多模态大模型串讲--BLIP2、LLaVA、Qwen-VL,tokenizer是什么及其作用
本文系统梳理了多模态大模型(MLLM)的核心技术架构与发展趋势。首先详细解析了Tokenizer的工作原理,包括文本和图像的分词方法(如BPE、ViT、VQ-VAE),并比较了不同模态的统一tokenization实现。随后重点分析了BLIP、BLIP-2、LLaVA等代表性视觉语言模型的技术特点:BLIP通过多模态混合架构统一理解与生成任务;BLIP-2创新性地采用轻量级Q-Former桥接冻结
写在前面
在gpt系列等纯文本大模型的基础上,多模态大模型(MLLM,音频、图像/视频、文本、表格等模态)的发展热度和应用前景都高于单模态大模型。本文将串联分析目前成熟且热度高的基座多模态大模型(的架构)。在mllm之前,本文将介绍tokenizer,这也是大模型岗位的高频面试考点之一。
本文是我的学习笔记,若有不清晰或其他错误,欢迎讨论与指正!
目录
1.Tokenizer
1.1.Tokenizer(分词器)介绍
Tokenizer是大型语言模型处理文本的关键组件,它的主要功能是将原始文本转换为模型能够理解的数字序列(token IDs)。ID 编号与语义信息无关!!!
主要功能(其实主要相当于NLP文本预处理的流程):
- 文本分割:将文本拆分为更小的单元(token)
- 词汇表映射:每个token对应一个唯一的ID(包括标点符号、未知词、特殊token等)
- 规范化:对每个输入做规范化处理(如大小写统一,é→e ,Unicode规范化,空白字符处理等,部分tokenizer还会做词干化)
- 结构化:输出结构化信息
- input_ids: token的ID序列
- attention_mask: 哪些位置需要注意
- token_type_ids: token的类型(句子A/B)
- position_ids: 位置信息
- 特殊token标记
分词级别:
- 词级别:以单词为单位
- 子词级别:BPE、WordPiece等
- 字符级别:以字符为单位
| 策略 | 优点 | 缺点 | 使用模型 |
|---|---|---|---|
| BPE | 平衡词和字符 | 需要训练 | GPT系列 |
| WordPiece | 处理未知词好 | 更复杂 | BERT |
| SentencePiece | 无需预分词 | 训练慢 | T5, XLNet |
1.1.1.代码示例
使用Hugging Face Transformers库
from transformers import AutoTokenizer
# 加载预训练模型的分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
text = "Hello, how are you? I'm learning about tokenizers!"
# 1. 基础分词
tokens = tokenizer.tokenize(text)
print("Tokens:", tokens)
# 输出: ['hello', ',', 'how', 'are', 'you', '?', 'i', "'", 'm', 'learning', 'about', 'token', '##izer', '##s', '!']
# 2. 转换为ID
input_ids = tokenizer.encode(text)
print("Input IDs:", input_ids)
# 输出: [101, 7592, 1010, 2129, 2024, 2017, 1029, 1045, 1005, 1049, 4083, 2055, 19204, 17629, 17628, 999, 102]
# 3. 完整处理(包括attention mask等)
encoded = tokenizer(text, return_tensors="pt")
print("Encoded output:")
print(" Input IDs:", encoded["input_ids"])
print(" Attention Mask:", encoded["attention_mask"])
# 4. 解码回文本
decoded_text = tokenizer.decode(input_ids)
print("Decoded:", decoded_text)使用OpenAI的tiktoken(GPT系列使用)
# 运行你的代码
import tiktoken
# 加载不同模型的编码器
# GPT-4/3.5-turbo
enc = tiktoken.encoding_for_model("gpt-4")
text = "Tokenization is fascinating!"
# 编码
tokens = enc.encode(text)
print("Tokens IDs:", tokens)
# 输出: Tokens IDs: [100277, 374, 2948, 10185, 0]
print("Tokens:", [enc.decode_single_token_bytes(token) for token in tokens])
# 输出: Tokens: [b'Tokenization', b' is', b' fasc', b'inating', b'!']
# 解码
decoded = enc.decode(tokens)
print("Decoded:", decoded)
# 输出: Decoded: Tokenization is fascinating!
# 统计token数量
num_tokens = len(tokens)
print(f"Number of tokens: {num_tokens}")
# 输出: Number of tokens: 5结果:
"Tokenization" → 1个token (b'Tokenization')
" is" → 1个token (b' is') # 注意前面有空格
" fasc" → 1个token (b' fasc')
"inating" → 1个token (b'inating')
"!" → 1个token (b'!')
# 每个token对应的ID
Token: b'Tokenization' → ID: 100277
Token: b' is' → ID: 374
Token: b' fasc' → ID: 2948
Token: b'inating' → ID: 10185
Token: b'!' → ID: 0# 更多示例
test_texts = [
"Hello world!",
"I'm learning AI",
"ChatGPT is awesome",
"这是一个测试", # 中文
"🤗 🚀 🌟" # 表情符号
]
print("\n=== 不同文本的分词结果 ===")
for txt in test_texts:
token_ids = enc.encode(txt)
tokens = [enc.decode_single_token_bytes(tid) for tid in token_ids]
print(f"\n文本: '{txt}'")
print(f"Token数量: {len(token_ids)}")
print(f"Tokens: {tokens}")
print(f"IDs: {token_ids}")
------------------------------------------------------
# 输出结果
文本: 'Hello world!'
Token数量: 3
Tokens: [b'Hello', b' world', b'!']
IDs: [9906, 1917, 0]
文本: 'I'm learning AI'
Token数量: 5
Tokens: [b'I', b"'", b'm', b' learning', b' AI']
IDs: [40, 1688, 78, 4200, 1545]
文本: 'ChatGPT is awesome'
Token数量: 5
Tokens: [b'Chat', b'GPT', b' is', b' awesome', b'']
IDs: [36145, 1400, 374, 7686]
文本: '这是一个测试'
Token数量: 7 # 中文通常每个字或词对应多个token
Tokens: [b'\xe8', b'\xbf', b'\x99', b'\xe6', b'\x98', b'\xaf', b'\xe4', b'\xb8', b'\x80', b'\xe4', b'\xb8', b'\xaa', b'\xe6', b'\xb5', b'\x8b', b'\xe8', b'\xaf', b'\x95']
IDs: [232, 149, 151, 230, 153, 148, 230, 176, 161, 230, 176, 161, 230, 181, 139, 232, 175, 129]
文本: '🤗 🚀 🌟'
Token数量: 11 # 表情符号可能被拆分成多个字节
Tokens: [b'\xf0', b'\x9f', b'\xa4', b'\x97', b' ', b'\xf0', b'\x9f', b'\x9a', b'\x80', b' ', b'\xf0', b'\x9f', b'\x8c', b'\x9f']
IDs: [243, 129, 164, 151, 220, 129, 129, 154, 128, 220, 129, 140, 159]自定义BPE分词器示例
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import Whitespace
# 创建BPE分词器
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
tokenizer.pre_tokenizer = Whitespace()
# 准备训练数据
corpus = [
"This is the first sentence.",
"Here is another sentence for training.",
"The tokenizer will learn subword units."
]
# 训练分词器
trainer = BpeTrainer(
special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"],
vocab_size=1000
)
tokenizer.train_from_iterator(corpus, trainer)
# 使用训练好的分词器
text = "This is a new sentence."
output = tokenizer.encode(text)
print("Tokens:", output.tokens)
print("IDs:", output.ids)
# 批量编码
batch = ["First text", "Second text"]
batch_output = tokenizer.encode_batch(batch)输出结果
Tokens: ['This', 'is', 'a', 'new', 'sentence', '.']
IDs: [5, 9, 10, 8, 11, 12]BPE训练步骤示例:
- 初始词汇:所有字符 + 特殊token
- 统计所有相邻符号对频率
- 合并最高频的符号对
- 重复直到达到vocab_size=1000(这里实际用不到那么多)
处理中文文本
from transformers import AutoTokenizer
# 中文模型的分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
text = "自然语言处理很有趣!"
# 分词
tokens = tokenizer.tokenize(text)
print("中文Tokens:", tokens)
# 输出: ['自', '然', '语', '言', '处', '理', '很', '有', '趣', '!']
# 编码
input_ids = tokenizer.encode(text)
print("Input IDs:", input_ids)
# 解码
decoded = tokenizer.decode(input_ids)
print("Decoded:", decoded)实用函数
# 获取词汇表大小
vocab_size = tokenizer.vocab_size
print(f"词汇表大小: {vocab_size}")
# 添加新token
new_tokens = ["<custom_token>", "<another_token>"]
num_added = tokenizer.add_tokens(new_tokens)
print(f"添加了 {num_added} 个新token")
# 保存和加载
tokenizer.save_pretrained("./my_tokenizer")
loaded_tokenizer = AutoTokenizer.from_pretrained("./my_tokenizer")特殊token
# 常见的特殊tokens
special_tokens = {
"[CLS]": 分类起始标记,
"[SEP]": 分隔标记,
"[PAD]": 填充标记,
"[UNK]": 未知词标记,
"[MASK]": 掩码标记
}1.1.2.Tokenizer ≠ Encoder
Tokenizer(分词器) 和 Encoder(编码器) 在大语言模型中扮演不同角色:
1. Tokenizer:文本 → Token IDs(离散符号),像字典索引器
- 功能:将文本切分成token并映射到ID
- 输出:离散的数字序列
- 类比:像是把句子拆成单词并给每个单词编号
2. Encoder(模型的一部分):Token IDs → 向量表示,像语义理解器
- 功能:将token IDs转换为连续的向量表示
- 输出:高维的稠密向量(embeddings)
- 类比:给每个编号的单词赋予丰富的语义信息
1.1.3.完整流程示例
原始文本 → Tokenizer → Token IDs → Embedding层 → Transformer Encoder → 向量表示
↓ ↓ ↓ ↓ ↓
"Hello" → ["Hello"] → [15496] → [0.1,0.2,...] → [语义丰富的向量]先通过tokenizer把文字/图片处理后变成离散的token id,然后再通过embedding层(将离散变为连续,并学习基础语义相似性)和encoder(学习更复杂的上下文相关语义关系)把离散的token id变为一个个向量,同时,语义相近的不同文字对应的向量也会相近。
encoder不会改变embedding的维数。但经过encoder后向量本身的数值会改变,它的"位置"在向量空间中移动,变得更靠近语义相关的向量。
- 如“猫”经过embedding后结果是[1,3,5],那经过encoder的学习语义后,这个向量本身会变。(如变为[1.2,2.9,5.1]使得向量距离更靠近“动物类”)
from transformers import pipeline
# 完整流程示例:文本分类
classifier = pipeline("sentiment-analysis")
text = "I love using transformers!"
