【专辑】AI大模型应用开发入门-拥抱Hugging Face与Transformers生态 - 使用Transformers加载预训练模型 - 加载和使用预训练模型实例
《HuggingFace与Transformers入门指南》介绍了AI大模型应用开发的基础知识,重点讲解如何使用HuggingFace生态中的Transformers库。课程内容包括预训练模型加载(如Google BERT)、自定义数据集处理、模型推理与微调等核心内容。通过Pipeline API可快速实现文本分类、情感分析、命名实体识别等常见NLP任务,并详细解析了pipeline方法的各项参数
大家好,我是java1234_小锋老师,最近更新《AI大模型应用开发入门-拥抱Hugging Face与Transformers生态》专辑,感谢大家支持。
本课程主要介绍和讲解Hugging Face和Transformers,包括加载预训练模型,自定义数据集,模型推理,模型微调,模型性能评估等。是AI大模型应用开发的入门必备知识。

加载和使用预训练模型实例
我们第一个helloWorld示例,用下经典的Google-Bert大模型。
Google BERT(Bidirectional Encoder Representations from Transformers)是谷歌于2018年发布的开源自然语言处理(NLP)预训练模型,标志着NLP领域进入预训练模型的新时代。
BERT的核心突破在于双向上下文理解。与传统语言模型仅从左到右或从右到左进行预测不同,BERT通过Transformer编码器结构,同时利用句子前后所有词语的信息进行训练。这种双向性使其能更精准捕捉语言的复杂语义和上下文关联。
BERT采用两项关键预训练任务:掩码语言模型(MLM)随机遮盖部分词语让模型预测,以及下一句预测(NSP)判断两个句子是否连续。通过在海量文本上预训练后,只需针对特定任务(如文本分类、问答、情感分析)进行微调,即可获得卓越性能。
BERT开源后迅速成为NLP领域的基石模型,催生了ALBERT、RoBERTa等众多改进模型,并广泛应用于搜索引擎、智能客服、机器翻译等场景,显著提升了机器理解人类语言的能力。
下载地址:
https://huggingface.co/google-bert/bert-base-chinese
安装transformers库。
pip install transformers -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
Transformers Pipeline 是 Hugging Face 提供的一个高层次的 API,旨在简化使用预训练的 Transformer 模型进行各种自然语言处理(NLP)任务。这个工具使得开发者可以方便地加载、配置和使用各种模型,以完成文本分类、文本生成、命名实体识别(NER)、翻译等任务。以下是对 Transformers Pipeline 的详细介绍:
-
基本概念
-
Pipeline的作用:Pipeline 提供了一种简单的接口,用于快速执行常见的 NLP 任务。用户只需调用相应的任务函数,不需要深入理解模型的底层实现细节。
-
支持的任务
Transformers 提供的 Pipeline 可以用于多种 NLP 任务,包括但不限于:
-
文本分类(Text Classification):例如情感分析,给定一段文本,判断其情感倾向(积极、消极等)。
-
命名实体识别(Named Entity Recognition,NER):识别文本中的特定实体,如人名、地名、组织名等。
-
问答(Question Answering):给定上下文和问题,模型返回问题的答案。
-
文本生成(Text Generation):生成连续的文本,例如基于某些输入文本生成合理的后续内容。
-
翻译(Translation):将文本从一种语言翻译为另一种语言。
-
摘要(Summarization):生成给定长文本的简短摘要。
示例代码:
from transformers import pipeline
# 情感分析任务
def test_classfication():
# 1,下载模型 https://huggingface.co/google-bert/bert-base-chinese
# 2,创建模型,通过 pipeline 函数
model = pipeline(
task='text-classification', # 任务类型
model='./Bert-base-chinese', # 模型
device=0 # GPU 设备索引
)
# 3,调用模型,返回输出结果
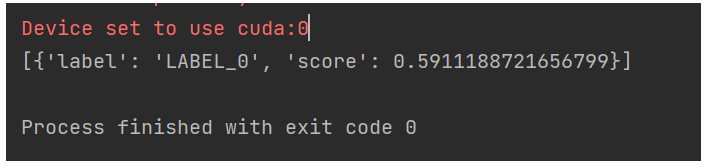
result = model('今天天气不错')
print(result)
if __name__ == '__main__':
test_classfication()运行输出:
在 Hugging Face 的 Transformers 库中,pipeline 方法用于简化模型的使用,使用户能够轻松地执行各种自然语言处理任务。这个方法的参数允许用户根据不同的需求配置和使用模型。以下是 pipeline 方法主要参数的简介:
-
task
-
类型:
str -
描述:指定要执行的任务类型,例如
"sentiment-analysis"、"text-classification"、"translation"、"question-answering"等。 -
示例:
pipeline("sentiment-analysis")
-
model
-
类型:
