【专辑】AI大模型应用开发入门-拥抱Hugging Face与Transformers生态 - 使用Transformers加载预训练模型 - 预训练模型结构文件介绍
《AI大模型应用开发入门教程》介绍了HuggingFace与Transformers生态的核心内容,包括预训练模型加载、微调、评估等关键技术。重点解析了模型文件结构:.gitattributes确保跨平台一致性;README.md提供项目说明;config.json定义模型架构参数;pytorch_model.bin/tf_model.h5存储权重;tokenizer相关文件处理文本分词。特别讲解
大家好,我是java1234_小锋老师,最近更新《AI大模型应用开发入门-拥抱Hugging Face与Transformers生态》专辑,感谢大家支持。
本课程主要介绍和讲解Hugging Face和Transformers,包括加载预训练模型,自定义数据集,模型推理,模型微调,模型性能评估等。是AI大模型应用开发的入门必备知识。

预训练模型结构文件介绍
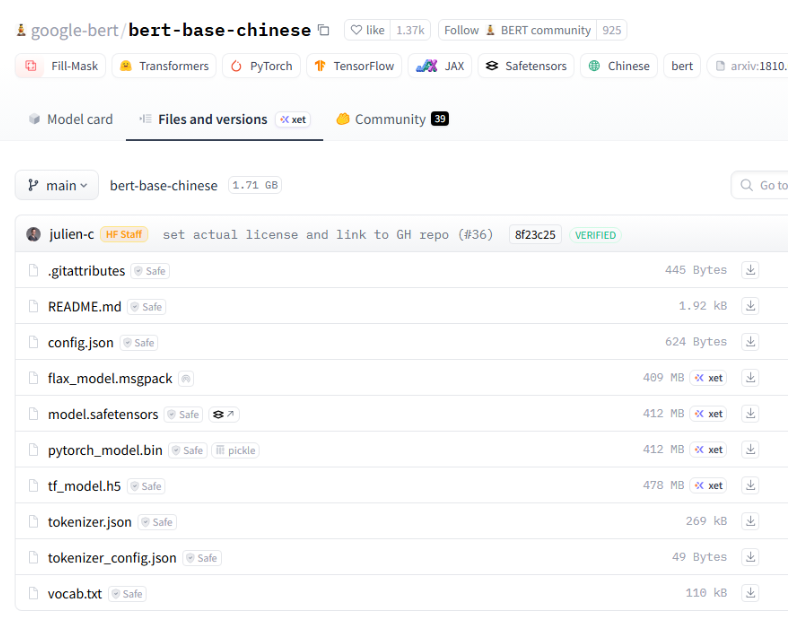
-
.gitattributes
这是一个 Git 配置文件,用于指定如何处理储存在 Git 仓库中的不同类型的文件。它可以定义文本文件的换行符、文件合并策略,以及某些文件在 Git 操作中的特殊处理方式(例如,指示某些文件使用特定的 diff 工具)。在机器学习项目中,使用 .gitattributes 文件可以确保项目在多平台上具有一致性。
-
README.md
这是一个 Markdown 格式的文档,通常用于描述项目的目的、功能、安装说明和使用方法。它是开源项目的"介绍性文档",提供给用户和开发者了解项目的重要信息。良好的 README 文件可以大大增加用户的使用体验和项目的可访问性。
-
config.json
这个文件通常包含模型的配置参数,比如模型的架构、超参数(如学习率、batch size)和训练细节。该文件为模型的加载和初始化提供了必要的信息,使得在不同平台或环境间共享模型变得更加容易。
-
flax_model.msgpack
这个文件是使用 Flax 库(一个用于构建神经网络的库,基于 JAX)保存的模型。在机器学习中,使用特定格式(如 msgpack)保存模型可以有效地进行序列化和反序列化,以便在不同的脚本或机器之间共享和加载。
-
model.safetensors
这是针对模型权重的保存格式,它通常用来在安全和效率之间取得良好平衡。safetensors格式避免了一些常见的安全问题,特别是在加载未验证的模型时。它旨在提升安全性,同时仍然保持高效的存储性能。
-
pytorch_model.bin
这是 PyTorch 框架中常见的模型权重文件,采用二进制格式存储模型的权重与参数。它是通过调用 model.save_pretrained() 方法生成的,通常与 PyTorch 的 transformers 库一起使用,便于模型在不同的应用中共享和加载。
-
tf_model.h5
这是 TensorFlow 框架中的模型保存文件,通常使用 HDF5 文件格式,对应于使用 TensorFlow/Keras 框架训练生成的模型。HDF5 是一种用于高效存储大型数据集的格式,.h5 文件可用于保存模型的权重、训练配置以及优化器状态等信息。
-
tokenizer.json
这个文件通常存储了与特定文本处理和模型输入相关的分词器(tokenizer)配置信息。它包含了分词器如何将原始文本转换为模型可以理解的输入格式的信息,例如词汇表(vocabulary)和编码方式。该文件有助于确保输入的正确预处理。
-
Update tokenizer.json
这个文件显然是一个临时或附加的配置文件,可能是为了更新现有的分词器或添加新的词汇。具体内容和功能依赖于项目的实际操作。
