深度学习实践方法论:一张“排错地图”搞清模型偏差/优化问题/过拟合/交叉验证/数据不匹配
训练集上的损失就降不下去。不是因为你训练不够久,而是模型的“表达能力”不足,装不下真实规律。大海捞针。如果针真的在海里,你努力(更大模型/更久训练)还有机会捞到;但如果针根本不在海里(模型假设空间里就没有正确答案),你捞到天荒地老也没用。不匹配和过拟合不同:它指的是训练集和测试集分布不同。这时就算你再收集训练数据也可能没用。原文例子:用2020年数据做训练、2021年数据做测试,就可能严重不匹配,
引言
你训练一个模型:分数很差。你第一反应可能是“加层数/加数据/调学习率”。但这往往是瞎试,越试越乱。第2章给的核心价值是:把“模型训练失败”拆成几类典型原因,然后按顺序排查,最后能得到一个闭环结论:到底该加模型(解决偏差)、该换优化/训练策略(解决优化问题)、该加数据/加限制(解决过拟合)、还是你根本遇到的是数据不匹配。
2.1 模型偏差:你不是“没训练好”,是“根本学不会”
什么是模型偏差
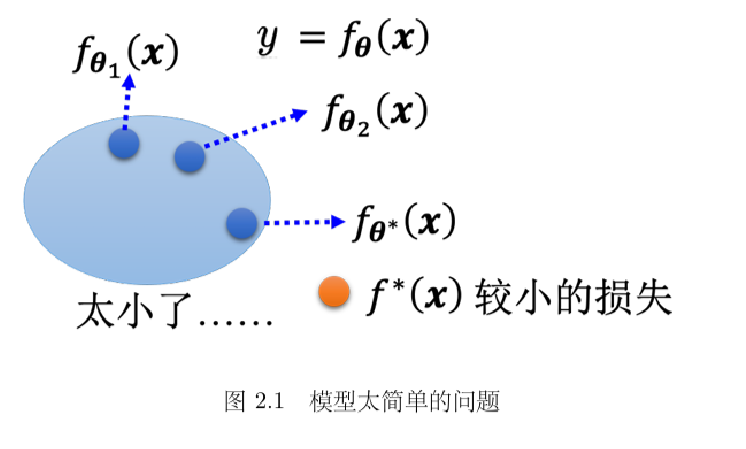
模型偏差的典型信号:训练集上的损失就降不下去。不是因为你训练不够久,而是模型的“表达能力”不足,装不下真实规律。
原文用一个很形象的类比:大海捞针。如果针真的在海里,你努力(更大模型/更久训练)还有机会捞到;但如果针根本不在海里(模型假设空间里就没有正确答案),你捞到天荒地老也没用。
你该怎么做
这章的思路很直接:当确认是偏差时,方向就是“把模型变大/更灵活”,让它有机会表达出正确关系。
小结:训练集都学不明白,先别谈泛化;先把“模型能不能学会”解决掉。
2.2 优化问题:模型够大,但你没把它训练出来
先记住一句话:效果差 ≠ 一定过拟合
原文强调:很多人一看“深模型更差”,就说过拟合。但这可能完全错。
经典例子:ResNet 20层 vs 56层
残差网络论文里比较了20层和56层:随着训练更新,损失会下降,但图里出现“20层损失更低,56层损失更高”的现象。很多人误以为这是过拟合,觉得“深度学习不行/太深没用”。原文明确说:这不是过拟合,因为在训练集上56层的损失也更高——这说明优化没做好(优化不给力)。
并且还有一个关键逻辑:56层比20层更灵活,如果它连20层能做到的事都做不到,那不是“能力不够”,而是“训练过程没把能力发挥出来”。原文用“前20层照抄20层网络、后面层什么都不做(复制输出)也能不更差”来解释这个直觉。
实践排查顺序:先用训练损失把“偏差 vs 优化”分开
原文给了一个很实用的流程:
- 如果训练损失大:先判断是模型偏差还是优化问题;偏差就加大模型。
- 当你努力把训练损失压下去后,再去看测试损失。
小结:深模型训练差,先别急着喊过拟合;先看“训练集到底学没学会”,很多时候是优化没搞定。
2.3 过拟合:训练集学得太好,离开训练集就翻车
过拟合的信号:训练损失小、测试损失大(但前提是先排除别的)
原文特别提醒:测试上结果不好,不一定是过拟合。要先确定优化没有问题、模型够大了;当出现“训练损失小、测试损失大”,才可能是过拟合。
极端例子:背答案的“废模型”
原文用一个极端反例解释过拟合:如果某个“很废”的方法学到的函数是——
- 输入x在训练集出现过:直接输出训练集中对应的y(背答案)
- x没见过:输出随机值
这在训练集上看起来“很准”,但在测试集上基本没法用。
为什么会这样:模型自由度太大
图示表达的是:训练集(蓝点)和测试集(橙点)来自同一分布采样但不完全一样;如果模型自由度很大,就可能拟合出“很奇怪的曲线”,导致训练集好、测试损失大。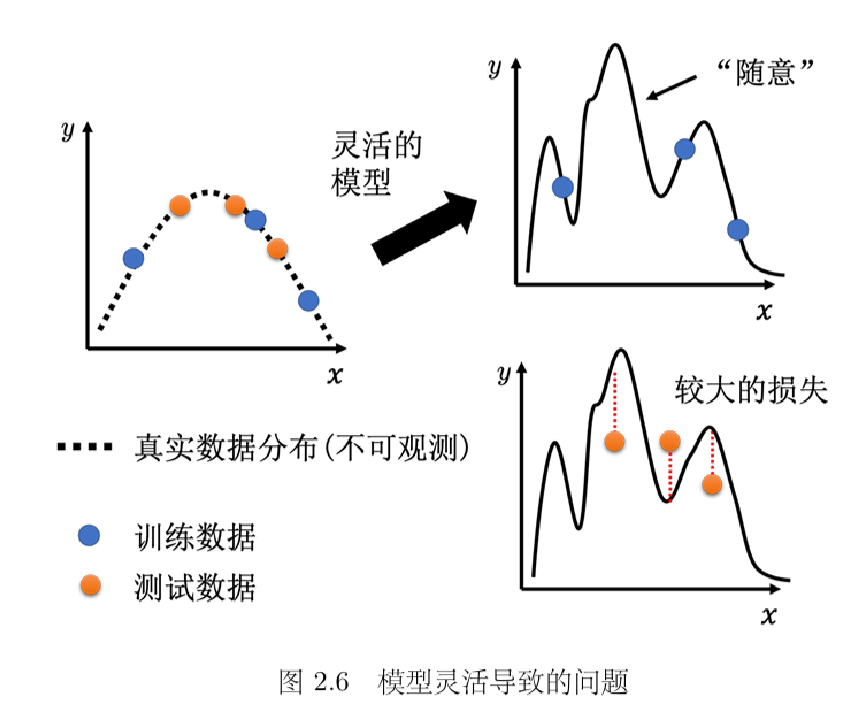
怎么解决过拟合:两条大方向
方向1:增加训练数据(最有效)
训练点变多后,即使模型很灵活,也会被更多数据“约束住”,更接近真实规律。
