预训练大模型
本文介绍了GPT模型的文本生成流程及预训练方法。
根据前面了解的知识,GPT模型通过三步过程生成文本:首先,分词器将输入文本转换为词元 ID;然后,模型接收这些词元 ID 并生成相应的 logits,这些 logits 表示词汇表中每个词元的概率分布的向量;最后,这些 logits 被转换回词元 ID,分词器会将其解码为人类可读的文本,这样就完成了从文本输入到文本输出的循环。如下图所示。
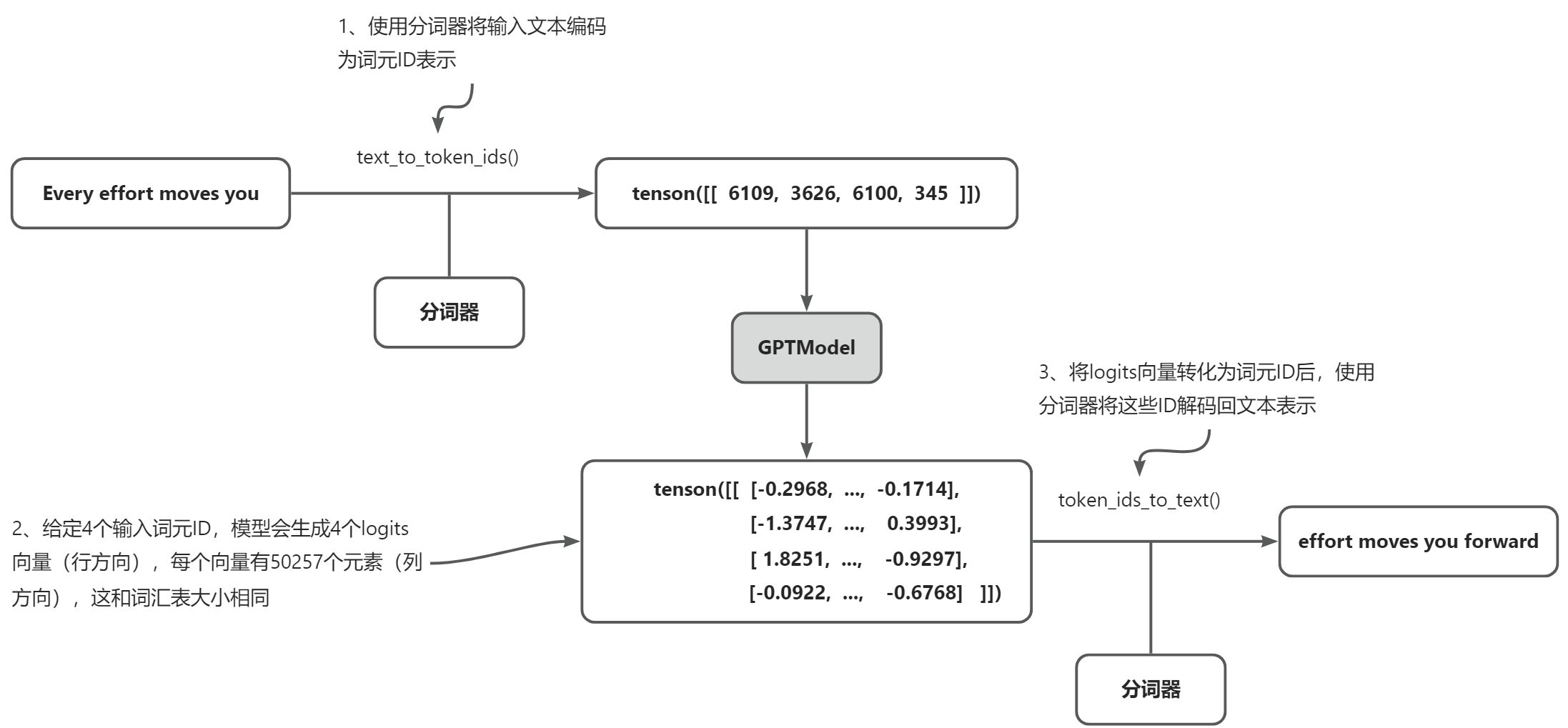
但由于未经过训练,模型还无法生成连贯的文本。要定义什么是“连贯”或“高质量”的文本,必须采用一种数值方法来评估生成的内容。这种方法使得我们能够在训练过程中监测和增强模型的性能。
评估文本生成模型
计算文本生成损失
首先,我们计算生成的输出结果的损失函数大小。这个损失值将作为训练进展和成功的衡量标准。通过损失指标来量化评估模型生成的文本的性能。这不仅有利于衡量生成的文本的质量,同时也是实现训练函数的一个构建块,我们将使用它来更新模型的权重,从而改善生成的文本。
模型训练的目标是增大与正确目标词元 ID 对应的索引位置的 softmax 概率。
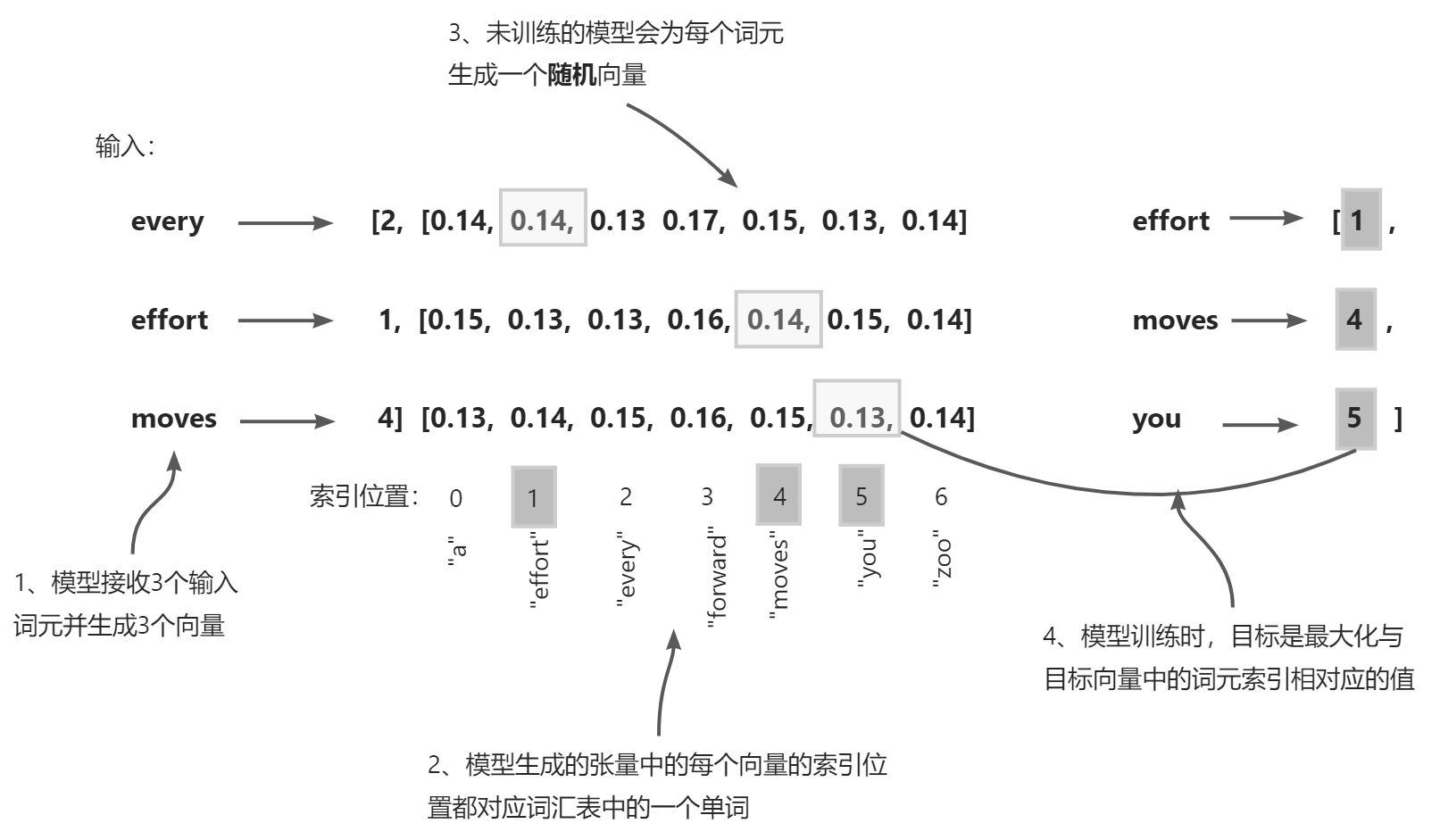
在训练之前,模型会随机生成下一个词元的概率向量。模型训练的目标是确保与图中框出的目标词元 ID 对应的概率值被最大化。
训练大语言模型的目标是最大化正确词元的可能性,这涉及增大其相对于其他词元的概率。通过这种方式,可以确保大语言模型始终选择目标词元(实质上是句子中的下一个单词)作为它生成的下一个词元。
