MatchTIR:用二分匹配解决LLM工具调用的“吃大锅饭“难题
MatchTIR 提出用**二分匹配**(Hungarian算法/最优传输)来给多轮工具调用中的每一步精确打分,配合**双重级优势估计**,让4B小模型在复杂工具使用任务上干翻一众8B大模型。
MatchTIR:用二分匹配解决LLM工具调用的"吃大锅饭"难题
一句话总结:MatchTIR 提出用二分匹配(Hungarian算法/最优传输)来给多轮工具调用中的每一步精确打分,配合双重级优势估计,让4B小模型在复杂工具使用任务上干翻一众8B大模型。
论文信息:
- 标题:MatchTIR: Fine-Grained Supervision for Tool-Integrated Reasoning via Bipartite Matching
- 作者:中国人民大学高瓴人工智能学院 & 百度公司
- arXiv:https://arxiv.org/abs/2601.10712
📖 背景:从DETR到MatchTIR,二分匹配的跨界应用
工具集成推理(TIR)的现状
大语言模型(LLM)越来越多地被用来调用外部工具——查天气、搜资料、执行代码、调API。这种能力叫做工具集成推理(Tool-Integrated Reasoning, TIR)。
一个典型的TIR任务长这样:
用户问题: "北京今天天气怎么样?气温适合穿什么衣服?"
模型执行轨迹:
Turn 1: 思考 → 调用天气API(city="北京") → 获得结果
Turn 2: 思考 → 调用穿衣建议API(temp=15) → 获得结果
Turn 3: 思考 → 生成最终答案
DeepSeek R1带火GRPO之后,Agent Tool Use Learning也开始用上了各种强化学习算法——GRPO、Reinforce++、PPO、Policy Gradient等。以前训练工具调用能力主要靠SFT+DPO,需要大量标注数据来cover各种bad case,现在用RL可以让模型在试错中自我进化。
单轮工具调用相对简单,多轮就麻烦多了:数据难获取、建模方式不清晰(MDP只看当前状态,还是用Full History看所有历史?),这是一个新兴的研究方向。
问题出在哪?信用分配的"大锅饭"困境
现有方法在给奖励时有个大问题:“吃大锅饭”——所有步骤拿同样的奖励,无法区分关键步骤和冗余步骤。
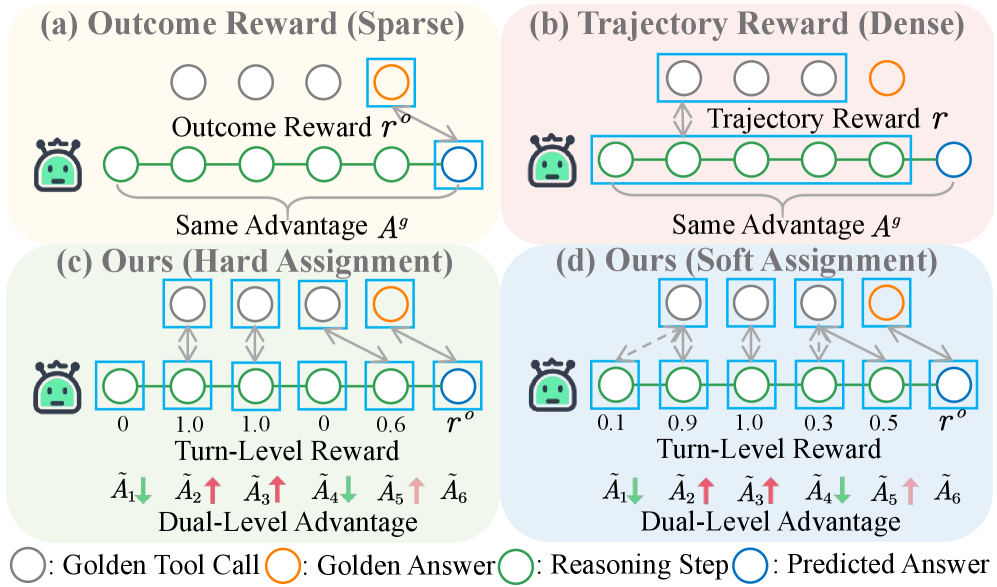
图1:四种奖励和优势分配策略的对比。(a)结果奖励只看最终答案对不对;(b)轨迹奖励给整条轨迹一个分数;©和(d)是MatchTIR提出的方法,能给每一轮不同的奖励和优势值。
上图展示了四种策略:
-
(a) 结果奖励(Outcome Reward):只看最终答案对不对。模型调了10次工具,只要最后答案对了,所有步骤都拿同样的奖励。就像考试只看总分,不管你是靠数学还是语文得分的。
-
(b) 轨迹奖励(Trajectory Reward):给整条轨迹一个总分,然后平均分给每一步。比(a)好一点,但本质上还是"平均主义"——调对了的工具和调错了的工具,拿的奖励一样多。
这种粗粒度的信用分配在简单任务上还能凑合,但遇到长轨迹、多轮交互的复杂任务时就崩了。
想象一个需要调用8次工具的复杂任务:
- 模型调对了6次,调错了2次,但最后答案还是对的
- 用现有方法,错误的2次调用也会得到正向奖励
- 训练多了之后,模型学到的是"差不多就行",而不是"每一步都要精准"
这就是强化学习中经典的信用分配问题(Credit Assignment Problem, CAP)。这个问题可以追溯到1984年Sutton的论文《Temporal Credit Assignment in Reinforcement Learning》。在多智能体强化学习(MARL)中,这个问题更加突出——多个Agent共同影响全局奖励,如何找到每个Agent的具体贡献?