# 内部流程分解:
# 1. Tokenizer阶段
print("Tokenizer阶段:")
tokenized = classifier.tokenizer(text, return_tensors="pt")
print(f" Input IDs: {tokenized['input_ids'][0]}")
print(f" Attention Mask: {tokenized['attention_mask'][0]}")
# 2. Encoder阶段(模型内部)
print("\nEncoder阶段(模型内部处理):")
# 模型内部:
# a) embedding_layer(token_ids) → 初始向量
# b) transformer_layers(embeddings) → 上下文向量
# c) classification_head(context_vectors) → 预测结果
result = classifier(text)
print(f"\n最终结果: {result}")| 组件 | 输入 | 输出 | 是否有参数 | 是否可训练 |
|---|---|---|---|---|
| Tokenizer | 原始文本 | Token IDs | 无(词汇表固定) | 通常不训练 |
| Embedding层 | Token IDs | 向量(768维等) | 有 | 可训练 |
| Transformer Encoder | 向量 | 上下文向量 | 有 | 可训练 |
1.2.图片Tokenizer
核心思想:将图片"压扁"成序列:图片 → 预处理 → 编码为token → 像文本一样处理
- 分块编码:将图片分割成小块(patch/token)
- 向量量化:在预训练的codebook中查找最接近的表示
- 序列化:将2D图像网格展平为1D序列
- 统一处理:与文本token一起输入Transformer
这使得模型能够:
- 像处理文字一样"阅读"图片
- 从图片中"学习"视觉概念
- 根据文字描述"生成"对应图片
与文本tokenization相比,图像tokenization更复杂,因为它需要将连续的、高维的视觉信息转换为离散的、低维的符号序列。这是多模态AI能工作的关键技术基础。以下是几种主流方法介绍:
1.2.1.ViT
import torch
import numpy as np
from PIL import Image
def vit_tokenization_demo(image_path, patch_size=16):
"""
模拟ViT的分patch过程
"""
# 1. 加载图片
img = Image.open(image_path).convert('RGB')
img = img.resize((224, 224)) # ViT标准输入尺寸
# 2. 转换为numpy数组
img_array = np.array(img) # 形状: (224, 224, 3)
print(f"原始图片形状: {img_array.shape}")
print(f"像素值范围: {img_array.min()} ~ {img_array.max()}")
# 3. 分割成patch
h, w, c = img_array.shape
patches = []
for i in range(0, h, patch_size):
for j in range(0, w, patch_size):
patch = img_array[i:i+patch_size, j:j+patch_size, :]
patches.append(patch)
num_patches = len(patches)
print(f"分割成 {num_patches} 个patch")
print(f"每个patch形状: {patches[0].shape}")
# 4. 展平并线性投影(模拟)
# 每个patch: (16, 16, 3) = 768像素
patch_dim = patch_size * patch_size * 3
# 5. 添加位置编码
positions = np.arange(num_patches)
return img_array, patches, positions
# 模拟这个过程
print("=== ViT Tokenization 示例 ===")
# 实际中不会这样手动操作,这里只是展示概念1.2.2.VQ-VAE
Vector Quantized Variational Autoencoder,这是DALL-E、Stable Diffusion等图像生成模型使用的关键方法。
图片 → VQ-VAE编码器 → 连续特征图 → 向量量化 → 离散token IDs
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimplifiedVQVAE(nn.Module):
"""简化的VQ-VAE演示"""
def __init__(self, vocab_size=8192, latent_dim=256):
super().__init__()
self.vocab_size = vocab_size
self.latent_dim = latent_dim
# 编码器
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, 4, stride=2, padding=1), # 112x112
nn.ReLU(),
nn.Conv2d(64, 128, 4, stride=2, padding=1), # 56x56
nn.ReLU(),
nn.Conv2d(128, latent_dim, 1) # 最终特征图
)
# 向量量化层(codebook)
self.codebook = nn.Embedding(vocab_size, latent_dim)
# 解码器
self.decoder = nn.Sequential(
nn.ConvTranspose2d(latent_dim, 128, 4, stride=2, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(64, 3, 4, stride=2, padding=1),
nn.Sigmoid()
)
def encode_to_tokens(self, x):
"""将图片编码为token IDs"""
# 1. 通过编码器得到特征图
z = self.encoder(x) # 形状: [B, D, H, W]
# 2. 展平以便查找最近邻
b, d, h, w = z.shape
z_flat = z.permute(0, 2, 3, 1).reshape(-1, d) # [B*H*W, D]
# 3. 在codebook中查找最近的向量
distances = torch.cdist(z_flat, self.codebook.weight) # 计算距离
token_ids = torch.argmin(distances, dim=-1) # 得到token IDs
# 4. 重塑回2D网格
token_ids = token_ids.reshape(b, h, w)
return token_ids
def decode_from_tokens(self, token_ids):
"""从token IDs解码回图片"""
# 1. 通过codebook查找对应向量
z_q = self.codebook(token_ids) # [B, H, W, D]
# 2. 调整维度并解码
z_q = z_q.permute(0, 3, 1, 2) # [B, D, H, W]
recon = self.decoder(z_q)
return recon
# 演示VQ-VAE过程
print("\n=== VQ-VAE Tokenization 过程 ===")
print("1. 输入图片: 256x256 RGB")
print("2. 编码器下采样: 64x64 特征图")
print("3. 向量量化: 64x64 个token IDs (每个来自8192词汇表)")
print("4. 每个位置: 选择codebook中最接近的向量")
print(f"5. 输出: 64×64 = 4096个token IDs")1.2.3.实际代码示例:使用Hugging Face
这个过程将整个图片编码为一个特征向量。对于生成任务(如图片生成文本),需要更细粒度的tokenization。
from transformers import AutoProcessor, AutoModel
from PIL import Image
import torch
# 加载支持图像的模型(如BLIP、CLIP)
print("=== 使用预训练的图像处理器 ===")
# 示例1: BLIP模型
processor = AutoProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = AutoModel.from_pretrained("Salesforce/blip-image-captioning-base")
# 加载图片
image = Image.open("example.jpg").convert("RGB")
# 处理图片
inputs = processor(images=image, return_tensors="pt")
print(f"像素值形状: {inputs['pixel_values'].shape}")
# 输出: torch.Size([1, 3, 384, 384])
# 获取图像特征
with torch.no_grad():
outputs = model.get_image_features(**inputs)
print(f"图像特征形状: {outputs.shape}")
# 输出: torch.Size([1, 768]) - 一个向量表示整个图片1.2.4.多模态模型的统一tokenization
import torch
from PIL import Image
from transformers import (
AutoTokenizer, # 文本tokenizer
AutoImageProcessor, # 图像processor
CLIPProcessor, # CLIP的多模态processor
BlipProcessor, # BLIP的多模态processor
ViTImageProcessor # ViT图像processor
)
import requests
from io import BytesIO
class MultimodalTokenizer:
"""使用Hugging Face实现的多模态tokenizer"""
def __init__(self, model_name="openai/clip-vit-base-patch32"):
"""
初始化多模态tokenizer
Args:
model_name: 预训练模型名称
- "openai/clip-vit-base-patch32": CLIP模型
- "Salesforce/blip-image-captioning-base": BLIP模型
"""
self.model_name = model_name
# 加载文本tokenizer和图像processor
if "clip" in model_name:
self.processor = CLIPProcessor.from_pretrained(model_name)
self.text_tokenizer = self.processor.tokenizer
self.image_processor = self.processor.image_processor
elif "blip" in model_name:
self.processor = BlipProcessor.from_pretrained(model_name)
self.text_tokenizer = self.processor.tokenizer
self.image_processor = self.processor.image_processor
else:
# 分开加载文本和图像处理器
self.text_tokenizer = AutoTokenizer.from_pretrained(model_name)
self.image_processor = AutoImageProcessor.from_pretrained(model_name)
self.processor = None
# 添加特殊token(如果需要)
self._setup_special_tokens()
def _setup_special_tokens(self):
"""设置多模态特殊token"""
# 获取基础词汇表大小
self.text_vocab_size = len(self.text_tokenizer)
# 定义特殊token
special_tokens_dict = {
'additional_special_tokens': [
'<image>',
'</image>',
'<audio>',
'</audio>'
]
}
# 添加特殊token到tokenizer
num_added = self.text_tokenizer.add_special_tokens(special_tokens_dict)
# 特殊token的ID映射
self.special_tokens = {
'bos_token': self.text_tokenizer.bos_token,
'eos_token': self.text_tokenizer.eos_token,
'pad_token': self.text_tokenizer.pad_token,
'image_start': self.text_tokenizer.convert_tokens_to_ids('<image>'),
'image_end': self.text_tokenizer.convert_tokens_to_ids('</image>'),
}
print(f"添加了 {num_added} 个特殊token")
print(f"词汇表大小: {len(self.text_tokenizer)}")
def encode_text(self, text, add_special_tokens=True):
"""编码文本"""
encoding = self.text_tokenizer(
text,
return_tensors="pt", # 返回PyTorch tensor
add_special_tokens=add_special_tokens,
padding=True,
truncation=True,
max_length=512
)
return encoding
def encode_image(self, image_path_or_url):
"""编码图像"""
# 加载图像
if image_path_or_url.startswith('http'):
response = requests.get(image_path_or_url)
image = Image.open(BytesIO(response.content)).convert('RGB')
else:
image = Image.open(image_path_or_url).convert('RGB')
# 使用processor处理图像
if self.processor:
# 使用多模态processor
image_inputs = self.processor(images=image, return_tensors="pt")
else:
# 使用单独的image processor
image_inputs = self.image_processor(image, return_tensors="pt")
return image_inputs, image
def encode_multimodal(self, texts, images, image_positions=None):
"""
编码多模态输入(文本+图像)
Args:
texts: 文本列表,None表示图像位置
images: 图像路径/URL列表
image_positions: 图像插入位置,如[1]表示在第一个文本后插入图像
Returns:
包含input_ids, attention_mask, pixel_values等的字典
"""
if image_positions is None:
image_positions = [0] # 默认在开头插入图像
# 处理所有图像
image_inputs_list = []
images_processed = []
for img_path in images:
img_inputs, img = self.encode_image(img_path)
image_inputs_list.append(img_inputs)
images_processed.append(img)
# 处理文本
if texts is None:
texts = [""] * (len(images) + 1)
# 构建多模态输入
multimodal_inputs = {
'input_ids': [],
'attention_mask': [],
'pixel_values': [],
'image_positions': image_positions
}
current_pos = 0
text_idx = 0
for img_idx, img_inputs in enumerate(image_inputs_list):
# 添加当前文本
if text_idx < len(texts):
text_encoding = self.encode_text(texts[text_idx], add_special_tokens=True)
multimodal_inputs['input_ids'].append(text_encoding['input_ids'])
multimodal_inputs['attention_mask'].append(text_encoding['attention_mask'])
text_idx += 1
# 添加图像标记和图像特征
# 添加图像开始标记
img_start_tensor = torch.tensor([[self.special_tokens['image_start']]])
multimodal_inputs['input_ids'].append(img_start_tensor)
multimodal_inputs['attention_mask'].append(torch.tensor([[1]]))
# 添加图像特征(在实际模型中,这通常是分开处理的)
# 这里我们保存pixel_values供后续使用
multimodal_inputs['pixel_values'].append(img_inputs['pixel_values'])
# 添加图像结束标记
img_end_tensor = torch.tensor([[self.special_tokens['image_end']]])
multimodal_inputs['input_ids'].append(img_end_tensor)
multimodal_inputs['attention_mask'].append(torch.tensor([[1]]))
# 添加剩余文本
while text_idx < len(texts):
text_encoding = self.encode_text(texts[text_idx], add_special_tokens=True)
multimodal_inputs['input_ids'].append(text_encoding['input_ids'])
multimodal_inputs['attention_mask'].append(text_encoding['attention_mask'])
text_idx += 1
# 合并所有输入
multimodal_inputs['input_ids'] = torch.cat(multimodal_inputs['input_ids'], dim=1)
multimodal_inputs['attention_mask'] = torch.cat(multimodal_inputs['attention_mask'], dim=1)
multimodal_inputs['pixel_values'] = torch.cat(multimodal_inputs['pixel_values'], dim=0)
return multimodal_inputs, images_processed
def decode_text(self, input_ids):
"""解码文本token"""
return self.text_tokenizer.decode(input_ids[0], skip_special_tokens=False)
def visualize_multimodal_input(self, multimodal_inputs):
"""可视化多模态输入结构"""
input_ids = multimodal_inputs['input_ids'][0]
tokens = self.text_tokenizer.convert_ids_to_tokens(input_ids)
print("\n" + "="*50)
print("多模态输入结构分析")
print("="*50)
print(f"\n输入ID序列长度: {len(input_ids)}")
print(f"特殊token映射: {self.special_tokens}")
print("\nToken序列:")
for i, (token, token_id) in enumerate(zip(tokens, input_ids)):
if token == '<image>':
print(f"{i:3d}: [IMAGE_START] (ID: {token_id})")
elif token == '</image>':
print(f"{i:3d}: [IMAGE_END] (ID: {token_id})")
elif token == self.text_tokenizer.bos_token:
print(f"{i:3d}: [BOS] (ID: {token_id})")
elif token == self.text_tokenizer.eos_token:
print(f"{i:3d}: [EOS] (ID: {token_id})")
elif token == self.text_tokenizer.pad_token:
print(f"{i:3d}: [PAD] (ID: {token_id})")
else:
print(f"{i:3d}: {token} (ID: {token_id})")
print(f"\n图像特征形状: {multimodal_inputs['pixel_values'].shape}")
print(f"图像位置: {multimodal_inputs['image_positions']}")
# =========== 使用示例 ===========
def main():
print("=== Hugging Face 多模态Tokenizer示例 ===\n")
# 示例1: 使用CLIP模型
print("1. 使用CLIP模型的多模态processor")
clip_tokenizer = MultimodalTokenizer("openai/clip-vit-base-patch32")
# 示例文本
text = "A cute cat sitting on a sofa"
# 编码文本
text_encoding = clip_tokenizer.encode_text(text)
print(f"文本: '{text}'")
print(f"文本token数量: {text_encoding['input_ids'].shape[1]}")
print(f"文本token IDs: {text_encoding['input_ids'][0][:10]}...")
