你的模型真的能打吗?上交发布了近百项场景的GM-100,操作任务的长尾场景评测来了
GM-100包含100项精心设计的任务,涵盖各类交互场景与长尾行为,旨在提供一组多样化且具有挑战性的任务集合,全面评估机器人智能体的能力,并推动机器人数据集任务设计向多样化与复杂化方向发展。GM-100包含100项精心设计的任务,涵盖各类交互场景与长尾行为,旨在提供一组多样化且具有挑战性的任务集合,全面评估机器人智能体的能力,并推动机器人数据集任务设计向多样化与复杂化方向发展。然而,这些方法往往缺
现有数据集真的推动机器人能力提升了吗?
近年来,随着机器人学习和模仿学习的快速发展,各类数据集与方法层出不穷。然而,这些数据集及其任务设计往往缺乏系统性的考量与原则。这引发了两个关键问题:现有数据集与任务设计是否真正推动了机器人能力的提升?仅通过少数常见任务的评估,能否准确反映不同团队提出的各类方法在不同任务上的差异化性能?
为解决这些问题,上海交大等研究团队提出GM-100基准测试,将其作为迈向机器人学习奥林匹克盛会的第一步。GM-100包含100项精心设计的任务,涵盖各类交互场景与长尾行为,旨在提供一组多样化且具有挑战性的任务集合,全面评估机器人智能体的能力,并推动机器人数据集任务设计向多样化与复杂化方向发展。这些任务通过对现有任务设计的系统性分析与扩展,并结合人物交互基元与物体功能特性的相关insights开发而成。