灵感来源:DETR的二分匹配损失
MatchTIR的核心思路并非凭空而来。在计算机视觉领域,Facebook的**DETR(Detection Transformer)**用二分匹配彻底革新了目标检测:
- 传统方法:生成大量候选框 → NMS去重 → 预测类别
- DETR:直接预测N个框 → 用二分匹配与Ground Truth一一对应 → 计算损失
DETR的关键洞察是:目标检测本质上是一个集合预测问题(Set Prediction),预测的框和真实的框之间需要找到最优匹配。
MatchTIR把这个思路迁移到了工具调用:
- 传统方法:给整条轨迹一个奖励 → 平均分给每一步
- MatchTIR:预测的工具调用与真实的工具调用做二分匹配 → 根据匹配质量给每一步精确打分
这种"借鉴CV思路解决NLP问题"的跨界思维,是这篇论文最有意思的地方。
🎯 核心思路:把信用分配建模为二分匹配问题
什么是二分匹配?
假设你是婚介所的老板,手上有5个男生和5个女生,每对之间都有个"匹配度"分数。你的目标是把他们配成5对,让总匹配度最高。
这就是经典的二分匹配问题,可以用匈牙利算法高效求解。
匈牙利算法(Hungarian Algorithm),也叫Kuhn-Munkres算法,是一种在多项式时间内( O ( n 3 ) O(n^3) O(n3))求解任务分配问题的组合优化算法。它的核心思路是:
- 构造一个初始可行解
- 通过找增广路径(从一个未匹配点出发,通过交错路径到达另一个未匹配点)逐步改进
- 直到找不到增广路径为止
MatchTIR的核心洞察是:工具调用的信用分配,本质上也是一个匹配问题。
- 一边是模型预测的工具调用(可能有对有错,可能多调了几次)
- 一边是真实应该调用的工具(ground truth)
- 目标是找到最优的匹配关系,然后根据匹配质量给每个预测调用打分
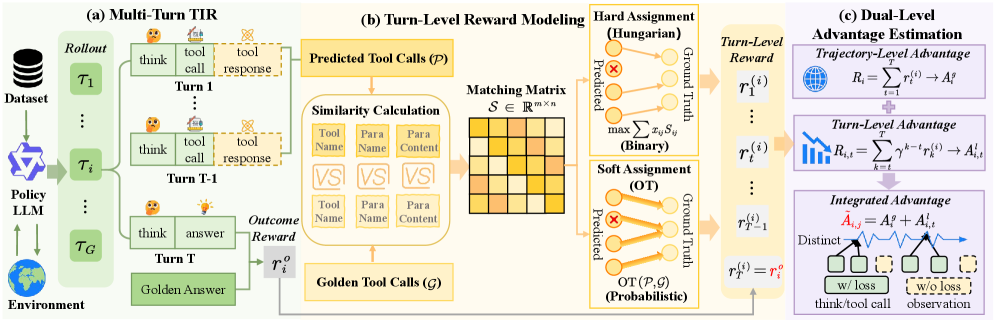
图2:MatchTIR框架全景图。左边是多轮TIR的执行过程;中间是基于二分匹配的轮级奖励建模(支持硬分配和软分配);右边是双重级优势估计。
🏗️ 方法详解:怎么匹配,怎么打分?
任务形式化
给定用户查询 q q q 和工具集 T \mathcal{T} T,目标是生成交互轨迹 τ = { s 1 , s 2 , … , s T } \tau=\{s_1, s_2, \dots, s_T\} τ={s1,s2,…,sT}。每个交互轮次 s i = ( n i , c i , o i ) s_i=(n_i, c_i, o_i) si=(ni,ci,oi) 包含:
- n i n_i ni:自然语言推理(思考过程)
- c i c_i ci:调用的工具及参数
- o i o_i oi:环境返回的观察结果
模型需要学会在每一轮做出正确的决策:该调什么工具?传什么参数?