# 示例图像URL(来自网络)
image_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/cats.png"
# 编码图像输入
try:
multimodal_inputs, processed_images = clip_tokenizer.encode_multimodal(
texts=["What is in this image?", "Describe the image."],
images=[image_url],
image_positions=[1] # 在第一个文本后插入图像
)
print(f"输入ID序列形状: {multimodal_inputs['input_ids'].shape}")
print(f"注意力掩码形状: {multimodal_inputs['attention_mask'].shape}")
print(f"图像特征形状: {multimodal_inputs['pixel_values'].shape}")
# 可视化输入结构
clip_tokenizer.visualize_multimodal_input(multimodal_inputs)
# 解码查看
decoded = clip_tokenizer.decode_text(multimodal_inputs['input_ids'])
print(f"\n解码后的序列(部分): {decoded[:100]}...")
except Exception as e:
print(f"网络请求失败,使用本地示例: {e}")
# 本地示例
multimodal_inputs = {
'input_ids': torch.tensor([[0, 100, 101, 50258, 50259, 102, 103, 1]]),
'attention_mask': torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]]),
'pixel_values': torch.randn(1, 3, 224, 224),
'image_positions': [2]
}
clip_tokenizer.visualize_multimodal_input(multimodal_inputs)
# 示例2: 使用BLIP模型
print("\n2. 使用BLIP模型进行图像描述")
blip_tokenizer = MultimodalTokenizer("Salesforce/blip-image-captioning-base")
# 编码文本提示
prompt = "a photography of"
prompt_encoding = blip_tokenizer.encode_text(prompt)
print(f"提示词: '{prompt}'")
print(f"Token IDs: {prompt_encoding['input_ids'][0]}")
# 图像编码(这里只是展示结构)
print("\nBLIP图像处理流程:")
print("1. 图像resize到384x384")
print("2. 归一化像素值")
print("3. 提取视觉特征")
print("4. 与文本特征拼接")
# 示例3: 实际应用场景
print("\n3. 实际应用:视觉问答(VQA)")
def visual_qa_example():
"""视觉问答示例"""
vqa_tokenizer = MultimodalTokenizer("openai/clip-vit-base-patch32")
# 模拟VQA输入
question = "What color is the cat?"
# 在实际应用中,这里会有真实的图像
# 这里用随机数据模拟
vqa_inputs = {
'input_ids': torch.tensor([[0, 1054, 2067, 2024, 1037, 3899, 30, 50258, 50259, 1]]),
'attention_mask': torch.ones(1, 10),
'pixel_values': torch.randn(1, 3, 224, 224)
}
print(f"问题: '{question}'")
print(f"输入序列长度: {vqa_inputs['input_ids'].shape[1]}")
# 显示token序列
tokens = vqa_tokenizer.text_tokenizer.convert_ids_to_tokens(vqa_inputs['input_ids'][0])
print(f"Token序列: {tokens}")
visual_qa_example()
# 示例4: 自定义多模态提示工程
print("\n4. 自定义多模态提示工程")
class MultimodalPromptEngineer:
"""多模态提示工程"""
def __init__(self, tokenizer):
self.tokenizer = tokenizer
def create_image_caption_prompt(self, image_count=1):
"""创建图像描述提示"""
prompt = "Describe the image in detail: "
# 添加图像占位符
for i in range(image_count):
prompt += f" <image> [Image {i+1}] </image> "
prompt += " Provide a detailed description."
return prompt
def create_vqa_prompt(self, question, image_count=1):
"""创建视觉问答提示"""
prompt = f"Question: {question}\n\n"
# 添加图像占位符
for i in range(image_count):
prompt += f" <image> [Image {i+1}] </image> "
prompt += "\n\nAnswer:"
return prompt
prompt_engineer = MultimodalPromptEngineer(clip_tokenizer)
caption_prompt = prompt_engineer.create_image_caption_prompt(image_count=2)
print(f"图像描述提示: {caption_prompt}")
vqa_prompt = prompt_engineer.create_vqa_prompt("How many cats are there?", image_count=1)
print(f"VQA提示: {vqa_prompt}")
# 编码自定义提示
caption_encoding = clip_tokenizer.encode_text(caption_prompt)
print(f"提示token数量: {caption_encoding['input_ids'].shape[1]}")
if __name__ == "__main__":
main()简化版本
from transformers import CLIPProcessor, CLIPTokenizer, CLIPImageProcessor
import torch
from PIL import Image
class SimpleMultimodalTokenizer:
"""简化版多模态tokenizer"""
def __init__(self):
# 使用CLIP的处理器(同时处理文本和图像)
self.processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 单独获取tokenizer和image_processor
self.tokenizer = self.processor.tokenizer
self.image_processor = self.processor.image_processor
# 添加图像特殊token
special_tokens = {'additional_special_tokens': ['<image>']}
self.tokenizer.add_special_tokens(special_tokens)
self.image_token_id = self.tokenizer.convert_tokens_to_ids('<image>')
def prepare_multimodal_input(self, text_prompt, image):
"""
准备多模态输入
Args:
text_prompt: 包含<image>标记的文本,如"A cat <image> on a sofa"
image: PIL Image对象
"""
# 处理文本
text_inputs = self.tokenizer(
text_prompt,
return_tensors="pt",
padding=True,
truncation=True
)
# 处理图像
image_inputs = self.image_processor(image, return_tensors="pt")
# 在实际模型中,这里需要将图像特征插入到<image>标记的位置
# 这个简化版本只是返回分开的输入
return {
'input_ids': text_inputs['input_ids'],
'attention_mask': text_inputs['attention_mask'],
'pixel_values': image_inputs['pixel_values']
}
# 使用示例
tokenizer = SimpleMultimodalTokenizer()
# 创建包含图像标记的文本
text = "This is an image of <image> showing a beautiful landscape."
# 加载图像
image = Image.new('RGB', (224, 224), color='red') # 示例图像
# 准备输入
inputs = tokenizer.prepare_multimodal_input(text, image)
print("\n1. 文本token分析:")
print(f" 原始文本: {text}")
print(f" Token IDs: {inputs['input_ids'][0].tolist()}")
print(f" Token序列: {tokenizer.tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])}")
print(f" 图像标记<image>的ID: {tokenizer.image_token_id}")
print("\n2. 图像特征:")
print(f" 像素值形状: {inputs['pixel_values'].shape}") # [1, 3, 224, 224]
print(f" 批次大小: {inputs['pixel_values'].shape[0]}")
print(f" 通道数: {inputs['pixel_values'].shape[1]}")
print(f" 图像高度: {inputs['pixel_values'].shape[2]}")
print(f" 图像宽度: {inputs['pixel_values'].shape[3]}")
print("\n3. 注意力掩码:")
print(f" Attention Mask: {inputs['attention_mask'][0].tolist()}")=== 简易版本实际输出 ===
1. 文本token分析:
原始文本: This is an image of <image> showing a beautiful landscape.
Token IDs: [49406, 566, 533, 716, 508, 49408, 1196, 257, 4524, 10838, 49407]
Token序列: ['<|startoftext|>', 'this', 'is', 'an', 'image', 'of', '<image>', 'showing', 'a', 'beautiful', 'landscape', '<|endoftext|>']
图像标记<image>的ID: 49408
2. 图像特征:
像素值形状: torch.Size([1, 3, 224, 224])
批次大小: 1
通道数: 3
图像高度: 224
图像宽度: 224
3. 注意力掩码:
Attention Mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]- 统一接口:Hugging Face的多模态模型通常提供
processor来处理文本和图像 - 特殊token:通过添加
<image>等特殊标记来表示图像位置 - 分开处理:文本和图像通常分开处理,然后在模型中融合
- 实际模型:在实际的多模态Transformer中,图像特征会通过一个投影层转换为与文本embedding相同的维度
这个示例展示了如何使用Hugging Face库来处理多模态输入,实际的多模态模型(如BLIP、CLIP、Flamingo等)内部会有更复杂的机制来处理图像和文本的交互。
Tokenizer只是数据预处理器,不会生成任何描述!
# ❌错误理解:
Tokenizer → 生成图像描述
# ✅正确流程:
图像/文本 → Tokenizer预处理 → 模型推理 → 输出结果
↑
(这才是关键)1.3.减少Token数量的方法
由于各模型厂商通过token数量计费,且模型上下文记忆也以token计算,故减少token的使用数量成为了一个重要课题。
| 方法类别 | 具体方法 | 适用场景 | 举例 |
|---|---|---|---|
| 文本精简 | 删除冗余词 | 所有文本处理 | "I would like to go to" → "Go to" |
| 使用短词替代 | 正式文档、技术文本 | "utilization" → "use" | |
| 删除不必要标点 | 代码、结构化内容 | "Hello, world!!!" → "Hello world" | |
| 提示工程 | 精简prompt指令 | AI对话、指令跟随 | 删除重复说明和过度礼貌用语 |
| 减少示例数量 | 少样本学习 | 5个示例减为2-3个关键示例 | |
| 用系统消息 | 角色扮演、持续对话 | 将角色设定放在system而非user | |
| 结构优化 | JSON/YAML格式 | 数据提取、API调用 | 自然语言描述 → 结构化JSON |
| 专有名词缩写 | 学术、技术文档 | "Large Language Model (LLM)"后只用LLM | |
| 代码压缩 | 代码生成和分析 | 删除注释、压缩空格 | |
| 处理策略 | 文本分块 | 长文档处理 | 100页PDF分成10个10页块处理 |
| 批处理请求 | 批量数据处理 | 多个相似问题合并为一个请求 | |
| 缓存机制 | 常见问答、模板 | 缓存常见问题的回答模板 | |
| 技术优化 | 选择高效模型 | 模型选型 | GPT-4替代GPT-3.5(更高效) |
| 自定义分词器 | 特定领域应用 | 为医疗领域训练专用分词器 | |
| Embedding复用 | 向量检索系统 | 缓存常用文本的embedding | |
| 语言优化 | 中文精简表达 | 中文内容处理 | "非常非常的感谢" → "感谢" |
| 符号替代文字 | 数学、逻辑内容 | "greater than" → ">" | |
| 使用术语缩写 | 专业领域交流 | "Artificial Intelligence" → "AI" | |
| 格式优化 | 列表替代段落 | 项目列举、要点 | 段落描述 → 要点列表 |
| 表格替代描述 | 数据对比、属性 | 文字描述 → 简洁表格 | |
| 标记语言简化 | 网页内容、文档 | 简化HTML标签和属性 |
1.4.开源tokenizer.py能看出什么
为什么说看一个大模型的tokenizer.py就能看出他是否是蒸馏出来的或完全原创预训练出来的?
