|
第一阶段(L1):0基础快速入门AI大模型应用与实战
建立大模型技术的基础知识,理解核心概念,并能够实现自己的AI大模型应用 |
|
课程名称 |
主要内容 |
课程目标 |
|
01. 大模型应用开发基础 |
- AGI 时代的个人职业发展
- 个人定位
- AI产品的使用者
- AI产品的研发者
- 基础模型训练和算法
- 职业发展路径(AI大模型应用开发、AI产品经理)
- AI大模型开发的核心能力模型
- AI全栈工程师(懂业务、懂AI、懂编程)
- AI产品经理(懂业务、懂AI)
- AI大模型应用开发(懂编程、懂AI)
- AI大模型宏观能力图谱详解(找准定位)
- 了解大模型的前世今生
- AI的前世今生
- 大模型的发展与历史
- AI大模型存在的短板
- AI大模型的基本使用
- 用API实现AI大模型的调用实现一个基本的模型对话
- 用Anaconda创建虚拟环境
- 安装依赖包
- 申请APIkey
- 第一个与AI大模型的API对话
- 关于dotenv管理环境变量
- 国产大模型的介绍
- ChatGPT引发的“百模大战”
- Deepseek爆火背后的原因分析
- Qwen3发布对行业的影响
- 通用模型/思考模型基本概述
- 基座大模型的发展趋势与未来
- 大模型的落地现状与落地方向
- 从基座模型到AI大模型应用
- AI大模型落地方向
- 原生AI应用
- 大模型结合行业场景
- 企业内部AI大模型应用提效
- AI大模型会对哪些行业产生实际影响
- 如何寻找AI大模型的落地方向
- AI大模型成果落地的核心要素
- 企业内部如何选择基座AI大模型?
- AI大模型应用架构分析
- 纯Prompt
- Agent+Function Calling+MCP
- RAG
- FineTuning
- 企业内部如何选择对应的技术架构
- 需要补充知识-RAG
- 对接外部系统-MCP/Function Calling
- 大量历史数据处理-微调
- 大模型未来的发展趋势与挑战
|
了解大模型的大致发展历史、基本概念以及目前的重要性。
划重点: 这一节课的目的,是建立全局视角, 了解AI大模型能做什么、行业落地现状、大模型的工作机会、 大模型的应用架构!
目标: 让每一个零基础的普通人,彻底搞懂AI大模型的现状以及发展趋势,快速建立AI大模型的宏观认知! |
|
02.大模型核心概念和基本原理 |
- AI人工智能的发展和原理
- 学习与推理
- 数据/训练/模型/推理
- 通俗理解AI中的学习和推理的基本概念
- 从机器学习了解AI推理的基本原理
- y=ax+b 算法实现数据特征的提取
- 从数据->算法->模型-推理全流程剖析
- 案例演示房价预测:了解模型训练到模型推理
- 通俗理解AI人工智能算法的演进
- 机器学习算法
- 深度学习算法
- 神经网络的概念
- 神经网络是如何做决策的?
- 如何用神经网络实现训练和推理?
- HunggingFace获取开源数据集
- 模型训练过程分析
- 了解“参数”到底是什么?
- 用训练好的模型做推理
- AI大模型的的基本原理
- 模型是如何得到的
- 训练
- 微调
- 人类反馈强化学习
- AI大模型的发展(亿级别参数到万亿参数)
- 模型是如何”生成“文本的?
- AI大模型的一些基本概念
- 模型参数规模
- 模型上下文大小
- LLM模型与多模态模型
- MoE架构是什么意思?
- 思考模型与推理模型的区别
- 算力消耗Token是啥?怎么计算?
- Deepseek中的模型蒸馏又是啥?
- 从“决策式AI”到“生成式”AI,了解AI大模型爆火的底层原因!
|
从应用视角了解大模型中的基本概念,如机器学习神经网络、token、transformer等。
这些内容,对于初学者而言,可以快速建立一个感性的认识。
了解AI领域中的训练、推理的基本逻辑,并用最简单的数学公式搞懂AI训练和推理的基本原理
从而对AI大模型的工作机制建立一个全局的感知认识。
接着,从AI大模型的企业应用视角,了解大模型在应用领域的技术体系。
划重点:用通俗的案例和通俗的讲解,让每一个零基础的同学,都能从宏观上了解AI大模型是如何工作的! |
|
03.提示词工程(Prompt Engineering) |
- 提示工程的基本概述与发展
- 什么是提示词以及提示词工程
- 提示词是如何影响AI大模型的输出
- 提示词的重要性以及要掌握的程度
- 一个典型的结构化提示词展示
- 一个Prompt 的典型构成
- 角色/提示/上下文/样本/输入/输出
- 为什么不建议”套“模板
- 提示词该如何迭代和调优-达到期望结果
- Prompt指令调优方法论
- 角色定义
- 限制输出格式
- Few-shot
- 思维链和思维树
- 提示词进阶技巧详解
- Prompt 攻击和防范
- 攻击:Prompt越狱
- 攻击:Prompt注入
- 防范:Prompt注入分类器
- 防范:在输入中做防御
- 思考模型与通用模型提示词设计的差异
- 提示词的设计原则
- 不同基座模型对于提示词应用的差异
- 提示词的基本原理分析
- 「定义角色」为什么有效?
- 为什么提示词对基座模型的输出能产生直接影响?
- "多轮对话"的本质
- 从0到1完成一个只能客服对话机器人的Prompt构建(代码实操)
- 使用GPT模型构建一个基础对话环境
- 定义Prompt目标与用户输入
- 优化Prompt的输出格式-JSON输出
- 进一步优化Prompt,把Json输出格式定义更精细
- 加入样本提示词让模型输出更稳定
- 通过Prompt构建多轮对话
- 通过一个完整的程序串联所有流程实现智能客服助手
- 加入静态行业知识库,提高回答的话术专业度
- 如何提高Prompt提示词编写能力
- 利用第三方Prompt提示词生成器(coze/LangGPT)
- 根据输出结果不断反向优化Prompt设计
- 定义角色、给样本是常用的有效手段
|
提示词是和AI大模型交流的一种语言,掌握提示词,能够在不对模型进行微调的情况下,让模型更好的反馈结果,是一个很重要的能力。
在未来的RAG和Agent等应用场景中, Prompt提示词设计的好坏,决定了应用在实际落地过程中的呈现效果。
划重点:本次课主要从底层掌握提示词的工作原理,以及理解提示词工程的设计和优化的方法。
并对基于提示词诱导等情况做出一定的防范。 |
|
04.GPTs与Function Calling开发AI大模型应用 |
- GPTs的基本概述与实操
- 什么是GPTs
- GPTs的目标与发展现状
- 使用GPTs搭建一个AI大模型应用
- GPTs的平替产品介绍
- Coze
- Dify
- FastGPT
- RAGFlow
- N8N
- GPTs实战案例讲解
- 用GPTs实现一个小红书爆款文案生成应用
- 用GPTs完成一个流程图设计与编辑
- 用GPTs实现excel数据分析
- 如何让GPTs的应用跳出ChatGPT平台来执行
- Function Calling & Tools
- AI大模型的短板
- GPT模型提出的Function Calling
- 详解Function Calling的工作原理
- Function Calling 带来的产品想象空间
- Function Calling实战与原理分析
- 使用Function Calling实现天气预报查询
- 多Function Calling
- AI大模型是如何决策function 调用
- 从代码层面拆解整体工作流程
- Function Calling的注意事项
- Function Calling对token的消耗
- Function Calling调用的稳定性,避免错误调用带来的灾难
- AI大模型与企业内部应用结合的一些经验
- 判断合理的切入点
- 基座模型的准确率
- bad case对业务流程的影响
- 实战:Function Calling实现数据库查询
- 整体工作流程分析
- 数据库表定义与数据初始化
- 定义数据库查询Function
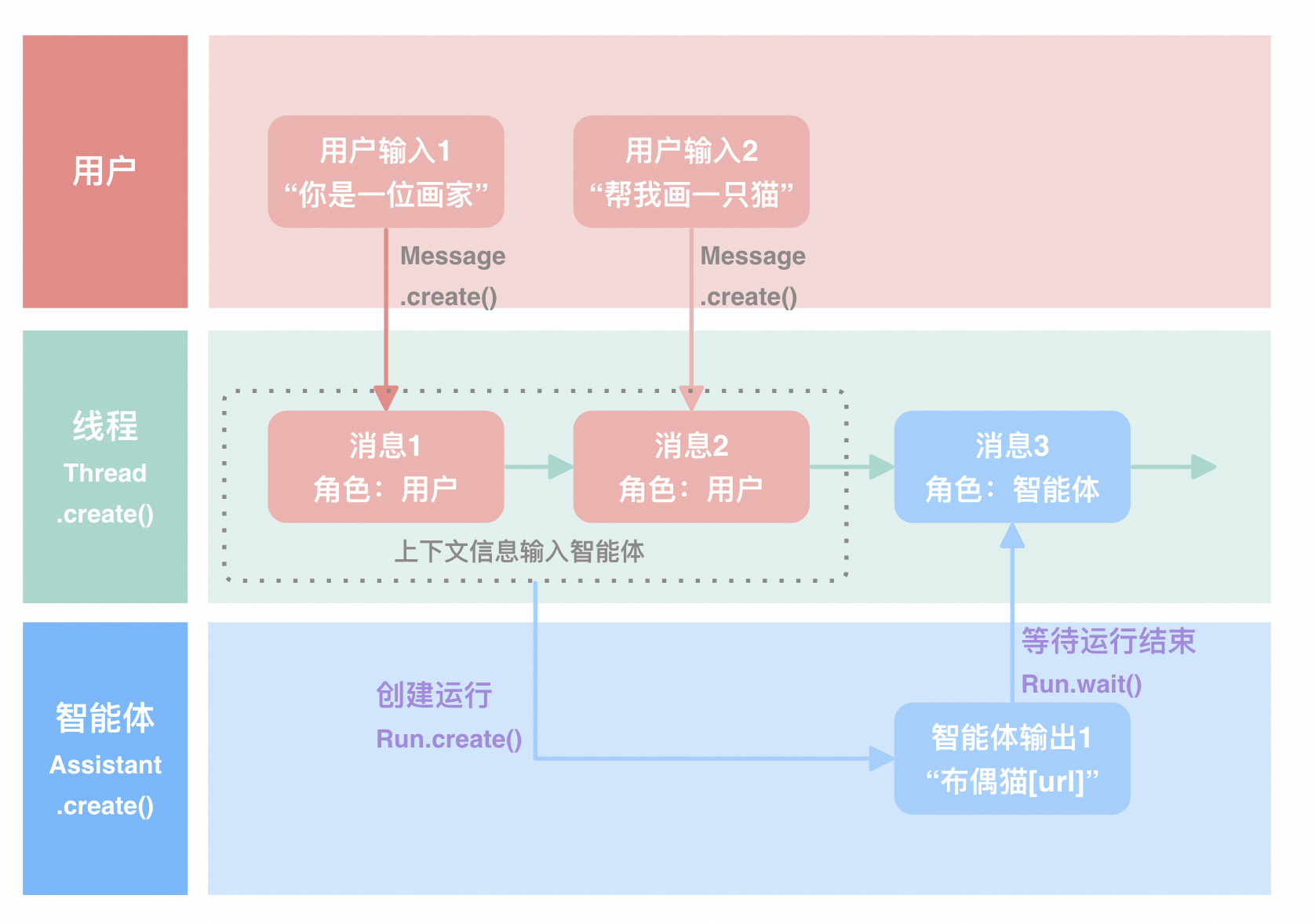
- Assistants API入门到应用实战
- Assistants API快速入门
- Assistants开发的完整操作步骤[图解]
- Assistants开发实战-绘画智能助手
- 准备开发环境
- 创建 Assistant
- 创建 Thread
- 添加 Message 到 Thread
- 创建 Run 并执行
- Assistants结合Tools实现智能翻译助手
|
从OpenAI的GPTs平台,了解基于AI大模型创建智能应用。
再基于Python语言,对接Assistant API,在本地搭建AI应用,最后引入Function Calling技术,实现模型和外部接口的对接。
让学员对大模型应用方向有一个清晰的认识!
