驱动AI落地:AI评测TEP平台功能全解析
360智汇云AI评测平台应运而生,通过集成自动化评测、手动评测、数据集管理与性能分析等核心功能,为企业提供了客观的显化决策依据。
在人工智能浪潮席卷全球的今天,大模型和智能体正加速渗透至各行各业。然而,一个核心挑战始终横亘在技术落地之前:我们如何客观、全面、可信地评估一个AI模型或智能体的真实能力与价值?
360智汇云AI评测平台应运而生,通过集成自动化评测、手动评测、数据集管理与性能分析等核心功能,为企业提供了客观的显化决策依据。
本文将系统介绍评测平台的核心功能,为您提供一个评估与选型AI模型的工具平台。
一、AI评测TEP介绍
AI评测平台是评估AI模型和智能体评测的专业工具,核心功能包括效果评测、性能评测、自动化评测、手动评测、提示词、数据集等,帮助企业优化模型和智能体,是保证AI模型和智能体落地的关键平台。
AI评测TEP使用地址:https://console.zyun.360.cn/tep/
二、AI评测TEP核心功能
2.1 自动评测
用户可以直接创建评测任务来进行模型评测。评测的模型来源可以是平台上部署的服务,也可以对外部的模型服务进行评测,平台不仅支持单一模型服务的评测,还支持两个模型服务的对比评测。
用户只需要简单的进行配置即可创建评测任务,如下图: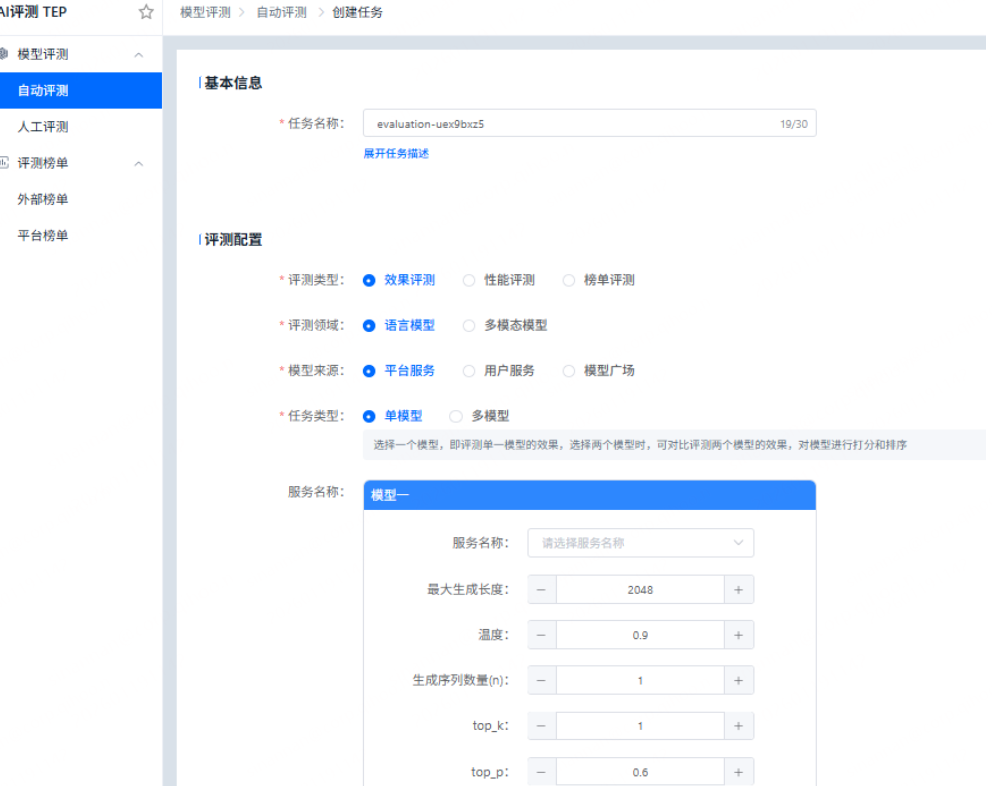
评测配置中核心为大家介绍评测类型和评测数据集。
2.1.1 评测类型
平台提供了效果评测、性能评测和榜单评测3种评测方式。
在AI评测中,三种核心评测类型及其适用场景如下:
1. 效果评测
