多模态大模型中的Cross-attention
Q-Former的设计体现了多模态大模型中的几个核心原则模态解耦:冻结单模态编码器,专注于跨模态对齐信息瓶颈:通过查询向量自适应压缩视觉信息多任务学习:ITC+ITM+ITG确保多层次对齐数学优雅性:Cross-Attention的简洁公式蕴含强大的表达能力数学基础:准确表述Cross-Attention公式几何直觉:流形、投影、压缩等概念工程思维:计算复杂度、训练成本、实际部署前沿视野:局限性和
知识点3:多模态大模型中的Cross-attention
注1:本文系"视觉方向大厂面试·硬核通关"专栏文章。本专栏致力于对多模态大模型/CV领域的高频高难面试题进行深度拆解。本期攻克的难题是: Cross-Attention在多模态大模型中的深度解析与Q-Former机制
注2:本文Markdown源码可提供下载,详情见文末
关注"大厂SSP我来啦"公众号,每天一个知识点的深度解析!
http://weixin.qq.com/r/mp/LCAsNAjEtVXKrUxX93U_ (二维码自动识别)
面试原题:BLIP-2中的Q-Former核心机制
问题陈述:
"请详细解释BLIP-2模型中Q-Former的设计原理。相比于LLaVA中简单的线性投影层,Q-Former通过Cross-Attention机制实现了视觉特征到语言空间的对齐。请从数学建模角度分析:
- Q-Former中可学习查询向量(Learnable Queries)如何通过Cross-Attention提取视觉特征?
- 为什么要冻结视觉编码器和语言模型,仅训练Q-Former?这背后的数学原理是什么?
- Q-Former采用的三种预训练目标(ITC、ITM、ITG)各自的作用是什么?
- 如果让你手写实现一个简化的Cross-Attention层,如何实现?"
关键回答
核心直觉:
Q-Former的本质是在冻结的高维视觉特征空间和冻结的语言嵌入空间之间,通过一组可学习的查询向量(Learnable Queries)和Cross-Attention机制,构建了一个信息瓶颈(Information Bottleneck)。这个瓶颈不是简单的线性投影,而是一个自适应的特征选择和压缩模块,它能够从视觉特征中动态提取与语言任务最相关的信息,同时忽略无关的视觉细节。
⚠️ 追问:这里的"自适应"具体是指什么?请用数学公式解释查询向量如何"学习"到关注哪些视觉区域。
从数学角度看,Q-Formers解决了多模态对齐中的模态鸿沟(Modality Gap)问题。视觉特征和语言特征在初始空间中分布差异巨大,直接线性对齐会导致信息损失和语义扭曲。Q-Former通过软约束(Soft Constraint)和多任务学习(Multi-task Learning),在保持视觉信息完整性的同时,实现了向语言空间的平滑过渡。
与LLaVA的关键区别:
- LLaVA:简单线性投影(Wv × V)→ 快速但信息损失大
- Q-Former:Cross-Attention + 可学习查询 → 计算复杂但信息保留充分
深度原理解析:从数学建模到几何直觉
一、Cross-Attention的数学本质
1.1 标准Cross-Attention公式
给定查询向量 Q(来自可学习查询或文本)、键向量 K(来自视觉特征)、值向量 V(来自视觉特征),Cross-Attention的计算过程如下:
其中:
- Q ∈ ℝ^(n×d_k):查询矩阵(n个查询向量,每个维度为d_k)
- K ∈ ℝ^(m×d_k):键矩阵(m个视觉token的键表示)
- V ∈ ℝ^(m×d_v):值矩阵(m个视觉token的值表示)
- d_k:缩放因子,用于避免点积过大导致梯度消失
面试官追问点:为什么需要除以√d_k?
