Agent开发实战:从“手搓代码”到“光速搭建”——Coze、Dify、n8n 低代码平台深度解析与实战指南
Coze 的一个插件可能封装了 5 次 LLM 调用。你只看到了结果,没看到中间消耗了多少 Token。等月底账单出来时,你会发现低代码的 Token 消耗往往比纯代码高出 30%-50%。因为它是通用的,它不能像你写代码那样进行极致的优化。我们还需要学编程吗?答案是肯定的,而且比以往更重要。低代码平台并没有消灭编程,它只是消灭了重复造轮子。它把 API 调用、数据库连接这些基础工作变成了“基础设
核心摘要:本文不讲空洞的理论,只讲实战。作为一名习惯了 Python 编写
class ReActAgent的开发者,我曾对“低代码”嗤之以鼻。但当我在 Coze 上用 15 分钟搭出一个原本需要两天开发量的“多源信息聚合简报机器人”时,我意识到:Agent 时代的“Hello World”变了。本文将带你像搭乐高一样拆解Coze(扣子)、像架构师一样驾驭Dify、像管道工一样玩转n8n。我们将深入剖析每个平台的底层逻辑、适用场景,并直面开发中的“肮脏真相”——那些文档里不写、只有踩坑后才知道的经验。
引言:为什么我们不再从零写 class Agent?
还记得我们刚学编程时,写下第一行 print("Hello World") 的激动吗?在 Agent 开发的早期(大约 2023 年),我们的“Hello World”是手写一个 While 循环,里面放一个 LLM 调用,再手动根据正则解析结果来调用工具。
那感觉就像是开手动挡汽车。
你需要关注离合器(Prompt 的格式)、挂档(工具调用的解析)、油门(API 令牌管理),稍有不慎就熄火(JSON 解析错误)。虽然这让你深刻理解了内燃机原理(ReAct 范式),但在早晚高峰的堵车路段(复杂的企业级业务流),手动挡简直是折磨。
低代码平台(Low Code Platform)就是 Agent 时代的“自动驾驶”。
现在的你,不再需要关心如何解析 JSON,不需要关心如何手动维护对话历史列表(Memory List),也不需要写 100 行代码去封装一个 Google Search 工具。你只需要坐在驾驶座上,告诉车机:“我要去上海”。
但请注意,“自动驾驶”不代表你可以睡觉。相反,你从**“司机”变成了“领航员”**。你的核心技能不再是“换挡”,而是“路线规划”。如果路线规划错误(业务逻辑混乱),自动驾驶会以更快的速度把你带进沟里。
本文的目标,就是教你如何做一个合格的 Agent 领航员。我们将忽略那些学术上的“认知架构”定义,直接进入泥泞的现实战场,用三个真实案例,带你领略三个不同维度的低代码世界。
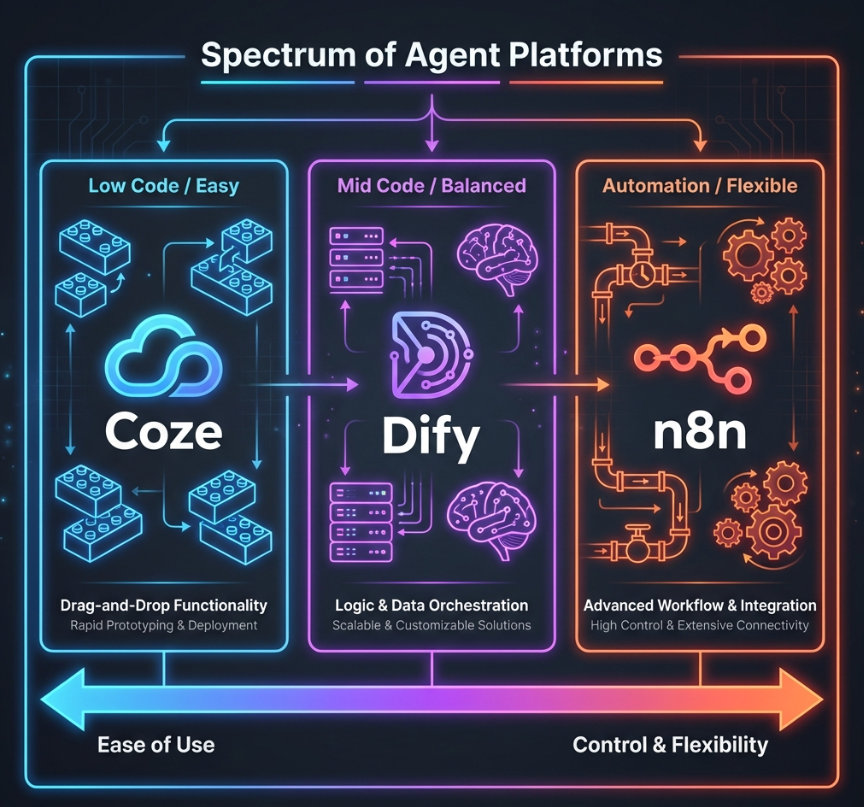
图 1:Agent 平台的“光谱”。从构建“乐高积木”的 Coze,到兼顾灵活与架构的 Dify,再到极客最爱的“管道工厂” n8n。越向右,你的控制力越强,但上手难度也越大。
第一部分:Coze(扣子)—— 产品经理的“乐高乐园”
如果把搭建 Agent 比作盖房子,Coze 就是精装修的预制房。你不需要懂水泥配比(API 鉴权),也不需要画施工图(复杂的代码架构),所有的家具(插件)都是现成的,你只需要拖拽摆放。