划重点:掌握GPTs与Function Calling的概念与应用,并具备企业内部业务场景与大模型结合的实战能力 |
|
05.掌握AI编程让普通人也能开发各种技术应用 |
- 不懂编程如何用好AI工具做代码创作
- AI编程能帮我解决哪些问题?
- AI编程的使用技巧
- AI编程智能助手GitHub Copilot实战
- 商业成功分析
- 补全代码的技巧和原理
- GitHub Copilot Chat
- GitHub Copilot Extensions
- GitHub Copilot基本原理分析
- 了解Vibe Coding
- 了解Vibe Coding的基本概念
- Vibe Coding主流的工具
- Cursor
- Trae
- 同义灵码
- 集成AI编程工具
- 使用AI编程工具辅助开发实战
- 开源平替
- Ollama + Continue
- 可本机部署的 Tabby
- 开源编程大模型
- Code Llama
- DeepSeek-Coder
- Google CodeGemma
- AI编程底层模型的选择
- AI编程领域趋势
- 技术:搜索 + 训练
- 案例
- 用 AI 学 Python
- AI代码阅读
- AI代码审校
|
普通小白,想要基于python开发应用,又因为不懂代码导致开发难度大,无法快速实现自己的大模型应用。
通过代码生成工具,实现不懂代码也能写程序。
其次,养成和 AI 共处的习惯,日常体会 AI 如何提效、如何惊喜,及如何不靠谱。
最后,对主流的代码生成工具如何集成以及进行开发做一个系统化的讲解,包括底层的工作原理。
划重点: 多利用AI编程辅助开发,提高开发效率,降低开发门槛!
|
|
06.N8N快速入门到应用实战 |
- 为什么你需要n8n?破解“信息孤岛”与“重复劳动”困局
- 什么是n8n?一个“数字员工调度中心”
- n8n 的核心优势
- n8n 在AI时代的全新定位
- 本地部署n8n——掌握自动化系统的“控制中心”
- 部署方式选型指南
- 实战:Docker方式快速部署
- 关键配置说明
- 初识n8n——掌握自动化流程的“语法”与“积木”
- n8n 核心概念解析
- Workflow(工作流):自动化任务的完整流程
- Node(节点):构成流程的基本单元
- JSON Data Structure:节点间传递的数据格式
- 界面导览与操作入门(画布区、节点库、调试面板、执行历史)
- 四大核心节点类型详解
- Trigger Nodes(触发器)
- Action Nodes(执行器)
- Function Nodes(函数节点)
- Logic Nodes(逻辑节点)
- 数据流动机制
- 调试与日志查看
- 连接真实世界——集成主流应用与API
- 连接飞书 / 企业微信
- 连接邮件系统(SMTP)
- 调用自定义API
- 项目实战1-全自动AI短视频工厂
- 项目实战2-智能日报汇总系统
|
帮助学员掌握 n8n —— 开源可视化工作流自动化引擎 的核心能力,理解其在AI时代与大模型应用集成中的关键作用,实现从本地部署、节点编排、API对接到复杂任务自动化的全链路实战能力。
划重点:连接一切系统”的工程思维 + “无需编码”的自动化实现能力 |
|
第二阶段(L2):AI大模型的企业级应用
深入学习大模型的企业级应用技术,包括常见技术和应用场景和工具 |
|
07.AI大模型能力以及行业应用分析 |
1. 2025大模型核心能力全景
a. 多模态能力突破:文本/图像/视频/语音/代码生成
b. 主流模型对比:GPT-5/Claude 4/通义千问3/Doubao核心指标
c. 能力演示:文生视频(Sora 2.0)、文生图(Gemini3/Nano banana Pro)、语音交互(Gemini Audio)
2. 行业落地与变现模式
a. 高价值行业应用:
- 电商(虚拟试衣间)、医疗(AI影像诊断)、教育(个性化私教)
b. 个人/小微团队案例:
- 独立开发者:API工具变现
- 超级个体
c. 避坑指南:2024失败项目共性 vs 2025生存法则
3. 如何找企业结合 AI 的切入点
4. 成熟商业案例拆解
5. 2025趋势与个人机会
a. 技术拐点:小模型+大模型协同部署
b. 新兴岗位:AI产品经理/大模型应用开发/提示词工程师
c. 个人能力定位:
- 非技术岗:行业痛点翻译+PoC验证
- 技术岗:RAG优化+人类反馈强化学】‘
6. 企业级应用的技术架构 |
这节课,目的是让学员了解,2025年这一年,AI大模型基础能力的发展情况,比如文生图、文生视频、语音、文生图、编码等各个维度,以及这些领域主流的模型,还有针对这些模型的能力的演示。
其次,了解目前那些行业、那些人已经应用AI能力来做一些AI工具、或者企业的解决方案,来进行变现和体现了
最后,对AI大模型的整体发展趋势,和个人在AI时代能够介入的领域做深度剖析。
划重点: 了解模型能力以及如何与行业结合变现! |
|
08.RAG检索增强生成技术实战 |
- 从基座模型的局限性了解RAG
- AI基座模型的知识库局限性与幻觉问题
- AI大模型如何回答非公开数据的问题
- RAG检索增强生成的整体概述
- RAG的工作原理分析
- 解 RAG 的三个核心组成部分:文档读取、检索和生成
- 10 大核心组件:文档导入、文本分块、嵌入、向量存储、查询优化、检索、检索后处理、生成、评估、整体流程优化
- RAG 的完整流程,并讲解每个环节的作用和意义
- 使用Coze/Dify/FastGPT演示RAG的实现流程
- RAG 的典型应用场景分析
- 企业知识库问答(HR制度、财务流程)
- 行业研究报告分析(金融、医疗、法律)
- 产品文档智能客服(SaaS厂商)
- 教育辅助:论文解读、教材答疑
- 用代码从0到1快速搭建一个RAG系统
- 搭建流程分析
- 文档的加载与切割
- 检索引擎(基于向量化检索)
- LLM/与Prompt编写
- RAG Pipeline
- 企业级RAG落地存在的问题以及解决思路
- 原始数据的处理与清洗
- 文本分块的策略
- 如何选择合适向量模型
- 检索优化(混合检索)
- 检索后的重排序(Rerank)
- 如何优化 RAG 系统?
- 分块策略:不同粒度对检索效率和准确度的影响
- 嵌入策略:如何选择合适的嵌入模型和向量数据库
- 检索策略:关键词检索、语义检索和混合检索的优缺点
- 生成策略:如何控制生成内容的质量和相关性
- 评估体系:如何评估 RAG 系统的性能和效果
- 实战:公司新员工企业制度问答机器人
|
帮助学员深入理解 RAG 技术的原理与价值,掌握从数据预处理、向量化存储、语义检索到生成优化的全链路能力,最终能独立构建基于私有知识库的高准确率AI问答系统。
划重点:让学员具备“数据 → 检索 → 增强 → 生成 → 评估”的RAG工程闭环能力,成为企业AI知识系统的构建者! |
|
9. Embeddings和向量数据库 |
- 从RAG的场景了解为什么要用向量存储!
- 什么是向量模型?
- 如何将数据(如文本、图像、音频等)转化为向量表示
- 嵌入空间的结构与语义:如何通过向量之间的距离表示相似性
- 向量数据库的选型目标与指南?
- 向量数据库与传统数据库的区别与优劣对比
- 向量数据库的三大核心能力
- 向量存储
- 近似最近邻搜索(ANN)
- 索引机制
- 常见开源向量库
- Weaviate
- Pinecone
- Milvus
- 向量嵌入的基本工作原理
- 词嵌入:Word2Vec、GloVe、FastText等经典方法
- 文本嵌入:BERT、GPT等预训练模型的嵌入
- 图像和音频的嵌入表示
- 特征嵌入:如何将结构化数据转换为嵌入表示
- 深入Embeddings—向量是如何“得到的”?
- Embedding 模型如何训练?
- 对比学习
- 三元组损失
- 向量维度与精度的关系
- 开源向量模型的基本概述
- 中文场景特别推荐:BGE 系列详解
- 开源向量模型VS闭源向量模型
- 选型决策树
- 是否需要中文支持
- 是否追求极致精度
- 是否要求数据不出境
- 是否高并发
- 嵌入模型的评估和选择
- MTEB 基准测试
- 稀疏嵌入和密集嵌入
- 重排序模型
- 使用向量数据库进行相似性检索
- 如何利用向量数据库进行高效的相似性检索:KNN(K最近邻)算法的应用
- 结合嵌入表示与向量数据库,实现大规模数据的快速搜索与推荐
- 示例:用FAISS进行大规模文本或图像检索
|
帮助学员深入理解 Embeddings 与向量数据库在大模型系统中的关键作用,掌握其数学本质、技术实现与工程选型能力,最终能为 AI 应用(如 RAG、推荐系统、语义搜索)构建高效、准确、可扩展的“语义理解底座”。
划重点:让学员具备“理解向量本质 → 选择合适模型 → 配置向量数据库 → 优化检索性能”的底层技术能力。
|
|
10. RAG企业级落地实战优化 |
- 主流RAG架构Native RAG/Advanced RAG/Modular RAG
- RAG各个节点的优化技巧详解
- 原始数据的质量决定RAG的效果
- 原始数据的清理方法
- 图片/表格数据的处理
- 文档处理辅助工具
- PyMuPDF
- RAGFlow
- Unstructured.io
- 数据分块策略(大小、语义、指定格式)、添加元数据
- Advanced-RAG: RAG进阶使用技巧
- 索引优化
- 滑动窗口方法
- 细粒度分段
- 合并元数据
- 预检索过程
- 查询构建
- 查询优化(重写、分解、扩展)
- 查询路由
- 检索后过程
- 重新排序块
- 上下文压缩
- 提升检索准确率的方法
- 检索策略(从小到大、分层合并、混合检索)
- 检索问题与解决方案
- 检索后置处理技术
- 重排序Rerank
- 压缩/校正
- LLM内容生成的稳定性优化
- Prompt提示词设计
- Self-RAG
- RAG检索结果评估
- 评估指标:召回率、准确率、响应相关性
- 手动构建“问题-标准答案”测试集
- 评估框架(RAGAS、Phoenix、TruLens )
- 评估结果的应用
- 优化分块策略、嵌入模型、检索算法等
- 构建高性能 RAG 系统
- 复杂检索策略和范式
- GraphRAG
- 利用图结构增强语义检索
- 构建知识图谱,实现更精准的知识问答
- Contextual Retrieval
- 基于上下文和多轮对话的高级检索策略
- 实现对结构化数据的精准检索
- 多模态 RAG
- 融合图像、视频等多模态信息
- 实现更全面的信息检索和理解
- Agentic-RAG
- 基于 Agent 的检索和生成策略
- Agent 作为检索控制器,实现更智能的检索和生成
- 动态检索路径(Dynamic Retrieval Planning)
- Graph RAG 工作原理与应用实战
- Graph RAG 的工作原理
- 查询处理
- 图遍历
- 子图检索
- 信息整合
- 响应生成
- Graph RAG 处理流程
- 实战:基于GraphRAG构建一个可以进行知识推理和问答的 RAG 系统
|
RAG研究范式在不断发展,我们将其分为三个阶段:Naive RAG、Advanced RAG和Modular RAG。
尽管 RAG 方法具有成本效益并且超越了LLM的性能,但它们也表现出一些局限性。 Advanced RAG 和 Modular RAG 的发展正是针对 Naive RAG 的这些具体缺点的回应。
划重点:成为组织中“RAG系统架构师”,能够主导从需求分析 → 架构设计 → 性能调优 → 效果评估的全链路交付。 |
|
11. 掌握LangChain实现AI大模型应用 |
- 基于API开发AI大模型应用存在的问题?
