list 迭代器:C++ 容器封装的 “行为统一” 艺术
在mini_list中,通过实例化模板,定义两种迭代器类型:代码语言:javascriptAI代码解释public:// 可写迭代器:ref=T&,ptr=T*// 只读迭代器:ref=const T&,ptr=const T*// ...用户无需关心的存在,只需使用即可,实现了 “封装底层细节” 的目标。list迭代器的封装,本质上是为了解决一个核心矛盾:链表的非连续内存结构,与用户对 “统一访
1. 链表节点的设计
对于双向链表,一个节点包含两个指针,用于存储前驱节点和后继节点的地址,以及存一个_data的值
如图:
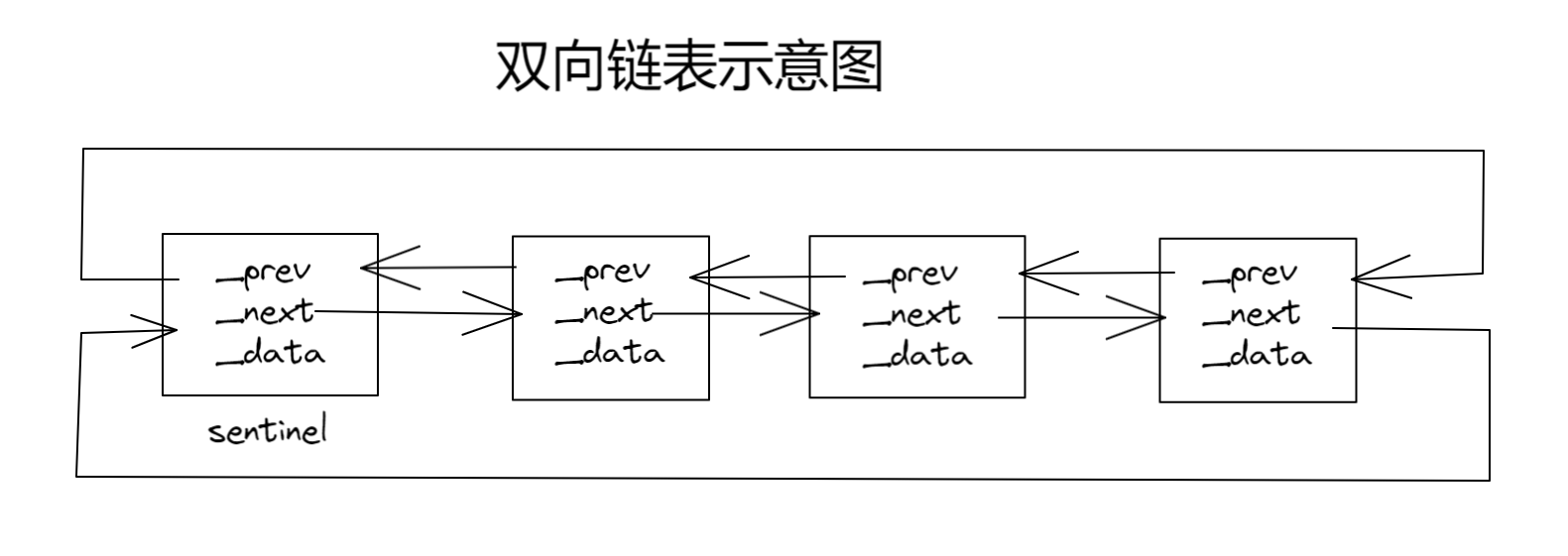
在这里插入图片描述
那么,我们就可以定义一个节点的模板类
代码语言:javascript
AI代码解释
template <class T>
struct list_node{
// 成员变量
list_node<T>* _prev; // 存储前驱节点地址
list_node<T>* _next; // 存储后继节点的值
T _data;
// 构造空节点 默认构造
list_node(const T& val = T())
:_prev(nullptr)
,_next(nullptr)
,_data(val)
{}
};设计要点:
- 为什么要设计成
struct?
