LangChain + Ollama 高级实战:基于 qwen2.5:7b 的本地大模型应用(完整可运行示例)
摘要:本文介绍如何利用 Qwen2.5:7b 大模型结合 LangChain 和 Ollama 构建本地化AI助手。该方案支持多轮对话、流式输出和Token控制,适用于企业内网、开发者工具等场景。文章详细说明了环境配置、模型参数优化(如temperature=0.2提升稳定性)、流式输出实现,并提供了完整的Python代码示例,兼容最新LangChain版本。关键亮点包括动态上下文管理、实时交互体
在当前大模型本地化部署的浪潮中,Qwen2.5:7b 凭借其出色的中文能力、代码理解力和结构化输出稳定性,成为私有化场景下的首选模型之一。结合 LangChain 与 Ollama,我们可以在普通开发机上构建一个功能完整、响应流畅的本地 AI 助手。
本文将带你从零搭建一个支持多轮对话、上下文记忆、流式输出、Token 限制控制的完整应用,并提供可直接运行的代码,适用于企业内网助手、开发者 Copilot、自动化脚本生成等场景。
一、为什么选择 qwen2.5:7b?
qwen2.5:7b 是目前本地部署性价比极高的开源大语言模型之一,具备以下优势:
- 多语言能力强:对中文和英文均有良好支持;
- 专业领域表现优秀:在代码生成、系统运维、架构设计等任务上表现出色;
- 硬件适配性强:7B 参数规模可在 CPU 或单张消费级 GPU 上流畅运行;
- 结构化输出能力强:对 JSON、指令遵循、工具调用等有较好原生支持。
👉 非常适合:LangChain + Ollama + 私有部署 的组合方案。
二、环境准备(前置条件)
1. 拉取模型
确保已安装 Ollama,然后执行:
ollama pull qwen2.5:7b
验证是否成功:
ollama list
应能看到 qwen2.5:7b 出现在列表中。
2. 安装 Python 依赖
pip install -U langchain langchain-ollama tiktoken
注意:LangChain 0.2+ 版本已重构内存模块,传统
ConversationTokenBufferMemory不再可用。本文采用更现代、兼容性更强的手动上下文管理方式。
三、ChatOllama 初始化(qwen2.5:7b 专用参数)
标准初始化(推荐基线)
from langchain_ollama import ChatOllama
llm = ChatOllama(
model="qwen2.5:7b",
base_url="http://localhost:11434",
temperature=0.2,
top_p=0.9,
top_k=40,
repeat_penalty=1.1,
streaming=True, # 启用流式输出
)
参数配置说明
| 参数 | 推荐值 | 原因 |
|---|---|---|
temperature |
0.2 | Qwen 指令遵循能力强,低温提升输出稳定性 |
top_p |
0.9 | 保留一定创造性,同时避免发散 |
repeat_penalty |
1.1 | 抑制偶发的重复输出问题 |
top_k |
40 | 对代码/结构化文本生成更友好 |
✅ 适用场景:代码生成、运维问答、Agent 决策等高精度任务。
四、Streaming(流式输出)——Qwen 体验最佳实践
Qwen2.5 在流式响应方面表现优异:Token 输出稳定、断句合理,非常适合实时交互。
启用方式已在初始化中设置 streaming=True,使用时直接调用 .stream():
messages = [
{"role": "system", "content": "你是一个专业助手"},
{"role": "user", "content": "解释什么是 LangChain"}
]
for chunk in llm.stream(messages):
print(chunk.content, end="", flush=True)
💡 该特性特别适合集成到 WebSocket、SSE(Server-Sent Events)等 Web 实时通信协议中。
五、完整可运行代码(兼容 LangChain ≥ 0.2)
以下代码完全自包含,无需依赖已废弃的 Memory 类,适用于最新版 LangChain:
# demo.py
from langchain_ollama import ChatOllama
import tiktoken
# 初始化 LLM
llm = ChatOllama(
model="qwen2.5:7b",
base_url="http://localhost:11434",
temperature=0.2,
top_p=0.9,
top_k=40,
repeat_penalty=1.1,
streaming=True,
)
# 使用 tiktoken 估算 token 数量(Qwen 使用与 GPT-4 兼容的 tokenizer)
enc = tiktoken.get_encoding("cl100k_base")
def count_tokens(text: str) -> int:
return len(enc.encode(text))
def truncate_history(messages, max_tokens=2048):
"""从后往前保留消息,确保总 token 不超过 max_tokens"""
total_tokens = 0
truncated = []
# 倒序遍历(从最新消息开始保留)
for msg in reversed(messages):
content = msg["content"]
tokens = count_tokens(content)
if total_tokens + tokens > max_tokens:
break
truncated.append(msg)
total_tokens += tokens
return list(reversed(truncated)) # 恢复时间顺序
def chat_loop():
print("💬 Qwen2.5 本地助手(输入 'quit' 退出)")
chat_history = [] # 存储 [{"role": "user", "content": "..."}, {"role": "assistant", "..."}]
while True:
user_input = input("\n你: ").strip()
if user_input.lower() in ["quit", "exit"]:
print("👋 再见!")