- API开发大模型应用的困境
- LangChain是什么?它能做什么?
- 大语言模型开发框架的价值是什么
- 常见的AI大模型应用开发框架
- LangChain
- LlamaIndex
- LangGraph
- LangChain 与生态工具的关系
- LangChain + LlamaIndex = 更强的 RAG 能力
- LangChain + LangGraph = 更复杂的流程控制
- LangChain + Weaviate/Pinecone = 完整的知识检索方案
- 了解LangChain框架的整体架构与核心组件
- 模型I/O封装
- 数据连接
- 对话历史管理
- 架构封装(Chain、Agent)
- Callbacks
- LangChain各个功能组件的使用
- 模型I/O封装功能演示
- 多轮对话Session封装
- Prompt提示词模板
- 结构化输出
- Function Calling功能演示
- 数据连接功能演示
- 文档加载器
- 文档处理器
- 向量库与向量检索
- 对话历史管理
- 历史记录剪裁
- 过滤带标识的历史记录
- Chain链式调用
- LangServe实现应用部署发布REST API
- 实战:LangChain实现一个新员工公司制度助手RAG应用
|
帮助学员深入理解 LangChain 作为大模型应用开发“操作系统”级框架的核心价值,掌握其模块化架构、关键组件与工程实践,最终能基于 LangChain 构建具备多轮对话、工具调用、知识增强、流程编排能力的生产级 AI 应用
划重点:掌握Langchain框架! |
|
12.大模型应用开发框架LlamaIndex |
- 为什么需要LlamaIndex?RAG的“数据瓶颈”如何突破
- RAG系统三大痛点
- LlamaIndex介绍
- LlamaIndex能做什么?
- LlamaIndex vs LangChain
- LlamaIndex安装与环境配置
- LlamaIndex 架构全景图
- LlamaIndex 核心架构六大组件
- Data Connectors(数据连接器)
- Data Processors(数据处理器)
- Indexing(索引构建)
- Query Interface(查询接口)
- Retrievers(检索器)
- Response Synthesizers(响应合成器)
- LlamaIndex 与 LangChain 的协同模式
- 核心组件实战——手把手掌握知识构建全流程
- 高级索引策略——打造“更聪明”的知识系统
- 多索引协同:Hybrid Indexing
- 同时构建向量索引 + 关键字索引 + 图索引
- 查询时自动路由到最合适的索引
- 子问题分解查询(Sub Question Query Engine)
- 将复杂问题拆解为多个子问题
- 示例:“比较A和B产品的优劣” → 分别检索A、B → 综合对比
- 摘要查询引擎(Summary Query Engine)
- 对整个文档集生成摘要,适合“整体了解”类问题
- 缓存与性能优化
- 使用
RedisCache 缓存高频查询结果
- 异步查询提升吞吐量
- 实战:基于LlamaIndex实现一个RAG系统
|
帮助学员深入理解 LlamaIndex 作为“RAG底层引擎” 的核心价值,掌握其在文档解析、索引构建、语义检索与上下文增强方面的强大能力,最终能基于 LlamaIndex 构建高精度、可扩展、可解释的企业级知识系统。
划重点:具备“数据接入 → 智能索引 → 高效检索 → 上下文增强 → 性能调优”的全流程能力 |
|
13. LangChain实现企业级Agent智能体 |
- 什么是Agent?
- Agent 的核心能力四要素
- Planning
- Memory
- Tools
- Reflection
- Agent不能提高大模型基础能力,但可以提高任务完成精准度
- Agent可以完成单次Prompt完成不了的任务
- Agent分类的四种使用方式:Reflection、Tool Use、Planning、Multi-agent
- 开发Agent的典型应用场景分析
- 运营自动化:每日数据汇总 → 生成报告 → 发送邮件
- 客户服务:自动处理工单、查询知识库、创建任务
- 研发辅助:代码生成 → 单元测试 → 提交PR
- 个人助理:安排行程、订票、写邮件、管理待办
- 利用Langchain与LlamaIndex提升开发效率、降低维护成本
- LangChain + Agent——让AI自主行动
- LangChain 中的 Agent 类型
- Zero-shot React Agent:基于 Prompt 决策
- Plan-and-Execute Agent:先规划再执行
- BabyAGI 风格 Agent:任务驱动、自我迭代
- Agent工作流程宏观剖析
- 关键组件详解
- Tools(工具)->Function Calling
- Memory(记忆)
- Agent Executor
- 实战:创建一个“旅行规划Agent”
- 工具集:天气API、地图API、酒店查询
- Prompt提示词设计
- 功能模块开发
- 高阶Agent模式——反思、多Agent协作与状态管理
- Self-Reflection Agent(自我反思)
- Multi-Agent 协作系统
- 状态管理与持久化
- 动态工具加载
|
帮助学员深入理解 LangChain 作为 Agent 开发“操作系统” 的核心能力,掌握其在任务规划、工具调用、反思机制、多 Agent 协作等方面的高级特性,最终能基于 LangChain 构建具备目标驱动、自主决策、持续执行能力的企业级智能体系统。
划重点:基于开发维度,掌握LangChain开发Agent的核心流程,具备全链路Agent的开发能力 |
|
14. AI工作流应用开发实战 |
- 为什么我们需要工作流?
- AI大模型的局限性
- 什么是AI工作流
- 工作流的应用场景
- 复杂任务
- 流程化任务
- 经典案例解析——吴恩达博士的翻译工作流项目
- 项目背景与价值
- 原始工作流设计蓝图
- 关键设计思想
- 使用 LangGraph 和 Agently Workflow分别复现翻译工作流
- LangGraph 简介
- 核心概念详解
- State(状态)
- Node(节点)
- Edge(边)
- 使用Agently Workflow复现翻译工作流
- Agently Workflow 简介
- JSON方式定义翻译流程
- 优势与适用场景
- 大模型应用工作流的关键要素解析
- AI工作流的五大基本要素
- 大模型应用工作流需要具备的特性
- LangGraph 的工作流要素图示
- Agently Workflow 的工作流要素图示
- LangGraph 和 Agently Workflow 的能力对比
- 复杂的工作流:故事创作/复杂的控制函数规划调用
- 设计思路
- 实现方案
- 进一步思考和讨论
|
掌握大模型时代下AI工作流的核心设计理念与开发能力,深入理解以 LangGraph 和 Agently Workflow 为代表的可视化编排框架,最终能独立构建具备条件判断、循环控制、状态管理、多节点协同的复杂AI工作流系统。
划重点:具备“需求分析 → 流程建模 → 框架选型 → 编排实现 → 性能调优”的全链路工作流开发能力 |
|
15.MCP模型上下文协议概述与应用实战 |
- 什么是MCP以及为什么需要MCP?
- 从Function Calling 到 MCP的发展
- 了解MCP的基本概念和组成
- MCP 的核心能力
- MCP 的典型应用场景
- MCP核心架构与四大核心概念
- MCP 架构全景图详解
- 四大核心概念详解
- Resources(资源)
- Tools(工具)
- Embeddings(嵌入)
- Transports(传输层)
- 动手实战-—实现一个MCP工具服务
- 开发一个天气预报查询与路线规划的MCP Server
- uv环境搭建
- 编写MCP Server以及MCP Tools
- MCP Server集成到Claude实现服务调用
- MCPInspector可视化工具
- 开放的MCP Server平台以及使用
- Claude Desktop 加载 MCP Server
- Claude Desktop使用mcp.so上的工具
- MCP是如何工作的?
|
帮助学员理解并掌握 MCP(Model Control Protocol)作为AI系统“控制平面” 的核心理念与实现方式,能够基于MCP思想构建多模型协同、多Agent调度、跨平台集成的企业级AI应用架构
划重点:了解MCP,掌握开发MCP服务的能力! |
|
16. 深入浅出A2A协议以及应用实战 |
- 了解A2A协议的基本概念以及发展
- 什么是A2A,它的价值是什么?
- A2A的典型应用场景有哪些?
- A2A协议核心功能与原理
- A2A协议的整体工作流程分析
- A2A 协议的四大核心要素
- 典型消息结构示例
- 主流A2A协议标准概览
- A2A vs API:本质区别
- 动手实战,实现两个Agent之间的A2A通信
- 场景:客服Agent委托审批Agent处理报销单
- 客服Agent(LangChain)收到用户请求
- 生成 A2A 消息发送给审批Agent
- 步骤分解与实施
- Agent to Agent (A2A) 与 MCP 的比较分析:技术、应用与影响
- A2A与MCP的未来发展与影响
- Agent Skill
|
帮助学员深入理解 A2A(Agent-to-Agent)协议的本质与价值,掌握其在多智能体协作、跨平台通信、系统集成中的关键技术,最终能基于主流A2A规范(如 GAIA、Agent Communication Protocol、JSON-LD 消息格式)构建可互操作、可扩展、可信任的多Agent协同系统。
划重点:具备“设计Agent角色 → 定义通信协议 → 实现跨Agent协作 → 构建自治组织(Auto-Org)”的全链路能力 |
|
17. AI大模型产品设计与落地 |
- 人人都是程序员和人人都是产品经理
- 为什么AI项目总是“雷声大、雨点小”?——破解落地困局
- 企业AI项目的三大常见失败原因
- 成功AI产品的共同特征
- AI产品落地的“三阶跃迁”模型
- 阶段1:Demo设计
- 阶段2:MVP
- 阶段3:规模化应用
- 从企业内部挖掘AI切入点(Problem Discovery)
- AI机会挖掘四象限法(高频率、低频率、高价值、低价值)
- 六大高频AI场景地图
- 数据分析
- 智能客服
- 知识问答
- 流程辅助
- 信息提取
- 内容生成
- 如何访谈业务部门?——“五问法”挖掘痛点
- 你每天花最多时间做的事是什么?
- 哪些工作你觉得重复、机械、无价值?
- 如果有一个“数字员工”,你最希望它帮你做什么?
- 当前有哪些工具用得不顺手?
- 如果AI能帮你节省1小时/天,你愿意尝试吗?
- 输出物:AI机会清单
- 设计AI产品原型(Design & Prototype)
- AI产品设计三大原则
- 最小可行功能
- 自然交互
- 可解释性
- 设计工具包
- Prompt流程图:用户输入 → 意图识别 → RAG检索 → 生成 → 输出
- 界面草图:使用Figma/Miro绘制对话界面
- RAG架构图:知识来源 → 向量化 → 检索 → 增强生成
- 错误处理设计:当AI不知道时,如何引导用户?