在C++中,struct里的成员默认是public的,我们光设计一个节点类是完全不够的,还需要一个链表类来控制链表的行为,而链表类会频繁使用节点类的成员,所以节点类成员public是为了方便链表类使用节点,提高效率
const T& val = T()缺省参数T()有什么巧思?
T()是模板类的 默认构造函数调用 ,是一种通用的初始化方式:
- 对于内置类型(
intdouble等):T()会生成 零值(指针类是nullptr,int类是0,double类是0.0) - 对于自定义类型(如用户自定义的
DatePerson):T()会调用该类型的默认构造函数,确保自定义类型的对象可以被正确初始化
参数类型const T&保证高效和安全:
- 传引用可以避免
T()类型对象的 拷贝构造,尤其对于大型对象,可以减少内存开销和性能损耗 const修饰确保传入的对象值只读性,不会被构造函数意外修改
2. 链表类的基本结构
对于双向链表的控制,我们增加一个哨兵位可以减少很多额外的考虑。
代码语言:javascript
AI代码解释
template <class T>
class mini_list{
public:
typedef list_node<T> Node; // 将类名缩短,便于后续编码
// 空链表函数 哨兵位两个指针都指向自己
void empty_list(){
// 开一个节点的空间
_head = new Node(); // 不存储有效值,默认为T()
_head->_next = _head;
_hean->_prev = _head;
}
// 构造空链表 默认构造
mini_list(){ empty_list(); }
private:
Node* _head; // 定义哨兵位节点
};这里埋个伏笔,写空链表函数是后续实现更多构造函数共同调用的
有了哨兵位,我们可以插入数据,但有个大问题:**我们如何访问插入的数据? ** —— 迭代器
3. 迭代器设计
3.1. 能否类比vector利用指针作为迭代器? ——不能!
- 先明确迭代器的本质:数据访问的抽象工具,类似指针
迭代器有两个核心功能:
- 定位:指向容器中的某个元素
- 移动和访问:支持
++(下一个)--(上一个)*(取数据)->(取数据成员)等操作,且接口对用户是完全统一的
- 为什么
vector可以用指针直接当迭代器?
vector的底层是连续的动态数组,元素在内存中依次排序,恰好与原生指针性能完美匹配,++ -- * ->这几个操作符指针可以直接使用,vector的迭代器本质就是T*的定位移动和访问
- 为什么
list不能用指针直接当迭代器?
list的底层是双向链表,元素存储在分散的节点list_node中,节点间通过两个指针关联(内存不连续),这导致了原生节点指针list_node<T>*完成不了++ -- * ->这几个操作符的功能,它的行为不满足迭代器的统一要求了,因此,对于list,我们需要自己封装一个迭代器类,来满足迭代器的统一行为要求
3.2. 迭代器模板的设计: 一份代码实现两种迭代器
手写迭代器时,我们需要同时支持 “可写迭代器(iterator)” 和 “只读迭代器(const_iterator)”。如果分别实现这两个类,会产生大量重复代码(二者仅数据访问权限不同)。
解决方案是用模板参数区分访问权限,通过一份迭代器模板生成两种类型。先看核心设计:
代码语言:javascript
AI代码解释
// 模板参数: T 数据类型 ref 引用类型 ptr 指针类型
template <class T, class ref, class ptr>
struct list_iterator{
typedef list_node<T> Node;
typedef list_iterator<T, ref, ptr> self; // 简化类型名
Node* _node; // 迭代器核心: 指向当前节点的指针
}模板参数的妙用
链表类中通过实例化模板,快速定义两种迭代器
代码语言:javascript
AI代码解释
class mini_list{
public:
// ref = T& ptr = T*
typedef list_iterator<T, T&, T*> iterator; // 可读可写迭代器
// ref = const T& ptr = const T*
typedef list_iterator<T, const T&,const T*> const_iterator; // 只读迭代器
}设计要点: 用模板参数延迟确定访问权限:
- 当
