让性能瓶颈自己开口说话:AI 驱动的下一代 JVM 性能诊断革命
本文介绍一种无侵入式性能诊断方案:利用 JDK Flight Recorder (JFR) 采集应用程序的执行采样事件,无需修改业务代码即可识别热点方法。该方案通过 Digger 日志系统汇总分析数据,并引入大语言模型 (LLM),使性能分析从依赖专家经验的“手工活”,转变为由智能体驱动的“自动化诊断工作流”。
本方案不仅实现了从数据采集、智能分析到优化建议的完整业务闭环,更在范式上完成了从“辅助工具”到“自主执行体”的跨越,为性能优化领域带来了可量化、可复制的效率革命。
一、背景
在研发的世界里,性能优化始终是永不褪色的话题。当用户抱怨系统卡顿、当大促流量如潮水般涌来,每一毫秒的延迟背后都牵动着研发们紧绷的神经。
然而传统性能分析工具却常让我们陷入困局:Arthas、Async-Profiler 提供火焰图,但对接入方性能影响较大,且分析解读高度依赖专家经验;JFR 作为 JDK 内置的低开销能力,在生产监控场景中仍未被充分利用。整个“发现问题 -> 定位根因 -> 实施优化”的流程存在多处断点,效率低下且门槛极高。
当我们在日志海洋中徒手打捞瓶颈线索时,大模型与智能体(Agent)技术的成熟正悄然改写这场游戏的规则。我们意识到,性能诊断的终极形态,不应只是一个更快的 Profiler,而应是一个能理解需求、自主分析、并给出精准建议的“性能诊断专家”。
因此,我们将无侵入的 JFR 事件采集、公司内部的日志投递系统与大语言模型的推理能力深度融合,打造了一个具备自主性与闭环价值的智能性能诊断方案。
二、目标
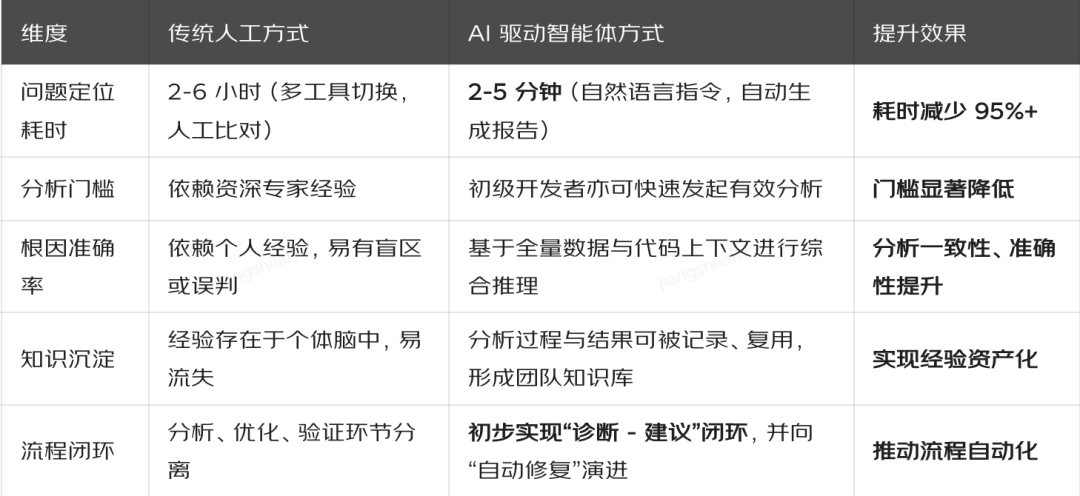
2.1、传统分析流程
传统的性能问题定位是一条断裂的、高度依赖人力的链条:
感知:通过 APM(如 SGM、PFinder)发现指标异常。
数据采集:在特定环境紧急部署 Arthas 或 Profiler 采集数据,影响业务并承担风险。
分析:资深研发解读火焰图、日志,凭经验猜测根因。
解决:修改代码,重新验证。 整个过程耗时数小时乃至数天,且质量波动大。
2.2、智能分析流程
我们的目标是构建一个 “感知 - 分析 - 决策” 一体化的自主智能体。其核心流程如下:
数据采集
首要目标是在生产环境以低于 1% 的 CPU 开销,实现持续、实时的性能数据采集。
我们自研的 JVM 探针深度集成 JDK Flight Recorder。通过配置采样周期与包路径过滤,持续捕获毫秒级精度的线程调用轨迹。采集到的原始堆栈经过清洗、聚合后,被转化为结构化的热点日志,并通过公司内部的 Digger 日志平台进行投递与汇聚,为后续分析提供实时、高质量的数据源。
性能分析
核心突破在于让 AI 同时“看到”运行时的性能数据和静态的源代码上下文。
我们通过 MCP 协议将 Digger 投递项的数据检索能力开放给大语言模型。当用户提出如“分析立减中心昨晚 8 点的性能瓶颈”这样的自然语言指令时,智能体会自主拆解任务:
1、理解指令:解析时间、应用、目标等要素。
2、调用工具:自动查询对应时间段的热点堆栈数据。
3、关联代码:结合获取到的具体方法名和堆栈信息,检索并分析相关源代码。
4、综合诊断:综合运行时行为与代码逻辑,定位根因(如数据库 N+1 查询、锁竞争、算法低效等),并生成结构化的诊断报告与优化建议。
这标志着性能分析从“人使用工具”演变为“人指挥智能体完成任务”。
三、核心价值与量化提升
本方案的价值远不止于一个智能查询工具,它通过打通关键断点,实现了效率与模式的双重变革。
该方案已逐步成为营销团队排查性能问题的“第一反应”。自然语言的交互方式和 IDE 深度集成的设计,使得“遇到性能问题,先问 AI 助手”成为新习惯,接受度和依赖性日益增强。
四、演
4.1、一次完整的自主诊断
环境
IntelliJ IDEA 2025.2.5 (Community Edition) + jdt_joycode (4.8.0) + Claude-4-Sonnet
流程
1、向大模型提问:请分析一下立减中心昨天晚上 8 点前后 30 分钟的性能数据,然后定位下性能瓶颈
2、查看生成的问题与解决方案文档
3、依据文档,让大模型进行改造或人工改造
样例
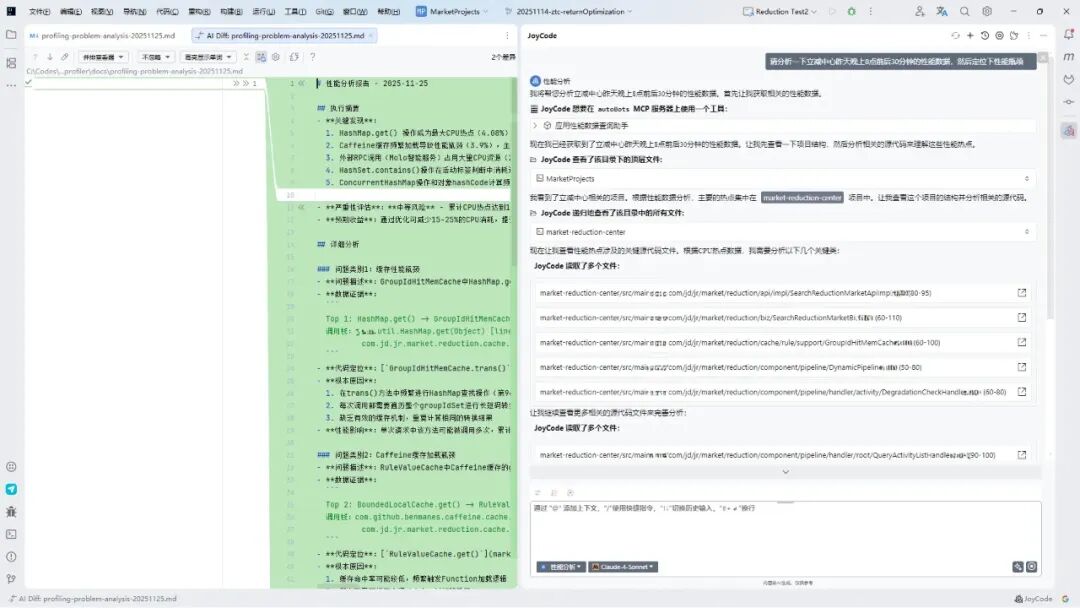
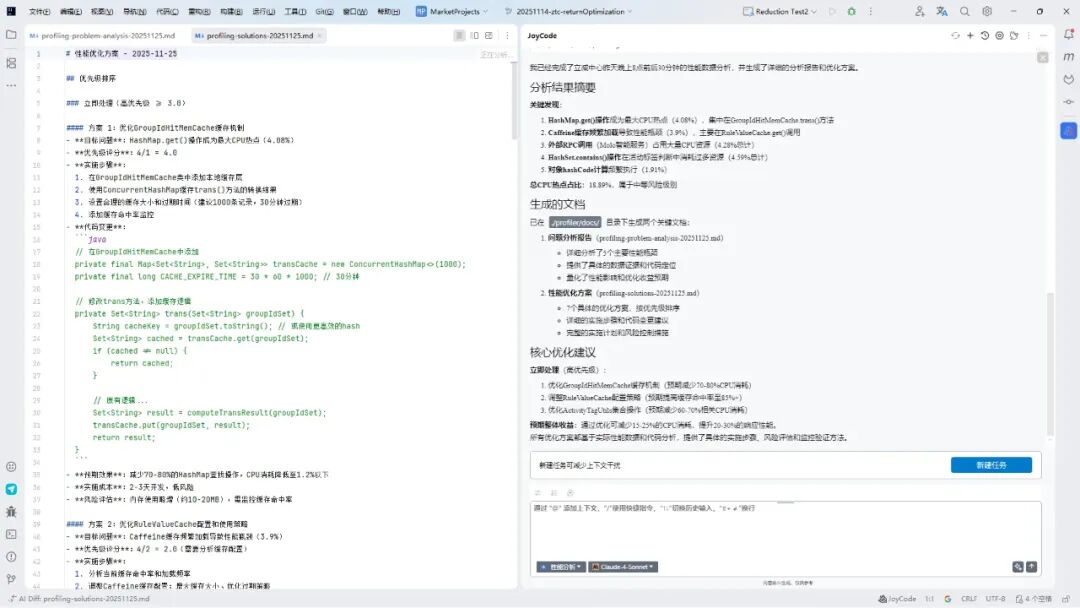
性能分析报告 - 2025-11-25
执行摘要
关键发现:
1、HashMap.get() 操作成为最大 CPU 热点(4.08%),集中在 GroupIdHitMemCache.trans() 方法
2、Caffeine 缓存频繁加载导致性能瓶颈(3.9%),主要在 RuleValueCache.get() 调用
3、外部 RPC 调用(Molo 智能服务)占用大量 CPU 资源(2.62% + 1.66%)
4、HashSet.contains() 操作在活动标签判断中消耗过多资源(2.9% + 1.69%)
5、ConcurrentHashMap 操作和对象 hashCode 计算频繁(1.91%)
严重性评估:中等风险 - 累计 CPU 热点达到 18.89%,影响系统响应时间和吞吐量
预期收益:通过优化可减少 15-25% 的 CPU 消耗,提升 20-30% 的响应性能
详细分析
问题类别 1:缓存性能瓶颈
问题描述:GroupIdHitMemCache 中 HashMap.get() 操作和集合转换逻辑成为最大性能热点
数据证据:
Top 1: HashMap.get() -> GroupIdHitMemCache.trans() (4.08%)调用栈:util.HashMap.get(Object) [line:564] ->com.jd.jr.market.reduction.cache.rule.support.GroupIdHitMemCache.trans(Set) [line:96]