- Tokenizer 几乎是预训练阶段“最不可能被事后修改”的组件,而蒸馏模型往往会“继承”教师模型的 tokenizer,因此在
tokenizer.py / tokenizer.json里会留下非常明显的“血缘痕迹”。 - Tokenizer 决定了整个预训练的数据空间,一旦 tokenizer 确定:
- 词表大小
|V| - token 的切分方式(BPE / Unigram / WordPiece)
- 每个 token 的 ID 编号
那么, - Embedding 矩阵形状被锁死
- 预训练 checkpoint 与 tokenizer 强绑定
- 换 tokenizer ≈ 重新预训练
- 词表大小
- 蒸馏模型为什么“必然暴露在 tokenizer 上”?
- 蒸馏通常是:Teacher LM outputs (logits / hidden states)→Student LM
-
因此蒸馏几乎必然要求:Student tokenizer = Teacher tokenizer
-
看 tokenizer 能看出什么“血缘关系”?
- 词表结构是否高度雷同(最关键,词表大小、自定义特殊token、顺序)
- 极不自然但“历史包袱式”的 token
- 语言覆盖范围是否“诡异一致”(辨别明显的设计动机)
- tokenizer 代码风格 & 文件格式(复用 HuggingFace 官方实现)
但使用相同 tokenizer ≠ 一定是蒸馏,也有可能是同一体系下的继续预训练 / 扩展预训练,如Qwen → Qwen2。
2.VLM
什么是视觉-语言模型?
- 在LLM的基础上加入了视觉(图像)编码token的分支,将视觉和文本的token共同输入至LLM解码器中。
有无理论上的缺点?
- tokenization 瓶颈:图像不像文本,自身没有结构化或可分解的标记,必须先进行编码。但编码图像需要相当多的token,这会增加内存使用量并减缓推理的速度。
- 产生幻觉:和LLM相同的问题,由于学习的只是概率分布,并非真实的人类逻辑和视觉。
- 产生偏见:和LLM相同的问题,由于训练的数据集中自带的偏见。
3.BLIP
原文链接:BLIP
3.1.动机
- 模型角度:encoder-based的模型无法做生成任务,而encoder-decoder-based的模型无法做检索和理解任务;
- 数据角度:预训练数据集中包含了很多噪声。
BLIP = 一个“可切换角色”的 Transformer:同一套参数,既能当编码器(理解),也能当解码器(生成),通过不同注意力掩码与任务头完成多种视觉-语言任务。
3.2.方法
和因果自注意力的对比:
|
机制 |
能看左边 |
能看右边 |
典型模型 |
|---|---|---|---|
|
双向自注意力 |
✅ |
✅ |
BERT / BLIP 编码器 |
|
因果自注意力 |
✅ |
❌ |
GPT / BLIP 解码器 |
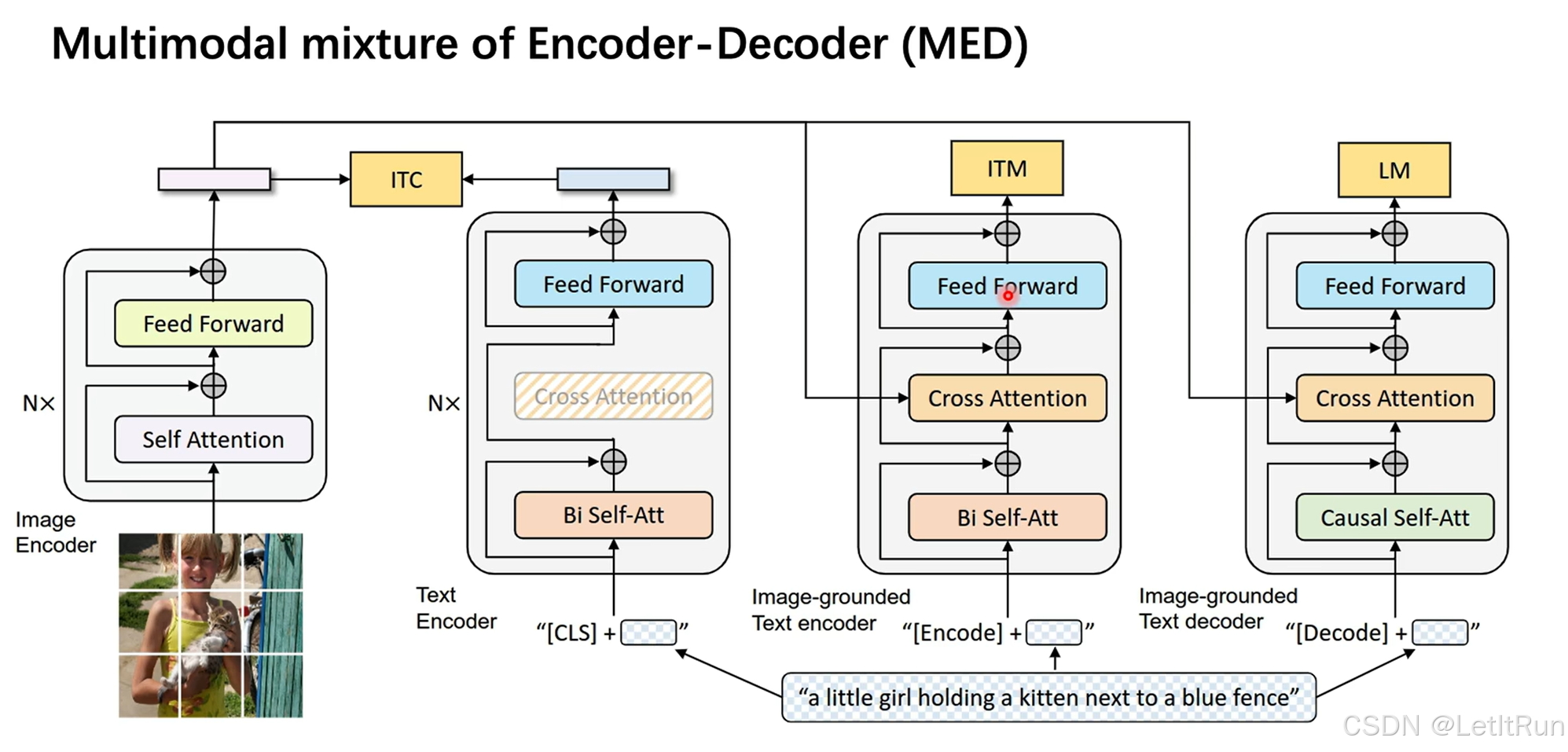
BLIP提出了一个多模态混合的Encoder-Decoder模型(MED),有四个板块:(统一了生成和理解任务的框架)
- 左一:图像编码器。
- 标准的ViT,
- 重复 N 次,输出得到特征embedding。
- 左二:文本编码器1。
- 输入是[CLS]token头+文本,会经过双向的self-attention并通过残差链接、不通过cross-attention、直接经过Feed Forward模块。Bi-directional Self-Attention(像 BERT)
- 得到一个 全局文本表示(CLS),输出得到特征embedding。
- 与图像编码器进行图文对比学习的对齐任务ITC。(这一步不做细粒度理解,只做全局对齐)
- 右二:文本编码器2。
- 输入是[encode]token头+文本,经过双向的self-attention、cross-attention、Feed Forward模块得到输出得到特征embedding。
- 图像的embedding会注入到cross-attention中。
- 与图像编码器进行图文的匹配任务ITM。(文本 token 可以逐词看图,学的是 细粒度跨模态对齐)
- 输出一个 二分类结果:这对图文是否匹配?