本数据集在不同的机器人平台上收集了大量轨迹数据,并对多个基准模型进行了评估。实验结果表明,GM-100的任务具备两大特性:1)可执行性;2)足够的挑战性,能够有效区分当前视觉-语言-动作(VLA)模型的性能。
- 论文标题:THE GREAT MARCH 100: 100 DETAIL-ORIENTED TASKS FOR EVALUATING EMBODIED AI AGENTS
- 论文链接:https://arxiv.org/abs/2601.11421
- 项目主页:https://rhos.ai/research/gm-100
提出的背景
近年来,随着机器人学习的快速发展,各类数据集与任务设计不断涌现。例如,Open X-Embodiment整合了22种不同机器人的数据集,包含160,266项任务;Agibot收集了200余项任务及超过100万条轨迹;RoboCOIN则为421项任务提供了18万余条演示数据。然而,这些数据集与任务往往聚焦于少数常见任务与行为。
去除重复项并按语义分类后发现,大多数任务集中于“拾取并握持”等极为常见的行为,而缺乏对复杂任务与长尾任务的覆盖。这种单一化的任务设计导致训练出的模型存在显著偏差,使其作为预训练模型时,除少数常见任务外,在真实场景中的适用性受限。
同样,当前的评估任务也存在类似问题:多数研究在提出新方法时,仅在少数常见任务上进行测试,且缺乏统一的任务设计标准,这使得不同研究成果之间难以进行公平对比。
为解决这些问题,上交提出“Great March 100”(GM-100)基准测试,将其作为迈向机器人学习奥林匹克盛会的第一步。GM-100包含100项精心设计的任务,涵盖各类交互场景与长尾行为,旨在提供一组多样化且具有挑战性的任务集合,全面评估机器人智能体的能力,并推动机器人数据集任务设计向多样化与复杂化方向发展。这些任务通过对现有任务设计的系统性分析与扩展,并结合人类动作理解的相关洞见开发而成。
本工作在两款不同的机器人平台上收集了大量轨迹数据,并对多个基准模型进行了评估。实验结果表明,GM-100的任务具备两大特性:1)可执行性;2)足够的挑战性,能够有效区分各类方法的性能。
此外,在任务设计过程中,本工作并未以真实世界任务的实用性为标准(以避免人为偏差),而是将物理常识与底层操作知识(即“如何操作”层面的功能特性)作为生成与筛选最终任务的唯一准则。
GM-100的任务设计
在以往的研究中,研究人员基于多种主观标准设计机器人任务,包括设计者的判断、常见日常活动以及应用场景。然而,这些方法往往缺乏系统性的考量和设计原则,导致不同研究中的任务存在大量重叠,且多聚焦于极为常见的活动和任务。这使得机器人数据集和评估任务中长尾任务的覆盖不足,数据积累集中在常见任务上,而忽略了稀有任务。