- 案例:设计“智能日报助手”
- AI实现与技术选型(AI Implementation)
- 技术选型决策树
- 四大实现路径对比
- 低代码平台(coze/dify)
- 框架开发(LangChain+LlamaIndex)
- API调用(Deepseek,Qwen3)
- 本地部署
- MVP开发三步法
- 搭积木:用Coze/Dify快速构建原型
- 接知识:导入制度文档、项目资料
- 调效果:优化Prompt、测试召回率
- 发布、推广与迭代(Launch & Loop)
- 发布前准备
- 制定《用户手册》与《常见问题FAQ》
- 培训关键用户(KOL)
- 设置灰度发布机制
- 推广策略三板斧
- 内部宣传:邮件通知、企业微信公告、短视频介绍
- 激励机制:使用AI最多的员工获奖励
- 标杆案例
- 建立反馈闭环
- 持续迭代路线图
- 衡量成功的关键指标(KPI)
- 项目实战——交付一个企业级AI产品
- 背景:某企业“智能制度问答机器人”
- 实施步骤
- 访谈HR与员工,挖掘痛点
- 设计对话流程与界面原型
- 使用Dify + RAG构建MVP
- 导入PDF制度文件,测试准确性
- 内部发布,收集反馈
- 输出《AI产品报告》
- 成果交付物
- AI产品立项书
- MVP原型系统
- 发布推广方案
- 效果评估报告
|
帮助学员建立AI大模型产品化思维,掌握从需求洞察、场景挖掘、原型设计、技术选型、跨部门协作到发布推广的全链路能力,最终能独立主导一个企业级AI项目的完整生命周期
划重点:让学员具备“业务洞察力 + 产品设计力 + 技术理解力 + 组织推动力”能力,成为企业中的“AI产品负责人”。 |
|
阶段三(L3):AI大模型的工作原理与优化
掌握大规模模型底层的工作原理,知其然知其所以然,从而更好的实现AI大模型的企业落地 |
|
18.从“NLP技术”到“AI大模型” |
- AI对话系统的“前世今生”——从规则到大模型的演进之路
- 人类与机器对话的愿景
- NLP 的三次浪潮
- 规则驱动
- 统计学习
- 深度学习/预训练
- 什么是NLP以及NLP应用举例
- NLP的定义
- 核心任务分类
- 理解类
- 生成类
- 结构化类
- NLP的典型应用案例
- NLP与大模型的关系
- NLP的核心技术分析
- 文本预处理与表示 & DataLoader
- 序列模型与注意力机制
- 生成模型与语言模型
- 词表示、语言模型(N-Gram模型)、分词算法
- NLP应用实践-实现一个传统NLP文本分类系统
- 背景:新闻分类系统
- 环境搭建与实施
- 代码效果演示
- 从NLP到大模型——能力跃迁与工程融合
- 大模型如何“继承”NLP能力?
- 如何融合传统与现代?
- 高级NLP技术的现代演进
|
帮助学员系统梳理 从传统 NLP 到现代大模型的技术演进路径,理解 NLP 的核心思想如何被继承、扩展并最终在大模型时代实现质的飞跃,最终建立起“技术发展观 + 工程实践力”的双重能力
划重点:不再割裂看待“NLP”与“大模型”,而是理解它们之间的传承、融合与跃迁关系 |
|
19.探索揭秘神经网络奥秘 |
- 神经网络是如何实现AI的训练和推理的
- 神经网络的灵感来源:模仿人脑
- 神经网络的核心能力
- 训练 vs 推理:AI 的“学习”与“应用”
- 神经网络在AI发展中的里程碑作用
- 神经网络与机器学习的关键技能
- 损失函数评定当前模型水平
- 梯度下降确定模型迭代方向
- 一次迭代提升模型精准程度
- 优化算法与正则化
- 回归问题与分类问题
- 常见的神经网络类型
- 全连接网络(Fully Connected / MLP)
- 卷积神经网络(CNN) & ResNet
- 循环神经网络(RNN), LSTM & Attention
- 实战:使用Python实现简单的神经网络训练过程。
- 项目实战——构建一个图像分类器(CNN简化版)
|
帮助学员深入理解 神经网络如何实现“学习”与“推理”,掌握其在训练过程中的关键机制(损失函数、梯度下降、优化算法),并能通过 Python 实现一个完整的前馈神经网络训练流程,最终建立起“数学直觉 + 工程实现 + 架构认知”三位一体的能力。
划重点:让大家不再将神经网络视为“黑箱”,而是理解其为“可解释、可调试、可构建”的智能系统基础组件 |
|
20. 揭秘Transformer的工作原理 |
- 为什么Transformer是大模型的“心脏”?
- RNN的三大致命缺陷
- 《Attention Is All You Need》论文的颠覆性创新
- Transformer 的三大革命性突破
- Transformer 的“家族谱系”
- BERT
- GPT
- T5
- Tokenization - 将对话内容变成Token
- 什么是Token?模型的“最小语义单元”
- 词元化(Tokenization)方法演进
- BPE(Byte Pair Encoding)算法详解
- 中英文Token化差异
- 效果演示:OpenAI Tokenizer 工具
- Embedding——让Token拥有“语义身份证”
- 数学对AI的突出贡献 - 空间与向量
- 为什么需要Embedding?计算机只懂数字
- 从One-Hot到稠密向量
- 空间的稀疏、稠密、距离、数学逻辑关系
- Word2Vec:让向量学会“类比推理”
- OpenAI Embedding Model
- OpenAI Clip - 文字与图片的多模态Encoder
- 效果演示:OpenAI Embedding-计算句子相似度
- Attention机制——Transformer的“核心引擎”
- Attention 的基本思想
- Self-Attention 计算三步曲
- 图解Self-Attention
- Multi-Head Attention:多角度理解语义
- Position Encoding:告诉模型“谁在哪儿”
- Encoder vs Decoder 的Attention差异
- Transformer架构详解——Encoder与Decoder的协同
- 完整Transformer架构(Encoder-Decoder)
- Encoder理解你的指令
- Decoder回答你的问题
- 基于循环神经网络的Encoder & Decoder
- 三大架构变体-Encoder only & Decoder only
- 为什么GPT只用Decoder?
- 为什么BERT只用Encoder?
- 实战: 从零搭建Transfomer模型,实现Self-attention机制。
|
帮助学员深入理解 Transformer 架构的每一个核心组件,掌握其从 Tokenization → Embedding → Attention → Encoder/Decoder 的完整工作流程,最终能通过代码实现一个简化的 Self-Attention 机制,并理解其在 GPT、BERT 等模型中的应用。
划重点: 掌握AI大模型底层的文本理解框架 Transformer |
|
21. 深入浅出了解多模态模型 |
- 多模态大模型的定义
- 跨模态模型
- 单模态大模型
- 多模态模型
- 多模态语言大模型
- 图文多模态模型的发展
- Vision Transformer
- 图像文本联合建模
- 大规模图-文 token 对齐模型(CLIP)
- 多模态大语言模型
- OpenAI GPT-4V
- Google Gemini
- GPT-4V 实战
- 多模态模型架构
- 多模训练技术
- 图文多模态大语言模型的评测
- 开源社区多模态大语言模型
- 开源 LLaVA 图文对话模型的训练
- 模型架构
- 训练过程
- 实战:数据构造与模型训练
- LLaVA 应用衍生以及优化方向
- 支持更多模态的大语言模型
- X-LLM
- NexT-GPT
- Multi-Agent 多模态语言模型
- LLM 驱动的跨模态生成模型 - VideoPoet
- 实战:通过实际项目,融合不同模态的数据,微调现有的多模态开源大模型。
|
学员系统掌握 多模态大模型的核心定义、技术演进、主流架构、训练方法与实战应用,理解其如何融合文本、图像、音频、视频等不同模态信息
划重点:具备“理解多模态 → 掌握主流模型 → 实战微调 → 构建跨模应用”的全链路能力
|
|
22. 国产大模型DeepSeek深度剖析 |
- 国产大模型崛起背景——为什么我们需要DeepSeek?
- 中国AI的“卡脖子”与“自研突围”
- Deepseek是什么以及Deepsekk能做什么?
- 如何使用Deepseek
- DeepSeek 的差异化优势——凭什么它能“对标GPT-4”?
- 了解Deepseek的优势
- Deepseek大模型生态以及模型选择
- 理解图例模型和非推理模型的差异
- Deepseek和行业其他模型的能力对比
- 如何在企业应用中选择合适的模型
- 详细讲解 DeepSeek - R1 的四阶段训练流程,包括每个阶段的训练目标、数据处理方式、模型参数调整策略等。
- DeepSeek-R1蒸馏模型详解
- 蒸馏模型概述:定义、作用及蒸馏过程。
- 蒸馏模型的变体与特性:涵盖不同参数规模(如 1.5B、7B、14B、32B 等),基于 Qwen 和 Llama 等基础模型。
- 国产大模型GLM-4的架构与应用、与GPT模型的对比分析。
- 文心一言大模型,通义千问大模型,盘古大模型,豆包大模型横向对比
|
帮助学员深入理解 DeepSeek 系列大模型的技术架构、训练方法与差异化优势,掌握其在推理、代码、长文本等场景中的突出能力,并能结合 GLM-4、通义千问等其他国产模型进行横向对比与企业级选型判断
划重点:具备“技术洞察 + 模型选型 + 应用落地”三位一体的能力 |
|
23.AI大模型微调实战
|
- 小实验1:动手微调一个小 GPT
- HuggingFace简介
- 模型加载
- 数据加载
- 训练器
- 什么是模型
- 什么是模型训练
- 训练时几个重要超参
- 调整超参,再跑实验1
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- Prompt Tuning
- P-Tuning
- Prefix Tuning
- LoRA
- QLoRA
- 实验数据集的构建
- 实战 1:基于 LoRA 微调 Qwen2 7B
- 实战 2:基于 QLoRA 微调 Llama3 8B
- 实战 3:基于 QLoRA 微调 GLM4 9B
- 更多训练数据的构建技巧
|
自己实现一个模型微调,彻底搞懂大模型微调的底层原理
划重点: 掌握企业级AI大模型的微调能力 |
|
24.GPU与CUDA以及AI大模型企业级部署方案 |
- 为什么AI离不开GPU?——算力革命的本质
- GPU与CPU 计算核心的区别对比
- AI计算的本质:大规模并行矩阵运算
- GPU带来的三大变革
- 速度提升
- 算法设计自由
- 商业化可能
- 1000倍以上的速度提升带来算法设计模式的巨大变化
- GPU如何工作?——深入并行计算的底层机制
- GPU并行计算五步法
- 关键概念解析
- CUDA Core:GPU的基本计算单元
- SM(Streaming Multiprocessor):包含多个CUDA Core的处理单元
- Warp:32个线程的执行单元,GPU调度的基本单位
- Global Memory(显存):GPU的“主存储”,容量大但延迟高
- Shared Memory:SM内部高速缓存,用于线程协作
- 代码示例:PyTorch中的GPU操作
- 英伟达的“技术护城河”——CUDA生态的绝对统治
- CUDA:18年积淀的并行计算平台
- 四大生态优势
- 开发者生态
- 框架深度集成
- 工具链完整性
- 硬件协同优化
- 试错成本过高带来的迁移困难
- 竞争对手现状
- AMD
- Intel
- 如何在GPU上做并行计算
- 启动普通CPU应用程序
- 将数据加载到内存
- 将数据从内存copy到显存
- 运行GPU应用程序完成大规模计算
- 将计算结果存储到显存
- 将计算结果从显存copy到内存
- 大模型私有化部署的必备知识体系
- 为什么要私有化部署?
