奇点算力云从工程视角看算力调度:为什么“有 GPU”≠“能高效跑 AI 任务”
摘要:本文探讨了奇点算力云AI算力调度的核心挑战与解决方案。传统调度系统难以满足AI任务的特殊需求,如长时运行、GPU异构性和位置敏感性。奇点算力云提出以"任务建模"为核心的调度理念,通过多源算力统一抽象、失败自动迁移、算力资产友好等工程设计,实现从"资源调度"到"算力流通"的转变。文章指出,在算力分散化趋势下,调度能力将比算力规模更重要
一、真实世界里的算力,并不是一个“统一资源”
在很多架构设计的理想模型中,算力被抽象为:
一组规格统一、性能稳定、随取随用的 GPU 资源。
但在真实世界中,我们面对的算力往往是:
-
不同厂商、不同架构的 GPU
-
不同机房、不同网络拓扑
-
不同部署形态(裸金属 / 虚拟化 / 容器)
-
不同使用约束(政务、私有、混合、国产化要求)
算力的首要难点,从来不是“算力不够”,而是“异构”。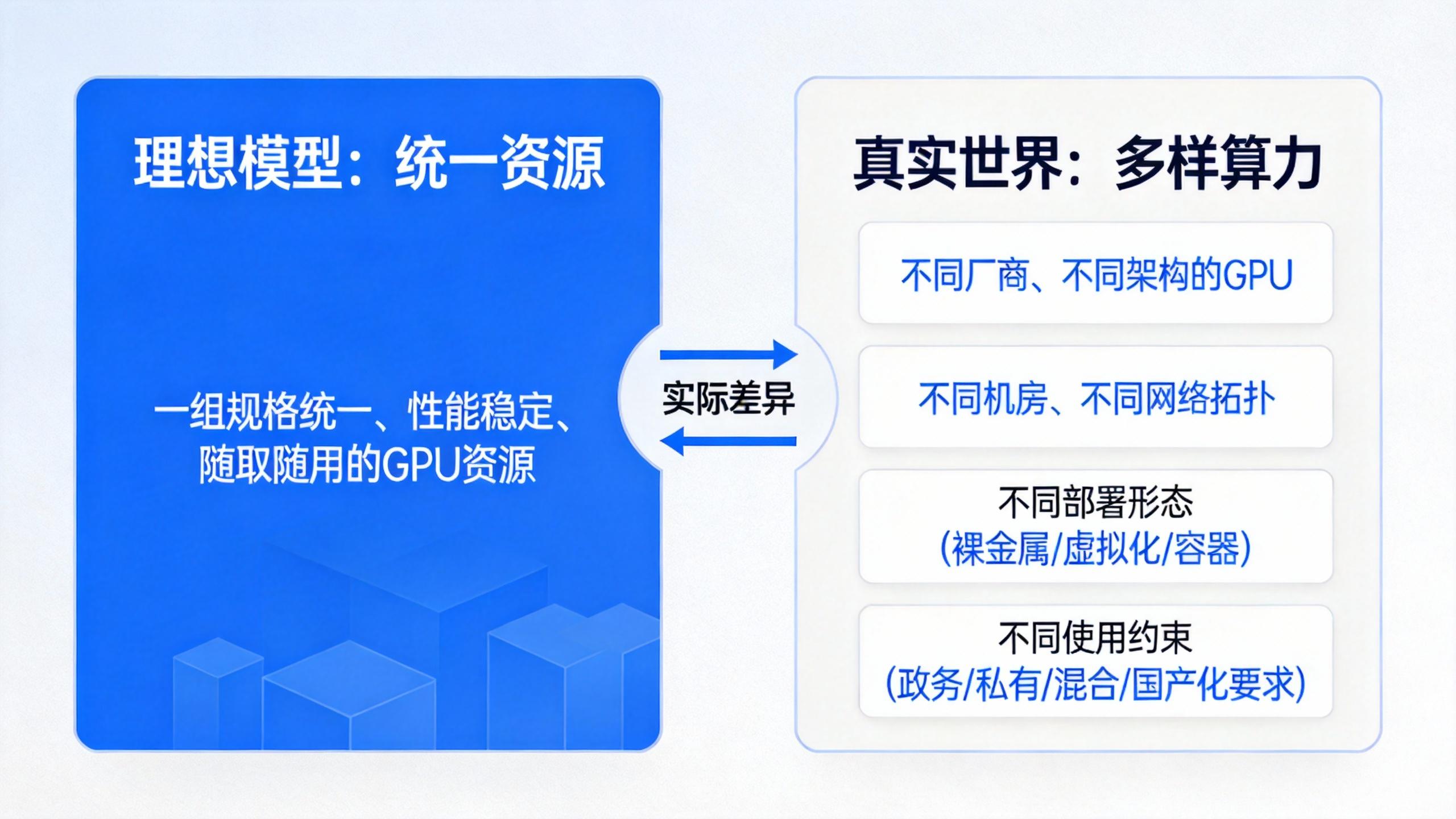
二、为什么传统 IaaS / Kubernetes 调度不适合 AI 任务?
