AI大模型前沿】GLM-TTS:智谱AI打造的可控情感零样本文本转语音模型
GLM-TTS 是智谱 AI 开发的零样本语音合成系统,基于大型语言模型,支持零样本语音克隆和流式推理。该系统采用两阶段架构,结合 LLM 生成语音 Token 和 Flow Matching 模型合成波形。通过引入多奖励强化学习框架,GLM-TTS 在情感表达和语音自然度上显著优于传统 TTS 系统。
系列篇章💥
前言
在人工智能技术飞速发展的今天,语音合成技术作为人机交互的重要组成部分,正逐渐改变着我们的生活和工作方式。GLM-TTS 作为智谱 AI 推出的创新性语音合成模型,凭借其强大的功能和卓越的性能,为语音合成领域带来了新的突破。
一、项目概述
GLM-TTS 是智谱 AI 开发的零样本语音合成系统,基于大型语言模型,支持零样本语音克隆和流式推理。该系统采用两阶段架构,结合 LLM 生成语音 Token 和 Flow Matching 模型合成波形。通过引入多奖励强化学习框架,GLM-TTS 在情感表达和语音自然度上显著优于传统 TTS 系统。
二、核心功能
(一)零样本语音克隆
GLM-TTS 能够仅用 3-10 秒的提示音频克隆任何说话人的声音,无需针对特定说话人进行微调。这一功能极大地降低了语音合成的门槛,使得个性化语音合成变得简单易行。
(二)强化学习增强情感控制
借助多奖励强化学习框架(GRPO),GLM-TTS 能够优化韵律和情感表达。在情感维度上,GLM-TTS 在快乐、悲伤、愤怒等情绪上均取得了 SOTA 表现,平均情感得分领先于其他商用模型。这使得合成语音更具表现力和感染力,能够更好地满足不同场景下的情感表达需求。
(三)高质量语音合成
GLM-TTS 的语音合成质量可与商业系统相媲美,其字符错误率(CER)在开源模型中处于领先水平。在 seed-tts-eval 中文测试集上,GLM-TTS 的 CER 为 1.03%,引入强化学习后的 GLM-TTS_RL 的 CER 降至 0.89%,达到开源 SOTA。同时,GLM-TTS 在音色相似度上也保持了较高水平,兼顾了发音准确性和音色还原。
(四)音素级控制
GLM-TTS 支持“混合音素 + 文本”输入,可精准控制发音。通过 Phoneme-in 技术,用户可以为多音字和生僻字指定目标音素,从而解决自动发音歧义问题。在推理阶段,系统将音素序列与文本结合输入模型,既保留了文本的韵律,又确保了特定词汇的发音准确。
(五)流式推理
GLM-TTS 支持实时音频生成,适用于交互式应用。这一特性使得 GLM-TTS 能够在需要实时语音反馈的场景中发挥重要作用,如智能语音助手和在线教育等。
(六)双语支持
GLM-TTS 特别针对中英文混合文本进行了优化。这使得 GLM-TTS 能够更好地适应国际化场景,满足不同语言背景用户的需求。
三、技术揭秘
(一)两阶段生成范式
GLM-TTS 采用两阶段生成范式,分为语义建模(Text-to-Token)和声学建模与波形重建(Token-to-Wav)。第一阶段通过自回归模型将文本转换为语义 Token 序列,确保内容的准确性和连贯性;第二阶段用 Conditional Flow-matching 模型预测梅尔频谱图,通过 2D-Vocos 声码器将其转换为高质量语音波形。
