PaddleOCR系列——基础环境安装及快速使用
PaddleOCR 是百度飞桨 (PaddlePaddle) 团队开发的开源 OCR 工具库,致力于打造丰富、领先且实用的 OCR 解决方案,打通数据准备、模型训练、压缩和推理部署全流程,是目前中文及多语言场景下最受欢迎的 OCR 工具之一,接下来进行介绍。相关参考连接:PP飞桨官网(深度学习框架):开始使用_飞桨-源于产业实践的开源深度学习平台PaddleOCR github:PaddleOCR
PaddleOCR 是百度飞桨 (PaddlePaddle) 团队开发的开源 OCR 工具库,致力于打造丰富、领先且实用的 OCR 解决方案,打通数据准备、模型训练、压缩和推理部署全流程,是目前中文及多语言场景下最受欢迎的 OCR 工具之一,接下来进行介绍。
相关参考连接:
PP飞桨官网(深度学习框架):
PaddleOCR github:
PaddleOCR/readme/README_cn.md at main · PaddlePaddle/PaddleOCR
PaddleOCR 官方文档:
PaddleX github:
GitHub - PaddlePaddle/PaddleX: All-in-One Development Tool based on PaddlePaddle
PaddleX 官方文档:
PP飞桨 AlStudio应用中心(在线使用官方OCR):
https://aistudio.baidu.com/application/center/app
一、环境管理工具
使用python,这边推荐包管理工具Anaconda,我使用的是Miniconda ,是 Anaconda 的轻量级版本,安装及相关使用命令参考链接:
Miniconda安装与使用_miniconda用法-CSDN博客
二、PP飞桨框架安装
PaddlePaddle(中文名:飞桨)是由百度公司自主研发并开源的深度学习框架,是国内首个开源、功能完备、工业级可用的深度学习平台,同时也是 PaddleOCR 的底层核心依赖与技术支撑——PaddleOCR 所有的模型训练、推理计算、硬件适配等能力,均基于 PaddlePaddle 框架实现。要使用PaddleOCR需要先安装百度的PP飞桨框架paddlepaddle。
这里官方有三种方式:Docker、pip、wheel 包(windows支持)
我使用的是pip安装,其他安装方式需要自行研究。
1、安装PP飞桨框架
PP飞桨官网(深度学习框架):
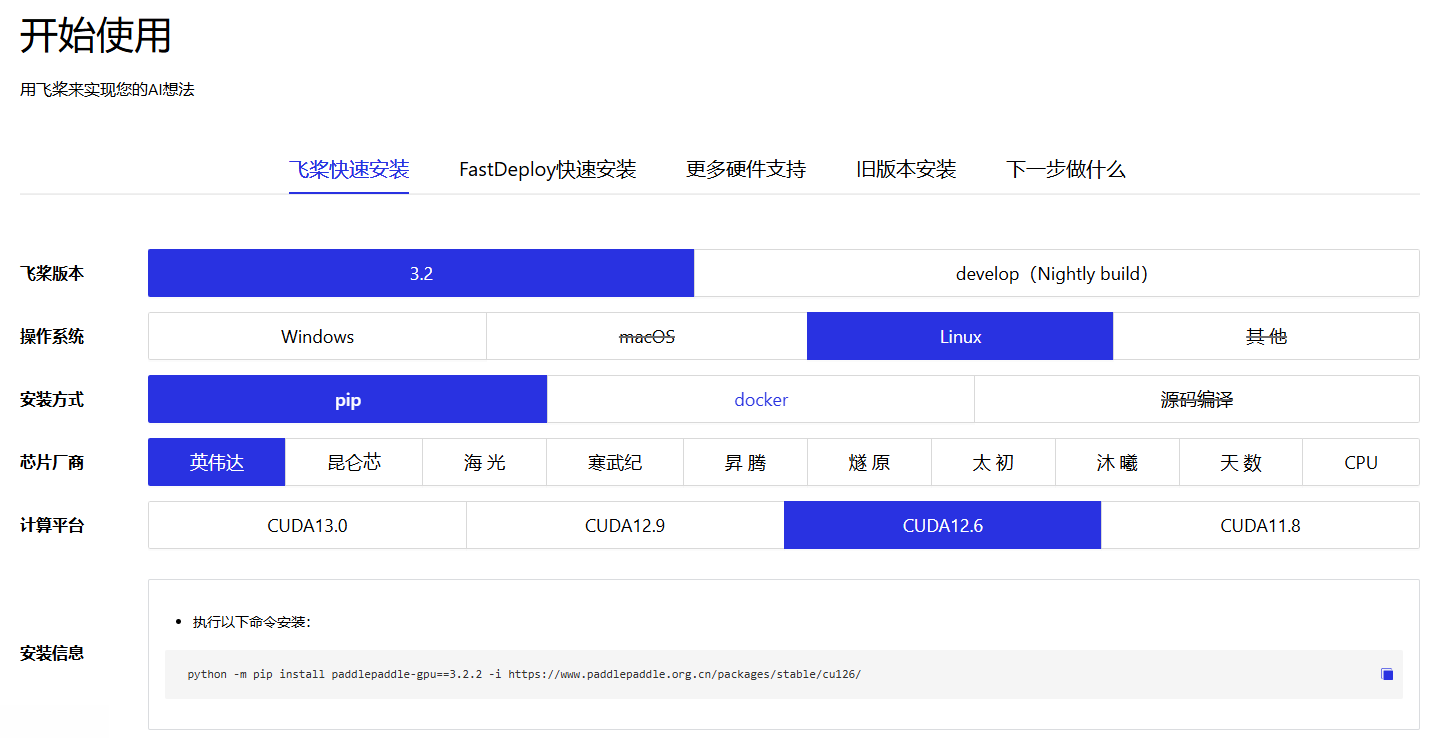
python -m pip install paddlepaddle-gpu==3.2.2 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/❗ 注意:无需关注物理机上的 CUDA 版本,只需关注显卡驱动程序版本。更多飞桨 Wheel 版本请参考飞桨官网。
安装完成后,使用以下命令可以验证 PaddlePaddle 是否安装成功:
python -c "import paddle; print(paddle.__version__)"如果已安装成功,将输出以下内容:
3.2.2卸载
请使用以下命令卸载 PaddlePaddle:
CPU 版本的 PaddlePaddle:
python -m pip uninstall paddlepaddleGPU 版本的 PaddlePaddle:
python -m pip uninstall paddlepaddle-gpu2、安装 PaddleOCR
如果只希望使用 PaddleOCR 的推理功能,请参考 安装推理包;如果希望进行模型训练、导出等,请参考 安装训练依赖。在同一环境中安装推理包和训练依赖是允许的,无需进行环境隔离。
2.1 安装推理包
从 PyPI 安装最新版本 PaddleOCR 推理包:
# 只希望使用基础文字识别功能(返回文字位置坐标和文本内容)
python -m pip install paddleocr# 希望使用文档解析、文档理解、文档翻译、关键信息抽取等全部功能(推荐)
python -m pip install "paddleocr[all]"或者从源码安装(默认为开发分支):
# 只希望使用基础文字识别功能(返回文字位置坐标和文本内容)
python -m pip install "paddleocr@git+https://github.com/PaddlePaddle/PaddleOCR.git"# 希望使用文档解析、文档理解、文档翻译、关键信息抽取等全部功能 #
python -m pip install "paddleocr[all]@git+https://github.com/PaddlePaddle/PaddleOCR.git"除了上面演示的 all 依赖组以外,PaddleOCR 也支持通过指定其它依赖组,安装部分可选功能。PaddleOCR 提供的所有依赖组如下:
