Linux 文件与目录 & 数据提取
系列文章目录第一章 Linux基础第二章 linux系统信息第三章 Linux 文件目录文章目录系列文章目录前言一、文件与目录1、CD 切换工作目录2、PWD打印当前工作目录3、MKDIR创建目录4、RMDIR删除目录二、文件与目录管理1、CP拷贝2、RM删除3、MV移动4、dirname和basename的用法三、文件内容的查阅1、CAT正向连续读2、TAC反向连续读3、NL输出行号显示文件4、
系列文章目录
第一章 Linux基础
第二章 linux系统信息
前言
一、文件与目录

1、CD 切换工作目录
- cd 路径 ·#直接切换到某路径下
- cd … #切换到上层目录
- cd . #切换到当前目录
- cd #切换到当前用户家目录
- cd ~ #切换到当前用户家目录
- cd - #切换到上次的工作目录
2、PWD打印当前工作目录
grammar:pwd [option]
options:
-L:显示逻辑工作目录
-P:显示物理工作目录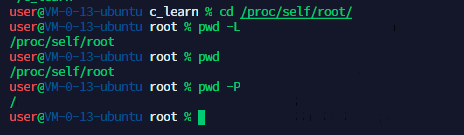
3、MKDIR创建目录
grammar:mkdir [pm]
-p:自动创建父目录
-m:设置权限

4、RMDIR删除目录
grammar:rmdir [p]
-p:删除祖先
1.为什么在linux操作系统中,自己写的程序在编译后,要使用./a.out来执行,直接使用a.out不可以么?这里的./是什么意思?
path 里有a.out 就直接运行,如果没有,就直接 ./a.out 来临时设置一个path 来运行
PATh=$PATH:/home/ {a.out path}
2.PATH=“$PATH”:/home/meng/ctest 的含义是什么
二、文件与目录管理

1、CP拷贝
grammar:cp [option]…
options:
-i:若文件存在,询问用户
-r:递归复制 复制文件夹
-a:pdr的集合
-p:连同文件属性一起拷贝 用户 权限 时间的信息
-d:若源文件为连接文件的属性,则复制连接文件的属性
-s:拷贝为软连接
-l:拷贝为硬连接
-u:源文件比目的文件新才拷贝
尝试:cp file1 file2 … dir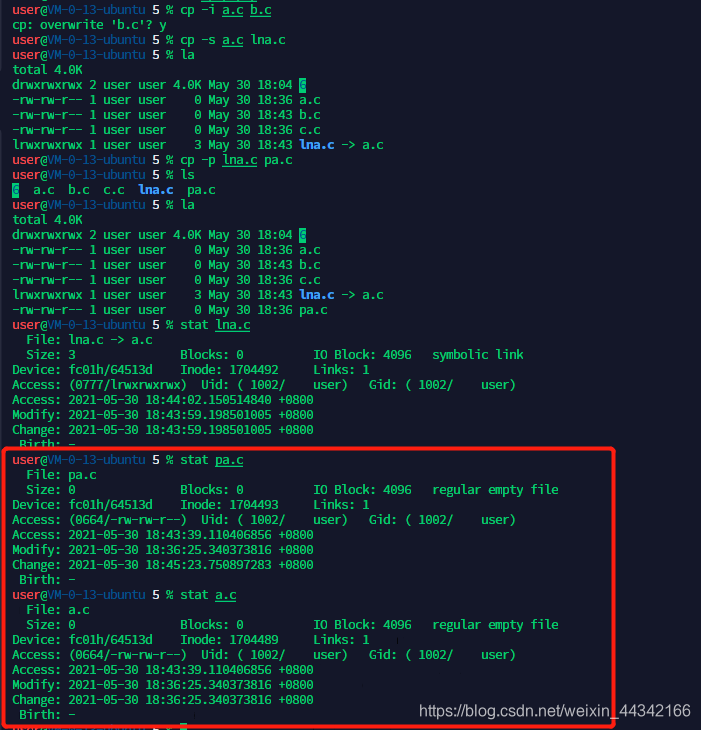
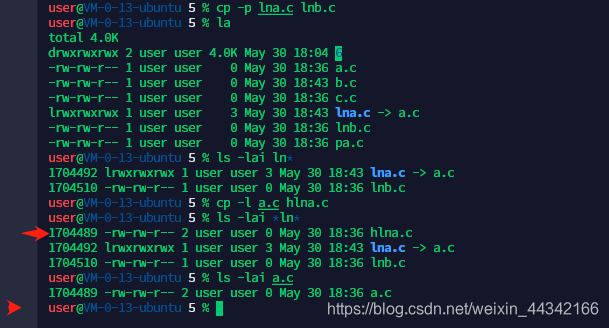
