Agent架构解析与实战(六)--PEV (Planner → Executor → Verifier)
🧱 拒绝“玩具级” Demo!构建真正“抗造”的生产级 Agent—— 你的 AI 一遇到 API 报错就“歇菜”? 深入 PEV (Planner-Executor-Verifier) 架构核心,手把手教你用 LangGraph 打造自带**“自动纠错回环”**的智能体,让系统稳定性原地起飞!🚀
参考自:all-agentic-architectures[1]
[!IMPORTANT]
Prompt 设计的重要性在 PEV 架构中,Prompt 的质量直接决定了系统的成败。特别是 Verifier 的判断逻辑以及pydantic模型中对于字段的descriptionon的描述,都依赖于精心设计的验证规则——如果 Prompt 设计不当,即使返回了正确的结果,Verifier 也可能误判为失败。因此,在实现 PEV 架构时,必须确保:
- Planner 的 Prompt 明确指定输出格式和约束
- Verifier 的判断标准要覆盖各种成功/失败情况
- 各节点之间的数据传递格式要保持一致
- Pedantic模型字段的description描述要清晰准确
1. 定义
PEV (Planner → Executor → Verifier) 架构是一种三阶段的工作流程,将规划、执行和验证三个步骤显式分离。它确保每一步的输出在 Agent 继续执行之前都经过验证,从而形成一个健壮的、自我修正的闭环系统。
与标准的 Planning Agent 不同,PEV 模式解决了一个关键假设问题:在现实世界中,API 可能失败、搜索可能返回空结果、数据可能格式错误。PEV 通过添加专用的 Verifier 代理来解决这些问题,使系统能够检测失败并动态恢复。
2. 宏观工作流
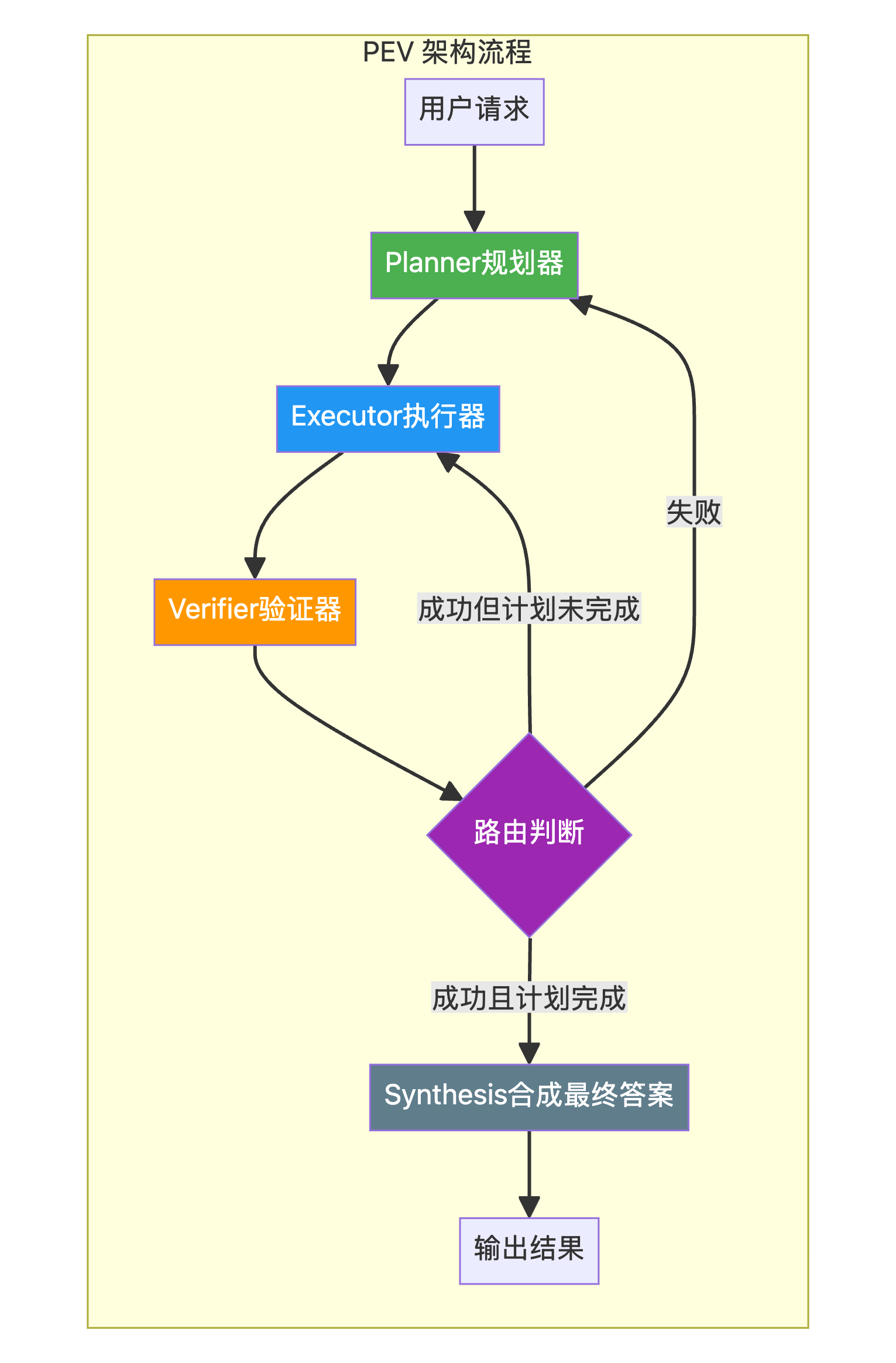
各阶段职责
| 阶段 | 职责 | 关键特性 |
|---|---|---|
| Plan (规划) | Planner 代理将高级目标分解为一系列具体的、可执行的步骤 | 结构化输出、步骤限制 |
| Execute (执行) | Executor 代理从计划中取出下一步并调用相应的工具 | 工具调用、结果捕获 |
| Verify (验证) | Verifier 代理检查 Executor 的输出,判断步骤是否成功 | 错误检测、质量评估 |
| Route & Iterate (路由) | 根据 Verifier 的判断决定下一步动作 | 动态重规划、循环控制 |
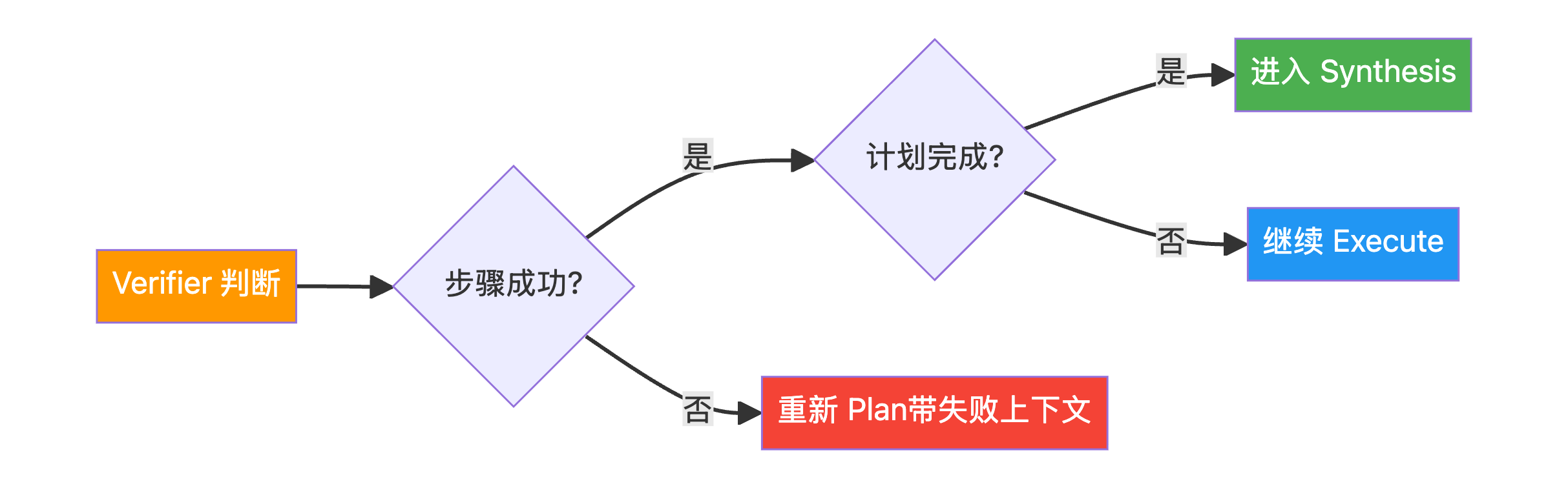
路由逻辑
3. 应用场景
| 场景类型 | 描述 | 示例 |