4.1 相似度矩阵:评估每个工具调用的质量
给定模型预测的工具调用集合 P = { p 1 , . . . , p m } \mathcal{P}=\{p_1, ..., p_m\} P={p1,...,pm} 和真实工具调用集合 G = { g 1 , . . . , g n } \mathcal{G}=\{g_1, ..., g_n\} G={g1,...,gn},我们需要计算一个 m × n m \times n m×n 的相似度矩阵 S S S。
每个元素 S i j S_{ij} Sij 衡量预测调用 p i p_i pi 和真实调用 g j g_j gj 的匹配程度,由三个部分组成:
| 维度 | 计算方式 | 直觉理解 |
|---|---|---|
| 工具名称 S t n S_{tn} Stn | 名字对了给1分,错了给0分 | 你调的是对的API吗? |
| 参数名称 S p n S_{pn} Spn | Jaccard相似度:$\frac{ | N_p \cap N_g |
| 参数内容 S p c S_{pc} Spc | 正确参数值的数量 | 参数的值对不对? |
最终相似度公式:
S i j = S t n ⋅ S t n + S p n + S p c 1 + 1 + ∣ N g j ∣ S_{ij} = S_{tn} \cdot \frac{S_{tn} + S_{pn} + S_{pc}}{1 + 1 + |N_{g_j}|} Sij=Stn⋅1+1+∣Ngj∣Stn+Spn+Spc
这个公式有几个巧妙的设计:
-
工具名称是乘法门控:如果 S t n = 0 S_{tn}=0 Stn=0(工具调错了),整个分数直接归零。这保证了调错工具不会因为"参数碰巧对了几个"而得到奖励。
-
参数名和参数值是加法关系:允许"名字对了但值错了"的情况拿部分分,提供更细粒度的反馈。
-
归一化到[0,1]区间:分母是 1 + 1 + ∣ N g j ∣ 1 + 1 + |N_{g_j}| 1+1+∣Ngj∣,确保分数在合理范围内。
举个例子:假设真实调用是 get_weather(city="北京", date="今天"),模型预测是 get_weather(city="北京", date="明天"):
- S t n = 1 S_{tn} = 1 Stn=1(工具名对了)
- S p n = 1 S_{pn} = 1 Spn=1(参数名都对了:city和date)
- S p c = 1 S_{pc} = 1 Spc=1(只有city的值对了)
- 最终 S = 1 ⋅ 1 + 1 + 1 1 + 1 + 2 = 0.75 S = 1 \cdot \frac{1+1+1}{1+1+2} = 0.75 S=1⋅1+1+21+1+1=0.75
4.2 硬分配:一对一的严格匹配(Hungarian算法)
硬分配用匈牙利算法找到最优的一对一匹配:
M ∗ = arg max M ∑ ( i , j ) ∈ M S i j \mathcal{M}^* = \arg\max_{\mathcal{M}} \sum_{(i,j) \in \mathcal{M}} S_{ij} M∗=argMmax(i,j)∈M∑Sij
这个优化问题的含义是:在所有可能的一对一匹配中,找到总相似度最高的那个。
找到最优匹配后,奖励这么分配:
- 匹配上了: r p i = S i j r_{p_i} = S_{ij} rpi=Sij(匹配质量就是奖励)
- 没匹配上: r p i = − λ r_{p_i} = -\lambda rpi=−λ(惩罚项,避免乱调工具)
惩罚参数 λ \lambda λ 很关键:
- λ \lambda λ 越大,对冗余工具调用的惩罚越重
- 可以调节模型在"召回率"和"精确率"之间的权衡
为什么选择匈牙利算法?
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 贪心匹配 | 计算快 O ( m n ) O(mn) O(mn) | 非全局最优 | 实时系统 |
| 匈牙利算法 | 全局最优一对一 | 严格,不允许一对多 | 大多数TIR任务 |
| 穷举 | 一定最优 | O ( n ! ) O(n!) O(n!)不可行 | 理论分析 |
实验显示,匈牙利算法(硬分配)在绝大多数情况下效果最好。这是因为工具调用本身就是离散的决策——你要么调对了API,要么没调对,中间态很少见。
4.3 软分配:基于最优传输的概率匹配
有些情况下,一对一匹配太严格了。比如模型调用了一个通用搜索API,真实答案是调两个细分API——这时候这个搜索调用应该得到部分信用。
软分配用**最优传输(Optimal Transport, OT)**来解决这个问题。
最优传输的直觉:想象你要把一堆沙子从若干个起点搬到若干个终点,每条路径有不同的运输成本,你要找到总成本最低的运输方案。这个方案可以是"分批运输"——一个起点的沙子可以分到多个终点。
具体实现:
- 把相似度矩阵 S S S 转化为代价矩阵 C C C(用归一化指数变换): C i j = e − S i j / τ ∑ k e − S i k / τ C_{ij} = \frac{e^{-S_{ij}/\tau}}{\sum_k e^{-S_{ik}/\tau}} Cij=∑ke−Sik/τe−Sij/τ
- 求解最优传输问题(可以用Sinkhorn算法高效求解),得到传输计划矩阵 Z \mathcal{Z} Z
- 奖励: r p i = ∑ j Z i j ⋅ S i j r_{p_i} = \sum_j Z_{ij} \cdot S_{ij} rpi=∑jZij⋅Sij
直觉上理解: Z i j Z_{ij} Zij 表示预测调用 p i p_i pi 有多少"功劳"应该分配给真实调用 g j g_j gj。软分配允许一个预测调用的功劳分散到多个真实调用上,反之亦然。
硬分配 vs 软分配的选择:
实验结果显示,硬分配(KM)普遍优于软分配(OT)。为什么?
