具身智能VLA论文系列解读(更新中)
标题:发布/更新时间: 2024.05首发,2025.08 最新版 (v5)为什么推荐:这是目前该领域引用率极高的一篇基础综述。它清晰地定义了 VLA 的概念,并把研究方向分为了三类:基于大型语言模型(LLM-based)、基于视觉语言模型(VLM-based)和从头训练的模型。它可以帮你理清 “VLA vs 传统控制” 的区别。你可以用它的分类逻辑来解释为什么现在的机器人比以前的更“聪明”(以前
本系列主要包含综述和经典模型的对应论文。
综述方面,我想通过两篇比较有代表性的具身智能方面的VLA综述,来详细了解相关发展,宏观了解各种模型的特性。所以我选取了一篇引用率非常高的,和一篇非常新的综述作为切入点,实现我的目的。
经典模型方面,目前解读了OpenVLA,后续准备继续解读pi系列等,读者有推荐的或者想看的都可以在下方评论留言。
文章目录
介绍与链接
1. VLA 领域的“百科全书”
标题: A Survey on Vision-Language-Action Models for Embodied AI,arXiv:2405.14093
-
发布/更新时间: 2024.05首发,2025.08 最新版 (v5)
-
为什么推荐:
-
这是目前该领域引用率极高的一篇基础综述。
它清晰地定义了 VLA 的概念,并把研究方向分为了三类:基于大型语言模型(LLM-based)、基于视觉语言模型(VLM-based)和从头训练的模型。 -
它可以帮你理清 “VLA vs 传统控制” 的区别。你可以用它的分类逻辑来解释为什么现在的机器人比以前的更“聪明”(以前是写死规则,现在是理解语言)。
-
2. 最新的“解剖学”视角(非常适合梳理技术栈)
-
发布时间: 2025.12 (非常新)
-
为什么推荐:
- 足够新,包含了很多最新的模型框架。
- 这篇文章非常有结构感,它像解剖一样把 VLA 拆解为:表示、执行、泛化、安全等模块。
3. OpenVLA
标题:OpenVLA: An Open-Source Vision-Language-Action Model, arXiv:2406.09246
-
发布时间: 2024.6首发,2024.8最新版(v3)
-
为什么推荐:
4. GR00T
标题:GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
-
发布时间: 2025.3
-
为什么推荐:
论文精读
① A Survey on Vision-Language-Action Models for Embodied AI
一、摘要与引言
-
背景 (Why Embodied AI?):
-
原文译意:具身智能被广泛认为是通往通用人工智能(AGI)的关键要素,因为它的核心在于控制智能体在物理世界中执行任务。
-
解读:这确立了VLA的地位——它不是像ChatGPT那样只处理信息的“大脑”,而是有身体、能干活的“实体”。
-
-
定义 (What is VLA?):
-
原文译意:建立在大语言模型(LLM)和视觉-语言模型(VLM)成功的基础上,一类新的多模态模型——视觉-语言-动作模型(VLAs)——应运而生。它利用生成动作的独特能力,解决了具身智能中受语言条件约束的机器人任务。
-
解读:VLA = 视觉 + 语言 + 动作生成。这是它与GPT-4V等模型的最大区别。
-
-
本文贡献 (What do we do?):
- 原文译意:这是关于具身智能VLA的第一篇综述。文章提供了一个详细的分类体系,分为三大主线:
-
组件:VLA的构成模块(如怎么看、怎么推理)。
-
控制策略:预测低层动作(如关节角度)的核心算法。
-
高层任务规划器:将长程任务(如“做早餐”)分解为子任务的模块。
-
资源与展望:
- 文章还总结了数据集、模拟器、基准测试,并讨论了未来的挑战。
为什么要研究VLA?这里解释了VLA诞生的技术逻辑。
- 从“缸中之脑”到“具身大脑”
-
核心观点:VLA是一类能同时处理视觉、语言和动作的模型。
-
对比:
-
传统对话AI:如ChatGPT,主要处理文本,像“缸中之脑”。
-
VLA:必须感知环境并控制物理实体。
-
-
挑战:在“语言条件下的机器人任务”中,模型必须同时具备:1. 语言理解;2. 视觉感知;3. 动作生成。
- VLA的优越性
-
术语起源:VLA这个词最早是由谷歌的 RT-2 (Robotic Transformer 2) 提出的。
-
核心优势:相比传统的“深度强化学习(Deep RL)”,VLA具有更强的:
-
通用性:能干多种活。
-
灵巧性:动作更细腻。
-
泛化能力:这一条最重要。以前的机器人换个桌子就不会抓了,VLA依靠大模型的知识,能适应新环境。
-
- 深度学习的演进历史
-
逻辑链条:
-