很多团队会自然地问一个问题:
用 Kubernetes / Slurm / 云厂商调度,不就够了吗?
从我们的实践来看,问题主要出在三个方面。
1️⃣ AI 任务不是“短生命周期任务”
传统云计算调度,假设任务是:
-
可快速重启
-
对中断不敏感
-
失败成本可控
但 AI 训练任务往往:
-
持续数小时到数天
-
GPU 中断代价极高
-
网络抖动可能直接导致训练失败
👉 调度的目标不只是“跑起来”,而是“稳定跑完”。
2️⃣ GPU ≠ CPU,调度维度完全不同
在 AI 场景中,GPU 调度至少涉及:
-
显存容量
-
NVLink / PCIe 拓扑
-
GPU 之间的通信带宽
-
存储与数据通路
而这些信息,在传统调度器中要么不可见,要么无法参与决策。
3️⃣ AI 任务对“位置”高度敏感
-
数据在哪里?
-
模型权重在哪里?
-
网络跨区域 RTT 是否可接受?
如果只做“资源空闲优先”的调度,很容易出现:
GPU 很空,但模型跑得极慢。

三、算力调度的核心,其实是“任务建模”
在奇点算力云的工程设计中,我们没有把调度的第一层抽象定义为 GPU,
而是定义为 “AI 任务”。
一个 AI 任务,至少包含以下信息:
-
任务类型(训练 / 推理 / 微调)
-
所需 GPU 数量与显存规格
-
对通信带宽 / 延迟的要求
-
对稳定性的容忍度
-
数据与模型所在位置
调度不是“找空闲 GPU”,而是“给任务找最合适的算力环境”。
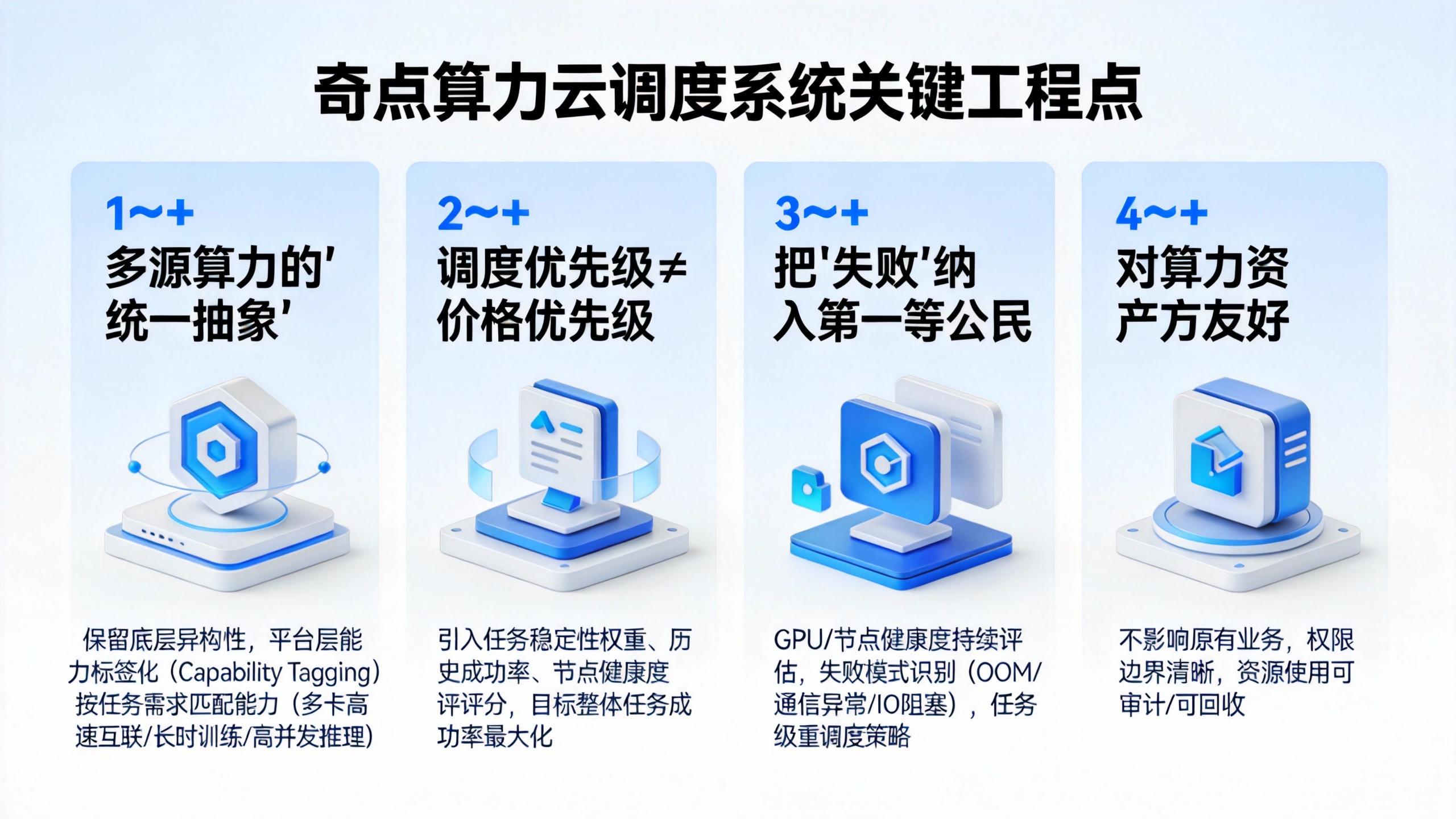
四、奇点算力云调度系统的几个关键工程点
下面是一些我们在实际工程中踩过坑、也反复验证有效的设计思路。
1️⃣ 多源算力的“统一抽象”,而不是强行同构
现实中不可能让所有算力环境完全一致。
我们的做法是:
-
保留底层异构性
-
在平台层做能力标签化(Capability Tagging)
-
调度时按任务需求匹配能力,而不是型号
例如:
-
是否支持多卡高速互联
-
是否适合长时训练
-
是否适合高并发推理
2️⃣ 调度优先级 ≠ 价格优先级
很多算力平台简单地用“谁出价高给谁”,
但在工程层面,这往往导致整体效率下降。