同时提到数据增强:这是“根据对问题的理解创造新数据”,而且不算使用额外数据。图像任务里常见做法:左右翻转、裁剪放大等;但不能乱搞,比如上下颠倒一般不做,因为不符合真实世界分布,会让模型学到怪东西。
方向2:给模型加限制(降低灵活性)
原文用“真实关系是一条二次曲线”的例子说明:当数据少时,使用更受限的模型(函数集更小)反而更可能选到接近真实分布的函数。
加限制的具体手段包括:
- 少参数/少神经元/参数共享(减少自由度)
- 架构层面的限制:全连接更灵活;CNN更“有限制”,利用图像特性做约束,所以在图像上反而更好。
- 少特征:比如3天数据改用2天数据。
小结:过拟合本质是“自由度太大 + 约束太少”。要么加数据(含合理增强),要么加限制(少参数/合适架构/少特征)。
2.4 交叉验证:别用测试集调参,用验证集选模型
为什么不能用测试集反复调模型(Kaggle的坑)
原文用Kaggle举例:如果测试集全公开,你甚至可以不断随机输出、反复提交,总能“蒙”到一个公开分数很高的结果——但这没意义。
所以Kaggle会把测试集分成公开/私人两部分;并且原文明确建议:不要用公开测试集调模型,否则可能对公开过拟合、私人测试很差。
更合理的流程:训练集拆出验证集
把训练数据分两部分:训练集训练参数;验证集用来打分选模型。比如90%训练、10%验证。
原文还强调一个非常“反直觉但很实用”的原则:最好的做法是直接用验证损失最小的模型,不要管公开测试集的结果。
k折交叉验证(k-fold):数据少时更稳
当数据有限,用一次90/10可能不稳定。k折做法:把训练数据分k份;每次拿1份当验证、其余k-1份训练;做k次得到k个分数再取平均。
小结:选模型要靠验证集(或k折平均),别把测试集当“练习本”。
2.5 不匹配(mismatch):不是过拟合,是训练集和测试集根本不是一回事
不匹配的定义
不匹配和过拟合不同:它指的是训练集和测试集分布不同。这时就算你再收集训练数据也可能没用。
原文例子:用2020年数据做训练、2021年数据做测试,就可能严重不匹配,因为背后的分布变了,预测当然不准。
怎么处理(原文给的关键点)
解决不匹配要看你对数据本身的理解:你需要理解训练集/测试集是怎么产生的,才能判断是否不匹配,以及该怎么改。
小结:过拟合是“同一分布下泛化差”;不匹配是“分布都变了”。别用“加训练数据”一招走天下。
FAQ
-
训练集损失降不下去,是不是一定要加数据?
不一定。原文把这类问题更倾向归为模型偏差:模型表达能力不足时,你再训练也学不会。 -
深层网络比浅层更差,就是过拟合吗?
不一定。ResNet 20层/56层例子说明:如果训练集上56层损失也更高,那更像优化问题,不是过拟合。 -
怎么区分“优化问题”和“过拟合”?
先看训练损失:训练损失压不下去,先考虑偏差或优化;当训练损失小、测试损失大,才可能是过拟合。 -
数据增强算不算“额外数据”?
原文明确说不算,但增强必须符合数据特性,不能瞎增强,否则会学到怪东西。 -
为什么不要用公开测试集调参?
因为你可能对公开测试集“调到过拟合”,但在私有测试集上崩盘;Kaggle分公开/私有就是为了减少这种投机。 -
k折交叉验证到底解决什么问题?
当数据少、一次划分不稳定时,k折用多次轮换验证,让评估更稳,然后取平均分做决策。 -
不匹配和过拟合有什么本质区别?
过拟合通常还在同一分布采样的前提下;不匹配是训练/测试分布不同,多加训练数据也未必有效。
总结
学完第2章,你应该能用一套固定顺序,把“模型效果差”拆清楚:
- 训练损失降不下去:优先考虑模型偏差或优化问题;别张口就说过拟合。
- 训练损失小、测试损失大:再考虑过拟合,用“加数据/合理增强”或“加限制(少参数/合适架构/少特征)”去处理。
- 如果训练/测试分布不同:这是不匹配,多加训练数据也未必有用,得回到数据生成机制本身。
参考资料
深度学习教程第二章

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)