-
tokenizer_config.json
这个文件包含有关分词器的配置信息,比如使用的分词算法类型(BPE、WordPiece等),以及特殊标记(如填充标记和开始/结束标记)。它在加载分词器时提供了必要的上下文,以确保分词器的正确运行。
-
vocab.txt
这个文件通常存储模型使用的词汇表。分词器会使用这个文本文件中的信息来识别和映射特定的单词或标记。词汇表是训练模型时的重要部分,因为它可以直接影响模型的性能和生成的文本的质量。
总结
以上文件共同构成了一个深度学习模型和分词器的完整定义及其配置,是在机器学习和 NLP 项目中不可或缺的组成部分。在模型的开发和部署过程中,正确管理和使用这些文件,对于确保模型的复现性、可重用性以及性能至关重要。
config.json
{
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 21128
}
这个 JSON 配置文件看起来是针对 BERT 模型的,其中包含了模型架构及其相关超参数的定义。以下是每个字段的详细解释:
-
architectures
-
类型: 数组
-
作用: 定义模型的架构类型。这里的
"BertForMaskedLM"表示该模型是用于任务“Mask Language Modeling”(掩码语言建模)的 BERT 模型。
-
attention_probs_dropout_prob
-
类型: 浮点数
-
作用: 表示在注意力机制中应用的 dropout 概率。0.1 表示有 10% 的概率将注意力概率置为零,以防止过拟合。
-
directionality
-
类型: 字符串
-
作用: 指定模型的方向性。
"bidi"表示这是一个双向模型,可以从句子的两端同时接收上下文信息。
-
hidden_act
-
类型: 字符串
-
作用: 定义隐藏层的激活函数。在此配置中,使用的是
"gelu"(高斯误差线性单元),被认为相较于标准的 ReLU 更能提升模型性能。
-
hidden_dropout_prob
-
类型: 浮点数
-
作用: 在隐藏层中应用的 dropout 概率,0.1 表示有 10% 的概率对隐藏层输出应用 dropout,有助于防止过拟合。
-
hidden_size
-
类型: 整数
-
作用: 定义每个隐藏层的大小(向量维度),在这里是 768。这意味着每个隐藏状态被表示为一个 768 维的向量。
-
initializer_range
-
类型: 浮点数
-
作用: 指定模型参数初始化时的范围,通常在 [-initializer_range, initializer_range] 之间。0.02 表示参数初始化的标准差。
-
intermediate_size
-
类型: 整数
-
作用: 定义中间层的大小。在 Transformer 的前馈神经网络中,通常大于隐藏层的大小。这里是 3072,意味着中间层的输出维度是 3072。
-
layer_norm_eps
-
类型: 浮点数
-
作用: 指定层归一化(Layer Normalization)时使用的小正数,用于避免除以零的情况。这里是 1e-12。
-
max_position_embeddings
-
类型: 整数
-
作用: 定义模型能够处理的最大序列长度(即最大位置嵌入),在这里是 512,这意味着输入序列的最大长度是 512 个标记(tokens)。
-
model_type
-
类型: 字符串
-
作用: 指明模型的类型,此处为
"bert",表明该架构是 BERT。
-
num_attention_heads
-
类型: 整数
-
作用: 定义注意力头的数量,这里是 12,表示在多头自注意力机制中使用了 12 个注意力头。
-
num_hidden_layers
-
类型: 整数
-