奇点算力云在调度中引入:
-
任务稳定性权重
-
历史成功率
-
节点健康度评分
目标不是单次收益最大化,而是整体任务成功率最大化。
3️⃣ 把“失败”纳入调度系统的第一等公民
AI 训练失败并不罕见,关键是:
-
能否快速感知
-
能否自动迁移
-
能否避免反复失败
我们在调度层面引入:
-
GPU / 节点健康度持续评估
-
失败模式识别(OOM / 通信异常 / IO 阻塞)
-
任务级重调度策略
4️⃣ 调度系统必须“对算力资产方友好”
算力流通的前提,是算力资产方愿意接入。
这意味着调度系统必须做到:
-
不影响原有业务
-
权限边界清晰
-
资源使用可审计、可回收
否则,平台永远只能靠“自营算力”。
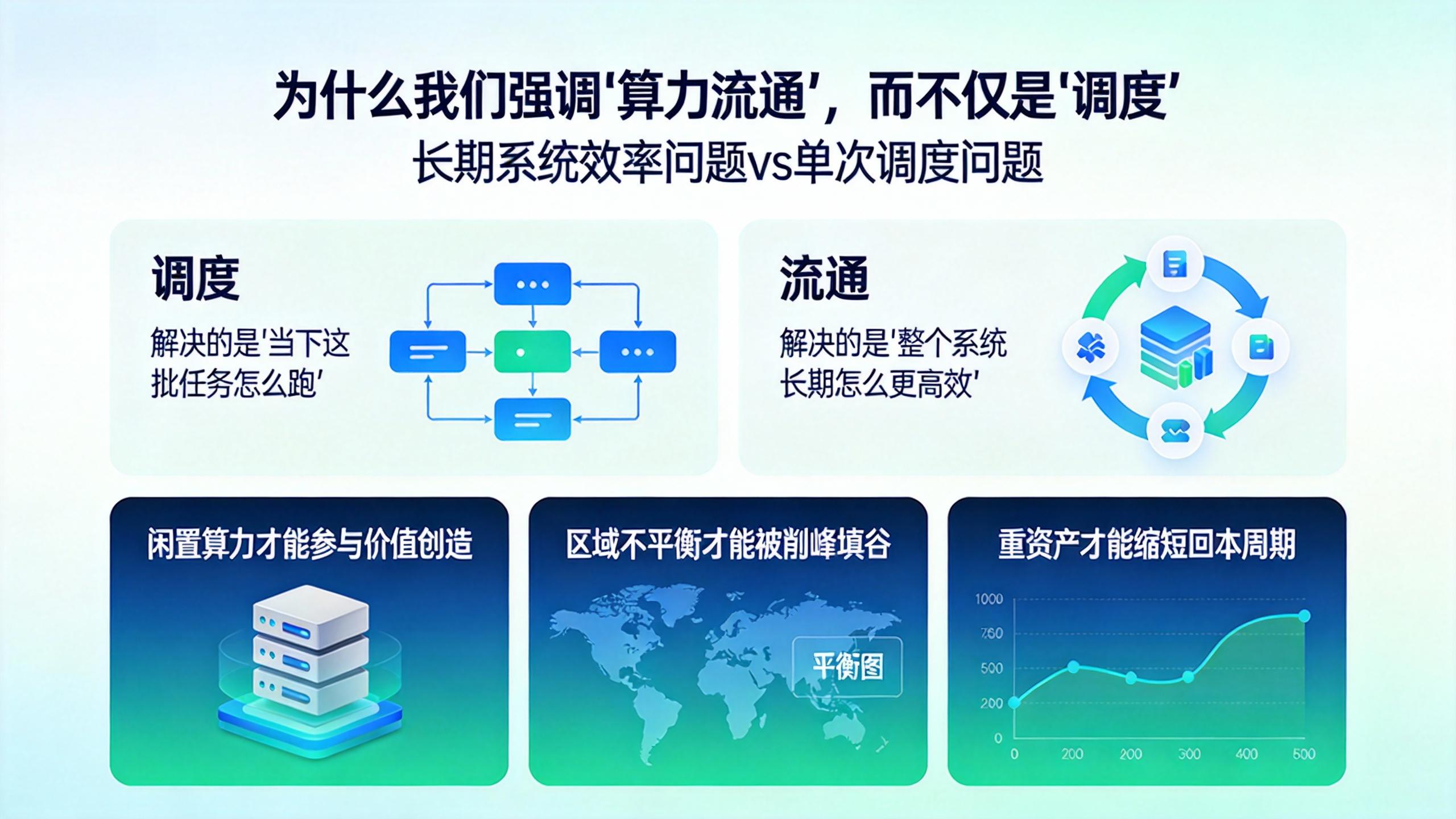
五、为什么我们强调“算力流通”,而不仅是“调度”
调度解决的是 “当下这批任务怎么跑”,
而流通解决的是 “整个系统长期怎么更高效”。
当算力可以流通:
-
闲置算力才能参与价值创造
-
区域不平衡才能被削峰填谷
-
重资产才能缩短回本周期