|---|---|---|
| 安全关键应用 | 错误代价极高的场景,PEV 提供必要的防护栏 | 金融交易、医疗诊断 |
| 不可靠工具系统 | 外部 API 可能不稳定或返回不一致数据 | 第三方 API 集成、网络爬虫 |
| 高精度任务 | 需要高度事实准确性的任务 | 法律文档分析、科学研究 |
4. 优缺点分析
优势
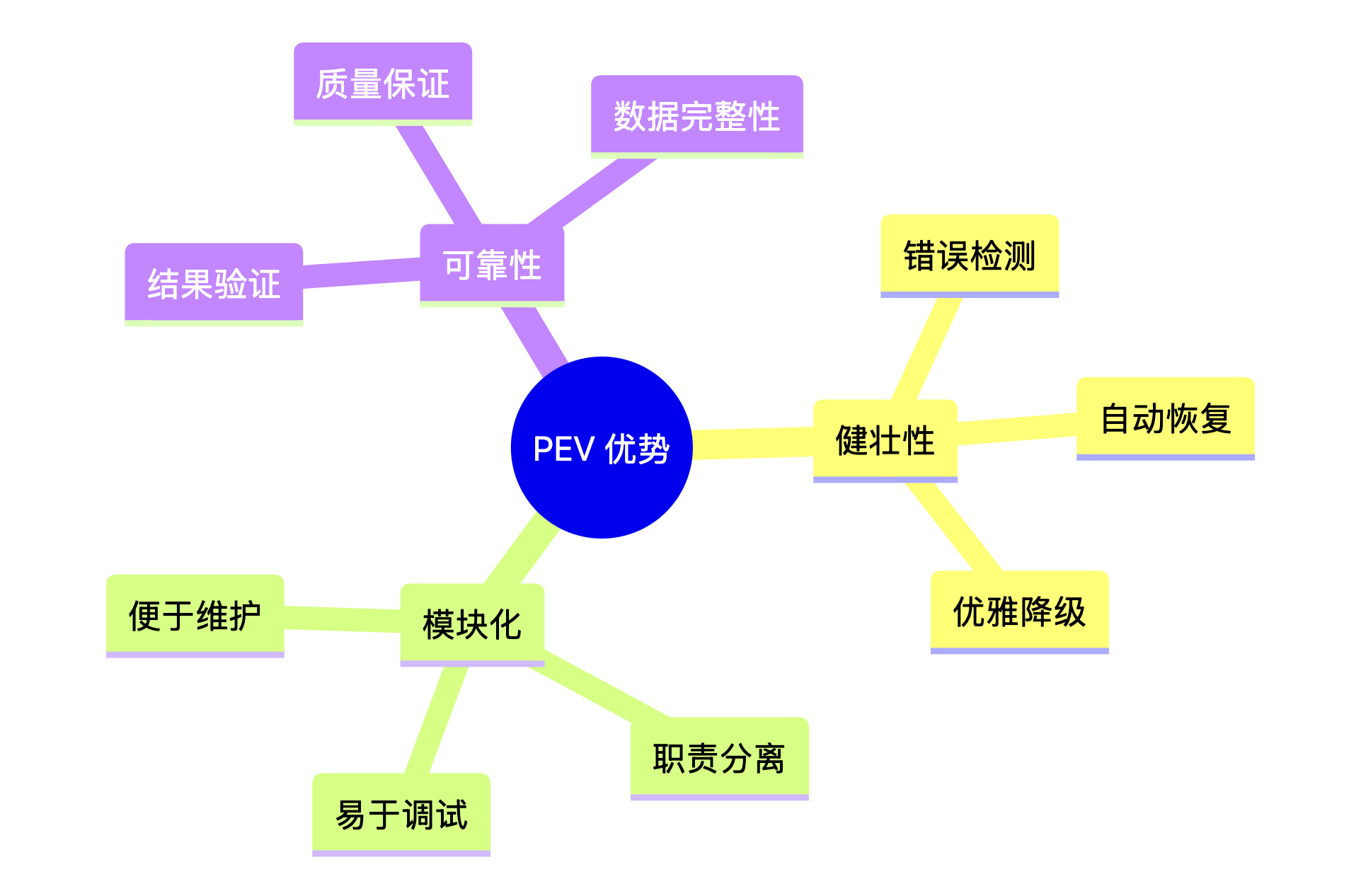
- 健壮性与可靠性:核心优势在于检测错误并从中恢复的能力
- 模块化设计:职责分离使系统更易于调试和维护
劣势
- 延迟与成本增加:每个动作后都有验证步骤,增加了 LLM 调用次数
- Verifier 复杂性:设计有效的 Verifier 具有挑战性,需要能够区分小问题和关键失败
5. 代码实现
5.1 基础配置
pip install -q -U langchain-openai langchain langgraph python-dotenv rich tavily-python pydantic langchain-coreimport os
import json
import re
from typing import List, Annotated, TypedDict, Optional
from dotenv import load_dotenv
from tavily import TavilyClient
# LangChain组件
from langchain_openai import ChatOpenAI
from langchain_core.messages import BaseMessage, SystemMessage, HumanMessage
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.tools import tool
# LangGraph组件
from langgraph.graph import StateGraph, END
from langgraph.graph.message import AnyMessage, add_messages
from langgraph.prebuilt import ToolNode, tools_condition
# 美化输出
from rich.console import Console
from rich.markdown import Markdown5.2 基础 Planner-Executor Agent (对照组)
# 定义基础P-E Agent状态
class BasicPEState(TypedDict):
user_request: str
