AI收窄了科学探索广度!清华新研究Nature+Science双杀
AI科技圈最近一周又发生了啥新鲜事?

AI科技圈最近一周又发生了啥新鲜事?
谷歌最强 AI 开放翻译模型 TranslateGemma,支持 55 种语言并可在手机端运行
谷歌基于 Gemma 3 架构发布了 TranslateGemma 开放翻译模型系列,提供 4B、12B 和 27B 三种参数规模,支持 55 种核心语言的高质量翻译,并具备多模态图像内文字翻译能力;其中 12B 版本在 WMT24++ 基准测试中表现优于参数量两倍的 Gemma 3 27B 基线模型,而 4B 小型版本性能则与 12B 基线相当,适合移动端和边缘设备部署;该系列采用“两阶段微调”策略,先通过 Gemini 生成的合成数据与人工翻译数据进行监督微调,再结合 MetricX-QE 与 AutoMQM 等奖励模型进行强化学习优化;所有模型已在 Kaggle、Hugging Face 和 Vertex AI 平台开放下载,分别适配手机、消费级笔记本及单张 H100 GPU 或云端 TPU 等不同部署场景
https://arxiv.org/pdf/2601.09012
国产芯片全程训练的多模态模型GLM-Image登顶Hugging Face Trending
由智谱AI推出的多模态生成模型GLM-Image,首次实现完全基于国产昇腾Atlas 800T A2芯片和昇思MindSpore框架进行端到端训练与推理,在开源不到24小时内登顶Hugging Face Trending榜单第一;该模型采用创新的“自回归+扩散解码器”混合架构,在CVTG-2K(复杂视觉文本生成)和LongText-Bench(长文本渲染)两个开源基准中取得第一,尤其在汉字生成任务上表现突出,适用于海报、PPT、科普图等知识密集型场景,相关代码与模型已在GitHub和Hugging Face平台开源
https://github.com/zai-org/GLM-Image
美团开源 LongCat-Flash-Thinking-2601,工具调用与重思考能力达开源 SOTA
美团 LongCat 团队开源发布 LongCat-Flash-Thinking-2601 模型,在多项核心评测中达到开源 SOTA 水平:τ²-Bench 工具调用得分 88.2,VitaBench 得分 29.3,BrowseComp 搜索任务得分 73.1,RW Search 得分 79.5;数学推理方面,在 AIME-25 获满分 100.0,IMO-AnswerBench 得 86.8;编程能力在 LCB 评测中得 82.8 分,OIBench EN 得 47.7 分。该模型支持“重思考模式”,通过并行生成多条推理路径并进行总结归纳,形成闭环迭代推理,并结合多环境强化学习与噪声注入训练,显著提升在复杂、随机及分布外任务中的泛化与鲁棒性,其权重、推理代码及在线体验已开放于 GitHub、Hugging Face、ModelScope 及官网 longcat.ai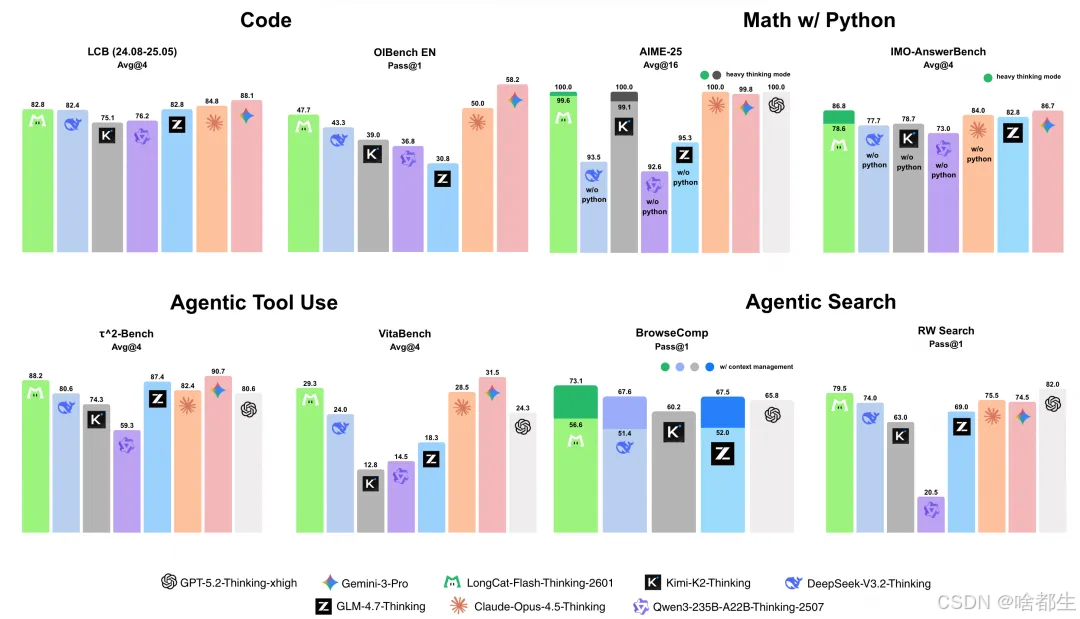
