-
Arize Phoenix:
- 核心卖点: 数据可视化的专家。
- 杀手级功能: Embedding 可视化。当你的 RAG 检索效果不好时,Phoenix 可以把你的向量数据投影到 3D 空间中(UMAP 降维)。你可以直观地看到:为什么这块文档明明相关,却在向量空间里离问题那么远?
- 适用场景: 需要深度排查检索问题(Retrieval Debugging)的数据科学家。
有了这些工具,你就不再是赤手空拳地对抗 AI 的黑盒了。
六、 实战演练:打造你的 AI 监控与评测实验室
纸上得来终觉浅。在这一章,我们将抛开理论,在你的本地机器上搭建一套完整的 LLMOps 实验室。
我们将完成三个目标:
- 环境搭建: 避开 Python 版本的坑,构建干净的 AI 开发环境。
- 全链路观测 (Observability): 运行一个 Agent,并实时看到它的“脑回路”。
- 自动化评测 (Evaluation): 编写测试代码,自动判断 Agent 记性好不好。
6.1 环境准备:避坑指南 (Mac/Linux)
AI 领域的工具链(如 PyTorch, Arize Phoenix)更新往往滞后于 Python 官方版本。目前 Python 3.10 或 3.11 是最稳定的“黄金版本”。如果你使用的是系统自带的 Python 3.12+ 或 3.13,安装过程大概率会报错。
因此,我们要使用 Miniconda 来隔离环境。请严格按照以下步骤操作:
第一步:安装 Miniconda (如果已有可跳过)
打开终端,执行以下命令安装 Conda 管理器:
# 1. 下载并安装 Miniconda (针对 Apple Silicon M1/M2/M3)
mkdir -p ~/miniconda3
curl https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.sh -o ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
# 2. 初始化 Shell (安装完需重启终端或执行 source ~/.zshrc)
~/miniconda3/bin/conda init zsh
第二步:解决服务条款问题 (关键!)
由于 Anaconda 最近更新了服务条款,创建环境前必须手动接受,否则会报错。
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/main
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/r
第三步:创建并激活 Python 3.11 环境
# 1. 创建名为 ai_env 的环境,指定版本 3.11
conda create -n ai_env python=3.11 -y
# 2. 激活环境
conda activate ai_env
# 3. 验证版本 (必须显示 3.11.x)
python --version
第四步:安装实战工具包
一次性安装本章所需的全部依赖:
arize-phoenix: 观测平台deepeval: 评测框架langgraph&langchain: Agent 编排opentelemetry: 数据传输标准
pip install arize-phoenix openinference-instrumentation-langchain opentelemetry-sdk opentelemetry-exporter-otlp langchain-openai langgraph deepeval
6.2 实战一:Observability (给 Agent 拍 X 光片)
我们将运行一个基于 LangGraph + DeepSeek 的对话机器人,并使用 Arize Phoenix 在网页端实时查看它的执行链路(Tracing)。
新建文件 obs_agent.py,粘贴以下代码:
import os
import operator
import phoenix as px
from typing import Annotated, TypedDict, List
# --- 观测依赖 ---
from openinference.instrumentation.langchain import LangChainInstrumentor
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
# --- Agent 依赖 ---
from langchain_openai import ChatOpenAI
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
# ================= 1. 启动观测台 (核心配置) =================
# 启动本地 Phoenix 服务
session = px.launch_app()
# 配置数据发送器
# 注意:使用 SimpleSpanProcessor 强制实时发送数据,避免数据卡在缓冲区
endpoint = "http://127.0.0.1:6006/v1/traces"
tracer_provider = TracerProvider()
tracer_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter(endpoint=endpoint)))
trace.set_tracer_provider(tracer_provider)
# 开启自动埋点 (Hook)
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
print(f"🚀 观测台已启动!请在浏览器访问: {session.url}")
print("-" * 6.)
