LLM应用开发八:Agent企业级智能体系统架构设计
通过清晰的分层设计,成功地将大模型的通用能力转化为解决特定业务问题的智能体能力。基础设施层保证了算力与资源的弹性。工具层通过 MCP 协议实现了能力的无限扩展。核心服务层通过 Memory 和 Workflow 赋予了 Agent “思考”与“回忆”的能力。应用层则快速响应业务需求,实现规模化落地。
1. 引言
1.1 背景与目标
随着大语言模型(LLM)能力的增强,单一的对话机器人已无法满足企业复杂的业务需求。本架构旨在构建一个高内聚、低耦合、可扩展的企业级智能体(Agent)平台。该平台支持多模态交互、长期记忆、技能动态编排及多 Agent 协作,为企业提供从底层模型能力到上层应用的全栈解决方案。
1.2 设计原则
- 分层解耦:基础设施、工具、核心服务与应用层清晰分离,便于独立演进。
- 按需加载:技能和记忆模块通过懒加载机制激活,优化资源利用。
- 记忆分层:通过短期与长期(场景/事实/偏好)记忆架构,实现对用户的深度个性化。
- 协议标准化:引入 MCP 协议统一模型与工具的交互标准。
2. 架构图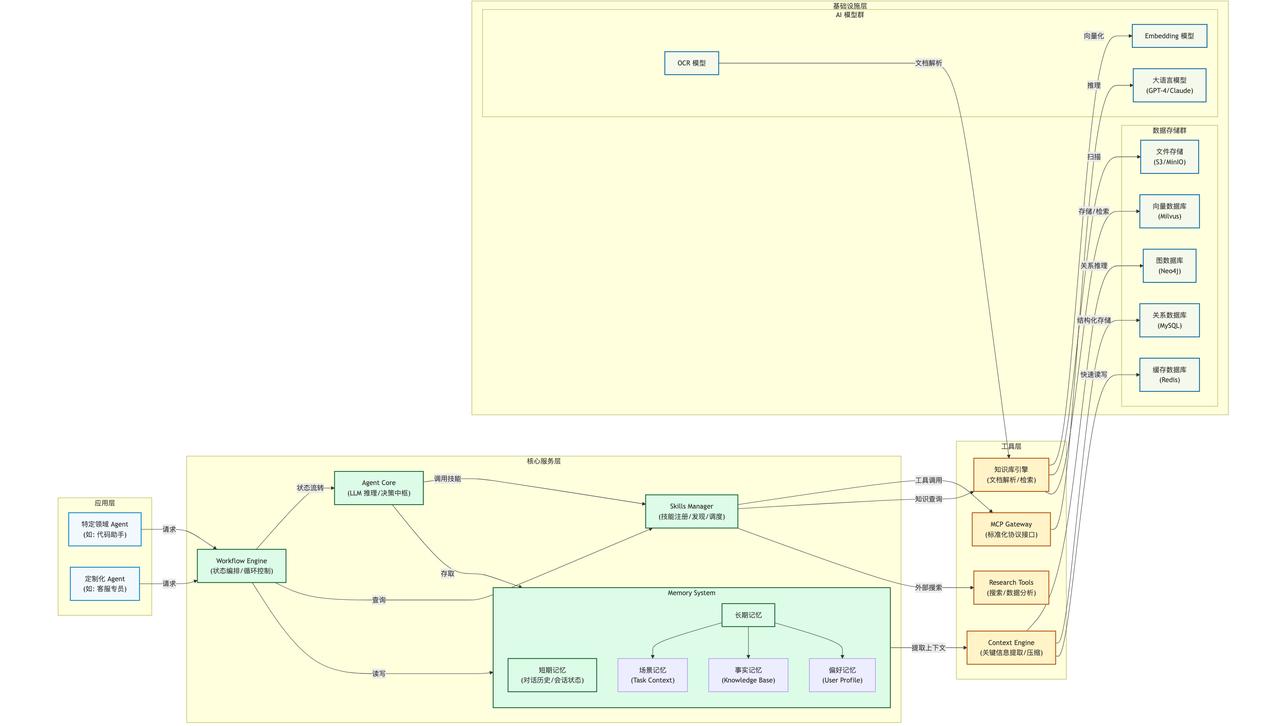
3. 架构分层详解
3.1 基础设施层
作为系统的“硬件”和“原材料”基础,提供算力与存储能力。
- 模型组件:
语言模型 (LLM):系统的大脑,支持多云多模型切换(如 Claude 3.5, GPT-4o, DeepSeek)。
Embedding & Rerank:负责将文本转化为向量表示,并优化检索结果的相关性。
OCR 模型:赋予 Agent 视觉能力,支持图片与 PDF 文档中的文字提取。
- 数据存储:
向量数据库:存储非结构化知识的向量化数据,支撑 RAG(检索增强生成)。
图数据库:存储实体及其复杂关系,支持 Agent 进行知识推理与连接。
关系数据库:存储结构化业务数据及长期记忆中的事实。
缓存数据库:用于短期记忆的高频读写,以及会话状态的快速存取。
3.2 工具
作为系统的“手”,封装了对外部世界的操作能力,通过 MCP 协议标准化。
- MCP Gateway:作为 Model Context Protocol 的网关,将内部各种技能封装为标准接口,使模型能够像调用函数一样调用工具。
- 知识库引擎:基于 RAG 技术,自动抓取、切片、向量化企业文档,并根据用户问题检索相关片段。
- Research 工具:集成搜索引擎、数据分析库(如 Pandas)、代码解释器等,扩展 Agent 的信息获取与处理能力。
- Context Engine:负责从海量对话与文档中提取关键上下文,进行压缩与去噪,防止上下文窗口溢出,并过滤敏感信息。
3.3 核心服务层
作为系统的“操作系统”,负责任务编排、记忆管理与决策逻辑,是 Agent 平台的核心。
- Agent Core (推理引擎):
基于提示词工程与 Chain-of-Thought 引导 LLM 进行推理。
负责任务拆解、子任务分配及最终结果汇总。
- Skills Manager (技能管理器):
注册与发现:动态注册新工具,通过描述向 Agent 暴露可用技能。
按需加载:根据 Agent 的意图动态加载必要的技能库,降低内存占用。
- Memory System (记忆系统):
短期记忆:基于 Redis,存储当前的对话历史、变量状态,具有快速读写特性,随会话结束而清空。
长期记忆:持久化存储,支持跨会话调用。
场景记忆:记录特定任务中的步骤与中间结果,支持断点续传。
事实记忆:将对话中确认的知识点转化为结构化数据存入 SQL/Graph DB。