Coze 是目前国内最大的 C 端 Agent 平台,它最大的特点是**“插件即技能”和“发布即运营”**。
1.1 实战案例:打造“每日 AI 简报助手”
我们将构建一个名为“AI 情报局长”的智能体。它的任务每天早上自动搜罗全网 AI 资讯,去伪存真,生成一份高质量简报。这个需求看似简单,用 Python 写可能需要处理 request 库的超时、HTML 解析的乱码、API Key 的管理……但在 Coze 里,这只是几块积木的拼接。
1.1.1 “信息源”的秘密:不仅仅是 RSS
在 Coze 中,我们首先需要为 Agent 装上“眼睛”。
我们添加了 RSS 订阅插件。
🔍 老师带你看细节:
别小看这个 RSS 插件。当你拖入一个 RSS 插件时,Coze 在后台不仅仅是做了一个 HTTP GET 请求。它其实帮你封装了一个微服务。假设你想监控 36Kr。你配置了链接
https://www.36kr.com/feed。
在纯代码模式下,你需要处理 XML 解析。但在 Coze 里,这个节点输出的直接就是标准化的 JSON 对象:[{ "title": "...", "link": "...", "summary": "..." }]。
这里的核心价值是“数据标准化”。Coze 的插件层屏蔽了不同源(RSS、API、网页)的数据异构性,丢给 LLM 的都是清洗过的“净菜”。
除了 RSS,我们还需要 GitHub 和 ArXiv 插件。
这三个插件代表了三种不同的数据形态:
- RSS:结构化最好的流式数据。
- GitHub:通过 API 获取的半结构化代码元数据。
- ArXiv:学术搜索,高密度的非结构化长文本摘要。
把这三者塞进同一个 bot,就像把西餐、中餐和日料放在一个桌子上,如何让 LLM 吃得消?这就涉及到下一步:Prompt 工程的代码化。
1.1.2 Prompt:不仅仅是说话,是“自然语言编程”
很多人写 Prompt 像写作文,这是错的。**在 Agent 开发中,Prompt 就是代码(Prompt as Code)。**你需要用结构化的思维来写 Prompt。
看看我们为“AI 情报局长”设计的 System Prompt:
# Role
你是一位资深且权威的科技媒体编辑...
# Workflow (这是关键!)
1. **数据清洗**:接收 `{{rss_news}}`, `{{github_trending}}`, `{{arxiv_paper}}` 三个变量。
2. **去重与过滤**:
- 剔除含有“广告”、“推广”关键词的条目。
- 同一事件若有多个来源,保留信息量最大的一个。
3. **内容重组**:
- **板块一:🚀 产业大事件**(来自 RSS)
- **板块二:💻 极客最爱**(来自 GitHub,必须包含 Star 数变化)
- **板块三:🎓 前沿学术**(来自 ArXiv,用通俗语言解释 Abstract)
4. **格式控制**:
- 每一条必须带原始链接。
- 这里的“Emoji”不是为了好玩,而是**作为视觉锚点**,帮助用户快速扫描。
💡 老师的思考题:
为什么我在 Prompt 里特别强调“必须带原始链接”?