# ================= 2. 定义 Agent =================
# 请替换为你的 DeepSeek Key
llm = ChatOpenAI(
api_key="sk-xxxxxx",
base_url="https://api.siliconflow.cn/v1",
model="deepseek-ai/DeepSeek-V3",
temperature=0
)
class State(TypedDict):
messages: Annotated[List[BaseMessage], operator.add]
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
builder = StateGraph(State)
builder.add_node("chatbot", chatbot)
builder.add_edge(START, "chatbot")
builder.add_edge("chatbot", END)
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)
# ================= 3. 运行对话 =================
if __name__ == "__main__":
print("🤖 Agent 已就绪...")
config = {"configurable": {"thread_id": "session_1"}}
# 第一轮
print("\n[Round 1] User: 我叫 Alex,是个 Python 程序员。")
input_1 = {"messages": [HumanMessage(content="我叫 Alex,是个 Python 程序员。")]}
for event in graph.stream(input_1, config=config, stream_mode="values"):
if isinstance(event["messages"][-1], AIMessage):
print(f"🤖 AI: {event['messages'][-1].content}")
# 第二轮
print("\n[Round 2] User: 我刚才说我职业是什么?")
input_2 = {"messages": [HumanMessage(content="我刚才说我职业是什么?")]}
for event in graph.stream(input_2, config=config, stream_mode="values"):
if isinstance(event["messages"][-1], AIMessage):
print(f"🤖 AI: {event['messages'][-1].content}")
print("-" * 6.)
print("👀 请不要关闭窗口!切换到浏览器 http://localhost:6006 查看 Traces。")
input("🛑 查看完毕后,按回车键退出程序...")
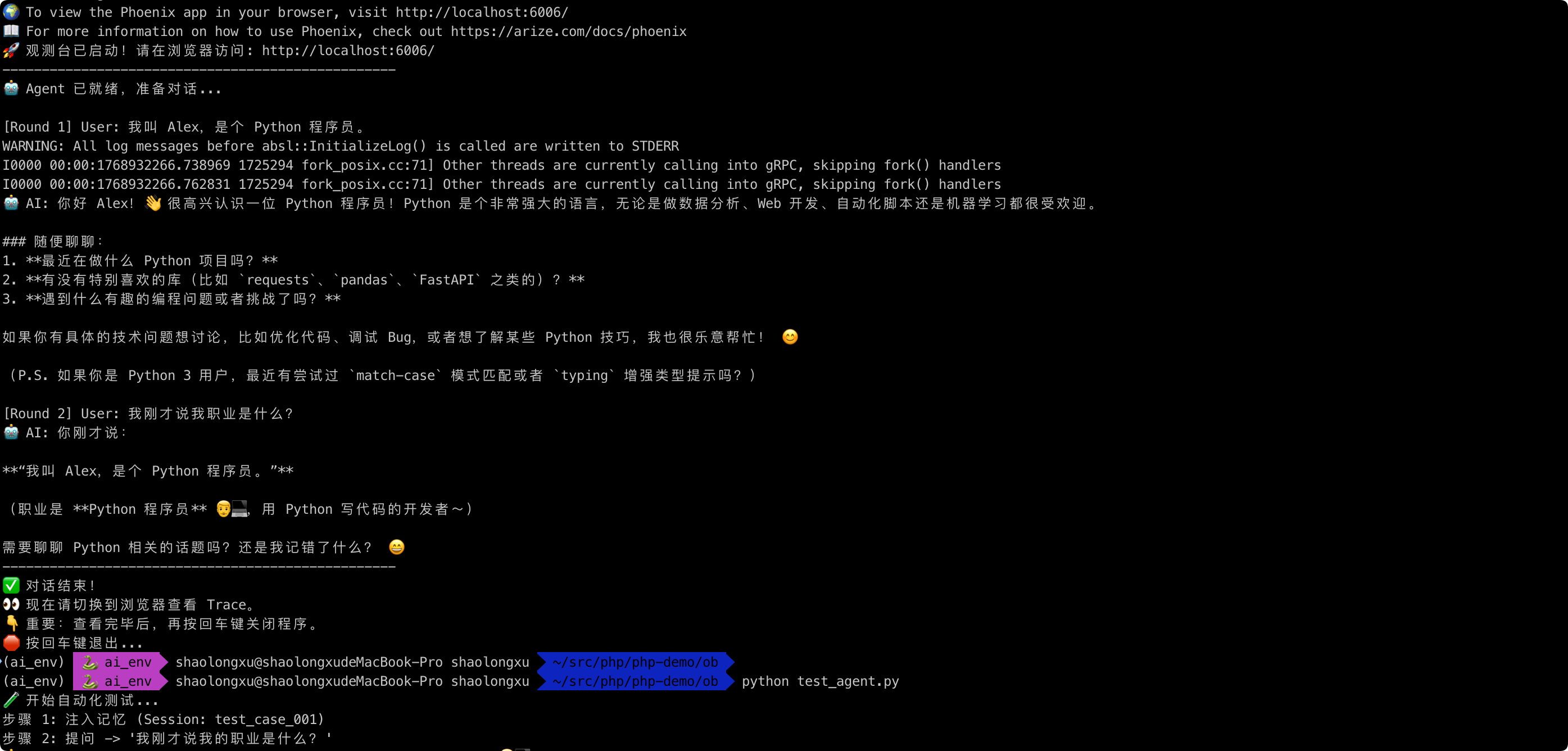
如何验证?