回答要点:这是为了控制梯度的范数。当d_k较大时,点积QK^T的值会很大,导致softmax的梯度趋于0(梯度消失)。除以√d_k可以保持梯度的稳定性。
1.2 几何解释
从几何角度看,Cross-Attention执行的是查询向量在视觉特征空间中的投影:
这可以理解为:
- 相似度计算:计算每个查询向量Q与所有视觉token的余弦相似度
- 权重分配:通过softmax将相似度转换为概率分布
- 特征聚合:按照权重对所有视觉特征进行加权求和
流形视角:
- 视觉特征位于高维流形 M_v 上
- 语言特征位于另一个高维流形 M_l 上
- Q-Former构建了一个映射函数 f: M_v → M_l
- 这个映射不是全局的,而是局部自适应的(通过查询向量Q)
图1:Cross-Attention机制示意图,展示了查询向量Q与键K、值V之间的交互过程
二、Q-Former的架构设计
2.1 Q-Former的核心组件
Q-Former由两个Transformer子模块组成:
(1)Image Transformer
- 输入:可学习查询向量 Q_q ∈ ℝ^(L×d)
- 功能:通过Self-Attention和Cross-Attention与视觉特征交互
- 输出:视觉查询特征 Q_out ∈ ℝ^(L×d)
- 输入:文本token T ∈ ℝ^(N×d) + 可学习查询 Q_q
- 功能:作为文本编码器和解码器
- 输出:对齐的文本特征 T_out ∈ ℝ^(N×d)
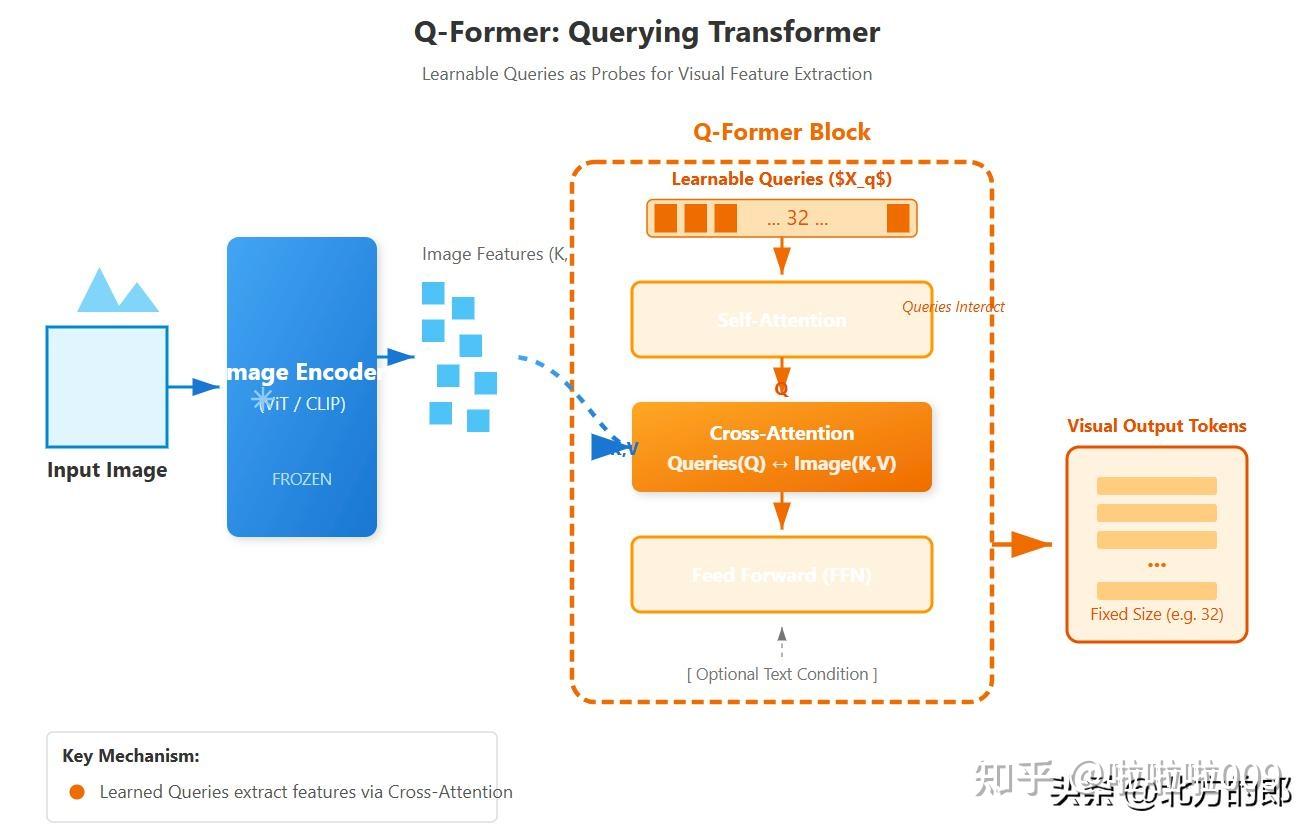
图2:BLIP-2中Q-Former的详细架构,展示了可学习查询向量如何通过自注意力和交叉注意力与图像特征交互
2.2 Cross-Attention层的数学表达
在Q-Former的Image Transformer中,每个Block的结构为:
其中:
- Q:可学习查询向量(初始化为可学习参数)
- K_img, V_img:来自冻结视觉编码器的特征(作为Cross-Attention的Key和Value)
关键洞察:
- Q-Former中的查询向量Q是端到端学习的
- 初始化时,这些查询向量是随机初始化的
- 通过多任务训练,查询向量学会关注视觉特征中与语言任务相关的区域
⚠️ 避坑指南:很多人误以为Q-Former的查询向量是"固定模式"或"网格"。实际上,它们完全通过反向传播学习,训练前没有任何预设模式。