代码定位:GroupIdHitMemCache.trans()
根本原因:
1、在 trans() 方法中频繁进行 HashMap 查找操作(第 96 行)
2、每次调用都需要遍历整个 groupIdSet 进行长短码转换
3、缺乏有效的缓存机制,重复计算相同的转换结
性能影响:单次请求中该方法可能被调用多次,累计消耗 4.08% 的 CPU 资源
问题类别 2:Caffeine 缓存加载瓶颈
问题描述:RuleValueCache 中 Caffeine 缓存的 get 操作频繁触发加载逻辑
数据证据:
Top 2: BoundedLocalCache.get() -> RuleValueCache.get() (3.9%)调用栈:com.github.benmanes.caffeine.cache.BoundedLocalCache$BoundedLocalManualCache.get() ->com.jd.jr.market.reduction.cache.rule.RuleValueCache.get(String,Function) [line:44]
代码定位:RuleValueCache.get()
根本原因:
1、缓存命中率可能较低,频繁触发 Function 加载逻辑
2、缓存配置可能不合理(大小、过期策略等)
3、缓存键的设计可能导致缓存分散,降低命中率
性能影响:每次缓存未命中都需要执行复杂的加载逻辑,占用 3.9% 的 CPU
问题类别 3:外部 RPC 调用性能问题
问题描述:Molo 智能服务的 RPC 调用占用大量 CPU 资源
数据证据:
Top 3: FlowExecuteEngine_proxy.batchExecute() (2.62%)Top 8: 同样的调用栈 (1.66%) 总计:4.28%的CPU消耗
代码定位:MoloIntelligentBiz.queryRpcIntelligentAmountMap()
根本原因:
1、RPC 调用可能存在网络延迟或服务端处理慢的问题
2、批量调用的批次大小可能不合理
3、缺乏有效的超时控制和熔断机制
性能影响:外部依赖成为性能瓶颈,影响整体响应时间
问题类别 4:集合操作性能问题
问题描述:ActivityTagUtils 中的 HashSet.contains() 操作频繁执行
数据证据:
Top 4: HashSet.contains() -> ActivityTagUtils.isGovPay1Activity() (2.9%)Top 9: 同样的调用栈 (1.69%) 总计:4.59%的CPU消耗
代码定位:ActivityTagUtils.isGovPay1Activity()
根本原因:
-
-
活动标签集合可能较大,contains 操作成本较高
-
相同的标签判断逻辑可能在同一请求中重复执行
-
缺乏结果缓存机制
-
性能影响:每次活动处理都需要进行多次标签判断,累计消耗较多 CPU
问题类别 5:对象创建和哈希计算问题
