【Gemini】获取Gemini API Key的多种方式全攻略:从入门到精通,再到详解教程!(gemini-2.0-flash)
这是 Google 最具代表性的技术成果,基于 Transformer 架构,通过大规模多模态数据(文本、代码、音频、图像、视频)预训练,并采用原生多模态统一建模技术——从底层打破模态壁垒,实现跨模态语义的深度对齐,大幅提升了模型的理解与交互能力,同时通过严格的安全对齐训练,降低有害信息生成概率,保障应用安全。2023 年 12 月发布,是 Google 首款原生多模态大模型,首次展现了原生多模态
文章目录
Gemini 的核心技术与产品
Gemini 是 Google 旗下的核心大语言模型(Large Language Models,简称 LLMs)品牌,围绕这一技术推出了多款具有广泛影响力的产品与服务,涵盖文本生成、对话交互、多模态处理、企业级定制等多个领域,其核心优势在于原生多模态融合、超强推理能力、全设备适配、超长上下文窗口。
1. Gemini 大语言模型系列
这是 Google 最具代表性的技术成果,基于 Transformer 架构,通过大规模多模态数据(文本、代码、音频、图像、视频)预训练,并采用原生多模态统一建模技术——从底层打破模态壁垒,实现跨模态语义的深度对齐,大幅提升了模型的理解与交互能力,同时通过严格的安全对齐训练,降低有害信息生成概率,保障应用安全。

-
Gemini 1.0 基础系列