(二)多奖励强化学习
GLM-TTS 引入基于 GRPO 算法框架的多奖励强化学习机制,融合字符错误率(CER)、相似度(Sim)、情感(Emotion)和副语言(如笑声)等多维度奖励。通过动态采样与梯度裁剪策略优化训练过程,显著提升了语音的情感表达能力和拟人化程度。
(三)精细化发音控制(Phoneme-in)
GLM-TTS 提供 Phoneme-in 技术,通过动态可控词典和混合输入形式,为多音字和生僻字提供目标音素,实现精准发音控制。在推理阶段,系统将音素序列与文本结合输入模型,保留文本韵律的同时确保发音准确。
(四)精品音色定制(LoRA)
GLM-TTS 采用优化的 LoRA 微调范式,仅需微调约 15% 的模型参数,结合少量高质量音频数据,实现与全参数微调相当的音色还原度和自然度。这大幅降低了音色定制的开发成本和落地门槛,提升了音色的泛化能力和跨场景稳定性。
(五)数据处理与特征提取
GLM-TTS 构建了完善的数据处理 Pipeline,包括语音标准化、背景音分离与降噪、说话人分离与拼接、WER 筛选、标点优化和特征提取等步骤。从异构音频中提取纯净语音和高质量特征,为模型训练提供可靠数据支持。
(六)模型结构优化
GLM-TTS 对 Speech Tokenizer 进行优化,提升 Token 码率和词表规模,引入音调估计模块(PE),取消因果卷积限制,优化音调建模精度。同时,2D-Vocos 声码器通过 2D 卷积和类 DiT 残差连接,提升频谱特征的解析精度和音质表现,增强模型对复杂声线的适应性。
四、基准评测
在 seed-tts-eval 中文测试集上,GLM-TTS 的 CER 为 1.03%,引入强化学习后的 GLM-TTS_RL 的 CER 降至 0.89%,达到开源 SOTA。同时,GLM-TTS 在音色相似度上也保持了较高水平,GLM-TTS 的相似度约 76.1,GLM-TTS_RL 提升至 76.4。这表明 GLM-TTS 在发音准确性和音色还原方面均取得了优异成绩。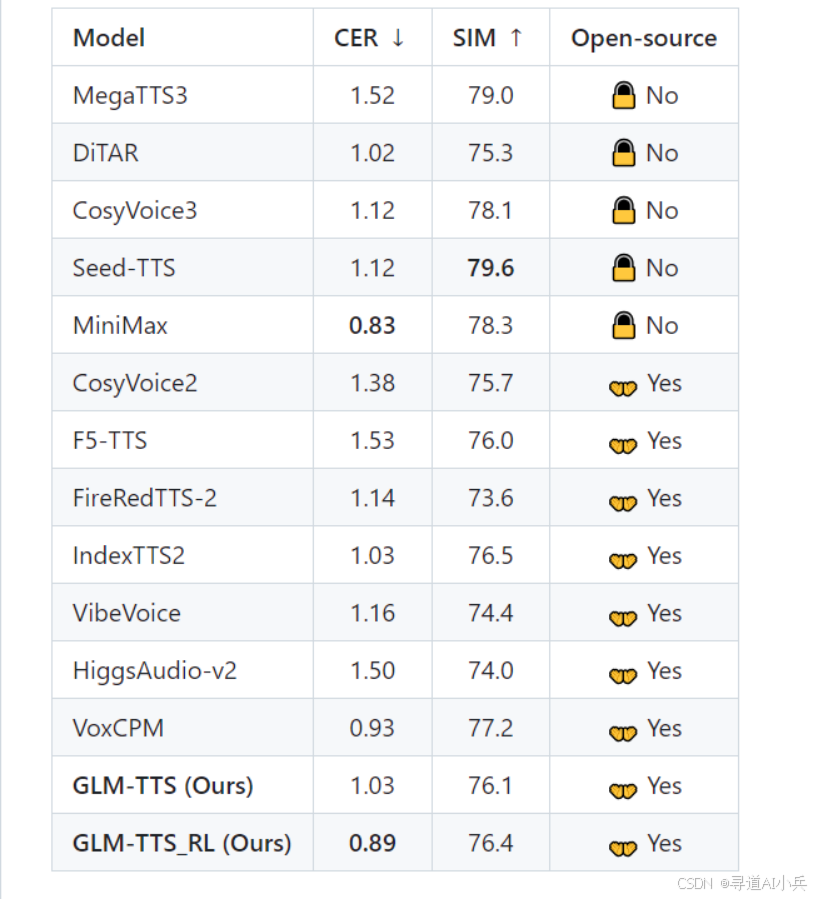
五、应用场景
(一)智能语音助手
GLM-TTS 为智能语音助手提供自然流畅的语音反馈,支持多语言和情感表达。根据用户指令生成贴合场景的语音交互,提升用户体验。
(二)有声读物与音频内容创作
GLM-TTS 可快速生成不同风格和情感的语音内容,支持多音色切换和方言朗读。满足有声读物、播客等多样化的音频创作需求。
(三)教育与培训
GLM-TTS 通过精细化发音控制,帮助学习者纠正多音字和生僻字发音。支持多语言和方言教学,提升教育质量和效率。
(四)娱乐与游戏
GLM-TTS 为游戏角色和娱乐内容生成带有方言和情感的语音。增强游戏和娱乐的沉浸感与趣味性。
(五)客服与智能交互
GLM-TTS 根据用户情绪调整语音风格。生成温和或耐心的语音回应,提升智能客服的交互体验和客户满意度。
六、快速使用
(一)环境准备
确保你的 Python 版本在 3.10 至 3.12 之间。然后按照以下步骤进行环境配置:
1、克隆仓库:
git clone https://github.com/zai-org/GLM-TTS.git
