可运维性分阶段建设实践:从目标设定到AI驱动的SRE转型思考
本文系统阐述了可运维性建设的分阶段实践路径与AI驱动的SRE转型策略。首先提出明确的三维目标体系(功能覆盖率80%-95%、系统可用性99.9%-99.99%、SRE研发精力优化分配),并建立量化指标体系。重点规划了SRE团队的年度研发目标和AI转型四阶段路线图(数据驱动→规则增强→自主学习→认知智能),详细介绍了各阶段技术重点与预期收益。通过分析全球领先企业的AIOps实践案例,展示了AI技术在
可运维性分阶段建设实践:从目标设定到AI驱动的SRE转型
在当今复杂的分布式系统环境中,可运维性(Operability)已成为系统稳定性和业务连续性的关键保障。随着AI技术的快速发展,SRE团队正面临前所未有的转型机遇。本文将分享一套完整的可运维性分阶段建设框架,并重点探讨如何通过AI技术实现SRE能力的质的飞跃,帮助团队从传统运维模式向智能化运维体系演进。
一、定目标:明确可运维性建设的核心指标
可运维性建设必须从明确的目标开始,避免盲目投入。我们建议设定以下三个维度的目标,并融入AI转型视角:
1. 功能覆盖率
目标值:80%-95%
- 初期阶段(0-6个月):核心功能覆盖率50%,确保关键业务链路的可运维能力
- 中期阶段(6-12个月):功能覆盖率提升至80%,覆盖主要业务场景
- 成熟阶段(12个月以上):功能覆盖率90%+,实现全方位可运维保障
- AI增强目标:在成熟阶段,30%的核心功能应具备AI驱动的自适应能力
2. 系统可用性
目标值:99.9%-99.99%
- 基础可用性:99.9%(全年宕机时间不超过8.76小时)
- 高可用性:99.95%(全年宕机时间不超过4.38小时)
- 金融级可用性:99.99%(全年宕机时间不超过52.6分钟)
- AI预测能力:通过AI预测,将计划外停机时间减少40%-60%
3. SRE研发精力分配
目标构成:工具研发40% + 平台建设30% + 业务支持30%
工具研发(40%)
- 监控工具:15%精力,构建统一的智能监控平台
- 自动化工具:15%精力,开发故障自愈、容量管理等自动化工具
- 效能工具:10%精力,研发研发效能提升工具链
平台建设(30%)
- 基础平台:10%精力,建设高可用、可扩展的基础设施平台
- AI平台:15%精力,构建MLOps平台、特征工程平台等AI基础设施
- 治理平台:5%精力,开发配置管理、变更管控等治理工具
业务支持(30%)
- 架构评审:10%精力,参与关键业务系统架构设计
- 故障支持:15%精力,提供重大故障的技术支持和复盘
- 能力建设:5%精力,为业务团队提供SRE能力培训
4. 研发时间占比的演进路径
目标值:运维投入占比20%-30%
- 初期阶段:SRE 70%时间用于救火和手动操作,30%用于研发
- 中期阶段:SRE 50%时间用于运维,50%用于研发工具和平台
- 成熟阶段:SRE 30%时间用于运维,70%用于研发和创新
- AI杠杆效应:引入AI后,同等运维效果下,人力投入可进一步降低30%-50%
- 最终目标:SRE团队80%精力投入价值创造(工具研发、架构优化、业务赋能)
二、定度量:建立可量化、可追踪的指标体系
目标需要通过具体的度量指标来验证,我们建议建立以下核心度量体系,并增加AI效果度量:
1. 功能完成度
- 计算公式:已实现可运维功能数 / 总规划功能数 × 100%
- AI功能占比:AI驱动功能数 / 总功能数 × 100%,目标值25%-40%
- 度量频率:每周统计,月度回顾
- 健康阈值:季度完成率不低于70%,年度完成率不低于90%
2. 服务调用成功率
- 核心指标:API成功率、服务间调用成功率、用户操作成功率