- 私有化部署的三大模式
- 关键技术组件
- 推理引擎:vLLM、TensorRT-LLM、Triton Inference Server
- 模型服务化:FastAPI + uvicorn + GPU调度
- 显存优化:量化(INT8/FP16)、LoRA微调、KV Cache管理
- 负载均衡:支持多实例并发请求
- 成本评估模型
- 动手实战——搭建一个本地大模型推理服务
|
帮助学员系统掌握 GPU与CUDA在AI训练与推理中的核心作用,理解英伟达生态的技术壁垒,并能基于企业需求设计安全、可控、可扩展的大模型私有化部署方案
划重点:具备“算力认知 + 技术理解 + 部署规划 + 成本评估”能力 |
|
阶段四(L4):AI大模型的企业级项目实战
通过真实项目的实践,巩固所学知识,提升职业技能,做好职业规划和求职准备 |
|
25.企业级AI销售助手应用实战 |
项目目标:
- 实现客户需求智能洞察
- 构建自动化销售流程引擎
- 提升线索转化率20%+
项目简介:
面向B2B销售场景的智能助手,集成CRM系统数据,支持客户画像分析、沟通策略推荐、合同风险预警等功能。
项目内容:
- 整体架构设计
- 初始化设置,包括AI的人设,公司基础信息、产品信息等
- 决定要做什么:
- 使用工具
- 向用户输出响应
- 意图识别
- 基于LangChain搭建代码实现流程
- 提示词模板设计
- 销售分析链构建
- 产品知识库提炼和集成
- 向量库选型和向量化嵌入
能够搭建企业级个性化本地知识库 |
|
26.企业级教育智能问答助手 |
项目目标:
- 引入Deepseek-R1推理技术,突破传统问答模式“一问一答”“不问不答”局限,实现“一问多答”“不问自答”!
- 解决问题“查找难、理解难、办理难”的痛点
- 针对不同场景的特点设计合适的技术落地方案,更进一步提高大家对于大模型应用落地的认知和能力
项目简介:
通过收集政务问答数据和相关政务问答文档,基于检索增强问答框架,构建了一个智能化的政务问答助手。
项目内容:
- 大模型与知识库结合的基础应用
- 了解GPT系列和BERT等大模型的基础结构
- 探索大模型与知识库结合的实际应用场景
- 认识常用的知识库技术,如向量数据库(FAISS、Pinecone)、ElasticSearch
- 知识库挂载的实战操作
- 分步完成大模型与知识库的集成
- 学习通过API或数据库连接,实现知识库与大模型的实时交互
- 实战演练:将知识库挂载到Deepseek-r1,提升问答能力
- 优化挂载效果与应对挑战
- 提升知识库查询的速度与准确度的技巧
- 解决挂载中的数据一致性问题
- 使用缓存技术,优化大模型的响应速度
掌握大模型与外部知识库实现增强型智能查询系统 |
|
27.LangGraph与Agentic多模态RAG系统实战:构建具备自主反馈机制的智能检索增强生成架构 |
项目目标:
掌握现代RAG系统架构演进与核心技术
掌握LangGraph框架与智能体系统开发
构建智能旅游助理实战项目
项目介绍:
本项目旨在通过构建一个基于LangGraph的Agentic多模态RAG智能旅游助理,让学员从理论到实践全面掌握现代AI系统的核心架构与实现方法,培养面向未来的AI系统设计与开发能力。
项目内容:
- RAG技术的发展演进与现状分析
1.1 技术发展的主要脉络:从Naive RAG到增强检索(如重排序、Hybrid Search),再到结构化RAG(如GraphRAG)和多模态RAG,最后到智能体驱动的RAG(Agentic RAG)。
1.2 RAG核心应用场景矩阵:列举不同RAG技术在不同场景(如问答、文档摘要、多模态对话等)的适用性,并以旅游领域为例说明。
- 初代文本匹配:Naive RAG技术架构剖析
2.1 Naive RAG的技术实现:基于文本嵌入的检索(如使用BERT或GPT的嵌入向量)和生成(如使用LLM)。
2.2 Naive RAG的系统流程:索引(文档切分、向量化、存储)和检索(问题向量化、相似性搜索、top-k检索)以及生成(将检索到的上下文与问题结合生成答案)。
2.3 Naive RAG面临的问题与挑战:检索精度低、上下文长度限制、无法处理多模态数据、缺乏推理能力等。
2.4 Naive RAG的适用场景:简单问答、文档检索等对精度要求不高的场景。
- 突破全局语义:GraphRAG——知识图谱与RAG的融合
3.1 GraphRAG的构建原理与方法:从非结构化文本中抽取实体和关系构建知识图谱,利用图数据库存储,并结合向量索引。
3.2 GraphRAG的查询方式与流程:将用户问题转化为图查询(如Cypher语句)和向量检索,结合两者结果进行答案生成。
3.3 GraphRAG的适用场景:需要深层次关系推理的复杂问答,如旅游行程规划中的多目的地关联查询。
- 突破模态限制:多模态RAG的技术实现
4.1 多模态统一表征学习:使用CLIP、BLIP等多模态模型将图像、文本等映射到同一向量空间。
4.2 多模态RAG的构建原理与方法:分别构建文本和图像的索引,或使用多模态模型统一索引。
4.3 多模态RAG的查询方式与流程:支持文本、图像或混合查询,检索多模态上下文,生成多模态答案(如生成图文并茂的旅游指南)。
4.4 多模态RAG的适用场景:需要处理多种类型数据的场景,如旅游景点介绍(包含图片和文本)。
- 智能演进:Agentic RAG的自主决策机制
5.1 智能RAG的决策原理:利用智能体(Agent)来决策RAG的每一步,例如是否需要进行检索、需要哪种检索方式(文本、图、多模态)、是否需要多个检索轮次、如何评估检索结果等。
5.2 自主错误反馈系统的构建:当生成的答案不符合要求时,系统能够自动调整检索策略或重新生成,例如通过自我反思(self-reflection)或使用工具(如计算器、验证器)来纠正。
- 项目实战:基于LangGraph+Agentic RAG技术构建智能旅游助理
我们将构建一个智能旅游助理,它能够处理用户的多模态输入(如文本描述和图片),并利用多模态RAG和GraphRAG来检索相关信息,同时使用Agentic RAG的自主决策机制来优化检索和生成过程。 |
|
|
28. MCP+LangGraph构建专属ChatBI数据分析智能助手 |
项目目标:
- 掌握利用MCP协议连接数据源与大模型的核心技术。
- 运用LangGraph框架构建可编排、有状态的智能数据分析工作流。
- 开发一个能够理解自然语言、执行数据查询、分析并生成可视化图表的电商ChatBI智能助手。
项目简介:
本项目聚焦于构建一个面向电商领域的智能商业分析(ChatBI)助手。该助手将利用MCP(Model Context Protocol)打破数据孤岛,安全地访问数据库等外部数据源 ,并借助LangGraph框架编排复杂的分析任务 。用户可通过自然语言提问,如“上个月华东区销售额最高的品类是什么?”,助手将自动完成数据抽取、分析挖掘,并生成可视化图表。
项目内容:
- 课程任务介绍
- 介绍本课程的核心目标:构建一个电商领域的ChatBI智能助手。
- 明确项目最终成果:一个可通过对话进行数据分析和可视化的应用。
- 概述所需技术栈:大语言模型(LLM)、MCP协议、LangGraph框架、数据库连接。
- ChatBI类产品的优势与挑战
- 优势:
- 降低使用门槛:业务人员无需掌握SQL或复杂BI工具,通过自然语言即可获取数据洞察
- 提升效率:实时数据交互,快速生成分析报告和可视化图表
- 智能建议:提供智能数据建议和归因分析
- 挑战:
- 自然语言理解的准确性:确保对用户意图的精准识别 。
- 端到端性能:模型推理和数据查询的性能需达到秒级响应 。
- 上下文缺失:独立搜索框可能导致用户需要手动输入完整业务背景 。
- 数据安全与权限:在连接真实数据源时需考虑安全访问控制。
- 剖析ChatBI的技术原理
- 核心流程:用户输入自然语言 -> 意图识别与语义理解 -> 转化为数据查询指令(如SQL)-> 执行查询 -> 分析结果 -> 生成可视化图表 -> 返回自然语言总结。
- 关键技术:自然语言处理(NLP)、大语言模型(LLM)、检索增强生成(RAG)、数据库查询引擎。
- 架构模式:通常结合了LLM的生成能力与传统BI的数据处理和可视化能力 。
- 驱动ChatBI的核心能力MCP理论介绍
- MCP(Model Context Protocol)是什么:一种由Anthropic推出的模型上下文协议,旨在让AI模型与外部工具和数据源进行标准化通信 。
- 核心价值:
- 打破数据孤岛:为AI模型提供安全访问本地文件、数据库及云端服务的双向数据通道 。
- 简化开发:通过统一的接口和标准化工具注册,替代重复的Function Calling代码,大幅降低开发复杂度 。
- 互联互通:作为AI智能体的“万能插头”,促进不同系统间的高效协同
|
|
29. 打造高性能知识增强RAG系统 |
项目目标:
- 深入理解RAG(检索增强生成)的核心原理与技术架构。
- 掌握从知识库构建、检索优化到生成增强的全流程关键技术。
- 能够针对不同业务场景设计并实现高性能的RAG解决方案。
项目简介:本项目旨在教授学员构建一个高性能的知识增强型RAG系统。RAG技术通过将大语言模型(LLM)与外部知识库相结合,有效缓解了模型的“幻觉”问题,使其能够生成更准确、更具事实依据的回复 。课程将从理论到实践,覆盖RAG的全生命周期,并通过证券和客服领域的实战案例,让学员掌握工业级应用的开发方法。
- 工业界RAG的难点与挑战
- 检索质量挑战:低精度的检索会导致检索到不相关或未对齐的文本块,直接影响最终生成内容的准确性和相关性 。
- 生成“幻觉”问题:即使检索到相关信息,大模型仍可能忽略上下文,生成与检索内容无关或错误的“幻觉”信息 。
- 增强障碍:将检索到的信息有效集成到生成过程中可能具有挑战性,有时会导致输出不连贯或出现冗余 。
- 端到端性能:在专业或技术性领域,确保整个系统(检索+生成)的响应速度和准确性是巨大挑战 。
- 如何高效构建知识库
- 数据预处理:清洗、去噪、格式化原始文档,确保输入质量 。
- 文档解析与分块(Chunking):将长文档分割成更小的片段。选择合适的分块策略(如按固定大小、递归字符、语义分割等)至关重要,它直接影响检索的精准度和生成的连贯性 。分块能避免模型输入超限,并提升检索效率 。
- 向量化与索引:为分块后的文本生成嵌入向量(Embedding),并将其存储到向量数据库中,建立可快速检索的索引 。
- 常用检索、增强、生成方法介绍
- 检索方法:
- 向量检索:基于语义相似性进行检索。
- 混合检索:结合向量检索与关键词检索(如BM25)等多种方法,提升召回率和准确率 。
- 增强方法:
- 重排序(Reranking):在初步检索后,使用更精细的模型对结果进行重新排序,将最相关的结果排在前面,显著提升答案质量 。
- 生成方法:
- 将检索到的最相关文档片段与用户原始问题拼接,形成新的提示(Prompt),输入给大模型进行生成。
- 如何选择合适的RAG策略
- 分析业务需求:是追求高精度(如金融、医疗)还是高召回率(如初步信息探索)?
