Rust深度学习框架Burn 0.20是否能超过python?
Burn 0.20 不仅仅是一个 Tensor 库的升级,它是 Rust 生态试图在 AI 算力领域建立“统一战线”的尝试。通过 CubeCL 屏蔽硬件差异,Burn 正在让“高性能 AI”变得不再是 Nvidia 的专利。如果你厌倦了配置复杂的 CUDA 环境,或者在 LibTorch 的内存 Bug 里苦苦挣扎,不妨试试 Burn。用 Rust 烧出来的模型,可能真的更香。
提到深度学习,大家脑子里跳出的第一个词肯定是大红大紫的 PyTorch 或者 TensorFlow。虽然 Python 在科研圈呼风唤雨,但到了真正追求极致性能、追求“一次编译,到处运行”的生产环境,Python 的解释器开销和复杂的依赖管理往往让人抓狂。
最近,Rust 圈的深度学习黑马 Burn 发布了 0.20 版本。这不仅仅是一个小版本的迭代,它带来的 CubeK 和 CubeCL 组合拳,直接向我们展示了 Rust 在 AI 基础设施领域的“降维打击”能力。
今天咱们就来拆解一下,为什么 Burn 0.20 值得每一个对性能有追求的开发者关注。
一、 核心痛点:AI 硬件的“碎片化”苦难
在 AI 领域,开发者最痛苦的事莫过于:为了给 Nvidia 卡写优化,得学 CUDA;为了兼容 AMD,得搞 ROCm;为了给 Mac 用户加速,得碰 Metal。代码库碎了一地,维护成本高到飞起。
Burn 0.20 的解法极其硬核:引入 CubeK(基于 CubeCL)。
CubeCL 是什么?它是专门为 Rust 打造的多平台计算语言扩展。它的野心很大:用 Rust 编写 GPU 内核,实现“零成本抽象”,然后自动适配 NVIDIA CUDA、AMD ROCm HIP、Apple Metal、WebGPU 甚至 Vulkan。
这意味着,你写的一份 Rust 内核代码,既能在最顶级的 Nvidia Blackwell GPU 上起飞,也能在普通的集显甚至 CPU(支持 SIMD)上稳健运行。
二、 性能实测:真的比 LibTorch 快?
根据 Phoronix 披露的官方基准测试数据,Burn 0.20 的表现非常惊人。在某些特定场景下,它的执行时间明显低于 LibTorch(PyTorch 的 C++ 后端)和 Rust 原生的 ndarray。
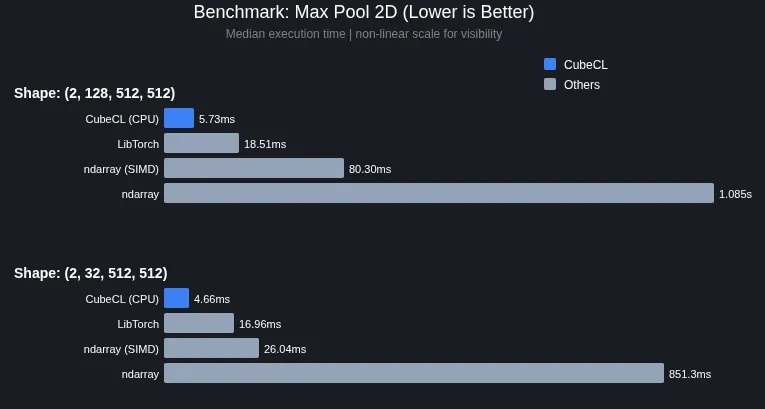
为什么 Rust 能更快?
-
内存安全无 GC:不像 Python 有全局解释器锁(GIL),Rust 的并发是真正的物理并发。
-
CubeCL 的内核编译器优化:CubeCL 在编译时会将 Rust 代码直接映射到目标硬件的底层指令集。由于 Rust 本身就是强类型和内存布局明确的,这给了编译器巨大的优化空间。
-
零成本抽象:你可以用高级语法写代码,但编译器生成的机器码和手写原生 C++/CUDA 几乎没有区别。
三、 破圈的关键:ONNX 导入系统的“大换血”
一个深度学习框架如果不能兼容现有的模型生态,那它就是一座孤岛。Burn 0.20 这次彻底重构了 ONNX 导入系统。
这意味着什么? 你可以直接在 PyTorch 里训练好模型,导出为 ONNX 格式,然后无缝“空投”到 Burn 里面。在高性能推理场景(比如边缘计算、实时视觉处理)下,这种“Python 训练,Rust 推理”的模式,可能会成为未来的主流架构。
四、 深度思考:AI 开发者的“阶级分化”?
以前,AI 开发者只需要懂调参、写 Python 脚本。但随着大模型时代的到来,AI 基础设施工程师的需求正在爆发。
Burn 的进化路径告诉我们:AI 的下半场是工程化的比拼。
-
对于算法工程:你可能不需要从头撸一个 Burn 框架,但你需要理解为什么 CubeCL 能让 Vulkan 跑得像 CUDA 一样快。
-
对于嵌入式/边缘端:Rust 的低内存占用和强安全性,解决了 C++ 容易内存泄漏、Python 环境太臃肿的死穴。
五、 总结
Burn 0.20 不仅仅是一个 Tensor 库的升级,它是 Rust 生态试图在 AI 算力领域建立“统一战线”的尝试。通过 CubeCL 屏蔽硬件差异,Burn 正在让“高性能 AI”变得不再是 Nvidia 的专利。
如果你厌倦了配置复杂的 CUDA 环境,或者在 LibTorch 的内存 Bug 里苦苦挣扎,不妨试试 Burn。用 Rust 烧出来的模型,可能真的更香。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)