偏好记忆:记录用户的习惯、风格与特定配置,提供个性化服务。
- Workflow Engine (工作流引擎):
基于 State Graph(状态图)管理 Agent 的生命周期。
定义状态转换条件(例如:模型输出 -> 判断是否调用工具 -> 调用工具 -> 更新状态 -> 返回模型)。
支持多 Agent 并行协作(如一个 Agent 搜索,另一个 Agent 写作)。
3.4 应用层
面向最终用户或开发者,提供具体的业务能力。
- 特定领域 Agent:基于核心服务层配置出专用智能体(如代码生成 Agent、数据分析 Agent、财务报表 Agent)。
- 特性:具备可插拔性,不同 Agent 可共享基础设施与工具,但拥有独立的 Prompt、技能集与记忆空间。
4. 工作流设计
4.1 智能体响应流程
- 输入处理:用户请求到达应用层,传递至 Workflow Engine。
- 状态初始化:Workflow Engine 初始化对话状态,从 Memory System 加载长期记忆与偏好。
- 感知与检索:Context Engine 从对话历史中提取必要上下文,并触发 RAG 检索相关文档。
- 模型推理:
Agent Core 构造 Prompt(包含用户指令、历史、检索到的文档)。
技能管理器根据 Prompt 动态加载必要的工具(如 Web Search Tool)。
调用 LLM 进行推理,判断是否需要执行工具。
- 工具执行:
若需执行工具,通过 MCP Gateway 调用工具层服务。
工具层可能访问基础设施层(如查询 VectorDB 或调用 API)。
- 结果更新与循环:
工具执行结果被写入 Memory System(短期记忆)。
Workflow Engine 判断是否继续迭代或结束流程。
若未结束,将新结果再次送入 Agent Core。
- 输出与记忆写入:
生成最终回复返回用户。
系统异步将本次交互中的重要事实与偏好写入长期记忆。
4.2 记忆
当 Agent 与用户交互时,后台的异步线程会:
- 提取对话中的实体与关系。
- 识别用户意图(如陈述事实、表达偏好)。
- 分类存储:
- Fact -> 写入 GraphDB / SQLDB。
- Preference -> 写入 User Profile。
- Scene -> 存储当前任务的执行树。
5. 技术选型建议
|
组件 |
推荐技术栈 |
说明 |
|
编排框架 |
LangGraph |
非常适合构建有状态、循环的 Workflow Engine。 |
|
模型协议 |
Anthropic MCP SDK |
实现模型与工具间的标准化交互。 |
|
向量数据库 |
Milvus / PGVector |
高性能向量检索。 |
|
记忆存储 |
Redis (短) + Neo4j (事实/关系) + PostgreSQL (结构化) |
经典的记忆架构组合。 |
|
消息队列 |
Kafka / RabbitMQ |
用于异步更新长期记忆及多 Agent 通信。 |
6. 总结
通过清晰的分层设计,成功地将大模型的通用能力转化为解决特定业务问题的智能体能力。
- 基础设施层保证了算力与资源的弹性。
- 工具层通过 MCP 协议实现了能力的无限扩展。
- 核心服务层通过 Memory 和 Workflow 赋予了 Agent “思考”与“回忆”的能力。
- 应用层则快速响应业务需求,实现规模化落地。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)