自动驾驶大模型---慕尼黑工业大学之OpenDriveVLA
OpenDriveVLA 通过端到端架构和多模态大模型,为自动驾驶提供了一种更高效、泛化的解决方案。其核心价值在于将语言模型的推理能力与视觉感知深度融合,突破了传统模块化系统的局限性。尽管在算力、数据隐私等方面仍需突破,但该研究为行业指明了 “感知 - 推理 - 决策” 一体化的未来方向,有望推动自动驾驶从 “功能实现” 向 “类人智能” 跨越。
1 前言
关于大模型的博客,笔者分为了两个系列:车企量产 + 科研论文。希望有兴趣的朋友能够从笔者的大模型博客系列当中收获一些知识或者idea。
车企量产:
《自动驾驶大模型---大疆车载(卓驭科技)之GenDrive》
科研论文:
《自动驾驶---阿里巴巴之AutoDrive-R²(VLA)大模型》
进入2025年,研究智驾的车企逐渐将技术路线转到VLA,或者VA,本篇博客主要介绍2025年比较经典的一篇论文,提出了一种基于大型视觉 - 语言 - 动作(VLA)模型的端到端自动驾驶框架。
2 OpenDriveVLA
该研究由慕尼黑工业大学的 Xingcheng Zhou 等学者完成,旨在通过多模态融合和大模型推理能力,解决传统模块化自动驾驶系统在复杂场景下的泛化难题。以下从技术架构、训练、创新、实验验证及应用等方面进行阐述。
2.1 技术架构
首先,看到下图所示OpenDriveVLA的架构,朋友们并不陌生,和笔者之前讨论的很多模型都比较像。下面主要从输入,输出以及中间层对OpenDriveVLA进行分解:
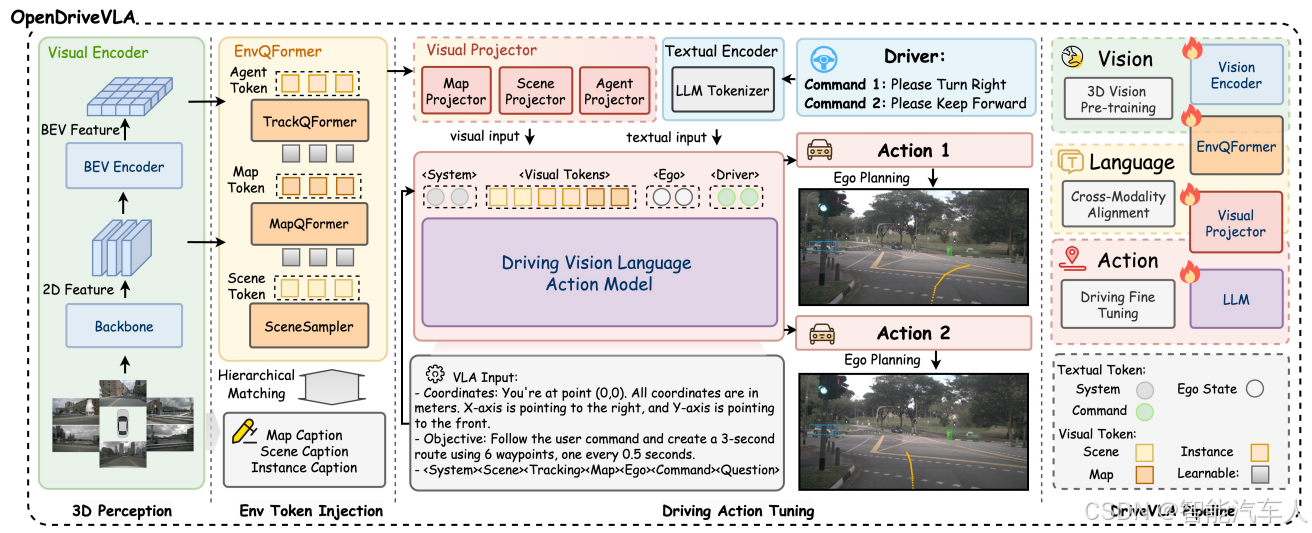
(1)输入模块
后面针对模型需要的输入信息,笔者会详细撰写一篇博客,因为不少文章中的输入信息似乎不太一样,很多读者朋友估计会困惑。
- 多模态数据融合:
- 视觉感知:整合摄像头图像(2D)和激光雷达点云(3D),通过分层视觉编码器提取结构化特征。其中,2D 图像采用 BEV(鸟瞰图)转换,3D 点云通过 PointPillars 生成体素特征。
- 语言指令:支持自然语言输入(如 “前方路口左转”)。
- 自车状态:实时采集车辆速度、转向角等动态参数,作为模型决策的约束条件。
(2)核心模型
- 分层视觉 - 语言对齐:
- 跨模态投影:将视觉特征(如 BEV 网格、体素特征)和语言嵌入投影到统一语义空间,通过可学习适配器(Adapter)消除模态差异。