ls -lai 文件 #查看文件的 inote
软链接是两个独立的文件,硬链接指向的是同一个文件,只是名字不一样
软链接如果不是绝对路径,当移出到创建时的目录时,就会跟其他同名的文件链接上
软链接相当于快捷方式
2、RM删除
grammar:rm [option]… <dir_or_file>
options:
-i:互动模式
-r:递归删除
-f:force
3、MV移动
grammar:mv <source…>
mv source1 source2 source3 dir
options:
-i:互动模式
-f:force
-u:源文件更新才会移动
4、dirname和basename的用法
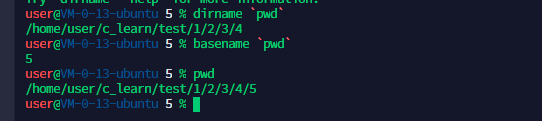
shell 脚本中经常用
三、文件内容的查阅
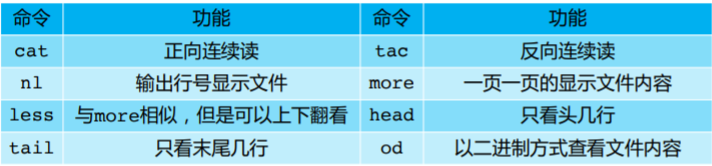
1、CAT正向连续读
grammar:cat [options]
options:
-A:相当于-vET
-v:列出看不出的字符
-E:显示断行符为$
-T:显示TAB为^I
-b:列出行号
-n:列出行号,连同空行也编号
2、TAC反向连续读
CAT->TAC
读取方向刚好与cat相反,从最后一行开始打印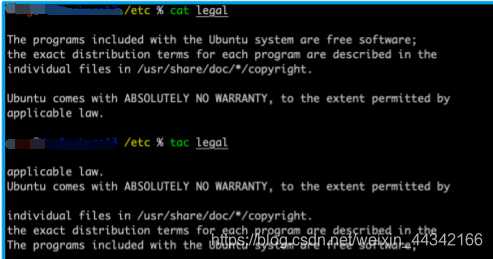
3、NL输出行号显示文件
grammar:nl [option]
options:
-b: 行号指定的方式
-b a:相当于cat -n
-b t:相当于cat -b
-n:列出行号的表示方法
-n ln:行号在屏幕最左边显示
-n rn:行号在自己字段的最右边显示
-n rz:行号在自己字段的最右边显示,前面自动补全0
-w :行号所占位数
4、MORE 按页查看
grammar:more
operation:
/string:向下查找string关键字
:f:显示文件名称和当前显示的行数
q:离开
?:查看其他命令
按空格键就可翻页
5、LESS 按页查看
grammar:less
operation:
/string:向下查找
?string:反向查找
n:继续向下查找
N:继续反向查询
q:退出
man 手册也是用的 less 来查看的
6、HEAD查看头几行
grammar:head [option]
options:
-n num:显示前num行
-n –num:除了后num行外,其他的都显示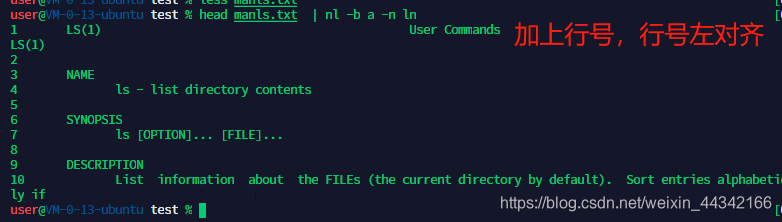
7、TAIL查看尾几行
grammar:tail [option]
options:
-n num:显示文件后num行
-n +num:除了前 (num - 1)行,其他的都显示
-f :打印文件中新增的内容
查看一个文件的第101行到120行
cat manls.txt | nl -b a > manls.txt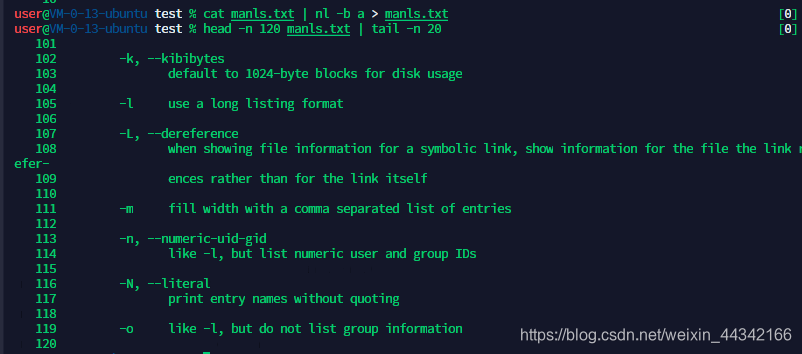
8、修改文件时间与新建文件
文件的三个时间acm
atime:access time, 内容被取用时,更新这个读取时间
ctime:status/change time, 权限,属性,所有者改动时,更新这个时间
mtime:modify time, 内容数据改动时,更新这个时间
atime 更新的两个条件(默认)
- atime < ctime atime才会被更新 ,atime > ctime 就不会被更新
- 如果两次查看的时间 超过了24h atime 才会被更新
想三个时间都一致,可以touch 一下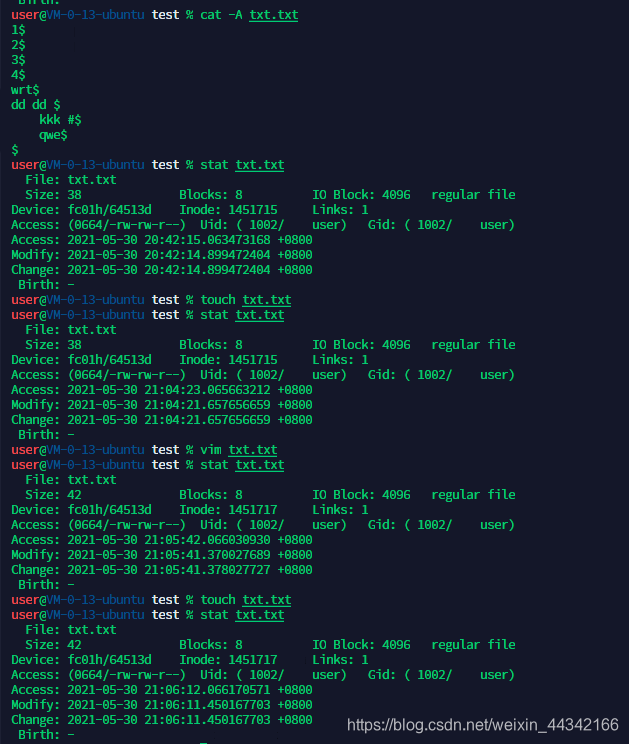
新建文件
grammar:touch [option]
options:
-a:仅修改访问时间
-c:仅修改文件的时间,若文件不存在,不新建
-d:修改文件日期
-m:仅修改mtime
-t:修改文件时间[yymmddhhmm]
9、查看文件的隐藏属性
grammar:lsattr [-adR] <file_or_dir>
options:
-a:打印隐藏文件的隐藏属性
-d:如果是目录,仅打印目录的信息
-R:递归
10、修改文件的隐藏属性
grammar:chattr [±=][option] <file_or_dir>
options:
A:不修改atime
S:同步写入
a:只能增加数据
c:自动压缩,解压
d:不会被dump程序备份
i:不能删除,修改,建立连接
s:文件删除时,直接从磁盘删除
u:文件删除时,数据内容存在磁盘中
11、文件的特殊权限
文件的普通权限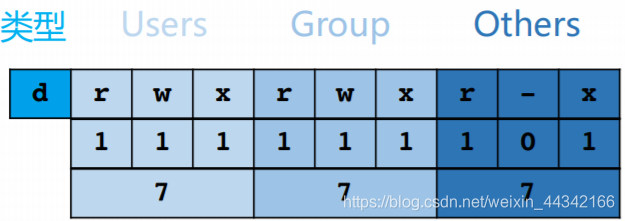
文件的特殊权限
SUID:set_uid
SGID:set_gid