- 评估数据特性:知识库的大小、结构化程度、更新频率。
- 权衡性能与成本:复杂的策略(如混合检索+重排序)效果更好,但延迟和成本也更高。
- 迭代优化:通过A/B测试等方式,持续评估不同策略(如分块大小、检索算法)的效果,选择最优方案。
- 实战案例:
- 实战案例一:证券交易所快捷查找
- 场景:帮助投资顾问或研究员快速从海量的公告、研报、法规中查找特定信息。
- 实现:构建包含证券相关文档的知识库,采用语义分块和混合检索策略,结合重排序技术,确保对专业术语和复杂查询的高精度响应 。可借鉴“主Agent+子Agent”多智能体架构,实现更复杂的分析任务 。
- 实战案例二:基于RAG的客服工作辅助系统
- 场景:为客服人员提供实时话术建议和知识支持,提升服务效率和准确性。
- 实现:构建公司产品手册、FAQ、服务政策等知识库。当客户咨询时,系统实时检索最相关的知识片段,并生成简洁明了的回复建议供客服参考 。可与Function Calling技术结合,处理账户查询等动态信息 。
|
|
30. 从0-1打造多MCP协同智能体系统实战 |
项目目标:
- 深入理解MCP(模型上下文协议)的核心原理、架构与通信机制。
- 掌握构建多MCP智能体系统的策略与方法,理解其相对于单一智能体的优势。
- 能够运用MCP及多智能体框架(如OpenAI Agent SDK)开发复杂的AI应用。
项目简介:本项目将系统性地教授如何利用MCP协议和多智能体框架构建高性能AI应用。MCP作为AI模型与外部工具、数据源通信的标准化“语言”,打破了数据孤岛,实现了工具的“即插即用” 。课程将从单个MCP系统构建出发,逐步演进到复杂的多智能体协作架构,通过金融领域的实战案例,让学员掌握前沿的AI系统开发范式。
- 多MCP智能体架构
- 介绍多智能体系统(MAS)的概念,即多个AI智能体协同工作以完成复杂任务 。
- 阐述在MCP语境下,如何通过多个MCP服务器(每个代表一个工具或服务)与一个或多个智能体(客户端)交互,形成一个多工具协作的生态系统。
- 探讨多智能体协作协议(MCP)作为框架,定义了多个基于LLM的智能体如何通信、协调和协作 。
- 如何构建多MCP系统?
- MCP server从低层实现到高层封装:
- 底层实现:MCP Server是提供特定功能的轻量级程序 。可通过标准的传输协议(如SSE或stdio)实现 。通信可通过本地进程间通信(stdin/stdout)进行 。
- 高层封装:利用现有的MCP工具包或框架(如MCP Toolbox)可以更便捷地开发和部署MCP Server 。
- MCP server的串行和并行调用机制:
- 串行调用:智能体按顺序调用多个MCP工具。
- 并行调用:支持同时运行多个任务或调用多个服务器,例如,一个支持多并发的浏览器MCP服务器可以同时运行多个浏览器实例 。MCP Client可以实现并行调用 。
- MCP client的实现:
- MCP Client作为调用方,是用户与MCP生态的交互入口 。它负责连接MCP服务器、发现可用工具、发起工具调用请求并将结果返回给主机应用(Host) 。主机应用(如聊天软件或IDE)内部运行MCP Client 。
- 实战项目一:股票心理按摩师
- 项目目标:构建一个能为投资者提供情绪安抚和市场分析的AI助手。
- 实现:集成多个MCP Server,例如:
- 一个用于检索实时市场新闻和数据。
- 一个用于分析市场情绪。
- 一个用于生成安抚性、鼓励性的回复(“心理按摩”)。
- 架构:可采用中心化智能体,协调调用上述工具,综合信息后生成最终回复。
- MCP与多智能体框架集成
- 为什么要用MCP+多智能体框架:MCP解决了工具连接问题,而多智能体框架解决了复杂任务的编排与协作问题。两者结合可以构建能力更强、更健壮的系统 。
- Agent框架与MCP:MCP为多智能体框架中的智能体提供了访问外部世界(工具和数据)的标准化途径,是构建实用型智能体的关键基础设施 。
- OpenAI Agent SDK介绍:这是一个轻量级但功能强大的框架,专为构建多智能体工作流而设计 。它支持MCP服务,允许开发者快速构建能与真实工具连接的智能体 。新版SDK已支持MCP,解锁了无限的工具扩展能力 。
- 实战项目二:金融投资虚拟顾问
- 项目目标:构建一个专业的投资顾问智能体,能进行宏观分析、基本面研究和量化策略评估。
- 实现:利用OpenAI Agent SDK 构建一个多智能体系统:
- 宏观分析师Agent:调用MCP Server获取经济数据。
- 基本面研究员Agent:调用MCP Server查询公司财报。
- 量化分析师Agent:调用MCP Server进行数据回测。
- 组合管理Agent:作为协调者,整合各子智能体的分析结果,生成最终的投资建议 。
- 优势:通过分工协作,模拟专业投资团队,提供更全面、深入的分析。
|
|
31.留学咨询引导式对话系统项目实战 |
|
|
|
32.企业级智能医疗问诊小助手(这个有问题)医疗大模型从0-1实战 |
项目目标:
- 掌握医疗场景下的语义精准理解
- 实现信息系统与DeepSeek的深度融合
- 使用定制数据集微调大模型
项目简介:
AI 就医助手是一款特别针对医疗场景需求打造的智能对话机器人,可接入医院官方微信公众号,为患者提供就诊流程指引、快速找医生、智能导科室、病情咨询、用药指导等多维度功能
项目内容:
课时一:实例:动手微调Qwen3 0.6B小模型
微调的必要性
领域适配:预训练模型(如BERT、GPT)学的是通用知识,微调使其适应特定任务(如
医疗问答、法律文本分析)。
数据效率:微调只需少量领域数据即可提升效果,比从头训练成本低。
任务定制:调整输出结构(如分类层、生成格式)以匹配具体需求。
知识储备
Transformer:理解自注意力机制(QKV矩阵)、位置编码、层归一化(LayerNorm)。
微调实战(以Qwen-0.6B为例)
数据处理:示例:医疗问答数据格式化为{"instruction": "...", "input": "...", "output": "..."}。
使用transformers库的AutoTokenizer处理文本(截断、填充至512长度)。
LoRA配置
SwanLab监控:可视化训练指标(损失、准确率):
课时二:预训练语言模型分类
Encoder-only
仅使用Transformer的编码器结构,专注于双向上下文建模,适合理解型任务(如文本分
类、实体识别)。
通常通过掩码语言建模(MLM)预训练,学习词语在上下文中的表示。
生成的表示是上下文相关的,每个词的嵌入依赖整个输入序列。
BERT
RoBERTa
ALBERT
Encoder-Decoder PLM
结合编码器和解码器,适合生成任务(如文本摘要、翻译)和理解-生成联合任务。
编码器双向编码输入,解码器自回归生成输出。
通常通过去噪自编码(Denoising AE)任务预训练。
T5
Decoder-Only PLM
仅使用Transformer的解码器结构,通过自回归(从左到右逐词生成)建模。
适合开放生成任务(如对话、创作),但缺乏双向上下文理解。
预训练目标为标准语言建模(预测下一个词)。
GPT
LLaMAQwen
GLM
介绍以上以上多个类别的特点和技术细节
课时三:如何构建一个大语言模型
Pretrain
目标:学习通用语言表示。
数据:1TB+文本(如Common Crawl),使用BPE分词。
硬件:千卡GPU集群(如A100×1024),训练月级时间。
SFT(Supervised Fine-Tuning)
数据格式:指令-输出对(示例):
{"instruction": "翻译成英文", "input": "今天天气很好", "output": "The weather is nice
today"}
损失函数:交叉熵(仅计算输出部分token的损失)。
RLHF(基于人类反馈的强化学习)
三步流程:SFT模型 → 2. 奖励模型(RM)训练(人类标注偏好数据) → 3. PPO优化。
课时四:实例:手搓Qwen3大模型(一)
了解Qwen3大模型基本知识
旋转位置编码(RoPE):通过复数域旋转注入位置信息,支持任意长度外推
Gated MLP(SwiGLU):引入门控机制,增强非线性表达能力。
RMSNorm:省去均值中心的LayerNorm,计算量减少。
定义超参数、构建正则化、Attention、MLP、Decoder模块
课时五:实例:手搓Qwen3大模型(二)
了解Tokenizer的基本知识和分类
BPE算法步骤:
1. 初始化:将所有单词拆分为字符(如"chat" → ["c", "h", "a", "t"])。
2. 统计相邻符号对频率,合并最高频对(如"c"+"h"→"ch")。
3. 重复合并直到达到目标词表大小(如32k)。
从零训练Tokenizer,以BPE Tokenizer为例
测试Tokenizer
使用上述Qwen3和Tokenizer开始预训练和微调
课时六:大模型训练标准流程
介绍Transformers框架和使用方法
预训练数据处理方法
使用Transformer中的Trainer类进行训练
使用 DeepSpeed 实现分布式训练
DeepSpeed优化策略:
ZeRO-2阶段:优化器状态分区(Optimizer State Partitioning),减少单卡显存占
用。
激活检查点:牺牲计算时间换取显存节省,适合超大模型训练。
混合精度训练:
FP16模式:前向/反向传播使用半精度,优化器维护FP32主权重。
动态损失缩放:自动调整梯度缩放因子,防止下溢出。
课时七:有监督微调
Pretrain VS SFT 对比
微调数据处理,以医疗行业数据为例子
数据清洗:去除非结构化文本(如PDF表格),标准化医学术语(ICD-10编码)。
高效微调方案:Adapt Tuning 和 Prefix Tuning
LoRA微调实例
课时八:大模型应用
LLM 的评测
LLM评测体系的三重维度
基础能力评测:
语言理解:GLUE基准(如文本蕴含、情感分析)
知识掌握:医学QA数据集(如MedQA-USMLE临床知识测试)
推理能力:Big-Bench Hard(BBH)中的因果推理任务
安全性与偏见:
毒性检测:RealToxicityPrompts数据集评估冒犯性输出
偏见指数:测量模型对性别/种族等敏感属性的倾向性(如StereoSet)
领域适应性:
医疗术语识别准确率(如UMLS实体匹配)
临床指南合规性(通过专家评审打分)
通用数据集
LLM主流评测榜单
RAG原理和应用核心流程:
检索阶段:
使用BM25(词频统计)+ 稠密检索(如Contriever模型)混合策略
医疗场景优先检索UpToDate/PubMed等权威知识库
生成阶段:
将检索结果作为上下文注入Prompt(如:"基于以下指南:{text},回答:
{question}")
医疗优化方向:
检索增强:构建医学本体库(如SNOMED CT)提升术语匹配精度
可信度控制:输出附带参考文献来源(PMID编号)
Agent原理和应用
课时九:医疗行业GPT串讲
介绍针对于医疗行业的GPT训练和微调
医疗文本的特性挑战
术语密度高:单个句子可能包含10+个专业实体(如"冠状动脉粥样硬化性心脏病")
标注成本极高:1份放射报告标注需放射科医师30分钟,错误标注可能引发法律风险
微调策略对比
全参数微调:
适用场景:拥有10万+高质量标注数据(如某专科医院病历库)
风险:可能导致模型遗忘基础医学常识
参数高效微调:
LoRA:在注意力层的Q/V矩阵注入低秩适配器(rank=8)
Prompt Tuning:学习软提示(Soft Prompt)引导模型输出专科倾向性
合规性保障机制
输出校验层
规则引擎:拦截剂量/用药禁忌冲突(如"孕妇禁用利巴韦林")
不确定性标记
典型应用场景
临床辅助决策:
输入:患者主诉+实验室指标 → 输出:鉴别诊断列表(按概率排序)
医患沟通增强:
将专业诊断转化为通俗解释(如"心肌梗死"→"心脏血管堵塞导致的心肌损伤") |
|
阶段五(L5):从模型训练到模型微调入门到精通🆕🔥(录播)