cd GLM-TTS
2、安装依赖:
pip install -r requirements.txt
如果你计划使用强化学习相关的功能,还需要额外安装以下依赖:
cd grpo/modules
git clone https://github.com/s3prl/s3prl
git clone https://github.com/omine-me/LaughterSegmentation
并下载 wavlm_large_finetune.pth 文件,放置在 grpo/ckpt 目录下。
(二)下载预训练模型
你可以从 Hugging Face 或 ModelScope 下载完整的模型权重。以下是两种下载方式的命令:
1、从 Hugging Face 下载:
pip install -U huggingface_hub
huggingface-cli download zai-org/GLM-TTS --local-dir ckpt
2、从 ModelScope 下载:
pip install -U modelscope
modelscope download --model ZhipuAI/GLM-TTS --local_dir ckpt
下载完成后,模型文件将存储在本地的 ckpt 文件夹中。
(三)运行推理
1、命令行推理
运行以下命令进行命令行推理:
python glmtts_inference.py \
--data=example_zh \
--exp_name=_test \
--use_cache \
# --phoneme # 添加此标志以启用音素功能
2、Shell 脚本推理
你也可以使用 Shell 脚本来运行推理。具体的脚本内容和运行方式可以参考仓库中的 glmtts_inference.sh 文件。
3、交互式 Web 界面
如果你希望通过图形界面进行交互式语音合成,可以运行以下命令启动 Web 界面:
python -m tools.gradio_app
启动后,系统会提示一个本地访问地址,你可以在浏览器中访问该地址,通过 Web 界面输入文本和参数,实时生成语音。
七、结语
GLM-TTS 作为智谱 AI 推出的创新性语音合成模型,凭借其零样本语音克隆、强化学习增强情感控制、高质量语音合成、音素级控制、流式推理和双语支持等核心功能,在语音合成领域展现出了强大的竞争力。其在基准评测中的优异表现,进一步证明了其在发音准确性、音色还原和情感表达方面的卓越性能。GLM-TTS 广泛的应用场景,使其能够为众多领域带来更加自然、高效和个性化的语音交互体验。随着技术的不断发展和优化,GLM-TTS 有望在语音合成领域发挥更大的作用,推动语音交互技术的进一步发展。
项目地址
- GitHub 仓库:https://github.com/zai-org/GLM-TTS
- Hugging Face 模型库:https://huggingface.co/zai-org/GLM-TTS
- 在线体验:https://audio.z.ai/

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)