2023 年 12 月发布,是 Google 首款原生多模态大模型,首次展现了原生多模态架构的技术优势,在文本理解、代码生成、多模态交互等场景中表现出色,奠定了 Gemini 系列的技术基础。 -
Gemini 1.0 Pro
面向大众与开发者的主力模型,支持最长 16 万 tokens 的上下文窗口(约相当于 12 万字文本),可直接处理长篇文档、代码库等大体积内容;同时开放了网页版对话界面与 API 服务,支持复杂的推理任务(如数据分析、报告撰写、语言翻译),并具备高效的响应速度,是 Google 面向消费级与中小开发者的核心解决方案。 -
Gemini 1.0 Ultra
2023 年 12 月发布的旗舰级模型,是当时全球能力最强的 AI 模型之一,在 MMLU(大规模多任务语言理解)基准测试中得分达 90.0%,首次超越人类专家水平。该模型支持更长的上下文窗口,具备顶尖的多模态处理能力,可精准理解图像、视频中的复杂信息,擅长量子物理公式推导、大型代码库重构、跨国法律合同审核等超复杂任务,主要面向企业级高端需求与科研场景。 -
Gemini 1.5 系列
2024 年 2 月发布的重大升级版本,核心亮点是上下文窗口扩展至 100 万 tokens(约 75 万字文本),可一次性处理整本书、完整的会议录音转写文本、大型代码库等超大规模内容;同时优化了多模态处理效率,支持更长时长的视频理解,降低了“幻觉”概率,提升了事实准确性,在企业级文档处理、科研数据分析等场景中优势更为突出。 -
Gemini Nano/Ace