因为 LLM 最大的毛病是幻觉(Hallucination)。它可能会编造一个看起来很像真的链接,比如github.com/openai/gpt-5。通过强制要求引用输入变量中的 URL,我们是在做一种**“Grounding”(落地)**操作,限制 LLM 的发散能力,强迫它忠实于上下文(Context)。
1.1.3 大杀器:多渠道发布
Coze 最让开发者“爽”的一点,是它的发布管道。
你做好的这个 bot,点一下“发布”,它就可以同时出现在:
- 微信公众号(作为客服接口)
- 飞书(作为群机器人)
- 豆包(作为 C 端应用)
这意味着什么?
这意味着你的 Agent 不再是一个躺在 IDE console 里的玩具,而是一个可以直接触达用户的产品。
对于想做副业、想验证 MVP(最小可行性产品)的独立开发者来说,Coze 缩短了从“代码”到“用户”的物理距离。你不需要买服务器,不需要备案域名,不需要开发前端 UI,甚至不需要申请微信开发者认证,就能让你的朋友在微信里用上你的 AI。
1.2 Coze 的“暗面”:当你撞上天花板
虽然 Coze 很美好,但作为一名负责任的技术讲解者,我必须泼一盆冷水。Coze 是有天花板的,而且这块天花板很低。
1. 黑盒的无奈
你无法看到插件背后的具体代码。如果 RSS 插件解析某个特定格式的 feed 失败了,你除了骂娘什么都做不了。你无法 git clone 下来修个 bug 再 push 上去。在 Coze 里,你是在租赁能力,而不是拥有能力。
2. 缺失的 MCP(目前)
这一点非常关键。MCP(Model Context Protocol) 是 Anthropic 等巨头正在推行的“Agent 接口标准”。它试图统一 LLM 连接世界的方式。目前 Coze 的插件生态是封闭的(虽然很大),如果未来世界走向了 MCP 标准化,Coze 如果不跟进,就会变成一座孤岛。虽然 Roadmap 说会支持,但目前这是硬伤。
3. 调试的噩梦
当你的工作流变得极其复杂,比如有 50 个节点,充满各种 If-Else 分支时,Coze 的画布会变成一团乱麻。一旦某个中间节点报错,你很难像在 PyCharm 里那样打断点(Breakpoint),查看堆栈(Stack Trace)。你只能靠不断的“试运行”和看日志来猜。图形化编程在处理复杂逻辑时,可维护性远低于代码。
第二部分:Dify——架构师的“私人服务器”
如果说 Coze 是给产品经理用的“玩具房”,那么 Dify 就是给架构师准备的“服务器机房”。
Dify(Do It For You)的定位非常清晰:BaaS(Backend as a Service)。它不仅仅是帮你画流程图,它是要成为你所有 LLM 应用的后端。
2.1 为什么企业偏爱 Dify?
在企业级交付中,有三个“死穴”是 C 端平台(如 Coze)很难解决的,而这正是 Dify 的护城河:
- 数据隐私(Privacy):你的向量数据库放在哪里?既然 Dify 是开源的,你可以用 Docker 把它部署在公司的内网服务器上。这一条就秒杀了所有 SaaS 平台。