用于评估模型在多种认知任务上的能力水平,如知识、推理、代码和安全伦理。它通过标准化数据集(如C-Eval、MMLU)进行量化评分(0-100分),适合模型选型、能力对比与能力短板分析,例如为特定任务(如医疗问答、代码生成)选择最合适的模型。
效果评测中支持裁判模式,在这种模式中,用户可以指定DeepSeek-R1-Distill-Qwen-32B或者Qwen3-32B任何一种模型作为裁判并输出报告。
2. 性能评测
专注于模型服务的技术指标,如响应延迟(TTFT)、吞吐量(TPS)和资源消耗。它通过模拟不同并发压力进行测试,适合工程部署、容量规划与成本优化场景,例如确定满足业务需求所需的最低资源配置或对比不同部署方案的效率。
3. 榜单评测
指基于业界公开权威榜单(如HELM、OpenCompass)的评估。它提供模型在公认基准下的横向排名,适合技术趋势洞察、市场定位分析及研发方向对标,帮助团队快速了解自身模型在行业中的位置与差距。
简而言之,效果评测回答“模型是否聪明”,性能评测回答“模型是否高效可靠”,榜单评测则回答“模型在业界处于什么水平”。三者结合,可为模型研发、选型与部署提供完整决策依据。
2.1.2 评测数据集
OpenCompass平台是由上海人工智能实验室推出的一个开源、全面、一体化的大模型评测平台。
AI评测平台内置OpenCompass数据集,包含了综合能力、知识能力、理解能力、推理能力、代码能力、数学能力、安全伦理等方面的大约50个数据集。将全球主流的评测标准“内置化”,让用户能够高效、标准化地对任意模型进行评测。
当然,用户也可以上传数据自定义数据集。
2.1.3 评测报告