深入理解 大模型微调(Fine-tuning)的原理、方法及在实际场景中的应用
掌握 大模型分布式训练与微调的各种技术,包括DDP、DeepSpeed、FSDP及其优化策略 |
|
大模型微调基础与LLaMA-Factory入门 |
课程介绍与大模型微调概览
-
- 传统微调方式的痛点与挑战
- 显存占用高、训练时间长、部署成本高
- 小样本学习与领域适应性问题
- 大模型高效微调框架 LLaMA-Factory 介绍
- LLaMA-Factory 的优势:支持多种微调方法、易用性、集成度高
- LLaMA-Factory 在大模型生命周期中的定位
- 大模型微调的价值与应用场景
- 领域知识注入、任务定制、性能优化
- 降低成本、提升效率、保持模型时效性
|
|
LLaMA-Factory 安装与环境配置
-
- 环境要求与硬件选择
- 微调环境的最低硬件要求(CPU、内存、GPU显存)及推荐配置
- GPU选型(NVIDIA A100/H100、RTX 4090等)与显存考量
- 云服务环境选择与优势(AutoDL、GPU租赁平台等)
- 本地环境安装 (Windows WSL/Linux)
- CUDA、cuDNN安装与版本匹配
- Python环境管理(conda、venv)与版本选择
- Git安装与代码克隆
- LLaMA-Factory安装及作用
- LLaMA-Factory 扩展模块的选择与安装(如FlashAttention、bitsandbytes)
- 云服务环境配置实践
- AutoDL等云平台下的环境配置流程
- SSH隧道、开放端口等网络配置
- 使用技巧与资源优化配置
- 常见安装问题排查与解决方案
实践: 学员动手搭建本地/云端 LLaMA-Factory 开发环境。 |
|
LLaMA-Factory WebUI 介绍
-
- WebUI 各功能模块详解
- 模型选择、数据集配置、微调参数设置
- 实验管理、日志查看、模型评估、模型导出
- WebUI 操作流程演示
- 实践: 学员熟悉并尝试使用 LLaMA-Factory WebUI 进行基本操作
|
|
大模型微调实践与优化 |
数据集准备与配置
-
- 大模型微调数据集格式详解
- Alpaca 格式: instruction, input, output
- ShareGPT 格式: 支持多轮对话
- 其他常见数据集格式(JSONL、CSV等)转换
- HuggingFace 公共数据集的使用
- HuggingFace Datasets库介绍与应用
- 如何下载、加载和预处理公共数据集用于微调
- 自定义数据集的构建与处理
- 文本数据的收集与清洗
- 数据标注策略与工具选择
- 自定义数据集转换为 LLaMA-Factory 支持的格式
- 数据增强技术在微调中的应用
实践: 准备并配置一个自定义数据集,使其符合 LLaMA-Factory 微调要求。 |
|
高效微调方法 LoRA 实践
-
- LoRA (Low-Rank Adaptation) 原理深入
- LoRA 核心思想:低秩矩阵分解,冻结大部分参数
- LoRA 在大模型微调中的优势:显存占用低、训练速度快、模型小
- 在 LLaMA-Factory 中配置 LoRA 微调
- 选择基础模型与微调数据集
- 详细配置 LoRA 参数: r 值、lora_alpha、lora_dropout等
- 学习率、优化器、批大小等训练参数设置
- 量化 (Quantization) 与 LoRA 结合
- LoRA 微调过程中常见的量化策略(如 QLoRA)
- bitsandbytes 库的使用与配置
- 实验监控与模型评估
- TensorBoard 集成与使用: 监控训练损失、指标变化
- 评估模型的方法:困惑度 (Perplexity)、BLEU/ROUGE、人工评估
- 模型保存与导出
实践: 完成一个 LoRA 微调任务,并进行实验监控和模型评估。 |
|
其他微调方法与训练加速
-
- 其他主流微调方法详解
- Full Parameter Fine-tuning: 全量参数微调的场景与挑战
- Freeze: 冻结部分层进行微调
- Galore: 优化器效率提升技术
- BAdam优化器技术
- P-tuning、Prompt Tuning、Prefix Tuning 等提示工程相关微调方法
- 大模型训练加速技术
- FlashAttention: 优化注意力计算,降低显存消耗
- Unsloth: 针对LoRA微调的性能优化库
- Liger Kernel: 其他自定义核优化技术
- PyTorch DDP、Accelerate、DeepSpeed 等训练框架的基础加速功能
- 模型量化技术深入 (Post-Training Quantization)
- PTQ (Post-Training Quantization): 训练后量化原理与方法
- GPTQ: 针对大模型的高效量化算法
- QAT (Quantization Aware Training): 量化感知训练简介
- AQLM、OFTQ: 其他高级量化技术
实践: 尝试使用一种除 LoRA 外的微调方法,或在微调过程中应用训练加速技术。 |
|
大模型分布式微调与高级优化 |
分布式训练环境与网络配置
- 分布式训练基础
- 单机多卡与多机多卡的区别与挑战
- 数据并行、模型并行、流水线并行
- 网络环境的解读与配置
- 如何确定不同主机的IP地址
- 集群网络拓扑、带宽、延迟对分布式训练的影响
- InfiniBand、RoCE等高性能网络技术简介
- 分布式通信原语
- All-reduce, Gather, Scatter等操作
- NCCL、Gloo 等通信后端
实践: 搭建一个简单的多卡分布式训练环境,并验证网络连通性。 |
|
主流分布式微调框架与技术
- DDP (Distributed Data Parallel) 详解
- DDP 原理:数据并行、梯度同步
- LLaMA-Factory 中 DDP 的配置与使用
- DDP 的优缺点及适用场景
- DeepSpeed 深度解析
- DeepSpeed 核心功能:优化器状态分区、梯度分区、参数分区
- DeepSpeed ZeRO 阶段解读:
- ZeRO-1: 优化器状态分区
- ZeRO-2: 优化器状态+梯度分区
- ZeRO-3: 优化器状态+梯度+参数分区
- DeepSpeed ZeRO 显存优化效果与实现细节
- LLaMA-Factory 中 DeepSpeed 的配置与实践
- FSDP (Fully Sharded Data Parallel) 详解
- FSDP 原理:分片化数据并行,更细粒度的显存优化
- FSDP 与 DeepSpeed ZeRO-3 的对比与选择
- LLaMA-Factory 中 FSDP 的配置与使用
- 其他分布式训练优化
- 梯度累积(Gradient Accumulation)、混合精度训练 (AMP)
- Checkpointing、Offloading等技术
实践: 在 LLaMA-Factory 中尝试使用 DeepSpeed ZeRO-2/3 或 FSDP 进行分布式微调,并对比不同配置下的资源占用和训练速度。 |
|
模型蒸馏原理与实战 |
- 什么是知识蒸馏
- 蒸馏目标:降低模型体积和计算量,保持性能
- 基本要素:教师模型、学生模型、知识载体
- 狭义与广义知识蒸馏
- 大模型知识蒸馏的主流技术方法
- 基于输出的蒸馏:软标签蒸馏、生成式蒸馏
- 基于特征的蒸馏:中间层特征模仿、注意力蒸馏
- 结构化蒸馏:模型结构迁移、知识图谱蒸馏
- 动态蒸馏与自蒸馏:在线蒸馏、自蒸馏
- 大模型特有的蒸馏挑战与解决方案
- 模型规模差距过大及解决方法
- 模型架构不同,特征无法对齐
- 生成式大模型的蒸馏难点及解决方法
- 实战项目:
- 基于输出的蒸馏:复现DeepSeek蒸馏Qwen1.5B-distill模型全流程
- 基于特征的蒸馏:挑一个LLM(如:Qwen、Bert等)进行基于输出层的对齐蒸馏(看前面讲的时间决定是否要讲)
|
|
大模型高效部署与应用 |
模型部署基础与推理优化
- 模型部署的挑战与目标
- 显存占用、推理速度、并发量、稳定性
- 模型版本管理、A/B测试、灰度发布
- 大模型推理优化技术
- KV Cache 优化: 减少重复计算
- 批处理 (Batching): 提高GPU利用率
- 模型剪枝 (Pruning): 结构化剪枝、非结构化剪枝
- 模型编译与加速: ONNX Runtime、TensorRT、OpenVINO等
- 模型服务化与API设计
- RESTful API设计原则
- gRPC在高性能服务中的应用
|
|
大模型部署方案实践
- Ollama 部署实践
- Ollama 简介:轻量级本地大模型运行框架
- Ollama 安装与模型下载
- 使用 Ollama 部署微调后的模型
- Ollama 的优缺点及适用场景
- VLLM + FastAPI 高性能部署
- VLLM 原理深入: PagedAttention、连续批处理等高效推理技术
- FastAPI 框架介绍: 高性能Web框架
- 构建 VLLM + FastAPI 服务:
- 编写 FastAPI 应用,集成 VLLM 推理后端
- 通过 OpenAI 兼容性接口访问模型
- 性能压测与优化
- 其他部署方案简介
- Triton Inference Server、OpenVINO Model Server、Ray Serve 、SGlang
- 基于Kubernetes的弹性伸缩部署
实践: 完成一个 VLLM + FastAPI 的大模型部署服务,并通过 OpenAI 兼容性接口进行访问。
实践:性能压测方法与优化 ,性能压测代码实现与指标观测、业务算力预估方法
- 其他部署方案简介
- Triton Inference Server、OpenVINO Model Server、Ray Serve 、SGlang
- 基 于Kubernetes的弹性伸缩部署
实践: 完成一个SGlang部署LLM服务 |
|
MLOps与大模型生命周期管理
- MLOps核心理念与工作流
- 数据版本管理、模型版本管理、实验管理
- 自动化训练、自动化部署、持续集成/持续交付(CI/CD)
- MLOps在大模型场景的特殊挑战
- 模型规模大、训练成本高、数据隐私复杂
- 模型漂移检测与自动再训练
|
|
综合实践与未来展望 |
综合项目实践
- 项目选择与需求分析
- 结合学员兴趣或实际业务场景,选择一个大模型应用项目
- 如:特定领域(金融、医疗、工业等)的智能问答系统、代码生成助手、报告摘要生成器等。
- 数据准备与微调实践
- 数据集收集、清洗、标注(或使用公开数据集)
- 选择合适的微调方法(LoRA/DeepSpeed/FSDP),进行模型训练
- 实验监控与评估
- 模型优化与部署实践
- 应用量化、推理加速等优化技术
- 选择合适的部署方案(Ollama/VLLM+FastAPI),搭建推理服务
- 进行简单的功能测试与性能测试
|
|
未来展望与职业发展
- 大模型技术发展趋势
- 更大的模型、更强的多模态能力
- 更高效的训练与推理框架
- Agent、具身智能、AGI发展方向
- 工业界大模型应用趋势
- 垂直领域大模型、企业私有化部署
- 大模型与边缘计算、数字孪生等技术融合
- AI工程师的职业发展路径
- 专家型技术人才、AI架构师、MLOps工程师、AI产品经理
- 持续学习与知识更新的重要性
|
|
技术扩展:AI大模型技术扩展(录播)
对AI大模型应用以及技术生态的知识体系做系统化扩展,成为AI大模型全栈人才! |
|
小白从0到1玩转AI Agent独立搭建个性化的智能体应用 |
|
课程名称 |
主要内容 |
课程目标 |
|
Dify |
课程大纲:Dify+DeepSeek构建智能体
课程时长:3-4课时
目标受众:
有AI/机器学习基础的开发人员、算法工程师、数据科学家
负责AI模型开发、训练、部署与运维的技术人员
希望深入理解Dify的小白
第一部分:Dify介绍(1-2课时)
1.1Dify平台介绍