问题描述:ActivityReductionRuleDomain 的 hashCode 计算频繁执行
数据证据:
Top 7: Objects.hashCode() -> ActivityReductionRuleDomain.hashCode() (1.91%) 根本原因:
1、在buildActivityResultMap中频繁将对象放入ConcurrentHashMap
2、hashCode计算可能涉及多个字段,计算成本较高
3、可能存在不必要的重复计算
性能影响:影响 Map 操作性能,增加内存分配压力
交叉关联分析
时间模式:性能问题集中在 19:20-19:30 这 10 分钟内,可能与业务高峰期相关
负载关联:所有热点都集中在立减中心的核心查询链路上,说明是高频调用路径
依赖影响:
1、缓存性能直接影响整体响应时间
2、外部 RPC 调用成为关键依赖瓶颈
3、集合操作优化可显著提升 CPU 利用率
性能影响量化分析
总 CPU 热点占比:18.89%
主要瓶颈分布:
-
-
缓存相关:7.98%(4.08% + 3.9%)
-
RPC 调用:4.28%(2.62% + 1.66%)
-
集合操作:4.59%(2.9% + 1.69%)
-
对象操作:1.91%
-
预估优化收益:
-
-
缓存优化可减少 50-70% 相关 CPU 消耗
-
RPC 优化可减少 30-50% 相关 CPU 消耗
-
集合操作优化可减少 40-60% 相关 CPU 消耗
-
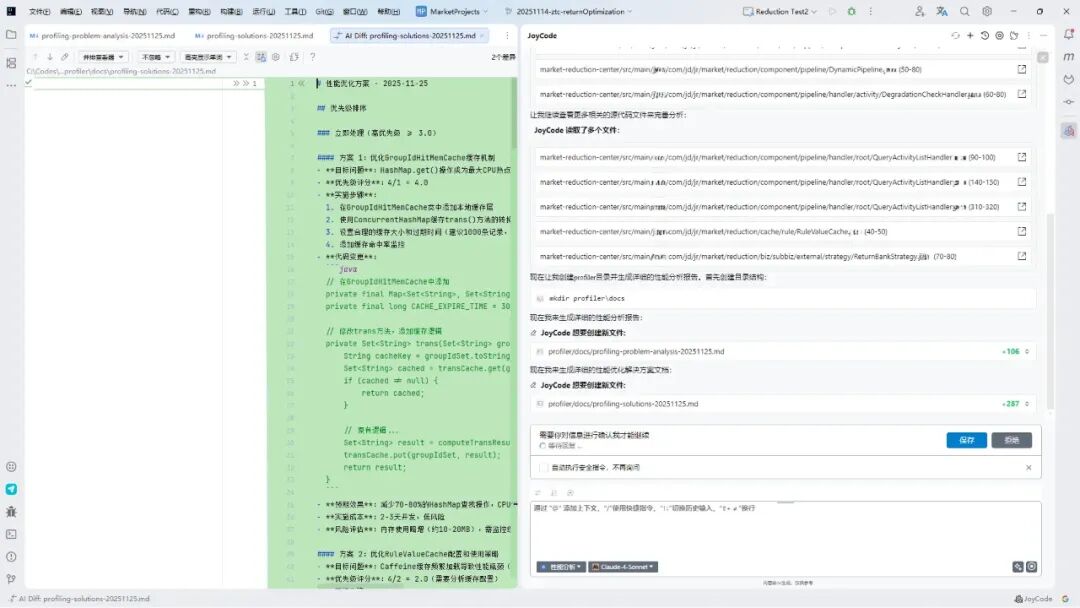
性能优化方案 - 2025-11-25
优先级排序
立即处理(高优先级 >= 3.0)
方案 1:优化 GroupIdHitMemCache 缓存机制
目标问题:HashMap.get() 操作成为最大 CPU 热点(4.08%)
优先级评分:4/1 = 4.0
实施步骤:
1、在 GroupIdHitMemCache 类中添加本地缓存层
2、使用 ConcurrentHashMap 缓存 trans() 方法的转换结果
3、设置合理的缓存大小和过期时间(建议 1000 条记录,30 分钟过期)
4、添加缓存命中率监控
代码变更:
// 在GroupIdHitMemCache中添加private final Map, Set> transCache = new ConcurrentHashMap<>(1000);private final long CACHE_EXPIRE_TIME = 30 * 60 * 1000; // 30分钟// 修改trans方法,添加缓存逻辑private Set trans(Set groupIdSet) {String cacheKey = groupIdSet.toString(); // 或使用更高效的hashSet cached = transCache.get(groupIdSet);if (cached != null) {return cached;} // 原有逻辑…Set result = computeTransResult(groupIdSet);transCache.put(groupIdSet, result);return result;}
