Dify私有化部署实战(二):通过 OpenAI-API-compatible 接入企业私有模型集群
本文介绍了在企业内网环境下如何通过OpenAI兼容接口将各类AI模型接入Dify平台。详细说明了LLM、Embedding和Rerank三类模型的配置方法,包括模型类型选择、名称匹配、API端点设置等关键参数。特别强调了模型能力标签识别的重要性,以及上下文长度的合理设置。最后分享了系统默认模型的配置策略,并通过文本和多模态测试验证了接入效果,为后续搭建企业级知识库奠定了基础。
前言
接上一篇 Dify私有化部署记录,环境搭建完成后,Dify 处于无模型可用的空置状态。
在企业内网环境下,出于数据安全和成本考虑,我们不直接调用公网 API,而是对接公司内部基于 vLLM/Xinference 等框架部署的模型推理集群。本文记录如何利用 Dify 的 OpenAI-API-compatible 接口,将 LLM(对话/代码/视觉)、Embedding(向量)、Rerank(重排)三类模型完整接入。
1. 接入方案分析
Dify 支持通过 OpenAI-API-compatible 协议接入任意兼容 OpenAI 接口规范的模型服务。这是最通用的接入方式,能够屏蔽后端推理框架的差异。
我们目前的模型池配置如下(这也是为了满足后续 RAG 知识库和多模态场景的需求):
-
通用 LLM:DeepSeek-V3(主力推理)
-
垂直 LLM:Qwen3-Coder(代码生成)、Qwen-VL(视觉理解)
-
Embedding:BGE-M3(支持多语言、长文本,RAG 必备)
-
Rerank:BGE-Reranker(检索重排序,提升召回准确率)
2. 配置过程记录
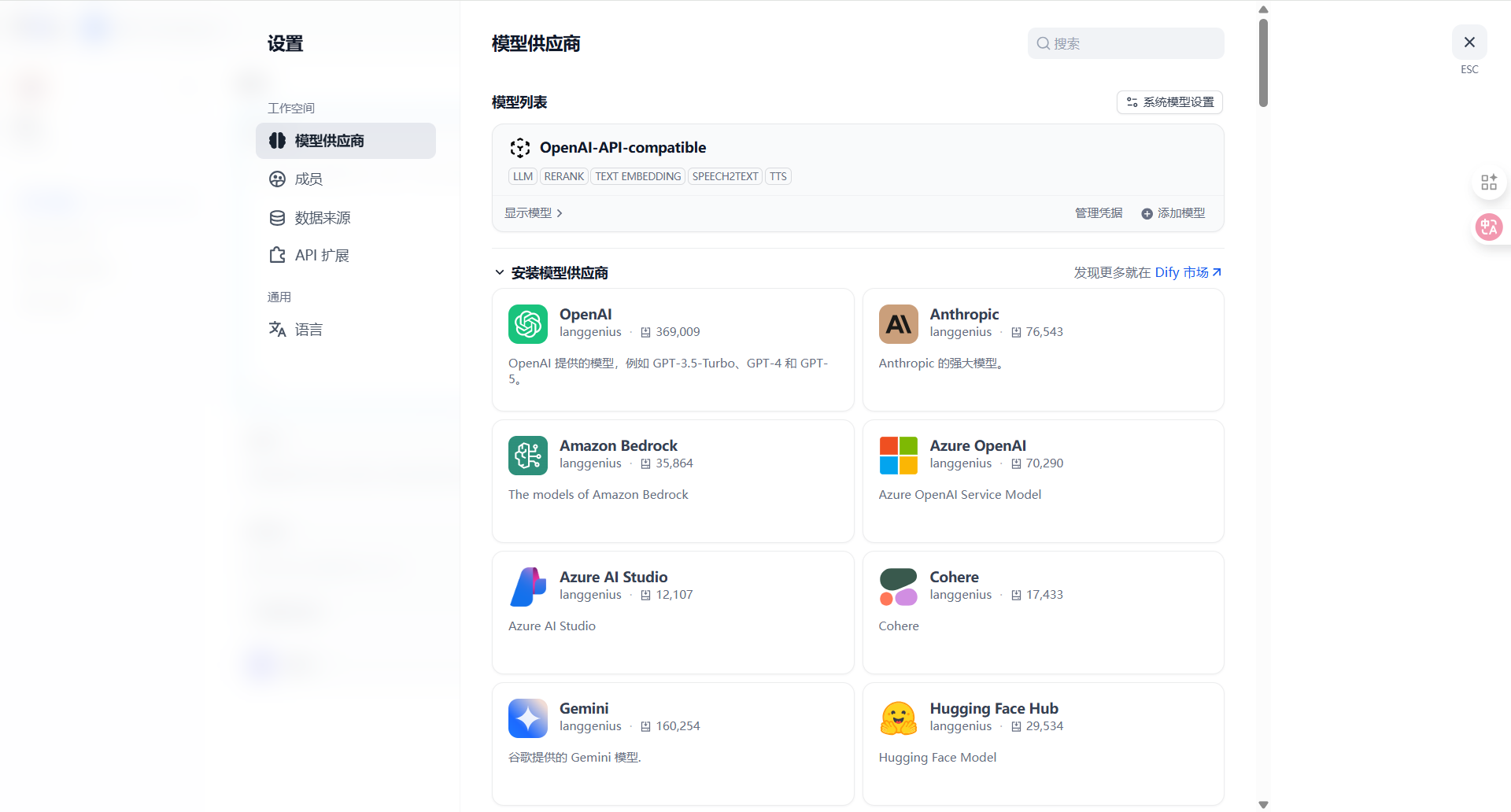