SBIT:sticky bit
大S和小s 的区别
如果文件在该组下是没有可执行权限的,当加上s权限后,x位会变成S
如果文件在该组下是有可执行权限的,当加上s权限后,x位会变成s

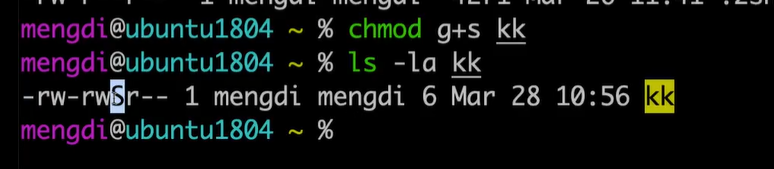
用数字来代替
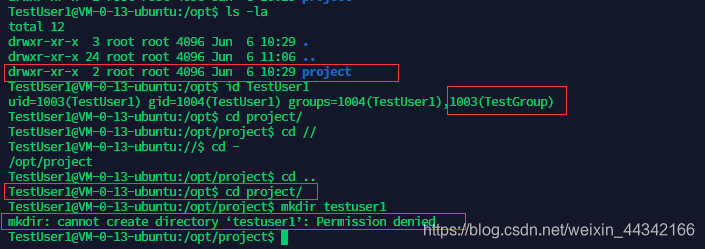
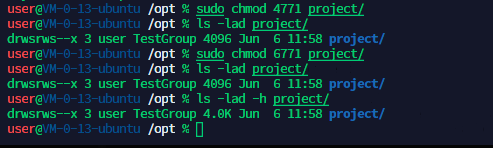
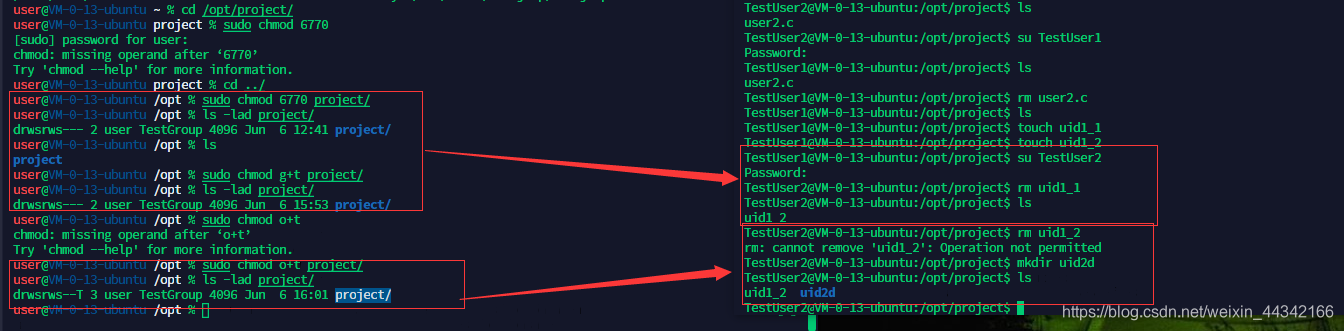
用户TestUser1 在TestGroup 里,能进去,但是不能创建目录
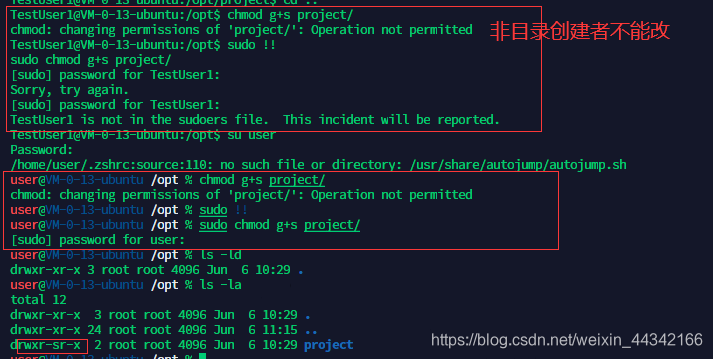
非目录创建者不能修改目录的组权限,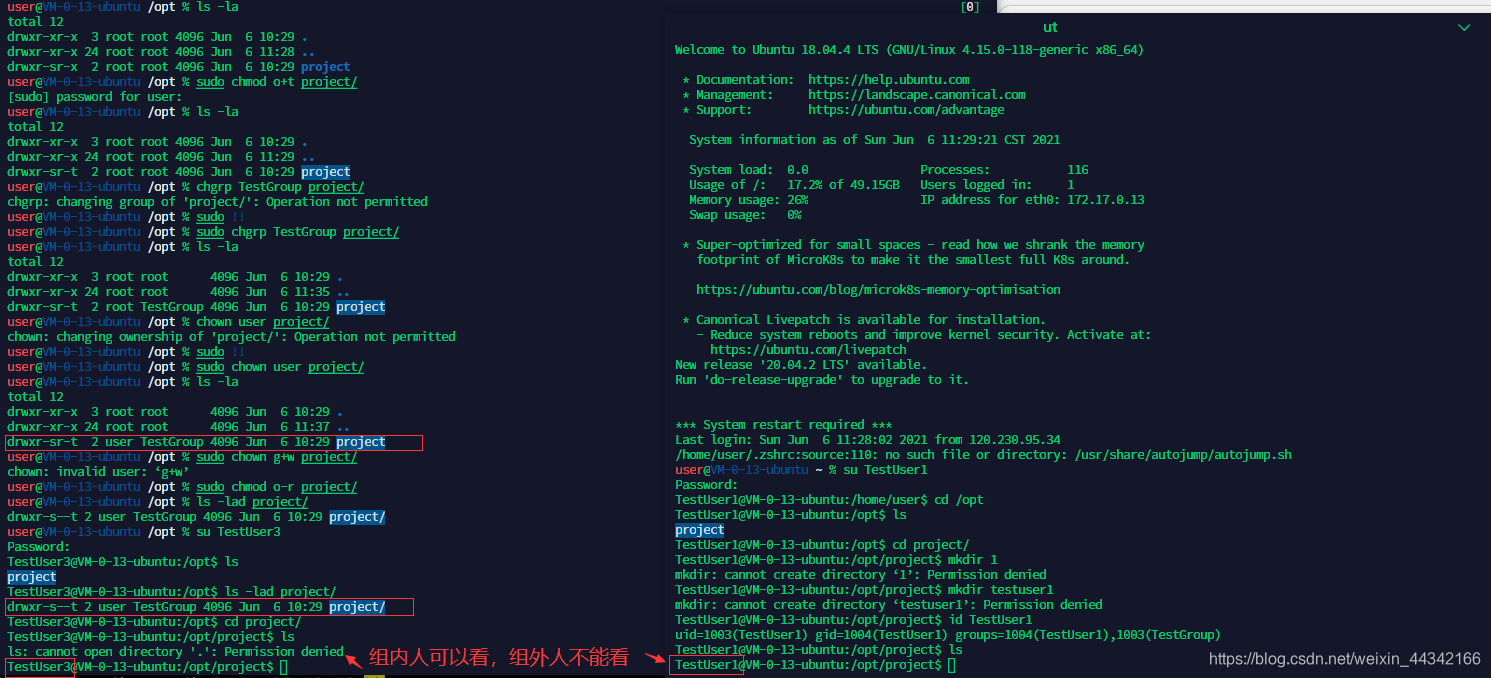
组内人可以看,组外人不可进入该目录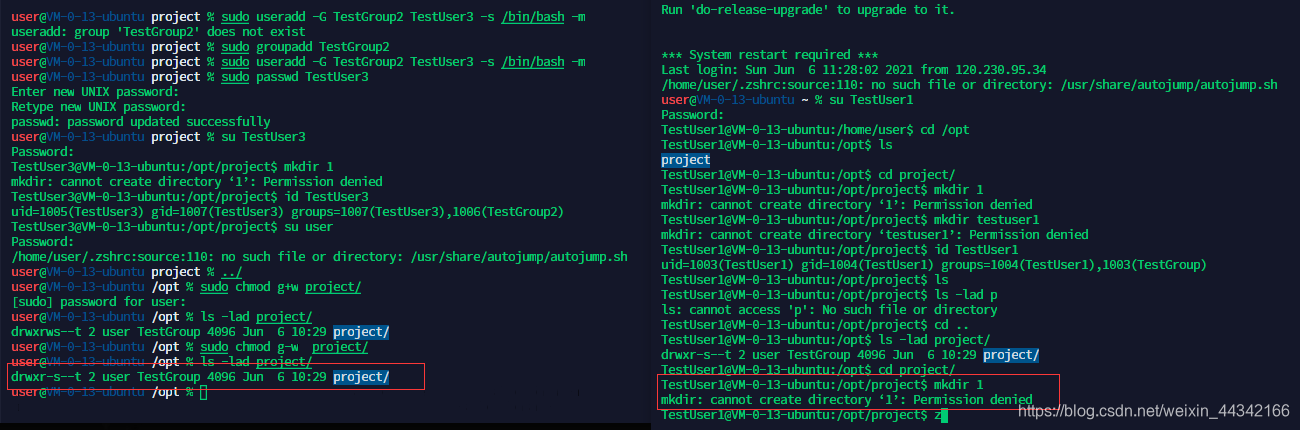
当创建者给组内 g+w 后组成员就可以在该组目录里追加内容
也可以用数字表示
- user 的s 用4 表示,group 的s 用2表示,other 的t 用1表示
- 6777 第1个6= 4+2 即uid 和 group 都赋予是s 的权限,后3位为文件原来的 rwx的属性权限
12、命令与文件的查询

WHICH寻找可执行文件
grammar:which name
查找PATH路径下所有的可执行文件
WHEREIS寻找特定文件
grammar:whereis [option] <file_or_dir>
options:
-b:只查找二进制文件
-m:只查找manual路径下的文件
-s:只查找source源文件
-u:查找其他文件
path路径下的可执行文件
LOCATE 模糊定位
grammar:locate [option]
options:
-i:忽略大小写
-r:后面可接正则表达式
相关文件:
/ect/updatedb.conf
/var/lib/mlocate
系统在空闲的时候会放 在一个索引库里
这样就会不能快速查到 这个文件,因为存在不能快速建立索引的问题,需要sudo updatedb,更新索引后,再创建。
FIND高级查找
grammar:find [PATH] [option] [action]
options:
与时间相关的参数:-atime,-ctime,-mtime
-mtime n:n天前的“一天之内”修改的文件
-mtime +n:n天之前,不包含n,修改过的文件
-mtime –n:n天之内,包含n,修改过的文件
-newer file:比file还要新的文件
与用户或用户组相关的参数:
-uid n:用户UID为n
-gid n:群组Gid为n
-user name:用户名为name
-group name:群组名为name
nouser:文件所有者不存在
nogroup:文件所在组不存在
与文件权限及名称有关的参数:
-name filename:文件名为filename
-size [±] SIZE:查找比SIZE大(+)或小(-)的 如,小于10k -size -10k
-type TYPE: f b c d l s p
-perm mode:mode刚好等于的文件
-perm –mode:全部包含mode的文件
find -exec ls –l {} \
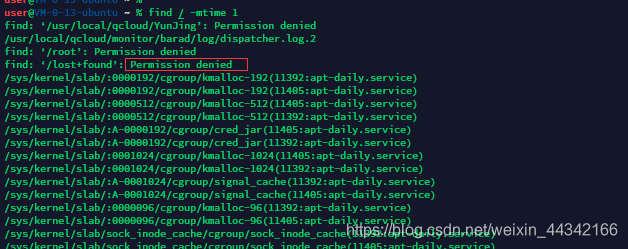
有很多没有权限的提示,如果想不显示这些提示可以 用 find / -name “install_vim.sh” 2>/dev/null
2>/dev/null会把没有用的放到回收站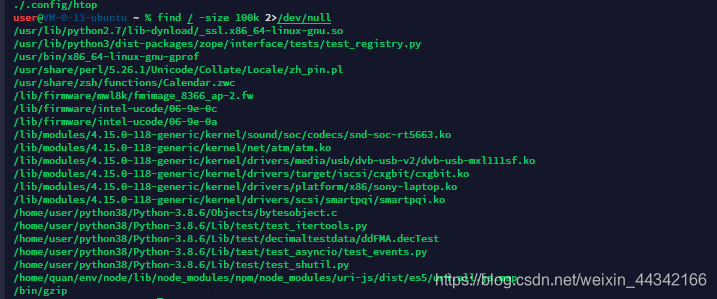
按类型查链接文件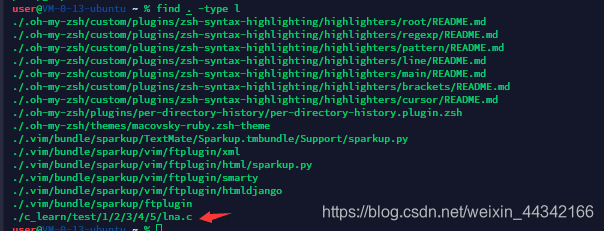
结合多个参数查找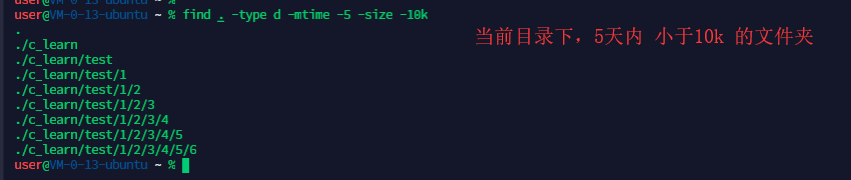
13、文件描述符
内核(kernel)利用文件描述符fd(file descriptor)来访问文件。
文件描述符:
0:stdio:标准输入
1:stdout:标准输出
2:stderror:标准错误输出
三个宏定义,定义在open、read、write函数的头文件中
0:STDIN_FILENO
1:STDOUT_FILENO
2:STDERR_FILENO
当我们打开一个进程的时候,会打开3个文件描述符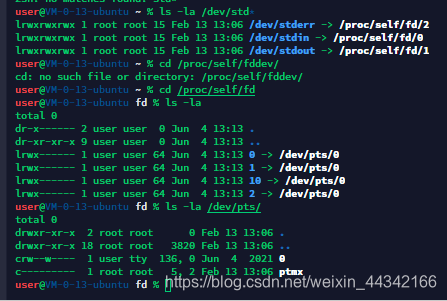
find / -name learn_c > learn.output 2>&1 :把命令find / -name learn_c 执行的错误和正确输出都重定向到learn.output里