- 右一:文本解码器。
- 输入是[decode]头+文本,经过因果关系的self-attention、cross-attention、Feed Forward模块得到输出得到特征embedding。
- 图像的embedding会注入到cross-attention中。
- 完成语言模型的解码任务LM。(“看着图,一词一词往外写句子”)
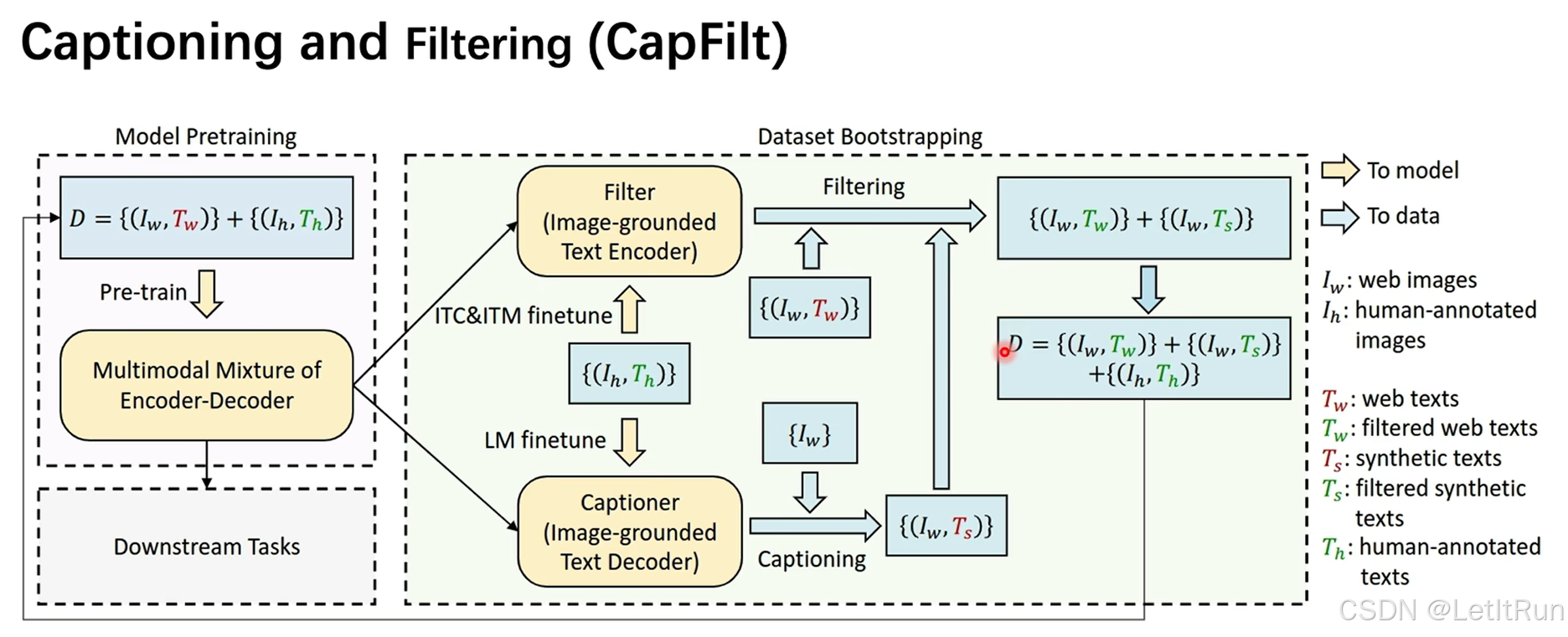
这幅图展示的是 BLIP 提出的 CapFilt(Captioning and Filtering)数据引导式预训练流程。
如果说 MED 讲的是模型结构,那 CapFilt 讲的就是:这个模型如何“自己造高质量数据,再喂给自己训练”。
- 左侧:Model Pretraining(模型预训练起点)
- Iw, Tw:网页图像 + 网页文本(量大但噪声大)
- $I_h, T_h$:人工标注图像 + 文本(量小但质量高)
- 用这些数据 预训练一个 BLIP(MED 架构)
- Dataset Bootstrapping(数据自举)右侧虚线框是整张图的精髓:
- 模型 → 生成数据 → 筛选数据 → 再训练模型
- 下支路:Captioning(生成描述)
- Captioner(Image-grounded Text Decoder)
- 使用的是 MED 里的 Decoder(因果自注意力 + cross-attention)
- 先用 人工数据 $(I_h, T_h)$ 做 LM 微调
- 学会:“如何看图写一句靠谱的话”
- 对网页图片生成文本,只给图片:$\{I_w\}$,模型生成:{(Iw,Ts)}。Ts:synthetic texts(合成描述,即模型写出来的 caption)
- 上支路:Filtering(过滤噪声)
- Filter(Image-grounded Text Encoder)
- 使用的是 MED 里的 Image-grounded Text Encoder
- 用 ITC + ITM 在人工数据 $(I_h, T_h)$ 上微调
- 学会判断:图文是否语义一致
- 最终结果:更强的训练集 $D'$
- 保留 高质量网页文本
- 加入 高质量模型生成文本
- 继续保留 人工标注数据
- 得到一个 规模大 + 噪声低 + 语义对齐强 的多模态训练集
4.BLIP-2
原文链接:BLIP-2
4.1.摘要
由于大规模模型的端到端训练,视觉和语言预训练的成本变得越来越高。本文提出了一种通用高效的预训练策略BLIP-2,从现成的冻结预训练图像编码器和冻结的大型语言模型中引导视觉语言预训练。BLIP-2通过一个轻量级查询转换器( Querying Transformer )来桥接模态鸿沟,该查询转换器分为两个阶段进行预训练。第一阶段从一个冻结的图像编码器中引导视觉-语言表示学习。第二阶段从冻结的语言模型中引导视觉到语言的生成学习。BLIP-2在各种视觉语言任务上取得了最先进的性能,尽管它的可训练参数显著少于现有方法。 例如,我们的模型比Flamingo80B提高了8.7 %,训练参数少54倍。我们还展示了模型的零样本图像到文本生成的能力,可以遵循自然语言指令。
用一个极小的 Q-Former,把“高维、密集的视觉特征”,压缩成“LLM 能直接理解的少量 token”,然后几乎不动视觉模型、不动语言模型,就实现强多模态生成。
4.2.动机
由于大规模模型的端到端训练,视觉与语言预训练的成本变得越来越高昂。和 BLIP(上一代)的关键区别:
|
BLIP |
BLIP-2 |
|---|---|
|
多模态 Transformer 很大 |
多模态部分 极小 |
|
编码 + 解码耦合 |
Q-Former 作为桥梁 |
|
训练成本高 |
冻结大模型,省算力 |
4.3.方法
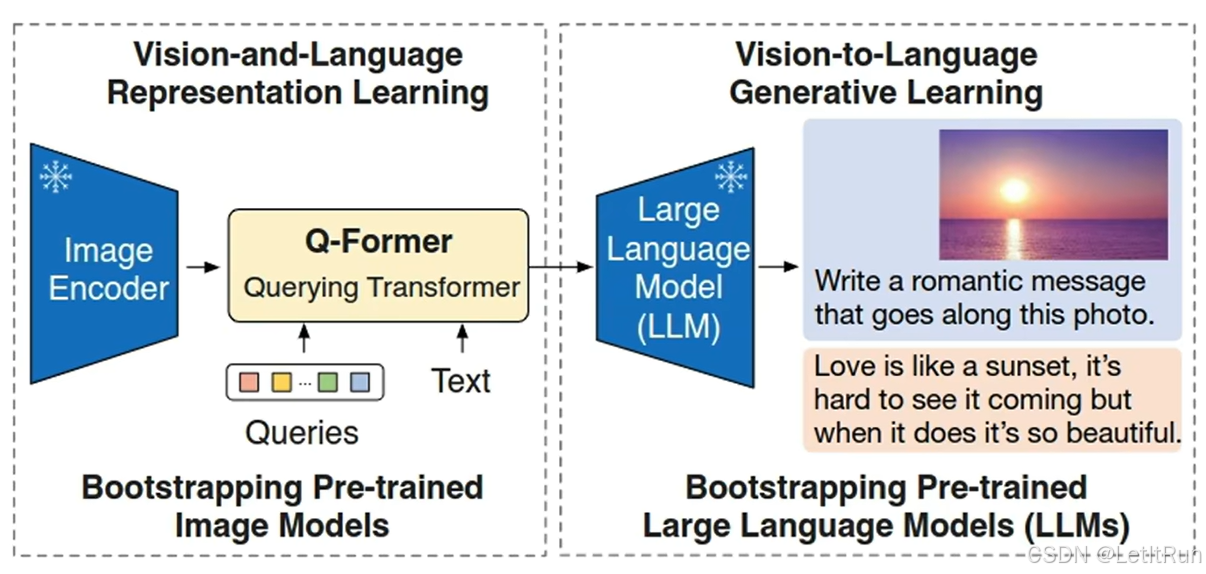
冻结图像和文本编码器,不让它们更新。
引入一个极小的Transformer,即Q-Former(Ouerying Transformer),来抹平图像和文本编码器之间的信息的gap。(Q-Former作为查询器,查询与输入的text最相关的图像信息是什么(同时达到抹去图像中不相关信息的作用))。整个模型架构分为两阶段:
- 视觉 和 语言的表征学习
- 视觉 到 语言的生成学习
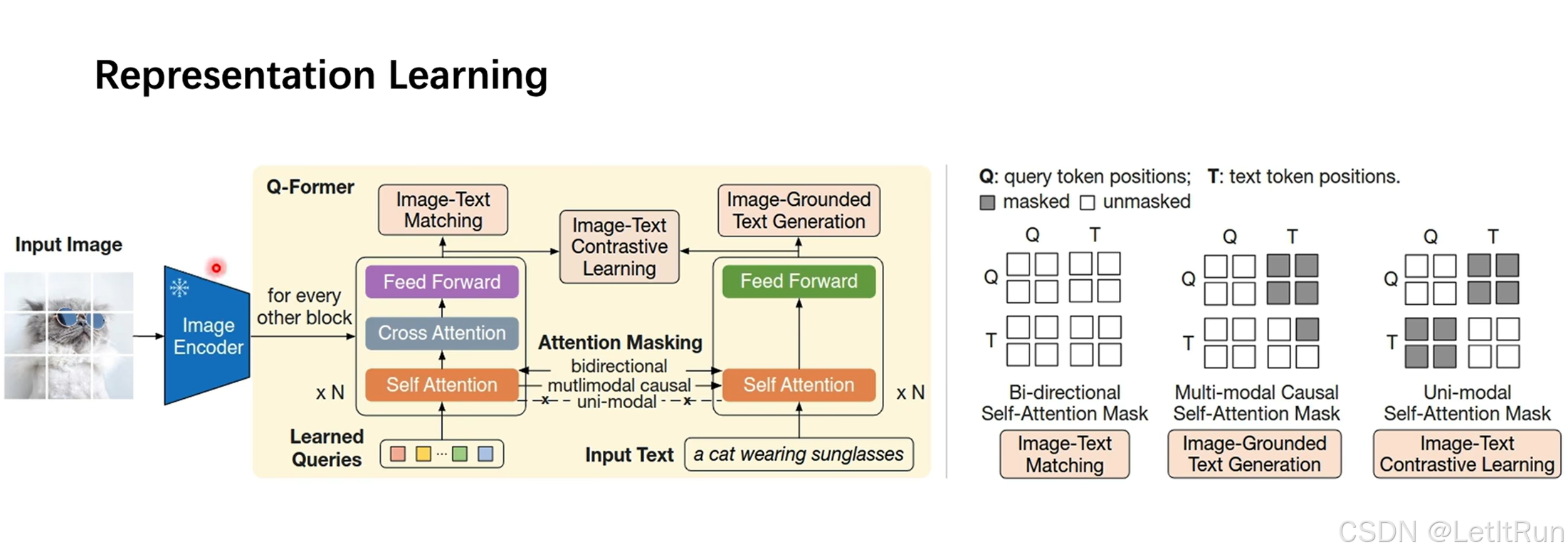
- Q-Former = 带“可学习查询 token”的 Transformer,Q-Former 由两个子模块(双塔)组成,这两个子模块共享相同的自注意力层。
- 左列用于提取图像特征 ;右列用于提取文本特征 ;左列+右列用于提取多模态特征。
- 左列做的事情整体可以理解为输入N个learned query。
- 输入:一张图像+对应的文本,在Q-Former中还会输入可学习的Query-vector。
- Query-vector直接输入到Q-Former中的Transformer块的自注意力模块中。
- 冻结的图像编码器得到图像embedding,输入到Q-Former中的Transformer块的交叉注意力模块中。使得Query可以真正去“查询”图像中有用的信息。
- 损失函数(指导模型学习什么东西--三种训练目标),同样是ITM(匹配)、文本生成(LM,GPT)、ITC(对齐)三块。