1.2Dify平台私有化部署
1.3Ollama部署
1.4Dify接入模型管理
1.5Dify接入在线模型
第二部分:Dify构建智能体(1-2课时)
2.1智能对话机器人
2.2智能面试官
2.3智能旅游系统
2.4智能客服
2.5企业私有知识库。 |
本课程旨在帮助具有技术背景的学员,系统掌握利用Dify开源框架与DeepSeek等主流大模型,从零开始私有化部署AI开发平台,并设计、开发与部署符合企业级需求的复杂AI智能体应用。课程将涵盖从本地模型(Ollama)与在线模型(DeepSeek)的集成与管理,到应用编排(工作流/Agent)的核心开发能力,最终使学员能独立完成一个高定制化、可私有部署的AI智能体解决方案。 |
|
COZE智能体搭建实战 |
课程介绍:
1-1节初识COZE打造自己的第一个工作流:新闻搜索与总结
1.工作流要完成的任务与节点定义
2.插件配置方法与参数
3.大模型节点配置方法
4.结束节点配置
5.智能体配置方法
1-2节新闻稿创作工作流(循环使用方法)
1.循环节点方法解读
2.循环中参数的定义方法
3.续写新闻稿件方法(循环中间变量使用)
4.智能体测试与输出节点
5.批处理的作用与效果
8-3节历史人物视频素材生成
1-3节历史人物视频素材生成
1.做视频素材业务逻辑分析
2.做剧本节点系统提示词方法
3.完成剧本节点输出
4.画面描述与图像生成节点构建
5.图像违规词限制与运镜节点
6.视频节点构建与错误分析
7.图像生成节点错误调试并保险
8.视频生成节点容易违规的解决方法
9.选修(当作拓展知识):配置外部视频软件成为插件
10.选修:自定义插件配置方法实例
11.选修:工作流中添加视频插件
1-4节历史人物自动化剪辑实例
1.时间线定义方法
2.剪映插件介绍
3.时间线和素材绑定方法
4.剪映草稿添加素材方法
5.得到合成后的视频
1-5节智能客服工作流
1.对话流配置与创建
2.选择器的使用方法
3.数据库与大模型的匹配方法
4.知识库构建与匹配方法
5.汇总输出与测试。
1-6节数据分析工作流
1.效果演示与数据读取
2.数据清洗与处理
3.结合DeepSeek构建代码节点
4.结合DeepSeek进行数据分析
5.配置插件把分析结果存在excel里
6.数据可视化配置方法与节点调试分析
7.不同可视化图表配置方法
8.输出与展示配置
1-7节影刀RPA自动化
1.影刀RPA分析
2.影刀安装方法
3.影刀流程配置方法实例
4.执行循环操作
5.完成文案采集的全部功能
|
本课程旨在帮助零基础的学员系统掌握使用Coze等主流AI平台,从0到1独立设计、搭建并部署个性化的智能体(AI Agent)与应用工作流。课程将覆盖从基础工作流搭建、复杂逻辑处理(如循环与分支)、多模态内容生成(文本、图像、视频),到与企业级场景(智能客服、数据分析)和外部工具(RPA)结合的完整知识体系。最终使学员具备解决实际问题的能力,能够独立开发出功能完整、可交付的AI智能体应用。
总结:通过本课程的学习,学员将从认识单个节点开始,逐步进阶到设计包含逻辑判断、循环控制、多工具调用、多模态输出的复杂工作流,最终具备解决内容创作、客户服务、数据分析、流程自动化等跨领域实际问题的综合开发能力,成为能独立交付项目的AI智能体应用开发者。 |
|
Python |
课程内容:
【基础篇】:Python快速入门
1-1节Python、PyCharm安装与配置
1-2节anaconda环境安装和搭建
1-3节Python简介
1-4节Python数据类型
1-5节Python列表
1-6节Python元组
1-7节Python集合
1-8节Python字典
1-9节Python条件判断
1-10节Python循环
1-11节字典的核心操作
1-12节Set结构
1-13节赋值机制
1-14节判断结构
1-15节循环结构
1-16节函数定义
1-17节模块与包
1-18节异常处理模块
1-19节文件操作
1-20节类的基本定义
1-21节类的属性操作
1-22节时间操作
1-23节Python练习题-1
1-24节Python练习题-2
1-25节 科学计算库-Numpy
1-26节 数据分析处理库-Pandas
1-27节 可视化库-Matplotlib
1-28节 可视化库-seaborn |
掌握python |
|
AutogenStudio(本地化智能体) |
1.Python环境说明
2.AutoGenStudio框架安装与介绍
3.动作API配置方法
4.国内常用API配置方法
5.API接口在线测试
6.工作流配置
7.执行流程与结果
8.API生成方法
9.GroupChat模块
10.执行流程分析
11.外接本地支持库配置方法
12.加入RAG技能
13.LMStudio本地下载部署模型.
14.调用本地模型方法与配置.
15.AutogenStudio本地化部署流程
16.本地化部署接入应用实例
17.调用SD-API完成设计
18.Ollama环境配置与安装.
19.autogen接入本地模型
20.论文概述分析
21.整体框架逻辑介绍
22.项目环境配置
23.基础解读-动作定义方式
24.基础解读-角色定义
25.单动作智能体实现方法
26.多动作配置方法.
27.定时器任务环境配置
28.定时器任务流程解读分析
29.基本Agent的组成
30.Agent要完成的任务和业务逻辑定义
31.问题拆解与执行流程
32.检索得到重要的URL
33.子问题生成总结结果
34.总结与结果输出
35.-案例实战演示与整体架构分析
36.后端GPT项目部署启动
37.前端助手API与流程图配置
38.接入外部API的方法与流程
39.引入API方法解读
40.指令提示构建 |
自己搭建AutogenStudio智能体平台 |
|
知识库与应用拓展 |
1.RAGFLOW介绍和特点
2.RAGFLOW接入本地模型
3.Chat与Embedding模型接入
4.知识库构建实例
5.封装成API调用
6.RAG要完成的任务解读
7.RAG整体流程解读
8.召回优化策略分析
9.召回改进方案解读
10.评估工具RAGAS
11.外接本地数据库工具
12.整体故事解读
13.要解决的问题和整体框架分析
14.论文基本框架分析
15.Agent的记忆信息
16.感知与反思模块构建流程
17.计划模块实现细节
18.整体流程框架图
19.感知模块解读
20.思考模块解读 |
掌握Agent和RAG,并自己搭建独立的知识库系统 |
|
本地大模型微调 |
1.llama3模型下载与配置安装
2.环境相关配置解读
3.工具调用流程拆解
4.功能调用方法实例
5.RAG环境配置搭建
6.LLAMA3应用-RAG搭建方法
7.RAG基本流程分析
8.LORA微调方法
9.指令微调所需数据与模型下载
10.llama3模型微调实例
11.llama3微调后进行量化
12.llama.cpp量化实例
13.部署应用 |
了解并掌握微调,以及微调相关数据LORA等 |
|
5.应用拓展分析 |
1.项目需求分析流程
2.数据与特征库准备
3.模型准备与项目分析
4.模型选择方法总结
5.项目经验总结与优化方法
6.数据挖掘要解决的问题
7.数据处理与清洗分析
8.特征工程的作用与流程
9.机器学习算法分析
10.模板到哪去找
11.知识图谱要解决的问题与流程分析
12.知识图谱项目实际应用分析
13.知识图谱实战应用项目解读
14.大模型要解决的问题和应用分析
15.工具总结分析
16.MOE概述分析
17.MOE模块实现方法解读
18.效果分析与总结
19.RAG与微调可以解决与无法解决的问题
20.RAG实践策略
21.微调要解决的问题 |
企业应用实施经验分享、以及复杂场景下的多维度能力的补充 |
|
从0到1实现AI大模型及各类开源组件的环境部署 |
|
从0到1实现AI大模型及各类开源组件的环境部署 |
- Anacnda环境管理工具的安装视频教程
- Pycharm环境安装与破解及整合Anaconda
- Pycharm+OpenAI运行第一个大模型案例
- Hanlp本地运行出现的问题及操作步骤分析
- Ollama+Deepseek+Anythingllm
- Window环境Deepseek+Ollama+Dify搭建个人旅行助手
- Ubuntu+Deepseek-R1+Ollama+Dify实现旅行助手Agent
- DeepSeek-R1+VLLM本地部署保姆级攻略
- Ubuntu24环境下部署Video-LLaVA-2视频理解大模型
- Window环境下LangChain_ChatChat+Deepseek-R1搭建本地知识库
- AnythingLLM+Ollama基于本地私有化大模型搭建RAG知识库
|
学会独立完成大模型相关应用生态的部署 |
|
LangChain零基础入门到企业级应用实战 |
|
LangChain入门到精通 |
- Langchain简介
- api_key设置
- Langchain中的基本数据结构
- 模型种类
- 提示
- 示例选择器
- 输出解析part1
- 输出解析part2
- 文档加载器
- 文档分割器
- 文档检索
- 记忆
- 链-简单顺序链
- 链-总结链
- Agent智能体简介
|
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。他主要拥有 2 个能力:
- 可以将 LLM 模型与外部数据源进行连接
- 允许与 LLM 模型进行交互
这一章节快速帮大家实现LangChain的基础入门,并熟练使用LangChian的各种API和组件 |
|
LangChain应用实战 |
- 总结摘要
- 上下文问答
- 结构化提取
- 评估
- SQL 查询
- 代码理解
- api交互
- 聊天机器人
- Agent
|
LangChain是一个强大的框架,主要帮助开发人员使用语言模型构建端到端的应用程序。
它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。
通过这一阶段的学习,可以用LangChain结合场景实现应用的开发落地 |
|
LangGraph入门到精通 |
- 简单的图
- langraph中的链
- 路由
- react agent
- agent和记忆
- 图状态一览
- 图状态更新
- 多重状态
- 修剪过滤消息
- 流式输出
- 断点
- 外部控制修改图状态
- 动态断点
- 并行运行
- 子图
- Map reduce控制流
|
LangGraph 是一个有用于构建有状态和多角色的 Agents 应用,它并不是一个独立于 Langchain 的新框架,而是基于 Langchain 之上构建的一个扩展库,可以与 Langchain 现有的链(Chains)、LangChain Expression Language(LCEL)等无缝协作。
|
|
RAG入门到精通 |
- 介绍
- 索引part1
- 索引part2
- 索引part3_词嵌入-案例实战
- 索引part4_总结
- 索引全流程-案例实战
- 检索
- 索引
- 生成
- 生成_-案例实战
- 问题改写
- 问题改写_-案例实战
- 问题改写_rerank_-案例实战
- 问题分解
- 问题分解_-案例实战
- 问题回退
- 问题回退-案例实战
- 虚拟文档
- 虚拟文档-案例实战
- 路由
- 路由-案例实战
- 结构化搜索
- 结构化搜索-案例实战
|
检索增强生成 (RAG) 是一种使用来自私有或专有数据源的信息来补充文本生成的技术。它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如大型语言模型 (LLM),此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。
通过从更多数据源添加背景信息,以及通过训练来补充 LLM 的原始知识库,检索增强生成能够提高搜索体验的相关性。
企业级大模型应用必备能力。 |



 10
10 0
0


 已为社区贡献8条内容
已为社区贡献8条内容

{kind=link}
所有评论(0)