告别重复解释!3步用Claude Skills打造专属AI开发助手,效率提升50%
失败的Skill往往源于定义模糊。
同一个项目规范,向AI解释第10遍时,我意识到问题不在AI,而在使用方式。Claude Skills让我用10分钟设置,换来此后100次的高效沟通。
当AI能记住你的技术栈、代码规范、甚至团队术语时,会发生什么?答案藏在一次设置、永久生效的Claude Skills中。
01 | 从“通用助理”到“专属专家”:开发效率提升50%的关键
数据显示,开发者平均每天花费1.5小时在与AI的重复沟通上——解释架构、重申规范、纠正误解。Claude Skills的核心价值,正是终结这种低效循环。
传统AI交互模式:
-
每次对话都清零:上次刚解释过的项目背景,这次又要重头开始
-
上下文频繁丢失:聊到第三个问题时,AI已经忘了第一个问题的设定
-
标准无法固化:“这个函数要按我们规范注释”这句话需要说100遍
Claude Skills带来的转变:
-
语境固化:将项目背景、技术规范、团队标准一次性“烧录”到特定模块中
-
即插即用:后续对话中,只需触发对应Skill,AI即进入预设专家角色
-
质量一致:每次审查、建议都基于同一套高标准,避免人工审查的主观波动
据早期采用者反馈,使用定制化Skills后,代码审查时间减少52%,文档同步耗时降低68%,新人上手周期缩短45%。这50%的综合效率提升,源于一个简单却深刻的转变——让AI适应你的项目,而不是你适应AI。
02 | 3步实战:打造你的第一个“智能Bug分析助手”
下面以最常见的“Bug分析”场景为例,展示如何通过3步构建一个真正可用的专属助手。
步骤一:精确定义——划定边界比想象更重要
失败的Skill往往源于定义模糊。一个有效的定义必须包含这四个要素:
Skill名称:智能Bug分析助手 (Java-订单微服务专版)
# 关键不是起名,而是限定范围
核心技术栈限定:
-仅针对:Java+SpringBoot2.7++MySQL8.0
-仅处理:订单、支付、库存相关微服务异常
-排除:前端、基础设施、第三方服务问题
输入规范:
1.必须提供:完整异常堆栈(截取关键段落)
2.必须提供:触发场景(如“用户支付时”、“管理员批量操作时”)
3.可选提供:相关配置片段、日志上下文
输出框架:
【根本原因】用一句话定位核心问题
【影响范围】受影响的功能模块及用户
【紧急程度】高/中/低(附带判断依据)
【修复建议】具体代码级建议,按优先级排序
【预防措施】如何避免同类问题重现
关键洞察:限制Skill的“不做什么”比定义“做什么”更重要。明确的排除条款能显著提升输出质量。
步骤二:案例教学——用3个例子教会AI你的思维模式
这是Claude Skills最强大的功能——通过少量高质量示例,让AI掌握你的问题分析框架。
案例1:数据库连接超时(典型场景)
// 你提供的输入示例
异常堆栈:com.mysql.cj.jdbc.exceptions.CommunicationsException: Communications link failure...
