论文阅读:Scaling laws for neural language models
为了实现计算效率最优,应当优先训练非常大的模型,并在模型远未收敛时就提早停止训练,因为大模型具有更高的样本效率,即达到同样的性能只需更少的数据。顺带一提,在极大的计算量下计算最优策略与过拟合避免规律会发生冲突,作者推测这可能暗示了语言模型性能的某种根本极限,或者标度律在此之前会失效。,其中第一项代表在无限时间训练下的最终收敛损失,仅受模型规模限制,第二项代表由于训练未完成(有限步数)带来的额外损失
Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models[J]. arXiv preprint arXiv:2001.08361, 2020.
确立核心前提与变量
文章首先确立了研究对象为Transformer架构的语言模型,并定义了影响性能(以交叉熵损失衡量)的三个主要尺度因子:模型规模 (N):非嵌入参数的数量;数据集大小 (D):训练用的Token数量 ;计算量 (C):训练所消耗的浮点运算次数。
排除干扰因素:架构无关性
在深入研究尺度因子之前,文章先排除了模型形状(如层数、宽度、注意力头数)对性能的显著影响。研究发现,只要总参数量(N)固定,模型具体的架构超参数对性能的影响非常微弱。
建立单变量的幂律关系
令L为测试集上的交叉熵损失,语言模型的性能与上述三个核心变量分别呈现出精确的幂律关系,且这一趋势在超过六个数量级的范围内都成立,当不受其他两个因素制约时,性能L与尺度因子X(N, D, C之一)遵循以下通用的幂律形式:,具体公式中的数值可以在下面的图表中看到。
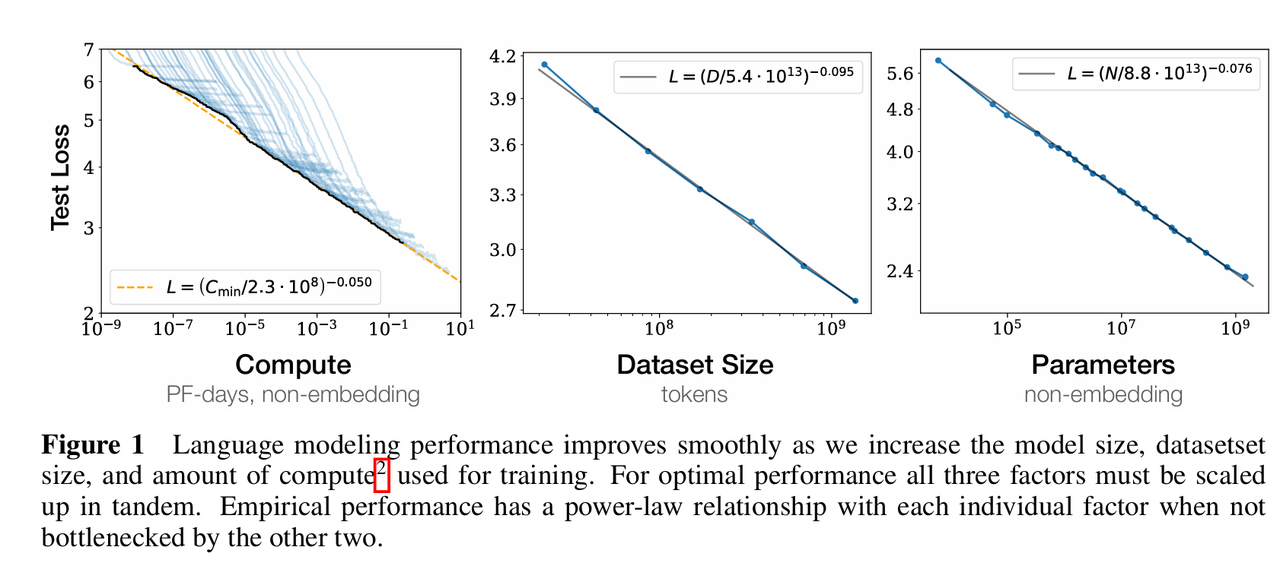
构建联合变量的标度律
为了描述当N和D同时变化时的损失,推导出了一个新的公式:,这个公式表明,模型性能的瓶颈是由模型规模项和数据规模项共同决定的
该部分的一个关键发现是关于过拟合的普适性,研究发现,过拟合的程度(即有限数据下的损失与无限数据极限下的损失之差)主要取决于这一比率,为了保持相同的性能且避免过拟合,数据集大小不需要与模型参数成线性比例增长,而是呈次线性关系,具体而言,为了避免过拟合,数据量应满足以下关系:
,这表明每当模型参数量增加 8 倍,数据量只需增加约 5 倍即可避免过拟合。
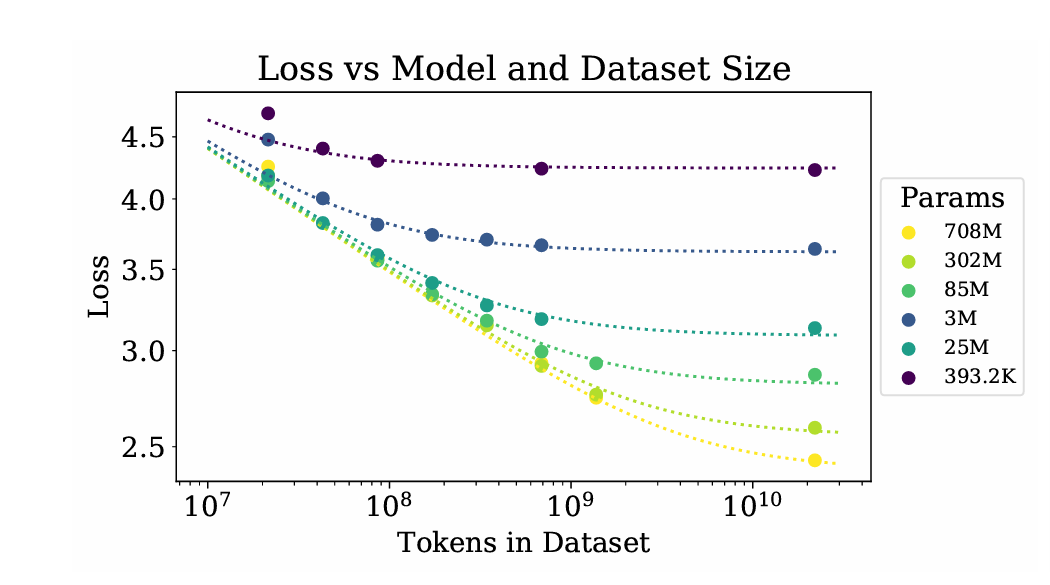
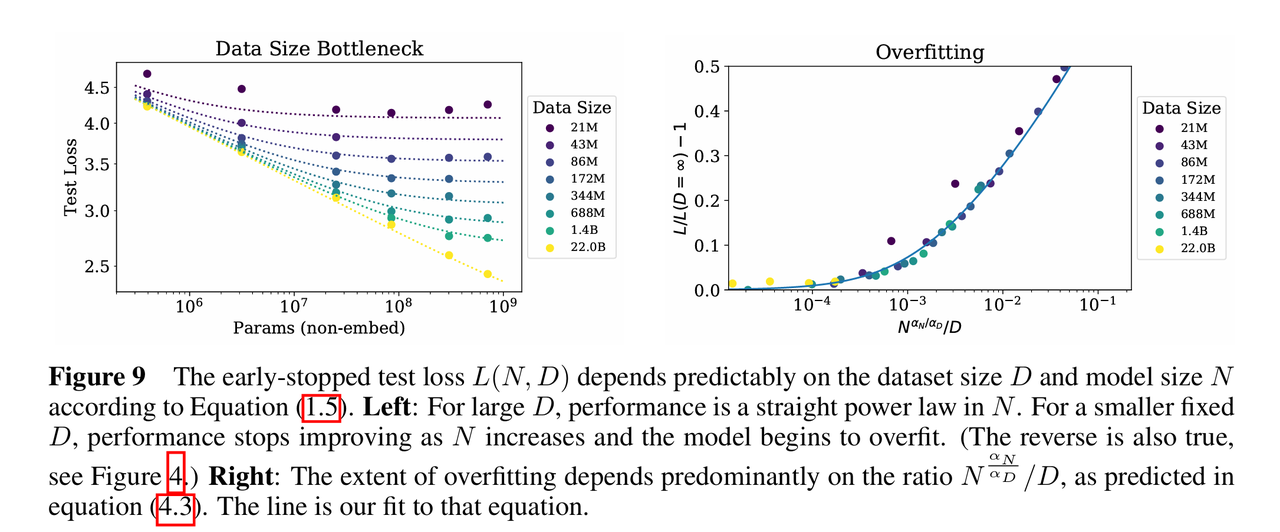