plan: Optional[List[str]]
intermediate_steps: List[str]
final_ans: Optional[str]
class Plan(BaseModel):
steps: List[str] = Field(description="A list of tool calls to execute.")
def basic_planner_node(state: BasicPEState):
"""规划节点:将用户请求分解为步骤"""
console.print("--- (Basic) PLANNER: Creating plan... ---")
planner = llm.with_structured_output(Plan)
prompt = f"""
You are a planning agent.
Your job is to decompose the user's request into a list of clear tool queries.
- Only return JSON that matches this schema: {{ "steps": [ "query1", "query2", ... ] }}
- Do NOT return any prose or explanation.
- Always use the 'flaky_web_search' tool for queries.
User's request: "{state['user_request']}"
"""
plan = planner.invoke(prompt)
return {"plan": plan.steps}
def basic_executor_node(state: BasicPEState):
"""执行节点:执行计划中的步骤"""
console.print("--- (Basic) EXECUTOR: Executing plan... ---")
next_step = state["plan"][0]
result = flaky_web_search(next_step)
return {"plan": state["plan"][1:], "intermediate_steps": state["intermediate_steps"] + [result]}
def basic_synthesis_node(state: BasicPEState):
"""合成节点:综合中间结果生成最终答案"""
console.print("--- (Basic) SYNTHESIS: Synthesizing final answer... ---")