- AI优化效果:通过AI动态调优,成功率提升幅度(目标:5%-15%)
- 监控维度:按服务、按接口、按用户分组进行统计
- 目标要求:核心服务成功率≥99.95%,非核心服务≥99.9%
3. 故障缓冲能力(故障Buffer)
- 容量缓冲:系统设计容量的20%-30%作为安全余量
- AI预测缓冲:基于AI的容量预测准确率≥85%,减少过度预留
- 时间缓冲:故障检测到自动恢复的时间控制在5分钟以内
- AI加速:AI辅助故障定位时间缩短60%-80%
- 资源缓冲:关键服务预留30%的额外资源应对突发流量
三、SRE研发目标与计划
SRE团队不仅是运维保障者,更是效能提升的推动者。需要制定清晰的研发目标和实施计划:
1. 年度研发目标规划
Q1:基础能力筑基
- 监控体系重构:构建统一的智能监控平台,整合分散的监控工具
- 自动化框架搭建:开发通用的自动化任务执行框架
- 数据平台建设:构建运维数据湖,为AI应用奠定基础
- 关键指标:监控覆盖率提升至80%,自动化任务框架支持50+场景
Q2:AI能力孵化
- 异常检测模型:开发基于时序数据的异常检测算法
- 根因分析引擎:构建服务依赖图和根因分析算法
- 智能告警系统:实现告警收敛和智能分派
- 关键指标:异常检测准确率≥85%,告警噪音减少50%
Q3:平台能力深化
- 自愈平台建设:开发故障自愈引擎,支持常见故障自动修复
- 容量优化系统:实现基于AI的容量预测和优化建议
- 知识图谱构建:将运维知识结构化,支持智能问答
- 关键指标:自愈成功率≥70%,容量预测准确率≥80%
Q4:业务价值闭环
- 业务监控体系:将技术指标与业务指标关联分析
- 成本优化平台:实现资源成本的精细化管理和优化
- 效能度量体系:建立完整的研发效能度量和改进体系
- 关键指标:业务影响评估准确率≥90%,资源成本降低20%
2. SRE与研发团队的协作模式
嵌入式协作
- SRE嵌入研发团队:每个核心业务团队配置1名SRE,全程参与需求评审、架构设计、代码审查
- 共同责任制:SRE与研发团队共同对系统可用性、性能、成本负责
- 效能指标:SRE参与的需求评审覆盖率100%,架构设计合规率≥95%
平台化赋能
- 自助服务平台:构建研发自助服务平台,提供监控、日志、报警等能力
- 标准规范输出:制定并推广统一的技术标准和最佳实践
- 培训体系建设:定期为研发团队提供SRE相关培训
- 效能指标:自助服务使用率≥80%,标准规范遵循率≥90%
共建共享机制
- 工具共建:SRE与研发团队共同开发运维工具,确保工具贴合实际需求
- 知识共享:建立跨团队的知识共享机制,定期组织技术分享
- 故障共担:重大故障的复盘和改进由SRE和研发团队共同负责
- 效能指标:工具共建项目数量≥5个/年,知识分享频次≥2次/月
四、SRE AI转型战略:分阶段推进智能化演进
AI转型不是一蹴而就的,需要制定清晰的战略路径和阶段性目标:
1. AI转型的四个阶段
第一阶段:数据驱动(0-6个月)
- 核心任务:构建统一的数据湖,整合监控、日志、告警、工单等多源数据
- 技术重点:数据标准化、特征工程、基础数据管道建设
- 预期收益:数据可用性提升50%,为AI模型训练奠定基础
- 关键指标:数据覆盖率≥80%,数据质量评分≥85分
第二阶段:规则增强(6-12个月)
- 核心任务:将专家经验转化为可执行的规则,并与机器学习结合
- 技术重点:规则引擎优化、简单机器学习模型(如决策树、随机森林)
- 应用场景:智能告警收敛、基础故障分类、资源推荐
- 预期收益:告警噪音减少40%,故障分类准确率≥85%
- 关键指标:AI辅助决策占比30%,人工干预率降低40%
第三阶段:自主学习(12-18个月)