https://github.com/meituan-longcat/LongCat-Flash-Thinking-2601
清华研究揭示AI加速个体科研却收窄科学探索广度,提出OmniScientist智能体系统
清华大学李勇团队基于对1980–2025年间2.5亿篇科学文献的分析,构建涵盖4130万篇论文与2857万研究者的“AI赋能科研全景地图”,发现使用AI的科学家个体发表论文数量提升3.02倍、引用量增加4.84倍,并平均提前1.37年成为项目负责人;但与此同时,集体层面的科研知识广度下降4.63%,跨领域合作减少22%,且AI相关论文呈现高度集中的“星型引用”结构。研究指出这一“个体加速、群体趋同”现象源于当前AI for Science模型缺乏通用性,导致科研活动集中于少数适合AI处理的“热门山峰”。为应对该问题,团队推出全流程、跨学科科研智能体系统OmniScientist,旨在通过大模型的通用推理能力支持假说生成、实验设计与理论构建等全链条科研任务
https://arxiv.org/abs/2412.07727
千问App上线400多项AI办事功能
千问App正式推出400多项AI办事功能,基于Qwen大模型与阿里生态资源,深度接入淘宝、支付宝、飞猪、高德等平台,支持AI点外卖(整合淘宝闪购与支付宝AI付)、AI购物、AI打电话订餐厅(结合高德扫街榜)、智能规划旅行并一键预订机票酒店门票,以及覆盖签证、户口、公积金等50项民生政务事项;同时上线“任务助理”功能,可处理应用开发、办公、调研及生活类多步骤复杂任务,并新增“找卷子、讲难题、练错题”等学习辅助能力,依托AI Coding、全模态理解与超长上下文处理三大技术支撑,实现从对话到办事的升级
https://mp.weixin.qq.com/s/gqTkVJ4UsdFqJoZsYfGbyQ
MiniMax推出OctoCodingBench评测集,聚焦Coding Agent过程规范遵循能力
MiniMax发布开源评测集OctoCodingBench,旨在评估Coding Agent在真实工程场景中对多层级过程规范的遵循能力,区别于传统以结果为导向的评估方式。该评测从Check-level准确率(CSR)和Instance-level成功率(ISR)两个维度衡量模型表现,测试涵盖系统提示、用户多轮指令、仓库规范文件(如CLAUDE.md/AGENTS.md)、Skills调用流程及用户记忆偏好等约束。评估结果显示,当前主流模型虽CSR可达80%以上,但ISR普遍仅为10%-30%,其中Claude 4.5 Opus以36.2% ISR领先,而开源模型MiniMax M2.1(26.1%)与DeepSeek V3.2(26%)已超越部分闭源模型如Claude 4.5 Sonnet(22.8%)和Gemini 3 Pro(22.9%)。