三、为什么要冻结视觉编码器和语言模型?
这是一个经典面试题,背后有深刻的数学和工程原理。
3.1 数学原理:梯度流的优化效率
如果同时训练视觉编码器(V)、语言模型(L)和Q-Former(Q),总参数量为:
梯度更新需要同时优化三个巨大的参数空间:
问题:
- 优化难度大:三个参数空间的梯度可能相互冲突
- 计算成本高:需要计算所有参数的梯度
- 灾难性遗忘:可能破坏预训练编码器/语言模型已有的知识
3.2 Q-Former作为桥梁的数学合理性
冻结V和L后,仅训练Q,优化目标变为:
其中:
- g_V(I):冻结的视觉编码器,输出视觉特征
- h_L(T):冻结的语言模型,输出文本嵌入
- f_Q(·):Q-Former的映射函数
- y:目标(文本生成、匹配分数等)
数学优势:
- 优化空间大幅缩小:仅需优化θ_Q(约1.18亿参数,相比LLM的1750亿参数)
- 梯度方向明确:Q-Former专注于模态对齐,不受其他任务干扰
- 避免知识遗忘:预训练编码器和语言模型的能力得到保留
图3:不同类型的Cross-Attention机制对比,展示了Q-Former在多模态融合中的独特设计
3.3 信息论视角
从信息论角度看,Q-Former执行的是有损信息压缩:
其中:
- I(V; L):视觉和语言的互信息
- I(V; Q):视觉和查询的互信息(最大化)
- I(Q; L|V):给定视觉时,查询和语言的互信息(最大化)
- H(Q|V):查询的熵(通过训练自适应调节)
Q-Former的目标是在最小化信息损失的同时,实现模态对齐。
四、三种预训练目标的数学解析
Q-Former的第一阶段训练采用三种损失函数,分别解决不同的对齐问题。
4.1 Image-Text Contrastive Learning (ITC)
目标:拉近正样本对(匹配的图文),推远负样本对(不匹配的图文)。
损失函数:
其中:
- q_i:第i个图像的Q-Former输出(取所有查询输出的最大值)
- t_i:第i个文本的CLIP文本嵌入
- τ:温度参数
- sim(·, ·):余弦相似度
关键洞察:
- ITC学习全局对齐:确保图像和文本在语义空间中的整体距离相近
- 使用单模态自注意力掩码(Unimodal Self-Attention Mask):防止查询向量直接看到文本token,避免信息泄露
⚠️ 面试官追问:为什么ITC需要使用单模态掩码?