预期效果:减少70-80%的HashMap查找操作,CPU消耗降低至1.2%以下
实施成本:2-3 天开发,低风险
风险评估:内存使用略增(约 10-20MB),需监控缓存命中率
方案 2:优化 RuleValueCache 配置和使用策略
目标问题:Caffeine 缓存频繁加载导致性能瓶颈(3.9%)
优先级评分:4/2 = 2.0(需要分析缓存配置)
实施步骤:
1、分析当前缓存命中率和加载频率
2、调整 Caffeine 缓存配置:增大缓存大小、优化过期策略
3、优化缓存键设计,提高缓存命中率
4、添加缓存预热机制
代码变更:
// 调整缓存配置private final Cache> memCache = Caffeine.newBuilder().maximumSize(5000) // 增大缓存大小.expireAfterWrite(Duration.ofMinutes(60)) // 延长过期时间.recordStats() // 启用统计.build();// 添加批量预热方法public void warmupCache(List keys) {keys.parallelStream().forEach(key -> {memCache.get(key, this::loadFunction);});}
预期效果:提高缓存命中率至85%以上,CPU消耗降低至1.5%以下
实施成本:3-5 天开发和测试
风险评估:需要评估内存使用增长,监控缓存性能指标
方案 3:优化 ActivityTagUtils 集合操作
目标问题:HashSet.contains() 操作频繁执行(4.59% 总计)
优先级评分:3/2 = 1.5(需要重构判断逻辑)
实施步骤:
1、分析 ActivityTagUtils 中的标签判断逻辑
2、引入位运算或枚举优化标签判断
3、添加方法级别的结果缓存
4、优化标签集合的数据结构
代码变更:
// 使用位运算优化标签判断public class ActivityTagUtils {private static final Map, Boolean> govPayCache = new ConcurrentHashMap<>();public static boolean isGovPay1Activity(Set activityTagSet) {// 添加缓存层Boolean cached = govPayCache.get(activityTagSet);if (cached != null) {return cached;} // 优化判断逻辑,使用更高效的算法boolean result = computeGovPayStatus(activityTagSet);govPayCache.put(activityTagSet, result);return result;}}