从工程角度看,这其实是一个:
长期系统效率问题,而不是单次调度问题。
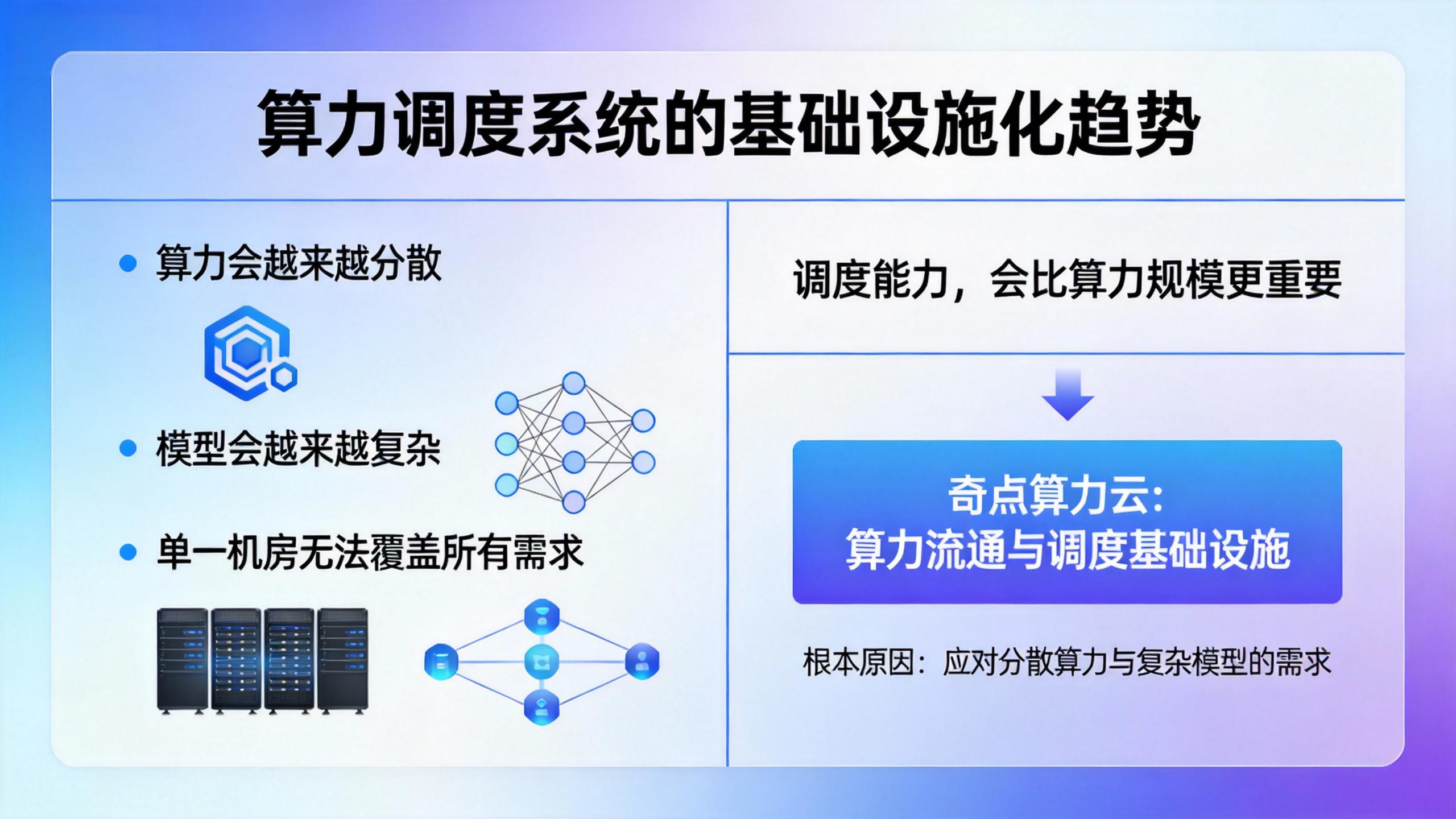
六、算力调度系统,最终会走向“基础设施化”
我们越来越清晰地看到一个趋势:
-
算力会越来越分散
-
模型会越来越复杂
-
单一机房无法覆盖所有需求
在这种情况下:
调度能力,会比算力规模更重要。
这也是奇点算力云选择做“算力流通与调度基础设施”的根本原因。
七、写给工程师的最后一句话
如果你曾经遇到过:
-
GPU 明明很多,却总跑不顺
-
训练任务反复失败却无从下手
-
算力资源分散,无法统一管理
那么你遇到的,本质上都是调度问题。
奇点算力云正在尝试,从工程层面把这个问题系统性地解决掉。
📌 这是奇点算力云技术系列的第一篇工程向文章
后续我们将继续拆解:
-
算力调度系统的架构设计
-
GPU 利用率提升的真实案例
-
国产算力在实际 AI 任务中的调度实践
欢迎持续交流。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)