context = "\n".join(state["intermediate_steps"])
prompt = f"Synthesize an answer for '{state['user_request']}' using this data: \n{context}"
answer = llm.invoke(prompt).content
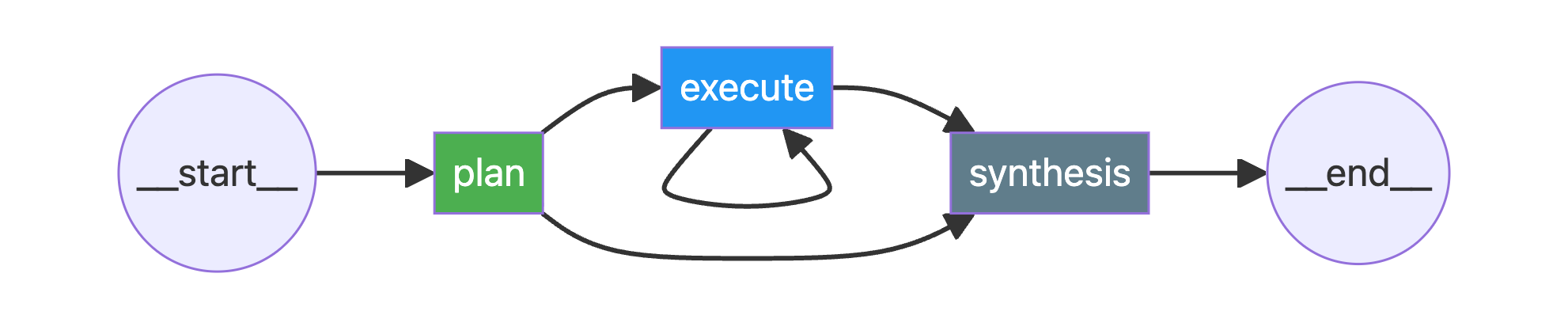
return {"final_ans": answer}基础 P-E Agent 的工作流图:
5.3 完整 PEV Agent 实现
class VerificationResult(BaseModel):
"""Verifier 输出的结构化模式"""
is_successful: bool = Field(
description="True if the tool execution's response is not null and the field 'results' is not null"
)
reasoning: str = Field(description="Reasoning for the verification decision.")
class PEVState(BasicPEState):
user_request: str
plan: Optional[List[str]]
last_tool_result: Optional[str]
intermediate_steps: List[str]
final_ans: Optional[str]
retries: int # 重试计数器
def pev_planner_node(state: PEVState):
"""PEV 规划节点:带重试限制"""
retries = state.get("retries", 0)
if retries > 3:
console.print("--- PLANNER: [bold red]Maximum retries exceeded. Aborting![/bold red] ---")
return {
"plan": [],
"final_ans": "Error: Unable to complete task after multiple retries."
}
console.print(f"--- (PEV) PLANNER: Creating/revising plan (retry {retries})... ---")
planner_llm = llm.with_structured_output(Plan, strict=True)