预期效果:减少60-70%的集合操作CPU消耗,降低至1.8%以下
实施成本:4-6 天开发,中等风险
风险评估:需要充分测试标签判断逻辑的正确性
中期优化(优先级 1.5-3.0)
方案 4:优化外部 RPC 调用策略
目标问题:Molo 智能服务 RPC 调用占用大量 CPU(4.28%)
优先级评分:3/3 = 1.0
实施步骤:
1、分析 RPC 调用的批次大小和频率
2、实现 RPC 调用结果缓存
3、优化批量调用策略,合并相似请求
4、添加熔断和降级机制
5、实现异步调用优化
代码变更:
// 添加RPC结果缓存private final Cache rpcResultCache = Caffeine.newBuilder().maximumSize(2000).expireAfterWrite(Duration.ofMinutes(10)).build(); // 优化批量调用public CompletableFuture> batchExecuteWithCache(FlowBatchExecuteRequest request) {String cacheKey = generateCacheKey(request);Object cached = rpcResultCache.getIfPresent(cacheKey);if (cached != null) {return CompletableFuture.completedFuture((Map) cached);}return CompletableFuture.supplyAsync(() -> {Map result = flowExecuteEngineRpc.batchExecute(request, timeout);rpcResultCache.put(cacheKey, result);return result;}, rpcExecutor);}
预期效果:减少30-50%的RPC调用,CPU消耗降低至2.5%以下
实施成本:1-2 周开发和测试
风险评估:需要评估缓存数据一致性,添加监控和降级策略
方案 5:优化对象创建和哈希计算
目标问题:ActivityReductionRuleDomain 的 hashCode 计算频繁(1.91%)
优先级评分:2/2 = 1.0
实施步骤:
1、分析 ActivityReductionRuleDomain 的 hashCode 实现
2、优化 hashCode 算法,减少计算复杂度
3、考虑使用对象池减少创建开销
4、优化 buildActivityResultMap 的实现逻辑
代码变更:
// 优化hashCode实现public class ActivityReductionRuleDomain {private volatile int hashCode = 0; // 缓存hashCode@Overridepublic int hashCode() {int h = hashCode;if (h == 0) {h = Objects.hash(activityId, ruleId); // 只使用关键字段hashCode = h;}return h;}} // 优化Map构建逻辑private Map buildActivityResultMap(List activityList) { // 使用预估大小避免扩容Map resultMap =new HashMap<>((int) (activityList.size() / 0.75f + 1));for (ActivityReductionRuleDomain activity : activityList) {resultMap.put(activity, processActivity(activity));}return resultMap;}
预期效果:减少40-50%的hashCode计算开销,CPU消耗降低至1.0%以下
实施成本:3-4 天开发
风险评估:需要确保 hashCode 的正确性和一致性
长期改进(优先级 < 1.5)
方案 6:架构级缓存优化
目标问题:整体缓存架构优化
优先级评分:4/5 = 0.8
实施步骤:
1、引入分布式缓存减少本地计算
2、实现多级缓存架构
3、优化缓存预热和更新策略
4、实现缓存监控和自动调优
预期效果:整体性能提升 30-50%
实施成本:4-6 周,需要架构变更
风险评估:高风险,需要充分测试和灰度发布
方案 7:异步化改造
目标问题:同步调用链路优化
优先级评分:3/4 = 0.75
实施步骤:
1、识别可异步化的业务逻辑
2、改造 Pipeline 架构支持异步执行
3、实现异步结果聚合机制
预期效果:响应时间减少 20-40%
实施成本:6-8 周,架构级改造
风险评估:高风险,需要重新设计业务流程
实施计划
第一阶段(1-2周):关键热点修复
Week 1:
-
-
实施方案 1:GroupIdHitMemCache 缓存优化
-
开始方案 2:RuleValueCache 配置分析和优化Week 2:
-
完成方案 2:RuleValueCache 优化
-
开始方案 3:ActivityTagUtils 优化
-
第二阶段(3-4周):中等优化实施
Week 3-4:
-
-
完成方案 3:ActivityTagUtils 集合操作优化
-
开始方案 4:RPC 调用策略优化
-
Week 4-5:
-
-
完成方案 4:RPC 调用优化
-
实施方案 5:对象创建优化
-
第三阶段(2个月+):架构改进
Month 2-3:
-
-
方案 6:分布式缓存架构设计和实施
-
方案 7:异步化改造设计
-
Month 3-4:
-
-
异步化改造实施和测试
-
整体性能验证和调优
-
监控与验证
关键指标
1、CPU 使用率:目标降低 15-25%