ref为T&,ptr为T*时,迭代器可读可写 - 当
ref为const T&,ptr为const T*时,迭代器只读
其中,ref和ptr是 “变化的参数”,用于控制数据访问的权限;T是 “不变的参数”,表示容器中元素的类型。一份代码实现了两种功能,将脏活累活全部交给编译器处理。
3.3. 迭代器核心实现:运算符重载
迭代器的“行为统一”完全靠运算符重载实现,我们需要重载++ -- * ->这几个操作符,让用户可以像指针一样使用迭代器
- **核心成员变量:
_node**
Node* _node时迭代器与底层节点沟通的唯一桥梁,它存储当前链表节点的地址,让所有运算符都围绕_node展开
- 移动操作符:
++与--
代码语言:javascript
AI代码解释
self& operator++(){
_node = _node->_next;
return *this;
}
// 往后移动一位 返回旧值
self operator++(int){
self tmp = *this;
_node = _node->_next;
return tmp;
}
self& operator--(){
_node = _node->_prev;
return *this;
}
self operator(int){
self tmp = *this;
_node = _node->_prev;
return tmp;
}注意:
- 前置操作返回
self&,避免了迭代器对象的拷贝,同时允许对原迭代器进行修改(如++it后直接使用it) - 后置操作返回临时对象(
tmp),临时对象生命周期结束后引用会失效,所以不能返回引用,这也是前置版本比后置版本更高效的原因:没有额外拷贝的开销
- 解引用
代码语言:javascript
AI代码解释
// * 解引用 返回 ref(可以是 T& 或 const T&)
ref operator*(){
assert(_node); // 防止对哨兵位解引用
return _node->_data; // 返回数据域的引用
}设计要点:
- 返回引用:避免数据拷贝,支持“通过迭代器修改数据”(可读可写迭代器场景)
- 指针访问
当T是自定义类型(如结构体、类)时,迭代器需要支持it->member的访问方式:
代码语言:javascript
AI代码解释
// -> 指针访问成员 返回ptr(T* 或 const T*)
ptr operator->(){
assert(_ndoe);assert(_node); // 防止对哨兵位访问
return &_node->_data; //取地址
}使用示例:若T为struct Person { string name; int age; },则:
代码语言:javascript
AI代码解释
mini_list<Person> lst;
auto it = lst.begin();
cout << it->name; // 等价于 (*it).name,编译器会优化为 it.operator->()->name编译器会将it->name解释为(it.operator->())->name,因此operator->只需返回数据的指针即可。
- 相等比较
代码语言:javascript
AI代码解释
// != ==重载
bool operator==(const self& other) const {
return _node == other._node;
}
bool operator!=(const self& other) const {
return _node != other._node;
}4. 迭代器与链表类结合:统一行为
迭代器本身是独立的模板类,但需要与mini_list类配合,才能实现完整的容器功能。核心是链表类提供迭代器的创建入口(begin()/end()),并遵循 STL 的 “前闭后开” 区间规范。
4. 1. 迭代器类型定义
在mini_list中,通过实例化list_iterator模板,定义两种迭代器类型:
代码语言:javascript
AI代码解释
class mini_list {
public:
typedef list_node<T> Node;
// 可写迭代器:ref=T&,ptr=T*
typedef list_iterator<T, T&, T*> iterator;
// 只读迭代器:ref=const T&,ptr=const T*
typedef list_iterator<T, const T&, const T*> const_iterator;
// ...
