ReAct 与 Chain-of-Thought(CoT):大模型推理与智能体框架详解
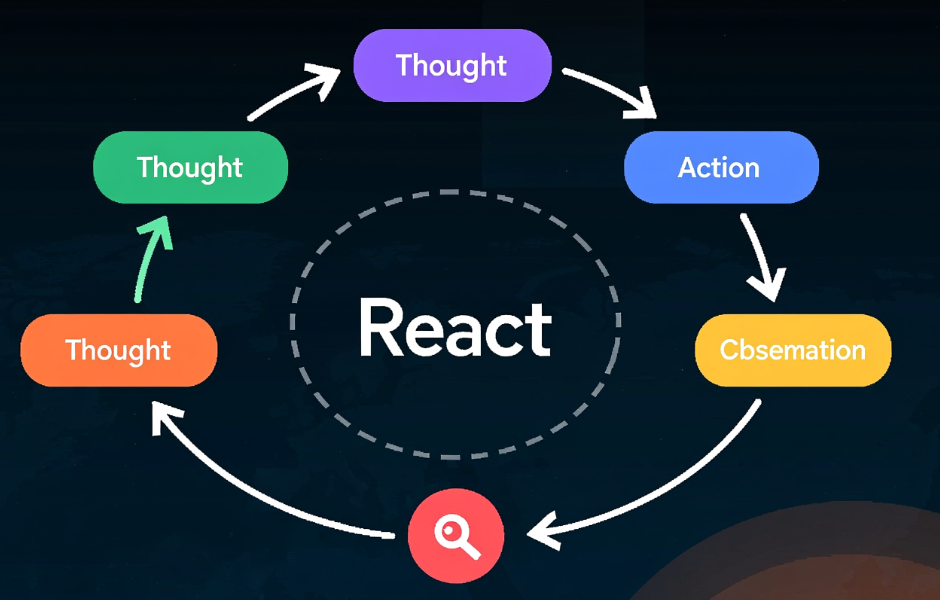
React 是 Google 与 Princeton 团队在 2022 年提出的一种基于提示的智能体(Agent)框架。它通过交替进行和的循环,让大模型在解决复杂问题时能够进行外部工具调用(如搜索、各种 API),并基于工具反馈更新推理状态,从而实现多步、可交互的问题求解。让大模型在解决问题时,显式交替输出 Thought,形成一个的推理-执行循环。期间涉及对外部环境的感知(通过工具调用获取真实世
React 是 Google 与 Princeton 团队在 2022 年提出的一种基于提示的智能体(Agent)框架。它通过交替进行思考(Thought)、行动(Action) 和 观察(Observation) 的循环,让大模型在解决复杂问题时能够进行外部工具调用(如搜索、各种 API),并基于工具反馈更新推理状态,从而实现多步、可交互的问题求解。
让大模型在解决问题时,显式交替输出 Thought,形成一个可观察、可干预、可调式的推理-执行循环。期间涉及对外部环境的感知(通过工具调用获取真实世界信息)以及对问题状态的持续更新。
ReAct 的关键突破是打破纯语言推理的封闭性,通过 Observation 引入外部真实数据(如 API 返回、搜索结果),而不仅是“感知原先内容”。
Chain-of-Thought(CoT)
Chain-of-Thought(COT)是 2022 年由 Google 论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中首次提出,通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能,是一种促使大模型显式输出中间推理步骤的技术。
- 最简单的实现是在提示词中加入
"Let's think step by step."(零样本 CoT); - 更有效的方式是提供包含推理过程的示例(少样本 CoT)。
模型内部可能一直在“思考”,但 CoT 的价值在于把思考过程写出来,这对复杂任务的准确性提升至关重要。
CoT 的局限性
- 效果显著依赖模型规模:研究发现小模型(<20B)导致无法理解最基本的知识,难以生成连贯、正确的推理链。
- 如果希望模型在各类任务上稳定展现思维链能力,通常需要在监督微调(SFT)阶段引入大量思维链数据,使模型增加分布推理的能力(Prompting + SFT)。
ReAct 与 CoT 的关系
ReAct 本质上是 CoT 的结构化扩展,它将 CoT 的思维链与外部工具相结合,形成一个 “感知–决策–执行” 的闭环,从而突破纯语言模型的知识与实时性限制。在 ReAct 中,Thought 就是 CoT 的具体体现。
示例对比
Zero-shot CoT:
在 prompt 中加一句:
Let's think step by step.
Few-shot CoT:
在 prompt 中提供带推理步骤的示例:
Q: 小明有 5 个苹果,吃了 2 个,又买了 3 个,现在有几个?
A: 我们一步步来想:1. 初始有 5 个;2. 吃了 2 个,剩 3 个;3. 又买 3 个,共 6 个。答案是 6。
现代 Agent 框架的发展
补充:现代 Agent 框架已超越原始 ReAct
- Plan-and-Execute:先整体规划,再分步执行(减少试错)
- Reflexion:失败后自我反思并重试
- Toolformer / Gorilla:通过微调让模型原生支持工具调用
但 ReAct 仍是这些高级框架的基础构件。
进阶挑战与解决方案
| 问题 | 解决方案 |
|---|---|
| 格式不遵守,模型可能乱写 Action,导致解析失败 | 使用 JSON mode / 强约束 decoding |
| 无限循环,模型反复调用工具不终止 | 设置最大步数 + 终止判断 |
| 工具误用,如用 calculator 处理非数学问题 | 在 Prompt 中明确工具用途 |
| 无规划能力,对复杂任务可能路径错误 | 结合 Plan-and-Execute 框架 |
ReAct + Self-Reflection:在失败后让模型反思 “为什么没成功?下一步该怎么做?”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)