强化学习、PPO和GRPO算法之间的关系
强化学习和监督学习是机器学习中的两种不同的学习范式,强化学习让智能体通过与环境的交互,学习到一个最优策略,以最大化长期累积奖励,如下图在这里引入了几个关键参数:状态(State:表示当前的状态行动(Action:表示下一步操作奖励(Reward:根据行动导致环境改变,由规则给出的评分智能体(Agent):执行行动的主体(如机器人、游戏 AI 等)环境(Environment):智能体所处的外部场景
目录
强化学习模型(Reinforce Learning Model)
什么是强化学习(RLHF)
强化学习和监督学习是机器学习中的两种不同的学习范式,强化学习让智能体通过与环境的交互,学习到一个最优策略,以最大化长期累积奖励,如下图
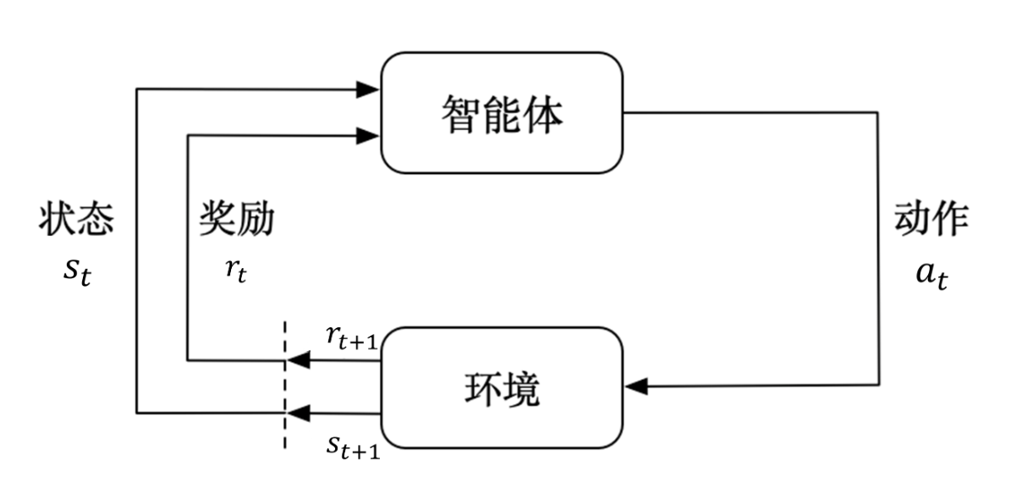
在这里引入了几个关键参数:
状态(State):表示当前的状态
行动(Action):表示下一步操作
奖励(Reward):根据行动导致环境改变,由规则给出的评分
智能体(Agent):执行行动的主体(如机器人、游戏 AI 等)
环境(Environment):智能体所处的外部场景(如游戏地图、机器人工作空间等)
策略(Policy):策略简单的理解就是智能体根据当前的状态state,做出下一步操作action,有了策略之后,就可以不断在每个状态下,决定执行什么动作,进而进入下一个状态,依次类推完成整个任务
举个例子说明:在机器人导航任务中,智能体需要学习如何在复杂环境中移动,以最快速度到达目标位置,同时避免碰撞障碍物,这个过程中智能体要不断尝试不同的行动序列来找到最优路径。在这个例子里面状态可以理解为当前位置,行动理解下一步走哪里,奖励理解为行动后根据规则给出的评分
在强化学习过程中智能体需要学习的有策略和价值函数
价值函数(Value Function)
状态价值函数

表示从状态s开始,遵循策略π所能获得的长期累积奖励(rt)的期望
动作价值函数
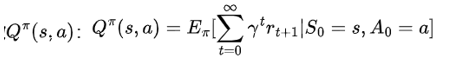
表示在状态s下采取行动a,遵循策略π所能获得的长期累积奖励的期望
二者关系
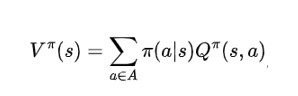
强化学习(RLHF)的实现方式
目前主流的方式有PPO、GRPO、DPO,其中DPO跳过reward model训练,直接使用两个数据进行学习,实际上DPO并不是严格意义的强化学习,更适合叫对比学习
什么是PPO算法和GRPO算法
PPO算法
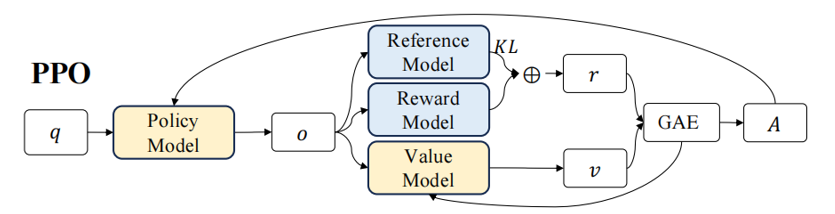
以PPO算法举个例子
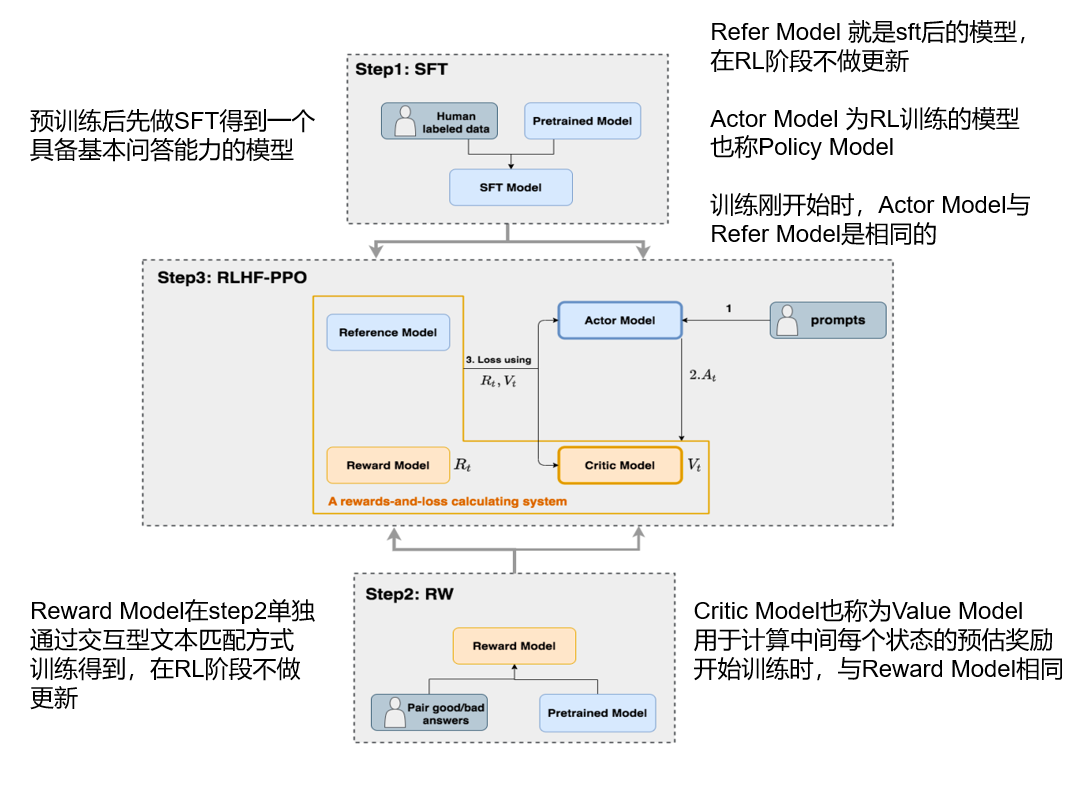