find / -name learn_c &> learn.output :默认把命令find / -name learn_c 执行的错误和正确输出都重定向到learn.output里,跟上面的效果一致
14、/dev/null回收站
command 2>/dev/null
练习:
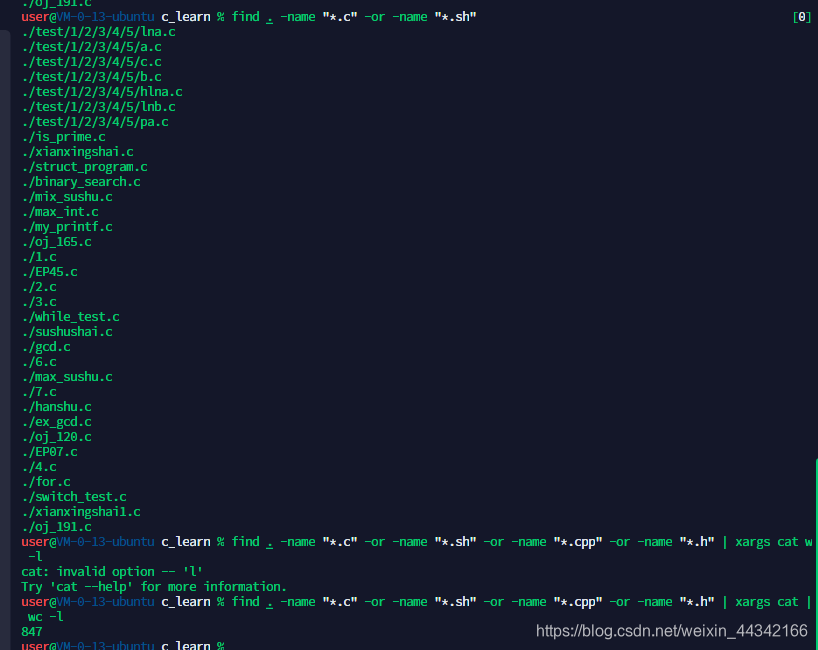
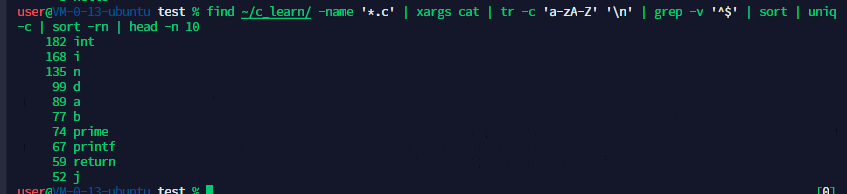
1、求.c cpp sh h 的代码总行数
xargs 前面返回的变量作为后面 命令的入参
-or 或的意思
四、数据提取操作
cut 切分
grammer:cut [-dfc]
-d c:以c字符分割
-f num:显示num字段的内容 [n- ; n-m ; -m; m,n]
-b num:字节
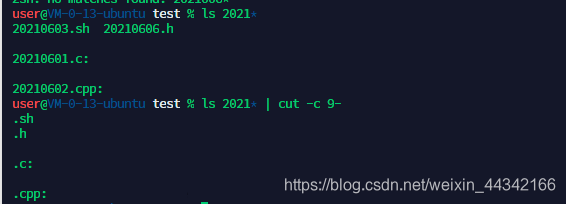
-c num:字符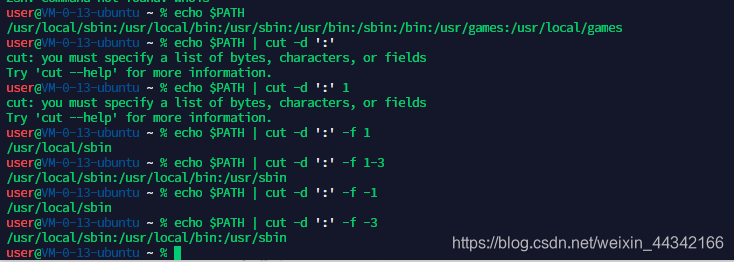

查看登陆失败的uid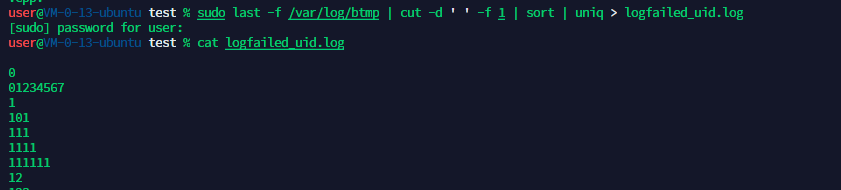
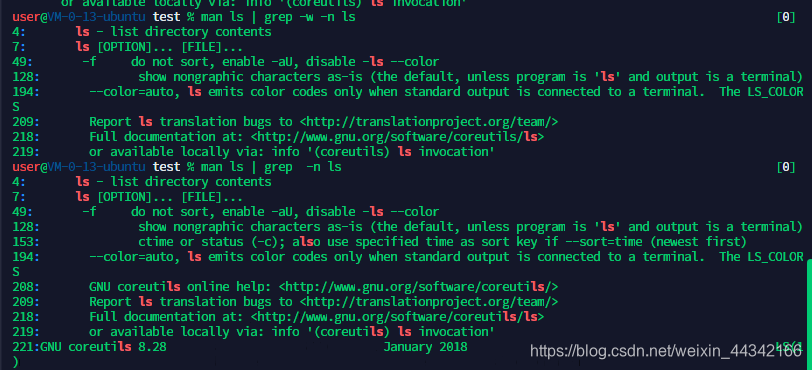
grep 检索
grammer:grep [-cinvw]
-c:统计搜寻到的行数
-i:忽略大小写
-n:顺序输出行号
-v:反向输出(输出没找到的)
-w:匹配整个单词,而不是单词的一部分
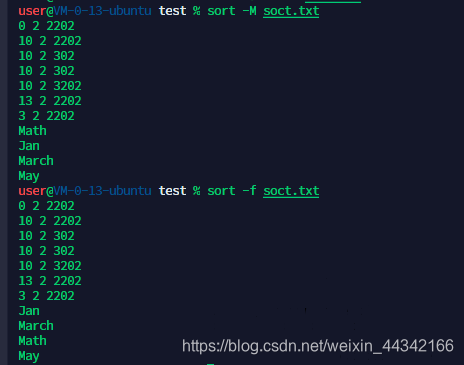
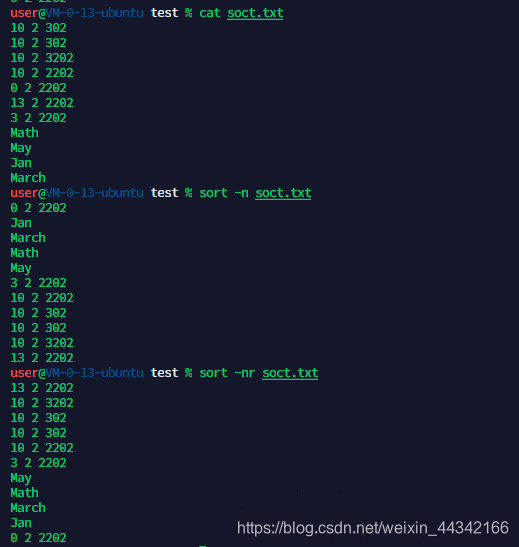
sort 排序
grammer:sort [-fMnructk] <file_or_stdio>
-f:忽略大小写
-M:以月份名称排序
-n:根据数值进行排序
-r:反向排序
-u:uniq
-c:检查文件是否有序
-t 分隔字符:指定排序时用的栏位分隔字符
-k:以那个区间排序
+ :排序栏位,第一栏为0,按顺序优先排序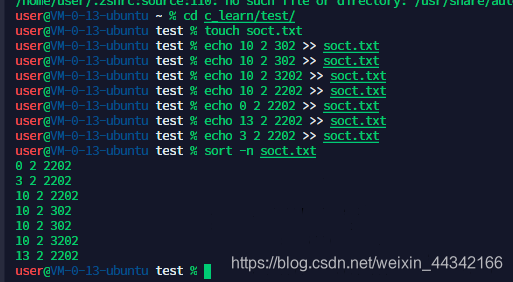
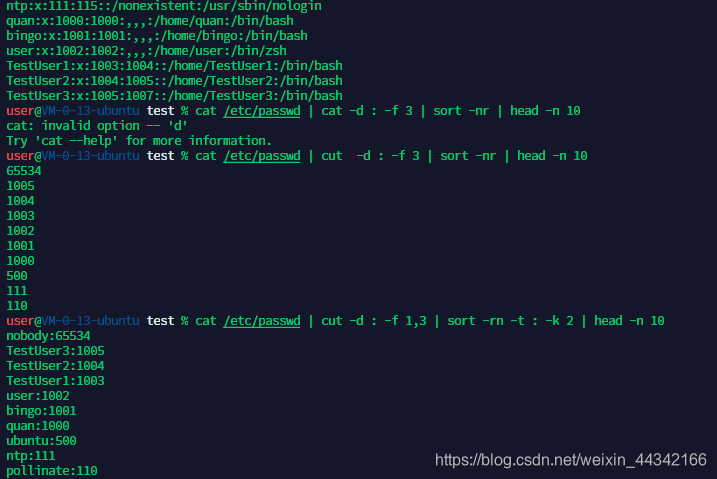
过滤以用户id 为排序的 前10个用户 和用户id