如何最大化与目标词元对应的 softmax 概率值呢?大致思路是,更新模型权重,以便模型为我们想要生成的相应词元 ID 输出更高的值。权重更新是通过一种称为反向传播的过程完成的。
反向传播需要一个损失函数,它会计算模型的预测输出(在这里是与目标词元 ID 对应的概率)与实际期望输出之间的差异。这个损失函数衡量的是模型的预测与目标值之间的偏差。
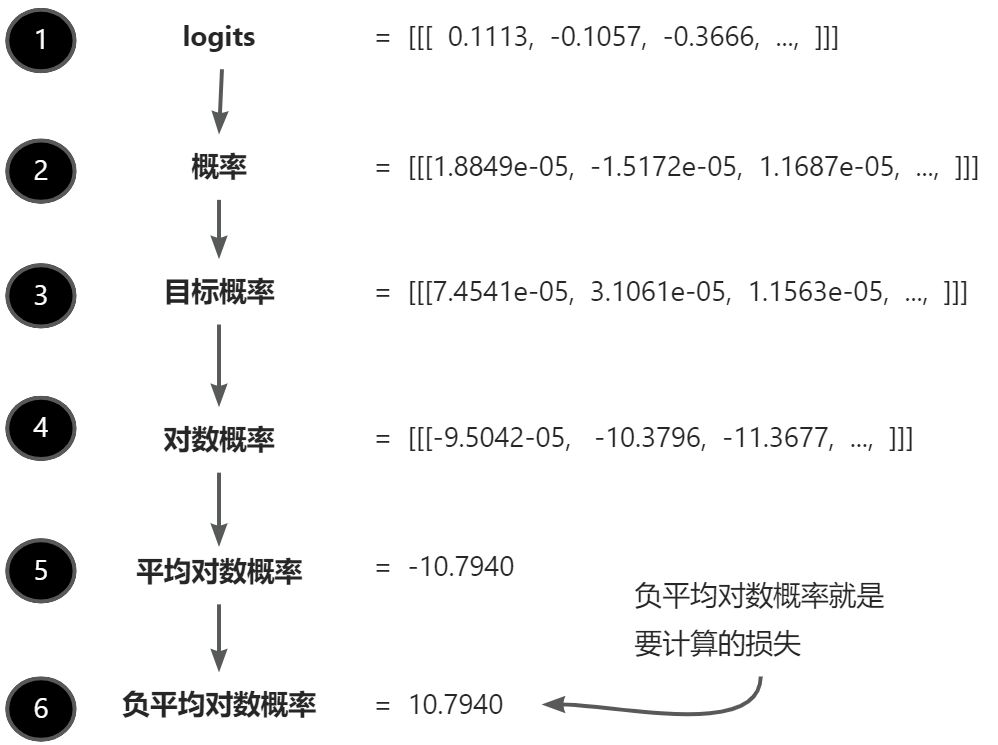
计算损失涉及的几个步骤。我们已经完成了第❶❸步,计算了与目标张量对应的词元的概率,这些概率在第❹❻步中将通过取对数并求平均值进行转换。
在数学优化中,使用概率分数的对数比直接处理分数更容易操作。
我们的目标是通过在训练过程中更新模型的权重,使平均对数概率尽可能接近 0。然而,在深度学习中,通常的做法不是将平均对数概率升至0,而是将负平均对数概率降至0。负平均对数概率就是平均对数概率乘以-1。
在深度学习中,将-10.7940 这个负值转换为 10.7940 的术语被称为交叉熵损失。
PyTorch 的内置cross_entropy 函数,可以为我们处理上图的所有步骤。
在计算交叉熵损失后,接下来可以将这个损失计算应用到将用于模型训练的整个文本数据集中。
计算训练集和验证集的损失
首先,准备用于训练大语言模型的训练数据集和验证数据集。然后,我们将计算训练集和验证集的交叉熵。
接下来,我们将数据集分成训练集和验证集,并使用前面的数据加载器来准备大语言模型训练所需的批次数据。这个过程在下图中进行了可视化展示。由于空间限制,我们使用了max_length=6。然而,对于实际的数据加载器,可以将max_length设置为256个词元的上下文长度,以便训练期间大语言模型能够看到更长的文本。
