Forensic Self-Descriptions 文章阅读
这篇文章提出了一种名为“取证自描述”的新方法,用于检测和溯源AI生成的图像。该方法的核心思想是,无论是相机还是AI生成器,都会在图像中留下独特的、像素级的统计“取证显微结构”。文章通过一种仅使用真实图像的自监督过程,学习一组多样化的预测滤波器来提取包含这些显微结构的残差。然后,通过一个紧凑的参数模型对这些多尺度残差进行联合建模,其参数构成了每张图像唯一的“取证自描述”。
·
CVPR 2025:Forensic Self-Descriptions Are All You Need for Zero-Shot Detection, Open-Set Source Attribution, and Clustering of AI-generated Images
| 作者 | Tai D. Nguyen, Aref Azizpour, Matthew C. Stamm Drexel University Philadelphia, PA, USA |
|---|---|
| 状态 | 已读完 |
| 简介 | 这篇文章提出了一种名为“取证自描述”的新方法,用于检测和溯源AI生成的图像。该方法的核心思想是,无论是相机还是AI生成器,都会在图像中留下独特的、像素级的统计“取证显微结构”。文章通过一种仅使用真实图像的自监督过程,学习一组多样化的预测滤波器来提取包含这些显微结构的残差。然后,通过一个紧凑的参数模型对这些多尺度残差进行联合建模,其参数构成了每张图像唯一的“取证自描述”。 |
Method
1.取证显微结构提取
- 图像I建模为场景内容S与取证显微结构Ψ之和:I(x,y)=S(x,y)+Ψ(x,y)
- 使用一系列K个不同的预测滤波器来产生K个独特的残差:r_k(x,y)=I(x,y)-Ŝ_k(x,y)=Ψ_k(x,y)+ε_k(x,y) 【用k个不同的预测滤波器,根据一个像素点周围不同的像素点,去猜测原本的图像到底是什么样子,用真实图片测试】
- 为了学习滤波器权重w,需要最小化所有残差的总能量,其损失项为L_E 。【最小化损失让模型最贴近原图】为防止滤波器冗余,引入了一种新颖的频谱多样性正则化项,鼓励滤波器尽可能线性独立,以最大化捕获信息的多样性 。该正则化项通过构建权重矩阵W,进行奇异值分解,并对奇异值进行惩罚来实现【从不同的角度提取,奇异值尽可能大】 。
- 最终,结合能量损失和多样性正则化项,得到学习预测滤波器的总体目标函数 。需要强调的是,权重w仅从由真实图像组成的训练集中学习。
2.取证自描述
- 在多个尺度上对残差进行建模。尺度l的残差定义为原始残差的下采样 。【多尺度准备,做成几个不同版本,比如“原图,缩小一半,再缩小一半”,可以看细节也可以看整体纹路】
- 使用线性卷积滤波器φ_k对每个残差r_k在尺度l上进行建模 。【还是去预测中心点自己的值是多少】
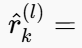
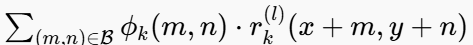
- 一起学习相互配合,最终总结出一个一张图片的参数集合就是这张图片独一无二的“取证自描述”。
应用
- 零样本合成图像检测
方法是在训练阶段,只用大量真实图像的“取证自描述”来训练一个高斯混合模型,以此建模真实图像描述的分布。在测试时,计算待测图像的自描述属于这个“真实分布”的可能性。如果可能性低于设定的阈值,就判定为合成图像。其依据是,真实图像与合成图像的取证自描述存在显著差异。
- 开放集源归属
该方法为每个已知的生成源分别建立其图像“取证自描述”的高斯混合模型。归属时,计算待测图像的自描述属于每个源模型的似然,并选择似然最高的源作为候选来源。如果该最高似然低于拒绝阈值,则判定图像来自未知源;否则接受该候选来源 。
- 无监督聚类
该方法直接提取所有图像的“取证自描述”作为特征向量,然后对其应用K-means等聚类算法,根据描述的相似性对图像进行分组。其有效性源于取证自描述能有效捕捉取证显微结构,使得来自同一源的图像在特征空间中自然聚集 。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)