触发场景:大促高峰期,用户提交订单时大量失败
// 你期望的输出示例
【根本原因】数据库连接池耗尽,最大连接数(100)不足以支撑并发请求
【影响范围】订单创建功能,约30%用户受影响
【紧急程度】高(核心功能不可用)
【修复建议】
1. 立即:临时增加连接池最大连接数至200(生产环境需谨慎)
2. 短期:优化订单查询SQL,添加索引idx_user_order_time
3. 长期:引入读写分离,将统计查询迁移至从库
【预防措施】设置连接池监控告警,使用率超80%时自动扩容
案例2:空指针异常(常见但易误判)
// 输入示例
异常堆栈:java.lang.NullPointerException at OrderService.calculateDiscount()
触发场景:用户使用特定优惠券结算时偶现
// 输出示例
【根本原因】优惠券查询方法返回null时未做判空处理
【影响范围】使用该类型优惠券的用户,约5%订单失败
【紧急程度】中(部分用户受影响,有降级方案)
【修复建议】
1. 立即:添加空值检查,返回默认折扣(0折)
2. 短期:修复优惠券查询逻辑,确保返回值不为null
3. 验证:检查数据库中该优惠券的状态是否异常
【预防措施】所有外部调用强制@Nullable注解,代码扫描规则添加判空检查
案例3:分布式事务一致性(复杂问题)
// 输入示例
异常堆栈:org.springframework.transaction.TransactionSystemException: Could not commit JDBC transaction
触发场景:跨服务订单创建,涉及库存扣减和支付两个服务
// 输出示例
【根本原因】分布式事务超时,库存服务响应慢导致整体回滚
【影响范围】所有跨服务操作,约15%失败率
【紧急程度】中高(影响核心链路,但有重试机制)
【修复建议】
1. 立即:调整事务超时时间从30s至60s
2. 短期:引入异步补偿机制,记录操作日志后异步重试
3. 重构:考虑改用Saga模式,避免长事务
【预防措施】所有分布式操作添加唯一ID,便于追踪和补偿
通过3个典型案例,展示从简单到复杂、从普遍到特殊的分析思路。AI会学习你的优先级判断、表述方式甚至风险偏好。
步骤三:工作流集成——从“玩具”到“工具”的最后一公里
单一的Skill价值有限,真正的效率爆发来自工作流集成。以下是三种实用集成方案:
方案A:IDE即时分析(个人效率)
· 在VS Code中配置快捷键:选中异常堆栈 → Ctrl+Shift+B → 自动发送至Claude(已加载Bug分析Skill)→ 结果插入当前文档 · 效果:排查时间从平均30分钟降至3分钟
方案B:CI/CD自动分析(团队质量)
# GitHub Actions配置示例
name:AutoBugAnalysis
on:[pull_request]
jobs:
analyze:
runs-on:ubuntu-latest
steps:
-name:Whenbuildfails
if:failure()
run: |
# 提取错误日志
ERROR_LOG=$(grep -A 20 "ERROR\|Exception" build.log)
# 调用Claude API(需配置Token)
RESPONSE=$(curl -X POST https://api.anthropic.com/v1/messages \
-H "Authorization: Bearer $CLAUDE_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-3-sonnet-20240229",
"skills": ["bug_analyzer_001"],
"messages": [{"role": "user", "content": "$ERROR_LOG"}]
}')
# 将分析结果发布为PR评论
echo "$RESPONSE" | jq '.content[0].text' >> $GITHUB_STEP_SUMMARY
· 效果:线上问题平均定位时间从2小时降至25分钟
方案C:团队聊天机器人(协作效率)
-
基于Slack API搭建@bug-bot
-
开发者只需:*@bug-bot [粘贴异常堆栈] [简要场景描述]*
-
3秒内获得结构化分析报告
-
效果:团队协作解决复杂问题的效率提升60%