右上角入口位置:设置 > 模型供应商 > OpenAI-API-compatible。
刚部署完在模型列表这里没有OpenAI-API-compatible,需要在下方的模型供应商中找到OpenAI-API-compatible进行安装
2.1 基础配置参数
在添加模型时,有几个关键参数需要注意,否则容易报错或无法调用:
-
模型类型 (Model Type):这里必须严格区分。
-
接入 DeepSeek/Qwen 时选 LLM。
-
接入 BGE-M3 时务必选 Text Embedding。
-
接入 BGE-Reranker 时务必选 Rerank。
-
-
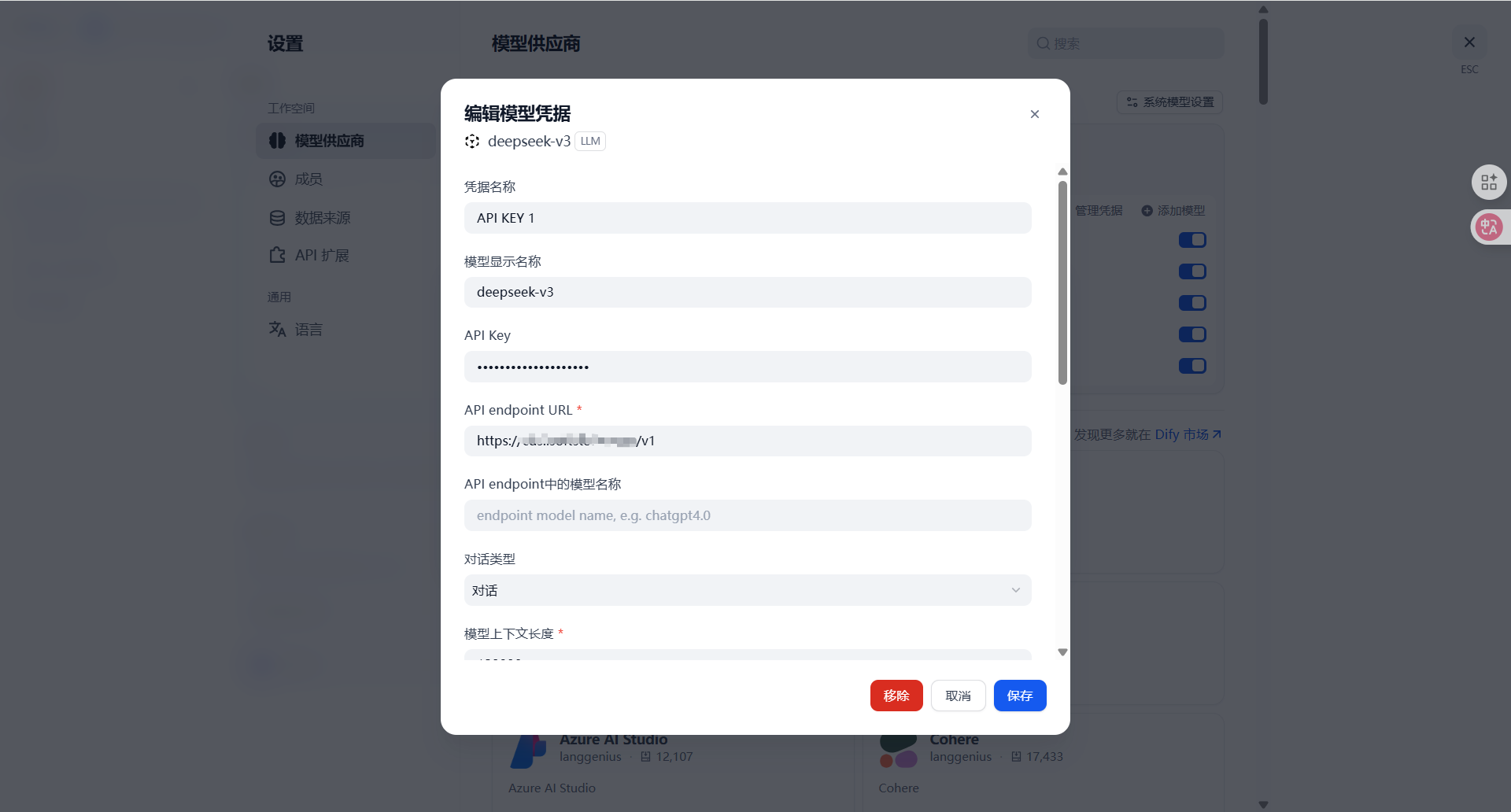
模型名称 (Model Name):这是最容易踩坑的地方。
-
填写的名称必须与后端推理服务暴露出的 model_name 完全一致,否则 Dify 发起请求时,后端会报 Model not found。
-
-
API Key:
-
内网服务通常无鉴权(模型和dify在同一个机器上部署),但 Dify 前端校验不许为空。直接填 sk-123456 或任意字符占位即可。
-
如果非内网服务需要填写完整的key
-
-
API Endpoint URL:
-
标准格式通常为 http://{IP}:{PORT}/v1。注意 URL 结尾是否需要带 /v1 取决于后端框架的路由设置,实测 vLLM 通常需要带上。
-
2.2 模型能力标签识别
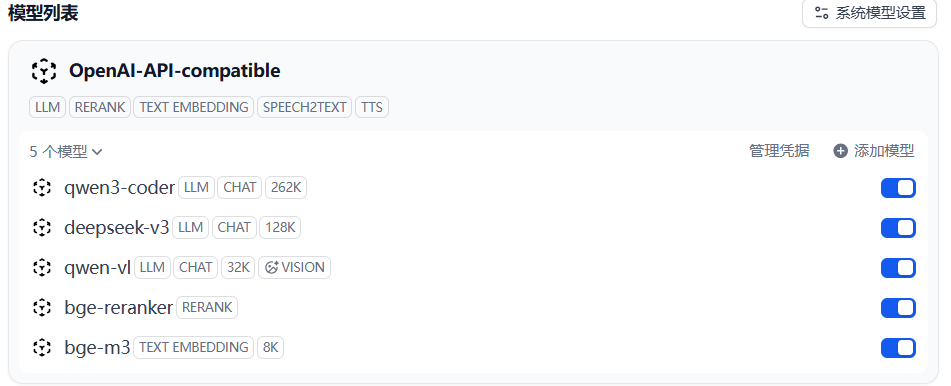
配置完成后,Dify 会自动识别模型的能力标签(如下图)。
配置分析:
从上图可以看到接入状态正常:
-