这里收集并分析了Agibot、Open X-Embodiment等以往研究的任务设计,去除重复项后进行分类。图1中的词云和动词频率分布图清晰显示出对最常见任务的明显偏向,许多任务都需要“拾取并握持”等类似动作。该分析凸显了以往任务设计的局限性:它们往往忽视了长尾分布中稀有但重要的任务,且不同任务间存在显著重叠。这些问题源于长期以来对人类活动的长尾特性以及多类别动作耦合性的忽视,而这些正是本工作需要机器人学习和执行的核心内容。
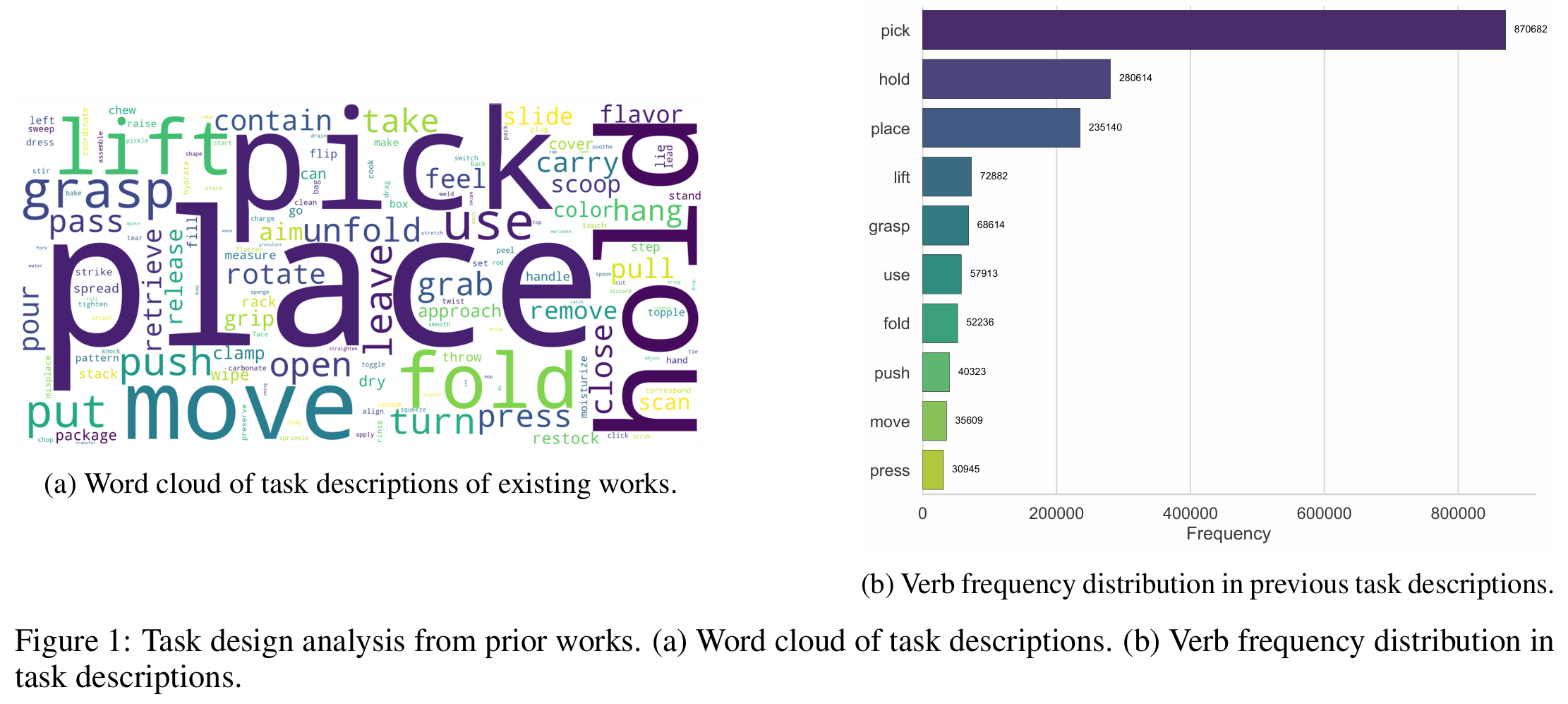
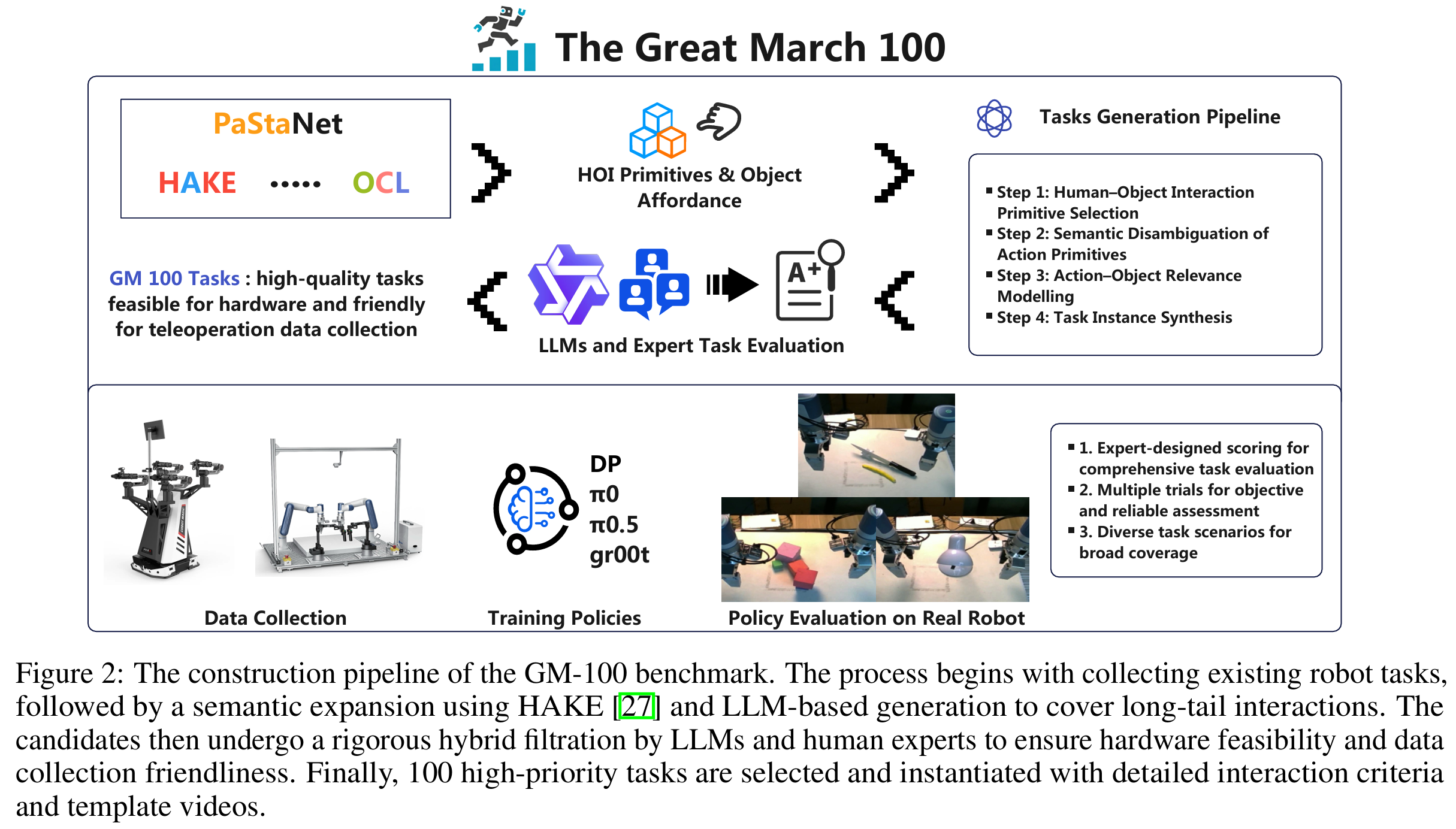
鉴于此,这项研究提出依据人类动作合理性设计机器人任务。旨在构建一组多样化的任务,涵盖广泛的交互场景,同时考虑动作的耦合性,并确保长尾、稀有但重要的动作得到体现。此外,基于HAKE、PaStaNet、OCL等人类-物体交互研究的洞见,这里还设计了一些想象中看似简单但实际执行颇具挑战性的任务。
这里先基于以往的机器人学习研究选择基础交互动作,例如Agibot的任务列表和 π 0.5 \pi_{0.5} π0.5的评估任务,收集这些研究中的所有任务,去除重复项后按语义进行分类。