- 模型中立(Model Agnostic):今天 OpenAI 强,明天 Claude 强,后天 DeepSeek 便宜。Dify 允许你像换灯泡一样随意切换底层模型,甚至接入你自己微调的 local Llama 3。
- API First:Dify 创建的每一个 Bot,天生就是一个 API。你可以用它来给你的原有 APP 加功能,而不是被迫使用平台提供的前端。
2.2 实战案例:打造“超级个人助理”
在 Coze 里,我们做了一个单任务的 Bot。现在,我们要用 Dify 做一个多任务的“超级助理”。
这个助理不只是聊天,它实际上是三个“专家”的合体:
- 生活顾问:查天气、做攻略。
- 文案专家:帮你润色朋友圈、写周报。
- 数据分析师:对接 SQL 数据库,画图表。
2.2.1 核心架构:路由模式(Router Pattern)
这涉及到一个经典的 Agent 设计模式:Router(路由)。
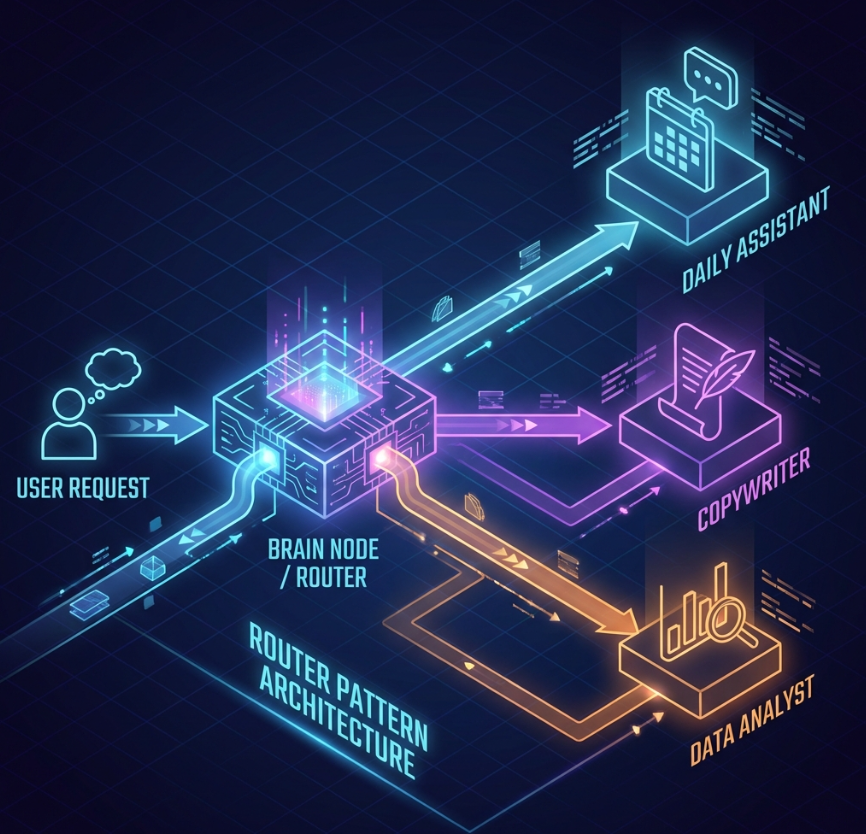
图 2:路由模式架构图。用户的请求通过中央“大脑”进行分诊,然后派发给专科医生。
在 Dify 的工作流中,我们放置一个**“问题分类器”**节点。
- 当用户问:“明天去上海穿什么?” -> 分类器识别为
Daily_Life-> 路由给 生活顾问 Agent。 - 当用户说:“把这段话改得高大上一点。” -> 分类器识别为
Copywriting-> 路由给 文案专家 Agent。
🔍 老师讲原理:
为什么要拆分?为什么不让一个大 Prompt 处理所有事?
“专才优于通才”。当 System Prompt 超过 2000 token 时,LLM 的注意力会分散(Lost in the Middle),指令遵循能力下降。
通过“路由模式”,我们将复杂的任务解耦。每个子 Agent 只需要维护自己那份短小精悍的 Prompt,这极大地提高了响应的准确度和系统的可维护性。这即使在微服务架构中,也是金科玉律。
2.2.2 黑科技:RAG 与私有知识库
Dify 的 RAG(检索增强生成)流水线是目前市面上做得最可视化的之一。
当你上传一份 PDF(比如你的公司员工手册)时,Dify 在后台默默做了四件事:
- 分块(Chunking):把长文切成 500 字符的小块。
- 清洗(Cleaning):去掉换行符、乱码。
- 嵌入(Embedding):调用 Embedding 模型(如 text-embedding-3)把文字变成向量。
- 存储(Indexing):存入向量数据库(如 Weaviate)。
当你问:“出差报销标准是多少?”时,Dify 会先去数据库里“捞”出最相关的三块碎片,拼接到你的 Prompt 后面,再发给 GPT。
这就是为什么 Dify 能回答你私有数据的原因。
2.2.3 未来的接口:MCP(Model Context Protocol)
我们在文档中提到了 MCP。这是本章必须要划重点的概念。
什么是 MCP?