因为工具调用场景下,"调对工具"和"调错工具"通常是非黑即白的:
- 调用
get_weather和get_stock_price完全是两回事 - 不存在"调了get_weather但其实有50%是get_stock_price"这种情况
软分配更适合那些边界模糊的场景,比如:
- 一个复杂查询可以用一个大API搞定,也可以用多个小API组合
- 不同工具之间有功能重叠
4.4 轮级奖励的计算
一个turn里可能包含多个工具调用。轮级奖励取该turn内所有工具调用奖励的平均值:
r t = 1 ∣ C t ∣ ∑ c ∈ C t r c r_t = \frac{1}{|C_t|} \sum_{c \in C_t} r_c rt=∣Ct∣1c∈Ct∑rc
其中 C t C_t Ct 是第 t t t 轮的所有工具调用集合。
同时,模型的最终答案也需要评分。这里用的是F1分数来计算结果级奖励 r o r^o ro:
r o = F1 ( predicted_answer , golden_answer ) r^o = \text{F1}(\text{predicted\_answer}, \text{golden\_answer}) ro=F1(predicted_answer,golden_answer)
F1分数综合考虑了精确率和召回率,比简单的Exact Match更细腻。
4.5 双重级优势估计:兼顾局部和全局
有了每一轮的奖励,下一个问题是:怎么把这些奖励转化为强化学习中的"优势(Advantage)"?
在GRPO算法中,优势函数用于指导策略更新——优势为正的动作应该被鼓励,优势为负的动作应该被抑制。
传统GRPO的做法是:给整条轨迹算一个优势值,然后所有token共享这个值。这就是"吃大锅饭"的根源。
MatchTIR提出双重级优势估计(Dual-Level Advantage Estimation),同时考虑两个维度:
轨迹级优势(Trajectory-Level Advantage) A i g A_i^g Aig:
R i = ∑ t = 1 T r i , t + r i o R_i = \sum_{t=1}^{T} r_{i,t} + r_i^o Ri=t=1∑Tri,t+rio
A i g = R i − μ R σ R A_i^g = \frac{R_i - \mu_R}{\sigma_R} Aig=σRRi−μR
这里 R i R_i Ri 是第 i i i 条轨迹的总奖励, μ R \mu_R μR 和 σ R \sigma_R σR 是同一组rollout中所有轨迹奖励的均值和标准差。
这个信号告诉模型:“你这条轨迹整体比别的好还是差?”——提供全局视角。
轮级优势(Turn-Level Advantage) A i , t l A_{i,t}^l Ai,tl:
R i , t l = ∑ k = t T γ k − t r i , k + γ T − t + 1 r i o R_{i,t}^l = \sum_{k=t}^{T} \gamma^{k-t} r_{i,k} + \gamma^{T-t+1} r_i^o Ri,tl=k=t∑Tγk−tri,k+γT−t+1rio
A i , t l = R i , t l − μ R t l σ R t l A_{i,t}^l = \frac{R_{i,t}^l - \mu_{R_t^l}}{\sigma_{R_t^l}} Ai,tl=σRtlRi,tl−μRtl
这里引入了折扣因子 γ \gamma γ,用于计算从当前轮次开始的折现累积奖励。
这个公式值得仔细品味:
- γ k − t \gamma^{k-t} γk−t 对未来奖励做折扣,越远的奖励权重越小
- γ T − t + 1 r i o \gamma^{T-t+1} r_i^o γT−t+1rio 把最终答案的奖励也纳入考虑
- 归一化是在同一位置的不同轨迹之间进行的
这个信号告诉模型:“你这一步的决定,对后续有多大影响?”——捕捉局部决策的长期价值。
整合优势:直接相加
A ~ i , j = A i g + A i , t l \tilde{A}_{i,j} = A_i^g + A_{i,t}^l A~i,j=Aig+Ai,tl
为什么这么设计?因为两个信号互补:
- 轨迹级优势避免模型只盯着单步优化,忽视全局目标
- 轮级优势让模型学会区分每一步的贡献差异
这种设计借鉴了强化学习中**GAE(Generalized Advantage Estimation)**的思想,但做了适应TIR场景的改造。