为了实现数据拆分和加载,首先定义一个 train_ratio,我们使用 90%的数据进行训练,剩余的 10%作为验证数据,以便在训练过程中对模型进行评估。
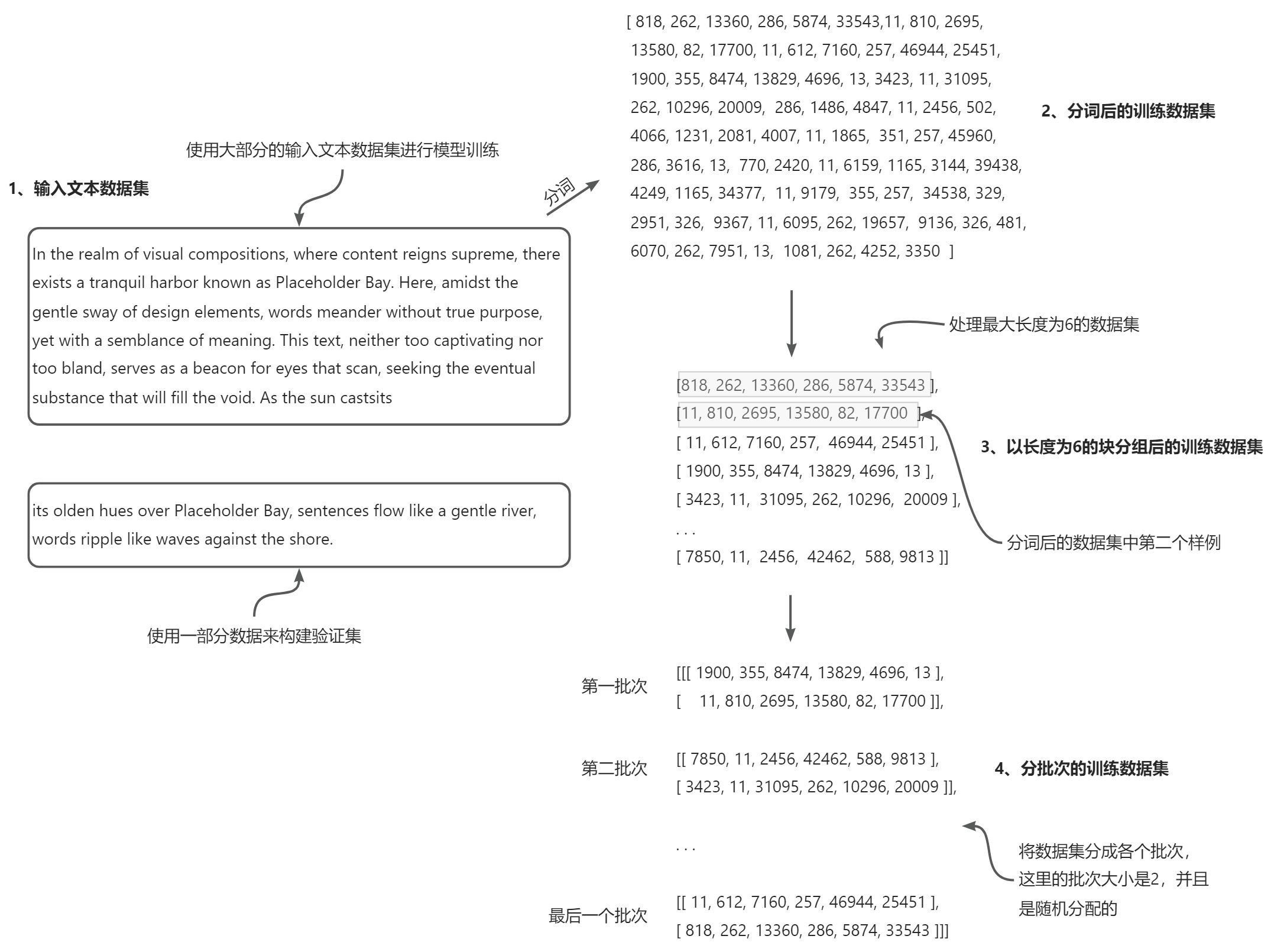
在准备数据加载器时,将输入文本分割为训练集和验证集。然后,对文本进行分词(为了简化操作,这里仅显示了训练集),并将分词后的文本分成用户指定长度的块(这里是 6)。
最后,对行进行重排,并将分块后的文本组织成批次(这里批次大小为 2),这些批次可用于进行模型训练。接下来,可以利用 train_data 和 val_data 创建相应的数据加载。
此时,模型未经过训练,因此损失值相对较高。相比之下,如果模型学会按照训练集和验证集中词元的出现顺序生成下一个词元,那么损失将接近于 0。
训练大语言模型
下图描述了一个典型的 PyTorch 神经网络训练工作流程,我们使用它来训练一个大语言模型。它概述了 8 个步骤,从遍历每个训练轮次开始,处理批次,重置梯度,计算损失和新梯度,更新权重,最后以监控步骤(包括打印损失、生成文本样本等操作)结束。
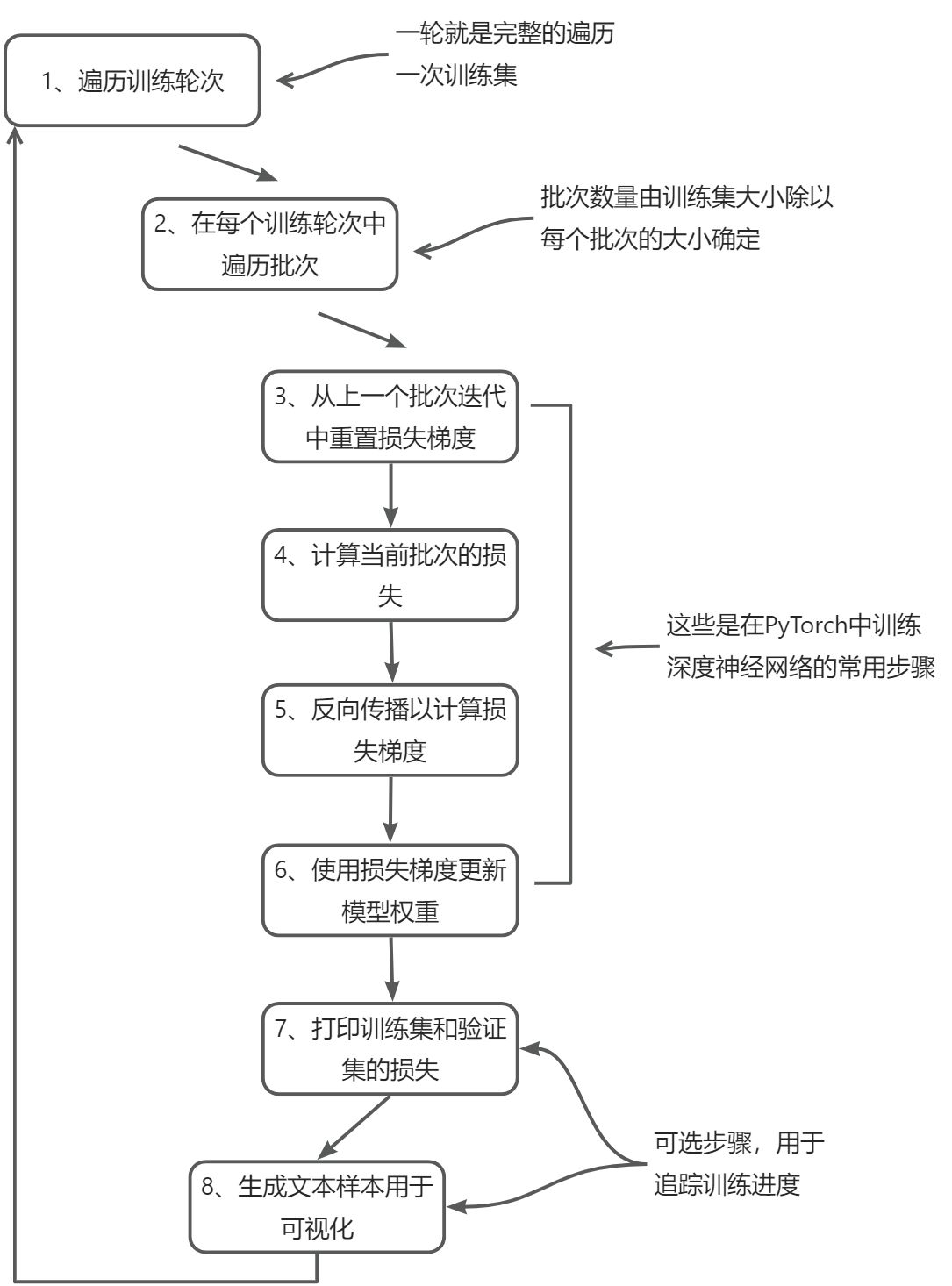
在PyTorch中训练深度神经网络的典型训练循环包括多个步骤,涉及对训练集中的批次进行多轮迭代。在每次循环中,我们计算每个训练集批次的损失以确定损失梯度,然后使用这些梯度来更新模型权重,以使训练集损失最小化。
def train_model_simple(model, train_loader, val_loader,