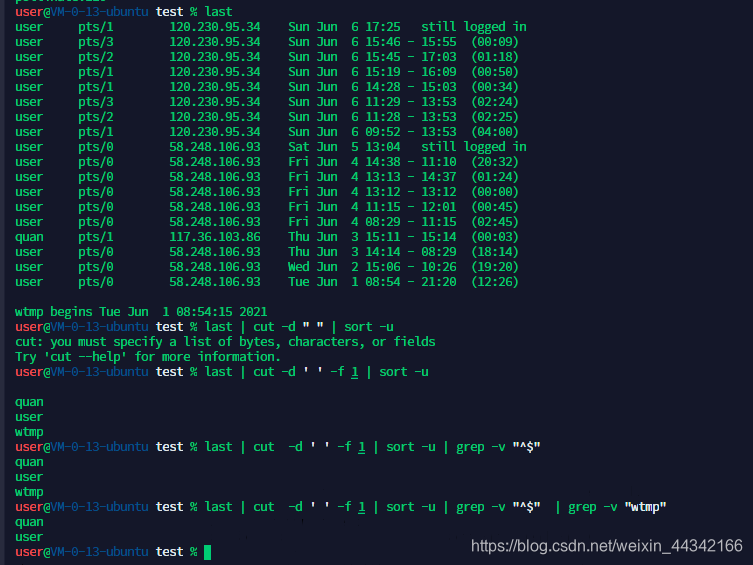
过滤最近登陆的用户
从第4行开始就是无序的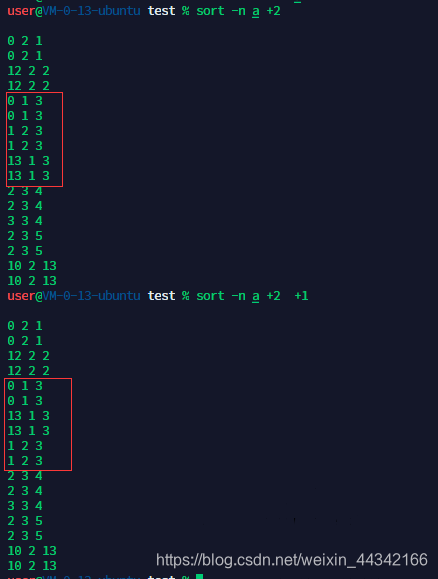
第一列的 index=0 先以第3列的为准排序,再以第2列的为准排序
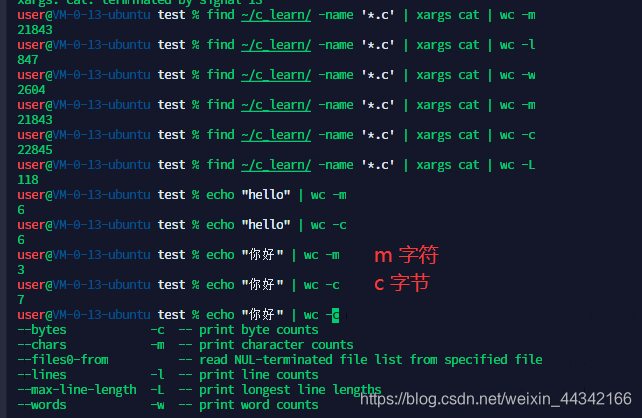
WC 统计字符,字数,行数
grammer:wc [-lwmcL] <file_or_stdin>
-l:仅列出行号
-w:仅列出多少字
-m:仅列出多少字符
-c:仅列出多少字节
-L:列出最长一行的字符长度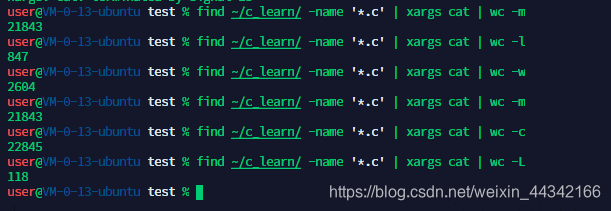
uniq 去重
grammer:uniq [-ic]
-i:忽略大小写字符的不同
-c:进行计数
-u:只输出无重复的行
如果不排序就去重,不会去全局重复的,只会去上下附近重复的。

tee 双向重定向
grammer:tee [-a] file
-a:append
不加 -a 相当于 < 加 -a 相当于 <<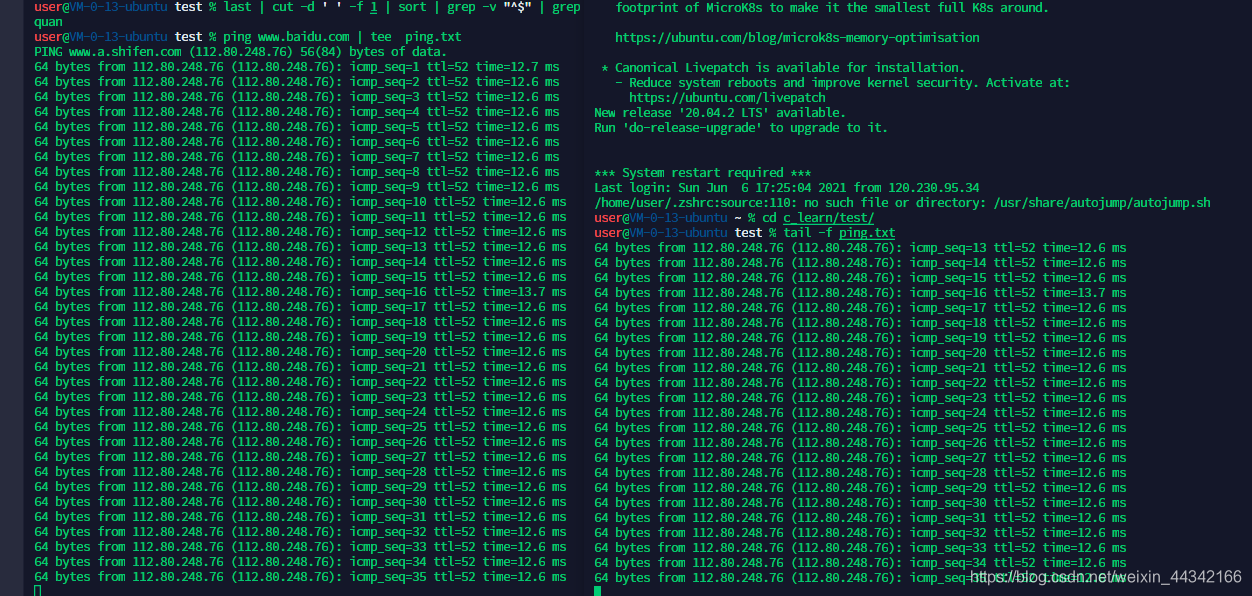
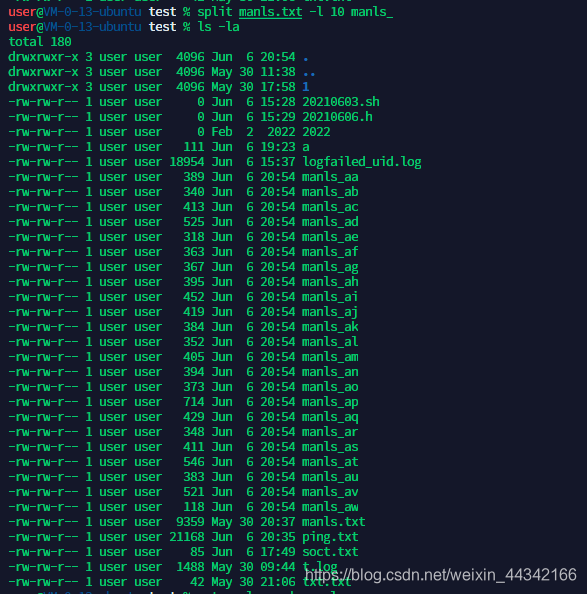
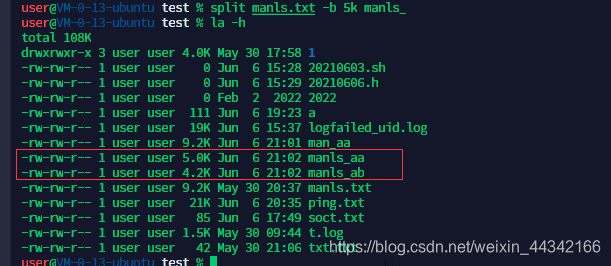
split 文件切分
grammer:split [-bl] PREFIX
-b SIZE:切分为SIZE大小的文件
-l num:以num行为大小切分
xargs 参数代换
grammer: args [-pne]
-eEOF:当xargs读到EOF时停止
-p:执行指令前询问
-n num:每次执行command时需要的参数个数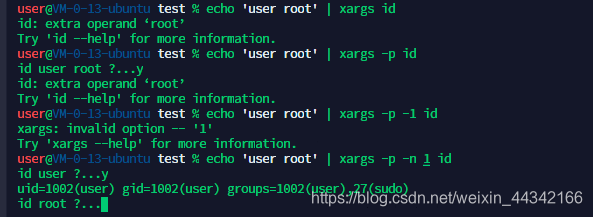

读到TestUser1 就停止读入
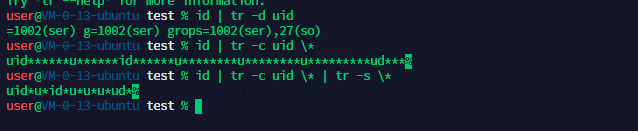
tr 对标准输入的字符替换、压缩、删除
grammer:tr [cdst] <字符集1> <字符集2>
-c 取代所有不属于第一字符集的字符
-d 删除所有属于第一字符集的字符
-s 将连续重复的字符以单独一个字符表示
-t 先删除第一字符集较第二字符集多出的字符
“[:lower:]” “[:upper:]”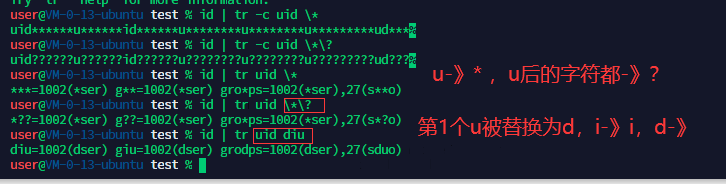