Vision 能力:qwen-vl 被正确识别出 VISION 标签。这很重要,只有带这个标签,后续在应用编排中才能开启“图片上传”功能。
-
Rerank 能力:bge-reranker 被识别为 RERANK 类型。这是做高精度知识库检索的关键组件,很多教程忽略了这一点,导致 RAG 效果不佳。
2.3 上下文长度 (Context Window)
我们在添加模型时,需要手动定义 Max Tokens。
-
DeepSeek-V3 和 Qwen 系列通常支持较长上下文(如 32k/128k)。
-
建议:在 Dify 配置中显式填入较大的数值(如 4096 或 16384),避免 Dify 默认截断导致长文档分析失败。
3. 系统默认模型设置
接入这么多模型后,需要指定系统级的默认调用逻辑,避免每次创建应用都要手动选模型。
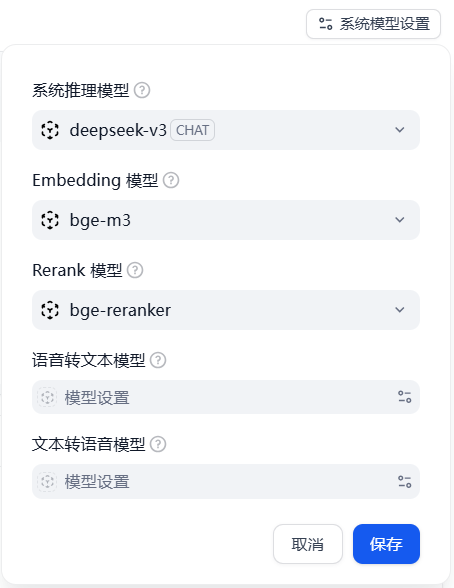
进入 系统模型设置,我的配置策略如下:
-
系统推理模型:deepseek-v3(兼顾速度和效果)。
-
Embedding 模型:bge-m3(目前中文环境下的最优解)。
-
Rerank 模型:bge-reranker。
4. 验证测试
配置完毕后,新建一个简单的 Chat 应用进行冒烟测试:
-
文本测试:调用 DeepSeek-V3,响应速度正常。
-
多模态测试:切换到 Qwen-VL,上传图片,模型能正确描述图片内容。
小结
至此,Dify 的底层模型基座已搭建完毕。通过 OpenAI 兼容协议,我们成功复用了公司现有的 AI 基础设施。且引入了 Rerank 模型,为后续搭建企业级知识库做好了准备。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)