- 交互建模:引入自回归代理 - 环境 - 自车(Agent-Env-Ego)交互模块,动态建模车辆与周围环境(如行人、障碍物)的时空关系,预测未来轨迹。
(3)输出模块
- 动作生成:直接输出车辆控制信号(如转向、加速),支持连续轨迹规划(如未来 10 秒的路径点)。
- 可解释性增强:通过语言模型生成驾驶决策的自然语言解释(如 “因前方施工,需绕行”),提升用户信任度。
在这个阶段,OpenDriveVLA将未来的驾驶动作规划为未来几秒内的一系列路标点,表示为 。每个路标点
代表自车在时间步 (t) 的2D坐标
。为了使用大语言模型进行自回归生成,路标点首先被token化为一系列离散的文本token:
。
然后,生成过程被转化为一个因果序列预测任务,其中每个token都基于视觉感知token 、自车状态
和驾驶命令
进行预测:
在训练过程中,整个模型,包括视觉编码器、跨模态投影器和大语言模型,进行端到端的联合优化。在推理时,模型以自回归的方式生成token化的轨迹 ,然后解码回数值路标点:
2.2 训练
OpenDriveVLA 模型的训练采用训练集与对应的问答标注数据配对的方式,而验证集则专门用于性能评估,以此确保与现有研究成果进行公平对比。
训练步骤如下(注意每一步需要冻结的模块):
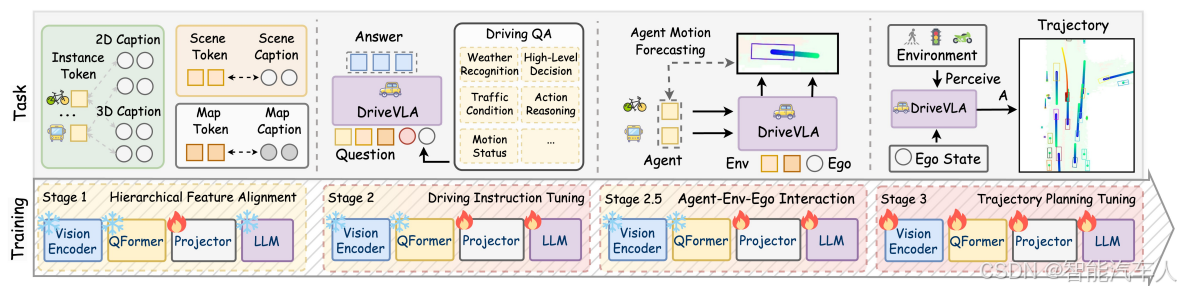
每一步对应的内容主要包括下面四个部分:
(1)输入数据对齐;
(2)数据标注;
(3)动态障碍物运动轨迹预测;
(4)自车轨迹生成;
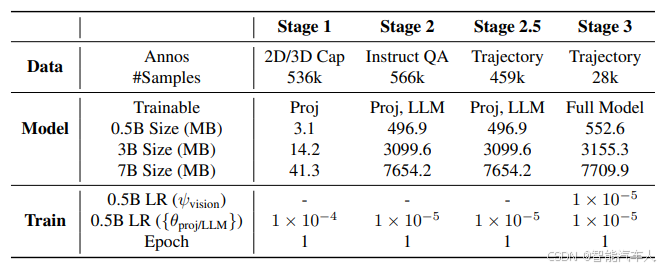
训练过程/结果的数据如下:
2.3 创新点
(1)端到端架构突破
- 模块化解耦:摒弃传统的 “感知 - 定位 - 规划 - 控制” 流水线,直接从原始传感器数据生成控制指令,减少中间环节误差累积。
- 长尾场景泛化:利用大模型的 “世界知识”(如交通规则、人类驾驶习惯),处理训练数据之外的复杂场景(如交警手势、异形路口)。这也是LLM大语言模型的魅力之处。
(2)多模态协同机制
- 语言引导决策:语言模型不仅用于理解指令,还通过链式思维(Chain-of-Thought)推理隐藏约束。例如,输入 “避开拥堵路段” 时,模型可结合实时路况和地图数据动态调整路线。