随后,在这些现有任务的基础上,参考HAKE和OCL中的人类-物体交互原语及物体功能特性,进一步扩展和补充任务列表。借助大型语言模型,基于精心设计的提示词(融合了上述动作和物体信息)自动生成大量任务,并筛选出多样化的活动。
这里挑选了一组具有代表性的人类-物体交互原语,涵盖从高频到低频的各类活动。在统一的任务设计提示词下,利用Qwen3模型自动生成大量候选任务。
首先,对所选动作原语进行词义消歧,以消除潜在歧义,确保语义的唯一性和一致性。随后,引导Qwen3列举出与每个动作原语在语义和物理层面相关的物体。基于这些动作-物体对,模型进一步合成具体的任务实例,并优化任务描述,生成清晰、易于人类理解的文本说明。
在任务筛选阶段,首先利用Qwen3自动对生成任务的机器人可执行性进行评分,随后由五名人类专家进行最终筛选,将其作为黄金标准。通过这一过程,获得了一组高质量的机器人任务,这些任务在现有硬件约束下具备可行性,且便于基于遥操作的数据收集。最终,结合多个大型语言模型和人类专家的评估结果对任务进行评分和筛选,确保所选任务符合当前硬件能力且易于数据收集。
这里根据任务得分确定优先级,对于高优先级任务,设计了具体的交互细节并筛选物体(例如从淘宝网选择合适的物体)。我们还制定了明确的任务完成评估标准,为未来超越成功率(SR)的评估指标奠定基础。此外,录制了人类完成这些任务的模板视频,以指导数据收集工作。