past_context = "\n".join(state["intermediate_steps"])
base_prompt = f"""
You are a planning agent.
Create a plan to answer: '{state['user_request']}'.
Use the 'flaky_web_search' tool.
Rules:
- Return ONLY valid JSON in this exact format: {{ "steps": ["query1", "query2"] }}
- Maximum 5 steps.
- Do NOT repeat failed queries or endless variations.
- Do NOT output explanations, only JSON.
Previous attempts and results:
{past_context}
"""
plan = planner_llm.invoke(base_prompt)
return {"plan": plan.steps, "retries": retries + 1}
def pev_executor_node(state: PEVState):
"""PEV 执行节点"""
if not state.get("plan"):
console.print("--- (PEV) EXECUTOR: [bold red]No plan provided. Aborting![/bold red] ---")
return {}
console.print("--- (PEV) EXECUTOR: Executing plan... ---")
next_step = state["plan"][0]
result = flaky_web_search(next_step)
return {"plan": state["plan"][1:], "last_tool_result": result}
def verify_node(state: PEVState):
"""验证节点:检查执行结果的有效性"""
console.print("--- (PEV) VERIFIER: Verifying tool output... ---")
verifier_llm = llm.with_structured_output(VerificationResult)
prompt = f"""Verify if the following tool output is a successful result or an error message.
The task was '{state['user_request']}'.