- 运行
python obs_agent.py。 - 等待终端完成两轮对话。
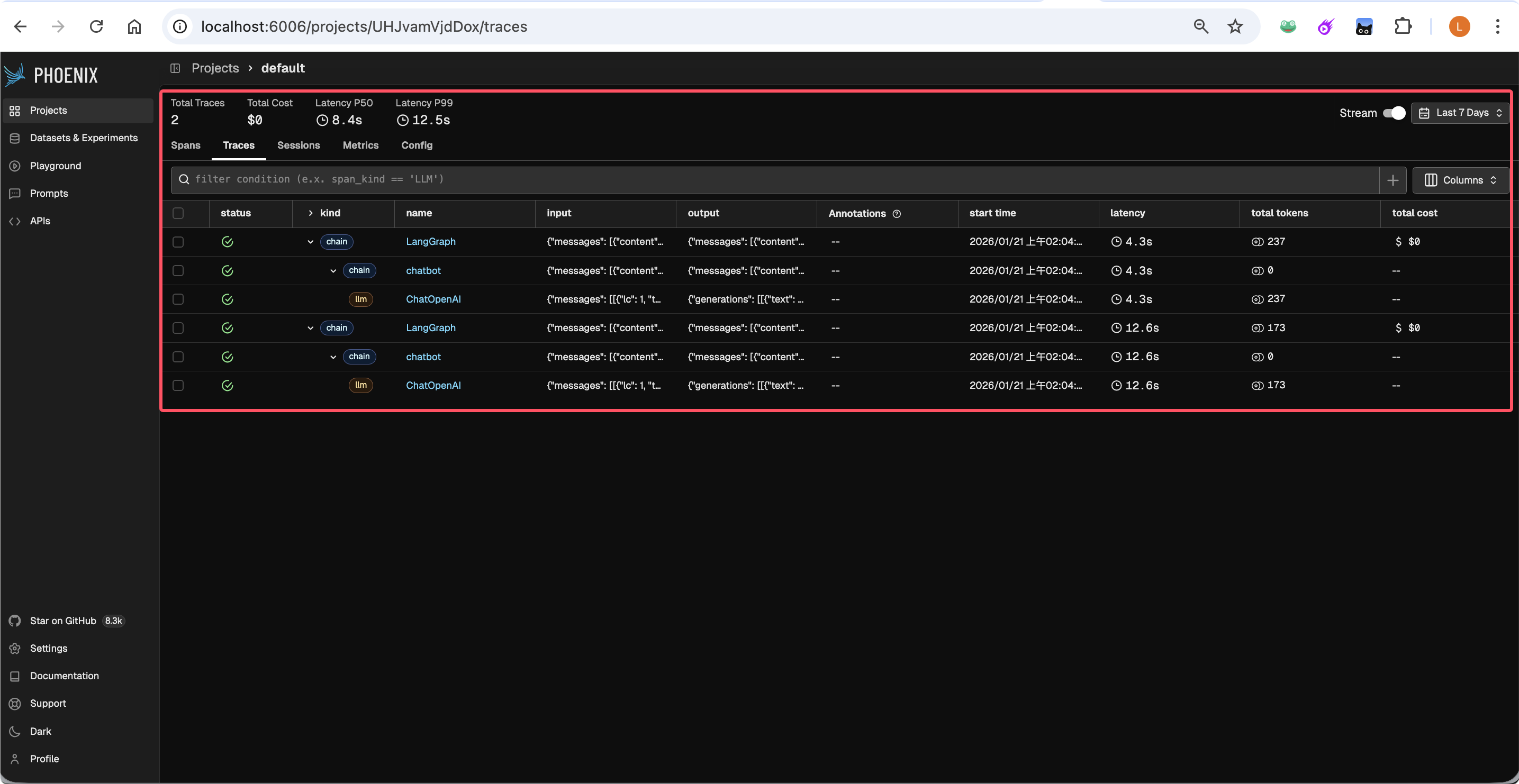
- 打开浏览器访问
http://localhost:6006,点击 Projects -> default -> Traces。 - 你将看到清晰的 Waterfall (瀑布图),展示了 Agent 从接收输入、查询内存到调用 DeepSeek 的完整耗时和参数。
6.3 实战二:Evaluation (自动化评测记忆力)
能够观测还不够,我们需要自动化的手段来衡量 Agent 的质量。接下来,我们使用 DeepEval 编写一个自动化测试用例,考察 Agent 是否真的记住了上下文。
亮点: 为了降低成本并复用环境,我们将配置 DeepEval 使用 DeepSeek 作为“考官”(Judge),而不是默认的 OpenAI。
新建文件 test_eval.py,粘贴以下代码:
import pytest
from deepeval import evaluate
from deepeval.metrics import GEval, LLMTestCaseParams
from deepeval.test_case import LLMTestCase
from deepeval.models.base_model import DeepEvalBaseLLM
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
from typing import Annotated, TypedDict, List
import operator
# 配置 Key
API_KEY = "sk-xxxxxx"
BASE_URL = "https://api.siliconflow.cn/v1"
MODEL_NAME = "deepseek-ai/DeepSeek-V3"
# ================= 1. 定义被测对象 (The Agent) =================
# (这里复用了上面的 Agent 逻辑,封装为函数以便测试调用)
llm = ChatOpenAI(api_key=API_KEY, base_url=BASE_URL, model=MODEL_NAME, temperature=0)
class State(TypedDict):
messages: Annotated[List[dict], operator.add]
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
builder = StateGraph(State)
builder.add_node("chatbot", chatbot)
builder.add_edge(START, "chatbot")
builder.add_edge("chatbot", END)
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)
def call_agent(user_input: str, thread_id: str) -> str:
config = {"configurable": {"thread_id": thread_id}}
response = ""
for event in graph.stream({"messages": [HumanMessage(content=user_input)]}, config=config, stream_mode="values"):
