2万字吊打40万字:为什么我的“牛马Agent”比“数字分身”更聪明?
本文分享了作者开发的两个AI助手:牛马Agent(职场总结)和网络分身Agent(数字分身)。通过对比发现,数据量较小的牛马Agent表现更优,因其定位明确、数据结构化程度高。作者总结出三点经验:1)明确Agent边界和定位;2)重视数据质量而非数量;3)场景理解比技术实现更重要。最后提供了数字分身Agent的体验链接,并预告将继续分享垂类Agent的实践经验。
我最近尝试做了两个Agent:一个是在工作中给我做年底工作总结的,另一个是我在网络上的数字分身,这里我分别叫它牛马Agent和网络分身Agent。
先说下两个Agent的实现。技术方案完全一样:先把我能找到的内容切片后灌入向量数据库,然后给Agent设置一个身份和简单的背景信息,关键是告诉它需要自行检索向量数据库来完成对话。懂行的同学已经看出来了,其实就是一个Agentic RAG。
这里给大家简单介绍下Agentic RAG ,这是一种智能检索增强生成技术。与传统 RAG 直接用用户问题检索不同,Agentic RAG 让 AI 自主决定检索策略、动态生成查询关键词,并能进行多轮检索和推理,就像一个主动思考的研究助手。
如图是我用n8n快速的牛马Agent 的具体实现: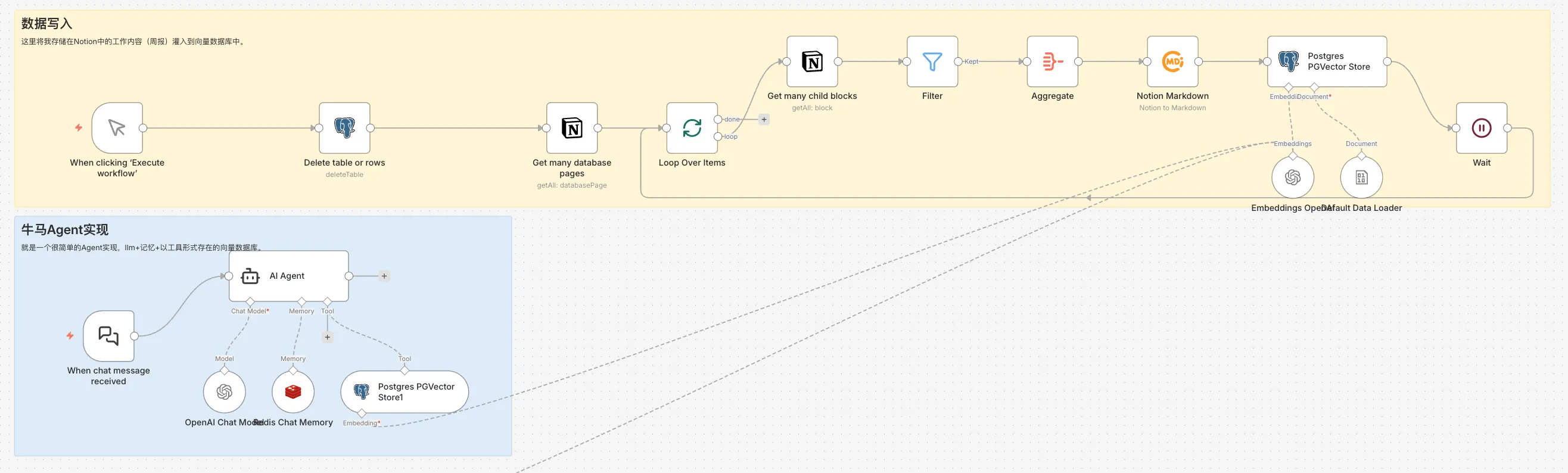
核心分两个流程
- 数据写入:数据初始化流程,手动触发将 Notion 中记录的工作内容召回并导入向量数据库。这里使用基于 PostgreSQL 实现的 PGVector,n8n 中有对应节点可直接使用。
- 问答流程:这个问答流程其实就是标准的Agentic RAG 流程,用户提问后,Agent 会先分析问题,生成合适的检索关键词,然后从向量数据库中召回相关内容,最后基于召回的上下文生成回答。整个过程完全自动化,Agent 可以根据问题复杂度自主决定是否需要多轮检索。
网络分身Agent的实现与牛马Agent一致(不再赘述),区别仅在于向量数据库中存储的数据,以及 System Prompt 差异。牛马Agent主要使用工作相关数据,核心是每周周报,涵盖所有项目进展、思考和总结,总计40来份周报,累计不到 2w 字。而网络分身Agent中,我放入的是我在各个平台的输出内容——博客文章、社交媒体发言、技术分享、个人思考等。数据量方面,有400多篇博客,还有2年多周报中脱敏后的思考总结,累计40万字以上。
无奖竞猜环节:你觉得哪个Agent的问答效果会更好?答案出乎意料——是牛马Agent!没错,就是底层数据量只有网络分身Agent十分之一的那个。
这个我没办法去量化它俩之间之间效果的差异,就从我使用的感受上来说下,我在和牛马 Agent 对话的时候,它给我的答案远超我预期,如果真让它替我去给老板们去做述职总结,它的回答一定比我的更符合老板眼中优秀员工的标准,回答有条有理、逻辑清晰,面对职场灵魂拷问还能保持情绪稳定。反观数字分身Agent,它给我的答案就远不及预期,整个回答就很 AI,虽然它能够引用我写过的内容,但往往缺乏针对性,回答显得泛泛而谈。
然后我就开始思考,究竟是什么导致了两个Agent效果上的巨大差异。思考了两天后,我终于悟了——其实结果本该如此,是我对数字分身Agent抱有了过多不切实际的幻想。我总结起来,其实有以下两大核心因素导致效果的差异。
1. 角色定位的差异