以前,你的 Agent 想获取高德地图的数据,你得写代码对接高德 API。
现在,如果有了一个由社区维护的“高德 MCP Server”,你的 Dify Agent 只需要填上这个 Server 的地址,瞬间就拥有了查路线的能力。
MCP 就像是 AI 界的 USB-C 接口。
它让工具的提供方(高德、飞书、Notion)和工具的使用方(Dify, Claude Desktop)解耦了。
我们在 Dify 实战中配置了“高德 MCP”,采用了 SSE(Server-Sent Events) 模式。
这意味着,Dify 不再需要自己去轮询(Polling)数据,而是建立一条长连接,实时接收地图数据的推送。这在体验上是质的飞跃。
2.3 Dify 的“隐形坑”
作为企业级产品,Dify 也有它的痛点:
1. 性能瓶颈(Performance)
Dify 的后端是 Python 写的。虽然 Python 易于开发,但在处理高并发请求时(比如这是公司全员使用的客服机器人),Python 的GIL(全局解释器锁) 会成为噩梦。虽然可以通过 Docker 扩容,但相比于 Go 或 Java 写的网关,它的吞吐量上限较低。
2. 学习曲线
在 Coze,你随便拖拽一下就能跑。在 Dify,你得懂什么是 Top-K,什么是 Re-ranking(重排序),什么是 Temperature。它不仅考研你的 Prompt 能力,还考验你对 AI 原理的理解。它是给工程师用的,不是给小白用的。
3. API 兼容性
虽然 Dify 号称兼容 OpenAI,但它的 API 格式其实是自成一派的。如果你想把它无缝替换掉现有的 LangChain 应用,可能需要重写这部分适配层。
(未完待续… 下一部分我们将分别解析自动化神器 n8n 和最后的总结)
第三部分:n8n——极客的“自动化流水线”
如果 Coze 是乐高,Dify 是服务器,那么 n8n 就是连接整个世界的管道。
大多数人理解的 Agent 是与人聊天的 Bot。但在 n8n 里,Agent 是一个在后台默默工作的员工。它不需要前端界面,它的“界面”就是数据流。
3.1 真的需要 AI 吗?自动化 vs 智能化
很多时候,你其实不需要 AI。
比如:“每天早上 9 点把 Github 的 Star 数发到 Slack”。这根本不需要 LLM,只需要一个 HTTP Request 节点和一个 Slack 节点。这叫自动化(Automation)。
但是,如果你要:“每天早上 9 点读 Slack 里的所有未读消息,把那是‘紧急’的挑出来,并起草回复”。
这就需要 AI 了。这叫智能化 Agent。
n8n 的强大之处在于:它让你在一个画布上,同时混合使用“传统自动化”和“AI Agent”。
3.2 实战案例:打造“没人知道我是 AI 的邮件助理”
我们要构建一个系统:它自动监控你的 Gmail,当收到邮件时,它会判断这是否是在你的“非工作时间”。如果是,并且对方问的是工作问题,它会查阅你的日程表,回复说:“我在休息,但我查了一下文档,你的问题可能是这个原因…”
3.2.1 架构图:管道中的大脑
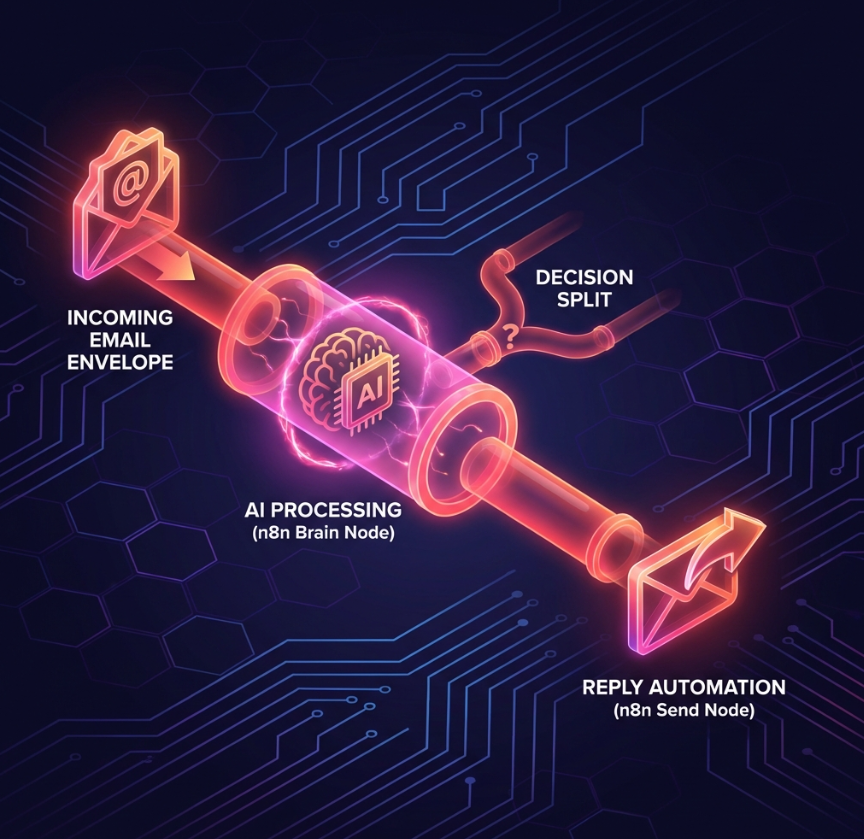
图 3:n8n 邮件处理流水线。邮件像水流一样进入管道,流经 AI 这个“过滤器”,最后变成回复流出。
在这个流程中,核心组件是 AI Agent 节点。
以往,我们需要手动构建类似 LangChain 的 ReAct 循环。但在 n8n 的新版中,AI Agent 节点把这一切都封装好了。
你只需要给它两个东西:
- Memory(记忆):连接
Window Buffer Memory,让它记住这封邮件的前因后果。 - Tools(工具):连接
Google Calendar(查日程)和Vector Store(查私有文档)。
3.2.2 向量数据库的“冷知识”
在 n8n 案例中,我们使用了 Simple Vector Store。
⚠️ 必须警告:
这个Simple Vector Store是存在内存里的!