回答:如果Q和T直接交互,模型会"偷懒",直接从文本token中复制信息,而不是从视觉特征中提取。掩码强制Q-Former真正理解视觉内容。
4.2 Image-Text Matching (ITM)
目标:判断给定的图像-文本对是否匹配(二分类任务)。
损失函数:
其中:
- y_i ∈ {0, 1}:标签(1表示匹配,0表示不匹配)
- p_i = σ(W_m · \text{mean}(Q_{aligned})) + b_m:匹配概率
- Q_aligned:经过双向自注意力后的查询输出
- W_m, b_m:分类头参数
关键洞察:
- ITM学习细粒度对齐:判断视觉和文本在语义上的具体对应关系
- 使用双向自注意力掩码(Bidirectional Self-Attention Mask):Q和T可以充分交互
面试加分项: ITM不仅判断匹配,还通过注意力权重可视化,提供可解释性。例如,当回答"图像中的猫是什么颜色?"时,ITM的注意力热力图应该集中在猫的毛发区域。
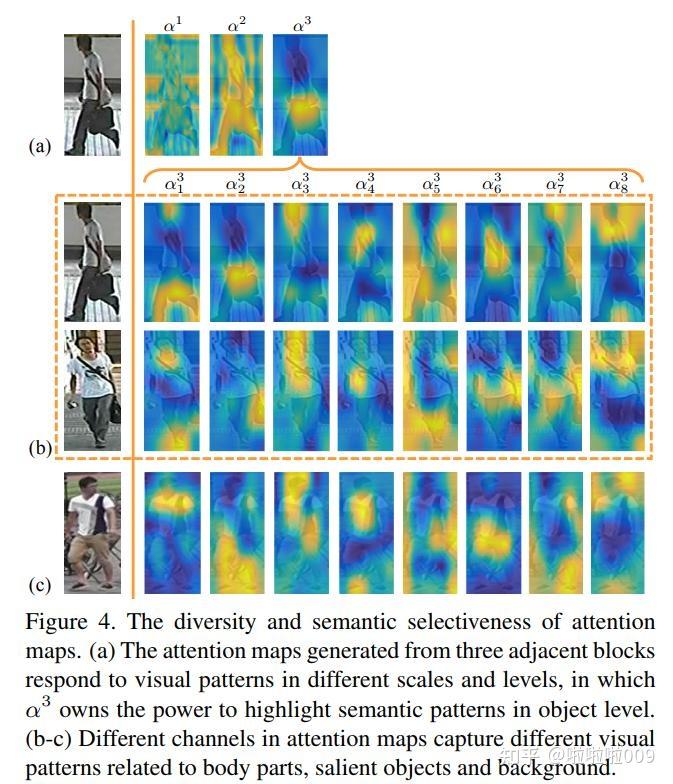
图4:注意力图的可视化,展示了不同通道捕捉的视觉模式,从全局语义到细粒度细节
4.3 Image-Grounded Text Generation (ITG)
目标:给定图像,生成描述文本。
损失函数:
$$\mathcal{L}_{ITG} = -\sum_{t=1}^T \log p(w_t | w_{其中:
- w_t:第t个文本token
- w_{<t}:之前的所有token
- I:图像(通过Q-Former编码)
关键洞察:
- ITG学习生成对齐:确保Q-Former的输出能够被语言模型用于生成文本
- 使用因果自注意力掩码(Causal Self-Attention Mask):文本token只能看到之前的token和查询向量
与ITC/ITM的关系:
- ITC确保Q-Former输出在语义空间中对齐
- ITM确保Q-Former输出在细粒度上与文本匹配
- ITG确保Q-Former输出在生成任务上有效
三者共同训练,使Q-Former学习到多层次的视觉-语言对齐。
五、代码手撕环节:PyTorch实现简化的Cross-Attention
以下是一个完整的、工业界规范的Cross-Attention实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossAttention(nn.Module):
"""
简化的Cross-Attention层实现
Args:
embed_dim: 嵌入维度
num_heads: 注意力头数
dropout: Dropout概率
"""
def __init__(self, embed_dim: int, num_heads: int = 8, dropout: float = 0.1):
super().__init__()
assert embed_dim % num_heads == 0, "embed_dim must be divisible by num_heads"
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.scale = self.head_dim ** -0.5 # 1/sqrt(d_k)
# 查询、键、值的线性投影
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
# 输出投影
self.out_proj = nn.Linear(embed_dim, embed_dim)
self.dropout = nn.Dropout(dropout)
# 初始化权重
self._reset_parameters()
def _reset_parameters(self):
"""Xavier初始化"""
nn.init.xavier_uniform_(self.q_proj.weight)
nn.init.xavier_uniform_(self.k_proj.weight)
nn.init.xavier_uniform_(self.v_proj.weight)
nn.init.xavier_uniform_(self.out_proj.weight)
def forward(
self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
key_padding_mask: torch.Tensor = None,
need_weights: bool = False
):
"""
Args:
query: [batch_size, tgt_len, embed_dim] 查询(通常来自文本或可学习查询)
key: [batch_size, src_len, embed_dim] 键(通常来自视觉特征)
value: [batch_size, src_len, embed_dim] 值(通常来自视觉特征)
key_padding_mask: [batch_size, src_len] 键的填充掩码
need_weights: 是否返回注意力权重
Returns:
output: [batch_size, tgt_len, embed_dim]
attn_weights: [batch_size, num_heads, tgt_len, src_len] (optional)
"""
batch_size, tgt_len, _ = query.size()
src_len = key.size(1)
# 线性投影
Q = self.q_proj(query) # [batch_size, tgt_len, embed_dim]
K = self.k_proj(key) # [batch_size, src_len, embed_dim]
V = self.v_proj(value) # [batch_size, src_len, embed_dim]
# 多头拆分
Q = Q.view(batch_size, tgt_len, self.num_heads, self.head_dim).transpose(1, 2)
K = K.view(batch_size, src_len, self.num_heads, self.head_dim).transpose(1, 2)
V = V.view(batch_size, src_len, self.num_heads, self.head_dim).transpose(1, 2)
# Q, K, V: [batch_size, num_heads, seq_len, head_dim]
# 计算注意力分数: Q @ K^T / sqrt(d_k)
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) * self.scale
# attn_scores: [batch_size, num_heads, tgt_len, src_len]
# 处理填充掩码(如果有)
if key_padding_mask is not None:
attn_scores = attn_scores.masked_fill(
key_padding_mask.unsqueeze(1).unsqueeze(2),
float('-inf')
)
# Softmax得到注意力权重
attn_weights = F.softmax(attn_scores, dim=-1)
attn_weights = self.dropout(attn_weights)
# 加权求和: attn_weights @ V
output = torch.matmul(attn_weights, V)
# output: [batch_size, num_heads, tgt_len, head_dim]
# 多头拼接
output = output.transpose(1, 2).contiguous()
output = output.view(batch_size, tgt_len, self.embed_dim)
# output: [batch_size, tgt_len, embed_dim]
# 输出投影
output = self.out_proj(output)
if need_weights:
return output, attn_weights
return output
class SimplifiedQFormer(nn.Module):
"""
简化的Q-Former实现
用于演示核心原理
"""
def __init__(self, embed_dim: int = 768, num_heads: int = 8, num_queries: int = 32):
super().__init__()
self.num_queries = num_queries
# 可学习查询向量
self.query_embed = nn.Parameter(torch.randn(1, num_queries, embed_dim))
# 交叉注意力层
self.cross_attn = CrossAttention(embed_dim, num_heads)
# 前馈网络
self.ffn = nn.Sequential(
nn.Linear(embed_dim, embed_dim * 4),
nn.GELU(),
nn.Linear(embed_dim * 4, embed_dim),
nn.Dropout(0.1)
)
# 层归一化
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
def forward(
self,
visual_features: torch.Tensor,
text_features: torch.Tensor = None
):
"""
Args:
visual_features: [batch_size, num_patches, embed_dim] 视觉特征
text_features: [batch_size, seq_len, embed_dim] 文本特征(可选)
Returns:
visual_queries: [batch_size, num_queries, embed_dim]
"""