Tool Output: '{state['last_tool_result']}'"""
verification_result = verifier_llm.invoke(prompt)
console.print(f"--- VERIFIER: Judgment is '{'Success' if verification_result.is_successful else 'Failure'}' ---")
if verification_result.is_successful:
return {"intermediate_steps": state["intermediate_steps"] + [state["last_tool_result"]]}
else:
return {
"plan": [],
"intermediate_steps": state["intermediate_steps"] + [f"Verification Failed: {state['last_tool_result']}"]
}
def pev_router(state: PEVState):
"""路由函数:决定下一步走向"""
if state.get("final_ans"):
console.print("--- (PEV) ROUTER: [bold green]Final answer found. Aborting![/bold green] ---")
return "synthesis"
if not state["plan"]:
if state["intermediate_steps"] and "Verification Failed" in state["intermediate_steps"][-1]:
console.print("--- ROUTER: Verification failed. Re-planning... ---")
return "plan"
else:
console.print("--- ROUTER: Plan complete. Moving to synthesizer. ---")
return "synthesis"
else:
console.print("--- ROUTER: Executing next step... ---")
return "execute"PEV Agent 的工作流图:
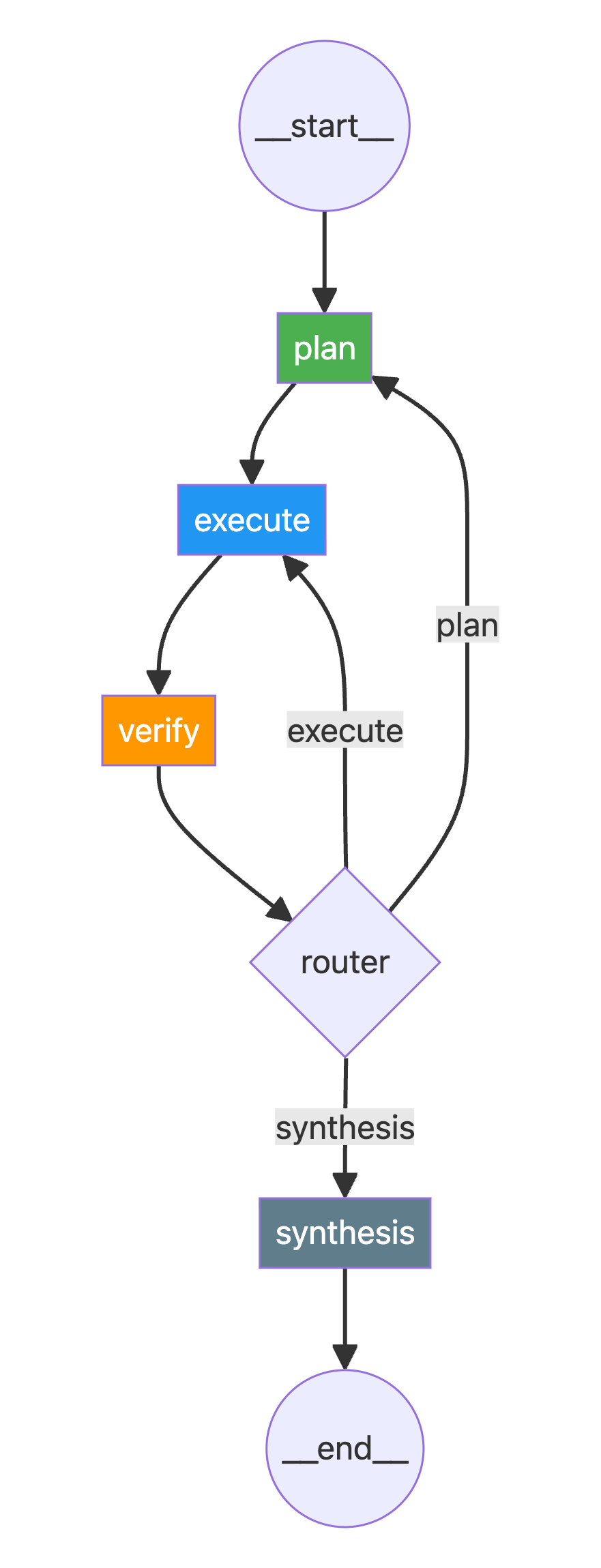
6. 运行结果对比
6.1 基础 P-E Agent 测试结果
测试查询:"What was Apple's R&D spend in their last fiscal year, and what was their total employee count? Calculate the R&D spend per employee."