str或PreTrainedModel -
描述:指定要加载的模型名称或路径。可以使用 Hugging Face 模型库中的模型名称,也可以指向本地保存的模型路径。
-
示例:
pipeline("translation", model="Helsinki-NLP/opus-mt-en-fr")
-
tokenizer
-
类型:
str或PreTrainedTokenizer -
描述:指定要使用的分词器名称或路径。通常,如果模型和 tokenizer 是配套的,可以省略此参数,默认会自动加载合适的 tokenizer。
-
示例:
pipeline("text-classification", model="dbmdz/distilbert-base-uncased-finetuned-sst-2-english", tokenizer="dbmdz/distilbert-base-uncased-finetuned-sst-2-english")
-
config
-
类型:
str或PretrainedConfig -
描述:指定模型配置的名称或路径。通常情况下,除非需要特别定制模型的行为,否则可以省略此参数。
-
示例:
pipeline("ner", model="bert-base-uncased", config="path/to/config.json")
-
device
-
类型:
int -
描述:指定要使用的计算设备。可以用于选择 CPU(-1)或 GPU(一般为 0,1,2 等)。例如,如果有多个 GPU,可以指定使用哪一个。
-
示例:
pipeline("text-classification", model="model-name", device=0)(使用第一个 GPU)
-
revision
-
类型:
str -
描述:指定模型的特定版本,例如分支或标签等。如果不特别指定,将默认加载最新版本。
-
示例:
pipeline("sentiment-analysis", model="model-name", revision="specific-branch-or-tag")
-
use_auth_tokens
-
类型:
bool或str -
描述:在访问某些需要授权的模型时,可以通过设置这个参数来使用 Hugging Face 的认证令牌。可以设置为
True,使得会自动使用 Hugging Face 的令牌;或者提供具体的认证令牌。 -
示例:
pipeline("text-classification", model="model-name", use_auth_token=True)
-
return_all_logits
-
类型:
bool -
描述:是否返回所有类别的 logits,通常对多分类任务很有用。默认值为
False,即只返回预测的标签。 -
示例:
pipeline("text-classification", model="model-name", return_all_logits=True)
-
kwargs
-
类型:
Any -
描述:可以传递其他模型具体支持的参数,根据不同的任务可能会有不同的可选参数。
-
示例:使用模型特定的参数例如
top_k、max_length等。
task (`str`):
The task defining which pipeline will be returned. Currently accepted tasks are:
- `"audio-classification"`: will return a [`AudioClassificationPipeline`].
- `"automatic-speech-recognition"`: will return a [`AutomaticSpeechRecognitionPipeline`].
- `"depth-estimation"`: will return a [`DepthEstimationPipeline`].
- `"document-question-answering"`: will return a [`DocumentQuestionAnsweringPipeline`].
- `"feature-extraction"`: will return a [`FeatureExtractionPipeline`].
- `"fill-mask"`: will return a [`FillMaskPipeline`]:.
- `"image-classification"`: will return a [`ImageClassificationPipeline`].
- `"image-feature-extraction"`: will return an [`ImageFeatureExtractionPipeline`].
- `"image-segmentation"`: will return a [`ImageSegmentationPipeline`].
- `"image-text-to-text"`: will return a [`ImageTextToTextPipeline`].
- `"image-to-image"`: will return a [`ImageToImagePipeline`].
- `"image-to-text"`: will return a [`ImageToTextPipeline`].
- `"keypoint-matching"`: will return a [`KeypointMatchingPipeline`].