4.6 策略优化
最后,在GRPO目标函数中使用整合优势 A ~ i , j \tilde{A}_{i,j} A~i,j 替代原有的统一优势:
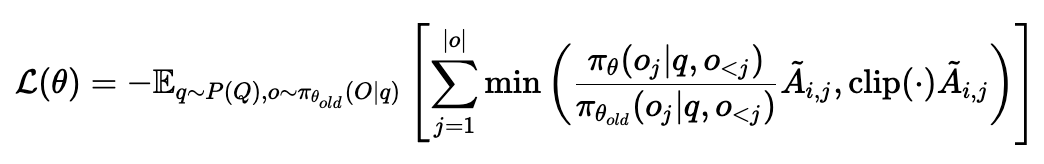
这个目标函数和PPO类似,但关键区别在于:每个token位置 j j j 都有自己的优势值 A ~ i , j \tilde{A}_{i,j} A~i,j,而不是共享同一个值。
🧪 实验结果:4B模型干翻8B
实验设置
- 训练数据:FTRL数据集(2000+自动构建的工具使用环境)
- 评估基准:
- FTRL(领域内):工具调用基准,评估工具使用能力
- BFCL(领域外):Berkeley Function Calling Leaderboard,测试多轮Agent能力
- ToolHop(领域外):专注于多跳工具使用,需要串联多个工具完成复杂任务
- 基线方法:
- Vanilla:基础SFT模型
- GRPO:标准GRPO训练
- ToolRL:专门针对工具调用的RL方法
- FTRL:FTRL论文提出的方法
- 模型:Qwen3-4B 和 Qwen3-8B
- 训练超参数:学习率 1 × 10 − 6 1 \times 10^{-6} 1×10−6,batch size 128,rollout数 G=4
主要结果
| 模型 | 方法 | FTRL Solve-R | FTRL Solve-P | BFCL | ToolHop |
|---|---|---|---|---|---|
| Qwen3-4B | Vanilla | 38.3 | 33.2 | 50.4 | 24.9 |
| Qwen3-4B | GRPO | 40.0 | 34.5 | 51.6 | 26.2 |
| Qwen3-4B | ToolRL | 41.2 | 35.8 | 51.6 | 26.4 |
| Qwen3-4B | FTRL | 41.5 | 36.0 | 52.8 | 27.1 |
| Qwen3-4B | MatchTIR-OT | 43.8 | 37.2 | 54.6 | 28.3 |
| Qwen3-4B | MatchTIR-KM | 45.4 | 38.1 | 55.9 | 29.5 |
| Qwen3-8B | Vanilla | 42.2 | 36.8 | 51.1 | 26.9 |
| Qwen3-8B | GRPO | 43.4 | 37.5 | 51.5 | 28.6 |
| Qwen3-8B | ToolRL | 45.1 | 38.2 | 52.3 | 29.8 |
| Qwen3-8B | FTRL | 46.3 | 39.1 | 53.8 | 31.2 |
| Qwen3-8B | MatchTIR-OT | 47.8 | 40.3 | 55.4 | 32.5 |
| Qwen3-8B | MatchTIR-KM | 49.2 | 41.2 | 56.7 | 33.9 |
几个关键发现:
1. 4B小模型超越8B大模型
MatchTIR-4B的Solve-R (45.4%) 超过了GRPO-8B (43.4%)、ToolRL-8B (45.1%),甚至接近FTRL-8B (46.3%)。
这说明:细粒度监督带来的训练效率提升,可以弥补模型规模的差距。对于资源有限的团队来说,这是个好消息——不用堆参数,优化训练方法也能拿到好效果。
2. 硬分配(KM)普遍优于软分配(OT)
在所有指标上,MatchTIR-KM都比MatchTIR-OT高1-2个点。这验证了前面的分析:工具调用是离散决策,严格的一对一匹配更合适。
3. 领域外泛化能力强
BFCL和ToolHop是模型从未见过的数据集,但MatchTIR依然有明显提升。这说明学到的不是对特定数据集的过拟合,而是更通用的工具使用能力。
任务复杂度分析:越难的任务,优势越大
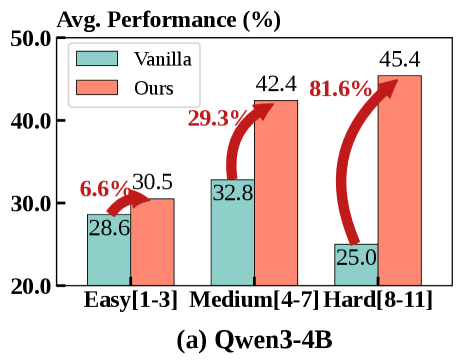
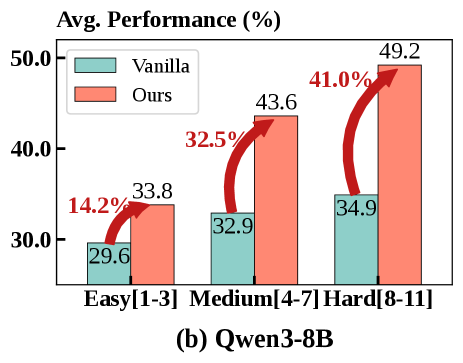
图3-4:按工具调用次数划分任务难度(Easy: 1-3次, Medium: 4-7次, Hard: 8-11次)。MatchTIR在困难任务上的相对提升最大。
这两张图揭示了一个重要规律:
| 任务难度 | 工具调用次数 | Qwen3-4B相对提升 | Qwen3-8B相对提升 |
|---|---|---|---|
| Easy | 1-3次 | +6.6% | +14.2% |