单模态时代:AlexNet(看图)、RNN(读文)、DQN(玩游戏)。
-
多模态时代:Transformer的出现统一了架构,催生了像CLIP这样的模型。
-
VLA时代:将这种多模态能力引入机器人控制。
-
- 第四段:传统方法的瓶颈
-
痛点:传统的机器人策略通常是在受控环境中针对特定任务训练的。
-
需求:我们想要的是通用的、能听懂人话的机器人。比如你说“帮我拿瓶水”,它能理解并执行,而不是需要程序员写代码来控制。这推动了“语言条件策略”的发展。
VLA的全景分类体系
VLA通用架构图:
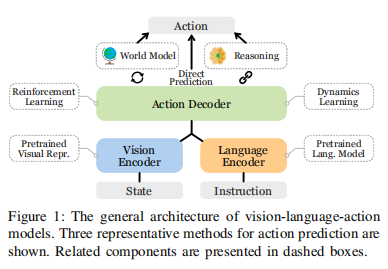

作者把所有相关的论文和模型归纳进了三条主线,就像把机器人拆解成了三个部分:
-
支柱一:组件 —— “器官”
这部分研究机器人的“零件”。比如:眼睛怎么看(视觉表征)、脑子怎么转(推理)、怎么预知未来(世界模型)。如果你想改进 VLA 的某个具体能力(比如让它看懂透明玻璃),你就关注这一块。
-
支柱二:控制策略 —— “小脑与脊髓”
这部分是 VLA 的本体。输入是图像和指令,输出直接是动作。而作者把这里分成了两派:
-
Transformer派:像做完形填空一样预测动作(如 RT-2)。
-
Diffusion派:像画图一样生成动作轨迹(如 Octo)。
-
-
支柱三:任务规划器—— “大脑皮层”
这部分负责宏观指挥。当任务很长(比如“把厨房收拾干净”)时,底层的 VLA 搞不定。这时需要一个 Planner 把大任务切分成小任务(“去水槽” -> “拿海绵” -> “擦桌子”)。事实上,这里主要研究如何把 GPT-4 这种纯语言模型接入到机器人系统里。
VLA 的发展时间线
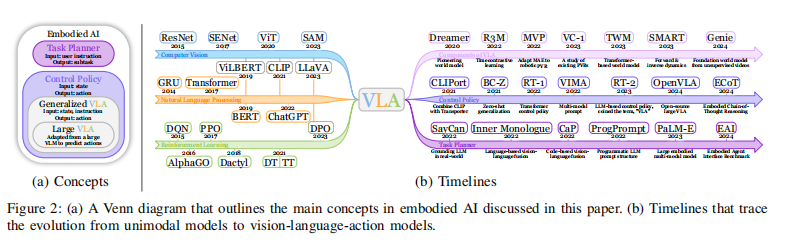
这张图分为两个部分:
-
图 2(a) - 韦恩图:
目的:解决概念混淆。
内容:它画了几个圈,解释了 “Large VLA” (大模型VLA) 和 “General VLA” (通用VLA) 的关系。
核心定义:作者提出,VLA 是一个广义概念,指任何“视觉+语言->动作”的模型。而像 RT-2 这种基于 LLM 微调的,被特指为 “Large VLA”(类似 LLM 之于 LM)。
-
图 2(b) - 时间线:
展示了三条平行进化的路线,最终汇聚成 VLA:
单模态 (Unimodal):ResNet, BERT。
多模态 (Multimodal):CLIP, ViLBERT。
具身智能 (Embodied AI):DQN -> Gato -> RT-2。
2022年之前:主要是传统的 BC(行为克隆)和 RL(强化学习)。
2022年转折点:Gato 和 RT-1 出现。Gato 证明了一个模型可以同时玩游戏、聊代天、控制机器人;RT-1 证明了 Transformer 可以控制真机器人。
2023年爆发:PaLM-E、RT-2、VoxPoser 井喷。大模型正式接管机器人身体。
二、VLA模型
核心问题:机器人应该怎么“看”世界?
普通的计算机视觉(比如 ImageNet 分类)只能告诉机器人“这是一瓶水”。但这对机器人不够,机器人需要知道“瓶盖在哪”、“有多重”、“能不能捏扁”。因此论文对比了三种视觉编码器的进化路线:
第一代:通用视觉
-
代表:ImageNet 预训练的 ResNet。
-
缺点:懂分类,不懂物理。它知道那是“锤子”,但不知道“锤柄”是用来抓的地方。
第二代:语义对齐
-
代表:CLIP (OpenAI)。
-
原理:用互联网上海量的“图-文”对进行训练。
-
优势:懂语义。如果你告诉机器人“捡起那个毛茸茸的东西”,虽然机器人从没见过这个玩偶,但 CLIP 能把“毛茸茸”和视觉特征对齐,机器人就能做对。
-
局限:对空间位置不敏感。
第三代:具身视觉
-
代表:R3M (Representation for Robot Manipulation), VIP.
-
核心逻辑:不再看静态图,而是看视频(Ego4D数据集,人类第一人称视角的做事视频)。
-
R3M:通过对比学习,学习视频中手和物体的交互。它能理解“手靠近杯子” -> “手接触杯子” -> “杯子被拿起”的过程。
-
VIP:引入了价值的概念。它把图像编码成一个“距离目标的进度条”。如果你离目标越近,VIP 输出的特征值就越代表“高价值”,这对机器人做决策是非常强大的辅助。
An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
OpenVLA: An Open-Source Vision-Language-Action Model
详见我的另一篇文章:OpenVLA学习记录(论文解读与复现微调)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)