- 图文匹配:双向自注意力机制(序列中每一个 token,在计算表示时,可以同时“看见”左边和右边的所有 token)。
- 文本生成:根据给定的Query生成Text。采用注意力掩码(多模态因果自注意力),给出Q时不能看到T,给出已知的T不能看到后面的T(文本T只能看左边,但可以看Q视觉)。
- 图文对齐:Q和T得到各自的embedding。采用注意力掩码,给出Q时不能看到T,给出T时不能看到Q。
- Q-Former 通过“不同 attention mask”,在同一结构里同时学会:对齐、匹配、生成。这在思想上,和 BLIP 的 MED 是完全同源的。
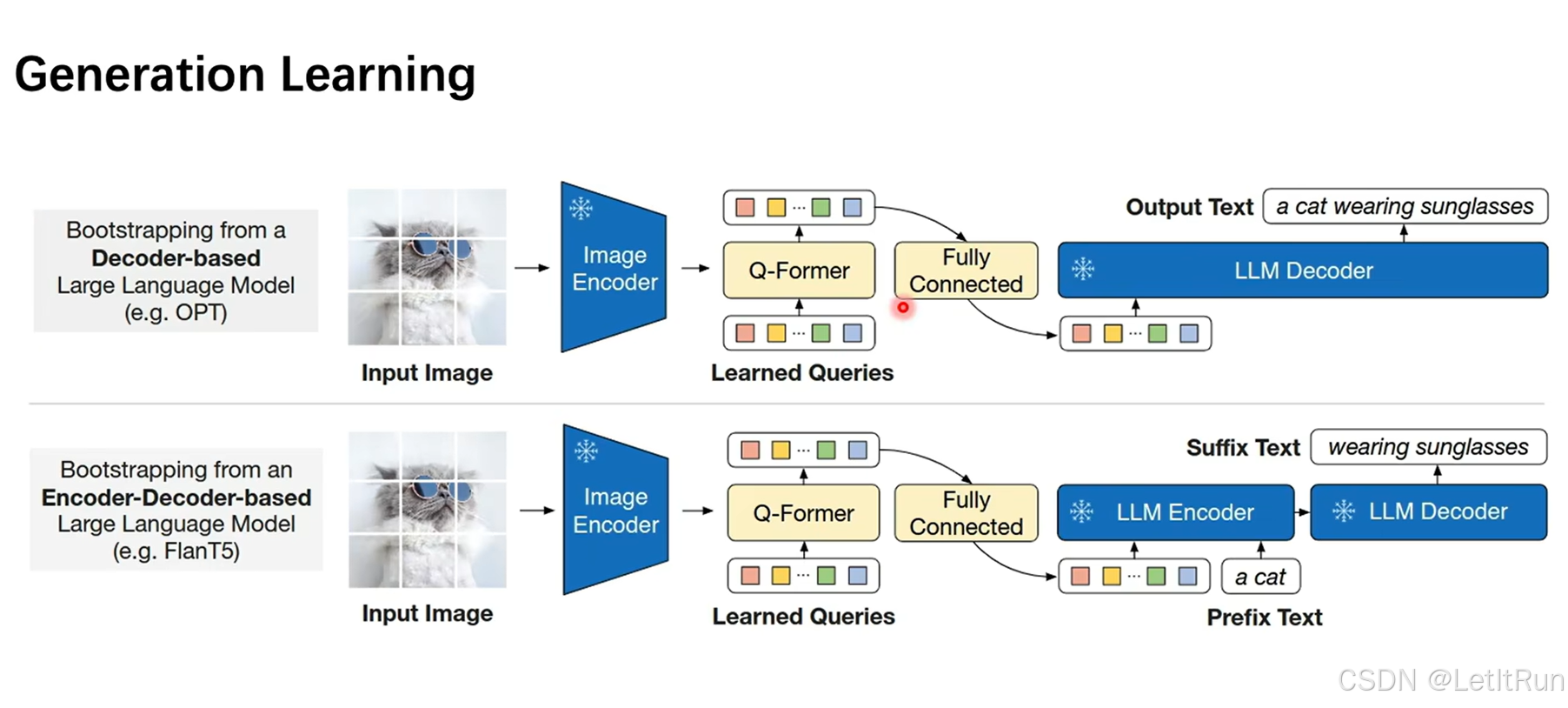
将Q-Former的输出通过一个全连接层投影到LLM解码器的空间。有两种形式(图中上下两块):
- 上:完全不给任何文本,直接将投影的embedding输入LLM decoder(如 OPT / GPT);
- 类似:“我先把图像信息写成几句话,塞进 GPT 的上下文里”
- 下:给出一个词(词组)作为prefix,Q-Former 输出作为 encoder 条件,与embedding在LLM encoder进行拼接后再一起进入LLM decoder(如 Flan-T5)。
5.LLaVA
原文链接:Visual Instruction Tuning
5.1.动机
大型语言模型(LLMs)在自然语言处理领域取得了巨大成功。它们通过指令微调(instruction tuning)的方式,即使用大量人工或机器生成的“指令-响应”对进行训练,显著提升了模型在新任务上的零样本泛化能力(zero-shot generalization)。 然而,这一思想在多模态领域(尤其是图像与语言结合)尚未被深入探索。传统的视觉模型虽然在分类、检测、分割等任务上表现出色,但通常是针对特定任务独立设计的,缺乏与用户进行交互式对话或遵循复杂多步指令的能力。
把“擅长听话的 LLM”和“能看世界的视觉模型”连起来,让模型真正“按人类指令看图并思考”,而不是只会描述图片。
- 已有多模态模型(如 BLIP-2)更像 captioner ,擅长“图 → 文”,但不擅长“听指令 → 理解 → 回答”
- LLM(如 Vicuna / ChatGPT)极强的指令对齐能力,但完全看不见图像
LLaVA 的成功不在于“更复杂的视觉-语言架构”,而在于证明了:当一个强对齐的 LLM 被正确地“教会看图”,多模态智能会自然涌现。
5.2.方法
LLaVA = 冻结视觉模型 + 冻结/微调 LLM + 极简视觉投影(直接将视觉特征拼接在文本特征后) + 强指令微调
- “图像已经被翻译成语言能理解的 token,LLM 并不知道谁是图、谁是字”
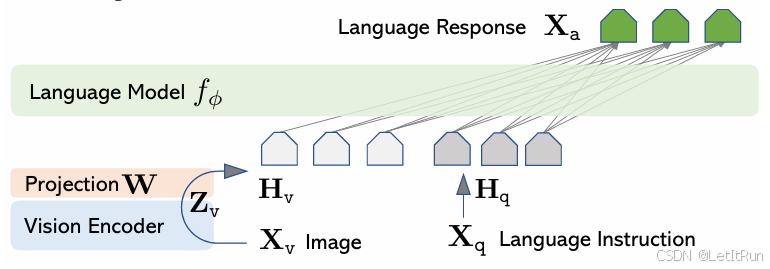
- Vision Encoder(图左下,Xv → Zv):
- 使用:CLIP ViT-L/14,完全冻结
- 输出图像 patch 特征 Zv=g(Xv)
- 设计含义:LLaVA 不再训练视觉模型,而是假设 CLIP 已经学会“视觉概念”。
- Projection W(关键但“刻意简单”):
- W 是一个线性层 Hv=W⋅Zv
- 把视觉特征投到 LLM 的词向量空间
- 输出:一串“看起来像 token 的视觉 embedding”
- 论文原话:更复杂的连接方式(如 Flamingo / BLIP-2)是可行的,但我们刻意选择简单方案,以便聚焦“视觉指令微调”的效果。
- Language Model $f_\phi$(图上方):
- 使用:Vicuna(LLaMA 指令微调版)
- 输入:视觉 token Hv 和 语言指令 token Hq
- 输出:语言响应 Xa
- 视觉 token 与文本 token 在同一个 Transformer 序列中,LLM 用 因果自注意力,视觉 token 相当于“上下文前缀”
- 这就是:视觉信息被“塞进”语言模型,而不是语言去 cross-attend 图像。即大多数多模态方法:语言 token 去 cross-attend 图像特征;LLaVA:把图像特征 当成语言 token 的一部分拼接进来,然后只用 语言模型自己的自注意力。Self-Attention over all tokens
- 两阶段训练:
- Stage 1:视觉–语言对齐(冻结 Vision Encoder、冻结 LLM、只训练 Projection W),把视觉 token 调到 LLM 能“自然理解”的 embedding 空间。
- Stage 2:视觉指令微调(Vision Encoder 冻结、LLM + W 一起微调),学会“在有图的前提下,遵循复杂语言指令”
除结构外,论文最核心贡献是:第一次系统性地把“instruction tuning”引入视觉-语言领域(指令数据集)。数据怎么来?
- GPT-4 / ChatGPT
- 输入:
- captions
- bounding boxes(文本形式)
- 输出三类数据:
- 多轮对话(conversation)
- 详细描述(description)
- 复杂推理(reasoning)
这是一种跨模态 teacher–student 蒸馏。
5.3.LLaVA 相对 BLIP-2 的区别