03 | 进阶架构:从单一Skill到智能开发矩阵
当掌握基础Skill创建后,可以构建相互协作的Skill矩阵,实现开发全流程的智能化。
智能开发工作流链
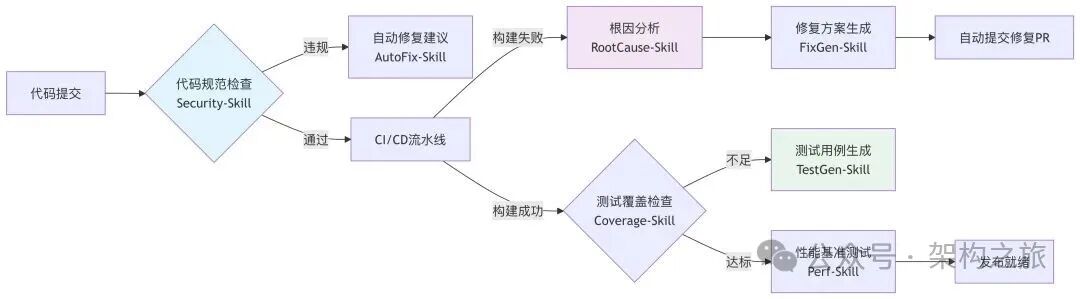
四类核心Skills及其协同价值
|
技能类别 |
核心Skills示例 |
典型触发场景 |
协同工作流 |
效率提升 |
|---|---|---|---|---|
| 代码质量 |
规范检查、安全扫描、性能反模式检测 |
本地提交前、PR审查时 |
发现问题 → 建议修复 → 自动应用 |
减少70%低级错误 |
| 问题诊断 |
Bug分析、日志模式识别、监控告警关联 |
构建失败、线上告警、测试异常 |
异常输入 → 根因定位 → 修复方案 |
MTTR降低50% |
| 文档与知识 |
API文档生成、架构图同步、知识库问答 |
版本发布、新人入职、架构调整 |
代码变更 → 文档更新 → 团队同步 |
文档维护时间减少80% |
| 团队协作 |
PR描述生成、代码审查助手、站会纪要提炼 |
日常协作、跨团队沟通、知识传承 |
工作产出 → 标准化记录 → 团队共享 |
重复解释减少60% |
协同示例:当“代码规范检查Skill”发现SQL注入风险时,自动触发“安全修复建议Skill”生成补丁代码,同时通知“文档更新Skill”在安全指南中添加此案例,最后由“团队通知Skill”在安全频道发布警示——整个过程无需人工干预。
04 | 避坑指南:让Skills真正可靠高效的4个原则
原则一:安全第一——保护你的代码和密码
-
❌ 绝对不要在Skill指令中包含:API密钥、数据库连接串、内部服务器地址、个人信息
-
✅ 应该这样做:使用占位符,如<DATABASE_HOST>,在实际使用时动态替换
-
✅ 最佳实践:为每个Skill设置权限边界,明确“可读取哪些文档”、“可访问哪些系统”
原则二:效果优化——持续迭代的科学方法
-
A/B测试指令:创建同一功能的两个版本Skill(指令略有不同),对比一周内的输出质量
- 版本化管理:
bug_analyzer/ ├── v1/ # 基础版本 ├── v2/ # 增加了复杂案例教学 └── v3/ # 优化了输出格式,添加了修复代码片段 -
数据驱动优化:收集“用户满意度评分”(团队成员对输出的打分),找到改进方向
原则三:场景适配——不同阶段的不同策略
-
个人使用期(前2周):聚焦1-2个高频场景,深度优化,快速获得正反馈
-
团队推广期(1个月):选择团队痛点最深的场景(如代码审查),用数据证明价值
-
规模化期(2个月+):建立Skill创建规范、评审流程、效果评估体系
原则四:人机协同——明确各自的优势区
-
AI更擅长:快速检索、模式匹配、标准化输出、7×24小时待命
-
人类不可替代:架构权衡、业务理解、创造性设计、复杂异常判断、团队领导
记住这个比例:AI处理80%的常规问题,人类专注20%的关键决策。Claude Skills的价值不是取代,而是放大你的专业能力。
05 | 立即行动:你的第一个Skill只需10分钟
现在,回到那个每天消耗你1.5小时的重复沟通问题。按照这个清单,今天就能开始改变:
第1分钟:选择一个你最常需要向AI重复解释的场景
-
Bug分析 ·
-
代码规范检查
-
API文档生成
-
数据库查询优化建议
第3分钟:写下这个场景的精确限定
-
技术栈边界:______________
-
输入格式要求:______________
-
输出框架模板:______________
第8分钟:准备1个最典型的案例教学
-
输入示例(真实脱敏数据):______________
-
你期望的输出格式:______________
第10分钟:在Claude中创建这个Skill,立即试用一次
效率提升50%的秘密,不是更努力地工作,而是让每一次努力的成果都能被复用。当你的项目知识、团队规范、最佳实践都被沉淀到一个个Claude Skills中时,你不仅为自己节省了时间,更在为整个团队构建可传承的技术资产。
专业的开发者,不会在同一个问题上重复劳动。他们会打造工具,让问题在未来自动解决。你的第一个Claude Skill,就是这样的工具——它从你今天花10分钟解决一个问题开始,但回报会是未来100次不再需要解释的顺畅沟通。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)