面向移动设备的轻量化模型,专为安卓终端优化,可在手机本地离线运行,实现低延迟响应。其中 Gemini Nano 主要集成于 Google Pixel 系列手机的 AI 功能中,支持语音助手增强、本地文档总结、实时翻译等轻量场景;Gemini Ace 则进一步提升了移动端运行效率,拓展了更多本地交互功能,推动 AI 能力向终端设备深度渗透。
通过“能用AI”获取API Key(国内)
针对国内用户,由于部分海外服务访问限制,可以通过国内平台“能用AI”获取API Key。
1. 访问能用AI工具
在浏览器中打开能用AI进入主页
https://ai.nengyongai.cn/register?aff=PEeJ
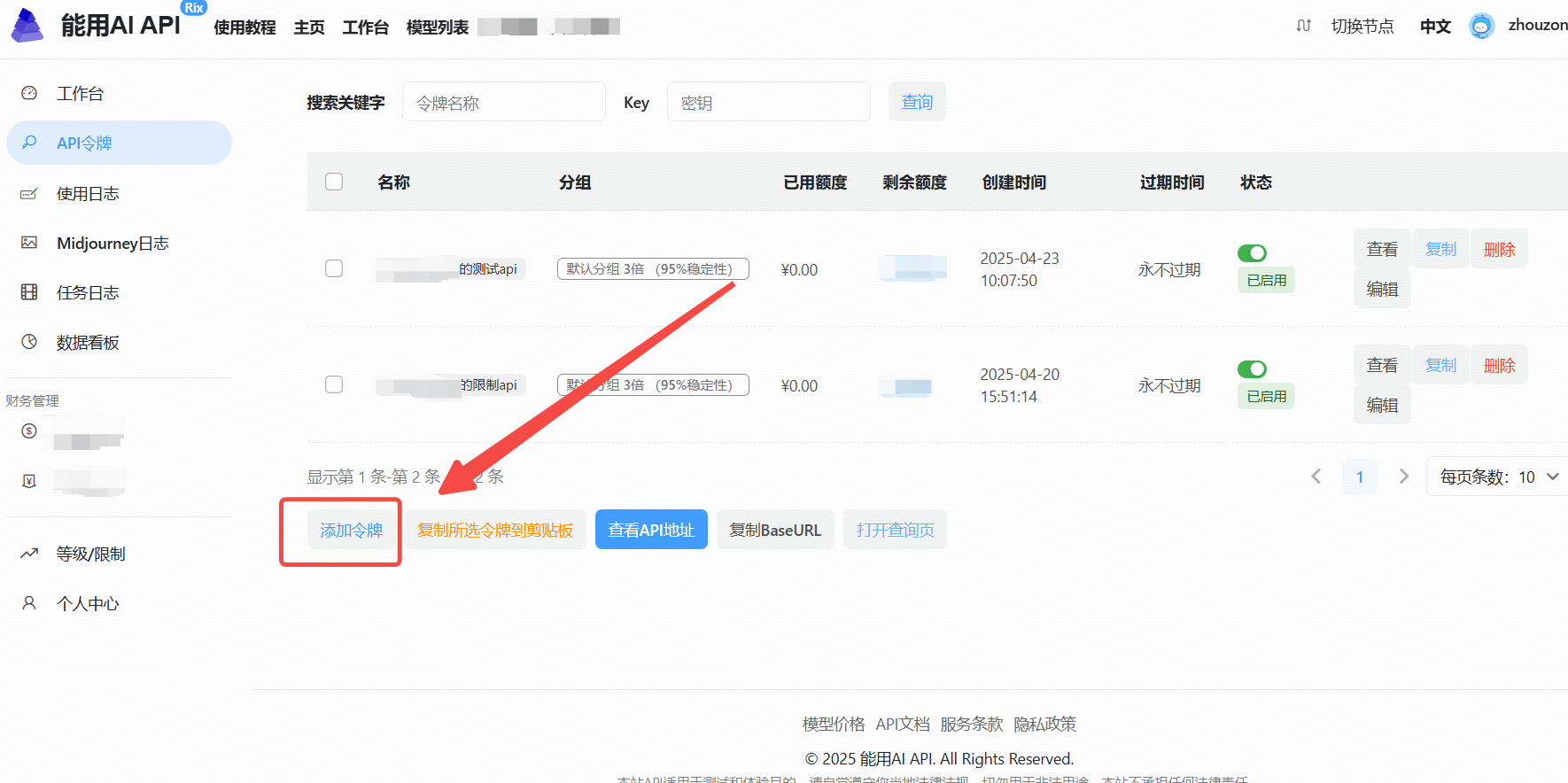
登录后,导航至API管理页面。
2、生成API Key
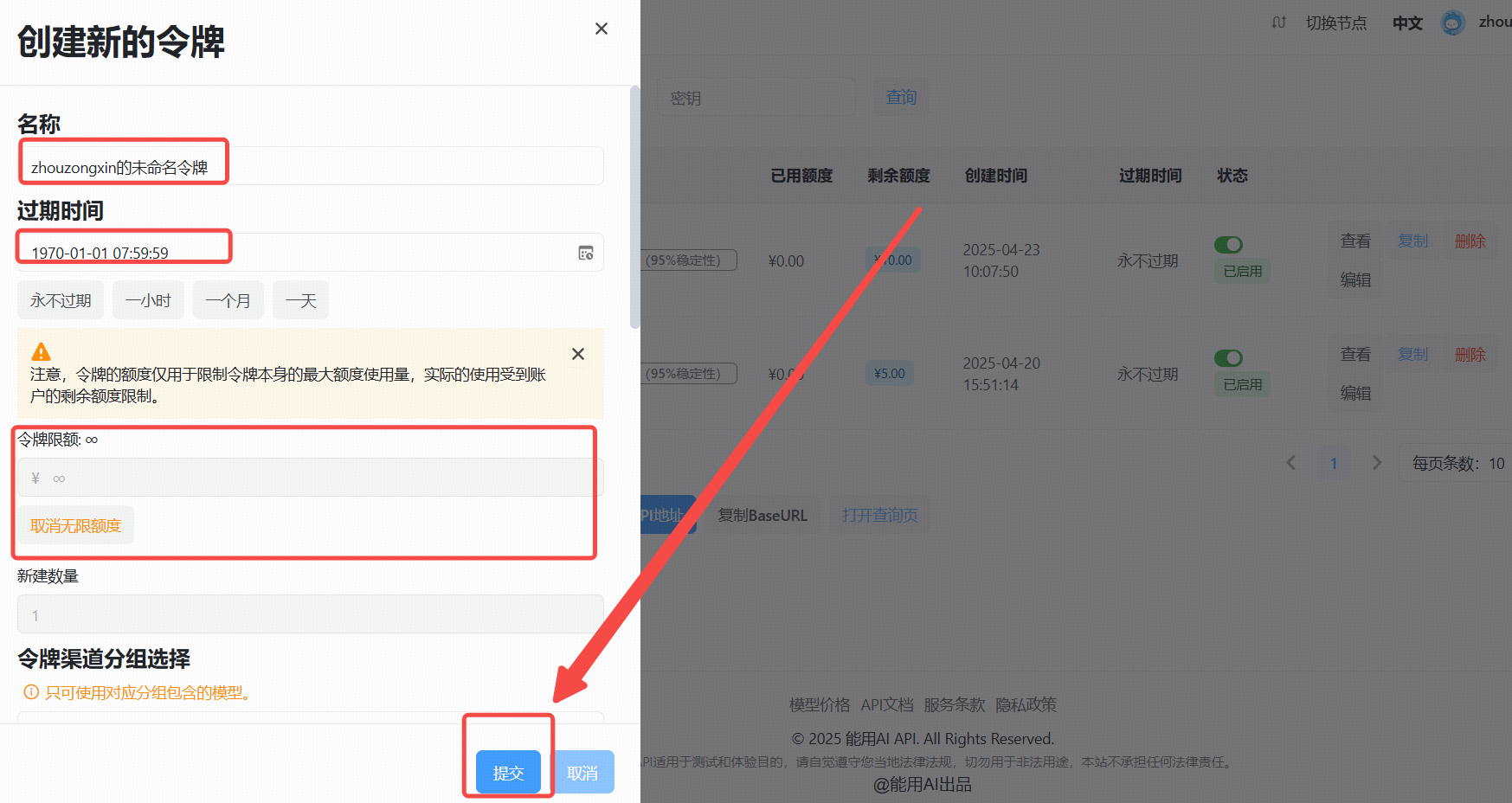
- 点击“添加令牌”按钮。
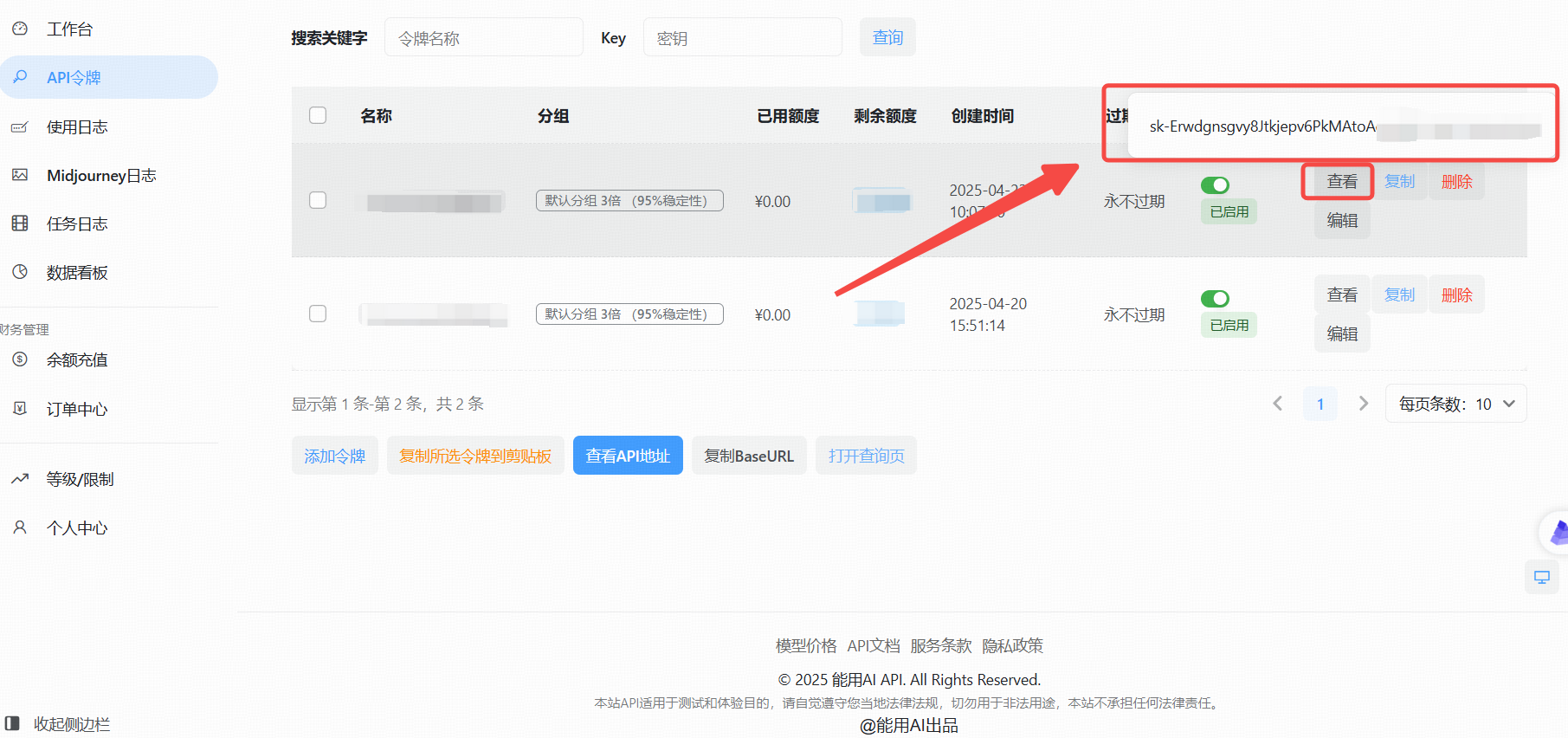
- 创建成功后,点击“查看KEY”按钮,获取你的API Key。
3、使用大模型 API的实战教程
拥有了API Key后,接下来就是如何在你的项目中调用大模型 API了。以下以Python为例,详细展示如何进行调用。
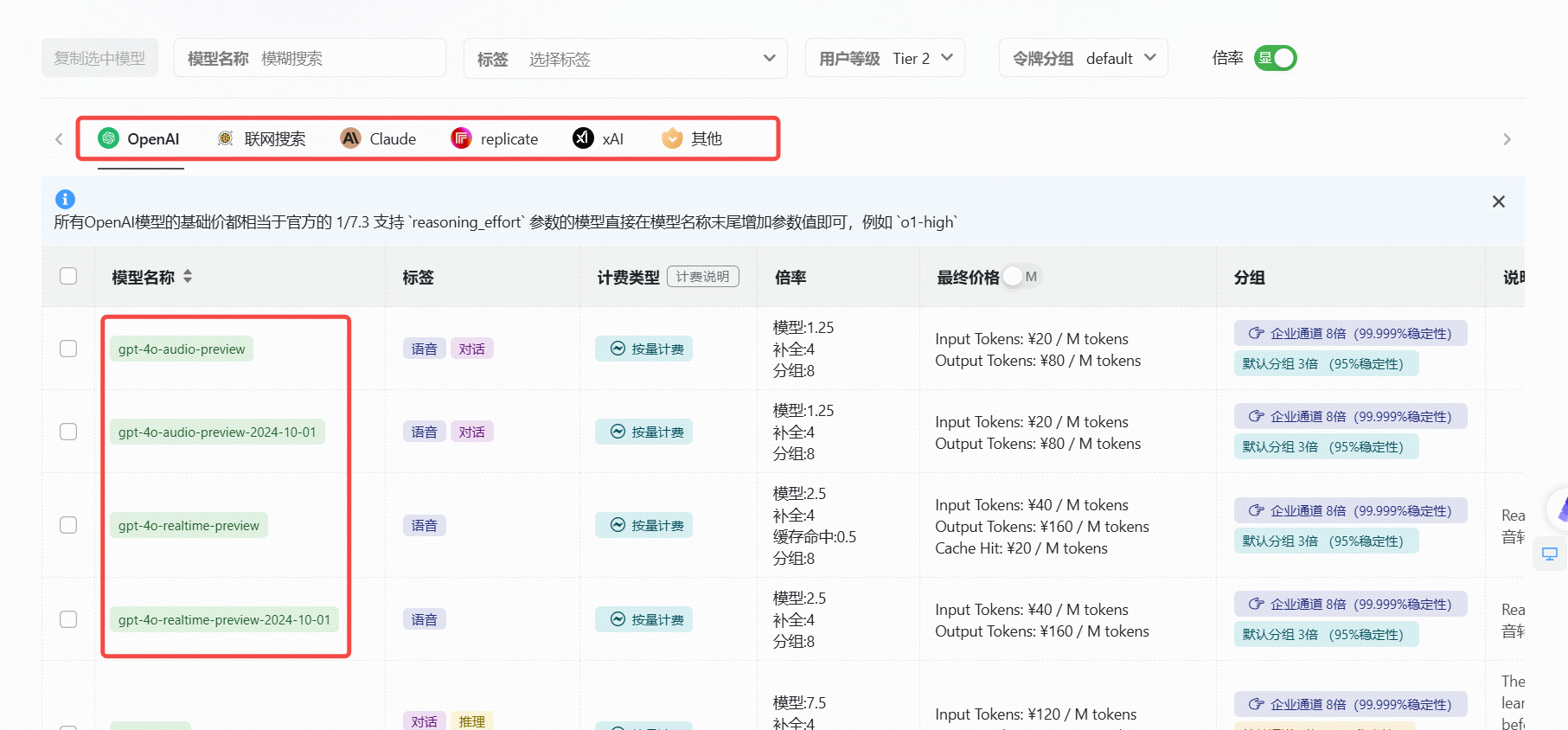
(1).可以调用的模型
gpt-3.5-turbo
gpt-3.5-turbo-1106
gpt-3.5-turbo-0125
gpt-3.5-16K
gpt-4
gpt-4-1106-preview