引入训练动力学与时间维度
主要解决了一个关键问题:如何量化训练时间(步数)对模型性能的影响,并将其与模型规模的影响整合到一个统一的公式中。
文章首先指出存在一个临界批量大小,当B小于这个东西的时候增加批量大小可以线性减少训练步数,计算效率最高;大于这个东西的时候增加批量大小带来的收益递减。此外,
不直接取决于模型大小,而是取决于当前的损失值,随着模型性能提升(损失降低),临界批量大小会变大。
为了统一衡量训练进度,文章定义了,即“如果以远大于
的批量大小训练时所需的最小优化步数,具体公式可写为:
,其中S/B为实际训练的步数/batch大小。基于这个东西,文章提出了模型损失随模型参数量和训练程度变化的联合幂律公式:
,其中第一项代表在无限时间训练下的最终收敛损失,仅受模型规模限制,第二项代表由于训练未完成(有限步数)带来的额外损失惩罚。核心思想就是:总损失 = 模型容量限制产生的损失 + 训练不足产生的损失
这一部分还利用上述关系推导了在数据受限情况下,应该在何时停止训练的下界:$$L(N, S)$$描述了无限数据下的训练曲线,当实际训练损失偏离这条理想曲线时,就意味着开始过拟合,早停(终止训练)步数的估算如下:(里面没有出现过的东西都是常量)