这意味着什么?意味着如果你重启了 n8n 的 Docker 容器,或者你的电脑断电了,你的所有知识库索引都会瞬间消失。
这就是“玩具”和“生产”的区别。在此处,我们必须引入“持久化”概念。
在生产环境中,你绝不能用 Simple Vector Store。你必须换成 Pinecone 或 Qdrant 节点。这就像你写代码时,不能把用户数据只存在List变量里,必须存进 MySQL 一样。
3.2.3 Prompt:精准的时间控制
在这个案例中,Prompt 最难写的部分是时间和时区。
LLM 是没有时间观念的。你必须在 Prompt 里显式地告诉它:Current Time: {{ $now }}
而且,要处理时区问题(UTC vs local time)。稍微搞错一点,Agent 就可能在半夜三更告诉客户“我现在是工作时间”。
这也是 n8n 相比于 Dify 的优势:n8n 有着极其强大的时间处理函数库(Date & Time)。你可以在数据送进 LLM 之前,先用 n8n 的 Code 节点把时间格式化得清清楚楚。用代码解决逻辑,用 LLM 解决模糊,这才是最佳实践。
3.3 n8n 的“劝退指南”
n8n 非常强大,但也很容易“劝退”:
1. 调试极其痛苦
在 Coze 里,如果错了,你还能对着对话框调试。在 n8n 里,如果你处理的是一个 webhook 触发的流程,你需要不断地发送测试数据。当流程分支变多(几十个节点),哪怕是查看其中某一个节点的 JSON Output,都需要点好几次鼠标。它的可视化调试体验,其实不如写代码时的断点调试。
2. JSON 的诅咒
n8n 的数据流转完全依赖 JSON。你的上一级节点输出了 json.body.content,如果你在下一级节点里写成了 json.body.text,流程直接挂掉。作为“领航员”,你需要非常熟悉 JSON Path 语法。低代码不代表无代码,你必须懂数据结构。
3. 运维成本
相比于 Coze 的 SaaS 模式,n8n 通常需要你自建(Self-hosted)。这意味着你需要懂 Docker,懂 Nginx 反向代理,懂 SSL 证书配置。你不仅是开发,还是运维(DevOps)。
(未完待续… 最终章:关于低代码 Agent 的 10 个真相与总结)
第四部分:低代码 Agent 开发的 10 个“肮脏真相”
在大多数营销文章里,低代码平台是完美的。但作为一个在生产环境中摸爬滚打过的开发者,我有责任告诉你那些只有当你系统上线并在半夜三更崩溃时才会学到的“真相”。
真相 1:Demo 很简单,Production 很难
在 Coze 上用 5 分钟搭一个 Bot 是很容易的。但如果你的 Bot 需要每天处理 10,000 次请求,并且响应时间不能超过 3 秒,这完全是另一回事。低代码平台往往掩盖了并发控制、重试机制和限流等工程难题。当你遇到这些问题时,你会发现图形化界面里根本没有地方给你配置 max_retries。
真相 2:供应商锁定(Vendor Lock-in)是真实的恐惧
你在 Coze 上花了一个月精心编排的工作流,可能仅仅是一堆无法导出的 JSON 配置。如果有一天 Coze 修改了收费策略(这很常见),或者它的服务器在海外不稳定,你想迁移到 Dify 或 LangChain?对不起,重写是唯一的出路。低代码平台的迁移成本极高,这是一种隐形的“技术债务”。
真相 3:抽象是有代价的(Cost of Abstraction)
Coze 的一个插件可能封装了 5 次 LLM 调用。你只看到了结果,没看到中间消耗了多少 Token。等月底账单出来时,你会发现低代码的 Token 消耗往往比纯代码高出 30%-50%。因为它是通用的,它不能像你写代码那样进行极致的优化。