batch_size = visual_features.size(0)
# 扩展查询向量到batch
queries = self.query_embed.expand(batch_size, -1, -1)
# 交叉注意力:查询向量(Q)从视觉特征(K, V)中提取信息
attn_out = self.cross_attn(queries, visual_features, visual_features)
queries = self.norm1(queries + attn_out)
# 前馈网络
ffn_out = self.ffn(queries)
queries = self.norm2(queries + ffn_out)
return queries
# 使用示例
if __name__ == "__main__":
# 模拟视觉编码器输出(冻结的CLIP/ViT)
visual_features = torch.randn(2, 197, 768) # [batch_size, num_patches, embed_dim]
# 初始化Q-Former
q_former = SimplifiedQFormer(embed_dim=768, num_heads=8, num_queries=32)
# 前向传播
visual_queries = q_former(visual_features)
print(f"输入视觉特征shape: {visual_features.shape}")
print(f"输出查询特征shape: {visual_queries.shape}")
print(f"可学习查询参数shape: {q_former.query_embed.shape}")
代码关键点解析:
- 多头注意力(Multi-Head Attention):
- 将嵌入维度拆分为多个头,每个头关注不同的语义子空间
- 拆分后维度:head_dim = embed_dim / num_heads
- 通过转置实现多头并行计算
- 缩放点积(Scaled Dot-Product):
self.scale = self.head_dim ** -0.5:计算√d_k的倒数- 在点积后立即缩放,避免梯度消失
- 掩码处理(Masking):
key_padding_mask:处理变长序列的填充token- 将填充位置的注意力分数设为-inf,使softmax后权重为0
- 残差连接(Residual Connection):
queries = self.norm1(queries + attn_out)- 标准的Transformer结构,稳定训练
- 可学习查询向量:
self.query_embed = nn.Parameter(torch.randn(...))- 这些查询向量通过反向传播学习,没有任何预设模式
⚠️ 面试官追问:为什么Q-Former需要LayerNorm?
回答:LayerNorm解决了深度网络中的内部协变量偏移(Internal Covariate Shift)问题。在Q-Former中,由于多头注意力和FFN的交替使用,激活值的分布会不断变化,LayerNorm稳定了梯度的流动,使训练更稳定。
进阶追问与展望:前沿研究方向
问题1:Q-Former的查询向量数量如何选择?
当前设置:BLIP-2使用32个查询向量(L=32)
选择依据:
- 信息容量:32个查询向量可以编码足够丰富的视觉信息
- 计算效率:相比直接使用197个视觉token(ViT-L/14),减少了约84%的计算量
- 实验验证:作者通过消融实验发现,L=32在效率和性能之间达到最佳平衡
面试加分项: 查询向量数量本质上是一个超参数,需要根据任务调整:
- 图像分类任务:可以减少到16个(全局语义足够)
- 视觉问答(VQA):需要增加到64个(细粒度细节)
- 视频理解:可能需要更多(时序信息)
⚠️ 避坑指南:不要说"32是一个魔法数字"。要强调这是通过 消融实验和 任务需求确定的。
问题2:Q-Former与Perceiver Resampler有什么区别?
共同点:
- 都使用可学习查询向量
- 都通过Cross-Attention提取特征
核心区别:
| 维度 | Q-Former (BLIP-2) | Perceiver Resampler (Flamingo) |
|---|---|---|
| 查询向量来源 | 可学习查询(Learnable Queries) | Latent Queries(潜在查询) |
| 训练目标 | 三任务联合训练(ITC+ITM+ITG) | 仅生成任务 |
| 与文本交互 | 是(Text Transformer) | 否(仅视觉编码) |
| 掩码策略 | 复杂(根据任务动态调整) | 固定(无掩码) |
| 计算复杂度 | 较高(需要处理文本) | 较低(纯视觉) |
数学差异:
Q-Former的损失函数:
Perceiver Resampler的损失函数:
面试加分项: Q-Former通过多任务学习,使查询向量同时学习全局对齐(ITC)、细粒度匹配(ITM)和生成能力(ITG),因此比Perceiver Resampler更通用。
问题3:Q-Former的局限性是什么?