基于生成和筛选后的任务,并考虑到第一版的工作量,选取100个任务组成GM-100基准测试集,作为GM系列的首个版本。该集合将为未来的GM系列研究奠定基础。本工作通过遥操作收集了GM-100任务的中型数据集,包含超过1.3万条轨迹。
数据收集
这里通过遥操作方式在GM-100任务中收集了一个中型数据集,包含超过13000条轨迹。
硬件平台
这里采用两款机器人平台(Agilex Cobot Magic和Dobot Xtrainer)进行数据集收集和具身智能体评估。这两款平台具有不同的运动学结构、双臂设计和主相机视角,能够为评估提供多样化数据。Cobot Magic是类Mobile-Aloha型机器人平台,采用前伸式手臂结构并配备头戴式相机;而Xtrainer是类Aloha型平台,采用内折式手臂结构并提供俯视相机视角,两款平台如图3所示。

轨迹数据通过遥操作方式收集,由人类操作员控制机器人手臂执行各类任务。当前版本中,在Cobot Magic平台上完成了全部100个任务的数据收集,在Xtrainer平台上完成了10个任务的数据收集。更多数据收集工作正在进行中,后续版本将逐步开源。
数据分布
对于每个任务,首先收集100条具有不同初始条件和设计扰动的轨迹,以确保位置、姿态和物体放置的多样性。随后再收集30条与前100条轨迹分布相似的轨迹。这30条轨迹用于评估过程中的测试用例对齐,确保不同checkpoint或不同模型的测试环境保持一致。
实验设置
基线模型
为验证GM-100任务的可行性和挑战性,在100个任务上对多个基线模型进行了评估,包括DP、 π 0 \pi_0 π0、 π 0.5 \pi_{0.5} π0.5和GR00T。这些模型中,DP为从头训练,VLA类模型( π 0 \pi_0 π0、 π 0.5 \pi_{0.5} π0.5、GR00T)基于每个任务收集的100条轨迹进行微调,直至收敛。
评估指标
为评估不同模型在GM-100任务上的性能,这里采用以下指标:
-
成功率(SR):固定尝试次数内成功完成任务的百分比。这是评估机器人任务性能最常用且最直观的指标。为确保公平性和可复现性,使用每个任务收集的30条测试轨迹对不同模型的测试用例进行对齐。由于真实世界机器人测试耗时较长,这里将逐步发布所有基线模型的完整结果。
-
部分成功率(PSR):任务中成功完成的子任务百分比。对于涉及多步骤或多目标的复杂任务,仅用成功率难以全面反映模型性能。特定任务下机器人手臂配置的非最优性、收集数据集的广泛分布以及训练数据的不足,共同导致GM-100基准测试的整体成功率较低。这一结果既凸显了此类数据约束下任务本身的固有挑战性,也影响了本文对模型性能进行细粒度评估的能力。