先有一个预训练和有监督微调(SFT)的基础语言模型Refer Model生成初始输出(如:a furry mammal)这个模型参数在RL微调过程中一般保持冻结,不进行反向传播,复制一份基础模型,作为策略模型Actor Model,在强化学习框架中对其进行微调,也会生成新的答案(如:man’s best friend)。接着用单独训练好的奖励模型Reward Model对策略模型生成的答案进行打分,分数越高表示答案越符合,Reward Model保持冻结,复制一个奖励模型作为预评估模型Critic Model对每个输出答案进行预估奖励,图解如下,其中Actor Model是要训练的模型:
GRPO算法
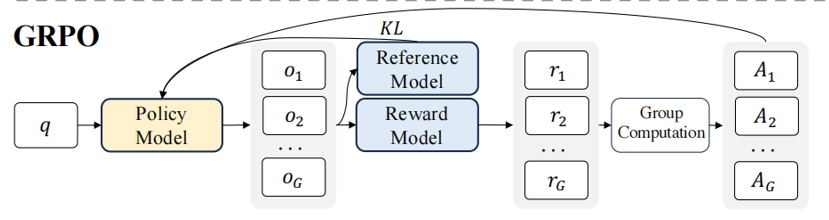
与PPO算法不同的是GRPO使用上文输入进行多次采样,生成多个预测结果,并分别使用 Reward Model对这些预测结果进行评分,最后取这些评分的平均值来替代 Critic Model的预期总收益,这样可以减少一个模型的前向和反向传播计算,从而降低计算资源的消耗
奖励模型(Reward Model)
损失函数公式为 Pairwise Ranking Loss,具体如下:
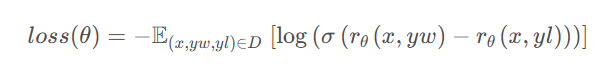
右边部分为做了个分数差,其中rθ是一个交互式文本匹配模型,输出为标量(0-1),x为问题(Prompt),yw为相对好的输出结果,yl为相对差的输出结果。我们希望分数差越大越好,σ是一个softmax归一化,分数越大概率越接近1,计算loss的时候越小,对结果再做个log,最小化loss,等价于最大化分数差。
————————————————
版权声明:本文为CSDN博主「放松吃羊肉」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_54713489/article/details/148556725
强化学习模型(Reinforce Learning Model)
损失函数公式如下:
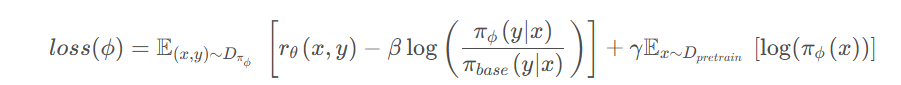
其中![]() 为奖励模型RW的打分,越高越好,
为奖励模型RW的打分,越高越好,![]() 衡量强化学习微调后的模型分布和原本模型分布的“距离”。防止模式坍缩,即维护模型输出的,
衡量强化学习微调后的模型分布和原本模型分布的“距离”。防止模式坍缩,即维护模型输出的,![]() 让RL 模型不要遗忘预训练阶段学到的知识。让 RL 微调后的模型还能保留通用能力,防止灾难性遗忘
让RL 模型不要遗忘预训练阶段学到的知识。让 RL 微调后的模型还能保留通用能力,防止灾难性遗忘
————————————————
版权声明:本文为CSDN博主「放松吃羊肉」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_54713489/article/details/148556725

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)