| Medium | 4-7次 | +29.3% | +32.5% |
| Hard | 8-11次 | +81.6% | +41.0% |
任务越复杂,MatchTIR的优势越明显。
这正好印证了核心假设:
- 简单任务只需调1-3次工具,"吃大锅饭"问题不突出——即使奖励分配不精确,模型也能学会
- 复杂任务需要调8-11次工具,必须精确归因才能学好——这时候MatchTIR的细粒度监督优势就体现出来了
4B模型在Hard任务上的81.6%提升尤其惊人,这意味着原来基本做不对的复杂任务,现在有了突破。
消融实验:每个组件都有用
| 配置 | FTRL Solve-R | FTRL Solve-P | BFCL |
|---|---|---|---|
| 仅结果奖励 | 40.0 | 34.5 | 51.6 |
| 仅轨迹奖励 | 40.1 | 34.7 | 52.9 |
| 轨迹奖励+结果奖励 | 40.5 | 35.0 | 52.9 |
| 仅轮级奖励 | 42.0 | 36.3 | 53.9 |
| 轮级奖励+结果奖励(无双重优势) | 43.5 | 37.4 | 54.8 |
| 轮级奖励+结果奖励+双重优势 | 45.4 | 38.1 | 55.9 |
消融实验表明:
- 奖励粒度:轮级奖励 > 轨迹级奖励 > 结果奖励
- 奖励组合:轮级奖励+结果奖励的组合效果最好
- 优势估计:双重级优势比单一优势提升约2个点
这说明MatchTIR的两个核心创新——二分匹配奖励和双重优势估计——都有独立贡献。
优势估计方式的深入分析
论文还对比了不同的优势估计方式:
| 优势估计方法 | FTRL Solve-R | BFCL |
|---|---|---|
| 仅轨迹级优势 | 42.8 | 54.1 |
| 仅轮级优势 | 43.2 | 54.5 |
| 轨迹内加权(每轮不同权重) | 43.5 | 54.7 |
| 双重级优势(组间比较) | 45.4 | 55.9 |
有意思的是,“轨迹内加权"方法(给同一轨迹内的不同轮次分配不同权重)效果不如"双重级优势”(在不同轨迹之间做比较)。
为什么?因为轨迹内加权只能区分"这一步比上一步好/差",但无法区分"这条轨迹的这一步比另一条轨迹的同位置步骤好/差"。后者提供了更丰富的对比信号。
超参数敏感性分析
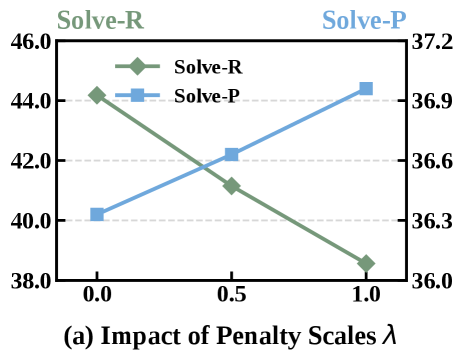
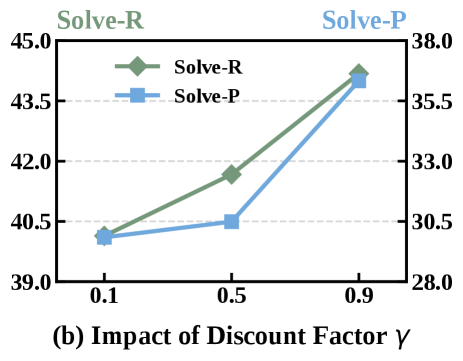
图5-6:惩罚系数 λ \lambda λ 和折扣因子 γ \gamma γ 的影响。
惩罚系数 λ \lambda λ(图5):
| λ \lambda λ | Solve-R | Solve-P | 分析 |
|---|---|---|---|
| 0.0 | 44.5 | 36.2 | 不惩罚冗余调用,召回高但精确率低 |
| 0.5 | 45.4 | 37.8 | 平衡点 |
| 1.0 | 43.8 | 38.5 | 惩罚过重,可能抑制必要的工具调用 |
λ \lambda λ 控制"不匹配的工具调用"的惩罚力度:
- λ \lambda λ 太小:模型倾向于"多调几次保险",精确率低
- λ \lambda λ 太大:模型倾向于"少调为妙",召回率低
- 0.5左右是个好的平衡点
折扣因子 γ \gamma γ(图6):
| γ \gamma γ | Solve-R | Solve-P | 分析 |
|---|---|---|---|
| 0.1 | 42.5 | 35.8 | 只看眼前,忽视长期影响 |
| 0.5 | 43.8 | 37.2 | 中等程度考虑未来 |
| 0.9 | 45.4 | 38.1 | 充分考虑长期影响 |
γ = 0.9 \gamma = 0.9 γ=0.9 效果最好,这说明:TIR任务中长期依赖很重要。
直觉上理解:如果你第3轮调错了工具,可能导致第5轮拿不到正确信息,最终答案也错。这种"蝴蝶效应"需要高折扣因子才能捕捉到。
工具使用效率和准确性
| 方法 | 平均工具调用次数 | 工具调用成功率 | 冗余调用比例 |
|---|---|---|---|
| Vanilla | 4.2 | 68.3% | 23.5% |
| GRPO | 4.0 | 71.5% | 19.2% |
| ToolRL | 3.9 | 73.8% | 16.8% |
| MatchTIR | 3.6 | 78.2% | 11.3% |
MatchTIR训练出的模型有三个显著特点:
- 调用次数更少:平均3.6次 vs Vanilla的4.2次
- 成功率更高:78.2% vs Vanilla的68.3%
- 冗余调用更少:11.3% vs Vanilla的23.5%
这说明模型学会了"精准出击",而不是"广撒网"。细粒度的奖励信号让模型明白:每一次工具调用都有成本,要调就要调对。
🔬 技术细节讨论
为什么MatchTIR有效?直觉解释
让我用一个类比来解释MatchTIR为什么有效:
想象你在教一个学生做数学题。传统方法相当于:
- 学生做了10道题,对了8道,你给他80分
- 但你不告诉他哪道对了哪道错了
MatchTIR相当于:
- 学生做了10道题,你把他的答案和标准答案一一对比
- 第1题对了+10分,第3题方法对了但答案算错了+5分,第5题完全错了-2分…
- 学生清楚地知道每一步该怎么改进
这种精细的反馈,让学习效率大大提高。
与DETR的对比:同源但有差异
| 维度 | DETR | MatchTIR |
|---|---|---|
| 任务 | 目标检测 | 工具调用 |
| 匹配对象 | 预测框 vs GT框 | 预测工具调用 vs GT工具调用 |
| 匹配目标 | 最小化损失 | 最大化奖励 |
| 匹配粒度 | 图像级 | 轨迹级 |
| 应用阶段 | 训练时计算loss | RL训练时计算reward |
关键差异:
- DETR的匹配是为了计算损失函数,用于梯度下降
- MatchTIR的匹配是为了计算奖励,用于策略梯度
与其他细粒度奖励方法的对比
| 方法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 过程奖励模型(PRM) | 训练额外模型评估每一步 | 可以学到复杂的评估标准 | 需要大量人工标注;可能产生幻觉;增加计算开销 |
| 蒙特卡洛采样 | 多次rollout估计每一步价值 | 无偏估计 | 计算成本高(需要多次执行);方差大 |
| COMA | 用反事实基线估计贡献 | 理论优雅 | 需要训练Critic网络;在LLM场景计算量大 |
| MatchTIR | 利用TIR的结构化信号直接匹配 | 无需额外模型;计算高效;利用问题结构 | 依赖ground truth存在 |
MatchTIR的优势在于:
- 不需要额外模型:不用训练PRM或Critic
- 不需要多次采样:一次rollout就能给出所有奖励
- 利用问题结构:工具调用天然是结构化的(工具名、参数名、参数值),可以直接比较
软分配中代价矩阵的设计
论文在附录中探讨了软分配中代价矩阵的不同构建方式:
| 变换方式 | 公式 | 效果 |
|---|---|---|
| 线性 | C i j = 1 − S i j C_{ij} = 1 - S_{ij} Cij=1−Sij | 一般 |
| 归一化 | C i j = ( 1 − S i j ) / ∑ k ( 1 − S i k ) C_{ij} = (1-S_{ij}) / \sum_k (1-S_{ik}) Cij=(1−Sij)/∑k(1−Sik) | 较好 |
| 指数 | C i j = e − S i j / τ / ∑ k e − S i k / τ C_{ij} = e^{-S_{ij}/\tau} / \sum_k e^{-S_{ik}/\tau} Cij=e−Sij/τ/∑ke−Sik/τ | 最好 |
指数变换效果最好,因为它能更好地区分高相似度和低相似度的配对。
多轮训练 vs 扩展单轮训练
论文还比较了两种训练范式:
| 范式 | 描述 | FTRL Solve-R |
|---|---|---|
| 单轮训练×3 | 每次只优化一轮决策,训练3次 | 41.2 |
| 多轮端到端 | 一次优化整条轨迹的所有决策 | 45.4 |
多轮端到端训练效果好4个多点。为什么?
因为多轮任务中,各轮决策是相互依赖的:
- 第1轮的决策影响第2轮能看到的信息
- 分开训练无法捕捉这种跨轮依赖
💡 局限性与未来方向
作者坦诚地指出了两个主要局限:
1. 计算资源限制
只在4B和8B模型上做了实验,更大模型(70B级别)的效果未知。
我的猜测:MatchTIR在大模型上可能依然有效,但边际收益可能递减。因为大模型本身能力更强,"吃大锅饭"的负面影响相对较小。
2. 依赖Ground Truth
MatchTIR需要知道"正确的工具调用序列是什么"才能进行匹配。这在有明确答案的任务(如数学、事实查询)上没问题,但在开放式任务(如Deep Research、创意写作)上就麻烦了——你怎么定义"正确的工具调用"?