-
动作预测误差:测试轨迹特定预测窗口内,预测动作与真实动作之间的均方误差(MSE)和L1损失。尽管较低的动作预测误差并不一定保证较高的任务成功率,但它反映了模型理解和复现未见过的专家演示的能力。然而,不同基线模型可能预测不同长度的动作块,因此为确保公平比较,这里仅在所有基线模型的特定重叠预测窗口上计算动作预测误差。
结果与分析
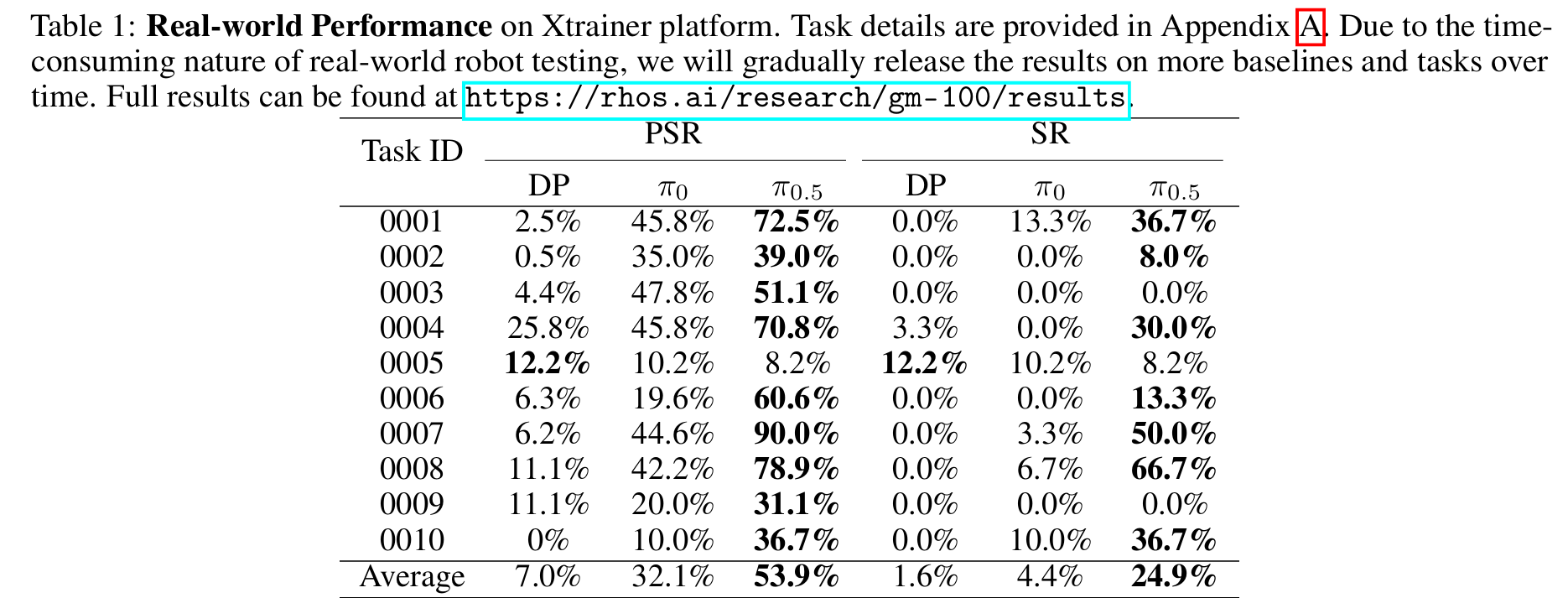
实际场景性能
表1展示了不同基线模型在Xtrainer平台的实际场景性能,在图4中呈现了各模型在Cobot Magic平台的部分成功率。
预测损失
表2列出了通过均方误差(MSE)和L1损失衡量的动作预测误差。
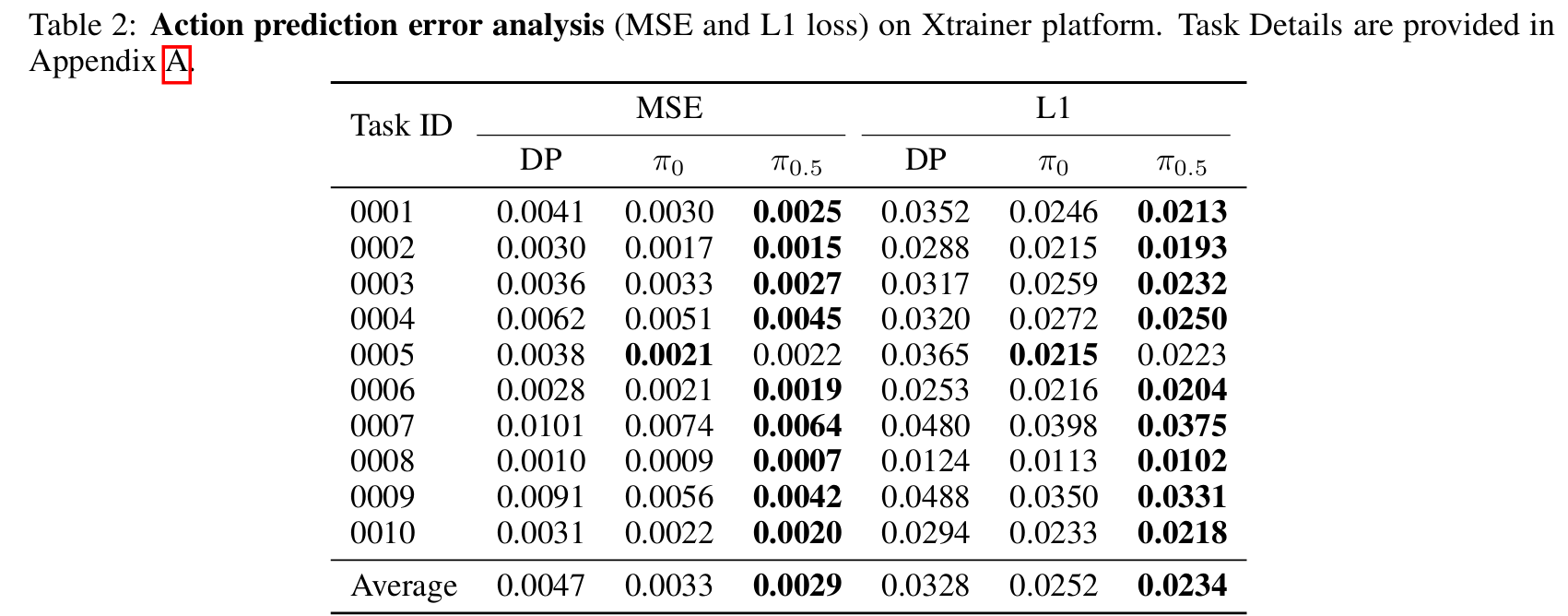
图4:Cobot Magic平台的部分成功率。热力图中的颜色深浅表示部分成功率(PSR)的高低。
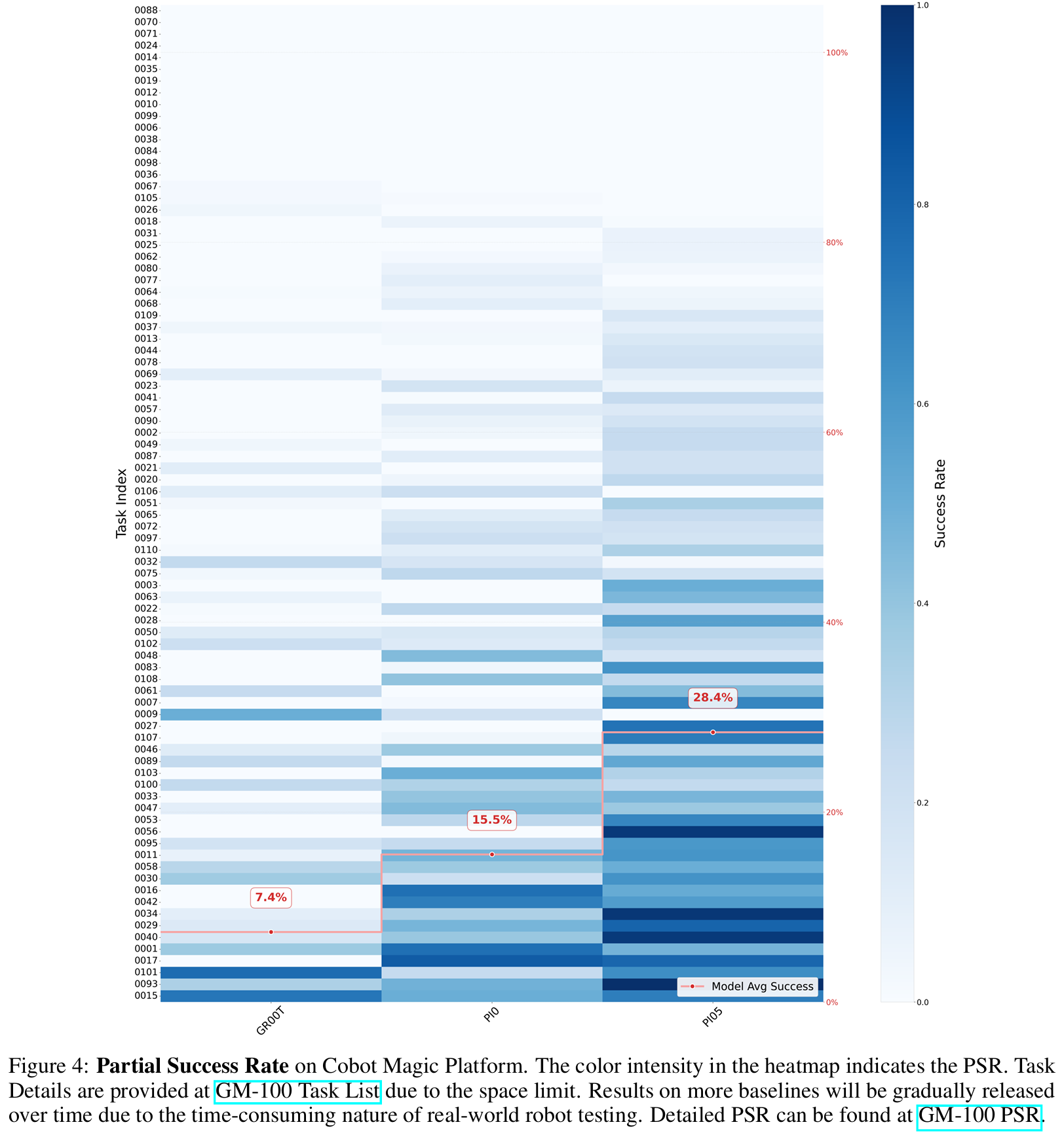
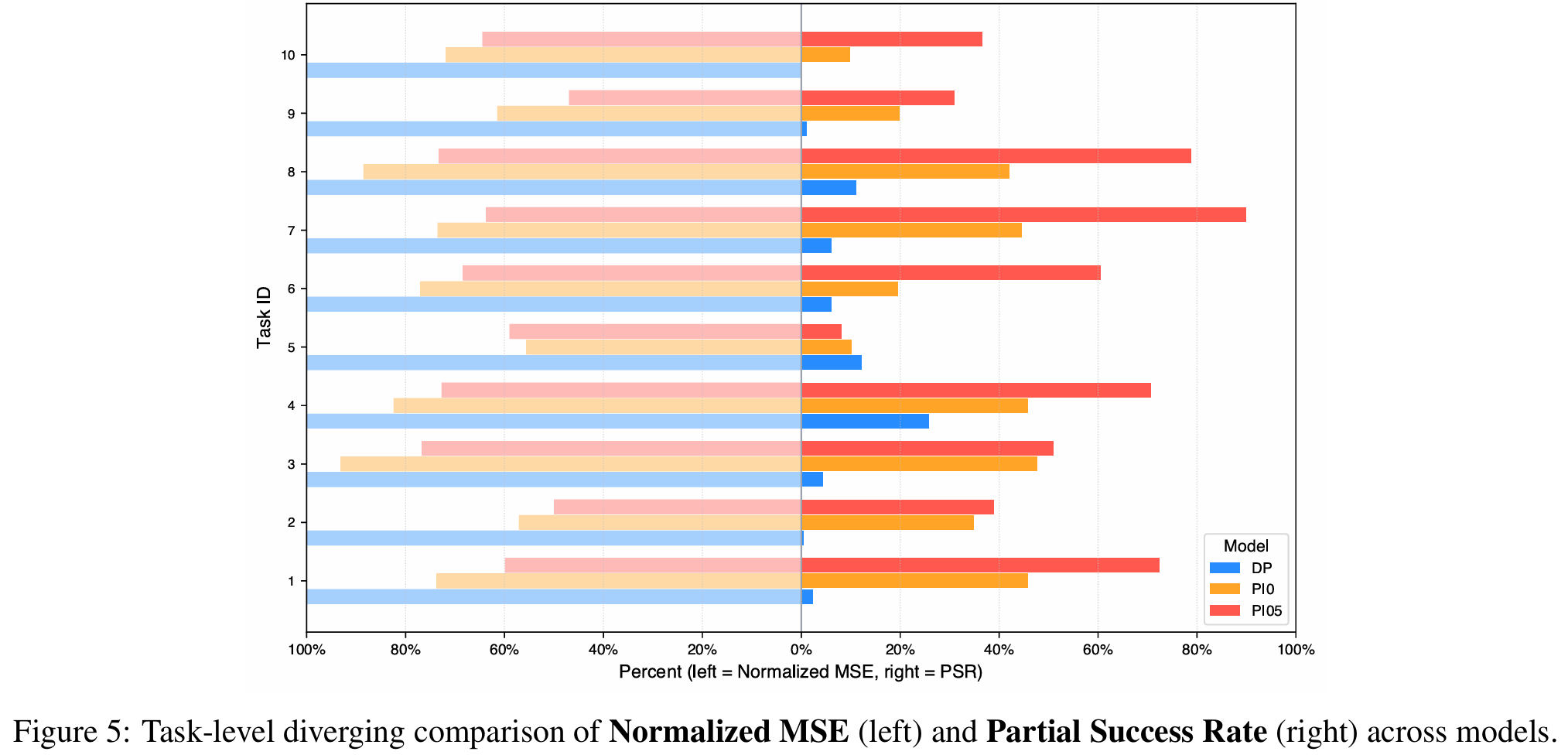
图5:各模型在任务层面的归一化均方误差(左侧)与部分成功率(右侧)对比图。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)