局限性分析:
- 计算复杂度:
- Q-Former包含多个Transformer层(通常12层)
- 相比线性投影,推理速度慢约3-5倍
- 训练成本:
- 需要大规模图文对预训练(约1.29亿对)
- 多任务训练需要平衡三个损失函数的权重
- 迁移性:
- Q-Former针对特定视觉编码器(如ViT-L/14)训练
- 更换视觉编码器需要重新训练Q-Former
- 信息瓶颈:
- 32个查询向量可能无法编码所有视觉细节
- 对于需要高分辨率细节的任务(如医学影像),可能不够
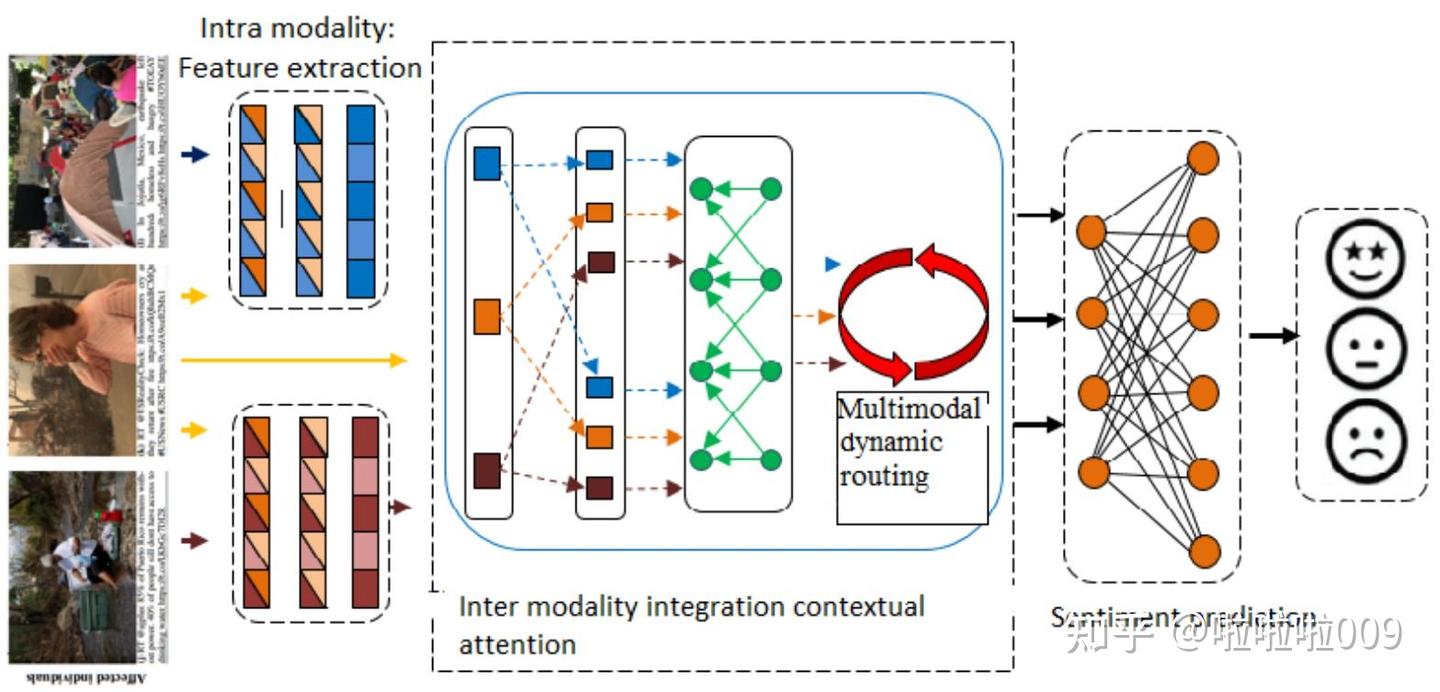
图5:多模态情感分析中Cross-Attention的应用,展示了跨模态整合和动态路由的机制
改进方向(SOTA):
- MoE(Mixture of Experts):使用稀疏专家网络,在保持效率的同时增加容量
- 动态查询:根据输入图像自适应调整查询向量数量
- 分层Q-Former:不同层使用不同数量的查询向量(细粒度到粗粒度)
问题4:如何扩展到视频和音频模态?