后面的字符集取代前面的字符集
删除所有 包含uid 的字符
把重复的 * 做压缩 把重复的压缩成1个

小写改为大写,大写改为小写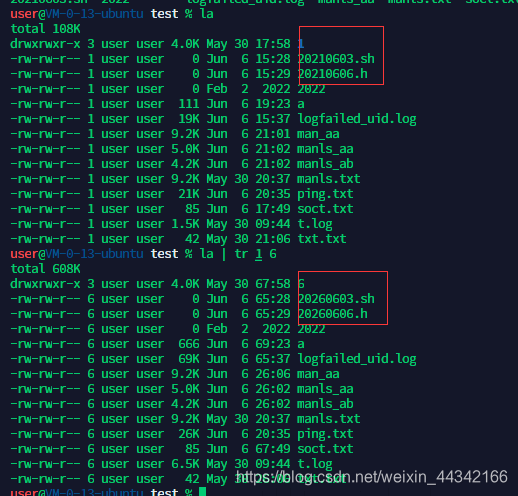
练习
1、tr命令对⽂件的重命名,内容的替换操作。
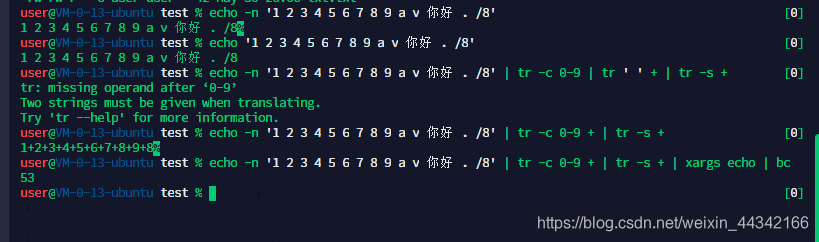
#“1 2 3 4 5 6 7 9 a v 你好 . /8”
#求以上字符串中所有数字之和
- bc 可以计算 1+2+3的值,相当于计算器
- echo -n 不换行,如果不加 -n 就会自动换行
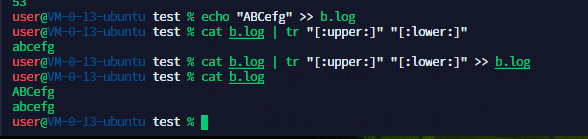
#echo “ABCefg” >> test.log
#请将该⽂件中所有⼤写字⺟转换为⼩写
2、找到 PATH 变量中的最后⼀个路径。
3、使⽤ last 命令,输出所有的登录⽤户名及登录次数,按登录次数由多及少排序。

4、在云主机上查找系统登录⽤户的总⼈次
5、将 /etc/passwd 中的内容按照⽤户名排序。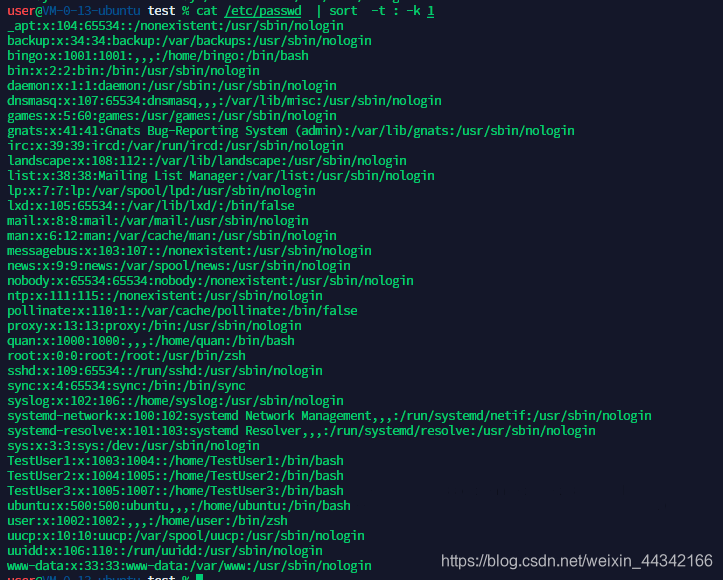
6、将 /etc/passwd 中的内容按 uid 排序。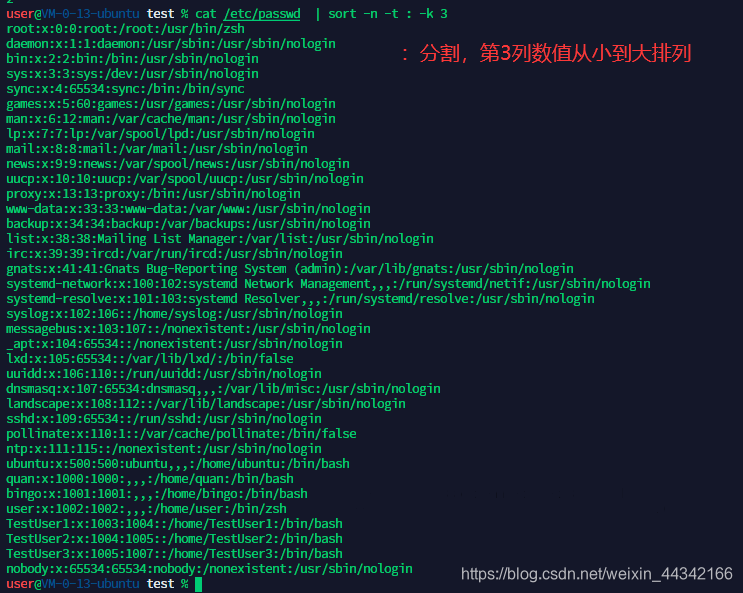
7、将本地的 /etc ⽬录下的⽂件及⽬录,每⼗条保存到⼀个⽂件中。
8、将 /etc/passwd 中存放的第10到20个⽤户,输出 uid , gid 和 groups 。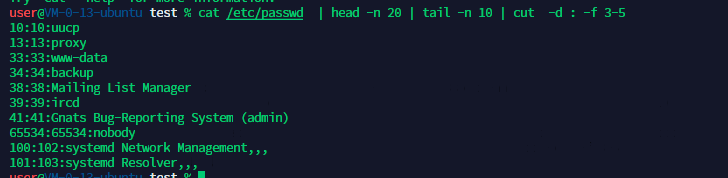
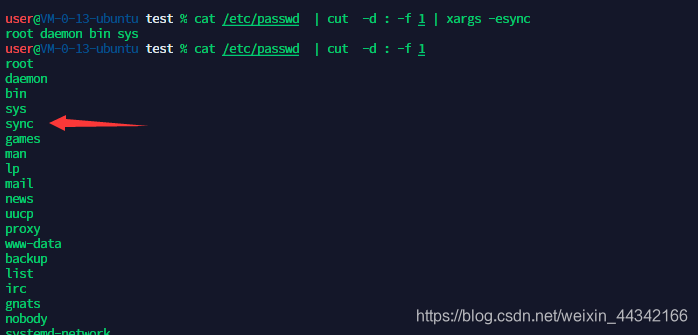
9、将按照⽤户名查看 /etc/passwd 中的⽤户,读到 'sync’ ⽤户时结束
10、词频统计
使⽤下⾯这个命令⽣成⼀个⽂本⽂件。
cat >> a.txt << xxx
nihao hello hello 你好
nihao
hello
ls
cd
world
pwd
xxx
统计a.txt中各词的词频,并按照从⼤到⼩的顺序输出。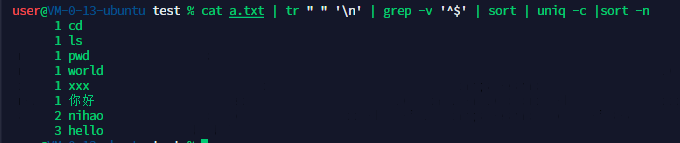
总结

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)