Testing BASIC P-E agent on a flaky query:
--- (Basic) PLANNER: Creating plan... ---
--- (Basic) EXECUTOR: Executing plan... ---
--- TOOL: Searching for 'flaky_web_search: Apple 2025 Form 10-K "research and development"...' ---
DEBUG - Contains 'employee': False ✓
--- (Basic) EXECUTOR: Executing plan... ---
--- TOOL: Searching for 'flaky_web_search: Apple 2025 Form 10-K "number of employees"...' ---
DEBUG - Contains 'employee': True
--- TOOL: Simulating API failure! ❌
--- (Basic) EXECUTOR: Executing plan... ---
--- TOOL: Simulating API failure! ❌
--- (Basic) SYNTHESIS: Synthesizing final answer... ---结果:基础 Agent 无法识别工具错误,直接使用 LLM 的内置知识生成了答案,但由于缺少实际验证,结果可靠性存疑。
6.2 PEV Agent 测试结果
Testing PEV agent on the same flaky query:
--- (PEV) PLANNER: Creating/revising plan (retry 0)... ---
--- (PEV) EXECUTOR: Executing plan... ---
--- TOOL: Searching for 'Apple Form 10-K 2024 research and development expense total' ---
--- (PEV) VERIFIER: Verifying tool output... ---
--- VERIFIER: Judgment is 'Success' ✓
--- (PEV) EXECUTOR: Executing plan... ---
--- TOOL: Searching for 'Apple Form 10-K 2024 total number of employees' ---
--- TOOL: Simulating API failure! ❌
--- (PEV) VERIFIER: Verifying tool output... ---
verification_result: The tool output is an explicit error message...
--- VERIFIER: Judgment is 'Failure' ❌
--- ROUTER: Verification failed. Re-planning... ---
--- (PEV) PLANNER: Creating/revising plan (retry 1)... ---
[尝试新的查询策略...]
--- (PEV) PLANNER: Creating/revising plan (retry 2)... ---
[继续尝试...]
--- (PEV) PLANNER: Creating/revising plan (retry 3)... ---
[最后一次尝试...]