视频扩展:
- 时间维度:将视觉特征扩展为 [batch, frames, patches, embed_dim]
- 时空注意力:在Cross-Attention中同时建模时间和空间
- 查询设计:可学习查询向量包含时间信息(如"第1帧的猫"、"第2帧的猫")
音频扩展:
- 音频编码器:使用预训练的音频编码器(如AudioMAE)
- 多模态Q-Former:扩展为视觉-音频-语言三模态对齐
- 注意力模式:视觉查询关注视觉+音频,音频查询关注音频+视觉
数学表达(三模态Cross-Attention):
其中⊕表示特征拼接或加权融合。
面试回答模板:3分钟黄金回答
开场(10秒): "Q-Former是BLIP-2的核心创新,它通过可学习查询向量和Cross-Attention机制,在冻结的视觉编码器和语言模型之间构建了一个信息瓶颈,实现了高效的跨模态对齐。"
核心原理(60秒): "具体来说,Q-Former包含32个可学习查询向量,这些向量通过Self-Attention相互交互,并通过Cross-Attention从视觉特征中提取信息。Cross-Attention的数学公式是softmax(QK^T/√d_k)V,其中Q是查询向量,K和V是视觉特征。这个过程可以理解为查询向量在视觉特征空间中的动态投影,自适应地关注与语言任务相关的视觉区域。"
为什么冻结编码器(60秒): "冻结视觉编码器和语言模型有三个原因:一是优化效率,只需训练约1亿参数而非数千亿;二是避免灾难性遗忘,保留预训练模型的强大能力;三是数学上,Q-Former专注于模态对齐这一单一目标,梯度方向更明确。"
三种训练目标(40秒): "Q-Former采用三任务训练:ITC实现全局语义对齐,ITM实现细粒度匹配,ITG确保生成能力。通过多任务学习,查询向量同时学习到不同层次的对齐。"
代码实现(30秒): "Cross-Attention的核心实现包括多头拆分、缩放点积、掩码处理和残差连接。关键点在于正确处理维度变换和掩码。"
结尾(20秒): "相比LLaVA的简单投影,Q-Former通过自适应查询和复杂训练,实现了更好的信息保留和对齐精度,但计算成本更高。这是效率和性能的经典权衡。"
总结:从数学到工程的完整视角
Q-Former的设计体现了多模态大模型中的几个核心原则:
- 模态解耦:冻结单模态编码器,专注于跨模态对齐
- 信息瓶颈:通过查询向量自适应压缩视觉信息
- 多任务学习:ITC+ITM+ITG确保多层次对齐
- 数学优雅性:Cross-Attention的简洁公式蕴含强大的表达能力
从面试角度看,回答Q-Former问题需要:
- 数学基础:准确表述Cross-Attention公式
- 几何直觉:流形、投影、压缩等概念
- 工程思维:计算复杂度、训练成本、实际部署
- 前沿视野:局限性和改进方向
最后一句话:
"Q-Former不仅是一个技术模块,更是多模态学习中的 设计哲学:在复杂系统中,通过精心设计的中间层,实现不同模态之间的优雅对齐。"
参考文献:
- BLIP-2论文: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- Flamingo论文: Flamingo: a Visual Language Model for Few-Shot Learning
- LLaVA论文: Visual Instruction Tuning
- Perceiver IO论文: General Perception with Iterative Attention
延伸阅读:
- Qwen-VL: 通用视觉语言模型
- InternVL: 多模态大规模预训练
- SigLIP: Sigmoid Loss for Language-Image Pre-training

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)