- 核心任务:构建自学习、自适应的AI运维系统
- 技术重点:深度学习、强化学习、时序预测模型
- 应用场景:异常检测、根因分析、容量预测、自动扩缩容
- 预期收益:MTTR缩短50%,资源利用率提升25%
- 关键指标:自主处理能力≥60%,预测准确率≥90%
第四阶段:认知智能(18-24个月)
- 核心任务:实现具备业务理解能力的认知运维系统
- 技术重点:大语言模型、知识图谱、多模态学习
- 应用场景:业务影响分析、变更风险评估、运维知识问答、自动化报告生成
- 预期收益:运维决策质量提升70%,业务中断时间减少60%
- 关键指标:认知理解准确率≥85%,用户满意度≥90%
2. AI技术栈选型指南
数据层
- 时序数据库:InfluxDB、TimescaleDB(处理监控指标)
- 日志平台:ELK Stack、Loki(日志收集与分析)
- 图数据库:Neo4j、JanusGraph(服务依赖关系建模)
算法层
- 异常检测:LSTM、Transformer、Isolation Forest
- 根因分析:贝叶斯网络、因果推理、图神经网络
- 容量预测:Prophet、ARIMA、深度学习时序模型
- 自然语言处理:BERT、GPT系列(工单分析、知识问答)
应用层
- AIOps平台:自研或商业平台(如Datadog、New Relic的AI功能)
- 低代码AI:AutoML工具,让运维工程师也能参与模型训练
- MLOps集成:模型版本控制、持续训练、A/B测试
五、业界顶尖AIOps落地实践深度解析
保持对行业前沿实践的关注是SRE团队成功转型的关键。以下是当前业界领先的AIOps实践案例和经验总结:
1. 全球领先企业的AIOps实践
互联网巨头:数据驱动的智能运维
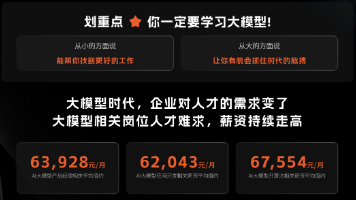
- 某头部电商平台:通过AI实现大促期间的智能容量预测,将资源利用率从30%提升至70%,每年节省服务器成本数亿元
- 某社交平台:构建基于深度学习的异常检测系统,将故障发现时间从15分钟缩短到30秒,年减少损失超千万美元
- 某视频平台:采用强化学习实现CDN智能调度,用户卡顿率降低40%,带宽成本下降25%
金融科技:高可靠性的AI保障
- 某国际银行:实施AI驱动的交易监控系统,欺诈检测准确率从85%提升至98%,误报率降低60%
- 某证券公司:构建基于知识图谱的故障定位系统,MTTR从45分钟缩短到8分钟,满足金融级合规要求
- 某支付平台:通过时间序列预测提前14天预测系统瓶颈,实现零感知扩容,全年可用性达99.999%
传统企业转型:从被动到主动
- 某制造业巨头:将IoT数据与AI结合,实现生产设备预测性维护,设备停机时间减少65%
- 某零售企业:通过AI优化门店IT基础设施,运维人力投入减少40%,系统稳定性提升300%
- 某电信运营商:构建端到端的智能运维平台,网络故障自愈率达到85%,客户投诉下降50%
2. 2025年AIOps前沿趋势
技术趋势
- 大模型与AIOps融合:LLM在运维知识管理、自然语言交互、自动化决策中的深度应用
- 边缘AI运维:在边缘计算环境中实现实时AI分析,减少数据传输延迟和带宽成本
- 多模态学习:融合指标、日志、调用链、业务数据等多维度信息,提升分析准确率
- 联邦学习应用:在保护数据隐私的前提下,实现跨企业、跨业务的AI模型协同训练
实践趋势
- 从救火到防火:AIOps重点从故障响应转向故障预防,预测准确率成为核心指标
- 业务驱动的AIOps:将技术指标与业务指标深度关联,直接衡量运维对业务价值的影响
- 人机协同优化:AI不是替代人类,而是增强人类能力,构建高效的协作机制