};用户无需关心list_iterator的存在,只需使用mini_list<T>::iterator即可,实现了 “封装底层细节” 的目标。
2. begin()与end()的实现
mini_list采用 “哨兵位双向循环链表” 设计(_head为哨兵节点,不存储有效数据),begin()和end()的实现需符合 “前闭后开” 原则:
代码语言:javascript
AI代码解释
// 可写迭代器的 begin/end
iterator begin() {
return iterator(_head->_next); // 指向第一个有效节点
}
iterator end() {
return iterator(_head); // 指向哨兵位节点(尾后位置)
}
// 只读迭代器的 begin/end(const版本)
const_iterator begin() const {
return const_iterator(_head->_next);
}
const_iterator end() const {
return const_iterator(_head);
}“前闭后开” 的优势:
- 遍历逻辑统一:
for (auto it = lst.begin(); it != lst.end(); ++it),适用于所有 STL 容器; - 空容器判断简单:
begin() == end()即表示容器为空; - 插入 / 删除接口统一:
insert()在迭代器位置前插入,erase()删除迭代器指向的元素,返回下一个迭代器。
3. 迭代器的实际应用:简化链表操作
有了封装好的迭代器,mini_list的插入、删除等操作变得异常简洁。例如push_back()(尾插)和erase()(删除):
代码语言:javascript
AI代码解释
// 尾插:在end()位置前插入(即最后一个有效节点后)
void push_back(const T& input_val) {
insert(end(), input_val);
}
// 删除迭代器指向的节点,返回下一个迭代器
iterator erase(iterator pos) {
assert(pos != end()); // 不能删除哨兵位
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* next = cur->_next;
// 调整节点指针
prev->_next = next;
next->_prev = prev;
delete cur;
return iterator(next); // 返回下一个有效节点的迭代器
}调用这些接口时,完全无需接触底层的list_node和指针操作,只需传递迭代器即可,这正体现了封装的思想,我只提供功能,底层逻辑你不需要知道,你也没必要知道,会用就好
5. list迭代器核心思想总结
list 迭代器的封装,本质上是为了解决一个核心矛盾:链表的非连续内存结构,与用户对 “统一访问接口” 的需求之间的不匹配。它的设计思路可以拆解为几个朴素且务实的想法:
5.1. 先解决 “非连续内存的访问问题”
链表的节点在内存中是分散的,靠_prev和_next指针串起来。这种结构下,原生指针(比如list_node*)没法直接当迭代器 —— 想 “移到下一个元素”,不能像数组指针那样++(数组指针++是跳一个元素大小的内存,链表不行),得手动改node = node->_next;想 “取当前元素”,不能直接解引用(解引用得到的是整个节点,不是数据),得取node->_data。
所以,迭代器首先要做的,就是把这些 “链表特有的操作” 包起来。用一个类(list_iterator)存节点指针(_node),然后重载++、--、*这些运算符,让++内部自动执行_node = _node->_next,让*内部自动返回_node->_data。这样一来,用户用迭代器时,就不用管底层是_next还是_data,像用数组指针一样写++it、*it就行。
5. 2. 再解决 “读写权限的区分问题”
用链表时,有时需要改元素(比如普通的list),有时只能读(比如const list)。这两种场景需要两种迭代器:一种能写(iterator),一种只能读(const_iterator)。
但这两种迭代器的 “移动逻辑”(++、--、比较是否相等)是完全一样的,只有 “访问数据的权限” 不同(*it返回T&还是const T&)。如果为它们写两个类,代码会大量重复。
所以,用模板参数来 “抽象权限差异”:给迭代器模板加两个参数(ref和ptr),分别代表 “数据引用类型” 和 “数据指针类型”。当ref是T&、ptr是T*时,就是可写迭代器;当ref是const T&、ptr是const T*时,就是只读迭代器。这样,一份代码就能通过不同的模板参数,生成两种迭代器,既省代码,又能保证逻辑一致。
5.3. 最后守住 “迭代器的本质:位置标识”
迭代器的核心作用是 “标记位置”,而不是 “比较数据”。两个迭代器相等,意思是 “它们指着同一个节点”,而不是 “它们指的节点数据一样”。所以比较迭代器时,直接比底层的_node指针(_node == other._node)就行,不用去碰节点里的数据。
这一点也影响了运算符的设计:==、!=只关心 “位置是否相同”,*、->才关心 “位置上的数据”,各司其职。
5.4. 最后的总结
用一个类把链表节点的指针 “包起来”,通过运算符重载,把链表特有的操作转换成和数组指针一样的用法(统一接口);用模板参数区分读写权限,避免重复代码(复用逻辑);始终牢记迭代器是 “位置标识”,让比较逻辑只关心位置,不关心数据(明确职责)。说到底,就是 “把复杂的底层细节藏起来,给用户一个简单、统一的用法”—— 这也是封装思想的核心。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)