| 依赖组名称 | 对应的功能 |
|---|---|
doc-parser |
文档解析,可用于提取文档中的表格、公式、印章、图片等版面元素,包含 PP-StructureV3 等模型方案 |
ie |
信息抽取,可用于从文档中提取关键信息,如姓名、日期、地址、金额等,包含 PP-ChatOCRv4 等模型方案 |
trans |
文档翻译,可用于将文档从一种语言翻译为另一种语言,包含 PP-DocTranslation 等模型方案 |
all |
完整功能 |
通用 OCR 产线(如 PP-OCRv3/v4/v5)、文档图像预处理产线的功能无需安装额外的依赖组即可使用。除了这两条产线外,每一条产线属于且仅属于一个依赖组。在各产线的使用文档中可以了解产线属于哪一依赖组。对于单功能模块,安装任意包含该模块的产线对应的依赖组后即可使用相关的基础功能。
2.2 安装训练依赖
要进行模型训练、导出等,需要首先将仓库克隆到本地:
# 推荐方式
git clone https://github.com/PaddlePaddle/PaddleOCR# (可选)切换到指定分支
git checkout release/3.2# 如果因为网络问题无法克隆成功,也可选择使用码云上的仓库:
git clone https://gitee.com/paddlepaddle/PaddleOCR# 注:码云托管代码可能无法实时同步本 GitHub 项目更新,存在3~5天延时,请优先使用推荐方式。
#再不行,挂梯子,进GitHub,下载压缩包吧,放到开发环境中。
三、快速测试
1、命令行使用
PP-OCRv5
paddleocr ocr -i ./general_ocr_002.png --use_doc_orientation_classify False --use_doc_unwarping False --use_textline_orientation FalsePP-OCRv5文本检测模块
paddleocr text_detection -i ./general_ocr_001.pngPP-OCRv5文本识别模块
paddleocr text_recognition -i ./general_ocr_rec_001.pngPP-StructureV3
paddleocr pp_structurev3 -i ./pp_structure_v3_demo.png --use_doc_orientation_classify False --use_doc_unwarping False2、Python脚本使用
下面是简单脚本使用,输入是图片,可以自己再修改。
PP-OCRv5
from paddleocr import PaddleOCR
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False) # 文本检测+文本识别
# ocr = PaddleOCR(use_doc_orientation_classify=True, use_doc_unwarping=True) # 文本图像预处理+文本检测+方向分类+文本识别
# ocr = PaddleOCR(use_doc_orientation_classify=False, use_doc_unwarping=False) # 文本检测+文本行方向分类+文本识别
# ocr = PaddleOCR(
# text_detection_model_name="PP-OCRv5_mobile_det",
# text_recognition_model_name="PP-OCRv5_mobile_rec",
# use_doc_orientation_classify=False,
# use_doc_unwarping=False,
# use_textline_orientation=False) # 更换 PP-OCRv5_mobile 模型
result = ocr.predict("./general_ocr_002.png")
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")PP-OCRv5文本检测模块
from paddleocr import TextDetection
model = TextDetection()
output = model.predict("general_ocr_001.png")
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/res.json")PP-OCRv5文本识别模块
from paddleocr import TextRecognition