optimizer, device, num_epochs,
eval_freq, eval_iter, start_context, tokenizer):
train_losses, val_losses, track_tokens_seen = [], [], [] #初始化列表以跟踪损失和所见词元
tokens_seen, global_step = 0, -1
for epoch in range(num_epochs): # 开始主训练循环
model.train()
for input_batch, target_batch in train_loader:
optimizer.zero_grad() # 重置上一个批次迭代中的损失梯度
loss = calc_loss_batch(
input_batch, target_batch, model, device
)
loss.backward() # 计算损失梯度
optimizer.step() # 使用损失梯度更新模型权重
tokens_seen += input_batch.numel()
global_step += 1
if global_step % eval_freq == 0: # 可选的评估步骤
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {train_loss:.3f}, "
f"Val loss {val_loss:.3f}"
)
generate_and_print_sample( # 每轮之后打印一个文本样本
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen
evaluate_model 函数提供了模型训练进度的数值估计,generate_and_print_sample函数提供了由模型生成的具体文本样本,以评估其在训练期间的能力。
模型在完成训练后已经可以生成连贯的文本了。然而,它经常逐字记忆训练集中的段落。接下来,我们将讨论生成更多样化输出文本的策略。
控制随机性的解码策略
下面,我们关注一下文本生成策略(也称为“解码策略”),以生成更具原创性的文本。
温度缩放
温度缩放是一种在下一个词元生成任务中添加概率选择过程的技术。
argmax(也称为贪婪解码)采样具有最高概率的词元作为下一个词元。为了生成更多样化的文本,可以用一个从概率分布(这里是大语言模型在每个词元生成步骤为每个词汇条目生成的概率分数)中采样的函数来取代 argmax。
通过一个称为温度缩放的概念,可以进一步控制分布和选择过程。温度缩放指的是将 logits除以一个大于 0的数。
def softmax_with_temperature(logits, temperature):
scaled_logits = logits / temperaturereturn torch.softmax(scaled_logits, dim=0)
温度大于 1 会导致词元概率更加均匀分布,而小于 1 的温度将导致更加自信(更尖锐或更陡峭)的分布。
温度为 1 意味着在将 logits 传递给 softmax 函数计算概率分数之前,先将 logits 除以 1。换句话说,使用温度 1 相当于不使用任何温度缩放。在这种情况下,通过 PyTorch 中的 multinomial采样函数,词元将与原始 softmax 概率分数相等的概率被选中。