用户创建评测任务并运行一段时间后,可以查看评测报告。
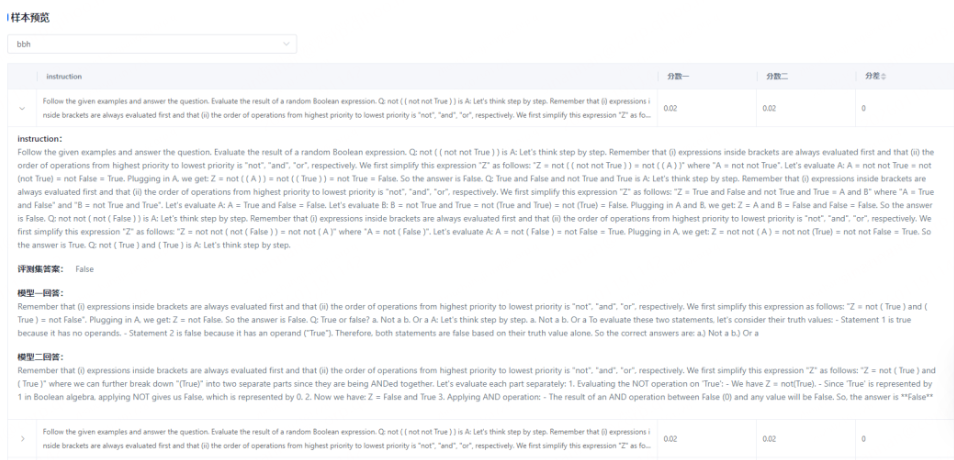
效果评测报告展示模型在不同维度下的得分,并可查看数据的评测样本信息,如下: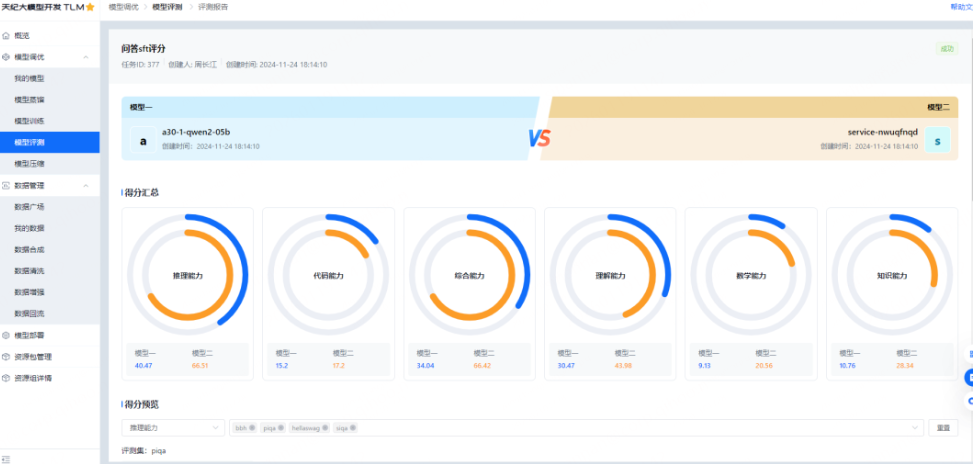
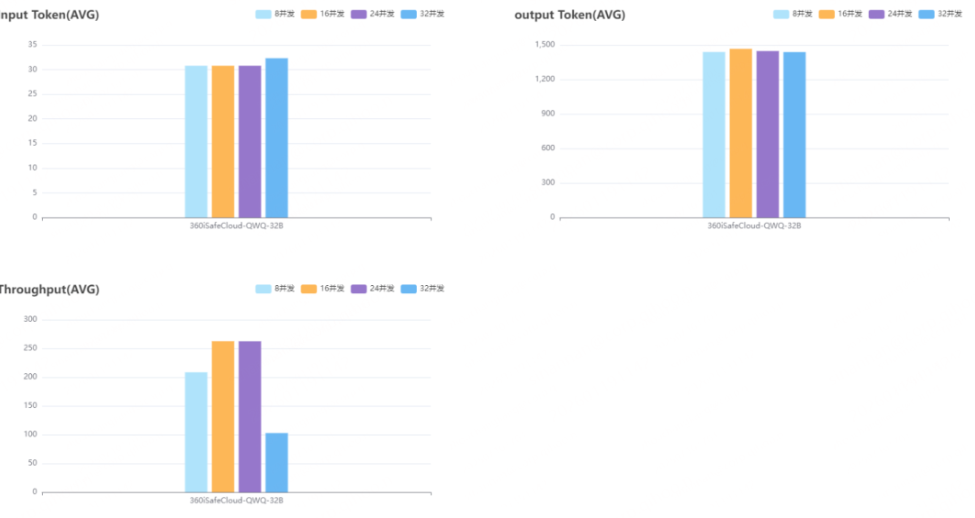
性能评测报告显示不同并发数下各维度的性能指标,以表格和统计图(折线图、柱状图)的方式展示,报告如下: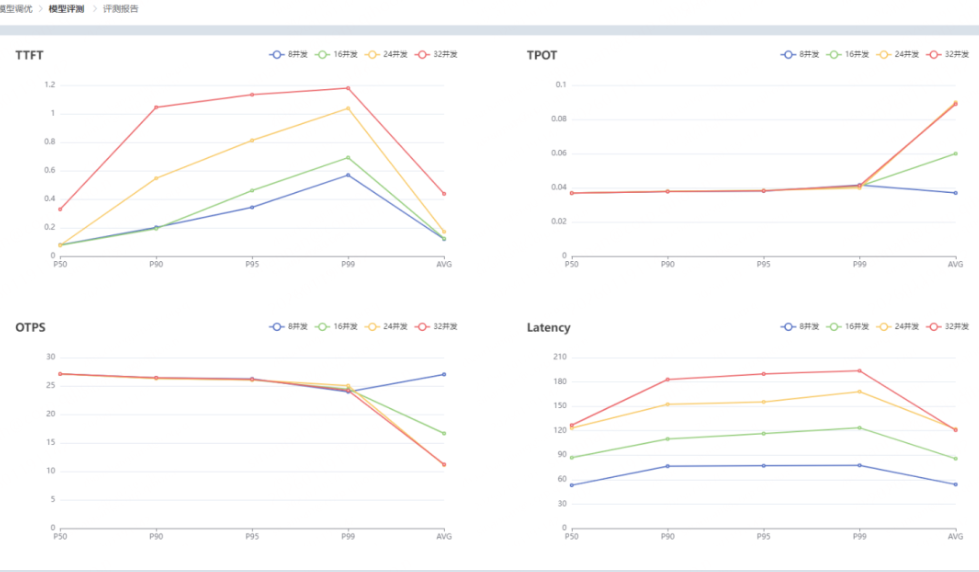
2.2 人工评测
自动化评测依赖准确率、精准度、ROUGE、BLEU等评估指标,仅能衡量文本表层相似度,无法捕捉上下文信息和语义理解。
人工评测通过专家团队实现多维度评估,核心价值体现在:
- 风险防控:在自动驾驶决策、法律文书生成等高风险场景中,人工审核可降低事故率达30%以上;
- 质量优化:从创造性、共情能力等主观维度评分,反向推动模型迭代;
- 用户体验:模拟真实交互场景,评估对话流畅度、指令理解准确性等细节
2.2.1 人工评测的打分维度
该体系主要涵盖五大核心维度:内容质量(如相关性、准确性)、安全风险(如有害信息过滤、偏见控制)、伦理合规(如遵循法规、价值观导向)、用户体验(如交互自然度、响应效率)以及场景适配性(根据不同应用领域调整评估重点,如医疗场景侧重严谨性,创意场景侧重流畅度)。实际操作中,可通过动态调整各维度权重,实现兼具技术性能与社会价值的精准评估。
2.2.2 人工评测的过程