if isinstance(event["messages"][-1], AIMessage):
response = event["messages"][-1].content
return response
# ================= 2. 定义自定义考官 (The Judge) =================
# 让 DeepEval 调用 DeepSeek 来打分
class DeepSeekJudge(DeepEvalBaseLLM):
def __init__(self):
self.model = ChatOpenAI(api_key=API_KEY, base_url=BASE_URL, model=MODEL_NAME, temperature=0)
def load_model(self): return self.model
def generate(self, prompt: str) -> str: return self.model.invoke(prompt).content
async def a_generate(self, prompt: str) -> str: res = await self.model.ainvoke(prompt); return res.content
def get_model_name(self): return "DeepSeek-V3"
# ================= 3. 执行测试用例 =================
if __name__ == "__main__":
print("🧪 开始自动化测试...")
session_id = "test_memory_001"
# Step 1: 注入记忆 (告诉它我是谁)
print("步骤 1: 注入信息...")
call_agent("我叫 Alex,是个 Python 程序员。", session_id)
# Step 2: 考试 (问它我是谁)
question = "我刚才说我的职业是什么?"
print(f"步骤 2: 提问 -> {question}")
actual_output = call_agent(question, session_id)
print(f"🤖 Agent 回答: {actual_output}")
# Step 3: 定义评分标准
# 我们使用 GEval (GPT-Eval) 指标,用自然语言描述评分规则
memory_metric = GEval(
name="Memory Accuracy",
criteria="判断 AI 是否准确复述了用户的职业(Python 程序员)。",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
model=DeepSeekJudge(), # 指定 DeepSeek 为裁判
threshold=0.7
)
# Step 4: 运行打分
print("\n⚖️ 裁判正在打分...")
test_case = LLMTestCase(input=question, actual_output=actual_output)
memory_metric.measure(test_case)
# Step 6. 输出报告
print("-" * 6.)
print(f"✅ 测试结果: {'通过' if memory_metric.is_successful() else '失败'}")
print(f"📊 分数: {memory_metric.score}")
print(f"💡 理由: {memory_metric.reason}")
print("-" * 6.)