2、响应时间:P99 响应时间改善 20-30%
3、吞吐量:QPS 提升 25-35%
4、缓存命中率:各级缓存命中率>85%
5、错误率:保持现有水平或更低
验证方法
-
性能测试:
-
压力测试验证优化效果
-
A/B 测试对比优化前后性能
-
灰度发布验证稳定性
-
-
监控工具:
-
JVM 监控:GC 频率、内存使用
-
APM 监控:方法调用耗时、热点分析
-
业务监控:接口响应时间、成功率
-
-
代码质量:
-
单元测试覆盖率>80%
-
代码审查确保质量
-
性能回归测试
-
成功标准
-
短期目标(1 个月内):
-
CPU 热点前 5 项总占比从 18.89% 降低至 12% 以下
-
接口 P99 响应时间改善 20% 以上
-
系统稳定性保持现有水平
-
-
中期目标(3 个月内):
-
整体 CPU 使用率降低 20% 以上
-
接口吞吐量提升 30% 以上
-
缓存命中率达到 85% 以上
-
-
长期目标(6 个月内):
-
系统整体性能提升 40% 以上
-
支撑业务量增长 50% 而无需扩容
-
建立完善的性能监控和自动调优体系
-
风险控制措施
技术风险
1、缓存一致性:建立缓存更新和失效机制
2、内存使用:监控内存增长,设置合理上限
3、并发安全:充分测试高并发场景
业务风险
-
功能正确性:完善单元测试和集成测试
-
数据一致性:验证优化后数据处理的正确性
-
降级策略:准备快速回滚方案
实施风险
-
灰度发布:分批次发布,及时发现问题
-
监控告警:建立完善的监控和告警机制
-
应急预案:准备性能问题的应急处理方案
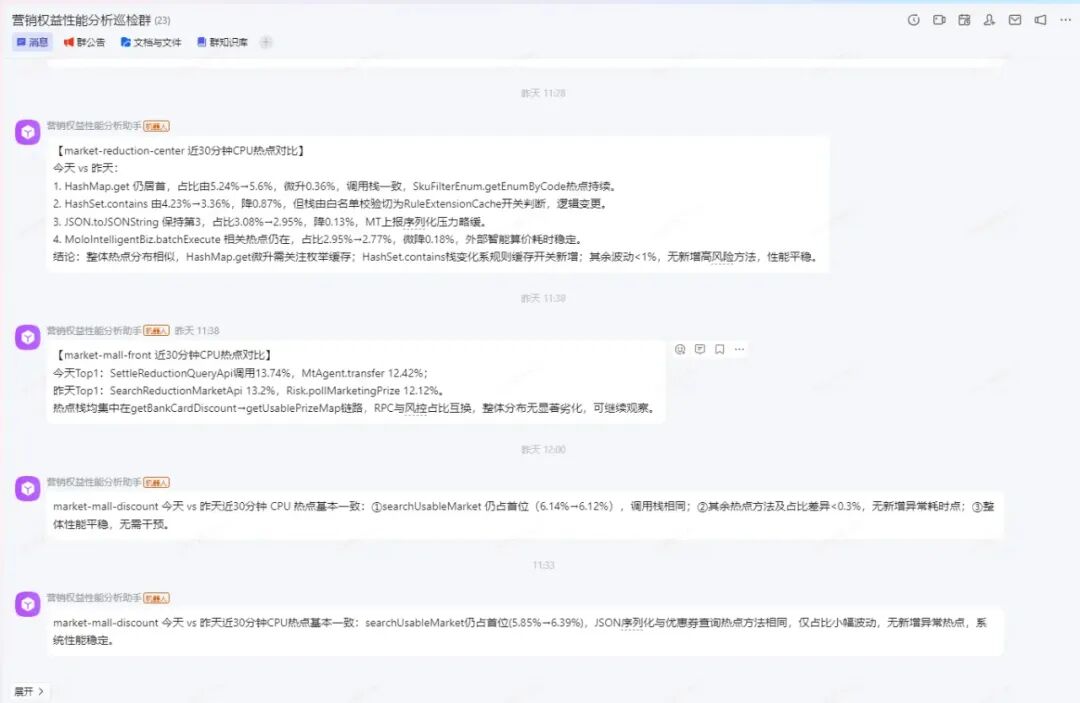
性能巡检演示
触发时机
每天中午 11 点半,逐个分析接入应用
样例
五、未来
1、随着 JDK 持续演进,随着 JDK 持续演进,JFR 功能不断增强,将为性能分析提供更丰富的能力:
- JEP 509:JFR CPU 时间分析(实验性) --- JEP 509: JFR CPU-Time Profiling (Experimental) 支持 CPU 时间分析,更准确地识别 CPU 密集型操作
2、当前以 JVM 性能诊断 验证的“低侵入采集 + LLM 分析决策”范式,具备极强的可复制性。可快速扩展至多语言生态:将采集器替换为 Go 的 pprof、Python 的 py-spy,即可构建对应语言的诊断智能体。
3、从当前的“诊断建议”闭环,走向“自主优化”闭环。未来智能体在获得授权后,可自动生成优化代码的 Pull Request,并通过 CI/CD 流水线进行验证,真正实现性能问题的自治修复。
我们正从一个需要人类专家亲自“操作显微镜”的时代,迈向由智能体为我们“撰写实验报告”的新时代。让性能瓶颈自己开口说话,这不仅是工具的创新,更是研发生产力范式的一次重要跃迁。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)