--- PLANNER: Maximum retries exceeded. Aborting! ---结果:PEV Agent 能够检测到 API 失败,触发重规划循环,尝试多种不同的查询策略。最终在达到重试上限后优雅终止,并向用户解释情况。
7. 量化评估
使用 LLM-as-Judge 方法评估两种 Agent 的鲁棒性:
class RobustnessEvaluation(BaseModel):
task_completion_score: int = Field(description="Score 1-10 on task completion")
error_handling_score: int = Field(description="Score 1-10 on error handling ability")
justification: str = Field(description="A brief Chinese justification for the scores")评估结果对比
| 指标 | Basic P-E Agent | PEV Agent | 差异 |
|---|---|---|---|
| 任务完成度 | 2/10 | 4/10 | +100% |
| 错误处理能力 | 3/10 | 6/10 | +100% |
评价详情
Basic P-E Agent:
代理在检索阶段显示出潜在的正确线索(包含10-K链接和Macrotrends等),但最终没有给出任何数值或计算结果,因此未完成任务。日志中出现了"API endpoint unavailable"错误,代理能检测到错误但没有采取有效的恢复措施:未尝试使用其他可用结果解析数据、未回退到次优信息来源、也未向用户说明并请求重试。
PEV Agent:
代理执行了多次检索并调用了权威来源(SEC、10-K PDF、q4cdn等),表明步骤合理且具有针对性,也能检测到"API endpoint unavailable"的错误并尝试重试与变更查询。虽然最终没有给出所需结果,但错误检测良好,展示了降级策略的尝试。
8. 核心原理图解
自我修正循环
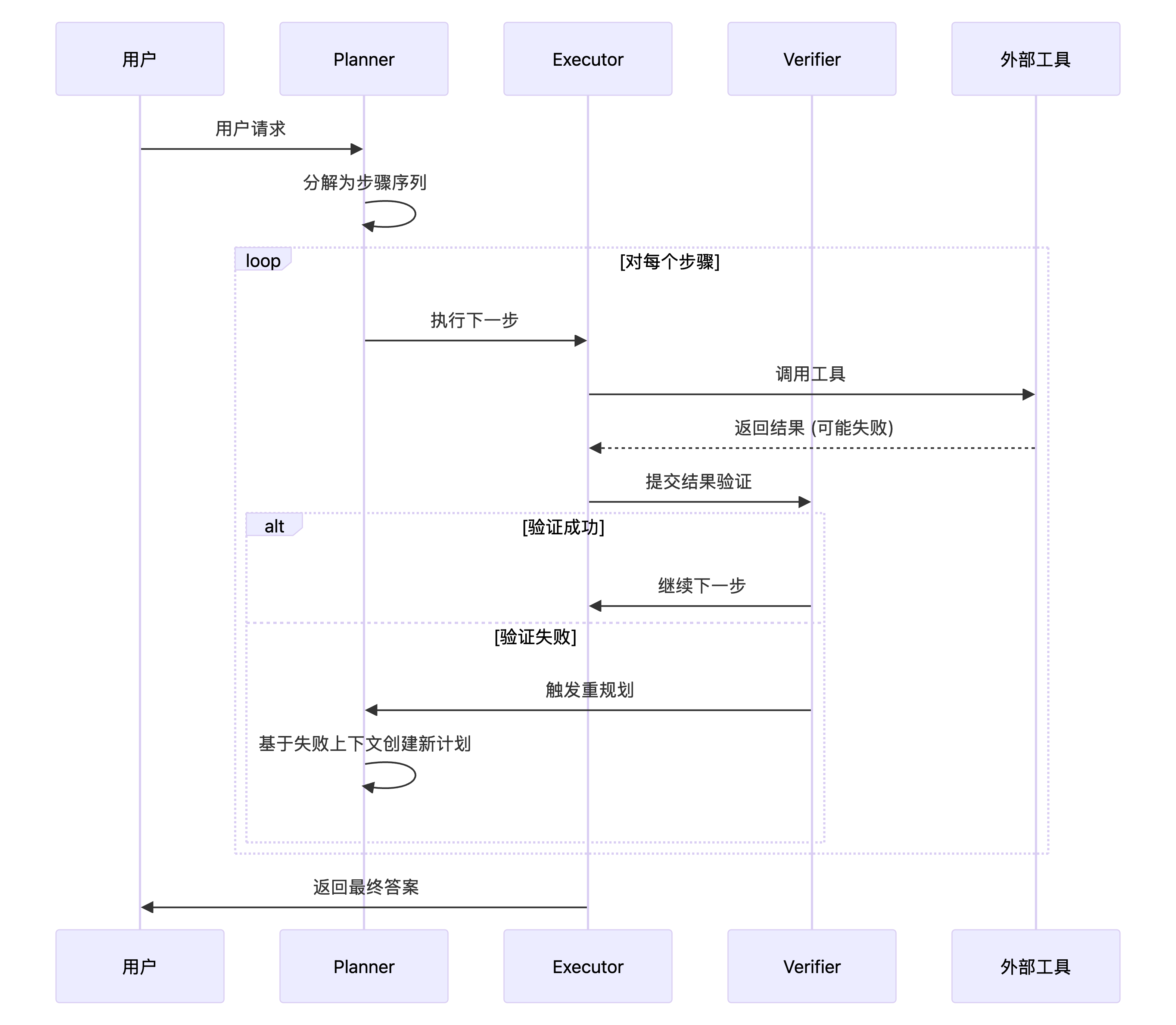
与其他架构的比较
| 特性 | Simple Agent | Planning Agent | PEV Agent |
|---|---|---|---|
| 计划能力 | ❌ | ✅ | ✅ |
| 错误检测 | ❌ | ❌ | ✅ |
| 自动恢复 | ❌ | ❌ | ✅ |
| LLM 调用次数 | 最少 | 中等 | 最多 |
| 可靠性 | 低 | 中 | 高 |
| 适用场景 | 简单任务 | 复杂任务 | 关键任务 |
9. 结论
PEV 架构通过引入专用的 Verifier 节点,为 AI Agent 提供了关键的"免疫系统",使其能够检测并从失败中恢复。
核心价值:
- 不仅仅是在一切顺利时获得正确答案
- 更重要的是在出错时不会得到错误答案
权衡考虑:
- 资源消耗更高(更多 LLM 调用)
- 但对于可靠性和准确性至关重要的应用,这种权衡是必要的
PEV 架构代表了构建真正可靠的 AI Agent 的重要一步,使其能够在外部工具和 API 的不可预测环境中安全有效地运行。
参考链接
[1] all-agentic-architectures: https://github.com/FareedKhan-dev/all-agentic-architectures/tree/main

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)