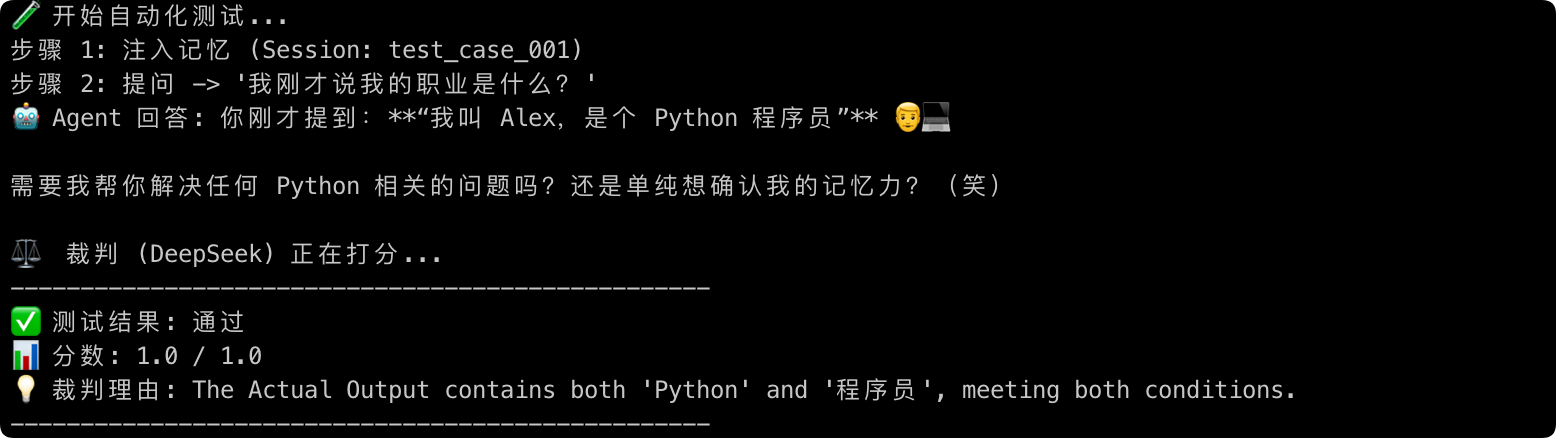
如何验证?
- 运行
python test_eval.py。 - 观察终端输出。你会看到 DeepSeek 扮演的“裁判”会自动分析 Agent 的回答,并给出理由(例如:“回答包含了 ‘Python’ 和 ‘程序员’,符合事实,给予满分”)。
6.4 小结
通过这一章的实战,我们成功在本地搭建了一套闭环系统:
- 用 Phoenix 看清了 Agent 内部的每一步流转。
- 用 DeepEval 实现了“用 AI 测试 AI”的自动化流程。
这不仅是代码的胜利,更是从“手工作坊”迈向“现代 AI 工程化”的第一步。
七、 总结:从“炼丹”到“建筑”
文章的最后,让我们回到最初的问题:为什么我们需要 Evaluation 和 Observability?
7.1 如果你不能度量它,你就不能优化它
管理学大师彼得·德鲁克曾说过一句名言:“You can’t improve what you don’t measure.”(无法衡量的东西,就无法改进。)
这句话在 AI 时代被赋予了新的重量。
- 如果你不知道模型的准确率是 80% 还是 90%,那么你所做的每一次 Prompt 优化,都只是在黑暗中扔飞镖。
- 如果你看不见线上的 Latency 和 Cost 消耗,那么你的应用不仅是一个黑盒,更是一颗随时可能引爆的财务炸弹。
拒绝 “Vibe Check”,本质上是拒绝盲目。通过建立 Evaluation (离线评分) 和 Observability (在线观测) 的双重防线,我们终于把玄学的 AI 开发,拉回了数据驱动 (Data-Driven) 的坚实地面。
7.2 升华:从“炼丹师”进阶为“AI 架构师”
在行业里,我们经常戏称自己是“Prompt Engineer”或者“炼丹师”。
- 炼丹师的做法是:调一下 Temperature,改两个词,祈祷模型能吐出好的结果。这是一种靠运气的艺术。
- AI 架构师的做法是:搭建测试流水线,追踪链路数据,构建自动化的反馈闭环。这是一种靠体系的工程。
当你开始不再纠结于某一个具体的 Prompt 词措辞,而是开始关注“如何构建一个自动发现 Bad Case 并自动修复的系统”时,你就完成了从炼丹师到架构师的蜕变。
AI 的浪潮还在继续,但只有那些掌握了“度量”能力的人,才能造出真正经得起风浪的船。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)