牛马Agent更像一个"纯职能型"角色——它的定位很明确:帮助我完成年终总结。因为任务单一,它只需要关注工作相关的内容,检索和回答都围绕着一个清晰的目标展开。由于牛马Agent的角色定位非常明确,上下文也不多,所以我在实现时甚至直接将所有周报内容提炼后放到了System Prompt里,而知识库只负责承载一些细节。 另外一点,大家在提问的时候,由于知道它是牛马 Agent,所以提问的问题也没有脱离它的能力范畴。
相比之下,网络分身Agent的定位是"代表你本人",需要回答各种问题——技术问题、人生感悟、个人观点等。一方面,Agent的System Prompt只能给出模糊的身份定位;另一方面,用户提问时不会刻意限制问题范围。这导致Agent需要应对的场景过于宽泛,检索效果自然大打折扣。
2. 数据结构化程度与内容特性的差异
信息的连续性: 牛马Agent的数据大部分围绕具体项目展开,工作事项之间有明确的延续性和因果关系。比如一个项目从立项、开发、测试到上线,整个过程在周报中形成了完整的叙事链条。这种连续性让Agent在回答"某个项目进展如何"时,能够串联起多个时间点的信息,给出有逻辑的完整答案。相比之下,网络分身Agent的博客内容大多是独立的观点和思考,每篇文章都是一个完整的闭环,文章之间缺乏明确的关联性。这导致在回答需要综合多个观点的问题时,Agent难以建立有效的信息关联。
信息聚焦程度: 工作周报的内容高度聚焦——每一条记录都围绕着明确的目标(项目交付、问题解决、进度推进)。这种聚焦性使得检索时的语义匹配更加精准,因为查询意图和文档内容的主题高度一致。而博客内容的主题范围极其广泛,从技术深度剖析、到职场感悟、再到生活思考,甚至一篇文章内就可能横跨多个话题。这种发散性在检索时会引入更多干扰,降低了召回内容的针对性。
信息的密度: 周报数据经过了刻意的结构化处理,每条信息都有明确的上下文(时间、项目、进展状态)和核心要点。信息密度高,冗余少,每个句子都承载着明确的事实。这种高密度让向量检索时的语义匹配更准确,因为查询意图和文档结构高度对齐。博客内容则往往包含大量修辞、情绪表达、背景铺垫等"软信息"。这些内容虽然让文章更有可读性和感染力,但在检索时会稀释核心事实的权重,导致召回结果的相关性下降。
以上就是我对这两个 Agent 的思考和总结。回顾整个实践过程,这是两次非常有价值的尝试——牛马 Agent 超出预期的表现让我看到了 Agent 在垂直场景的巨大潜力,而网络分身 Agent 虽未达预期,却恰恰暴露了当前技术在处理复杂、开放场景时的局限性。最后总结几点核心认知:
- 明确 Agent 的边界和定位至关重要。现阶段,定位清晰、职责明确的 Agent 效果远胜于"万能型" Agent。真正"无所不能"的 Agent 可能还需等待技术进一步成熟。当下能够落地的 Agent 应该聚焦于特定场景,解决特定问题。
- 数据、数据还是数据。小而精的数据效果远比大而泛的数据更好。高度结构化、主题聚焦的数据能够让 Agent 提供更精准、更有深度的回答。与其追求数据量的堆砌,还不如关注数据质量和与应用场景的匹配度。
- Agent落地技术实现反而没那么重要,核心挑战在于场景理解和数据质量。只要有明确的应用场景和高质量数据,即便使用最基础的 RAG 方案也能取得不错的效果。过度追求技术复杂度反而可能偏离实际需求,而这恰恰是很多技术同学常犯的错误。
最后,由于工作内容无法公开,我的牛马Agent无法供大家体验,但数字分身Agent可以:🔗 数字分身Agent体验地址:https://s.zxs.io/xindoo。我最近在工作中也在持续推进垂类 Agent 的建设和落地,后续会分享一些不涉及公司机密的实践经验。感兴趣的话可以关注我——xindoo。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)