- 成本效益平衡:在AI投入与收益之间找到最佳平衡点,避免过度追求技术先进性
3. AIOps成功的关键因素
根据Forrester等权威机构的研究,成功实施AIOps需要关注以下关键因素:
组织因素
- 高层支持:获得CTO/CIO级别的认可,确保资源投入
- 跨团队协作:打破运维、开发、数据科学团队之间的壁垒
- 技能转型:投资于团队技能提升,培养具备AI思维的SRE人才
技术因素
- 数据质量优先:80%的AIOps失败源于数据质量问题,必须优先解决
- 渐进式演进:从小场景开始,验证效果后再扩展,避免"大爆炸"式实施
- 可解释性:关键决策必须可解释,避免"黑盒"操作带来的信任问题
- 弹性架构:AI系统本身需要高可用设计,避免成为新的单点故障
流程因素
- 实验文化:建立A/B测试机制,持续验证AI效果
- 快速反馈:构建实时的模型效果监控和反馈机制
- 持续优化:AI模型需要持续训练和优化,避免模型退化
六、获取AIOps前沿信息的权威途径
保持对行业动态的敏感度,需要建立系统化的信息获取机制:
1. 权威研究报告与评估
国际权威机构报告
- Gartner魔力象限:每年发布的IT Operations Analytics (ITOA)和AIOps平台魔力象限,提供厂商能力评估
- Forrester Wave报告:2025年第二季度的AIOps平台报告将Dynatrace评为领导者,为选型提供重要参考
- IDC市场指南:IDC发布的AIOps解决方案市场指南,分析市场规模、增长趋势和厂商格局
- 中国信通院报告:《中国AIOps现状调查报告(2024)》将于2024年下半年发布,包含最佳实践案例
行业白皮书与指南
- SRE基金会白皮书:Google、LinkedIn等SRE实践者发布的AIOps实施指南
- CNCF云原生报告:云原生计算基金会发布的可观测性与AIOps趋势报告
- IEEE/ACM论文:学术界在AIOps算法、架构方面的最新研究成果
2. 专业社区与会议
国际顶级会议
- SREcon:由USENIX主办的SRE领域顶级会议,2025年将重点关注AI与SRE融合
- KubeCon+CloudNativeCon:云原生领域最大规模会议,设立专门的AIOps和可观测性分论坛
- AI in IT Summit:专注于AI在IT运维中应用的专业会议,提供140+个实际用例和案例研究
- Gartner IT Symposium/Xpo:Gartner年度IT峰会,包含AIOps战略规划和实施路径
国内专业论坛
- XOps产业论坛:2024年将发布《中国AIOps现状调查报告》最佳实践章节
- 云栖大会:阿里云主办,2025年重点关注从云原生到AI原生的核心技术与最佳实践
- GOPS全球运维大会:国内最大的运维技术盛会,设立AIOps专场
- AIOps社区Meetup:全国各地的AIOps技术沙龙,提供实操经验分享
3. 技术社区与开源项目
开源社区
- OpenTelemetry:CNCF毕业项目,是可观测性数据采集的事实标准,2025年将深度集成AI能力
- Prometheus生态:时序数据库领域的领导者,社区活跃度高,插件丰富
- Apache SkyWalking:国内开源的APM项目,提供AI驱动的根因分析功能
- MLflow:机器学习生命周期管理平台,适合AIOps模型管理
技术论坛与博客
- Google SRE Blog:Google SRE团队的官方博客,分享最前沿的SRE实践
- Dynatrace Blog:AIOps领导者Dynatrace的技术博客,提供大量实践案例
- InfoQ技术社区:设立AIOps专栏,定期发布技术文章和案例分析
- 知乎/掘金技术专栏:国内技术社区,有大量一线工程师分享的实战经验