同样,如果应用非常小的温度(如 0.1)会导致更集中的分布,使得 multinomial函数几乎 100%选择最可能的词元,接近于 argmax 函数的行为。类似地,温度为5会导致更均匀的分布,使得其他词元更容易被选中。这可以为生成的文本增加更多变化,但也容易生成无意义的文本。
Top-k 采样
结合温度缩放的概率采样方法,可以增加输出结果的多样性。但这种方法的缺点是,有时会导致语法不正确或完全无意义的输出。
通过与概率采样和温度缩放相结合,Top-k 采样可以改善文本生成结果。在 Top-k 采样中,可以将采样的词元限制在前k个最可能的词元上,并通过掩码概率分数的方式来排除其他词元。
Top-k 方法用负无穷值(-inf)替换所有未选择的 logits,因此在计算 softmax 值时,非前k词元的概率分数为0,剩余的概率总和为1。
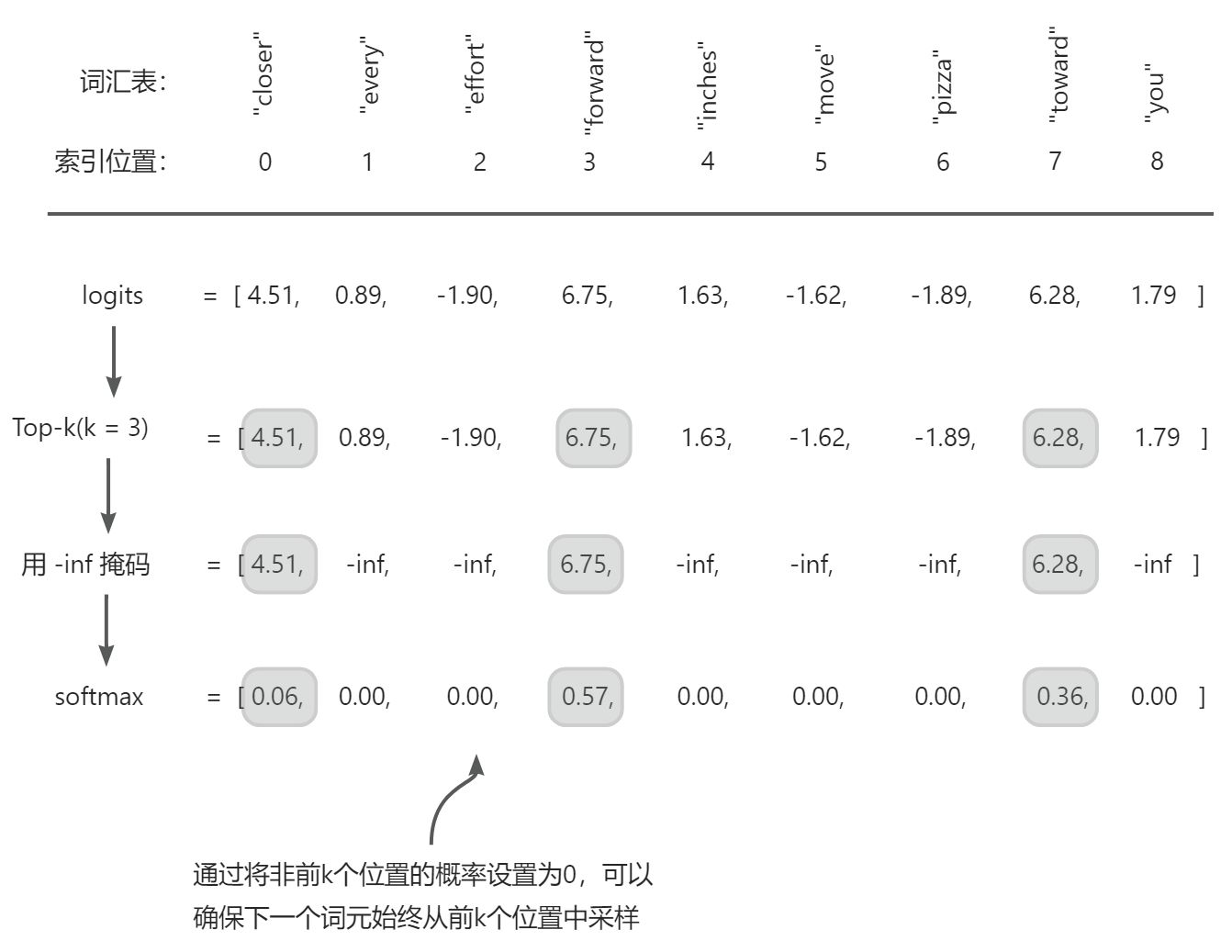
使用 Top-k 采样,其中 k = 3,我们专注于与最高 logits 值相关的 3 个词元,并在应用softmax函数之前用负无穷(-inf)掩码所有其他词元。这会产生一个对所有非前 k 个词元分配概率值 0 的概率分布(为了减少视觉混乱,该图中的数值截断为小数点后两位)。“softmax”行中的值加起来应为 1.0。
使用 PyTorch 加载和保存模型权重
使用 torch.save 函数保存模型的state_dict,即将每个层映射到其参数的字典
torch.save(model.state_dict(), "model.pth")