- `"mask-generation"`: will return a [`MaskGenerationPipeline`].
- `"object-detection"`: will return a [`ObjectDetectionPipeline`].
- `"question-answering"`: will return a [`QuestionAnsweringPipeline`].
- `"summarization"`: will return a [`SummarizationPipeline`].
- `"table-question-answering"`: will return a [`TableQuestionAnsweringPipeline`].
- `"text2text-generation"`: will return a [`Text2TextGenerationPipeline`].
- `"text-classification"` (alias `"sentiment-analysis"` available): will return a
[`TextClassificationPipeline`].
- `"text-generation"`: will return a [`TextGenerationPipeline`]:.
- `"text-to-audio"` (alias `"text-to-speech"` available): will return a [`TextToAudioPipeline`]:.
- `"token-classification"` (alias `"ner"` available): will return a [`TokenClassificationPipeline`].
- `"translation"`: will return a [`TranslationPipeline`].
- `"translation_xx_to_yy"`: will return a [`TranslationPipeline`].
- `"video-classification"`: will return a [`VideoClassificationPipeline`].
- `"visual-question-answering"`: will return a [`VisualQuestionAnsweringPipeline`].
- `"zero-shot-classification"`: will return a [`ZeroShotClassificationPipeline`].
- `"zero-shot-image-classification"`: will return a [`ZeroShotImageClassificationPipeline`].
- `"zero-shot-audio-classification"`: will return a [`ZeroShotAudioClassificationPipeline`].
- `"zero-shot-object-detection"`: will return a [`ZeroShotObjectDetectionPipeline`].在 Hugging Face 的 Transformers 库中,pipeline 方法支持多种自然语言处理(NLP)任务。这些任务涵盖了文本处理的多个方面,适合于不同的应用场景。以下是一些常见的任务及其简要描述:
-
文本分类(Text Classification)
-
描述:将输入文本分配到一个或多个类别。
-
示例:情感分析(判断一段文字是积极、消极或中性)。
pythonpipeline("text-classification")
-
情感分析(Sentiment Analysis)
-
描述:专门的文本分类,用于判断文本的情绪倾向。
-
示例:判断一条评论是正面的、负面的还是中性的。
pythonpipeline("sentiment-analysis")
-
命名实体识别(Named Entity Recognition, NER)
-
描述:识别文本中具有特定意义的实体,如人名、地点、组织名等。
-
示例:在句子 “Apple是一家科技公司” 中识别出 “Apple” 是一个组织实体。
pythonpipeline("ner")
-
问答(Question Answering)
-
描述:给定一个上下文和一个问题,模型返回上下文中的答案。
-
示例:在给定文本中回答特定的问题。
pythonpipeline("question-answering")
-
文本生成(Text Generation)
-
描述:基于输入文本生成一个或多个后续文本段落。
-
示例:给定一段文本生成完整的故事或段落。
pythonpipeline("text-generation")
-
机器翻译(Translation)
-
描述:将输入的文本从一种语言翻译成另一种语言。
-
示例:将英语转换为法语,或将中文转换为英文。
pythonpipeline("translation-en-to-fr") # 英语到法语
-
摘要(Summarization)
-
描述:为给定的长文本生成一个简短的摘要。
-
示例:从一篇文章中提取出其关键点。
pythonpipeline("summarization")
-
文本填空(Fill-Mask)
-
描述:在给定的上下文中,预测被遮住的单词或短语。
-
示例:在句子 "我喜欢吃[MASK]" 中预测被遮住的部分。
pythonpipeline("fill-mask")
-
句子相似度(Sentence Similarity)
-
描述:比较两个句子的相似度,通常用于语义匹配等任务。
-
示例:判断两条句子是否表达相似的意思。
pythonpipeline("text-similarity") # 请注意,这个任务的具体实现可能取决于模型。
-
多模态任务(如图像标注、图像分类等)
-
描述:处理图像与文本结合的任务(需特定模型支持)。
-
示例:图像分类,或者图像生成描述。
pythonpipeline("image-classification") # 图像分类,使用相关模型
-
自定义任务
-
描述:根据需要自定义特定的 NLP 任务,通常需要使用自定义模型。
pipeline("custom-task")
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)