作用: 指定 Transformer 模型中的隐藏层数量,这里是 12,表示该 BERT 模型有 12 层的编码器堆叠。
-
pad_token_id
-
类型: 整数
-
作用: 表示填充标记的 ID,0 通常用于标记“填充”位置,以便模型在处理不同长度的输入时能够合理对齐。
-
pooler_fc_size
-
类型: 整数
-
作用: 是 BERT 模型池化层中全连接层的大小,通常等于隐藏层的大小,这里是 768。
-
pooler_num_attention_heads
-
类型: 整数
-
作用: 池化层中使用的注意力头的数量,通常和编码层相同,这里是 12。
-
pooler_num_fc_layers
-
类型: 整数
-
作用: 池化层中的全连接层数量,这里是 3,表示在池化过程中应用了三层全连接网络。
-
pooler_size_per_head
-
类型: 整数
-
作用: 指明每个注意力头输出的维度大小,这里是 128,通常计算为
hidden_size / num_attention_heads。
-
pooler_type
-
类型: 字符串
-
作用: 表示池化层采用的类型,此处的
"first_token_transform"表示使用第一个 token 的表示经过线性变换作为整个序列的表示。这在分类任务中是常用的做法。
-
type_vocab_size
-
类型: 整数
-
作用: 定义类型词汇的大小。在 BERT 中,通常为 2,用于区分句子 A 和句子 B。
-
vocab_size
-
类型: 整数
-
作用: 表示模型使用的词汇表的大小,在这里是 21128,说明模型可以识别 21128 个不同的标记(tokens)。
-
[UNK]
-
全名: Unknown Token
-
作用: 这个标记用于表示模型无法识别的输入词汇或符号。当输入文本中存在不在模型词汇表中的单词时,这些单词将被替换为
[UNK]。它的目的是确保模型可以处理未知输入,而不会导致错误或中断。
-
[CLS]
-
全名: Classification Token
-
作用:
[CLS]标记通常添加到输入序列的开头,特别是在需要分类任务(如情感分析、句子分类等)时。模型在训练时会使用这个标记的最终隐藏状态作为对整个句子的表示,以便进行分类或其他任务。
-
[SEP]
-
全名: Separator Token
-
作用:
[SEP]标记用于分隔不同的句子或段落。在处理句子对(例如问题-答案、句子相似性任务)时,[SEP]可以清晰地表明两个句子之间的分界,帮助模型理解输入的结构。
-
[MASK]
-
全名: Mask Token
-
作用: 在掩码语言建模(Masked Language Modeling)任务中使用。该标记表示输入文本中某些单词已经被掩盖,模型的任务是根据上下文预测这些被掩盖的单词。通过这种方式,模型能够学习上下文关系和语言结构。
-
<S>
-
全名: Start Token
-
作用: 通常用于在序列生成任务(如机器翻译、文本生成等)中指示序列的开始。它可以帮助模型明确输入的起点,并相应地调整输出。
-
<T>
-
全名: Token (or Terminate Token)
-
作用: 类似于
<S>,通常用于指示序列的结束,标记生成序列中最后一个 token 的位置。在一些序列生成任务中,它可以帮助模型识别何时停止生成内容。
[PAD] 是一种特殊的标记(token),通常用于自然语言处理(NLP)模型中,尤其是在处理变长序列或批量输入时。以下是 [PAD] 标记的详细解释:
-
全名
-
Padding Token(填充标记)
-
作用
-
填充序列: 在自然语言处理任务中,模型通常需要处理固定长度的输入序列。然而,实际的文本序列往往具有不同的长度。为了使所有输入序列具有相同的长度,可以添加