研究指出,未来需引入过程监督、层级化指令遵循训练及可验证Checklist机制,推动Coding Agent从“能跑代码”向“合规协作”演进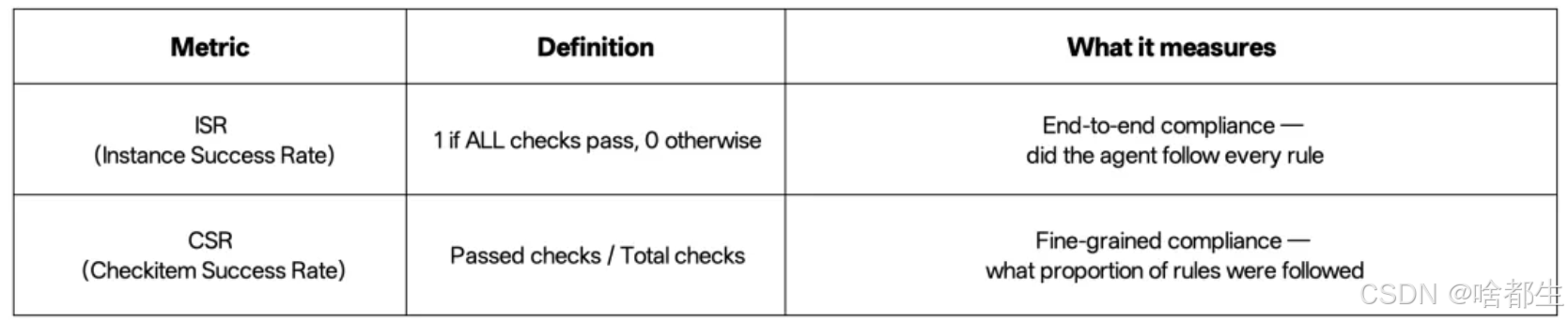
huggingface.co/datasets/MiniMaxAI/OctoCodingBench
百川开源全球最强医疗大模型M3
百川智能开源的新一代医疗大模型Baichuan-M3在权威医疗AI评测HealthBench中以65.1分的综合成绩位列全球第一,在其高难度子集HealthBench Hard上取得44.4分,首次全面超越GPT-5.2;该模型幻觉率为3.5%,为当前全球最低,并首次具备原生“端到端”严肃问诊能力,能主动追问、逐层逼近关键病史与风险信号。M3基于强化学习升级的全动态Verifier System训练而成,将医学事实一致性内化为核心能力,不依赖外部工具即可稳定输出可信回答;同时,百川提出“严肃问诊范式”与SCAN原则(安全分层、信息澄清、关联追问、规范化输出),构建SCAN-bench评测体系,并通过SPAR算法优化长对话训练,使M3在问诊各维度均显著高于真人医生平均水平,形成从精准问询到安全决策的完整闭环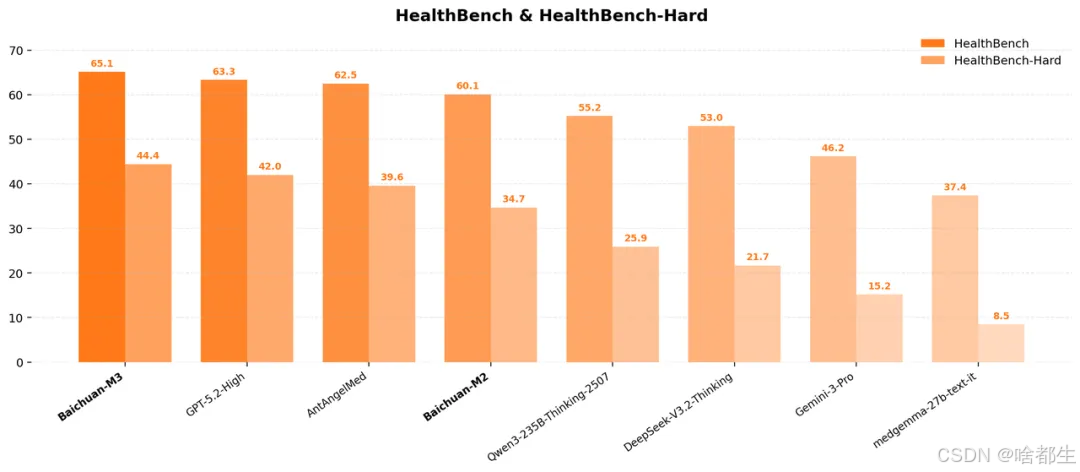
https://github.com/baichuan-inc/Baichuan-M3-235B
千寻Spirit v1.5登顶RoboChallenge,成首个成功率超50%的开源具身模型
千寻智能发布的具身智能基础模型Spirit v1.5在RoboChallenge真机评测中以总分66.09、整体任务成功率50.33%的成绩超越Physical Intelligence的Pi0.5,成为该榜单首个击败Pi0.5且成功率突破50%的开源模型;其在Table30任务集中多项任务表现领先,包括“寻找绿盒”(成功率90%)、“水果入篮”(80%,为Pi0.5的两倍)、“插花”“挂牙刷杯”“开瓶器入抽屉”“笔入笔盒”“浇花”等,并在高难度闭环触觉任务“贴胶带”中以20%成功率实现对Pi0.5(10%)的翻倍优势。该模型基于多样化、弱控制的真实世界数据采集范式进行预训练,在保持多任务通用性的同时显著提升泛化与微调效率,相关权重、推理代码及使用样例已同步开源。
https://github.com/Spirit-AI-Team/spirit-v1.5

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 39
39 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)