真相 4:可视化调试 = 低效调试
虽然连线看起来很直观,但当你有 100 个节点时,那张图就是著名的“意大利面条代码(Spaghetti Code)”的可视化版本。纯代码里,你可以用 IDE 的搜索功能、跳转定义。在画布上?你只能用鼠标拖来拖去,寻找那个断掉的连线。稍微复杂一点的逻辑,代码的可读性其实优于图形。
真相 5:版本控制几乎不存在
Git 是程序员的神器。你可以 git diff 看到每一行代码的变动。但在 n8n 或 Dify 里,你的工作流是一个巨大的 JSON 文件。即便你把它存进 Git,你也看不出这次提交到底改了哪根连线。团队协作开发同一个复杂工作流,很容易发生冲突且难以合并。
真相 6:数据隐私是个伪命题?
如果你使用的是 SaaS 版的 Coze 或 Dify,你的私有知识库(Vector Store)是存在别人的服务器上的。虽然大厂都承诺数据安全,但对于金融、医疗等敏感行业,物理隔离才是唯一的安全。这时候,开源且可私有部署的 Dify 和 n8n 就成了唯一选择。
真相 7:延迟是硬伤
低代码平台通常意味着多层封装和 HTTP 调用链。相比于直接在本地运行 Python 脚本,低代码工作流通常会有额外的网络延迟(Network Latency)和系统开销。对于实时性要求极高的应用,这几百毫秒可能是致命的。
真相 8:不要为了 AI 而 AI(Over-Engineering)
很多我在 Dify 上看到的工作流,其实用 10 行 Python 代码加一个正则表达式就能搞定。不要拿着锤子(Agent)找钉子。如果不涉及复杂的语义理解,传统的规则引擎往往更快、更准、更便宜。
真相 9:黑盒组件的不可维护性
当 Coze 的某个官方插件突然崩溃时,你什么都做不了。你不能修 bug,不能打补丁。你只能等官方修复。在这种时刻,你不再是工程师,你只是一个无助的用户。拥有源代码,通过开源掌控底层,是构建核心业务系统的底线。
真相 10:人机信任比技术很难
最后,无论你的 Agent 跑得再溜,让老板放心把“自动回复客户邮件”的权限交给它,通过比技术实现难 100 倍。Human-in-the-loop(人在回路) 不仅是技术设计(增加人工审核节点),更是产品设计。你必须设计出让用户“敢用”的界面,而不是仅仅追求“全自动”。
结语:做“掌控者”,不做“拼接怪”
回到我们最初的问题:我们还需要学编程吗?
答案是肯定的,而且比以往更重要。
低代码平台并没有消灭编程,它只是消灭了重复造轮子。
它把 API 调用、数据库连接这些基础工作变成了“基础设施”。
但**逻辑(Logic)**是无法被消灭的。
- 你在 Coze 里编排工作流,是在进行逻辑编程。
- 你在 Prompt 里写指令,是在进行自然语言编程。
- 你在 n8n 里写 JavaScript 处理数据,是在进行胶水编程。
未来的超级个体,一定不是只会拖拽积木的人,而是那些懂代码原理,但善用低代码工具来十倍级放大自己能力的人。
不要被平台捆绑,要驾驭平台。
先用 Python 写一遍 ReAct,理解它的痛;再用 Coze 搭一遍,享受它的快;最后用 Dify 和 n8n,构建属于你自己的、可控的数字帝国。
这就是 Agent 时代的生存法则。
关于作者
本文是基于《helloagent》第五章深度重构的实操指南。如果你觉得这篇文章对你有帮助,欢迎点赞收藏。记住,实践是检验 Agent 的唯一标准。现在,去打开 Coze/Dify/n8n,开始你的第一个 Agent 之旅吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)