|
维度 |
BLIP-2 |
LLaVA |
|---|---|---|
|
目标 |
图文生成 / VQA |
通用视觉助理 |
|
连接方式 |
Q-Former |
线性投影 |
|
核心创新 |
架构设计 |
视觉指令微调 |
|
数据 |
图文对 |
图 + 指令 + 推理 |
|
行为 |
描述图片 |
遵循指令回答 |
6.Qwen-VL
6.1.Qwen-VL
原文链接:[2309.16609] Qwen Technical Report
6.1.1.动机
Qwen-VL 的动机不是追求复杂的多模态结构,而是让一个已经“会思考、会对话”的语言模型,自然地获得视觉感知能力,并服务于真实场景。
6.1.2.方法

Qwen-VL 模型的整体网络架构包括以下三个组件:
- 大型语言模型(Large Language Model):
- 作用:作为Qwen-VL模型的基础组件,这个部分采用了一个大型语言模型,其初始权重来自于预训练的Qwen-7B模型。
- 来源:Qwen-VL的大型语言模型使用了来自Qwen-7B模型的预训练权重。
- 视觉编码器(Visual Encoder):
- 作用:视觉编码器采用了Vision Transformer(ViT)架构,用于处理输入图像并生成一组图像特征。在训练和推理过程中,将输入图像调整到特定的分辨率,然后通过将图像分割成大小为14的图块来处理它们,生成图像特征。
- 来源:视觉编码器的架构和预训练权重来自于Openclip的ViT-bigG模型。
- 位置感知的视觉-语言适配器(Position-aware Vision-Language Adapter):
- 作用:为了缓解由于长图像特征序列而产生的效率问题(ViT 输出的特征序列太长,例如,在 448x448 分辨率下,2D 图像会被切成 (448/14)x(448/14) = 32x32 = 1024 个 patch),Qwen-VL 引入了一个视觉-语言适配器,用于压缩图像特征。适配器包括一个单层的交叉注意力模块,随机初始化。
- 此模块使用一组可训练的向量(嵌入)作为查询向量,使用来自视觉编码器的图像特征作为交叉注意力操作的键。
- 充当视觉编码器(眼睛)和语言模型(大脑)之间的“翻译员”和“信息压缩器”。
- 这个机制将视觉特征序列压缩到固定长度的256。
- 来源:适配器的初始化是随机的。
- 作用:为了缓解由于长图像特征序列而产生的效率问题(ViT 输出的特征序列太长,例如,在 448x448 分辨率下,2D 图像会被切成 (448/14)x(448/14) = 32x32 = 1024 个 patch),Qwen-VL 引入了一个视觉-语言适配器,用于压缩图像特征。适配器包括一个单层的交叉注意力模块,随机初始化。
这三个组件共同构成了Qwen-VL模型的整体网络架构,实现了对图像和文本的综合理解与处理。
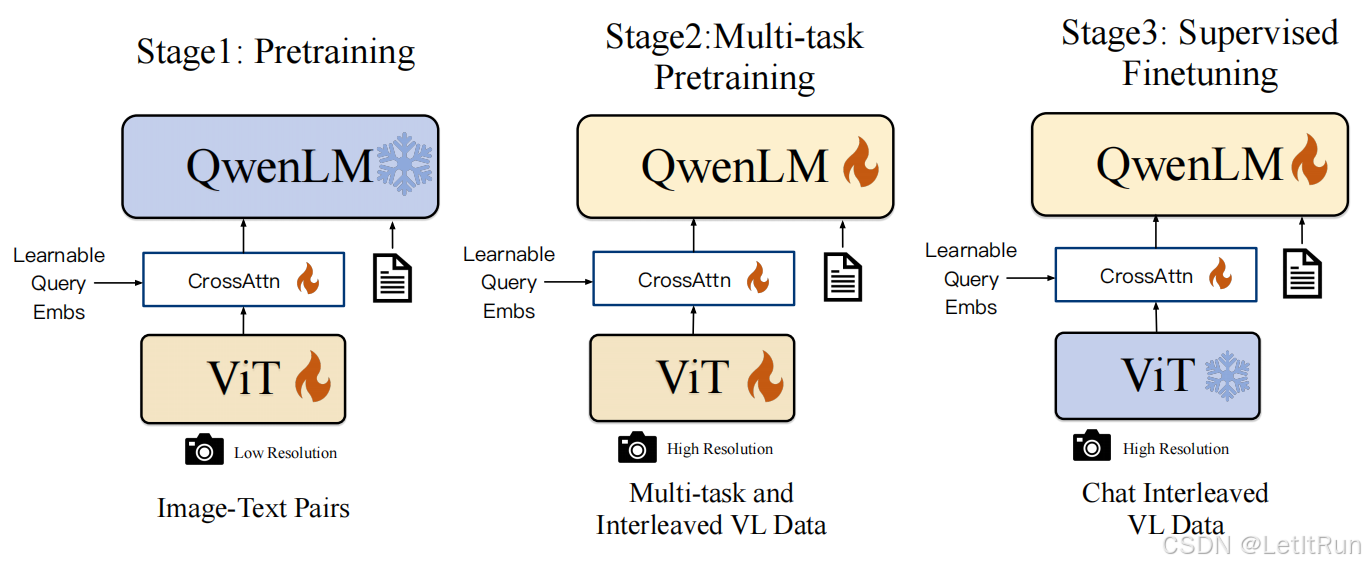
- Stage1 为预训练,目标是使用大量的图文Pair对数据对齐视觉模块和LLM的特征,这个阶段冻结LLM模块的参数;
- Stage2 为多任务预训练,使用更高质量的图文多任务数据(主要来源自开源VL任务,部分自建数据集),更高的图片像素输入,全参数训练;
- Stage3 为指令微调阶段,这个阶段冻结视觉Encoder模块,使用的数据主要来自大模型Self-Instruction方式自动生成,目标是提升模型的指令遵循和多轮对话能力。
Qwen-VL 的方法在结构层面与 BLIP / BLIP-2 思路高度一致,并没有提出全新的多模态基础模块;它的贡献重点不在“新架构”,而在“工程整合 + 数据与任务取向”。其主要贡献在于:
- 以 LLM 为中心的多模态设计:明确假设“语言模型才是智能来源”,视觉模块只负责把信息“送进去”,而不是主导推理
- 强调文档 / OCR / 图文混合场景
- 工程与数据驱动,而非结构驱动
6.2.Qwen2-VL
这是第一代成熟多模态 Qwen。
6.2.1.动机
上一代(Qwen-VL)主要问题集中在三个“结构性瓶颈”:
- 固定分辨率(Fixed Resolution)是 LVLM 的根本缺陷,现有 LVLM 普遍将图像强行编码为固定分辨率(如 224×224),通过 resize / padding / downsample 来“对齐接口”。这带来三个后果:
- 高分辨率图像信息被不可逆地丢失(文档、公式、OCR、细粒度区域 → 直接受损)
- 尺度不敏感(该看整体还是看细节)
- token 利用效率极低(小图浪费 token,大图信息不够)
- 1D Position Embedding 无法描述真实世界的空间与时间(文本是 1D sequence、图像是 2D 空间、视频是 2D + 时间(3D)),这直接导致:
- 空间位置关系建模能力不足
- 视频时间结构弱
- 长视频 extrapolation 极差
- Image / Video 被当作“不同模态”而不是“同一现实的不同切片”,现实世界是连续的三维时空,image 应是 video 的一个特例。
基础补充:
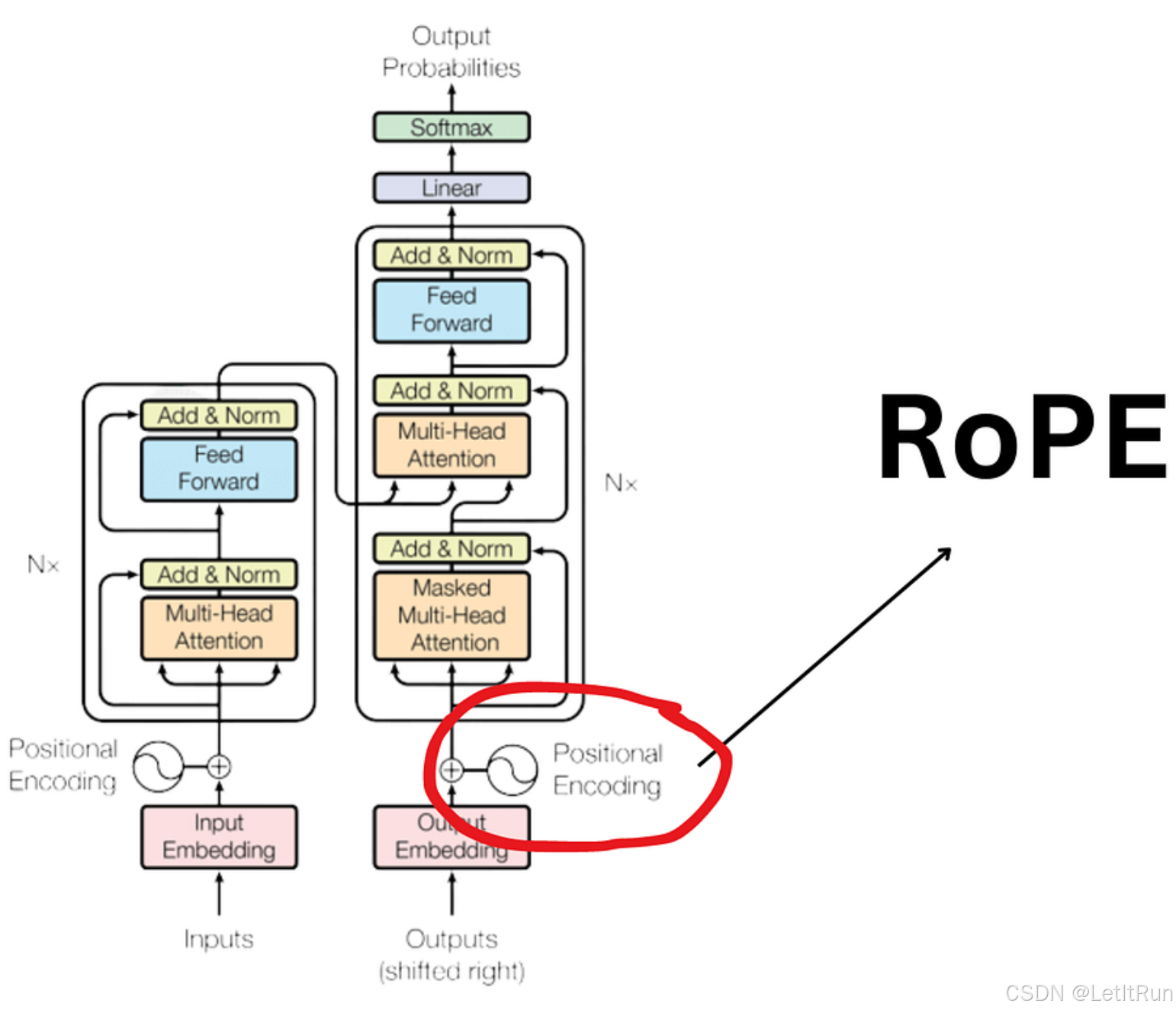