break
if not user_input:
continue
# 构建完整消息列表
messages = [
{"role": "system", "content": "你是一个专业、简洁、准确的技术助手。请用中文回答,避免冗余。"}
]
# 加入截断后的历史(预留空间给新输入)
messages.extend(truncate_history(chat_history, max_tokens=1536))
messages.append({"role": "user", "content": user_input})
print("助手: ", end="", flush=True)
full_response = ""
for chunk in llm.stream(messages):
content = chunk.content
print(content, end="", flush=True)
full_response += content
print() # 换行
# 保存到历史
chat_history.append({"role": "user", "content": user_input})
chat_history.append({"role": "assistant", "content": full_response})
if __name__ == "__main__":
chat_loop()
六、代码核心亮点解析
1. System Prompt 引导角色
{"role": "system", "content": "你是一个专业、简洁、准确的技术助手..."}
Qwen 对系统提示高度敏感,合理设计可显著提升回答质量与一致性。
2. 流式输出(Streaming)
for chunk in llm.stream(messages):
print(chunk.content, end="", flush=True)
实现逐 Token 实时输出,用户体验接近主流聊天界面。
3. Token 级上下文控制
- 使用
tiktoken精确估算 Token 数量; - 动态截断历史,保留最近 1536 Tokens;
- 避免因上下文过长导致推理变慢或显存溢出(OOM);
- 保证响应速度与系统稳定性。
4. 兼容 LangChain 最新版
- 不依赖
langchain.memory(已弃用); - 采用纯消息列表管理,逻辑清晰、未来兼容性强;
- 适用于 LangChain 0.2 及以上所有版本。
七、运行与测试
- 将上述代码保存为
demo.py; - 在终端执行:
python demo.py - 交互示例:
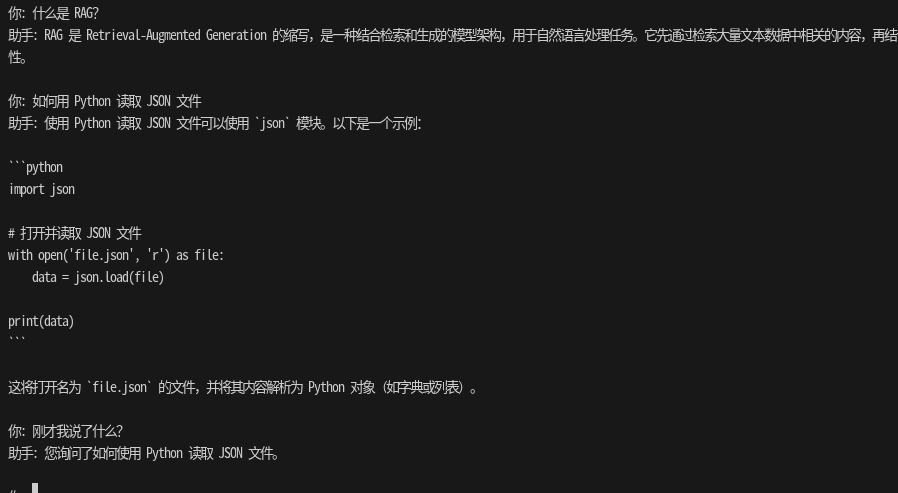
💬 Qwen2.5 本地助手(输入 'quit' 退出) 你: 什么是 RAG? 助手: RAG 是 Retrieval-Augmented Generation 的缩写,是一种结合检索和生成的模型架构,用于自然语言处理任务。它先通过检索大量文本数据中相关的内容,再结合生成模型进行文本生成或回答问题,以提高生成质量和相关性。 你: 刚才我说了什么? 助手: 你刚才问“什么是 RAG?”。
八、生产部署建议
| 场景 | 推荐配置 |
|---|---|
| 代码生成 / 运维 / RAG | temperature=0.0~0.2 |
| 自由对话 | temperature=0.6 |
| 高并发服务 | 多 Ollama 实例 + 请求队列 |
| Docker 环境 | base_url="http://ollama:11434" |
重要提醒:
- Ollama 默认为单进程服务,不支持高并发;
- LangChain 本身不做并发控制,需在应用层限流;
- 上下文长度务必限制,否则推理延迟急剧上升。
九、总结
本文围绕 qwen2.5:7b,完整展示了 langchain_ollama.ChatOllama 的高级用法,涵盖:
- ✅ 模型参数调优(专为 Qwen 优化)
- ✅ 流式输出(Streaming)
- ✅ 手动 Token 级上下文管理(替代废弃 Memory)
- ✅ System Prompt 工程化实践
- ✅ 生产环境注意事项
你现在已经拥有一个完全私有、本地运行、可工程化扩展的 AI 助手基础框架。下一步可轻松集成:
- 向量数据库(RAG)
- 自定义工具调用(如执行 Shell 命令)
- FastAPI 封装为 Web 服务
- 前端聊天界面(Vue/React)
技术栈黄金三角:Qwen2.5(模型) + Ollama(推理引擎) + LangChain(编排框架)
—— 让大模型真正落地于你的本地环境。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)