4. 专业培训与认证
厂商认证
- Dynatrace AIOps认证:全球认可的AIOps专业认证
- Datadog Certified Engineer:侧重于云监控和AIOps实践
- 阿里云AIOps专家认证:国内领先的AIOps技术认证
- 华为云AIOps架构师认证:面向企业级AIOps架构设计
学术培训
- CMU SRE课程:卡内基梅隆大学的SRE专业课程,包含AIOps模块
- 斯坦福AI for Operations:斯坦福大学的AI运维专业课程
- 中国科学院大学AIOps研修班:国内顶尖学术机构的AIOps培训项目
- Coursera/edX在线课程:平台上的AIOps专业课程,如"AI for IT Operations"
5. 建立内部信息获取机制
知识管理体系
- 定期技术雷达:每季度更新AIOps技术雷达,评估新技术成熟度
- 案例库建设:建立内部AIOps案例库,记录成功和失败的经验
- 外部专家交流:定期邀请外部专家进行技术分享和咨询
- 竞争对手分析:跟踪行业竞争对手的AIOps实施进展
实践学习机制
- POC项目:每季度选择1-2个新技术进行概念验证
- 黑客马拉松:组织AIOps主题的黑客马拉松,激发创新
- 外部考察:参观领先企业的AIOps实施现场
- 开源贡献:鼓励团队成员参与开源AIOps项目,保持技术前沿性
七、AI驱动的自动化场景深化
在原有自动化基础上,AI技术将带来质的飞跃:
1. 智能审批工单
- 传统方式:基于固定阈值的简单规则
- AI增强:
- 基于历史工单数据的学习,自动识别高风险操作
- 动态调整审批策略,根据操作者历史行为、系统负载、业务时段等因素
- 风险评分模型,准确率可达95%+
- 效果:审批效率提升300%,误审批率降低80%
2. 预测性扩缩容
- 传统方式:基于固定阈值的响应式扩缩容
- AI增强:
- 多维度预测:结合业务周期、营销活动、历史趋势、外部事件
- 动态阈值调整:根据实时负载和预测结果自动调整扩缩容阈值
- 成本优化:在SLA约束下自动寻找成本最优的资源组合
- 效果:资源利用率提升40%,扩缩容延迟减少90%
3. 智能故障处理
- 传统方式:人工诊断 + 标准化恢复流程
- AI增强:
- 故障预测:提前15-30分钟预测可能发生的故障,准确率85%+
- 根因定位:基于图神经网络的依赖分析,定位准确率90%+
- 自愈策略:强化学习驱动的自愈策略选择,成功率80%+
- 知识沉淀:自动将故障处理过程转化为可复用的知识
- 效果:MTTR从小时级降至分钟级,人工干预减少70%
4. 智能监控优化
- 传统监控:固定阈值告警,高噪音
- AI增强:
- 动态基线:自动学习正常行为模式,适应业务变化
- 智能收敛:基于故障传播图的告警聚合,减少90%噪音
- 业务影响分析:自动评估故障对核心业务指标的影响程度
- 语音交互:通过自然语言查询系统状态,降低使用门槛
- 效果:运维人员专注度提升3倍,关键问题发现速度提升5倍
八、平台功能分阶段发布策略(AI增强版)
可运维平台的功能建设需要采用渐进式发布策略,控制风险的同时快速迭代:
1. 内测版(Alpha阶段)
- 目标用户:SRE团队、核心开发团队
- 功能范围:核心监控、基础告警、关键自动化流程 + 基础AI功能(异常检测、简单预测)
- AI特性:规则引擎+基础机器学习模型,人工审核AI决策
- 发布周期:每周迭代,快速验证
- 质量要求:功能完整,AI模型准确率≥70%
- 持续时间:1-2个月
2. 公测版(Beta阶段)
- 目标用户:所有技术团队,部分业务团队
- 功能范围:完整功能集,包含自动化运维、容量管理、故障自愈 + 高级AI功能(根因分析、容量预测)