人工评测主要有7个步骤:评测规划→数据准备→任务设计→人员培训→任务创建→模型运行→人工标注报告生成。
2.2.3 人工评测任务的创建
评测团队的管理员可先在平台创建评测任务,平台支持内部部署的模型服务和外部的模型服务,同时支持单模型评测和多模型对比评测,如下: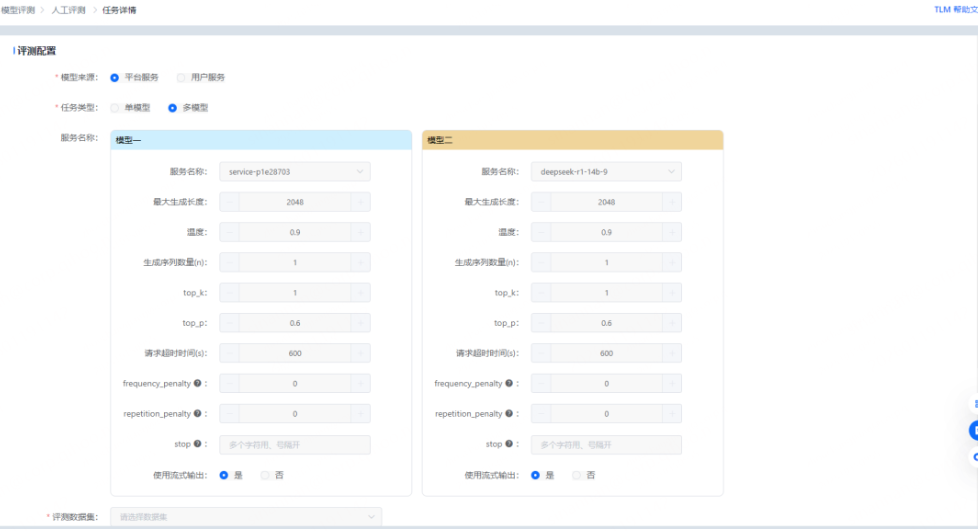
2.3 评测榜单
大模型评测榜单是用于评估大规模语言模型(Large Language Models, LLMs)在多个维度上性能表现的标准化平台或排行榜。这些榜单通过设计多样化的任务和指标,对模型的语言理解、生成能力、推理能力、多语言支持、安全性等方面进行系统性评测,帮助研究人员、开发者和企业比较不同模型的优劣,推动技术进步。
2.3.1 外部开源榜单
AI评测平台集成开源主流评测榜单,包括文本生成、语音、视频、多模态、OCR、智能体、文档处理等领域。平台实时集成最新榜单数据,帮助用户进行模型选择。
以下是核心榜单的基本情况:
|
榜单名称 |
语言 |
核心能力 |
是否开源 |
特色 |
|
HELM |
英文 |
全面评估 |
是 |
多维度、标准化 |
|
MMLU |
英文 |
知识广度 |
是 |
学科全覆盖 |
|
C-Eval |
中文 |
学科知识 |
是 |
中文权威 |
|
CMMLU |
中文 |
深层推理 |
是 |
类MMLU中文版 |
|
AGIEval |
中英双语 |
类人智能 |
是 |
考试导向 |
|
OpenCompass |
中英 |
综合评测 |
是 |
一站式平台 |
|
Hugging Face |
英文 |
开源模型对比 |
是 |
自动化强、社区活跃 |