model = TextRecognition()
output = model.predict(input="general_ocr_rec_001.png")
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/res.json")PP-StructureV3
from paddleocr import PPStructureV3
pipeline = PPStructureV3(
use_doc_orientation_classify=False,
use_doc_unwarping=False)
output = pipeline.predict(
input="./pp_structure_v3_demo.png",
)
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")PP-StructureV3_PDF
from pathlib import Path
from paddleocr import PPStructureV3
import json
input_file = "/xxx/aaa.pdf"
output_path = Path("/xxx/output")
pipeline = PPStructureV3(
device="gpu"
)
# 处理 PDF
output = pipeline.predict(input=input_file)
# 收集所有页面的 Markdown 内容和 JSON 数据
markdown_list = []
markdown_images = []
json_list = [] # 用于收集每个页面的JSON数据
for idx, res in enumerate(output): # 用enumerate获取页面索引(从0开始)
# 处理Markdown
md_info = res.markdown
markdown_list.append(md_info)
markdown_images.append(md_info.get("markdown_images", {}))
# 1. 保存单个页面的JSON(按页面索引命名,如page_0.json)
page_json_path = output_path / f"page_{idx}.json"
page_json_path.parent.mkdir(parents=True, exist_ok=True) # 确保目录存在
res.save_to_json(save_path=str(page_json_path)) # 保存当前页面的JSON
# 2. 收集当前页面的JSON数据(用于后续合并)
json_data = res.json # 获取JSON格式的数据(字典类型)
json_list.append(json_data)
# 合并所有页面的 Markdown 内容(原功能保留)
markdown_texts = pipeline.concatenate_markdown_pages(markdown_list)
mkd_file_path = output_path / f"{Path(input_file).stem}.md"
with open(mkd_file_path, "w", encoding="utf-8") as f:
f.write(markdown_texts)
# 保存图像文件(原功能保留)
for item in markdown_images:
if item:
for path, image in item.items():
file_path = output_path / path
file_path.parent.mkdir(parents=True, exist_ok=True)
image.save(file_path)
# 3. 保存合并后的JSON(所有页面数据整合到一个文件)
merged_json_path = output_path / f"{Path(input_file).stem}_merged.json"
with open(merged_json_path, "w", encoding="utf-8") as f:
# 合并逻辑:将每个页面的JSON数据放在一个列表中,方便查看
json.dump(
{"total_pages": len(json_list), "pages": json_list},
f,
ensure_ascii=False, # 支持中文显示
indent=2 # 格式化输出,便于阅读
)
print(f"处理完成!结果保存在:{output_path}")

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)