- AI特性:深度学习模型,A/B测试验证效果,人工与AI协同决策
- 发布周期:每两周迭代,注重稳定性
- 质量要求:核心功能稳定性99.9%,AI决策准确率≥85%
- 持续时间:2-3个月
3. 正式上线(GA阶段)
- 目标用户:全公司技术团队
- 功能范围:全部规划功能,包含高级分析、智能预测、认知运维
- AI特性:自适应学习系统,持续优化,关键决策可解释
- 发布周期:每月迭代,以稳定性为首要目标
- 质量要求:整体可用性99.95%,AI辅助决策占比≥70%
- 关键节点:设定明确的上线deadline,建议在季度末或财年末
九、监控覆盖率建设与AI融合
全面的监控体系是可运维性的基础保障,AI将带来革命性变化:
1. 智能基础设施监控
- 传统监控:固定阈值,被动告警
- AI增强:
- 设备故障预测:磁盘、CPU、内存等硬件故障提前预测
- 性能瓶颈识别:自动识别系统性能瓶颈点
- 资源浪费检测:识别闲置或过度配置的资源
- 目标覆盖率:100%,AI预测覆盖关键设备80%+
2. 应用性能监控(APM)智能化
- 传统APM:响应时间、错误率等基础指标
- AI增强:
- 代码级性能分析:自动识别性能劣化的代码路径
- 依赖关系建模:动态构建服务依赖图,识别关键路径
- 业务交易追踪:将技术指标与业务指标关联分析
- 目标覆盖率:95%+,AI分析覆盖核心服务100%
3. 业务监控的认知化
- 传统业务监控:KPI仪表盘
- AI增强:
- 异常业务行为检测:识别欺诈、刷单等异常模式
- 业务趋势预测:准确预测用户增长、交易量等关键指标
- 归因分析:自动分析业务指标变化的根本原因
- 目标覆盖率:90%+,预测准确率≥85%
4. 全链路监控的智能化
- 传统链路监控:调用链追踪
- AI增强:
- 智能链路分析:自动识别性能瓶颈链路
- 故障传播预测:预测故障可能影响的范围
- 优化建议生成:基于链路分析自动生成优化建议
- 目标覆盖率:85%+,AI分析准确率≥90%
十、MTTR与MTBF的AI驱动优化
MTTR(平均故障恢复时间)和MTBF(平均故障间隔时间)是衡量系统可靠性的黄金指标,AI将带来突破性改进:
1. MTTR优化策略(AI增强)
- 当前水平:30-60分钟
- 目标水平:5-10分钟(AI驱动)
- AI优化路径:
- 故障检测:AI异常检测将平均检测时间从10分钟缩短到30秒内
- 故障定位:图神经网络驱动的根因分析将定位时间从15分钟缩短到1分钟
- 故障恢复:强化学习驱动的自愈策略将恢复时间从15分钟缩短到2分钟
- 知识辅助:LLM驱动的运维知识助手,为人工处理提供实时指导
2. MTBF提升策略(AI增强)
- 当前水平:7-15天
- 目标水平:180+天(AI驱动)
- AI关键措施:
- 预测性维护:通过深度学习预测组件失效,提前7-14天预警
- 智能变更管控:AI风险评估模型,变更失败率降低60%
- 动态容量规划:基于业务增长预测和季节性模式,提前2-4周规划容量
- 架构韧性评估:自动识别架构中的单点故障,提供优化建议
十一、Oncall效能提升方案
Oncall是SRE工作的核心环节,直接影响系统稳定性和团队幸福感。需要系统化提升Oncall效能:
1. Oncall现状评估
关键痛点分析
- 告警疲劳:平均每人每晚接收20-30条告警,有效告警占比不足10%
- 响应延迟:平均响应时间超过10分钟,影响故障处理时效
- 知识断层:新成员需要3-6个月才能独立处理复杂故障
- 压力过大:70%的SRE表示Oncall压力影响工作生活平衡
2. 智能Oncall系统建设
分层告警机制
- P0级告警:业务完全不可用,需1分钟内响应