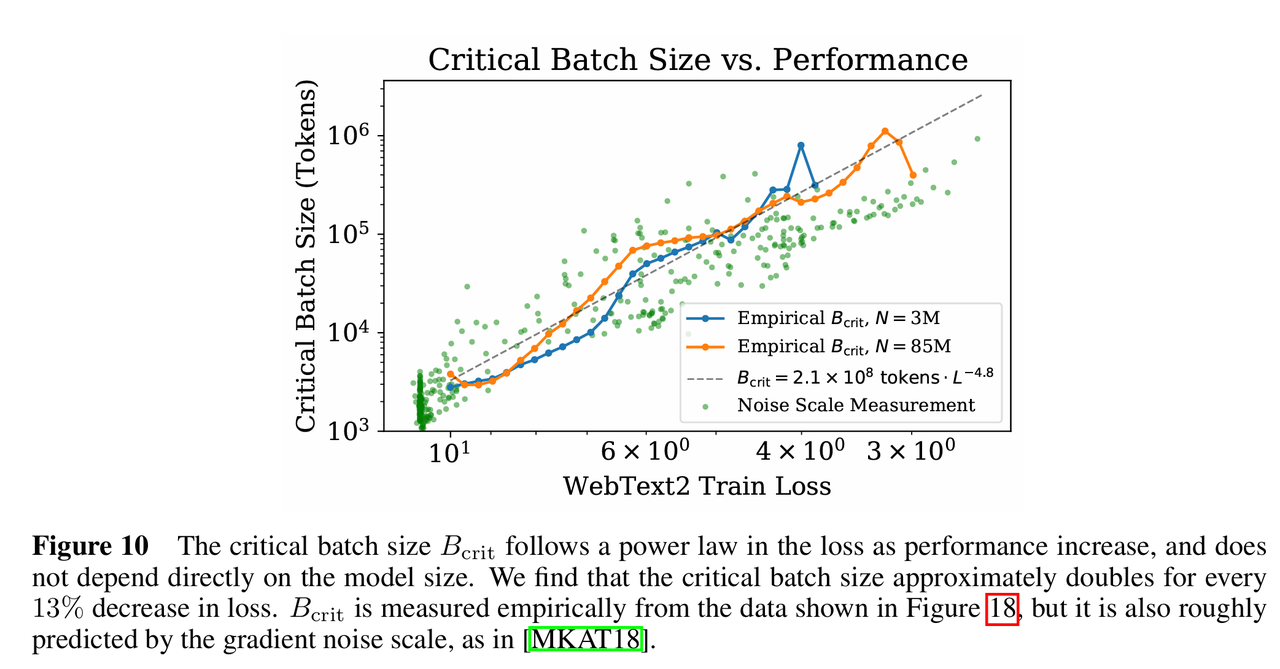
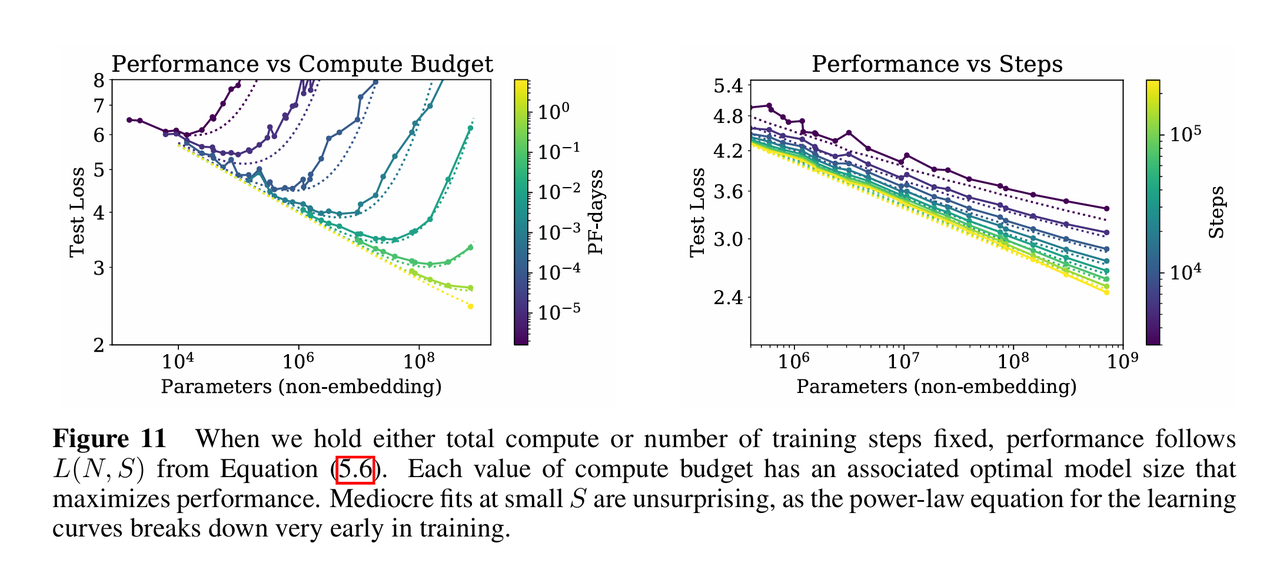
综合推导:最优计算分配
为了实现计算效率最优,应当优先训练非常大的模型,并在模型远未收敛时就提早停止训练,因为大模型具有更高的样本效率,即达到同样的性能只需更少的数据。
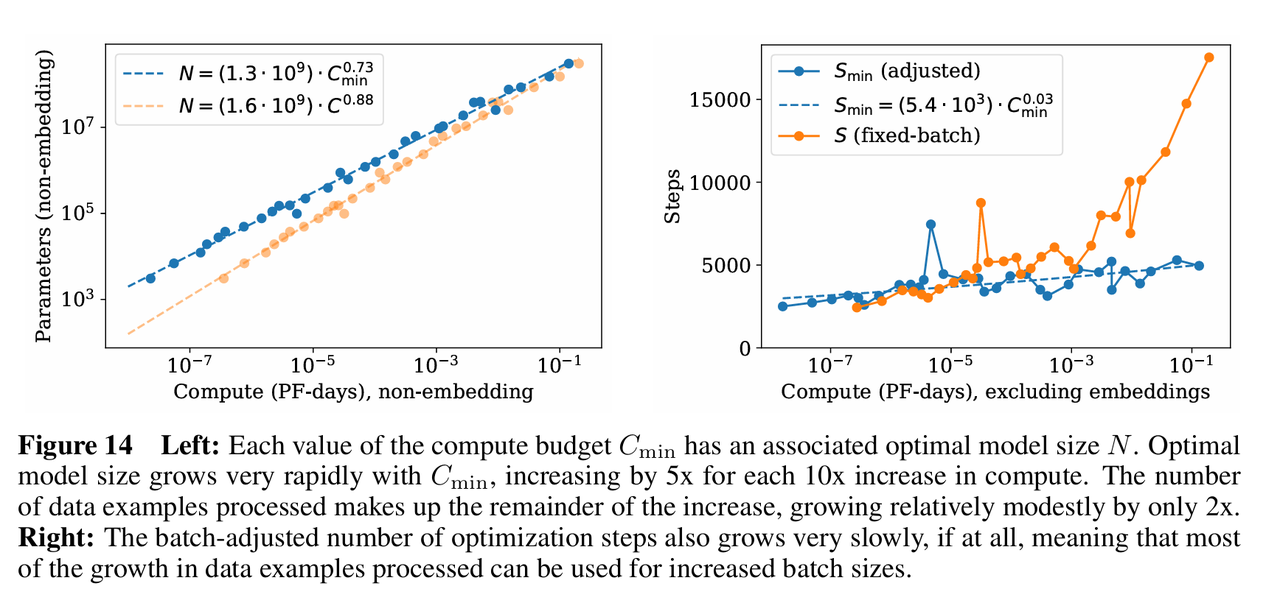
文章通过经验数据和理论推导,给出了具体的分配比例。当计算预算增加时,各要素应按以下幂律增长,其中最优模型大小增长极快,约占总预算增长的 73%(
,这意味着每当计算预算增加 10 倍,模型参数量应该增加 5 倍以上);最优批量大小适度增长(24%);最优训练步数增长极慢,几乎不变(3%)。意味着无论你有多少算力,最优的训练迭代次数(串行步数)几乎不需要增加,算力的增加主要通过并行处理更大的 Batch 和更大的模型来消耗。
顺带一提,在极大的计算量下计算最优策略与过拟合避免规律会发生冲突,作者推测这可能暗示了语言模型性能的某种根本极限,或者标度律在此之前会失效。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)