- 动态交互建模:自回归模块捕捉车辆与环境的长期依赖关系,支持 20 秒级的未来轨迹预测,优于传统模型的 7 秒推理能力。
(3)轻量化与实时性优化
- 模型压缩:采用知识蒸馏技术,将 50B 参数的预训练 VLM(视觉语言模型)压缩至 7B,适配车规级芯片(如英伟达 Thor)。
- 并行推理:视觉编码器与语言模型并行处理数据,单帧推理时间低于 50ms,满足实时性要求。
2.4 实验验证
(1)数据集与仿真环境
- 训练数据:
- 真实场景:使用 NuScenes(1000 个场景,40 万帧)和 Waymo Open Dataset(2030 个片段),覆盖城市道路、高速、夜间等复杂环境。
- 合成数据:通过 CARLA 模拟器生成极端场景(如暴雨、道路施工),增强模型鲁棒性。
- 测试场景:
- 开环轨迹规划:在 NuScenes 测试集上,OpenDriveVLA 的平均位移误差(ADE)为 0.52m,优于 UniAD(0.68m)和 LMDrive(0.58m)。
- 闭环驾驶:在 CARLA 模拟器中完成 100 公里无接管驾驶,成功率达 98.7%,违规次数(如闯红灯)减少 60%。
模型结果对比:
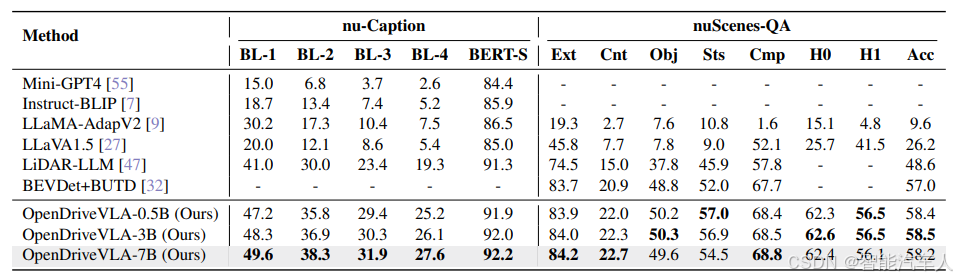
(2)语言指令处理
- 多语言支持:模型在中英双语指令下的任务完成率分别为 97.3% 和 95.8%,支持 “请在第二个匝道右转” 等复杂表述。
- 零样本泛化:对未训练过的指令(如 “跟随前方白色卡车”),模型仍能通过常识推理完成任务,成功率达 89.2%。
2.5 应用方向
- 人机协同:通过自然语言交互,实现 “用户说指令,车辆自主执行” 的无缝体验。
- 世界模型集成:结合云端大模型生成仿真数据,解决长尾场景数据稀缺问题。
- 实时性优化:探索稀疏计算、动态网络剪枝等技术,降低模型功耗。
3 总结
OpenDriveVLA 通过端到端架构和多模态大模型,为自动驾驶提供了一种更高效、泛化的解决方案。其核心价值在于将语言模型的推理能力与视觉感知深度融合,突破了传统模块化系统的局限性。尽管在算力、数据隐私等方面仍需突破,但该研究为行业指明了 “感知 - 推理 - 决策” 一体化的未来方向,有望推动自动驾驶从 “功能实现” 向 “类人智能” 跨越。
参考文献:《OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)