我的看法:这是更根本的限制。很多实际应用中,同一个问题可能有多种合理的解决路径:
- 查天气可以用Weather API,也可以搜索"北京天气"
- 两种方式都对,但没法硬性规定哪个是"正确"的
未来可能的解决方向:
- LLM-as-Judge:让另一个LLM来判断工具调用是否合理,而不是与Ground Truth精确匹配
- 多参考答案:构建多条合理的工具调用轨迹,预测只要匹配上任意一条就给奖励
- 功能等价性判断:不要求工具调用完全一致,只要求功能等价(比如查到了相同的信息)
其他潜在改进方向
-
动态惩罚系数: λ \lambda λ 可以随训练进程调整,早期小一些鼓励探索,后期大一些提高精确率
-
层次化匹配:先匹配工具名,再匹配参数,而不是一次性计算总相似度
-
跨轮依赖建模:目前奖励是逐轮计算的,没有显式建模"第3轮的工具调用为第5轮提供了关键信息"这种跨轮依赖
🤔 工程落地思考
如果你想把MatchTIR用到自己的项目中,这里有几点建议:
1. 数据准备是关键
你需要有ground truth工具调用轨迹。如果没有,可以:
- 让GPT-4生成参考轨迹:给GPT-4相同的任务和工具,让它生成"标准答案"
- 用规则+人工校验构建:对于结构化任务(如数据库查询),可以用规则生成Ground Truth
- 放弃轮级监督:如果实在没法构建Ground Truth,退回到用结果奖励
2. 惩罚系数 λ \lambda λ 需要调
- 如果你的模型倾向于"多调几次保险",把 λ \lambda λ 调大(0.8-1.0)
- 如果倾向于"懒得调工具",调小(0.2-0.3)
- 0.5是个不错的起点
3. 匈牙利算法实现
Python有现成的scipy实现,不用自己写:
from scipy.optimize import linear_sum_assignment
import numpy as np
# similarity_matrix: m x n 的相似度矩阵
# 匈牙利算法求最小代价,所以取负
cost_matrix = -similarity_matrix
# 求解最优匹配
row_ind, col_ind = linear_sum_assignment(cost_matrix)
# row_ind[i] 匹配 col_ind[i]
# 对应的相似度是 similarity_matrix[row_ind[i], col_ind[i]]
4. 适用场景判断
| 场景 | 是否适合 | 原因 |
|---|---|---|
| API调用任务(天气、股票等) | ✅ 非常适合 | 有明确的正确答案 |
| 数据库查询任务 | ✅ 非常适合 | SQL可以验证正确性 |
| 代码执行任务 | ✅ 适合 | 执行结果可验证 |
| 多跳推理任务 | ✅ 适合 | MatchTIR优势最大 |
| 开放式对话 | ⚠️ 需改造 | 没有明确Ground Truth |
| 创意生成任务 | ❌ 不太适合 | 无法定义"正确"的工具使用 |
5. 与现有代码的集成
如果你已经在用GRPO训练,集成MatchTIR主要改两个地方:
- 奖励计算:把原来的结果奖励/轨迹奖励,换成二分匹配计算的轮级奖励
- 优势估计:把原来的统一优势,换成双重级优势
核心代码量不大,主要是匹配算法和优势计算的逻辑。
📝 总结
MatchTIR这篇论文的贡献可以概括为:
问题定义清晰:明确指出了现有TIR训练方法"粗粒度信用分配"的问题——所有步骤拿相同的奖励,导致模型无法区分关键步骤和冗余步骤。这是强化学习中经典的信用分配问题在LLM Agent场景下的具体体现。
解决方案优雅:用二分匹配把信用分配建模为一个经典的组合优化问题,充分利用了工具调用的结构化特性(工具名、参数名、参数值)。这个思路借鉴了DETR在目标检测中的成功经验,是CV到NLP的漂亮迁移。
实验充分扎实:三个基准、两种模型规模、详细的消融实验和超参数分析,证明了方法的有效性。特别是在复杂任务上的大幅提升(Hard任务+81.6%),非常有说服力。
工程落地可行:不需要额外训练模型,不需要多次采样,计算开销可控。对于已有GRPO训练流程的团队来说,改造成本不高。
这篇工作让我联想到强化学习中经典的信用分配问题(Credit Assignment Problem)——在延迟奖励的情况下,如何判断是哪一步决策导致了最终的成功或失败?MatchTIR给出了一个针对TIR场景的漂亮答案:既然工具调用是结构化的,那就用结构化的方式去匹配和评分。
从更大的视角看,这篇工作也反映了当前Agent RL训练的一个趋势:从粗粒度到细粒度,从结果导向到过程导向。只看最终结果的训练方式已经不够用了,我们需要更精细的监督信号来指导模型学习复杂的多步决策。
📚 参考信息
- 论文标题:MatchTIR: Fine-Grained Supervision for Tool-Integrated Reasoning via Bipartite Matching
- 作者团队:中国人民大学高瓴人工智能学院 & 百度公司
- arXiv链接:https://arxiv.org/abs/2601.10712
- 关键词:Tool-Integrated Reasoning, 强化学习, 二分匹配, 细粒度信用分配, RLVR, GRPO
相关工作
- DETR:End-to-End Object Detection with Transformers(二分匹配在目标检测中的应用)
- GRPO:Group Relative Policy Optimization(MatchTIR的基础算法)
- SWEET-RL:Step-WisE Evaluation from Training-time information(另一种多轮Agent RL方法)
- COMA:Counterfactual Multi-Agent Policy Gradients(多智能体信用分配方法)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)