model.pth 是保存 state_dict 的文件名。.pth 扩展名是 PyTorch 文件的规范。
使用load_state_dict函数将模型权重加载到model实例中。
model.load_state_dict(torch.load("model.pth", map_location=device))
像AdamW 这样的自适应优化器可以为每个模型权重存储额外的参数。AdamW 使用历史数据动态地调整每个模型参数的学习率。如果没有它,那么优化器就会重置,模型可能学习效果不佳,甚至无法正确收敛,这意味着模型将失去生成连贯文本的能力。可以使用 torch.save保存模型和优化器的 state_dict 内容。
torch.save({
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
},"model_and_optimizer.pth")
其他
反向传播
如何最大化与目标词元对应的 softmax 概率值?大致思路是,更新模型权重,以便模型为我们想要生成的相应词元 ID 输出更高的值。权重更新是通过反向传播的过程完成的,这是训练深度神经网络的标准技术。
反向传播需要一个损失函数,它会计算模型的预测输出(在这里是与目标词元 ID 对应的概率)与实际期望输出之间的差异。这个损失函数衡量的是模型的预测与目标值之间的偏差。
交叉熵损失
在机器学习和深度学习中,交叉熵损失用于衡量两个概率分布之间的差异——通常是标签(在这里是数据集中的词元)的真实分布和模型生成的预测分布(例如,由大语言模型生成的词元概率)之间的差异。