- P1级告警:核心业务严重降级,需5分钟内响应
- P2级告警:非核心业务问题,需30分钟内响应
- P3级告警:性能或容量预警,可在工作时间内处理
AI增强的告警处理
- 智能收敛:基于故障传播关系自动聚合相关告警,减少90%告警量
- 优先级排序:根据业务影响、用户影响、技术严重性自动排序
- 根因预判:在告警触发时自动提供可能的根因分析
- 处理建议:基于历史处理记录,提供标准化的处理建议
自动化响应流程
- 自动诊断:触发告警后自动执行诊断脚本,收集关键信息
- 自动恢复:对于已知故障模式,自动执行恢复操作
- 自动升级:根据故障严重性和处理时效,自动升级到更高级别
- 自动通知:根据业务影响范围,自动通知相关业务方
3. Oncall能力建设
技能矩阵体系
- 基础技能:监控工具使用、日志分析、基础故障处理(100%覆盖)
- 中级技能:性能分析、容量规划、架构优化(80%覆盖)
- 高级技能:根因分析、系统设计、AI模型应用(50%覆盖)
- 专家技能:业务影响评估、战略规划、技术创新(20%覆盖)
实战训练机制
- 故障注入演练:每周进行1次真实故障注入演练
- 影子Oncall:新成员跟随经验丰富的Oncall工程师学习
- 案例复盘:每周复盘1-2个典型故障案例,提炼最佳实践
- 技能认证:建立Oncall技能认证体系,确保能力达标
4. Oncall体验优化
轮值机制优化
- 轮值周期:从传统的7天轮值优化为3天轮值,减少连续压力
- 备份机制:每班设置1名主Oncall + 1名备份Oncall
- 交接机制:建立标准化的交接流程,确保信息不丢失
- 假期补偿:Oncall期间的假期加倍补偿,平衡工作生活
工具体验升级
- 移动端优化:开发轻量级移动App,支持快速响应
- 语音交互:支持语音指令查询系统状态、执行简单操作
- 知识集成:将知识库与告警系统集成,一键获取相关文档
- 疲劳监测:通过响应时间、操作频次监测Oncall疲劳度,自动调整
5. Oncall效果度量
核心指标
- MTTA(平均响应时间):目标≤3分钟
- MTTR(平均恢复时间):目标≤15分钟
- 告警准确率:目标≥95%
- 自动化处理率:目标≥70%
- Oncall满意度:目标≥85分
持续改进机制
- 每周回顾:分析Oncall数据,识别改进点
- 月度优化:根据数据反馈优化告警规则和处理流程
- 季度评估:全面评估Oncall体系效果,制定下季度改进计划
- 年度升级:基于技术发展和业务变化,升级Oncall架构
十二、SRE与业务团队的深度合作模式
SRE的价值不仅在于技术保障,更在于业务赋能。需要建立与业务团队的深度合作机制:
1. 业务价值对齐机制
共同目标设定
- 业务KPI关联:将SRE指标与业务KPI直接关联,如"系统可用性每提升0.1%,GMV提升X万元"
- 季度规划对齐:每季度与业务团队共同制定技术目标,确保技术投入支撑业务发展
- 成本效益分析:为每个重大技术决策提供成本效益分析,帮助业务团队理解技术价值
价值度量体系
- 技术价值量化:将技术改进转化为业务价值,如"性能优化带来用户留存率提升X%"
- 故障成本计算:精确计算每次故障的业务损失,提升故障预防意识
- 投资回报评估:定期评估SRE投入的ROI,向业务团队展示价值
2. 前置介入机制
需求评审阶段
- SRE早期参与:SRE团队在需求评审阶段就参与,评估可运维性风险
- 架构设计评审:对关键业务系统的架构设计进行SRE评审,提出优化建议
- 容量规划支持:基于业务增长预测,提前规划系统容量,避免业务高峰期瓶颈
开发测试阶段
- 质量门禁设置:在CI/CD流程中设置SRE质量门禁,如性能基线、错误率阈值