gpt-4-0125-preview
gpt-4-1106-vision-preview
gpt-4-turbo-2024-04-09
gpt-4o-2024-05-13
gpt-4-32K
claude-2
claude-3-opus-20240229
claude-3-sonnet-20240229
等等100多种模型
(2).Python示例代码(基础)
基本使用:直接调用,没有设置系统提示词的代码
from openai import OpenAI
client = OpenAI(
api_key="这里是能用AI的api_key",
base_url="https://ai.nengyongai.cn/v1"
)
response = client.chat.completions.create(
messages=[
# 把用户提示词传进来content
{'role': 'user', 'content': "鲁迅为什么打周树人?"},
],
model='gpt-4', # 上面写了可以调用的模型
stream=True # 一定要设置True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="", flush=True)
在这里插入代码片
(3).Python示例代码(高阶)
进阶代码:根据用户反馈的问题,用Claude进行问题分类
from openai import OpenAI
# 创建OpenAI客户端
client = OpenAI(
api_key="your_api_key", # 你自己创建创建的Key
base_url="https://ai.nengyongai.cn/v1"
)
def api(content):
print()
# 这里是系统提示词
sysContent = f"请对下面的内容进行分类,并且描述出对应分类的理由。你只需要根据用户的内容输出下面几种类型:bug类型,用户体验问题,用户吐槽." \
f"输出格式:[类型]-[问题:{content}]-[分析的理由]"
response = client.chat.completions.create(
messages=[
# 把系统提示词传进来sysContent
{'role': 'system', 'content': sysContent},
# 把用户提示词传进来content
{'role': 'user', 'content': content},
],
# 这是模型
model='gpt-4', # 上面写了可以调用的模型
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="", flush=True)
if __name__ == '__main__':
content = "这个页面不太好看"
api(content)

通过这段代码,你可以轻松地与AI模型进行交互,获取所需的文本内容。✨
更多文章

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)