在机器学习的背景下,特别是在像 PyTorch 这样的框架中,交叉熵函数可以对离散的结果进行度量,类似于给定模型生成的词元概率时目标词元的负平均对数概率。因此,在实践中,“交叉熵”和“负平均对数概率”这两个术语是相关的,且经常可以互换使用。
困惑度
困惑度通常与交叉熵损失一起用来评估模型的性能。它提供更易解释的方式来理解模型在预测序列中的下一个词元时的不确定性。
困惑度可以衡量模型预测的概率分布与数据集中实际词汇分布的匹配程度。与交叉熵损失类似,较低的困惑度表明模型的预测更接近实际分布。
困惑度可以通过 perplexity = torch.exp(loss)计算得出。
困惑度通常被认为比原始损失值更易于解释,因为它表示模型在每一步中对于有效词汇量的不确定性。在现有的示例中,这意味着模型不确定在词汇表的 48725 个词元中应该生成哪个来作为下一个词元。
AdamW
Adam优化器是训练深度神经网络的一种常见选择。然而,我们的训练循环中选择了AdamW优化器。AdamW是Adam的变体,它改进了权重衰减方法,旨在通过对较大的权重进行惩罚来最小化模型复杂性并防止过拟合。这种调整使得AdamW能够实现更有效的正则化和更好的泛化能力。
贪婪解码
默认情况下,下一个词元是通过将模型输出转换为概率分数,并从词汇表中选择与最高概率分数对应的词元来生成的。
函数
PyTorch内置cross_entropy 函数,可以处理计算损失涉及的几个步骤。
multinomial 函数按照其概率分数采样下一个词元。
参考
《从零构建大模型》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)