- 混沌工程实验:在测试环境进行混沌工程实验,验证系统韧性
- 监控埋点审核:审核关键业务路径的监控埋点,确保可观测性
3. 协同运营机制
业务指标共建
- 核心业务指标:与业务团队共同定义核心业务指标,如订单成功率、支付成功率
- 技术业务映射:建立技术指标与业务指标的映射关系,快速定位业务问题
- 实时业务看板:为业务团队提供实时的业务健康度看板
故障协同处理
- 统一指挥体系:建立技术+业务的联合指挥体系,重大故障时快速决策
- 业务影响评估:SRE团队提供技术影响,业务团队提供业务影响,共同制定恢复策略
- 事后复盘机制:故障复盘必须包含业务影响分析,制定技术+业务的改进措施
4. 能力建设协同
知识共享机制
- 技术培训:SRE定期为业务团队提供技术培训,提升业务团队的技术理解
- 业务培训:业务团队为SRE提供业务知识培训,帮助SRE理解业务价值
- 联合工作坊:定期组织技术+业务的联合工作坊,解决跨领域问题
工具共建共享
- 自助服务平台:为业务团队提供自助服务平台,支持简单的故障诊断和处理
- 业务监控工具:与业务团队共建业务监控工具,将技术指标转化为业务语言
- 反馈收集机制:建立业务团队对SRE服务的反馈机制,持续改进服务质量
十三、SRE AI转型的组织与文化变革
技术转型必须伴随组织和文化的同步变革:
1. 人才结构转型
- 技能重塑:运维工程师需要掌握基础数据科学技能
- 新角色引入:MLOps工程师、数据科学家、AI产品经理
- 能力矩阵:
- 传统SRE技能:40%
- 数据分析能力:30%
- AI/ML理解:20%
- 业务理解:10%
2. 工作流程重构
- 数据驱动决策:所有运维决策必须有数据支撑
- 实验文化:建立A/B测试机制,持续验证AI效果
- 知识共享:构建组织级知识库,AI自动沉淀经验
- 快速迭代:从月度迭代转向周度甚至日度迭代
3. 质量保障体系
- AI模型监控:监控模型准确率、偏移度、公平性
- 回滚机制:AI决策必须支持快速人工回滚
- 伦理审查:建立AI使用伦理准则,避免偏见和歧视
- 透明性要求:关键AI决策必须可解释、可审计
十四、实施建议与风险管控
1. 分阶段推进,小步快跑
- 每个阶段聚焦1-2个AI场景,深度优化而非广度覆盖
- 从非核心系统开始试点,验证效果后再推广到核心系统
- 建立快速反馈机制,每周回顾AI模型效果
2. 风险管控策略
- 模型退化监控:设置模型性能监控阈值,自动触发重新训练
- 人工兜底机制:关键决策保留人工审核环节
- 数据质量保障:建立数据质量监控体系,确保训练数据可靠性
- 伦理风险评估:定期评估AI决策的公平性和合理性
3. 投资回报评估
- 成本维度:AI基础设施成本、人才成本、维护成本
- 收益维度:人力节省、故障减少、资源优化、业务保障
- ROI计算:通常在12-18个月内实现正向ROI
- 关键指标:每投入1元AI成本,应产生3-5元的运维收益
结语
SRE的AI转型不是简单的技术升级,而是一场深刻的组织变革和技术革命。通过本文提出的分阶段建设框架,团队可以系统化地推进可运维性建设,并在AI技术的加持下实现能力的跨越式发展。
关键在于坚持数据驱动,用具体的指标来衡量进展,避免陷入"为AI而AI"的陷阱。AI技术应该作为增强人类能力的工具,而不是替代人类。优秀的SRE团队应该善用AI,将重复性工作交给机器,而将人类智慧聚焦在创造性的问题解决和战略规划上。
在AI时代,SRE的核心价值不是操作机器,而是定义问题、设计解决方案、评估效果。通过人机协作,我们可以构建出更加智能、更加可靠的运维体系,为业务发展提供前所未有的技术保障。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)