RoPE(Rotary Position Embedding,旋转位置编码):是一种把“位置信息”直接注入到 Transformer 的注意力计算里的方法,通过对 Query / Key 向量做旋转,让模型“天然感知相对位置”。不是加在 embedding 上,而是作用在 Q/K 上。
6.2.2.方法
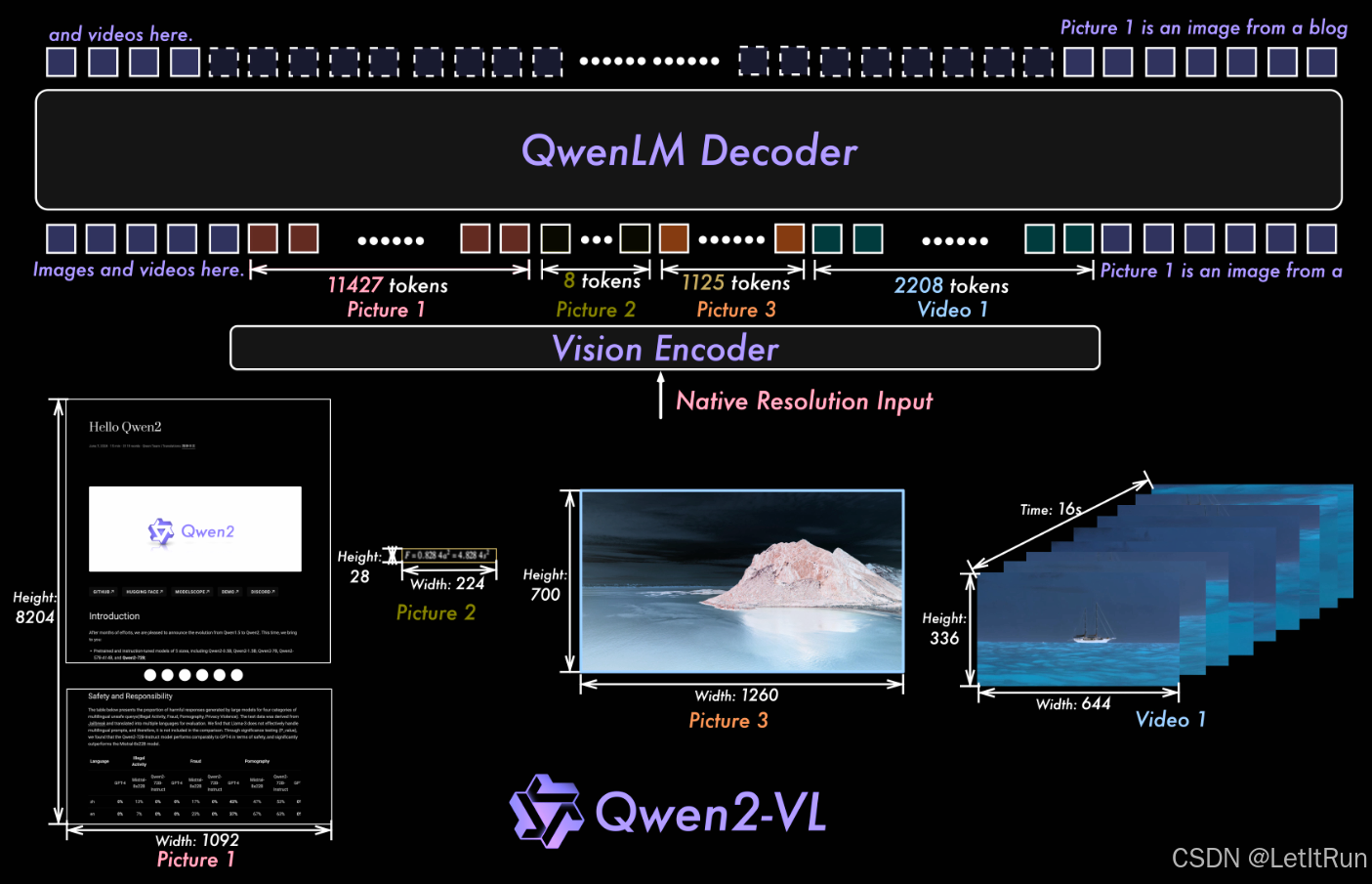
-
Vision Encoder(底部):
-
675M 参数 ViT,统一用于 image & video
-
Naive Dynamic Resolution(动态分辨率 token 化,移除 ViT 中的绝对位置编码、引入 2D Rotary Position Embedding(RoPE-2D)、图像 → 任意分辨率 → 可变数量视觉 token、2×2 token 压缩(MLP merge)、控制总 token 上限(推理时 pack))
-
核心思想:完全保留原始图像分辨率与长宽比,根据图像实际尺寸动态生成不同数量的视觉 token。
-
关键修改:完全移除 ViT 原有的绝对位置嵌入(Absolute Position Embeddings),代之以 2D 旋转位置编码(2D-RoPE)
-
-
使用RoPE-2D、3D Conv(视频)、动态 resolution
-
RoPE-2D(二维 RoPE):将位置编码分解为水平(x)和垂直(y)两个独立维度,并通过旋转矩阵实现空间关系建模

-
-
关键点:ViT 大小不随 LLM scale 改变 → 2B / 7B / 72B 视觉能力结构一致
-
-
Token Packing & Compression(中间):
-
不同图片 / 视频帧
-
不同分辨率
-
统一 pack 成一个 sequence
-
用
<|vision_start|>/<|vision_end|>包裹
-
-
Qwen2 LLM Decoder(顶部):
-
纯 decoder-only Transformer
-
使用 M-RoPE:
-
将 Rotary Position Embedding 拆解为 三维坐标系:Temporal (t)、Height (h)、Width (w)
-
效果:空间关系建模显式化、位置 ID 绝对值更小 → 更强的长度外推能力,这正是为什么:Qwen2-VL 在 长视频(80k token 推理) 上不崩。
-
-
所有模态 token 统一进入自注意力(没有 cross-attention,视觉 token = 语言 token = 同一序列)
-

M-RoPE 示意:
|
模态 |
t |
h |
w |
|---|---|---|---|
|
Text |
同一 position id |
同 |
同 |
|
Image |
固定 |
行坐标 |
列坐标 |
|
Video |
frame index |
行 |
列 |
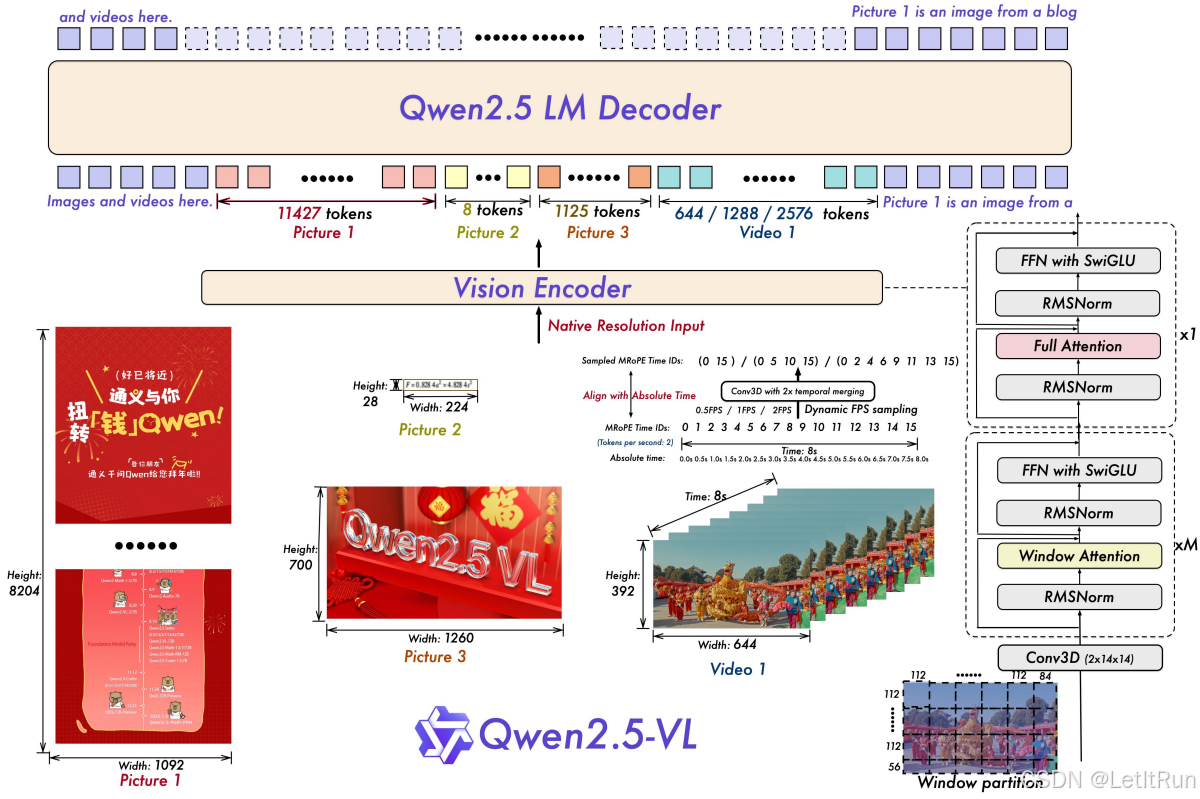
6.3.Qwen2.5-VL
架构相对 Qwen2-VL基本不变,引入了RLHF(仅用于对齐阶段)。
- 空间上:原生分辨率 + 绝对坐标
- 时间上:绝对时间对齐的 MRoPE
- 效率上:Window Attention + Patch Merger
- 能力上:文档、视频、Agent 的统一建模
后训练:SFT + DPO 的双阶段对齐
6.4.Qwen3-VL
6.4.1.动机
- 现有 LVLM 在“复杂视觉推理任务”上仍显不足
- 多模态模型需要“对齐到通用推理模型”的能力范式
- 统一支持更广泛的视觉-语言-视频任务谱系
6.4.2.方法
Qwen3-VL 并没有推翻 Qwen2-VL 的核心感知设计,延续了经典的三模块设计,这种设计思路的核心目标是:在不破坏语言模型能力的前提下,让视觉信息尽可能“自然”地融入语言建模过程。
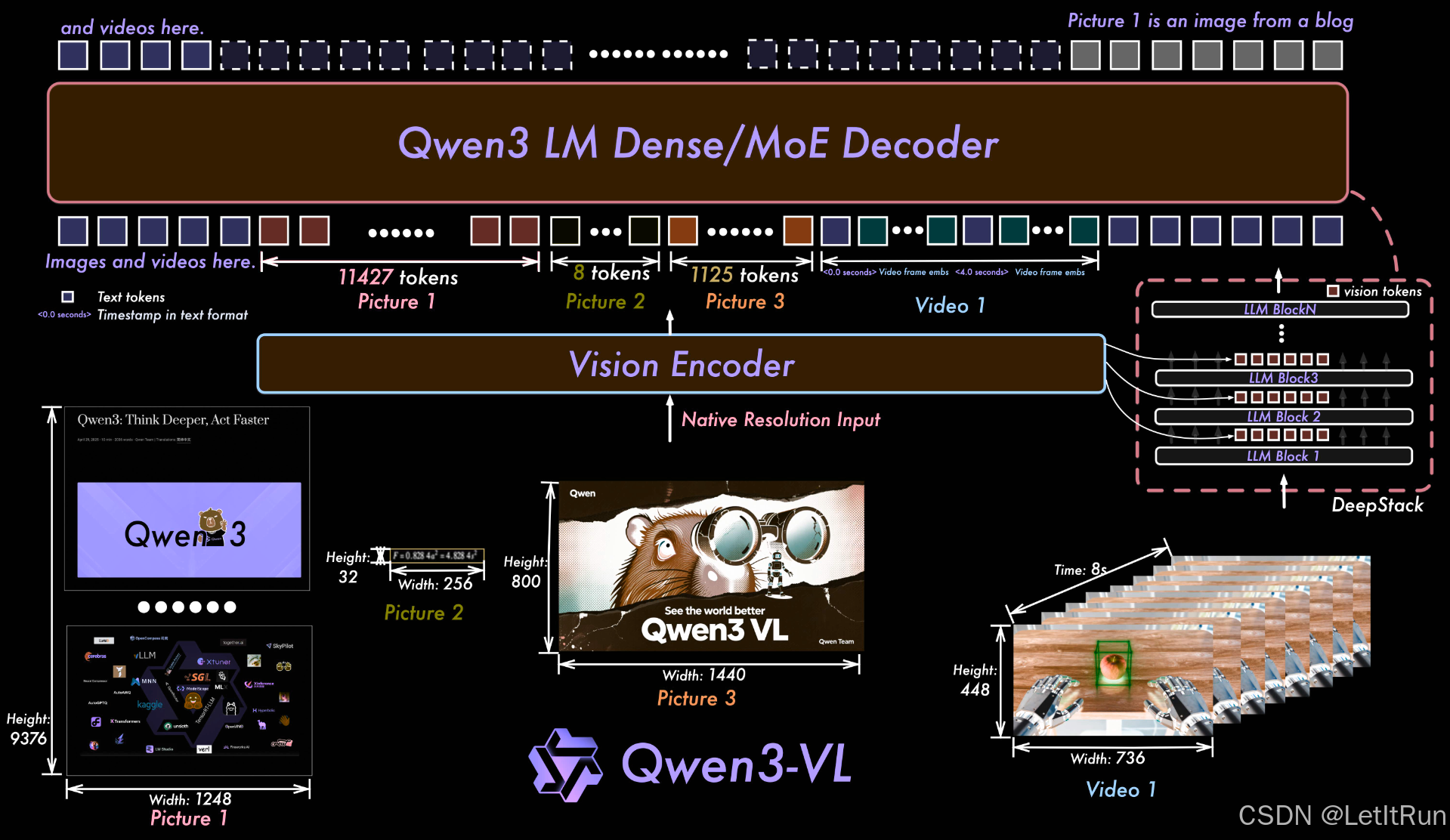
- 继承并稳定化 Qwen2-VL 的时空感知框架
- 以“推理能力”为核心的多模态训练范式(这是 Qwen3-VL 的方法学重心)
- 多阶段训练(reasoning-oriented multimodal data、long-context video reasoning),强调多步推理和中间推理一致性
- 更系统的任务对齐(这说明其方法不是“看得更清楚”,而是“想得更久、更深”)
- 架构图右侧中部的DeepStack 并不是一个独立的模型结构、算法模块或额外网络。它表达的是多层 LLM block 对视觉 token 的“逐层反复处理”,视觉信息会在多层中被反复组合、抽象、推理。
Qwen3-VL 如何提升复杂视觉推理?不是靠结构,而是靠 训练侧:
- 更多 reasoning-oriented multimodal data
- 长时序视频推理任务
- 多步骤、多中间状态的监督
- 对“推理一致性”的强调
在 Qwen3-VL 中,后训练不是单一阶段的微调,而是一套分阶段、分目标、层层递进的系统工程。整体流程可以概括为三个核心阶段:
- 监督微调(SFT):学会“按指令做事”
- 强到弱蒸馏(Strong-to-Weak Distillation):学会“怎么推理”
- 强化学习(RL):学会“做得更好、做得更像人”,使用SAPO算法。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)