[PAD]标记,以填充较短的序列。这种填充确保模型能够在批处理过程中均匀处理输入,避免因不同长度导致的计算问题。
-
应用场景
-
批量处理: 在训练和推理过程中,通常会将多个样本组合成一个批次(batch)进行并行处理。通过使用
[PAD]标记,将所有输入序列填充到相同的长度,可以有效提高模型的计算效率。 -
序列标记任务: 在任务如命名实体识别(NER)或文本分类中,
[PAD]标记用于保持输入序列的一致性,确保模型能够正确对齐输出和输入。
-
示例
假设有以下三个样本:
-
"我爱学习"(3 个字)
-
"人工智能很有趣"(6 个字)
-
"自然语言处理"(5 个字)
当将这三个样本填充到最大长度为 6 时,可以得到:
-
"我爱学习" → "我爱学习 [PAD]"
-
"人工智能很有趣" → "人工智能很有趣"
-
"自然语言处理" → "自然语言处理 [PAD]"
这样填充后的序列长度一致,便于输入模型。
tokenizer_config.json 分词器配置文件
{"do_lower_case": false, "model_max_length": 512}
-
do_lower_case
-
类型: 布尔值(boolean)
-
作用: 指定在文本预处理时是否将输入文本转换为小写。当设置为
false时,文本将保持其原始大小写。当设置为true时,所有的字母将被转换为小写。这项配置通常影响分词器的行为,尤其是在处理大小写敏感的任务时(例如命名实体识别或某些分类任务),保留原始大小写可能是很重要的。
-
model_max_length
-
类型: 整数
-
作用: 指定模型可以接受的最大输入长度(token数量)。在您的配置中,此值为 512,意味着模型可以处理最多 512 个标记(tokens)。超出此长度的文本通常需要截断或分割,以确保输入能够适应模型的要求。这项配置对于管理长文本输入特别重要,因为 Transformer 类模型的结构通常限制了最大输入长度。
vocab里面好和##好的区别
在自然语言处理(NLP)领域的词汇表(vocabulary)中,像 好 和 ##好 这样的词汇通常在使用子词(subword)分割技术的模型中出现,特别是在基于字典的分词方法(如 BERT、WordPiece 和 SentencePiece)中。以下是它们之间的主要区别:
-
好
-
完整的单词: 这个词可以被视为一个完整的词汇单元。它通常表示“好”的意思,是一个常见的中文词汇。
-
在词汇表中的表示: 如果使用的模型词汇表中包含
好,则模型可以直接使用这个单词进行训练和推理,而无需进一步的拆分。
-
##好
-
子词表示:
##前缀表示这是一个子词(subword)单元。具体来说,它表示这个词是由前面的部分词(prefix)构成的一部分。在 WordPiece 分词中,这种表示法通常用于处理那些不在词汇表中的较长词。 -
用于词汇表补充: 比如,对于一个较长的词汇,如果它不能完整出现在词汇表中,模型会将这个词拆分成更小的部分,并使用
##前缀来指示这些部分。这样,当模型处理较复杂的词时可以更有效地捕捉语义。
示例
假设我们有一个词汇表,其中包含以下词语:
-
电子 -
产品 -
好
如果输入文本是“电子产品好”,然后进行分词:
-
“电子产品好” 可能被分词为
电子、产品和##好,其中##好指的是“好”这个词的子词表示。
为什么使用子词表示
-
处理未知词: 通过使用子词表示,模型可以处理那些它从未见过的词,即使是从已知的子词构建的词。
-
减少词表大小: 有了子词单元,模型的词汇表可以变得小得多,因为它可以灵活构建较长的词而不需要为每个可能的组合创建一个词条。
-
语义保持: 子词保持了对原有词的语义,同时又能支持更广泛的表达,可以帮助模型更好地理解文本的上下文。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)