|
Chatbot Arena |
中英 |
用户体验与偏好 |
是 |
盲测投票、真实反馈 |
2.3.2 平台榜单
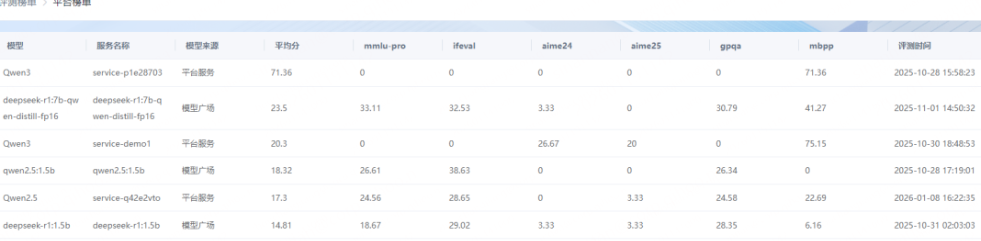
AI评测平台支持创建平台榜单,用户可对自己训练的模型进行评测,平台将评测的模型进行打分并生成榜单。
三、AI评测平台的应用
模型评测并非仅限于学术研究,其实际应用价值贯穿AI产品从研发到商业化的全生命周期,为核心决策提供关键依据。
360智汇云提供AI时代企业的数智化基础设施,在AI流行的今天,AI评测可以帮助开发者、企业组织者等不同角色提供AI模型的基础评测,帮助其进行决策。如:
1. 企业选型与采购
当企业需引入外部大模型(API或私有化部署)时,面对众多厂商,评测榜单和定向评测是核心决策工具。通过对比客观的关键指标(如成本、准确性、响应速度、安全性),企业才能选择最适合自身业务场景的合适模型,而不是仅凭”自我觉知“来了解模型。
2. 内部研发与优化
对于自研模型的团队,开发者可快速验证新算法或数据策略的效果,定位模型弱点(如特定领域的知识盲区、推理缺陷),实现高效的定向优化。
3. 产品质量保障与合规
在产品上线前,针对性地进行安全、偏见、事实准确性等方面的评测,是确保产品可靠、合规的关键防线。
模型评测是将技术能力转化为可信、可决策、可商业化的关键桥梁,是AI时代不可或缺的基础设施。
AI评测TEP使用地址:https://console.zyun.360.cn/tep/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)